
关闭
关闭并上载,翻译一下,就是保存的意思。会把结果和查询的步骤都保存下来,结果会生成到Excel里。
查询
刷新预览
刷新的概念
刷新 = 重新执行查询步骤,从数据源读取最新数据并生成结果
当源数据(例如 Excel 表)发生变化时:
- 不需要重新导入源数据
- 不需要重新创建查询
- 只需要点击刷新 → 查询会按照已有步骤重新生成最新结果
使用场景区分(手动&自动)
连接外部数据源(依赖手动刷新)
- 查询在 Excel 表 A
- 源数据来自 Excel 表 B、CSV、数据库等外部文件
- 查询不会自动更新
需要手动刷新(或设置自动刷新)才能获取最新数据,手动刷新就是本小节提到的"刷新预览"和"全部刷新"
同一工作簿数据源(可能自动刷新)
例如:查询在 Sheet1,源数据在 Sheet2
- Excel 可能触发内部联动刷新
- 修改源数据后,查询结果往往会自动更新
- 但这种更新不稳定,不应依赖
如果没有更新,需要手动刷新
刷新预览
- 只作用于当前正在编辑的查询
- 重新执行该查询步骤
- 更新编辑器中的预览数据
- ❗ 不会更新 Excel 中的最终结果
全部刷新
- 作用于当前工作簿中的所有查询
- 重新执行所有查询步骤
- 更新所有查询结果(Excel表 / 数据模型)
举个例子
**例子1:**同一工作簿(可能自动刷新)
我有以下数据源sheet1
|-------|----|-----|----|
| | | | |
| 日期 | 客户 | 金额 | 地区 |
| 45292 | 张三 | 100 | 上海 |
| 45293 | 李四 | 200 | 北京 |
| | | | |
| 45294 | 王五 | 150 | 上海 |
我对这个表格/区域导入PQ,进行以下操作步骤,删除空行- 提升标题-筛选出"上海"数据,以下是查询结果。
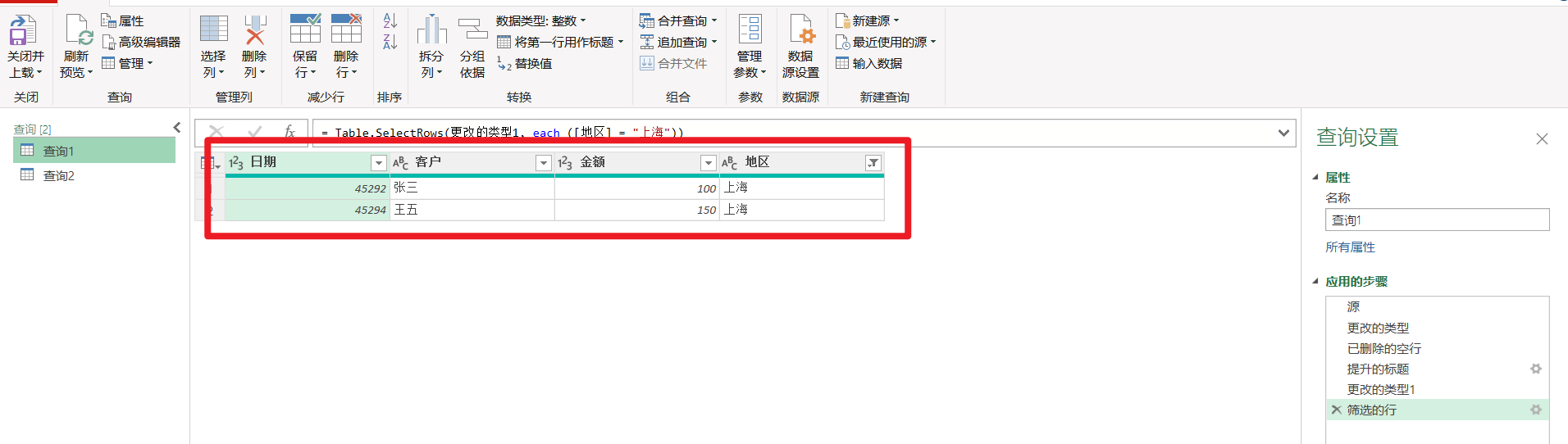
那么我现在对查询进行保存后,修改sheet1的源数据,增加3行上海数据。
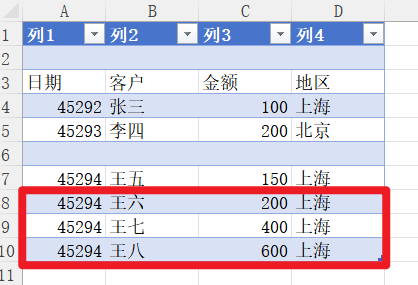
再次打开查询,会发现查询1的预览结果自动更新了,这个是Excel内部机制的自动更新,不稳定,但一般都会自动更新的。
**例子2:**外部数据源(必须手动刷新)
我们创建一个空白Excel表,链接一个外部数据源,创建2个查询,分别叫外部1,外部2。
外部数据源数据如下:
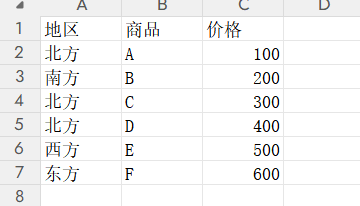
在空白Excel表导入该外部数据,创建的查询1筛选出北方的数据,查询2查询出东方的数据。
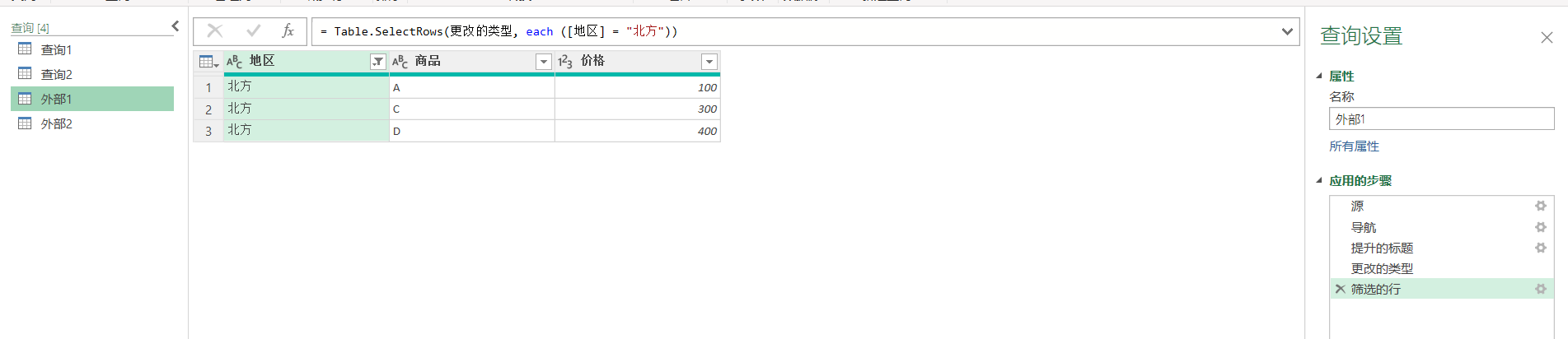
这个时候,我们修改外部的源数据,增加4行数据,2个北方,2个东方,保存更改。
这个时候,我们新建的查询并不会自动更新,我们需要手动的点击刷新。
若点击刷新预览,只会修改选中查询的结果
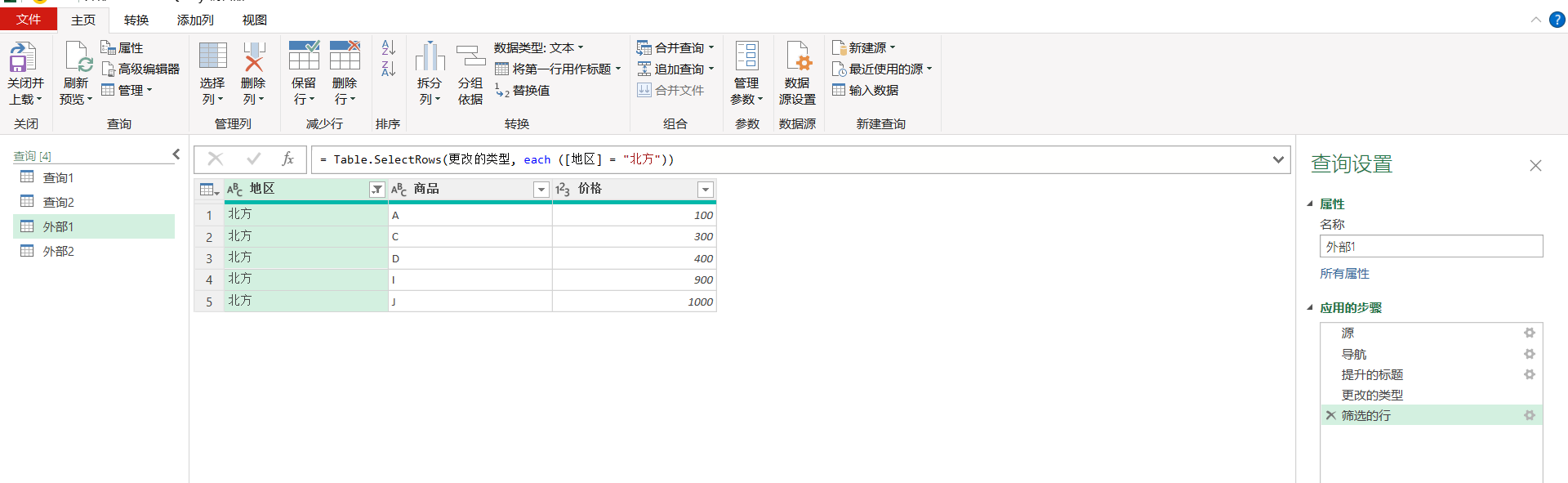
这个时候,外部2的查询是没有更新的,因为刷新预览只是更新当时在编辑的查询。
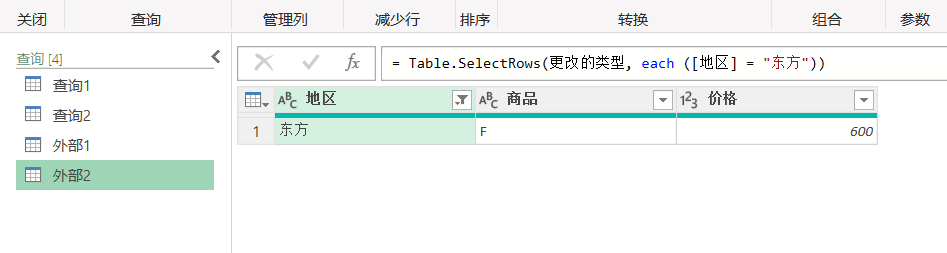
点击全部刷新,外部2的数据都会一起刷新了,全部刷新是针对全部的查询进行刷新。
配置刷新设置
可以更改刷新的配置,来配合自己的工作需求,比如我就不喜欢自动后台刷新,因为不小心改了什么数据我根本就不知道,那我就可以把后台刷新关闭了。
也可以设置全部刷新时,是否要刷新某个查询,也可以设置刷新频率等。
右键查询,点击'属性"即可设置。
属性(查询/修改名字+备注)
作用就是用于查询当前属性的名称和说明,当然也可以同步修改这些内容。
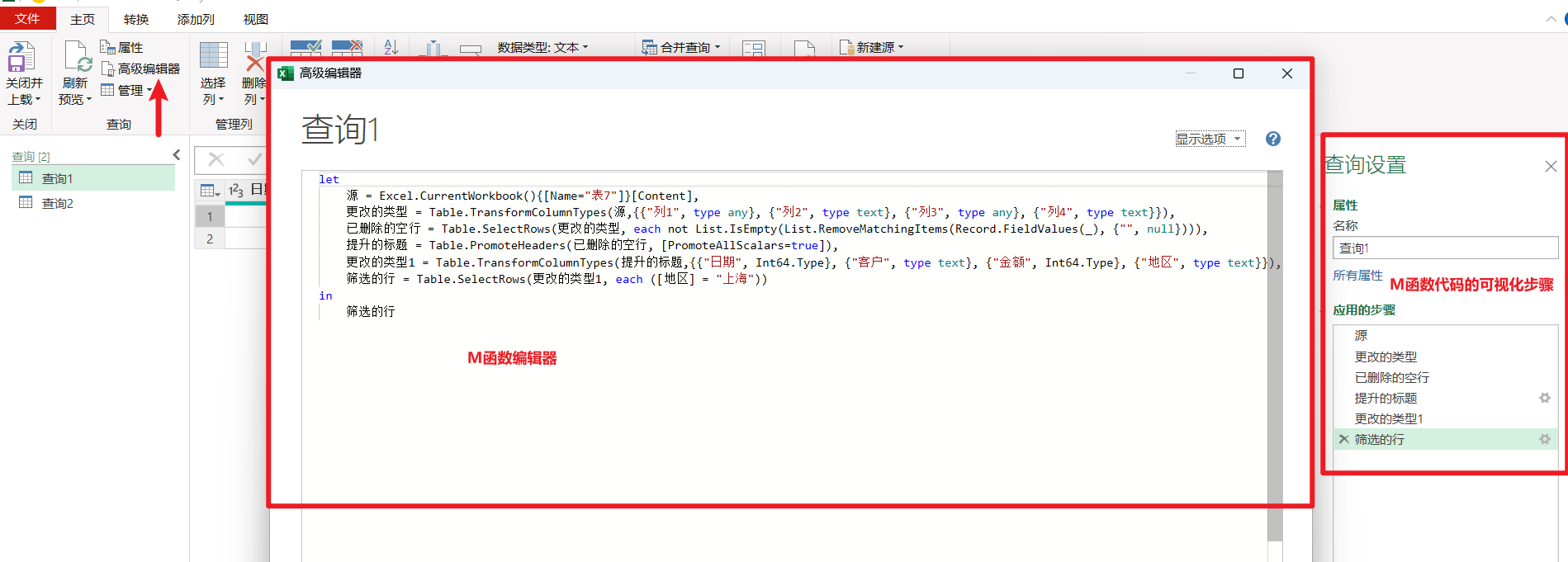
高级编辑器(M语言编辑器)
高级编辑器其实就是是M语言的编辑器,所有查询步骤本质都是M代码实现的。
右侧"应用的步骤"是 M 代码的可视化形式。
如果代码按"逐步命名"的方式编写,每一步都会显示为一个步骤;
如果使用嵌套或合并写法,则可能不会完整显示在步骤中。意思就是只有自己写代码时注意定义步骤,按"逐步命名"的方式,才会显示在右侧的步骤里。
- 逐步命名:每一步都用一个变量名命名,并在下一步明确引用上一步 → 右侧"应用的步骤"会完整显示每一步。
- 嵌套或合并写法:一行代码做多步处理,即使有变量名,也可能不会显示为独立步骤。
- 结论:只有在自己写代码时注意拆分并逐步命名,才能保证每一步在右侧步骤里可见。
可以自己找AI要个代码添加到编辑器里面,测试一下。
管理(管理查询)
对当前查询进行,删除,复制,引用的操作。
管理列(选择列+删除列)
字面意思
减少行(指定行数)
字面意思
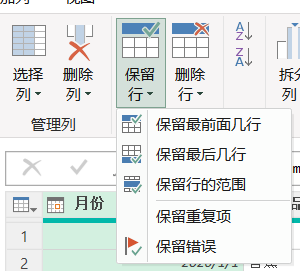
保留行
保留最前面几行,保护最后几行,这个几行是可以指定数目的,自己想搞几行就输入几行。
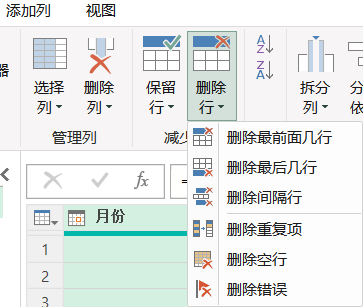
删除行
字面意思。
删除最前面机会,删除最后机会,这个几行是可以指定数目的,自己想搞几行就输入几行。
排序(Excel和PQ排序有差异)
PQ按照unicode排序
PQ的排序和Excel的排序不同,PQ的文本排序是按照unicode码排序的,而Excel在默认为中文系统的情况下,遇上汉字是按照拼音首字母排序的。
- 数字列 → 直接按数值大小排序。
- 文本列 → 按字符的 Unicode 编码 排序。
- 常见错误:以为PQ这边汉字按拼音首字母排序。
- 例如
"安"和"办":拼音分别是An和Ban,有人会以为"安"升序排在前。 - 实际上,PQ 排序看的是 Unicode 编码,而不是拼音。
"安"的 Unicode 比"办"大,所以升序时"办"在前,"安"在后。
- 例如
- Unicode 是固定编码,和拼音无关。
规则如下:
- 按第一个字符的 Unicode 比较
- Unicode 小 → 升序排前
- Unicode 大 → 升序排后
- 如果第一个字符相同
- 再比较第二个字符的 Unicode
- 依次类推,直到能确定顺序
- 如果字符完全一样但长度不同
- 短的排前(升序)
举个例子(Excel和PQ排序差异)
比如我现在对人名进行排序,有一下原始数据,未排序的哈

我在Excel表里对客户名字进行升序排序,结果如下,这是因为按照拼音首字母进行排序,Li,Wang,Zhang
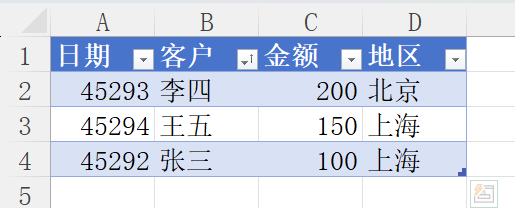
我在PQ里对客户名字进行升序排序,结果如下,这是因为按照第一个字符的unicode进行排序了。
| 名字 | 第一个汉字 | Unicode(十进制) |
|---|---|---|
| 张三 | 张 | 24352 |
| 李四 | 李 | 26446 |
| 王五 | 王 | 29579 |

转换
参考前面的笔记功能区"添加列"或者功能区"转换",里面有解释。
组合
合并查询
应用场景
合并查询可以替代 Excel 中的 VLOOKUP / INDEX + MATCH 等操作,当然这个应用更广。
关键字段 = 用于匹配的列(对应 VLOOKUP 里的查找列)
- 合并查询 = PQ 里的 可视化 VLOOKUP / XLOOKUP
- 作用都是 按关键字段匹配,把另一张表的数据加到当前表里
| Power Query | Excel |
|---|---|
| 匹配列(选中的列) | 查找值列(VLOOKUP 第1列) |
| 左表(主表) | 当前表 |
| 右表(副表) | 被查找的数据表 |
Excel vs Power Query 核心区别
- Excel(VLOOKUP)
- 需要指定返回第几列
- 如果要返回多列 → 每一列都要写一个公式
- 数据量大或字段多时,维护成本高
- Power Query(合并查询)
- 按关键字段匹配后
- 可以一次性展开右表的多个列
- 不需要重复写公式,只需点击展开
基本概念
在 Power Query(PQ)里,主页功能区的 "合并查询" 是用来把 两个或多个查询的数据按照某种关联关系(类似数据库的 Join)组合在一起。
简单说,它就是 把两个表按指定字段匹配,把数据"拼"到一起。
- 查询 A 和 查询 B 都是表格
- 选择 一个或多个关键字段 (就是列名)作为匹配条件
- 合并后会生成一个新的查询,把匹配上的数据加到左表(主表)里
- 类似数据库里的 INNER JOIN / LEFT JOIN
常见操作步骤
- 在 PQ 主页功能区 点击 "合并查询"
- 选择 主表(左表) 和 副表(右表)
- 选择 匹配列(比如名字、ID)
- 选择 联接类型 (Join 类型):
- 左连接(Left Outer):保留左表全部行,右表匹配的列加进来
- 右连接(Right Outer):保留右表全部行
- 内连接(Inner):只保留匹配上的行
- 全连接(Full Outer):左右表所有行,没匹配的空值
- 左反连接(Left Anti):左表中没有匹配的行
- 右反连接(Right Anti):右表中没有匹配的行
- 点击 确定 → 生成新的查询
- 展开右表列,选择需要合并进来的列
举个简单例子
用下面的例子自己试一遍上面的所有连接类型,就能理解每个联接类型的意思了。
A:工资表(主表)
| 员工 | 工资 |
|---|---|
| 张三 | 5000 |
| 李四 | 6000 |
| 王五 | 5500 |
表B:绩效表(副表)
| 员工 | 绩效 |
|---|---|
| 张三 | 优秀 |
| 李四 | 良好 |
| 赵六 | 良好 |
操作:
左联接
结果(新查询)
生成的查询结果默认是table类型,可以点击字段右侧的展开按钮来展开数据
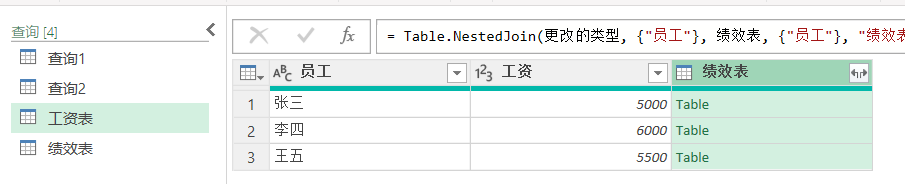
展开后

王五没有匹配 → 工号显示 null
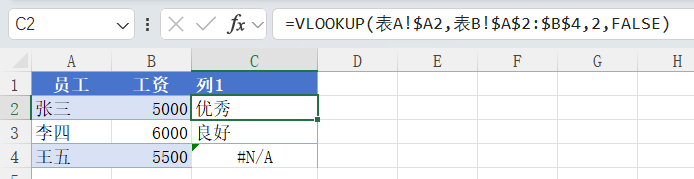
Excel对应的操作
得写一个vlookup
追加查询
在 Power Query 里,"追加查询" 和 "合并查询" 不同,它不是按字段匹配,而是 把两个或多个表"上下叠加"成一个表,就像把表 A 放在表 B 的下面。
应用场景
可以把追加查询理解为一种"手动版的合并文件",但两者适用场景不同:
追加查询和合并文件各有适用场景:
- 追加查询(Append Queries)
- 适合:少量数据源
- 特点:结构可以不完全一致(自动补 null)
- 优点:灵活,可控
- 缺点:需要手动逐个选择数据源
- 合并文件(Combine Files)
- 适合:批量文件(如一个文件夹下多个 Excel/CSV)
- 特点:要求结构基本一致(如 sheet 名、列结构)
- 优点:自动化,一次设置可长期复用
- 缺点:结构不一致时容易出问题
基本概念
- 追加查询 = 堆叠行
- 要求表的 列名和列类型最好一致 ,否则 PQ 会自动对齐列名,不存在的列用
null填充 - 生成的新查询包含 所有表的所有行
举个例子
表A
| 姓名 | 部门 |
|---|---|
| 张三 | 财务 |
| 李四 | 销售 |
表B
| 姓名 | 部门 |
|---|---|
| 王五 | 技术 |
| 赵六 | 财务 |
操作:

结果
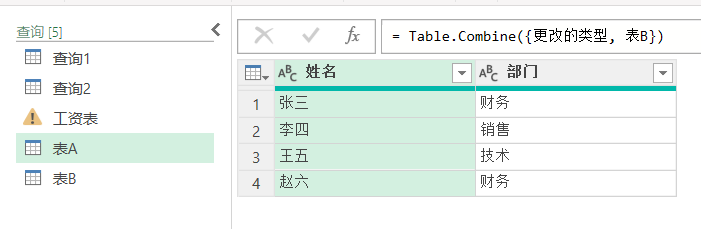
可以看到,行是上下堆叠的,不是按某个字段匹配
如果是三个表及以上的查询追加
结果如下,追加结果是根据列数最多的表来,不存在的列用 null 填充
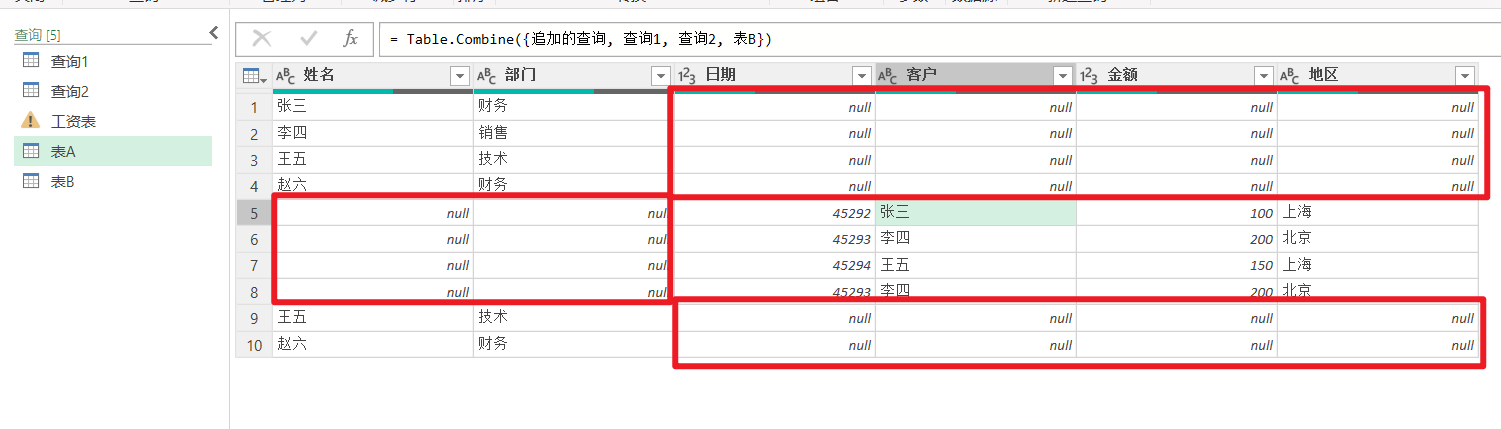
总结对比(合并/追加查询)
| 功能 | 操作方式 | 结果类型 |
|---|---|---|
| 合并查询 | 按匹配列连接(类似 Join) | 左表 + 匹配列(列扩展) |
| 追加查询 | 上下堆叠所有行 | 所有表行累加,列名对齐 |
参数
参数 = 可以被多个查询使用的"可修改变量",面对全局,不只是面对一个查询。
通俗理解的话,就是类比Excel里,绝对引用的单元格A1,参数就等于这个A1。
创建参数
管理参数-点图中的创建,就在右侧输入一些信息。
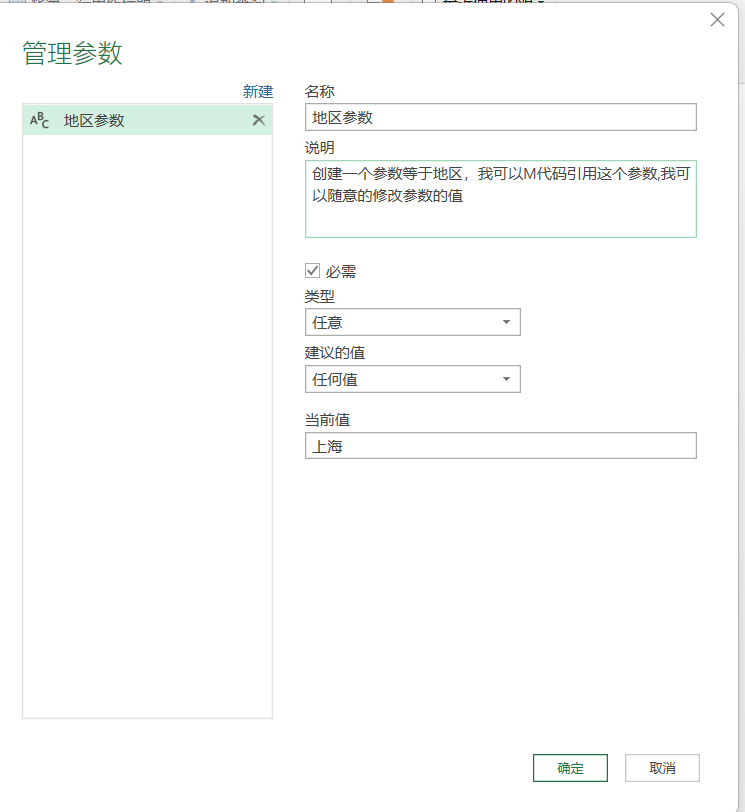
配置中,建议的值解释如下:
| 模式 | 含义 | 使用场景 |
|---|---|---|
| 任意值 | 参数可以填任何值 | 灵活,筛选文本、日期、数字都可以 |
| 列表中的值 | 你可以预先定义一个值列表,下拉选择 | 避免输入错误,比如地区参数只能选"上海/北京/广州" |
| 查询 | 参数值来源于另一个查询生成的列表 | 数据驱动,例如可选年份列表、部门列表等 |
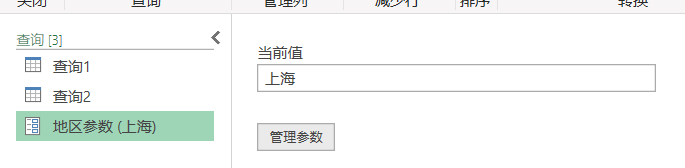
因此我们生成了一个参与,目前值是"上海"
使用参数(修改M代码)
打开查询1,手动筛选一下,M代码会自动生成,我们再打开高级编辑器,把这行代码复制下来。
筛选的行 = Table.SelectRows(更改的类型1, each (地区 = "上海"))
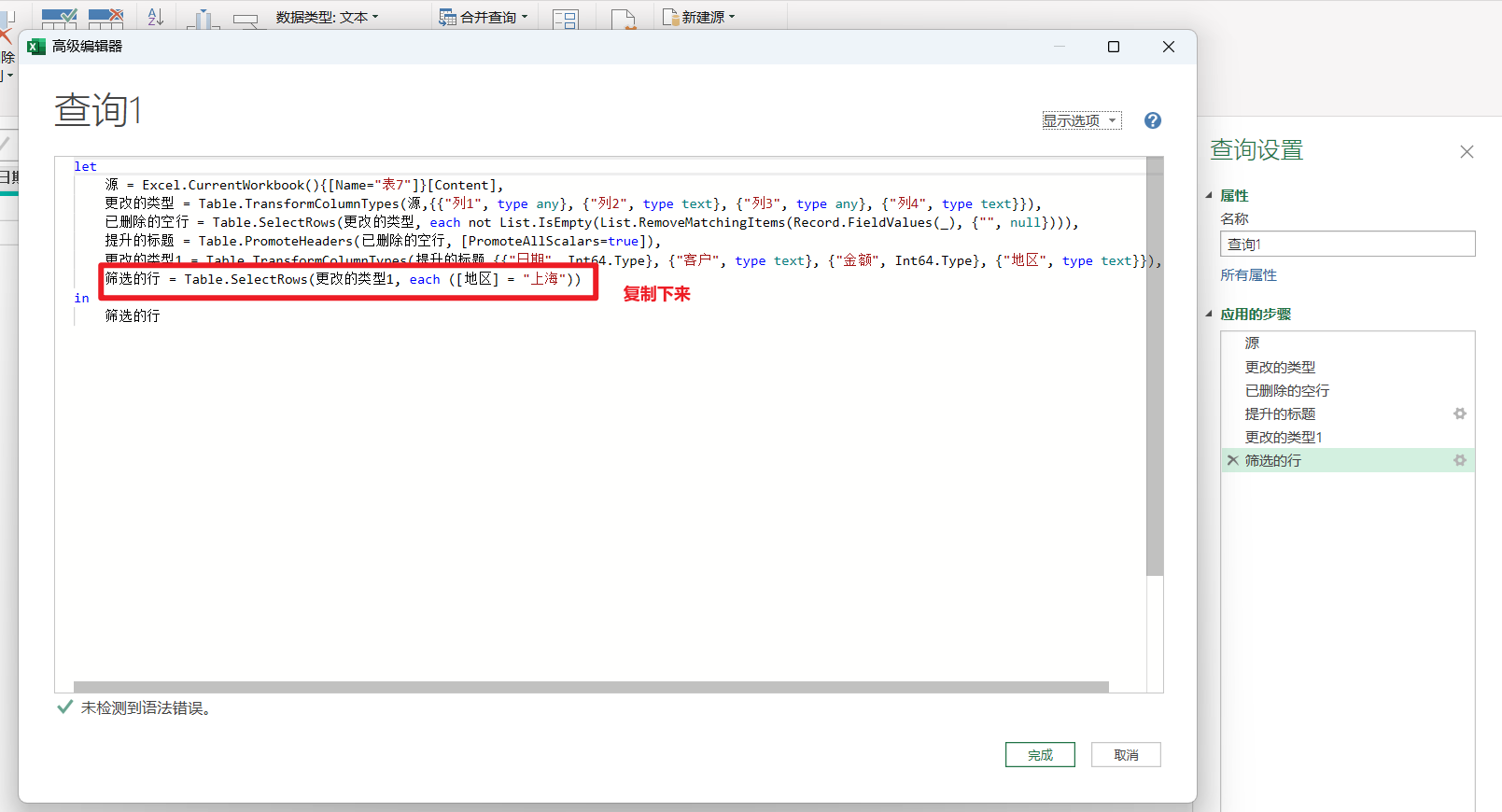
修改这一行筛选的代码,改成以下内容,然后打开查询2,打开高级编辑器,复制上去
使用参数来筛选行 = Table.SelectRows(更改的类型1, each (地区 = 地区参数))
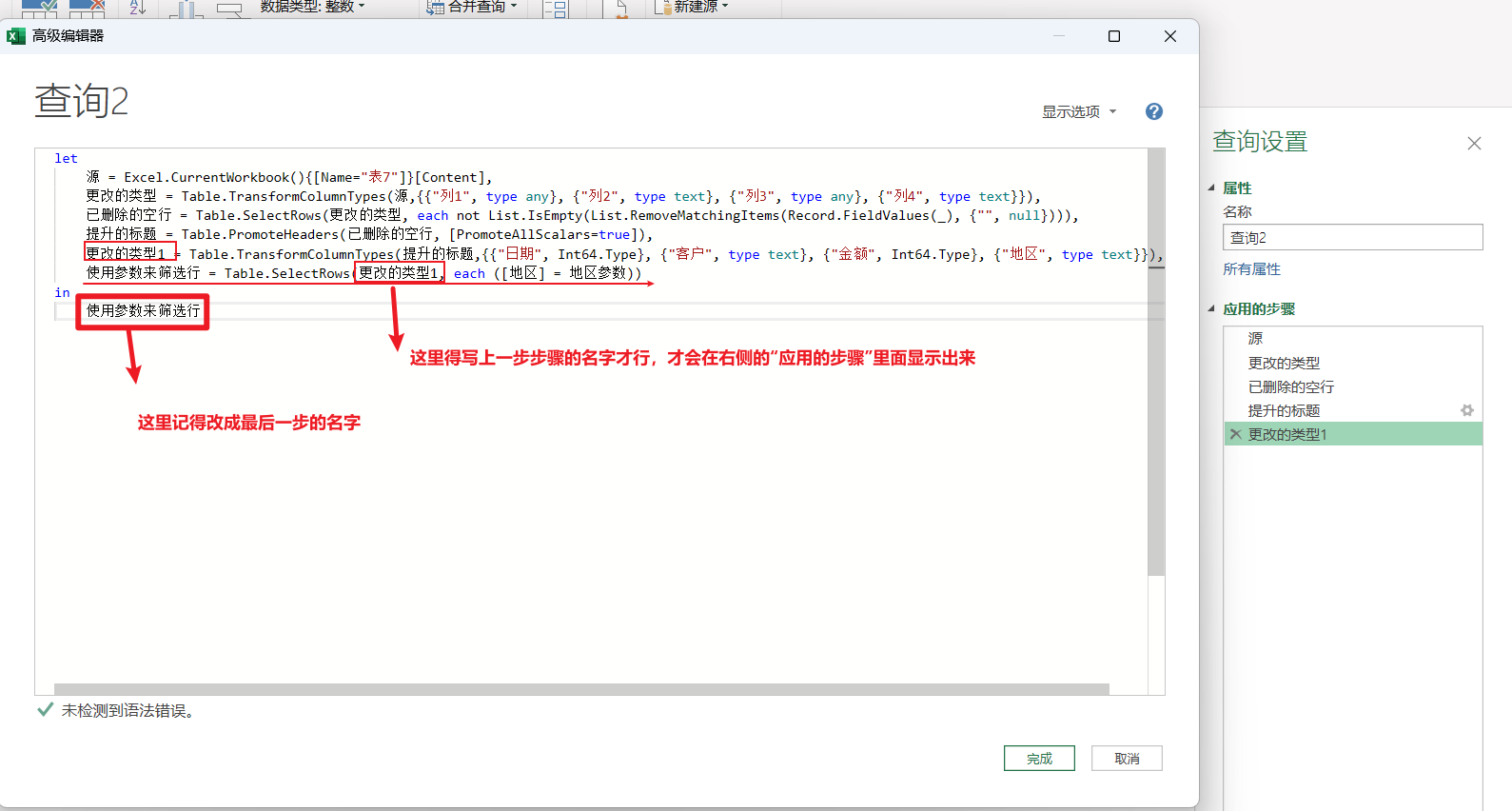
代码修改完毕,确认后结果如下
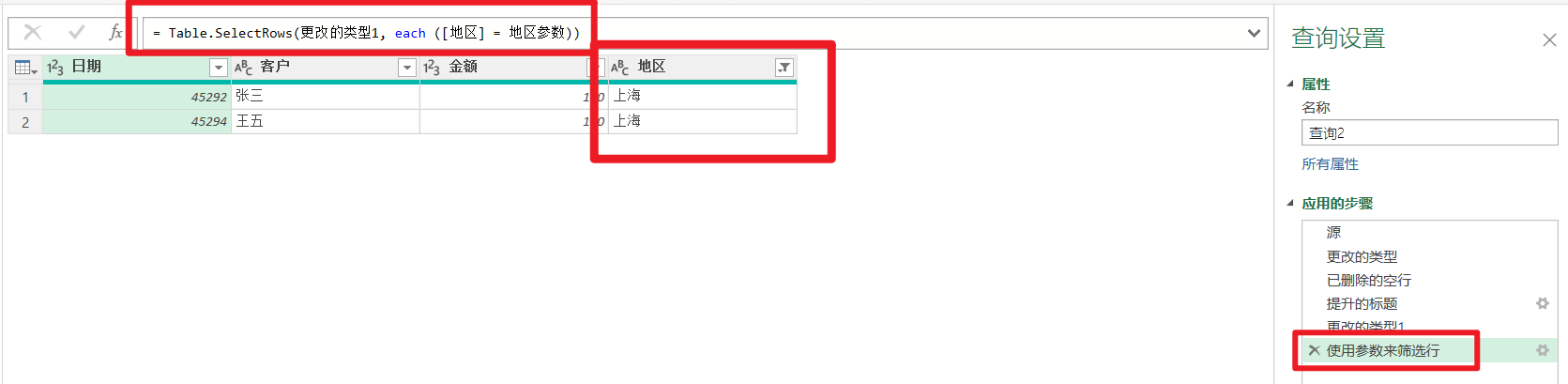
那现在我想把筛选的值换成"北京",点击左侧的参数,修改值为"北京",查询2的结果就自动修改了
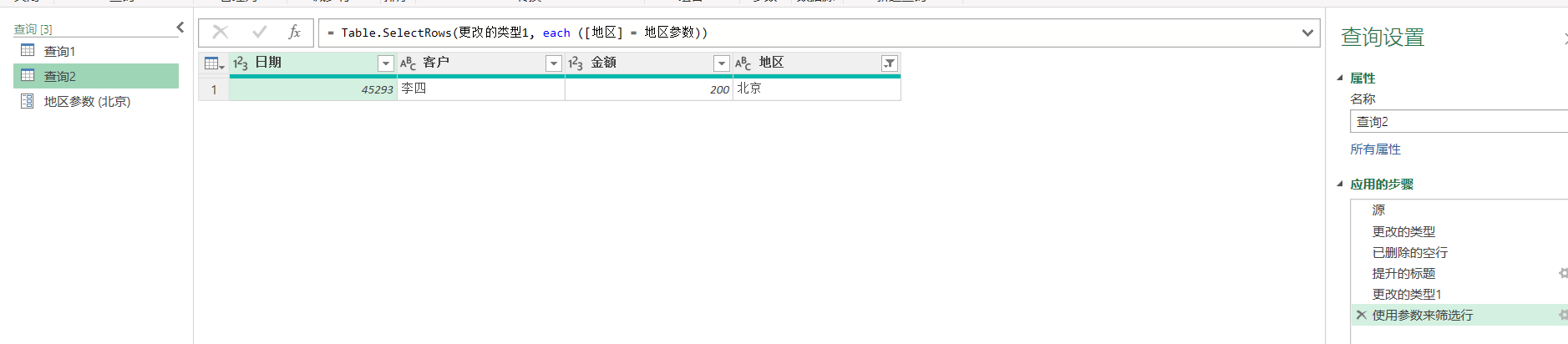
数据源(配置权限)
新建查询
就是新建一个查询,可以从外部导入,也可以自己手动输入数据,还可以创建自定义函数。
新建其他源 - 空白查询,一般用来创建函数,比如"添加列"功能区调用自定义函数时,就需要创建空白查询,输入代码来自定义一个函数。