1 单选题(每题 2 分,共 30 分)
第1题 如果字符变量 _1 的值是字符 1 ,那么 (int)_1 的值是?( )。
A. 1 B. -1 C. 49 D. +1 或者 -1
解析:答案C。字符类型变量存储的是字符对应的ASCII码值,字符1的ASCII码是49,转换为int时值为49,因此(int)_1 的值是49。故选C。
第2题 a,b是整型变量,各自有互不相同的初始值。下列程序实现了什么效果( )。
cpp
a=a^b;
b=a^b;
a=a^b;A. a,b 的值从始至终都没有改变。 B. a,b 的值实现了互换。
C. a,b 的值互换了以后,又还回去了,相当于没有变化。
D. a,b 的值最后和原值不一样,没有任何意义。
解析:答案B。知识点:异或(^)运算,某数异或同一数二次,则恢复原数。设a、m是两个不同的整形变量,则a^m^m==a成立。经第一行运算a成为原a与原b的异或结果,经第二行运算,b相当于是原a^原b^原b=原a,经第三行运算a相当于是原a^原b^原a=原b,实现了a与b的交换。故选C。
第3题 关于下列正确的程序段,说法正确的是( )。
cpp
char str1[] = "Hello";
char str2[] ={'H','e','l','l','0'};A. 字符数组 str1 和 str2 完全相同。
B.
cpp
cout<<str1<<endl;
cout<<str2<<endl;这段程序将输出不同的结果。
C. 字符数组 str1 和 str2 不相等。 D. 这两个赋值方式完全相同。
解析:答案C。str1 的定义为:char str1\[\] = "Hello";,在 C++ 中,字符串字面量 "Hello" 实际上会自动在末尾添加一个空字符 '\0',因此 str1 实际上是 {'H','e','l','l','o','\0'},共 6 个字符,str1为字符串。str2 的定义为:char str2\[\] = {'H','e','l','l','0'}; ,这里显式地定义了 5 个字符,没有自动添加 '\0'。所以 str2 是 {'H','e','l','l','0'},共 5 个字符。
选项A由于两个数组的长度不同,内容也不完全一致(str1有'\0'而str2没有),因此它们不相等,所以错误。选项B,cout << str1 << endl; 会正常打印 "Hello",而 str2 因为没有 '\0',其行为未定义,会打印到内存中出现的第一个'\0'为止,因此可能输出乱码或异常结果。但题目中未明确说明输出方式,因此不能确定是否"输出不同"。选项C正确。选项D字符串字面量赋值会自动添加 '\0',而字符数组初始化不会自动添加,所以错误。故选C。
第4题 关于以下程序段,说法正确的是( )。
cpp
int x=10;
cout<<(x++) + (++x)<<endl;A. C++11 标准中,这是未定义行为,不同的环境有可能出现不同的结果
B. 22 C. 21 D. 20
解析:答案B。知识点:后缀递增操作符(x++):表达式的值:表达式x++的值是变量x递增前的值,变量x在表达式求值之后递增1。前缀递增操作符(++x):表达式的值:表达式++x的值是变量x递增后的值,变量x在表达式求值之前递增1。+运算符是从左向右运算,(x++)的值为10,x=11,(++x)的值为12,x=12,所以(x++) + (++x)=10+12=22,所以输出结果为22。故选B。
第5题 8 位二进制下,十进制数-15 的补码是( )。
A. 11110000 B. 10001111 C. 10010000 D. 11110001
解析:答案D。知识点:二进制表示十进制,二进制最高位表示符号:0正1负,其他位表示数值。正数补码与原码相同,负数补码符号位保持不变,原码数值位按位取反后加1。-15=(10001111)₂原=(11110001)₂补,与项目D一致。故选D。
第6题 三进制数2102₍₃₎转换成十进制是:( )。
A. 63 B. 65 C. 67 D. 69
解析:答案B。2*3³+1*3²+0*3¹+2*3⁰=54+9+0+2=65,项目B正确。故选B。
第7题 二进制数 10110101 是某数的 8 位补码,该数的十进制是( )。
A. -73 B. -75 C. -77 D. 75
解析:答案D。高位为1,数据为负,0110101减1取反(或取反+1)为(1001011)₂=75,所以,该数的十进制是-75。故选D。
第8题 已知 unsigned char c = 0x0F; (十六进制 0F = 二进制 00001111 ),执行 c = c << 3; 后,c 的 十进制值是:( )。
A. 64 B. 72 C. 80 D. 120
解析:答案D。赋值从右向左运算,C++/C中<<为多位运算(左移),如数据没有溢出,则m<<n=m*2ⁿ,0x0F=15,15*2³=120,所以D正确。也可以这么思考:0x0F表示十六进制数,十六进制(0F)₁₆=(00001111)₂,左移3位结果为(01111000)₂=120。故选D。
第9题 补码的情况下,关于按位取反运算,用笔计算的情况下,以下说法错误的是:( )
A. ~5 的结果是 -6( int 类型,32 位) B. ~0 的结果是 0( int 类型,32 位)
C. ~(-3) 的结果是 2( int 类型,32 位) D. ~8 的结果是 -9( int 类型,32 位)
解析:答案B。~按位取反,即将表示数据的二进制简单地每一位取反。
选项A:~5=~(00000000 000000000 00000000 00000101)₂=(11111111 11111111 11111111 11111010)₂=-(00000000 000000000 00000000 00000110)₂=-6,正确。
选项B:~0=~(00000000 000000000 00000000 00000000)₂=(11111111 11111111 11111111 11111111)₂=-(0000000 00000000 00000000 00000001)₂=-1≠0,错误。
选项C:~(-3)=~(11111111 11111111 11111111 11111101)₂=(00000000 00000000 00000000 00000010)₂=2,正确。
选项D:~8=~(00000000 00000000 00000000 00001000)₂=(11111111 11111111 11111111 11110111)₂=-(0000000 00000000 00000000 00001001)₂=-9,正确。
故选B。
赋值从右向左运算,C++/C中<<为多位运算(左移),如数据没有溢出,则m<<n=m*2ⁿ,0x0F=15,15*2³=120,所以D正确。也可以这么思考:0x0F表示十六进制数,十六进制(0F)₁₆=(00001111)₂,左移3位结果为(01111000)₂=120。故选D。
第10题 执行以下 C++ 代码后, sub 的值是( )。
cpp
string str = "GESP2026";
string sub = str.substr(4, 2);A. 20 B. 02 C. 2026 D. 026
解析:答案A。C++的substr()为取子串方法,C++字符串中字符位置从左向右,位置编号从0开始,str.substr(m, n)表示从字符串str的m位开始取n位子串。str.substr(4, 2)="20",故选 A。
第11题 执行以下代码后,输出结果是:( )。
cpp
int arr[] = {5, 10, 15, 20, 25, 30};
int count = sizeof(arr) / sizeof(arr[0]);
cout << count;A. 4 B. 6 C. 24 D. 30
解析:答案B。第一行定义了一个整型数组,初始6个元素,在C++中,sizeof是一个编译期运算符,用于获取数据类型或对象在内存中所占的字节数,int类型占4字节,sizeof(arr) = 4 * 6 = 24,sizeof(arr0) = 4,所以count = 24 / 4 = 6。故选 B。
第12题 执行以下代码后,输出结果是:( )。
cpp
char s[10] = "abcde";
int a = sizeof(s) / sizeof(s[0]);
int b = strlen(s);
cout << a - b;A. 4 B. 5 C. 6 D. 10
解析:答案B。char类型占1字节,char数组一个下标占1字节。第一行定义一个C风格字符串,尾部会自动添加字符串结束标志'\0',所以存了6个字符,另4个下标(元素)自动初始化为ASCII码0(即'\0'),所以sizeof(s)=10,sizeof(a0) = 1,所以a = 10 / 1 = 10。strlen()函数为求字符串的实际长度,不包含尾部的'\0',所以b= strlen(s)=5,a-b=10-5=5。故选 B。
第13题 以下问题中,最不适合用枚举法解决的是:( )
A. 找出 1~100 之间所有能被 7 整除的数
B. 找出 100~200 之间的所有质数
C. 计算 1+2+3+...+1000 的和
D. 找出三位数中个位、十位、百位数字之和等于 10 的数
解析:答案C。枚举法是指从可能的集合中一一枚举各个元素,用题目给定的约束条件判定哪些是无用的,哪些是有用的。能使命题成立者,即为问题的解。特征是①枚举每一个可能元素,②计算约束条件是否使命题成立。
对选项A,枚举从1到100的数,计算这个数能否被7整除?如能被7整除,则找到此数,输出该数,继续找直到数超范围,符合枚举法特征,适合枚举法。
对选项B,枚举从100到200的数,计算这个数是否是质数?如是质数,则找到质数,输出该质数,继续找质数直到数超范围,符合枚举法特征,适合枚举法。
对选项C,枚举从1到1000的数,计算这个数与前数和的和,无判断,继续枚举直到数超范围,有点像枚举法,但不完全符合枚举法特征,不适合枚举法。
对选项D,枚举所有三位数,从100到999,计算这个数的个位、十位、百位数字之和,判断是否等于10?如等于10,则输出该数,继续找直到数超范围,符合枚举法特征,适合枚举法。
所以选项C最不适合用枚举法解决问题。故选 C。
第14题 用枚举法解决"鸡兔同笼问题:头共 35 个,脚共 94 只,求鸡和兔的数量",以下枚举逻辑最合理的是:( )
A. 枚举鸡的数量 x (0~35),兔的数量 y=35-x ,判断 2*x + 4*y == 94
B. 枚举兔的数量 y (0~94),鸡的数量 x=35-y ,判断 2*x + 4*y == 94
C. 枚举所有整数 x (0-100)和 y (0-100),判断 x+y==35 && 2*x+4*y==94
D. 枚举脚的总数 sum (0~94),判断 sum == 94
解析:答案A。分析:鸡、兔都只有1个,所以鸡数+兔数=头数,设鸡数x,兔数为y,则如枚举x(0~35),则兔数=头数-鸡数,即y=35-x。鸡只有2只脚,兔有4只脚,如2*x+4*y=94(脚数),就找到其中的一个问题解(可能有多个答案)。
所以选项A正确。
选项B,枚举兔数y,但y的范围也是0~35,而不是脚数0~94,所以错误。
选项C,x、y都超范围枚举,但也能得到结果,不是最佳方法,所以不太正确。
选项D,枚举脚数,判断脚数sum == 94,无法获得鸡数和兔数,所以错误。
故选 A。
第15题 模拟"字符串加密":规则为"每个字符 ASCII 码 + 3,若超过 z (122) 则从 a 重新开始",以下代码中正确的条件判断是:( )
cpp
for (int i = 0; i < str.length(); i++) {
// 需补充条件:
_______________________
else {
str[i] += 3;
}
}A. if (stri> 122) stri = stri + 3 - 26;
B. if (stri > 122) stri = stri - 26;
C. if (stri + 3 > 122) stri = stri - 23;
D. if (stri + 3 > 'z') stri = 'a' + (stri + 3 - 'z') - 1;
解析:答案D。这里假设字符串中为小写字母,知识点:'a'=97,'z'=122。'a' + 3 - 'z' - 1=-23,'a' + (stri + 3 - 'z') - 1与stri - 23等价,122与'z'等价。
选项A用原字符串元素stri去判>122,stri + 3至少等于125不会减26,所以错误。
选项B,用原字符串元素stri去判>122,不符合"每个字符 ASCII 码 + 3,若超过 z (122) 则从 a 重新开始",所以错误。
选项C,if (stri + 3 > 122) stri = stri - 23; 符合题目要求,答案也正确,但这里直接减23并不能直观反映题目要求的加密规则,所以不太直观、规范。
选项D,if (stri + 3 > 'z') stri = 'a' + (stri + 3 - 'z') - 1; 正确且字符比较的方式,更加直观和准确地实现了题目要求的加密规则,所以正确。
故选 D。
2 判断题(每题 2 分,共 20 分)
第1题 定义 int arr5 = {1,2,3}; ,则 arr3 的值为 0,arr5 是合法下标。
解析:答案错误(╳)。在 C++ 中,用int arr5 = {1,2,3}; 初始化数组,未初始化的为0,所以arr3 的值为 0正确。但arr5表示有5个下标(元素),下标编号为0、1、2、3、4,arr5已越界,是不合法下标。故错误。
第2题 定义 double arr10; ,未手动初始化时,数组中所有元素的默认值为 0.0。
解析:答案错误(╳)。在 C++ 中,未初始化的数组元素默认值取决于数组存储的位置。对于在栈区声明的 double arr10;,其元素值是未定义的(即随机垃圾值)。而全局或静态数组的元素默认值才是 0.0。故错误。
第3题 定义 int arr\[\] = {1,2,3}; ,则 sizeof(arr) 的结果为 12( int 占 4 字节)。
解析:答案正确(√)。C++中int arr\[\] = {1,2,3}定义了三个整型元素的数组,sizeof(arr)为arr占用内存字节数,即4*3=12,故正确。
第4题 下面的流程图是用来求 1+2+3+...+10 的和。请判断:这个流程图的逻辑正确还是错误?
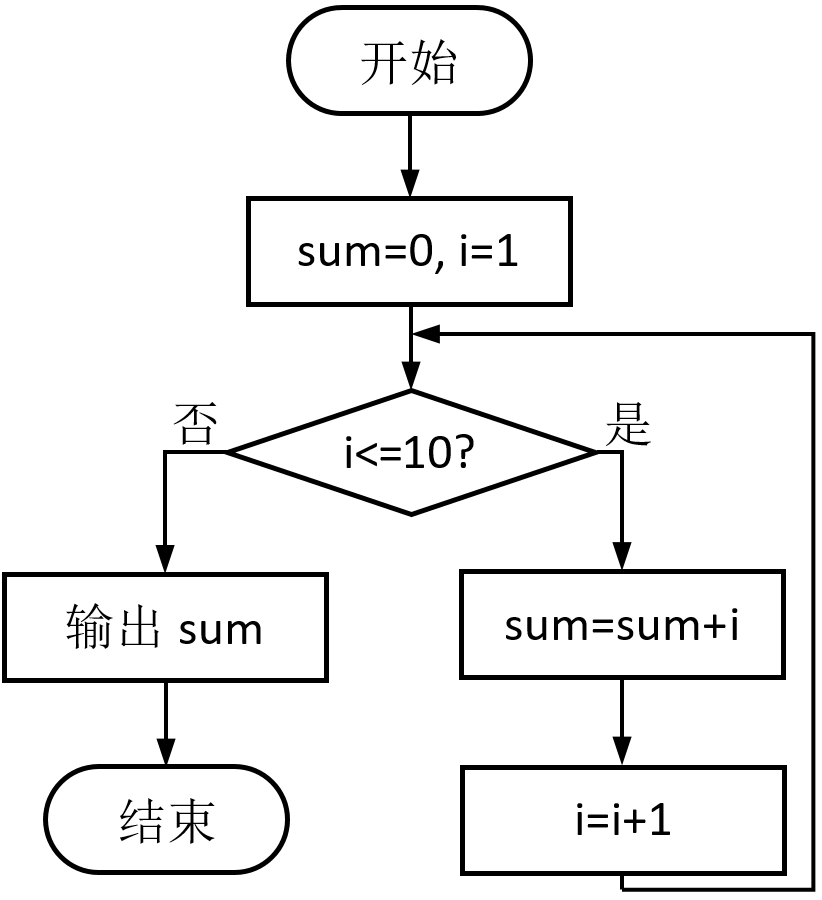
解析:答案正确(√)。Sum初始值为0,i从1开始,条件框中条件i<=10,条件成立sum加i,i每次加1,这样10次循环,sum从0开始,分别加1、2、...、9、10,所以流程图是用来求 1+2+3+...+10 的和,这个流程图的逻辑正确,故正确。
第5题 下面流程图的功能是计算 5 对 2 取余数,输出结果为 1。
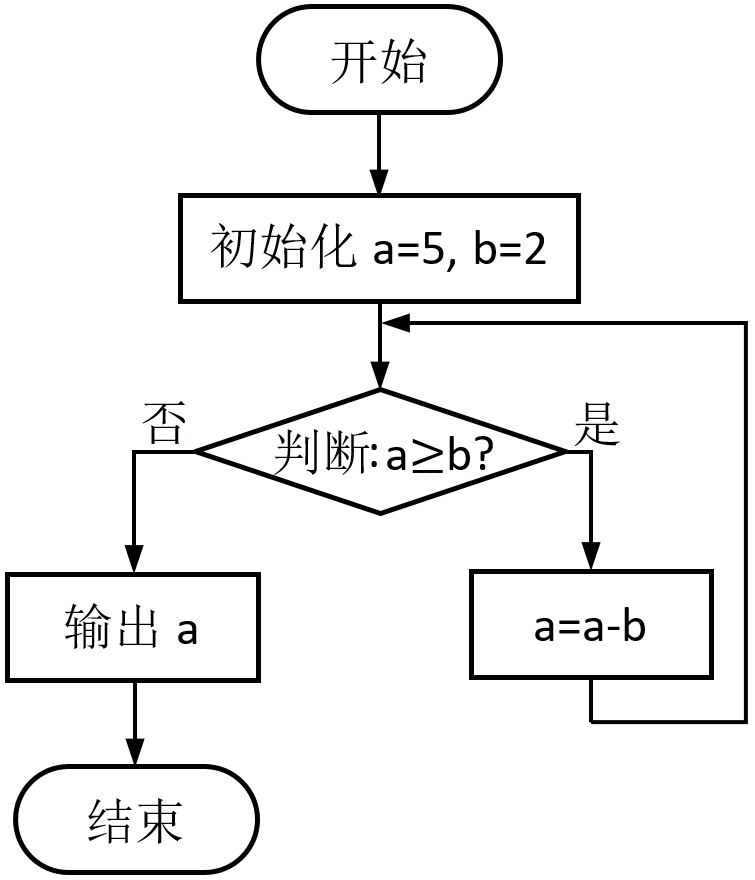
解析:答案正确(√)。A被减去多个b,直到小于a,其实就是计算a对b的余数。
a=5, b=2;第一轮a≥b即5≥2成立,a=a-b=5-2=3;第二轮a≥b即3≥2成立,a=a-b=3-2=1;第三轮a≥b即1≥2不成立,输出a即1。故正确。
第6题 已知大写字符 A 的ASCII编码的十六进制表示为 0x41 ,计算字符 m 的ASCII编码的八进制表示为 155(八进制)。
解析:答案正确(√)。大写字符A的ASCII编码的十六进制表示为0x41,则大写字符a的ASCII编码的十六进制表示为 0x61(相差32即0x20),a(第1)与m(第13)差12(0xC)个字母,所以字符m的ASCII编码的十六进制表示为0x61+0xC=0x6D=0b 0110 1101(4位一组)=0b 01 101 101(3位一级)=0o155。所以字符m的ASCII编码的八进制表示为155,故正确。
第7题 在 C++ 位运算中,各种不同的运算符有优先级的区分,使用括号能够解决优先级的问题。
解析:答案正确(√)。在 C++ 中,位运算符和其他运算符一样,具有明确的优先级 和结合性 。当表达式中包含多个不同优先级的运算符时,编译器会根据优先级规则来确定运算顺序。如果希望改变这种默认的运算顺序,可以使用圆括号 来明确指定优先计算的部分。故正确。
第8题 由于在 0~255 范围内, char 类型和 int 类型可以互换,因此在这里 x 和 y 相等。
cpp
char x='1';
int y=1;解析:答案错误(╳)。在 C++ 中,char为字符型,存储的是字符的ASCII码,int为整型,存储的是数字本身(正数高位为0,负数高位来1,数值用补码表示),所以char x='1'; x的值为49,int y=1; y的值为1,所以x和y不相等。故错误。
第9题 在C++语言中,表达式 ((0xf0 + 0x15) == 255) 的值为 true 。
解析:答案错误(╳)。在 C++ 中,(0xf0 + 0x15)=0x105d≠0xff(255),所以表达式 ((0xf0 + 0x15) == 255) 的值为false。故错误。
第10题 如果 a 为 int 类型的变量,且 a 的二进制最低位为 0 ,则表达式 ((a & 3 & 1) == 0) 的值为 true 。
解析:答案正确(√)。C++中&为按位与,任何二进制位与0为0,与1为原值(此位为0则为0,此位为1则为1)。设a的二进制形式为xxx...xxxx0,其中的x表示不定 二进制位(0或1),...表示省略其中的位(C++ int 类型变量共32位二进制),则:
a: xxx...xxxx0
a & 3: xxx...xxxx0 & 00...00011=000...000x0
((a & 3 & 1):000...000x0 & 000...00001=000...00000=0
所以题目表述成立。故正确。
3 编程题(每题 25 分,共 50 分)
3.1 编程题1
- 试题名称:二进制回文串
- 时间限制:1.0 s
- 内存限制:512.0 MB
3.1.1题目描述
对于一个正整数𝑛,我们将其转换为不含前导零的二进制表示,如果这个二进制序列从左向右读与从右向左读完全相同,则称该数为二进制回文数。例如,9的二进制表示为(1001)₂,是二进制回文数;12的二进制表示为(1100)₂,不是二进制回文数。
你的任务是:给定一个正整数𝑛,计算在1到𝑛的范围内二进制回文数的数量。
3.1.2 输入格式
输入一行,包含一个正整数𝑛。
3.1.3 输出格式
输出一行,包含一个数,表示在1到𝑛的范围内二进制回文数的数量。
3.1.4 样例
3.1.4.1 输入样例
cpp
153.1.4.2 输出样例
cpp
63.1.5 样例解释
样例1中,1到𝑛范围内1、3、5、7 、9、15是二进制回文数。
3.1.6 数据范围
1≤𝑛≤10⁵。
3.1.7 编写程序
解析:本题解决二个问题:一是十进制转二进制问题,二是二进制回文检测问题。
思路:问题一:用除2取余法转二进制,每位余数存入数组,商继续用除2取余法,直到商为0。因为2¹⁶=65536,2¹⁷=131072>10⁵,所以10⁵的十进制数,二进制不超过17位,数组的长度(元素个数 )为17,留点余量可定义为20。
问题二:设转换后的二进制长度为j位,不论j是奇数还是偶数,都只需判j/2位就可以确定是否是回文。
当j是奇数时,以j=9为例,j/2=4:
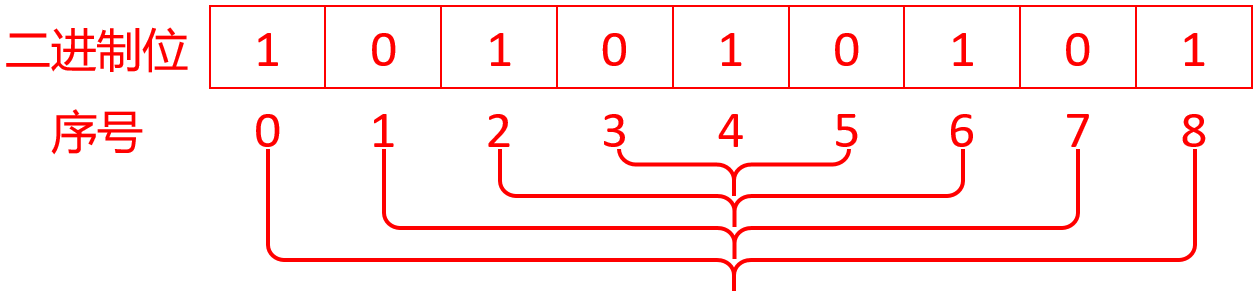
只需判断4对数是否相等,如有一对数不相等就不是回文,否则全部相等就是回文。中间一位只是一位,不管是0还是1都不影响对回文的判断。
当j是时数时,以j=10为例,j/2=5:
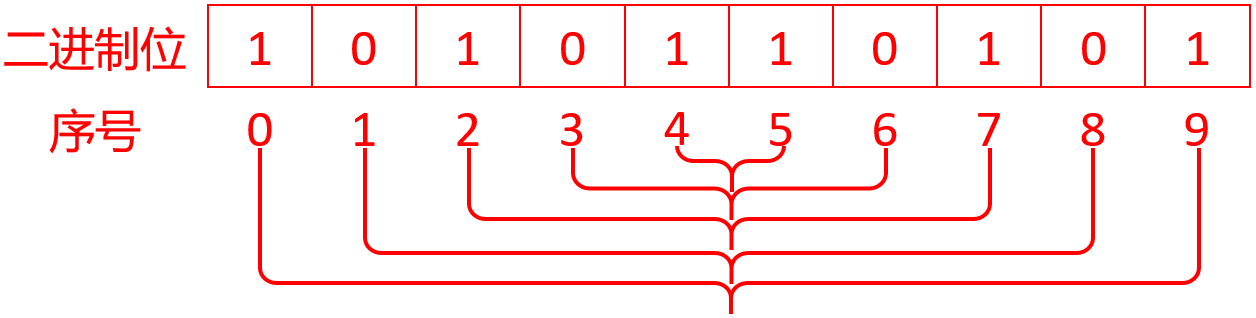
只需判断5对数是否相等,全部相等就是回文,否则如有一对数不相等就不是回文。
根据二个问题的解决方案编写的参考代码如下:
cpp
#include <iostream>
using namespace std;
int main() {
int n, bin[20] = {0}, cnt = 0; // 1≤n≤10⁵, bin存二进制位,cnt计数值
cin >> n; // 10⁵化为二进制最多17位,加点余量
for (int i = 1; i <= n; i++) { // 枚举1~n
int tmp = i, j = 0, k; // 将tmp(即i)转换为二进制(存入字符数组)
while (tmp) {
bin[j++] = tmp % 2; // j累计二进制位数,tmp % 2为除2取余法
tmp /= 2; // 余数存入数组bin,商继续运算直到为0
}
for (k = 0; k < j / 2; k++)
if (bin[k] != bin[j - k - 1]) // bin[j-k-1]从右向左读
break; // 从左向右读与从右向左读不相等,则不是回文
if (k == j / 2) cnt++; // 如没有中途跳出而正常结束循环,则是回文,+1
}
cout << cnt << endl;
return 0;
}3.2 编程题2
- 试题名称:凯撒密码
- 时间限制:1.0 s
- 内存限制:512.0 MB
3.2.1题目描述
凯撒密码是一种替换加密技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是3的时候,所有的字母𝐴将被替换成𝐷,𝐵被替换成𝐸,𝐶被替换成𝐹,以此类推,𝑊被替换成𝑍,𝑋被替换成𝐴,𝑌被替换成𝐵,𝑍被替换成𝐶。这个加密方法是以罗马共和时期凯撒的名字命名的,据称当年凯撒曾用此方法与其将军们进行联系。
但是和所有的利用字母表进行替换的加密技术一样,凯撒密码非常容易被破解,而且在实际应用中也无法保证通信安全。
现在给你一个已破解的凯撒密码明文与密文,与一个有相同偏移量的未破解凯撒密码密文,请你帮忙破解它。
3.2.2 输入格式
输入共三行:
第一行包含一个字符串,表示已破解的凯撒密码明文;
第二行包含一个字符串,表示已破解的凯撒密码密文;
第三行包含一个字符串,表示待破解的凯撒密码密文。
3.2.3 输出格式
输出一行,包含一个字符串,表示待破解的凯撒密码对应的明文。
3.2.4 样例
3.2.4.1 输入样例
cpp
ABCDEFGVWXYZ
DEFGHIJYZABC
WKHTXLFNEURZQIRAMXPSVRYHUWKHODCBGRJ3.2.4.2 输出样例
cpp
THEQUICKBROWNFOXJUMPSOVERTHELAZYDOG3.2.5 样例解释
样例 1 中,通过已破解的密码得出偏移量为 'D' - 'A' = 3 ,因此,对未破解部分进行逆向偏移:密文中的 W 对 应明文中的 T ( 'W' - 3 = 'T' ),密文中的 K 对应明文中的 H ( 'K' - 3 = 'H' ),以此类推。
3.2.6 数据范围
保证密码长度均不超过1000,所有字符串由大写字母组成。
3.2.7 编写程序
解析:本题是一个已知明文和密文破解新密文的题目,需要先破解密钥,然后用密钥破解密文。
思路:对凯撒密码密钥key为常数,只需计算密文与明文对应位置上字母间的距离(ASCII码之差),负数也不影响结果,key=3和key=-23等价。
设pt为明文字符串,ct为密文字符串,则key=ct0-pt0。
设ut为待解密文,解密为(uti-'A'-key+26)%26+'A'。
加+26的目的是防止uti-'A'-key为负数,+26不影响%26的结果(同余)。
方法一:
按此思路用C风格字符串编写的参考代码如下:
cpp
#include <iostream>
#include <cstring>
using namespace std;
char pt[1005], ct[1005], ut[1005]; // 密文长度均不超过1000, 1005留点余量
int main() {
cin >> pt >> ct >> ut; // 输入明文、对应密文和待破解密文
int n = strlen(ut); // C风格字符串求字符串长度函数
int key = ct[0] - pt[0]; // key正负不影响解密,故不调整
for (int i = 0; i < n; i++)
cout << (char)((ut[i] - 'A' - key + 26) % 26 + 'A'); // 结果为数值强制转换
return 0;
}方法二:
按此思路用C++字符串编写。对C++字符串string类型,32位系统 :通常为2³²-1(约4GB);64位系统:可能为2⁶⁴-1(理论值极大,但实际受内存限制),故存储1000字符没有问题。
参考代码如下:
cpp
#include <iostream>
using namespace std;
string pt, ct, ut; // C++字符串超长,一般不小于2³²-1个字符
int main() {
cin >> pt >> ct >> ut; // 输入明文、对应密文和待破解密文
int key = ct[0] - pt[0]; // key正负不影响解密,故不调整
for (int i = 0; i < ut.length(); i++) // length()为C++测字符串长度方法
cout << (char)((ut[i] - 'A' - key + 26) % 26 + 'A'); // 结果为数值强制转换
return 0;
}