核心技术篇④ | 让虚拟人"活起来":口型驱动与面部动画全技术拆解
导语
当虚拟人拥有了逼真的视觉形象、自然有情感的声音后,让声音与嘴型精准同步、面部表情自然灵动,是实现虚拟人拟人化的关键一步。如果口型与语音脱节、表情僵硬卡顿,即便形象和声音再优秀,也会陷入"恐怖谷效应",大幅降低用户体验。
口型驱动与面部动画技术,是虚拟人从"静态数字形象"变成"动态交互分身"的核心,从早期仅实现嘴型同步的Wav2Lip,到支持实时全脸驱动的LivePortrait,再到影视级超逼真的VASA-1,技术迭代让虚拟人的动态表达越来越贴近真人。本文将从原理拆解、核心模块、实战操作到场景适配,全面讲解虚拟人口型驱动与面部动画的全链路技术,让你的虚拟人真正"活起来"。
1. 虚拟人口型驱动技术核心分类与整体对比
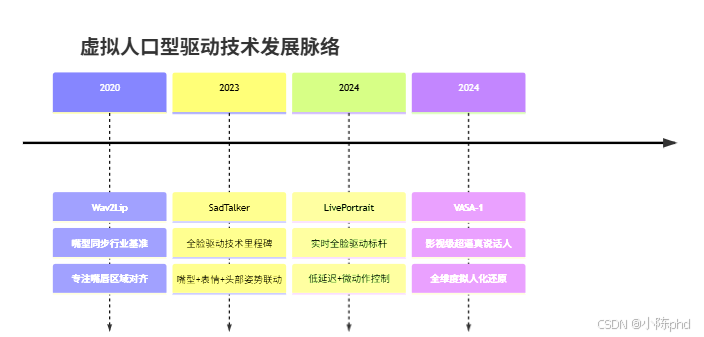
虚拟人口型驱动技术的核心是实现音频与面部动态的跨模态对齐,即让虚拟人的嘴型、表情、动作随语音节奏自然变化。目前行业主流的技术方案有四款,其中Wav2Lip、LivePortrait、VASA-1为核心落地模型,SadTalker为技术里程碑,四款模型的定位、特点与适配场景形成清晰的技术梯度,满足从基础口播到影视级制作的全场景需求。
配图2:主流口型驱动模型核心对比表(可视化表格图)
| 模型名称 | 发布时间 | 核心定位 | 核心特点 | 核心优势 | 主流适配场景 |
|---|---|---|---|---|---|
| Wav2Lip | 2020 | 嘴型同步行业基准 | 仅聚焦嘴唇区域,专注音频与嘴型的精准对齐 | 同步精度极高、开源生态成熟、开箱即用 | 影视配音修正、静态口播视频、短视频数字人 |
| SadTalker | 2023 | 全脸驱动技术里程碑 | 突破嘴型限制,实现嘴型+面部表情+头部姿势联动 | 经典开源项目、落地生态完善、全脸表达丰富 | 虚拟讲师、AI解说、非实时长视频制作 |
| LivePortrait | 2024 | 实时全脸驱动标杆 | 优化实时性与表情细节,支持眨眼、点头等自然微动作 | 低延迟、实时驱动、表情还原度高 | 虚拟人直播、实时互动、虚拟偶像、在线会议 |
| VASA-1 | 2024 | 影视级超逼真说话人生成 | 覆盖嘴型+表情+眼神+微动作+说话节奏,全维度拟人 | 效果以假乱真、突破恐怖谷效应 | 影视级数字人、高端虚拟助手(偏研究/高端落地) |
核心技术逻辑 :所有口型驱动模型均遵循"音频特征提取→面部特征匹配→动态帧生成→视频合成"的核心流程,差异在于特征覆盖的广度(仅嘴型/全脸/全维度)、生成的实时性、细节的还原度。
2. Wav2Lip:嘴型同步行业基准,入门首选
Wav2Lip是2020年推出的口型驱动模型,也是行业内嘴型与音频同步精度的标杆,至今仍是基础口播、配音修正的主流工具。其核心设计理念是"极致聚焦嘴型同步",舍弃复杂的面部表情,将所有算力与模型能力集中在嘴唇区域的跨模态对齐,实现近乎无误差的嘴型匹配。
输入静态图片/视频
S3FD人脸检测
人脸裁剪
下半脸遮挡
像素置0
输入音频
Mel频谱特征提取
GAN生成器
生成嘴部动态帧
画面拼接
输出口型同步视频
2.1 Wav2Lip核心原理
Wav2Lip采用**"遮挡-还原"的GAN对抗训练思路**,通过强制模型学习"根据音频特征还原被遮挡的嘴部区域",实现嘴型与音频的精准同步,核心分为三大关键步骤:
2.1.1 精准人脸检测与裁剪
模型通过face_detect()函数调用S3FD人脸检测模型(轻量级高精度人脸检测器),从输入的静态图片/视频帧中检测并裁剪出人脸区域;若未检测到人脸,模型会直接终止运行并抛出错误,人脸检测是后续所有操作的基础。
2.1.2 固定比例下半脸遮挡
对裁剪后的人脸图像进行机械性下半脸遮挡(将人脸下半部分像素置0),而非精准检测嘴唇区域,让模型无需学习嘴唇定位,直接聚焦"根据音频还原嘴部动态"的核心任务,简化模型学习难度,提升嘴型同步精度。
2.1.3 GAN对抗生成嘴型帧
Wav2Lip的核心网络是一款专用GAN模型,由生成器 和判别器组成:
- 生成器:融合音频Mel频谱特征与面部上半部分特征,生成匹配音频的嘴部动态帧;
- 判别器:判断生成的嘴部帧是否"真实",与真实视频帧对比优化模型,让生成的嘴型更自然。
2.2 Wav2Lip跨模态对齐核心设计
音频与视觉的跨模态对齐是口型驱动的核心难点,Wav2Lip通过声学启发规则+模仿学习+GAN模型优化,实现嘴型与音频的精准匹配:
- 声学启发规则:声音高频时让嘴型张大,声音低频时让嘴型闭合,建立音频频率与嘴型动作的基础关联;
- 模仿学习:以"真实视频帧+对应音频"为训练数据,让模型学习真实的嘴型-音频对应关系;
- GAN模型优化:通过生成器与判别器的持续博弈,优化嘴型生成的真实性与同步性。
2.3 Wav2Lip实战操作:一键生成口型同步视频
Wav2Lip开源项目开箱即用,无需复杂的模型调参,通过简单的命令行即可实现静态图片+音频→口型同步视频的转换,适配Windows、Linux、Mac全系统,以下是完整可运行的实战步骤:
2.3.1 步骤1:克隆项目仓库并进入目录
bash
# 克隆GitHub开源仓库
git clone https://github.com/Rudrabha/Wav2Lip.git
# 进入项目根目录
cd Wav2Lip2.3.2 步骤2:执行推理生成口型同步视频
核心调用inference.py脚本,指定模型权重、人脸素材、音频素材、输出路径即可,核心命令如下:
bash
python inference.py \
--checkpoint_path checkpoints/wav2lip_gan.pth \ # 模型权重文件(推荐GAN版,效果更自然)
--face "./virtual_person.png" \ # 输入虚拟人静态图片/视频路径
--audio "./virtual_voice.wav" \ # 输入匹配的音频文件路径(WAV/MP3均可)
--outfile "./lip_sync_video.mp4" \ # 输出口型同步视频路径
--static True \ # 输入为静态图片时设为True,固定人脸姿态
--fps 25 # 输出视频帧率,国内短视频/直播推荐25帧2.4 Wav2Lip核心使用技巧
- 输入图片建议为正面人脸照,避免大角度侧脸,否则会降低人脸检测与嘴型生成效果;
- 音频文件建议为无背景音的清晰语音,杂音会干扰音频特征提取,影响同步精度;
- 若生成视频出现嘴型模糊,可降低输入图片分辨率,或更换
wav2lip.pth基础版权重; - 处理长音频时,可将音频分段,生成后再拼接视频,提升运行效率。
3. LivePortrait:实时全脸驱动标杆,直播首选
LivePortrait是2024年由快手CVGI团队推出的面部动画驱动模型,是虚拟人实时交互场景的首选方案 。它在Wav2Lip、SadTalker的基础上,实现了低延迟实时驱动、超高精度全脸表情还原、自然的头部与微动作控制,彻底解决了传统模型"表情僵硬、延迟高、无法实时互动"的痛点,完美适配虚拟人直播、实时答疑、虚拟偶像互动等动态场景。
3.1 LivePortrait核心模块化设计
LivePortrait采用解耦式模块化设计,将"形象保留、动态提取、帧生成、画面优化"拆分为独立模块,各模块各司其职,既提升了模型的灵活性,又保证了生成效果的稳定性,六大核心模块的功能与作用如下:
3.1.1 外观特征提取器
从输入的虚拟人静态图片中提取身份特征(外貌embedding) ,核心作用是保证生成的视频全程保留原人物的形象一致性,避免出现"换脸""形象失真"问题。
3.1.2 运动特征提取器
从驱动视频中抽取面部表情、头部姿态、眨眼/点头等微动作的动态特征,是"让虚拟人脸动起来"的核心模块,决定了面部动态的丰富度与自然度。
3.1.3 图像变形模块
根据运动特征提取器输出的动态信息,对虚拟人的面部特征进行空间形变,让五官位置、面部肌肉随动态特征自然变化,实现表情与动作的精准匹配。
3.1.4 SPADE生成器
采用SPADE(空间自适应归一化) 结构,将变形后的面部特征重建成高清图像,核心作用是复原光照、纹理、细节,避免生成的视频出现模糊、失真、纹理丢失问题。
3.1.5 拼接/重定向模块
对所有生成帧的边缘进行时序平滑与空间拼接,防止视频出现画面闪烁、帧错位、边缘锯齿等问题;同时支持眼睛、嘴巴的单独重定向控制(如仅让虚拟人跟随驱动视频睁眼/张嘴)。
3.1.6 人脸关键点检测模型
轻量级ONNX模型,实时检测人脸68/106个关键点,为运动特征提取器提供精确的几何输入,保证动态特征提取的准确性。
3.2 LivePortrait核心训练流程
LivePortrait的训练分为两大阶段,分别聚焦"动态生成"与"效果优化",通过级联损失函数约束,实现形象一致性、表情还原度、画面流畅度的全方位提升:
3.2.1 第一阶段:外观与运动特征提取器训练
核心目标是让模型学会"从源图像提取身份特征、从驱动视频提取动态特征",通过人脸ID损失、引导损失、GAN对抗损失等,约束生成画面的身份一致性与动态自然度。
3.2.2 第二阶段:拼接与重定向模块训练
核心目标是优化画面的时序平滑度与跨人物驱动适配性,解决不同人物之间驱动时的表情错位、画面闪烁问题,同时实现眼睛、嘴巴的精细化单独控制。
3.3 LivePortrait实战操作:实时生成全脸动态视频
LivePortrait支持**"虚拟人静态图+驱动视频→全脸动态视频"** 的转换,可直接生成带表情、头部动作的口型同步视频,同时支持GPU加速,实时性拉满,以下是完整实战步骤:
3.3.1 步骤1:克隆项目仓库并安装依赖
bash
# 克隆GitHub开源仓库
git clone https://github.com/KwaiVGI/LivePortrait.git
# 进入项目根目录
cd LivePortrait
# 安装系统依赖(ffmpeg,用于音频/视频处理)
apt-get update -y && apt-get install -y ffmpeg
# 安装Python依赖
pip install -r requirements.txt3.3.2 步骤2:下载预训练权重
LivePortrait需要六大核心模块的预训练权重,可直接从官方仓库下载,放置在pretrained_weights/liveportrait/目录下,核心权重包括:
- appearance_feature_extractor.pth(外观特征提取器)
- motion_extractor.pth(运动特征提取器)
- warping_module.pth(图像变形模块)
- spade_generator.pth(SPADE生成器)
- stitching_retargeting_module.pth(拼接/重定向模块)
- landmark.onnx(人脸关键点检测模型)
3.3.3 步骤3:执行推理生成全脸动态视频
bash
python inference.py \
--source ./virtual_person.png \ # 输入虚拟人静态图片路径
--driving ./driver_video.mp4 \ # 输入驱动视频路径(含表情/动作参考)
--output-dir ./results \ # 输出结果保存目录
--device-id 0 \ # GPU设备ID,单卡设为0,CPU设为-1
--flag-crop-driving-video \ # 自动裁剪驱动视频中的人脸区域
--audio-priority driving # 输出视频保留驱动视频音频,保证音画同步配图6:LivePortrait实战效果展示图
(左侧:虚拟人静态原图;中间:驱动视频帧(真人表情);右侧:生成的虚拟人全脸动态帧,标注"表情/头部动作1:1还原")
3.4 LivePortrait实时直播适配技巧
- 驱动视频建议选择正面、表情自然、动作幅度适中的真人视频,避免夸张动作,否则会导致虚拟人表情失真;
- 实时直播时,可将驱动视频设置为循环播放,或通过摄像头实时采集真人动作作为驱动源,实现"真人操控虚拟人";
- 降低输入图片/驱动视频的分辨率(如512×512),可大幅提升推理速度,降低延迟,适配实时直播;
- 若出现头部动作僵硬,可调整模型的"姿态平滑系数",提升动作的自然度。
4. VASA-1:影视级超逼真说话人生成,前沿标杆
VASA-1是2024年由微软亚洲研究院推出的说话人生成模型,代表了当前虚拟人口型驱动与面部动画技术的前沿水平 。它突破了传统模型"仅关注嘴型/全脸"的限制,实现了嘴型+表情+眼神+微动作+说话节奏的全维度拟人化还原,生成效果几乎达到"以假乱真"的程度,彻底突破了"恐怖谷效应",是影视级数字人、高端虚拟助手的核心技术方案。
4.1 VASA-1核心技术架构
VASA-1采用**"统一归一化的运动潜空间扩散架构",将面部动态的生成转化为"运动潜变量的扩散去噪",核心分为 训练管线和测试管线**两部分,实现从"数据学习"到"端到端生成"的全流程闭环:
4.1.1 训练管线:学习面部动态的分布规律
以"真人说话视频"为训练数据,提取音频特征、人物身份特征、面部动态控制信号 ,通过运动潜空间扩散模型,学习真人说话时嘴型、表情、眼神、微动作的分布规律,训练模型生成匹配音频的面部运动潜变量。
4.1.2 测试管线:端到端生成超逼真说话人视频
输入单张虚拟人静态图片+一段音频 ,先通过编码器提取人物身份特征与音频特征,再通过训练好的扩散模型对运动潜变量进行去噪生成,最后将运动潜变量解码为面部动态帧,合成完整的、音画同步的超逼真说话人视频。
4.2 VASA-1的核心技术突破
相比Wav2Lip、LivePortrait,VASA-1的核心创新在于实现了全维度的拟人化还原,让虚拟人的说话动态与真人无异,四大核心突破如下:
4.2.1 精准的眼神还原
解决了传统模型"眼神空洞、死鱼眼"的痛点,能精准复刻真人说话时的眼神移动、眨眼频率、视线方向,甚至能还原"说话时看向镜头/侧方"的眼神变化,让虚拟人的眼神更有灵气。
4.2.2 细腻的微表情还原
能捕捉并还原真人说话时的面部微表情,如挑眉、嘴角微动、面部肌肉的细微收缩、鼻翼颤动等,这些细节让虚拟人的表情更自然,更贴近真人的表达习惯。
4.2.3 同步的说话节奏匹配
不仅实现嘴型与音频的同步,还能匹配真人说话时的头部微动、身体姿态变化、呼吸节奏,实现"语音-嘴型-表情-动作-呼吸"的全链路同步,让虚拟人的说话动态更具真实感。
4.2.4 超高清的画面生成
支持生成512×512分辨率、40fps的高清视频,画面的流畅度、纹理还原度、光照适配性远超传统模型,即使放大细节,也能保持画面的清晰与自然。
4.3 VASA-1的当前落地现状与未来方向
目前VASA-1仍偏研究展示阶段,暂未完全开源,模型的推理速度较慢、硬件要求极高(需高端GPU支持),暂时无法适配实时直播等轻量化场景,但它代表了虚拟人口型驱动技术的未来发展方向:
- 全维度拟人化:从"嘴型同步"向"嘴型+表情+眼神+微动作+说话节奏"的全维度还原发展;
- 低延迟实时化:通过模型蒸馏、轻量化优化,实现影视级效果的实时生成,适配直播、实时交互等场景;
- 多模态融合:结合语音情感、语义理解,让虚拟人的面部动态随语音情感、语义内容自动调整,实现"懂语义、会表达"的动态交互。
5. 三大核心模型的场景适配与技术选型
Wav2Lip、LivePortrait、VASA-1分别代表了口型驱动技术的基础级、实用级、前沿级 ,三者的能力、落地难度、硬件要求差异显著,在实际项目中,需根据落地场景、硬件资源、效果要求进行精准选型,避免盲目追求高端模型导致的资源浪费。
5.1 按落地场景选型
- 短视频口播/影视配音修正 :选Wav2Lip,嘴型同步精度高、开箱即用、硬件要求低,能满足基础的音画同步需求;
- 虚拟讲师/AI解说/非实时长视频 :选SadTalker,全脸表情丰富、落地生态完善,能提升虚拟人的表达效果;
- 虚拟人直播/实时互动/虚拟偶像 :选LivePortrait,低延迟、实时驱动、全脸动态自然,是当前实时场景的最优解;
- 影视级数字人/高端虚拟助手/品牌形象数字人 :选VASA-1(或其轻量化版),超逼真的拟人效果,能打造高端、沉浸式的用户体验。
5.2 按硬件资源选型
- 入门级硬件(普通电脑/低性能GPU) :选Wav2Lip,模型轻量、推理速度快,无需高端硬件支持;
- 中端硬件(游戏本/入门级专业GPU) :选LivePortrait,支持GPU加速,能实现实时推理,满足商业化落地需求;
- 高端硬件(专业服务器/旗舰级GPU) :可选VASA-1,满足影视级效果的生成需求,适合大厂/高端项目。
5.3 选型核心原则
"效果匹配需求,技术适配场景" ,不盲目追求最高端的模型,而是根据项目的实际需求(如是否需要实时、是否需要全脸表情、效果精度要求)选择最适配的方案,同时兼顾开发成本、硬件成本、落地效率。
6. 口型驱动技术与虚拟人全链路技术的联动
口型驱动并非独立的技术环节,而是虚拟人全链路技术的核心联动节点 ,需要与前期的形象生成、语音合成/声音克隆 ,以及后期的直播推流、交互系统深度融合,才能实现完整的虚拟人动态交互体验,核心联动流程如下:
6.1 与形象生成技术的联动
形象生成技术(Stable Diffusion+ControlNet)为口型驱动提供高质量的虚拟人静态形象,核心联动点:
- 生成的形象建议为正面、无遮挡、五官清晰的人脸照,提升人脸检测与口型生成效果;
- 通过ControlNet控制虚拟人的姿态(如坐姿、站姿),让口型驱动后的虚拟人保持固定姿态,适配直播/讲解场景。
6.2 与语音合成技术的联动
语音合成/声音克隆技术为口型驱动提供精准的音频素材,核心联动点:
- 音频的采样率、帧率需与口型驱动模型匹配(如25fps视频对应16kHz音频),避免音画不同步;
- 流式语音合成(ChatTTS)需与实时口型驱动模型(LivePortrait)联动,实现"边生成语音、边生成口型动态",满足实时交互需求。
6.3 与直播推流/交互系统的联动
口型驱动生成的动态视频,需通过直播推流工具(OBS/推流SDK)推流至直播平台,同时与大语言模型交互系统联动,实现**"用户提问→AI回答→语音合成→口型驱动→视频输出"** 的全流程闭环,让虚拟人能实时响应用户交互,实现真正的动态对话。
核心总结
口型驱动与面部动画技术,是虚拟人从"静态数字形象"到"动态交互分身"的关键桥梁,技术的迭代让虚拟人的动态表达越来越贴近真人:
- Wav2Lip是嘴型同步的行业基准,以极致的同步精度成为基础口播、配音修正的入门首选,开箱即用、成本极低;
- LivePortrait是实时全脸驱动的标杆,实现了低延迟、高还原的全脸表情与动作驱动,是当前虚拟人直播、实时交互的商业化最优解;
- VASA-1是影视级超逼真技术的前沿,实现了嘴型、表情、眼神、微动作的全维度拟人化还原,代表了未来的技术发展方向;
- 技术选型的核心是"效果匹配需求,技术适配场景",根据落地场景、硬件资源选择最适配的模型,同时注重与形象生成、语音合成、交互系统的全链路联动。
未来,口型驱动技术将朝着**"更实时、更逼真、更智能"** 的方向发展,结合大语言模型的语义理解与情感分析,让虚拟人的面部动态能随语义、情感自动调整,实现"懂话、会说、会表达"的真正拟人化交互。
拓展指引
下一篇:落地实战篇 | 虚拟人直播全流程:从形象制作到带货交互策略,将把虚拟人形象生成、AI大脑、语音合成、口型驱动的全链路技术整合,带你从零到一搭建可落地的虚拟人直播系统,同时拆解直播带货的核心交互策略与优化方案,实现虚拟人直播的商业化落地。