一、集成学习
1、集成学习思想
1.1 集成学习是什么?
通过多个模型的组合形成一个精度更高的模型,参与组合的模型称为弱学习器(弱学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。
1.2 集成学习的分类
bagging(自助聚合): 使用并行式的集成学习方法。它通过对原始数据集进行有放回的随机采样(Bootstrap采样),生成多个不同的训练子集,并在每个子集上独立训练一个基学习器(通常是决策树)。在预测阶段,对于分类任务采用"投票法"决定最终类别,对于回归任务则取所有预测结果的平均值。
bootsting(提升法): 一种串行式的集成学习方法。它将多个弱学习器按顺序进行训练,每一个新的学习器都会尝试修正前一个模型产生的错误。其机制通常是通过调整样本权重(让被错误分类的样本在下一轮得到更多关注)或拟合残差来实现。最终的预测结果是所有弱学习器的加权组合
Stacking(堆叠法): 一种分阶段的异构集成方法,属于元学习(Meta-Learning)的范畴。它分为两个阶段:第一阶段使用多种不同类型的基学习器对数据进行训练并得出各自的预测结果;第二阶段将这些预测结果作为新的特征输入,训练一个全新的"元学习器"(如逻辑回归),由该元学习器来输出最终的预测结果2。
Voting(投票法): 常用于异质模型的联合决策。它主要分为两种形式:
- 硬投票(Hard Voting):直接统计各个基模型预测类别的频次,采用"少数服从多数"的原则,选择得票最多的类别作为最终结果。
- 软投票(Soft Voting):利用各模型输出的概率分布进行加权平均,再取最大概率对应的类别作为最终结果(要求基模型支持输出概率接口)6。
1.3 理解bagging集成的思想
1.3.1 代表算法:
随机森林(具体内容见下方)
1.3.2 组合的形成模型,怎样进行训练?如何预测?
弱学习器 并行训练
采样不同的数据集-> 训练分类器 -> 平权投票
① 有放回的抽样(bootstrap抽样)出不同的训练集,使用各自抽样的训练集 训练学习器
② 结果预测:每个弱学习器得到各自的结果,通过平权投票、多数表决的方式决定最终结果
1.4 理解bootsting集成的思想
1.4.1 代表算法:
Adaboost、GBDT、XGBoost、LightGBM
1.4.2 组合的形成模型,怎样进行训练,怎样进行预测?
串行的训练方式
预测步骤:
① 第一个弱学习器使用全部数据进行训练
② 之后的训练器重点关注前一个训练器预测结果与真实值不同的数据进行训练
③ 通过加权投票的方式,得出预测结果。
权重由各个弱学习器的准确率确定,预测结果正确的数据占比越高,对应投票时权重越大
1.4.3 问题:
① 如何关注导前一个训练集的不足?
前一个的预测结果与真实值进行对比,选出与真实值结果不同的数据,就是前一个训练集的不足。之后使用前一个训练集的不足,对之后的弱学习进行训练。
② 如何正对不足进行训练
前一个的预测结果与真实值进行对比,选出与真实值结果不同的数据,用于之后的弱学习器训练
③ 加权投票时,权重是如何选择的?
根据预测准确率,准确率高的弱学习器给与更高的权重。
2、随机森林法则
随机森林是基于 Bagging 思想实现的一种集成学习算法,通过构建多棵CART决策树并汇总它们的预测结果来得出最终答案,被广泛应用于分类和回归任务中。
问题:
① 为什么要随机抽样训练集?
答:如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样
② 为什么要随机选特征?
答:决策树在选取特征时,一般都会优先选择影响最强的"强势特征"(例如预测信用卡违约时的"历史逾期次数"),如果不做限制,所有树都会反复使用这几个强特征进行分裂,导致整片森林中的树结构高度相似、同质化严重。通过每次只随机抽取一小部分特征作为候选,迫使不同的树去探索其他特征的组合价值,从而极大降低了树与树之间的相关性。
分类任务默认选取总特征数的平方根(max_features="sqrt"),回归任务默认取 log₂p 或 M/3
③ 为什么要进行有放回的采样?
答:弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果。如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
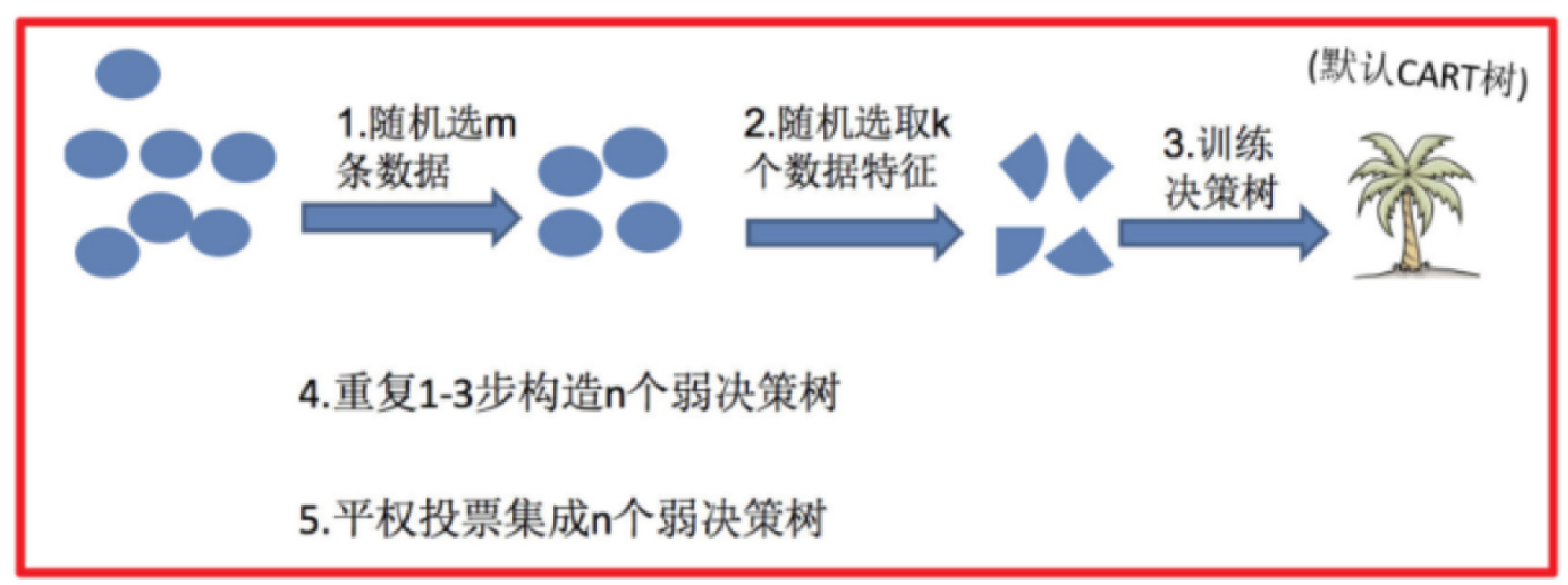
2.1 【理解】随机森林的构建方法
训练:
有放回的随机选择n个训练样本
随机挑选 n 个特征(n 小于总特征数量)
**预测:**每棵树预测结果取 "平权投票"。
分类任务:采用"多数投票制"。例如 100 棵树里有 70 棵判定为某一类别,则最终结果即为该类别
回归任务:采用"取平均值"。将所有树的预测数值相加后求平均,得到最终的预测值
2.2 随机森林的API

2.3 使用随机森林完成分类任务
随机森林实现------泰坦尼克号案例
python
import pandas as pd
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.tree import DecisionTreeClassifier,plot_tree
from sklearn.metrics import accuracy_score,classification_report
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("TkAgg")
# 数据处理
# 1、读取
titanic_df = pd.read_csv(r'./train.csv')
x = titanic_df[["Pclass","Sex","Age"]]
y = titanic_df["Survived"]
# 将Age为空的替换为Age的平均数
x['Age'] = x['Age'].fillna(x["Age"].mean())
# print(x)
# 将pclass类别转换为one-hot编码
x = pd.get_dummies(x)
# print(x.values)
# print(x.head())
# print(x.info())
# 特征化处理
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 模型训练
# 1、超级个体
estimator_tree = DecisionTreeClassifier()
estimator_tree.fit(x_train, y_train)
# 模型评估
# y_pred_tree = estimator_tree.predict(x_test)
# result_tree = accuracy_score(y_true=y_test,y_pred=y_pred_tree)
# print("cart评估结果:", result_tree)
# 输出评估报告
# evaluation_report = classification_report(y_true=y_test,y_pred=y_pred,target_names=['died', 'survived'])
# print("evaluation report:\n",evaluation_report)
# 交叉验证、网格搜索------获取最优超参数
estimator = RandomForestClassifier(n_estimators=50, max_depth=5, random_state=22)
estimator_cv = GridSearchCV(
estimator=estimator,
param_grid={"n_estimators": [30, 40, 50, 60], "max_depth": [3, 4, 5, 6], "random_state": [22]},
cv=3
)
estimator_cv.fit(x_train,y_train)
best_depth = estimator_cv.best_params_["max_depth"]
best_n_estimators = estimator_cv.best_params_["n_estimators"]
# 2、随机森林
estimator_rf = RandomForestClassifier(n_estimators=best_n_estimators, max_depth=best_depth, random_state=22)
estimator_rf.fit(x_train, y_train)
y_pred_rf = estimator_rf.predict(x_test)
result_rf = accuracy_score(y_true=y_test, y_pred=y_pred_rf)
print("随机森林:", result_rf)
# 输出:
# 随机森林: 0.7597765363128491二、聚类分析------无监督学习
1、聚类算法简介
1.1 【知道】什么是聚类
根据样本之间的相似性,将样本划分到不同的类别中;不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
**目的:**在没有先验知识的情况下,算法自动发现数据集中的内在结构和模式
1.2 了解聚类算法的应用场景
在没有先验知识,业务刚开始的时候情况下使用。算法自动发现数据集中的内在结构和模式,然后进行分类。
1.3 聚类算法的不同实现方法
K-means:按照质心分类,主要介绍K-means,通用、普遍
层次聚类:对数据进行逐层划分,直到达到聚类的类别个数
DBSCAN聚类:是一种基于密度的聚类算法
谱聚类:是一种基于图论的聚类算法
2、聚类算法API的使用
sklearn.cluster.KMeans(n_clusters=8)
参数:
n_clusters:聚类的个数,聚为几类
整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
方法:
estimator.fit(x)
estimator.predict(x)
estimator.fit_predict(x)
计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
python
import os
# 限制 OpenMP(开放多处理)并行程序在执行时使用的线程数量为 4
os.environ["OMP_NUM_THREADS"] = "4"
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import matplotlib
from sklearn.metrics import calinski_harabasz_score
# 新版本pycharm需要指定 matplotlib 使用 TkAgg 作为图形后端来渲染和显示图
matplotlib.use("TkAgg")
# 创建数据集,1000个样本、每个样本2个特征,4个质点簇,数据标准差[0.4, 0.2, 0.1, 0.2]
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[0, 0], [1, 1], [2, 2], [3, 3]],
cluster_std=[0.4, 0.2, 0.1, 0.2],
random_state=22)
# print(x)
plt.scatter(x[:, 0], x[:, 1])
plt.show()
# 模型训练
estimator = KMeans(n_clusters=4)
y_pred = estimator.fit_predict(x)
plt.scatter(x[:, 0], x[:, 1],c=y_pred)
plt.show()
# 模型评估
score = calinski_harabasz_score(x,y_pred)
print(score)
# 输出:6420.8745112842313、Kmeans实现流程
① 确定k值(通过n_clusters确定),常数k意味着聚为几个类
② 随机选择k个样本点作为初始的聚类中心
③ 计算每个样本到k个聚类中心的距离,离那个聚类中心最近,其就属于那个类
④ 根据每个类别中的样本点,重新计算出新的聚类中心点(平均值),如果计算得出的新中心点与原中心点一样则停止聚类,否则重新进行第 3 步过程,直到聚类中心不再变化
4、模型评估方法
4.1 SSE 聚类评估指标(The sum of squares due to error)
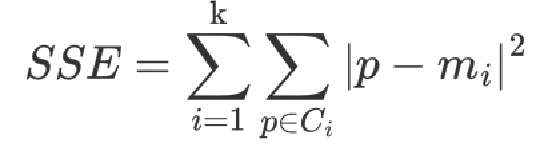
参数:
Ci 表示簇
k 表示聚类中心的个数
p 表示某个簇内的样本
m 表示质心点
SSE 越小,表示数据点越接近它们的中心,聚类效果越好
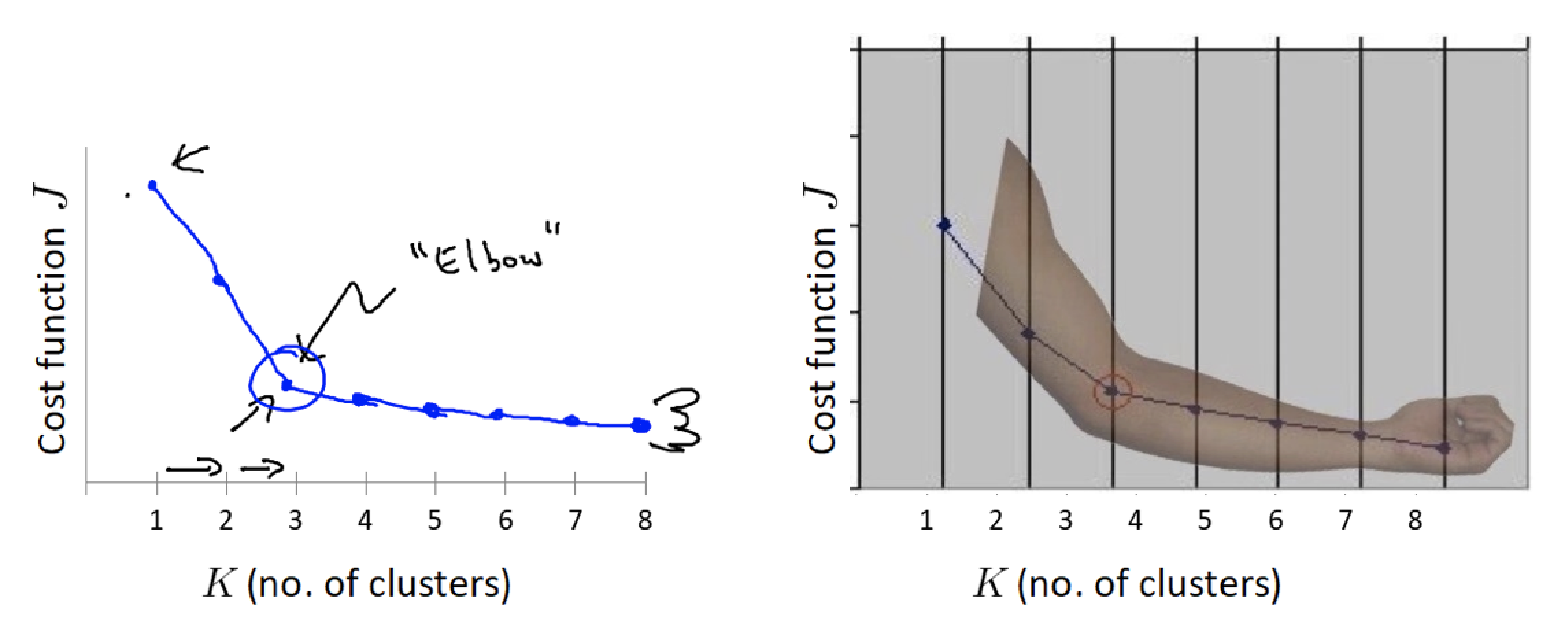
4.2 肘方法
**作用:**肘" 方法通过 SSE 确定 n_clusters 的值
实现步骤:
对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
4.3 代码示例
python
import os
# 限制 OpenMP(开放多处理)并行程序在执行时使用的线程数量为 4
os.environ["OMP_NUM_THREADS"] = "4"
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import matplotlib
from sklearn.metrics import calinski_harabasz_score
# 新版本pycharm需要指定 matplotlib 使用 TkAgg 作为图形后端来渲染和显示图
matplotlib.use("TkAgg")
# 添加支持中文
plt.rcParams['font.sans-serif'] = ['SimHei','Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 创建数据集,1000个样本、每个样本2个特征,4个质点簇,数据标准差[0.4, 0.2, 0.1, 0.2]
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[0, 0], [1, 1], [2, 2], [3, 3]],
cluster_std=[0.4, 0.2, 0.1, 0.2],
random_state=22)
# k值
sse_list = []
for i in range(1, 50):
estimator = KMeans(n_clusters=i, max_iter=100, random_state=22)
estimator.fit_predict(x)
sse_list.append(estimator.inertia_) # 获取sse的值
plt.title("SSE")
plt.plot(range(1, 50), sse_list,'o-')
plt.grid()
plt.xlabel("聚类个数")
plt.ylabel("sse")
plt.show()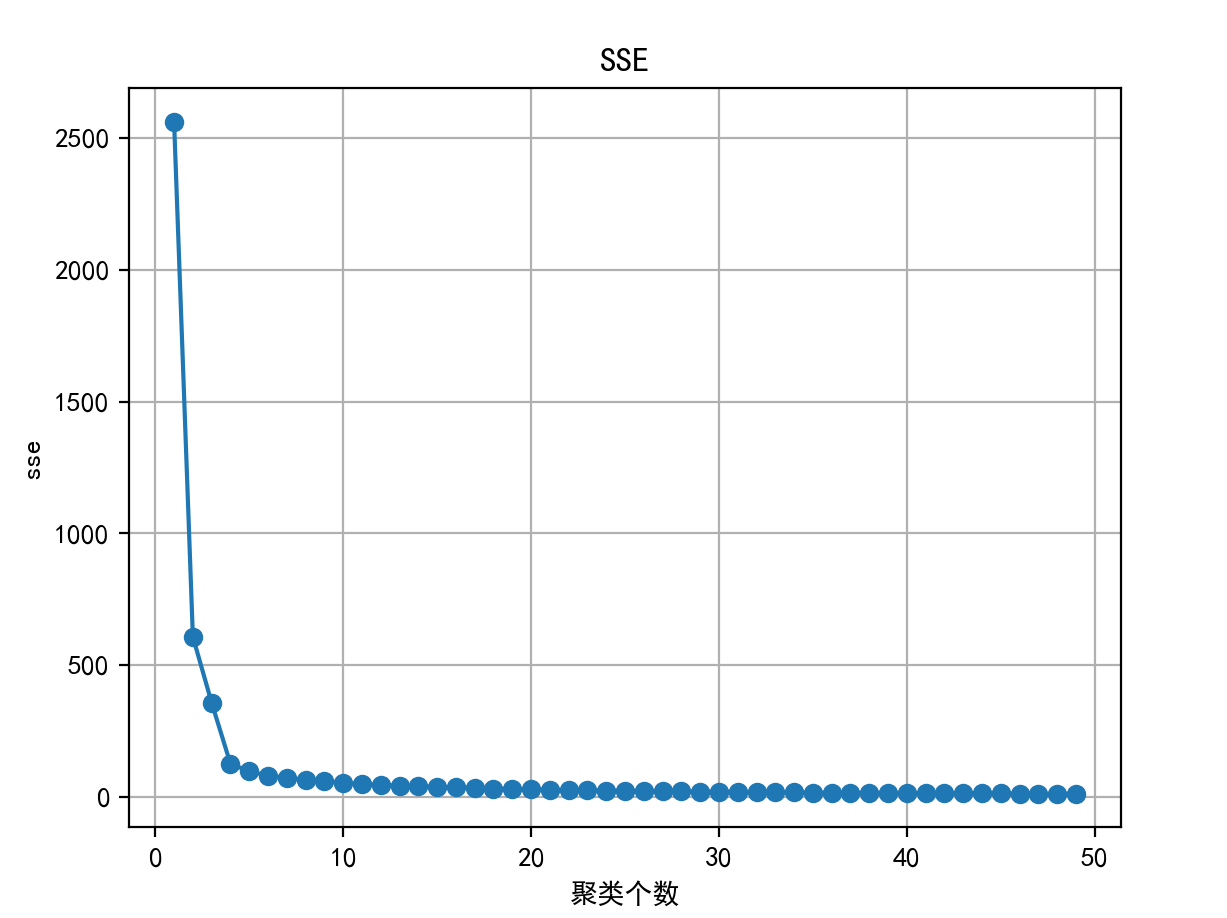
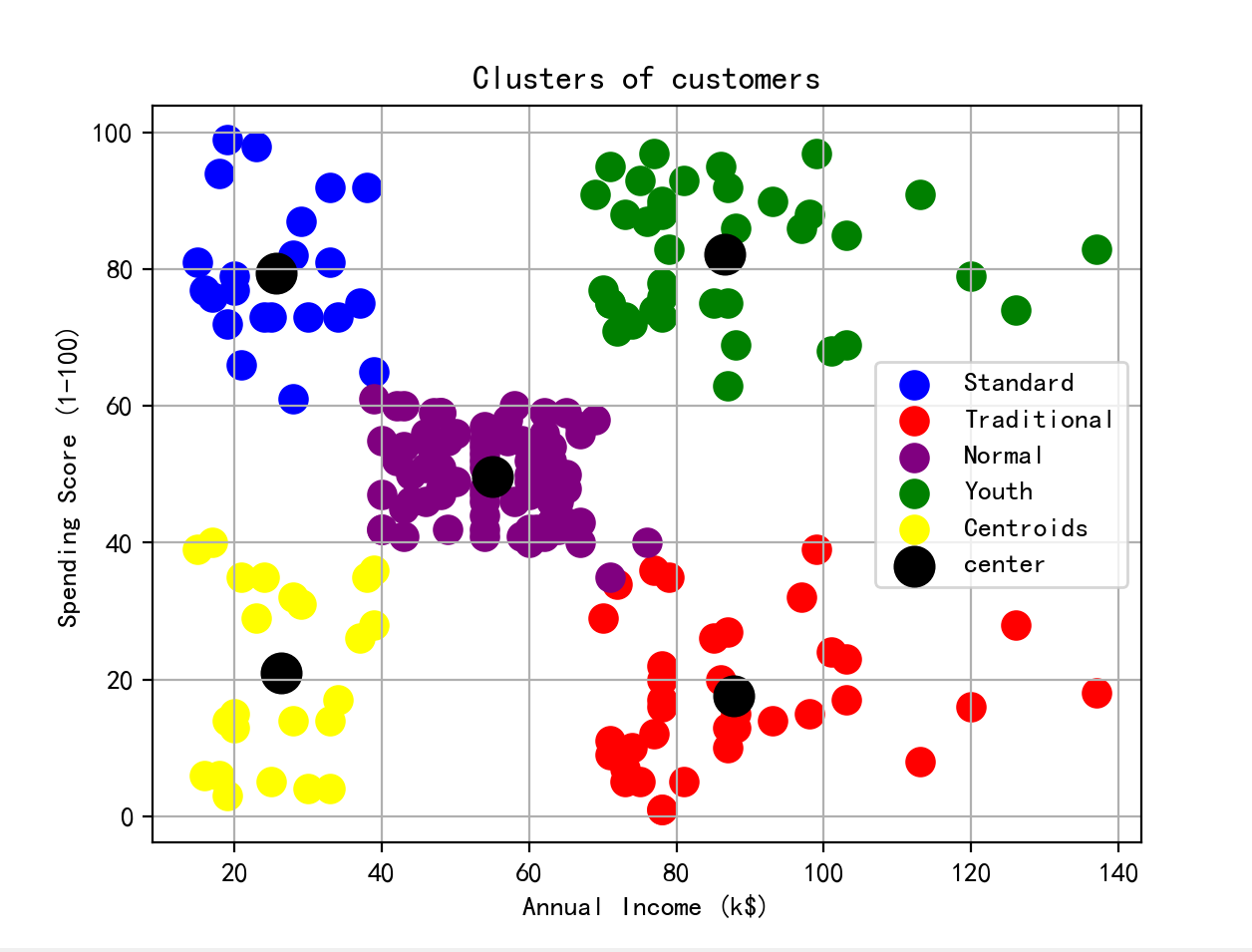
5、案例顾客数据聚类分析法
聚类分析:划分客户水平消费情况
python
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 新版本pycharm需要指定 matplotlib 使用 TkAgg 作为图形后端来渲染和显示图
matplotlib.use("TkAgg")
# 添加支持中文
plt.rcParams['font.sans-serif'] = ['SimHei','Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 数据处理
# 读取、处理本地文件
df = pd.read_csv(r'./customers.csv')
# print(df.info())
x = df[["Annual Income (k$)","Spending Score (1-100)"]]
# print(x)
# 获取k值,得k=5
# sse_list=[]
# sc_list=[]
# for i in range(2,20):
# estimator = KMeans(n_clusters=i,max_iter=100,random_state=22)
# estimator.fit_predict(x)
# y_pred = estimator.predict(x)
# # 获取sse
# sse_list.append(estimator.inertia_)
# # 获取sc系数
# sc_list.append(silhouette_score(x,y_pred))
#
#
# plt.plot(range(2,20),sse_list,'o-')
# plt.xlabel("聚类个数")
# plt.ylabel("sse")
# plt.grid()
# plt.show()
#
#
# plt.plot(range(2,20),sc_list,'o-')
# plt.xlabel("sc系数")
# plt.ylabel("sc")
# plt.grid()
# plt.show()
# 结果生成
estimator = KMeans(n_clusters=5,max_iter=20,random_state=22)
estimator.fit_transform(x)
y_pred = estimator.predict(x)
plt.scatter(x.values[y_pred == 0, 0], x.values[y_pred == 0, 1], s=100, c="blue", label="Standard")
plt.scatter(x.values[y_pred == 1, 0], x.values[y_pred == 1, 1], s=100, c="red", label='Traditional')
plt.scatter(x.values[y_pred == 2, 0], x.values[y_pred == 2, 1], s=100, c="purple", label='Normal')
plt.scatter(x.values[y_pred == 3, 0], x.values[y_pred == 3, 1], s=100, c="green", label='Youth')
plt.scatter(x.values[y_pred == 4, 0], x.values[y_pred == 4, 1], s=100, c="yellow", label='Centroids')
plt.scatter(estimator.cluster_centers_[:, 0], estimator.cluster_centers_[:, 1], s=200, c="black", label="center")
plt.grid()
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()