目录
MVCC
一致性非锁定读和锁定读
他们都是读操作,但是被分为了两类。一致性非锁定读(快照读) 和锁定读(当前读)
|--------|---------------------------------------------|--------------------------------------------------------------------------|
| 特性 | 一致性非锁定读(快照读) | 锁定读(当前读) |
| 本质 | 读取数据的历史版本(undo log) | 读取数据的最新版本 |
| 加锁 | 不加锁(读不加锁) | 加行锁 / 表锁(读也要加锁) |
| 依赖机制 | MVCC + Read View | 锁机制(行锁、间隙锁) |
| 适用 SQL | 普通 SELECT(不加 FOR UPDATE/LOCK IN SHARE MODE) | SELECT ... FOR UPDATE、SELECT ... LOCK IN SHARE MODE、INSERT/UPDATE/DELETE |
| 并发性能 | 极高(读写不阻塞) | 较低(需等待锁释放) |
| 数据时效性 | 可能不是最新(快照版本) | 绝对最新(当前版本) |
| 隔离级别影响 | RR/RC 下生效,不同级别 Read View 生成时机不同 | 所有级别生效,锁规则一致 |
InnoDB 默认的读方式,同时也是MVCC的实现,都是对应左边的快照读。
左边的快照读,永远不加锁。
写写互斥
|---------------|---------------|---------------|--------------------------------------------|
| 写操作 | 加锁类型 | 锁定范围(RR 级别) | 核心逻辑 |
| UPDATE/DELETE | 排他锁(X 锁)+ 间隙锁 | 匹配行 + 行所在间隙 | 先对匹配行加 X 锁,RR 级别下自动加间隙锁(Next-Key Lock)防止幻读 |
| INSERT | 插入意向锁 + 排他锁 | 插入行的位置间隙 + 新行 | 先加插入意向锁(不阻塞其他插入),插入成功后对新行加 X 锁 |
| REPLACE | 排他锁(X 锁) | 匹配行 + 新行 | 先删除旧行(加 X 锁),再插入新行(加 X 锁) |
场景示例:
-- 事务A(ID=10)
BEGIN;
UPDATE user SET age=20 WHERE id=1; -- 对id=1加X锁,未提交
-- 事务B(ID=20)
BEGIN;
UPDATE user SET age=21 WHERE id=1; -- 申请id=1的X锁,但已被事务A占用
-- 结果:事务B阻塞,直到事务A提交/回滚释放X锁
-- 这就是"写写互斥",InnoDB自动保证,无需手动干预MVCC解决的是读,当需要写操作时,使用的不是MVCC而是锁机制。
MVCC的底层实现
一、概念
-
MVCC(Multi-Version Concurrency Control,多版本并发控制) 是InnoDB存储引擎实现非阻塞读、读写并发的核心机制,通过为数据生成多个历史版本,让不同事务读取对应版本的数据,避免加锁导致的性能损耗。
-
核心作用:读的时候不加锁、读 写不阻塞。专门负责读操作,与写操作无关。
二、核心1:隐藏字段
InnoDB会为每行数据隐式添加3个字段,是MVCC实现的基础
++以下3个核心字段属于每行数据++
-
DB_TRX_ID :记录最后修改该行的事务ID(插入/更新/删除)
-
DB_ROLL_PTR :回滚指针 ,指向该行数据的上一个历史版本(历史数据存储在undo log)
-
DB_ROW_ID:隐藏行ID,无主键/唯一索引时,生成聚簇索引
三、核心2:undo log
undo log是事务回滚 和MVCC读取历史版本的关键,分为两类:
-
insert undo log:事务插入数据生成,仅用于事务回滚,提交后直接删除(无MVCC复用价值,因为是新数据,没有历史undo log链条)。
-
update undo log :事务更新/删除数据生成,记录数据的历史版本,事务提交后不会立即删除,供MVCC读取历史版本使用,由purge线程异步清理。
四、核心3:Read View(一致性视图)
Read View是事务启动时生成的快照
++以下4个核心字段属于Read View++
-
m_ids :生成Read View时,所有活跃未提交的事务ID集合。
-
min_trx_id :m_ids中的最小事务ID。
-
max_trx_id :生成Read View时,下一个要分配的事务ID(不是最大活跃ID)。
-
creator_trx_id :当前事务自身的ID。
m_ids 是 [min_trx_id, max_trx_id) 区间的子集 , min_trx_id不仅是m_ids的最小值,也是区间内的最小值。
[min_trx_id, max_trx_id) 这个区间里,包含:
活跃事务(在 m_ids 里)
已经提交的事务(不在 m_ids 里)
举个例子:
假设:
全局下一个 ID:max_trx_id = 100
当前活跃事务:m_ids = { 80, 90, 95 }
所以:min_trx_id = 80
现在区间是:80 ≤ DB_TRX_ID < 100
这个区间里有哪些 ID:80、81、82、...、99
但m_ids 只有:80、90、95,这三个是事务未提交 不可见的。剩余的都是已提交,可见的**。**
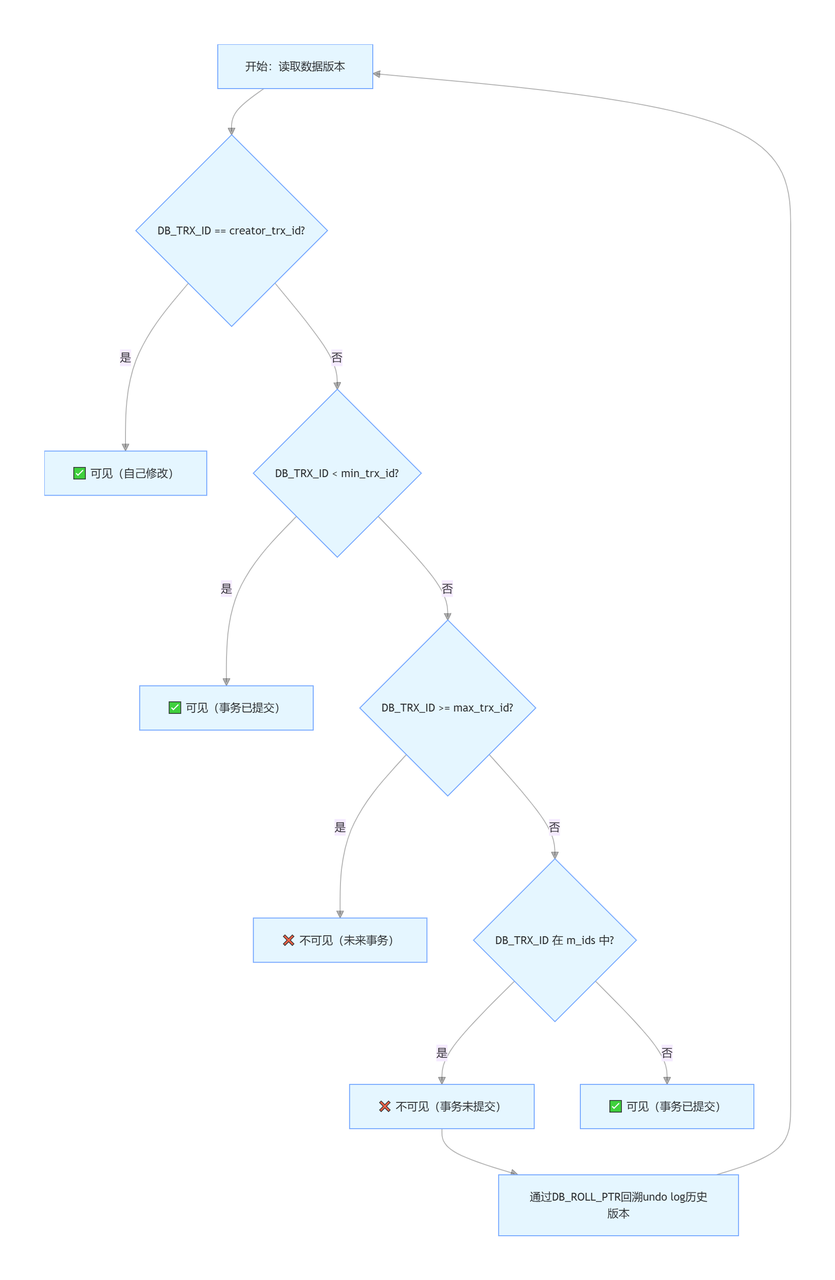
五、可见性判断规则
读取数据时,对比数据的DB_TRX_ID与Read View:
-
若
DB_TRX_ID = creator_trx_id:可见(自己改的肯定能看到)。 -
若
DB_TRX_ID < min_trx_id:可见(早于所有活跃事务,已提交)。 -
若
DB_TRX_ID >= max_trx_id:不可见(还没分配 ID,不存在)。 -
若
min_trx_id ≤ DB_TRX_ID < max_trx_id:-
若
DB_TRX_ID在m_ids中:不可见(事务未提交)。 -
若
DB_TRX_ID不在m_ids中:可见(事务已提交)。
-
不可见时,通过DB_ROLL_PTR回溯undo log中的历史版本,直到找到可见版本。
六、MVCC与事务隔离级别
MVCC仅支持读已提交(RC) 和可重复读(RR) 两个隔离级别,区别在于Read View的生成时机:
-
读已提交(RC)
-
事务每次执行SELECT时都重新生成Read View。
-
保证:只能看到已提交事务的数据(解决脏读,允许不可重复读)。
-
-
可重复读(RR,MySQL默认)
-
事务第一次执行SELECT时 生成Read View,整个事务期间复用。
-
保证:事务内多次读取同一数据,结果一致(解决不可重复读)。
-
七、示例
详见JavaGuide。
补充:事务ID什么时候分配?
不是 BEGIN,也不是 SELECT,是 "第一次写操作" 时分配!
-
BEGIN / START TRANSACTION → 不分配 ID
-
普通 SELECT(快照读) → 不分配 ID
-
第一次执行 INSERT / UPDATE / DELETE / SELECT ... FOR UPDATE → 才分配事务 ID
因为只读事务不需要写 undo log,不需要事务 ID,节省资源。
上述内容也同步在我的飞书,欢迎访问
https://my.feishu.cn/wiki/QLauws6lWif1pnkhB8IcAvkhncc?from=from_copylink
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,你们的支持就是我坚持下去的动力!