写在前面的话:
在复现paddleseg过程中,主要参考官方文档,程序也可在此下载:PaddleSeg
一、环境安装
1.创建虚拟环境,python≥3.6,然后点击链接,选择操作系统、安装方式、芯片厂商、计算平台等信息,然后复制生成的命令进行安装即可,链接:PP飞桨
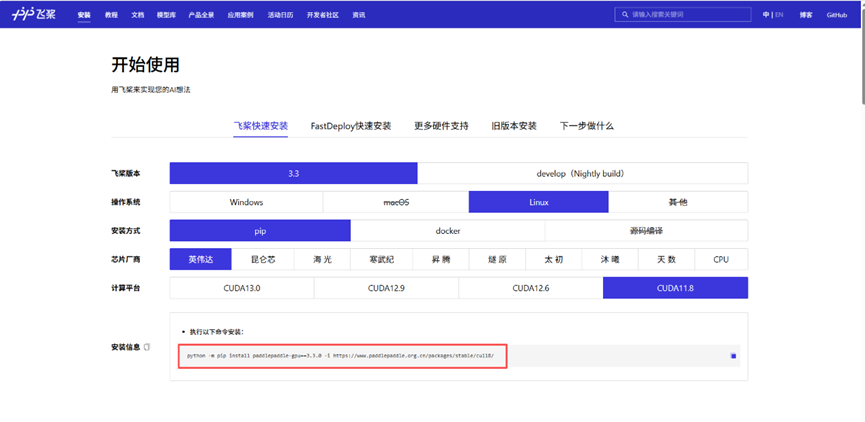
(快速安装里CUDA最低版本为11.8,所以先查看电脑或服务器的CUDA版本是多少,然后选择快速安装或旧版本安装)
2.检查是否安装成功及PaddlePaddle版本
# 在Python解释器中顺利执行如下命令
>>> import paddle
>>> paddle.utils.run_check()
# 如果命令行出现以下提示,说明PaddlePaddle安装成功
# PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
# 查看PaddlePaddle版本
>>> print(paddle.__version__)3.安装paddleseg,命令如下:
pip install paddleseg二、数据集准备
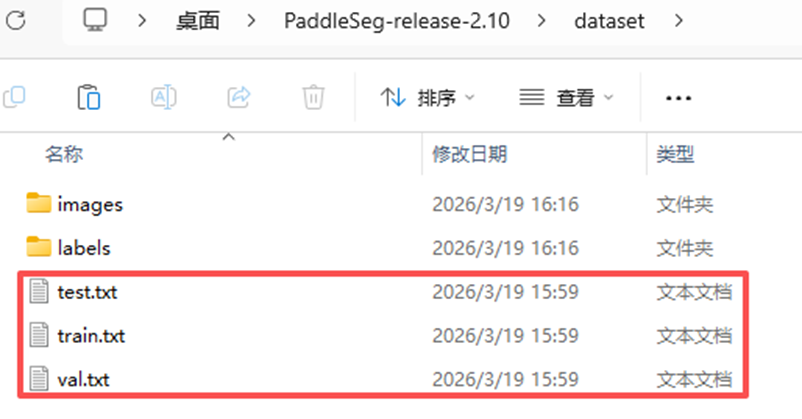
创建dataset文件夹,将原始图像存放在images子文件夹,标注图像放在labels子文件夹,使用tools/data/split_dataset_list.py程序进行数据集划分,对split_dataset_list.py程序做了小修改,在使用时修改99-102行的路径和划分比例即可。
# paddleseg划分数据集生成txt
# coding: utf8
import glob
import os.path
import argparse
import warnings
import numpy as np
def parse_args():
parser = argparse.ArgumentParser(
description='A tool for proportionally randomizing dataset to produce file lists.'
)
parser.add_argument('dataset_root', help='the dataset root path', type=str)
parser.add_argument('images_dir_name', help='the directory name of images', type=str)
parser.add_argument('labels_dir_name', help='the directory name of labels', type=str)
parser.add_argument('--split', help='', nargs=3, type=float, default=[0.7, 0.2, 0.1])
parser.add_argument('--separator', dest='separator', help='file list separator', default=" ", type=str)
parser.add_argument('--format', help='data format of images and labels', type=str, nargs=2, default=['jpg', 'png'])
parser.add_argument('--postfix', help='postfix of images or labels', type=str, nargs=2, default=['', ''])
return parser.parse_args()
def get_all_image_files(path):
""" 读取所有图片:jpg、jpeg、png、bmp 全部支持 """
files = []
for fmt in ['jpg', 'jpeg', 'png', 'bmp', 'tiff']:
files.extend(glob.glob(os.path.join(path, f'*.{fmt}')))
return sorted(files)
def get_all_label_files(path):
""" 读取所有标签:png、jpg 全部支持 """
files = []
for fmt in ['png', 'jpg', 'jpeg']:
files.extend(glob.glob(os.path.join(path, f'*.{fmt}')))
return sorted(files)
def generate_list(args):
separator = args.separator
dataset_root = args.dataset_root
if abs(sum(args.split) - 1.0) > 1e-8:
raise ValueError("The sum of input params `split` should be 1")
image_dir = os.path.join(dataset_root, args.images_dir_name)
label_dir = os.path.join(dataset_root, args.labels_dir_name)
# ===================== 核心:图片 + 标签都自动读取所有格式 =====================
image_files = get_all_image_files(image_dir)
label_files = get_all_label_files(label_dir)
print(f"📸 图片数量:{len(image_files)}")
print(f"🏷️ 标签数量:{len(label_files)}")
# 按文件名配对(无视后缀)
image_map = {os.path.splitext(os.path.basename(f))[0]: f for f in image_files}
label_map = {os.path.splitext(os.path.basename(f))[0]: f for f in label_files}
final_img = []
final_lab = []
for name in image_map:
if name in label_map:
final_img.append(image_map[name])
final_lab.append(label_map[name])
print(f"✅ 成功配对:{len(final_img)} 组")
if len(final_img) == 0:
raise Exception("未匹配到任何图片和标签")
# 随机打乱
final_img = np.array(final_img)
final_lab = np.array(final_lab)
state = np.random.get_state()
np.random.shuffle(final_img)
np.random.set_state(state)
np.random.shuffle(final_lab)
# 生成 txt
dataset_names = ['train', 'val', 'test']
start = 0
total = len(final_img)
for i, (name, ratio) in enumerate(zip(dataset_names, args.split)):
if ratio <= 0:
continue
print(f"Creating {name}.txt...")
num = round(ratio * total)
end = start + num if i != len(args.split)-1 else total
with open(os.path.join(dataset_root, f'{name}.txt'), 'w') as f:
for j in range(start, end):
img = final_img[j].replace(dataset_root, '').lstrip(os.path.sep)
lab = final_lab[j].replace(dataset_root, '').lstrip(os.path.sep)
f.write(f"{img}{separator}{lab}\n")
start = end
print("✅ 数据集划分完成!")
if __name__ == '__main__':
# ===================== 一键运行配置 =====================
DEFAULT_DATASET_ROOT = r"dataset"
DEFAULT_IMAGES_DIR = "images"
DEFAULT_LABELS_DIR = "labels"
DEFAULT_SPLIT = [0.8, 0.1, 0.1]
# =========================================================
import sys
if len(sys.argv) == 1:
print("使用默认配置一键运行...")
class DefaultArgs:
def __init__(self):
self.dataset_root = DEFAULT_DATASET_ROOT
self.images_dir_name = DEFAULT_IMAGES_DIR
self.labels_dir_name = DEFAULT_LABELS_DIR
self.split = DEFAULT_SPLIT
self.separator = " "
self.format = ["jpg", "png"]
self.postfix = ["", ""]
args = DefaultArgs()
generate_list(args)
else:
args = parse_args()
generate_list(args)运行该程序后在dataset目录下生成三个txt文件。
三、配置文件
主目录下创建data.yml,程序内容如下,使用时修改分割种类以及标识文件路径(划分数据集时生成的txt路径)。
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大。如果使用多卡训练,总得batch size等于该batch size乘以卡数。
iters: 75000 #模型训练迭代的轮数
# iters根据训练集数据的多少确定,若训练集为1000张数据,batch_size为4,则iters设置250,即为一个epoch;通常epoch设置为300.
train_dataset: #训练数据设置
type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。
dataset_root: dataset #数据集路径
train_path: dataset/train.txt #数据集中用于训练的标识文件
num_classes: 5 #指定类别个数(背景也算为一类)
mode: train #表示用于训练
transforms: #模型训练的数据预处理方式。
- type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小
crop_size: [512, 512]
- type: RandomHorizontalFlip #对原始图像和标注图像随机进行水平反转
- type: RandomDistort #对原始图像进行亮度、对比度、饱和度随机变动,标注图像不变
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize #对原始图像进行归一化,标注图像保持不变
val_dataset: #验证数据设置
type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。
dataset_root: dataset #数据集路径
val_path: dataset/val.txt #数据集中用于验证的标识文件
num_classes: 5 #指定类别个数(背景也算为一类)
mode: val #表示用于验证
transforms: #模型验证的数据预处理的方式
- type: Normalize #对原始图像进行归一化,标注图像保持不变
optimizer: #设定优化器的类型
type: SGD #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #设置SGD的动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合
lr_scheduler: # 学习率的相关设置
type: PolynomialDecay # 一种学习率类型。共支持12种策略
learning_rate: 0.01 # 初始学习率
power: 0.9
end_lr: 0
loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #CE损失
coef: [1, 1, 1] # PP-LiteSeg有一个主loss和两个辅助loss,coef表示权重,所以 total_loss = coef_1 * loss_1 + .... + coef_n * loss_n
model: #模型说明
type: PPLiteSeg #设定模型类别
backbone: # 设定模型的backbone,包括名字和预训练权重
type: STDC2
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet2.tar.gz四、模型训练、评估、预测
1.训练
(1)模型训练程序为tools/train.py,使用如下命令即可开始训练。
export CUDA_VISIBLE_DEVICES=0 # Linux上设置1张可用的卡
# set CUDA_VISIBLE_DEVICES=0 # Windows上设置1张可用的卡
python tools/train.py \
--config data.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output上述训练命令解释:
--config指定配置文件。
--save_interval指定每训练特定轮数后,就进行一次模型保存或者评估(如果开启模型评估)。
--do_eval开启模型评估。具体而言,在训练save_interval指定的轮数后,会进行模型评估。
--use_vdl开启写入VisualDL日志信息,用于VisualDL可视化训练过程。
--save_dir指定模型和visualdl日志文件的保存根路径。
(2)多卡训练是命令如下:
export CUDA_VISIBLE_DEVICES=0,1,2,3 # 设置4张可用的卡
python -m paddle.distributed.launch tools/train.py \
--config data.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output(3)训练中断时,通过给train.py脚本设置resume_model输入参数,加载中断前最近一次保存的模型信息,恢复训练。恢复训练命令如下:
python tools/train.py \
--config configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml \
--resume_model output/iter_500 \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output(4)训练可视化:
执行如下命令,启动VisualDL,然后在浏览器输入提示的网址,即可看到训练相关的精度图、mIoU等图。
visualdl --logdir output/对train.py做了小修改,在使用时修改其中的核心训练参数即可,避免了很长的命令,程序如下:
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
import yaml
import argparse
import random
import platform
import paddle
import numpy as np
import cv2
from paddleseg.cvlibs import Config, SegBuilder
from paddleseg.utils import get_sys_env, utils
from paddleseg.utils.logger import setup_logger
from paddleseg.core import train
def parse_args():
parser = argparse.ArgumentParser(description='Model training')
# Common params
parser.add_argument("--config", help="The path of config file.", type=str)
parser.add_argument('--device',
help='Set the device place for training model.',
default='gpu',
choices=['cpu', 'gpu', 'xpu', 'npu', 'mlu'],
type=str)
parser.add_argument('--save_dir',
help='The directory for saving the model snapshot.',
type=str,
default='./output')
parser.add_argument(
'--num_workers',
help=
'Number of workers for data loader. Bigger num_workers can speed up data processing.',
type=int,
default=0)
parser.add_argument('--do_eval',
help='Whether to do evaluation in training.',
action='store_true')
parser.add_argument(
'--use_vdl',
help='Whether to record the data to VisualDL in training.',
action='store_true')
parser.add_argument('--use_ema',
help='Whether to ema the model in training.',
action='store_true')
# Runntime params
parser.add_argument('--resume_model',
help='The path of the model to resume training.',
type=str)
parser.add_argument('--iters', help='Iterations in training.', type=int)
parser.add_argument('--batch_size',
help='Mini batch size of one gpu or cpu. ',
type=int)
parser.add_argument('--learning_rate', help='Learning rate.', type=float)
parser.add_argument(
'--save_interval',
help='How many iters to save a model snapshot once during training.',
type=int,
default=1000)
parser.add_argument(
'--log_iters',
help='Display logging information at every `log_iters`.',
default=10,
type=int)
parser.add_argument('--keep_checkpoint_max',
help='Maximum number of checkpoints to save.',
type=int,
default=5)
parser.add_argument('--early_stop_intervals',
help='Early Stop at args number of save intervals.',
type=int,
default=None)
# Other params
parser.add_argument('--seed',
help='Set the random seed in training.',
default=None,
type=int)
parser.add_argument(
"--precision",
default="fp32",
type=str,
choices=["fp32", "fp16"],
help=
"Use AMP (Auto mixed precision) if precision='fp16'. If precision='fp32', the training is normal."
)
parser.add_argument(
"--amp_level",
default="O1",
type=str,
choices=["O1", "O2"],
help=
"Auto mixed precision level. Accepted values are "O1" and "O2": O1 represent mixed precision, the input \
data type of each operator will be casted by white_list and black_list; O2 represent Pure fp16, all operators \
parameters and input data will be casted to fp16, except operators in black_list, don't support fp16 kernel \
and batchnorm. Default is O1(amp).")
parser.add_argument(
'--profiler_options',
type=str,
help='The option of train profiler. If profiler_options is not None, the train ' \
'profiler is enabled. Refer to the paddleseg/utils/train_profiler.py for details.'
)
parser.add_argument(
'--data_format',
help=
'Data format that specifies the layout of input. It can be "NCHW" or "NHWC". Default: "NCHW".',
type=str,
default='NCHW')
parser.add_argument(
'--repeats',
type=int,
default=1,
help=
"Repeat the samples in the dataset for `repeats` times in each epoch.")
parser.add_argument('--opts',
help='Update the key-value pairs of all options.',
nargs='+')
# Set multi-label mode
parser.add_argument(
'--use_multilabel',
action='store_true',
default=False,
help='Whether to enable multilabel mode. Default: False.')
parser.add_argument('--to_static_training',
action='store_true',
default=None,
help='Whether to enable to_static in training')
parser.add_argument(
'--output_op',
choices=['argmax', 'softmax', 'none'],
default="argmax",
help=
"Select the op to be appended to the last of inference model, default: argmax."
"In PaddleSeg, the output of trained model is logit (H*C*H*W). We can apply argmax and"
"softmax op to the logit according the actual situation.")
parser.add_argument(
"--input_shape",
nargs='+',
help=
"Export the model with fixed input shape, e.g., `--input_shape 1 3 1024 1024`.",
type=int,
default=None)
parser.add_argument('--for_fd',
action='store_true',
help="Export the model to FD-compatible format.")
# 手动设置默认参数(对应目标命令行参数)
args = parser.parse_args()
# 如果未传入任何命令行参数,则使用内置默认值
if len(sys.argv) == 1:
# 设置CUDA可见设备
if platform.system() == 'Linux':
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
elif platform.system() == 'Windows':
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 设置核心训练参数
args.config = 'data.yml'
args.do_eval = True
args.use_vdl = True
args.save_interval = 500
args.save_dir = 'output'
return args
def main(args):
assert args.config is not None, \
'No configuration file specified, please set --config'
cfg = Config(args.config,
learning_rate=args.learning_rate,
iters=args.iters,
batch_size=args.batch_size,
to_static_training=args.to_static_training,
opts=args.opts)
builder = SegBuilder(cfg)
utils.show_env_info()
utils.show_cfg_info(cfg)
utils.set_seed(args.seed)
utils.set_device(args.device)
utils.set_cv2_num_threads(args.num_workers)
uniform_output_enabled = cfg.dic.get("uniform_output_enabled", False)
if uniform_output_enabled:
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
if os.path.exists(os.path.join(args.save_dir, "train_result.json")):
os.remove(os.path.join(args.save_dir, "train_result.json"))
with open(os.path.join(args.save_dir, "config.yaml"), "w") as f:
yaml.dump(cfg.dic, f)
print_mem_info = cfg.dic.pop('print_mem_info', True)
shuffle = cfg.dic['train_dataset'].pop('shuffle', True)
log_ranks = cfg.dic.pop('log_ranks', '0')
if args.use_multilabel:
if 'test_config' not in cfg.dic:
cfg.dic['test_config'] = {'use_multilabel': True}
else:
cfg.dic['test_config']['use_multilabel'] = True
# TODO refactor
# Only support for the DeepLabv3+ model
if args.data_format == 'NHWC':
if cfg.dic['model']['type'] != 'DeepLabV3P':
raise ValueError(
'The "NHWC" data format only support the DeepLabV3P model!')
cfg.dic['model']['data_format'] = args.data_format
cfg.dic['model']['backbone']['data_format'] = args.data_format
loss_len = len(cfg.dic['loss']['types'])
for i in range(loss_len):
cfg.dic['loss']['types'][i]['data_format'] = args.data_format
model = utils.convert_sync_batchnorm(builder.model, args.device)
train_dataset = builder.train_dataset
# TODO refactor
if args.repeats > 1:
train_dataset.file_list *= args.repeats
val_dataset = builder.val_dataset if args.do_eval else None
optimizer = builder.optimizer
loss = builder.loss
logger = setup_logger(log_ranks=log_ranks)
train(model,
train_dataset,
val_dataset=val_dataset,
optimizer=optimizer,
save_dir=args.save_dir,
iters=cfg.iters,
batch_size=cfg.batch_size,
early_stop_intervals=args.early_stop_intervals,
resume_model=args.resume_model,
save_interval=args.save_interval,
log_iters=args.log_iters,
num_workers=args.num_workers,
use_vdl=args.use_vdl,
use_ema=args.use_ema,
losses=loss,
keep_checkpoint_max=args.keep_checkpoint_max,
test_config=cfg.test_config,
precision=args.precision,
amp_level=args.amp_level,
profiler_options=args.profiler_options,
to_static_training=cfg.to_static_training,
logger=logger,
print_mem_info=print_mem_info,
shuffle=shuffle,
uniform_output_enabled=uniform_output_enabled,
cli_args=None if not uniform_output_enabled else args)
if __name__ == '__main__':
args = parse_args()
main(args)2.评估
模型评估使用的是tools/val.py ,运行下边命令行即可启动评估,修改配置文件和模型文件路径即可。
python tools/val.py --config data.yml --model_path output/best_model/model.pdparams评估模型质量主要是通过三个指标进行判断,准确率(acc)、平均交并比(mIoU)、Kappa系数。
(1)准确率:指类别预测正确的像素占总像素的比例,准确率越高模型质量越好。
(2)平均交并比:对每个类别数据集单独进行推理计算,计算出的预测区域和实际区域交集除以预测区域和实际区域的并集,然后将所有类别得到的结果取平均。
(3)Kappa系数:一个用于一致性检验的指标,可以用于衡量分类的效果。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。其公式如下所示,P0P_0P0为分类器的准确率,PeP_eP**e为随机分类器的准确率。Kappa系数越高模型质量越好。
3.预测
tools/predict.py脚本是专门用来可视化预测的,命令格式如下所示。
python tools/predict.py \
--config data.yml \
--model_path output/best_model/model.pdparams \
--image_path dataset/test.txt \
--save_dir output/result其中:image_path可以是一张图片的路径,也可以是一个包含图片路径的文件列表,也可以是一个目录。
如果不指定输出位置,在默认文件夹output/results下将生成两个文件夹added_prediction与pseudo_color_prediction, 分别存放叠加效果图与预测mask的结果。
若要给分割的每个种类指定颜色,则可以自定义color map,命令如下:
python tools/predict.py \
--config data.yml \
--model_path output/best_model/model.pdparams \
--image_path dataset/test.txt \
--save_dir output/result
--custom_color 0 0 0 100 100 100 200 200 200 125 125 125 187 187 187在最后添加了 --custom_color 0 0 0 100 100 100 200 200 200 125 125 125 187 187 187,是因为在RGB图像中,每个像素最终呈现出来的颜色是由RGB三个通道的分量共同决定的,因此该命令行参数后每三位代表一种像素的颜色,位置与label.txt中各类像素点一一对应。
如果使用自定义color map,输入的color值的个数应该等于3 * 像素种类(取决于你所使用的数据集)。
五、标签与预测图可视化对比
上一步预测可以看到训练的模型分割的效果,这一步是将原图、标签、预测图放一起看,更能直观的看出来哪一部分没有分割好。官方程序路径为:tools/data/visualize_annotation.py
运行命令为:
python tools/data/visualize_annotation.py \
--file_path dataset/test.txt \
--pred_dir output/result/pseudo_color_prediction/images \
--save_dir output/visualize_out作用是读取 test.txt 里的原图 + 标签,把灰度标签变成彩色,彩色标签半透明盖在原图上,如果有预测图,也做一样的处理,最后把三张图拼成一张长图保存。
对visualize_annotation.py做了小改动,程序如下,使用时修改路径即可。
import argparse
import os
import shutil
import cv2
import numpy as np
from PIL import Image
from paddleseg.utils import progbar, visualize
# ===================== 官方灰度转伪彩色代码(已融合) =====================
def get_color_map_list(num_classes):
num_classes += 1
color_map = num_classes * [0, 0, 0]
for i in range(0, num_classes):
j = 0
lab = i
while lab:
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
j += 1
lab >>= 3
color_map = color_map[3:]
return color_map
def gray_to_pseudo_color(gray_img, num_classes=11):
color_map = get_color_map_list(num_classes)
lbl_pil = Image.fromarray(gray_img.astype(np.uint8), mode='P')
lbl_pil.putpalette(color_map)
return lbl_pil.convert("RGB")
# ==========================================================================
def parse_args():
parser = argparse.ArgumentParser(description='Visualization')
parser.add_argument('--file_path', type=str, default="dataset/test.txt")
parser.add_argument('--pred_dir', type=str, default="output/result/pseudo_color_prediction/images")
parser.add_argument('--save_dir', type=str, default='output/visualize_out')
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--weight', type=float, default=0.6) # 统一透明度
return parser.parse_args()
def get_images_path(file_path):
assert os.path.isfile(file_path)
images_path = []
image_dir = os.path.dirname(file_path)
with open(file_path, 'r') as f:
for line in f:
line = line.strip()
if not line:
continue
origin_path, annot_path = line.split(" ")
origin_path = os.path.join(image_dir, origin_path)
annot_path = os.path.join(image_dir, annot_path)
images_path.append([origin_path, annot_path])
return images_path
def mkdir(dir, rm_exist=False):
if not os.path.exists(dir):
os.makedirs(dir)
else:
if rm_exist:
shutil.rmtree(dir)
os.makedirs(dir)
# 叠加函数:原图 + 彩色图 → 透明叠加(统一透明度)
def overlay_image(origin_img, color_img, weight=0.3):
origin = np.array(origin_img).astype(np.float32)
color = np.array(color_img).astype(np.float32)
result = (1 - weight) * origin + weight * color
return Image.fromarray(np.uint8(result))
def visualize_imgs(args):
file_path = args.file_path
pred_dir = args.pred_dir
save_dir = args.save_dir
num_classes = args.num_classes
weight = args.weight
images_path = get_images_path(file_path)
bar = progbar.Progbar(target=len(images_path), verbose=1)
mkdir(save_dir, True)
for idx, (origin_path, annot_path) in enumerate(images_path):
# 1. 原图
origin_img = Image.open(origin_path).convert("RGB")
w, h = origin_img.size
# 2. 灰度标签 → 官方伪彩色 → 叠加原图
annot_gray = np.array(Image.open(annot_path))
annot_color = gray_to_pseudo_color(annot_gray, num_classes)
annot_color = annot_color.resize((w, h), Image.NEAREST)
overlay_annot = overlay_image(origin_img, annot_color, weight)
# 3. 预测图 → 直接叠加原图(与标签透明度一致)
img_name = os.path.basename(origin_path)
pred_name = os.path.splitext(img_name)[0] + ".png"
pred_path = os.path.join(pred_dir, pred_name)
pred_color = Image.open(pred_path).convert("RGB")
pred_color = pred_color.resize((w, h), Image.NEAREST)
overlay_pred = overlay_image(origin_img, pred_color, weight)
# 4. 三图拼接:原图 | 叠加标签 | 叠加预测
result_img = visualize.paste_images([origin_img, overlay_annot, overlay_pred])
result_img.save(os.path.join(save_dir, img_name))
bar.update(idx + 1)
print("\n✅ 处理完成!三图拼接已生成!")
print(f"📂 保存路径:{save_dir}")
if __name__ == '__main__':
args = parse_args()
visualize_imgs(args)六、模型导出
1.导出(静态)模型
运行tools/export.py,导出模型,保存在output/static_inference目录下,修改路径以及 --input_shape。
python tools/export.py \
--config data.yml \
--model_path output/best_model/model.pdparams \
--save_dir output/static_inference \
--input_shape 1 3 512 512
2.转onnx
安装Paddle2ONNX≥0.6,pip install paddle2onnx
执行如下命令,使用Paddle2ONNX将output文件夹中的预测模型导出为ONNX格式模型。
paddle2onnx --model_dir output/static_inference \
--model_filename model.json \
--params_filename model.pdiparams \
--opset_version 11 \
--save_file output.onnx七、使用onnx推理
1.训练没有随机裁剪
当训练时没有进行随即裁剪,推理时输入图片大小和模型固定输入尺寸一致,使用官方推理程序即可,onnx推理程序路径:deploy/python/infer_onnx.py,命令如下:
python deploy/python/infer_onnx.py \
--img_path dataset/test.jpg \
--onnx_file output.onnx \
--save_dir output/onnx_result2.训练时有随机裁剪
当训练时有随即裁剪时,训练好的模型固定输入尺寸即为随即裁剪的尺寸,推理时输入图片大小与模型固定输入尺寸不一致时,用下边程序。
# 模型与推理输入图像尺寸不一致时,修改为模型固定输入尺寸,该程序是将输入强制缩小到512×512
import os
import numpy as np
import cv2
from paddleseg.transforms import Normalize, Compose
from paddleseg.utils import get_image_list
from paddleseg.utils.visualize import get_pseudo_color_map
from onnxruntime import InferenceSession
# ====================== 固定配置 ======================
IMG_PATH = "dataset/test.txt" # 批量预测:test.txt
# IMG_PATH = "dataset/images" # 预测整个文件夹
# IMG_PATH = "dataset/images/xxx.png" # 单张图片
ONNX_FILE = "output.onnx" # ONNX模型
SAVE_DIR = "output/onnx_result" # 保存结果
# =================================================================
def _save_imgs(results, imgs_path, save_dir):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for i, result in enumerate(results):
if result.ndim == 3:
result = np.squeeze(result)
result = get_pseudo_color_map(result)
basename = os.path.basename(imgs_path[i])
basename, _ = os.path.splitext(basename)
save_path = os.path.join(save_dir, basename + '.png')
result.save(save_path)
print(f'✅ 已保存: {save_path}')
def main():
print("🔸 ONNX模型推理")
print(f"🔸 推理路径: {IMG_PATH}")
print(f"🔸 ONNX模型: {ONNX_FILE}")
print(f"🔸 保存目录: {SAVE_DIR}\n")
# 自动获取图片列表(支持 单张 / 文件夹 / test.txt)
imgs_list, _ = get_image_list(IMG_PATH)
transform = Compose([Normalize()])
# 加载ONNX
sess = InferenceSession(ONNX_FILE)
input_name = sess.get_inputs()[0].name
all_results = []
for img_path in imgs_list:
# 强制resize到512x512
img = cv2.imread(img_path)
img = cv2.resize(img, (512, 512))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
data = transform({'img': img})['img']
data = data[np.newaxis, ...]
out = sess.run(None, {input_name: data})[0]
all_results.append(out)
_save_imgs(all_results, imgs_list, SAVE_DIR)
print("\n🎉 全部预测完成!")
if __name__ == '__main__':
main()写在最后的话:
意识到问题就是解决了一半问题。