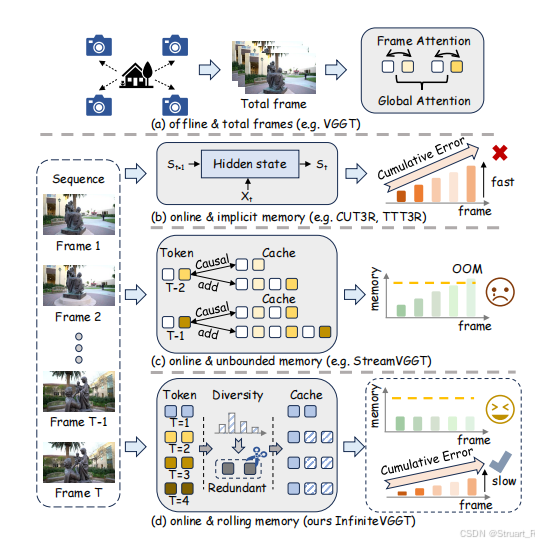
这三篇工作都是解决视频流中进行高效、在线、可扩展的4D几何重建问题。
目录
一、StreamVGGT
1、概述
motivation:VGGT实现流式输入下的重建存在效率低下,不能扩展,离线处理的问题。另外VGGT考虑全注意力机制复杂度较高,考虑大模型中的因果机制,引入到VGGT模型中。
contribution:先建立一个因果Transformer架构(StreamVGGT),之后利用具有全局注意力的VGGT作为教师模型,通过知识蒸馏指导StreamVGGT模型训练,并且在推理过程中引入了隐式缓存,用来存储历史帧的KV,实现增量式重建。
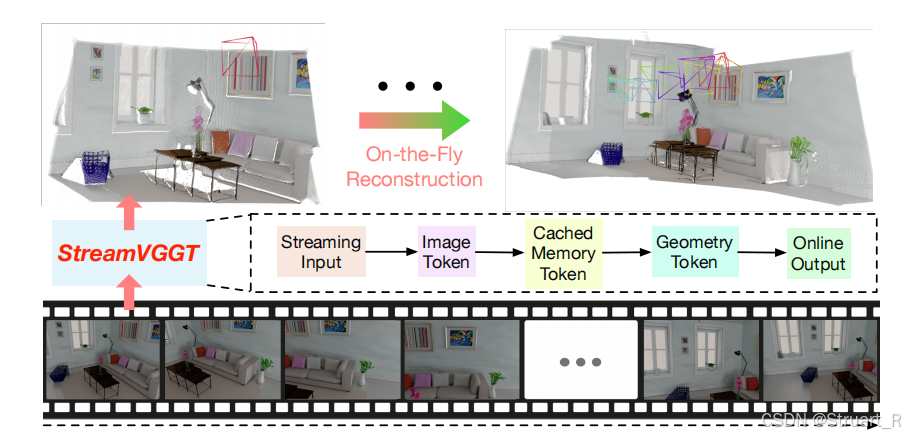
2、架构
(1)StreamVGGT
StreamVGGT与VGGT的模型只有Decoder不同,其中空间注意力机制就是以往的帧间注意力机制,而StreamVGGT中调整了顺序,先进行帧间注意力,保证每一帧特征明显,再进行因果推理。VGGT则是侧重全局性,所以优先全局注意力。
VGGT:(lobal attn->Frame attn) x n
Stream VGGT: (Spatial attn->Temporal Causal attn) x n
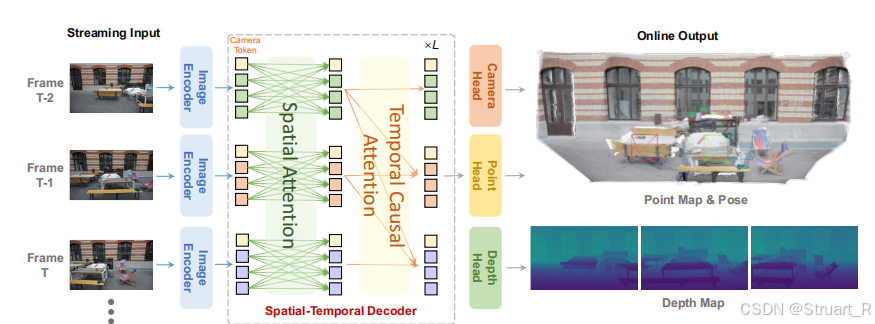
(2)推理机制
以往的VGGT,如果强行做流式推理,则需要每当新的一帧出现时,先计算与历史帧的全局交互,然后更新整个历史序列的几何信息。
cache memory tokens方法,当输入第T帧时,我们定义DINOv2生成的编码特征为,而前T-1帧的解码器得到的KV cache,作为缓存信息,保存了前T-1帧的几何信息:
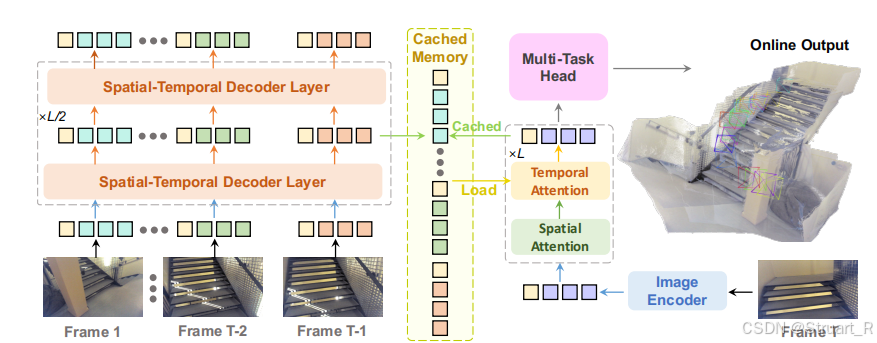
(3)训练过程
训练每次只采样10帧的短序列。
训练过程中采用蒸馏策略,教师模型为预训练好的VGGT仅用于推理,学生模型为StreamVGGT。首先利用VGGT训练一组相机参数、深度、点云等作为伪真值,然后基于伪真值计算所有的Loss(假定伪真值效果好于真值,完全相信伪真值),这样的好处是训练速度大大加快,目标只是在原有基础上学会因果关系。
这个蒸馏的代码来自于DUSt3R
二、Stream3R
1、概述
motivation:与StreamVGGT相同
contribution:直接修改VGGT的Decoder层为因果注意力,并基于VGGT权重进行端到端训练。
2、架构
这个模型更接近VGGT改causal attn,只是把全局注意力改成causal attn,这个是beta版本。
alpha版本则是基于DUSt3R的Croco DiT,但是解码器仍然用同一个共享的解码器,与VGGT相同。
训练过程中采用随机采样的短序列(4-10帧)进行端到端训练。
三、InfiniteVGGT
1、概述
motivation:
(1)解决在线3D几何理解中的根本矛盾:当前基于学习的3D重建方法分为离线处理和在线流式处理两种范式。离线方法(如VGGT)虽然重建质量高,但由于其批量处理的本质,内存需求与序列长度成正比,无法处理在线或无限长度的序列。而现有的在线流式方法则面临两难困境:一类(如StreamVGGT)通过不断累积Key-Value(KV)缓存来存储历史信息,导致内存和计算开销无限增长,最终系统崩溃;另一类(如CUT3R、TTT3R)将历史信息压缩到一个固定的隐状态(如RNN状态)中,虽然保证了有界资源,但会丢失关键信息,导致长期漂移和灾难性遗忘。
(2)**突破技术实现上的悖论:**为了高效处理不断增长的KV缓存,现有方法依赖于FlashAttention等硬件优化内核,这些内核通过避免显式计算完整的注意力矩阵来获得速度。然而,传统的缓存剪枝策略却恰恰需要访问这些注意力权重来判断token的重要性,这就形成了一个悖论:优化工具本身阻止了我们智能地缩小缓存。
(3)缺乏真正的长期评估基准:要验证一个系统在真正无限长序列上的性能,需要一个长期、连续的基准测试。而现有基准要么序列过短(≤1000帧),要么只是不连续片段的集合,无法对模型的长期、不间断性能进行严格评估。
contribution:VGGT/StreamVGGT+推理时动态运行的,基于Key相似度的KVcache智能缓存管理算法
comparison other algorithms:
2、架构
(1)分析
分析1:流式模型的KV cache一定与帧的数量成正比,所以长视频下内存一定会承受不住的,slide window确实可以解决内存线性膨胀的问题,但如何保留有价值记忆需要重点考虑。
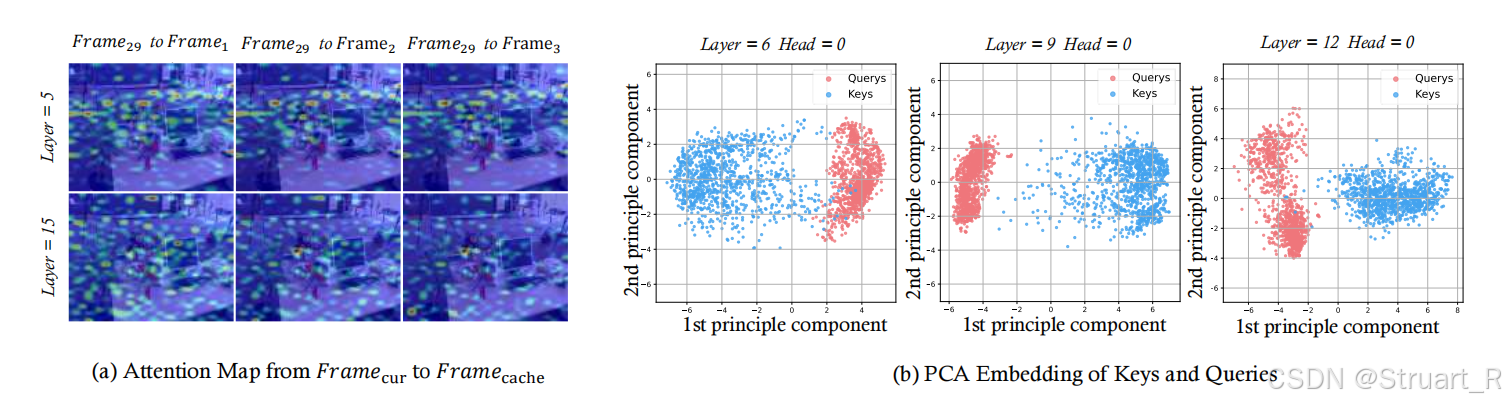
分析2:通过观测第29帧看向第1,2,3帧在不同层注意力的可视化。几乎不同历史帧的注意力图呈现近似分布,,这说明流式相机运动视角变化很小,当前帧查询会为相似的历史帧分配近似相同的注意力权重,但由于我们需要维护一个巨大的KV cache,所以这些近似相同的重复的value值严重影响内存,降低可扩展性。
分析3:不同注意力层的K和V在PCA降维后的特征空间分布。发现这两个点集是明显分离,方向大致垂直的,说明这两类向量降维后的核心特征维度上几乎没有线性相关性。
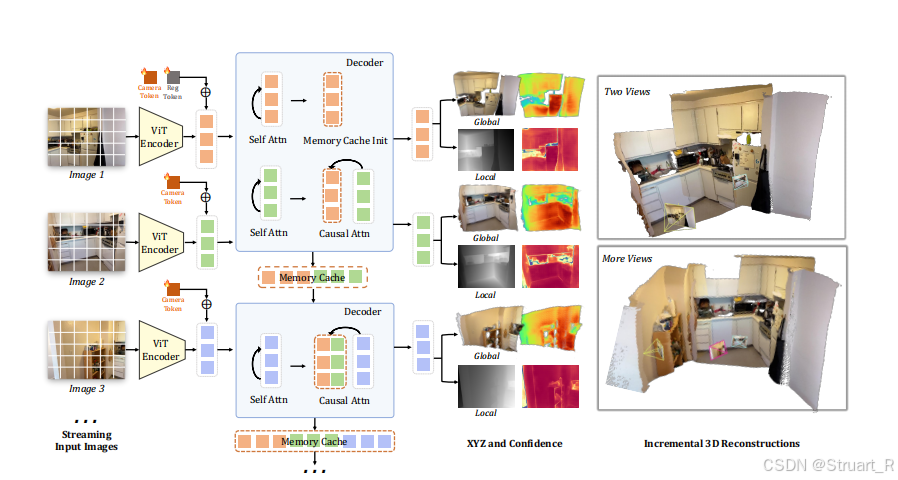
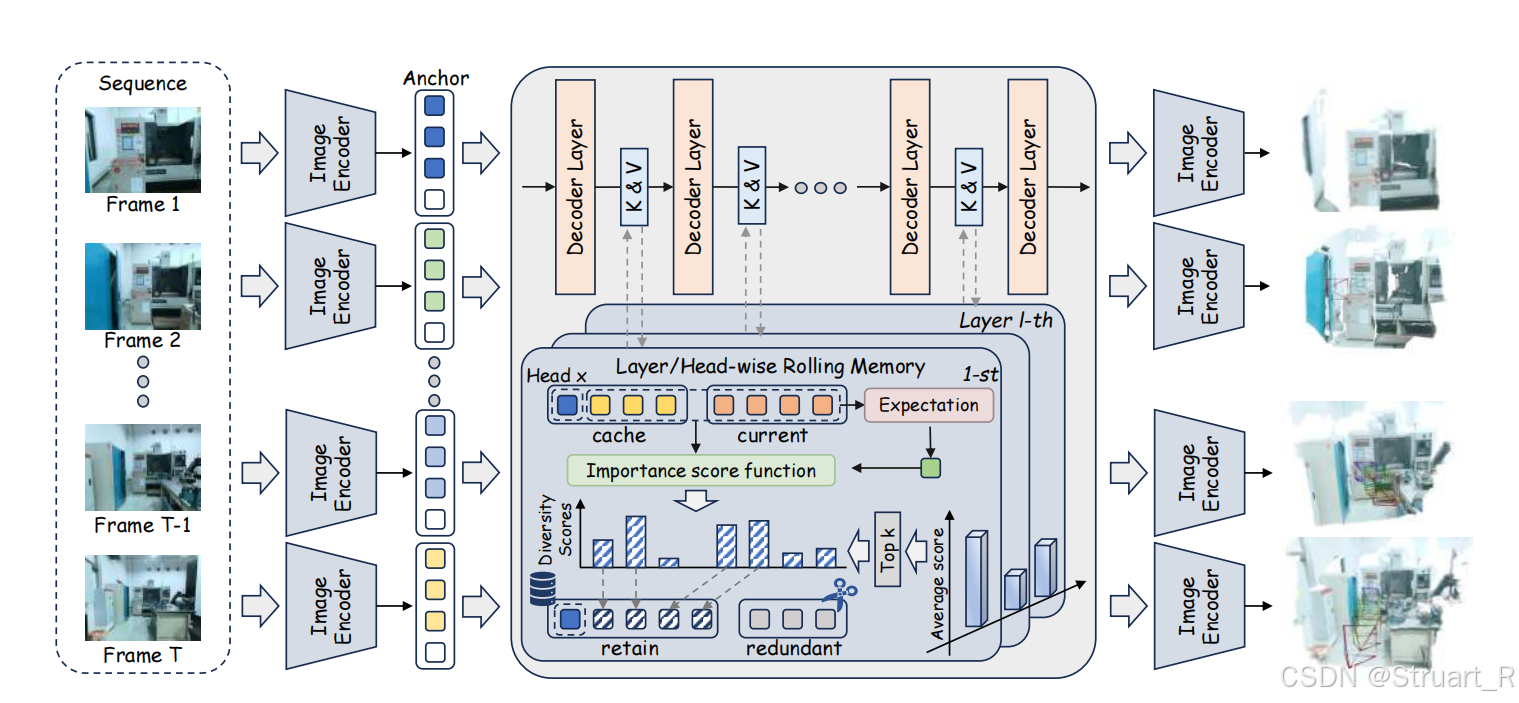
(2)建立记忆
模型基于StreamVGGT预训练模型,并修改KV cache的过滤操作
建立记忆:
首先第一帧经过DINOv2编码后的token在模型的第一层因果注意力模块中会生成对应的K和V,而这一帧所生成的KV对,被完整地存储起来作为不可变锚点集合。
对于任一时刻t,任一特定层l和注意力头h,其总缓存被分为两部分:不可变锚点集合
和包含第二帧开始到当前帧的所有历史token,即可变候选集
(3)相似度计算
剪枝策略仅应用与可变候选集,以保留信息量最大的token,计算是独立对每一层l和每一个头h进行的。
首先对候选集所有key向量归一化,并投影到单位球面上,得到key向量的方向:
对每一个头(l,h)的键空间建立一个参考向量,即平均键向量
使用负余弦相似度作为多样性分数,来衡量每一个归一化键与平均键差异,完全相同则cossim计算为1,完全相反则计算cossim为-1,所以尽量让负余弦相似度越大越好,保留每一层最独特的那部分token。
(4)分层自适应分配
信息多样性在模型中分布不均。浅层网络(如中间层) 负责提取和放大帧间的细微差异以进行空间推理,显示出较高的信息多样性。而最初的输入层 (处理颜色、亮度等低级统计信息)和最深的输出层(表征趋于融合,形成整体的语义理解)的多样性则显著较低。
计算层平均多样性分数 :对于每一层,先计算其内部所有token的"多样性分数"的均值,记为
。这代表了该层信息的平均独特程度。
通过Softmax分配预算比例 :将各层的平均多样性分数输入一个带温度参数的Softmax函数,计算出每一层应得的预算比例
。多样性越高的层,其预算比例就越大。
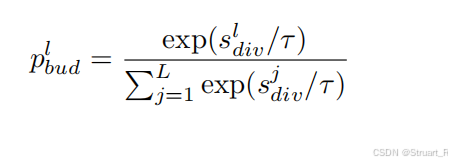
分配具体预算 :将总缓存预算 乘以各层的预算比例,就得到了该层实际的token存储预算
3、Long3D评估数据集
在Long3D提出之前,缺乏能够严格评估模型在极长、连续视频流上性能的公开基准。现有数据集(如7-Scenes)要么序列过短(≤1000帧),要么只是不连续片段的集合,无法测试模型在真正无限长、不间断输入下的长期稳定性和抗漂移能力。
Long3D数据集包含5个极具挑战性的室内外场景序列,每个序列长度约为2,000到10,000帧。它提供了连续的RGB图像流和对应的全局地面真值点云。研究者可以在该数据集上进行"密集视角流式重建"评估,即让模型处理整个图像流并生成一个全局点云,再与真值进行对齐和定量比较(使用Accuracy, Completion, Normal Consistency等指标)
参考:
https://github.com/NIRVANALAN/STream3R