Skill
为什么要有?
Skills 出现之前的痛点
没有Skills的时候,你每次让Agent干一件稍微有点规范要求的活儿,都得从头把要求说一遍。
比如你要求"代码文件头部必须加上版权声明、函数命名用驼峰、异常处理要统一格式",你说了一次Agent记住了,下次新对话又忘了 。更要命的是,不同的人给Agent的指令不一样,同一个团队里10个人可能写出10种风格的代码来。
Skills就是来解决这个问题的:把这些反复出现的指令和规范固化成文件,让Agent每次都能自动读取,保证行为一致。
执行流程(原理)
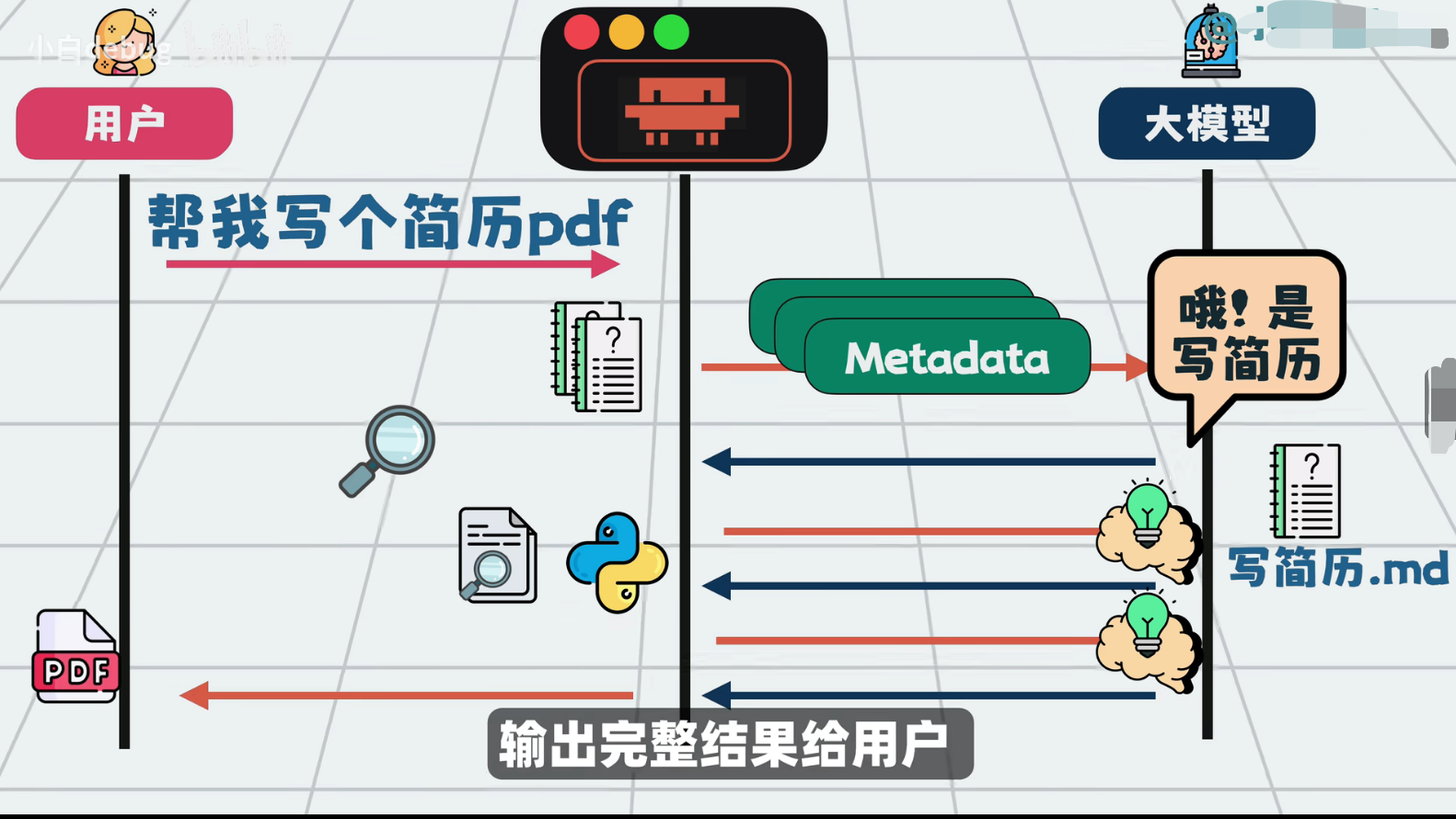
Skills的底层原理其实不复杂,本质上就是一种 Prompt注入机制 。在Agent执行任务之前,系统根据任务类型匹配合适的Skill文件,把文件内容注入到LLM的上下文中,相当于对话开始前先给AI"补课"。整个过程分三步走:
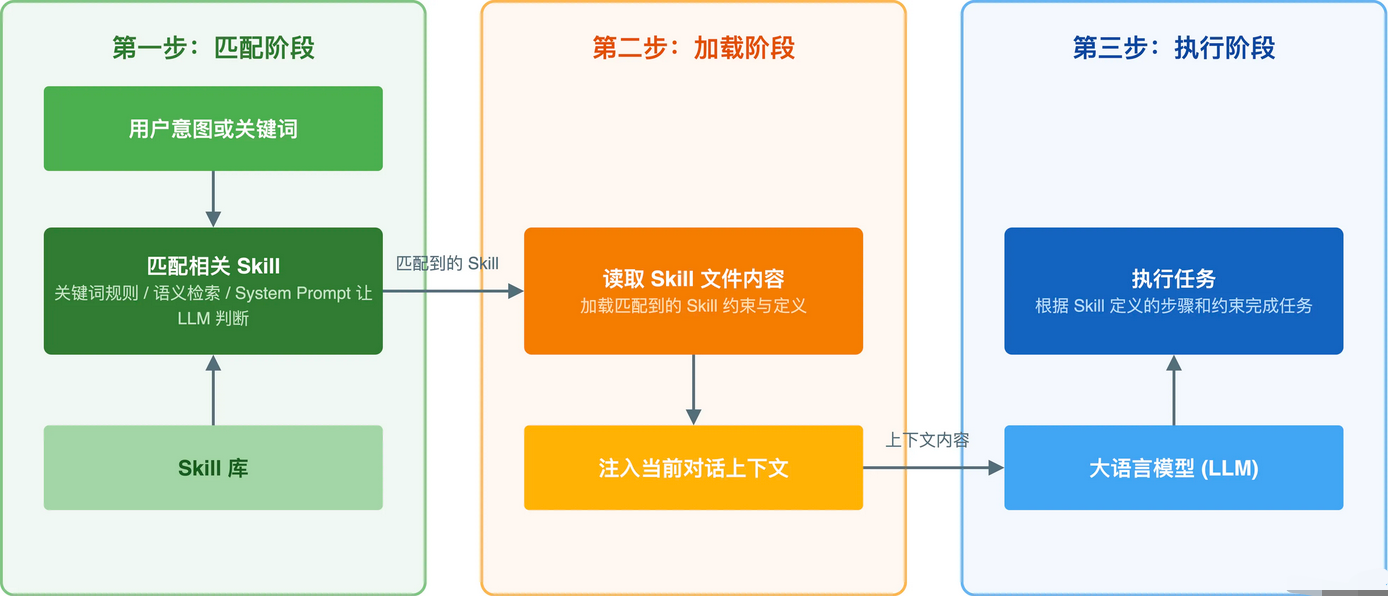
1.首先是匹配阶段,系统根据用户意图或关键词,从Skill库中找到相关的Skill匹配方式可以是关键词规则、语义检索,也可以直接在Agent的SystemPrompt里列出所有可用Skill让LLM 自己判断。
2.然后是加载阶段 ,读取匹配到的Skill文件内容,注入到当前对话的上下文中。
3.最后是执行阶段,LLM根据 Skill中定义的步骤和约束来完成任务。
应用
设计原则
写一个好的Skill跟写一个好的Prompt一样需要技巧:
1)一个Skill只解决一类问题,别把所有东西塞到一个文件里。"创建规则文件"和"修改编辑器配置"应该是两个独立的Skil
2)操作流程要清晰,每一步做什么、用什么工具都写明白,最好是编号列表
3**)明确定义输入参数和输出格式**,减少歧义
4)给出正确和错误的示例,比纯文字描述有效得多
5)Skill不是写完就不管了,要根据实际使用效果不断迭代优化
设计 Skills体系分三个层面来讲:
- 单个Skill怎么写、多个Skills怎么组织、上线后怎么维护。
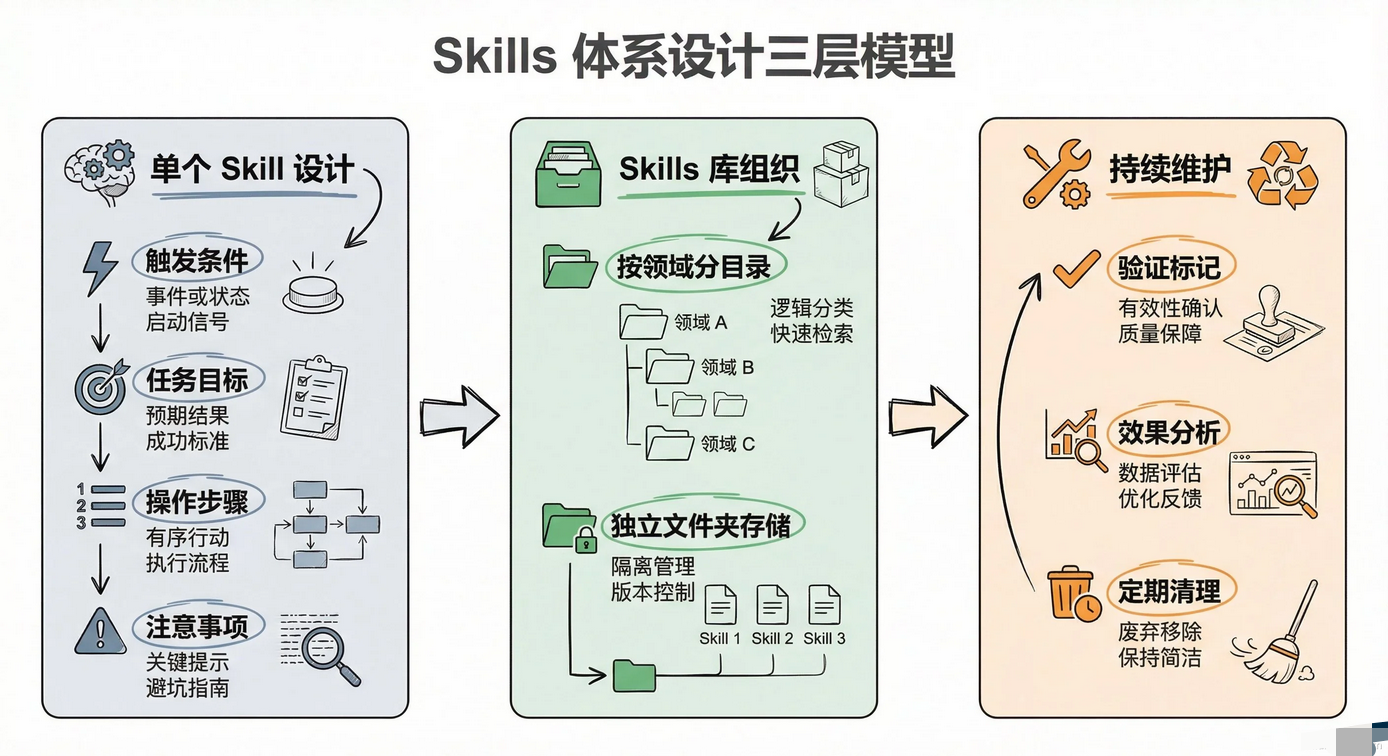
1)单个Skill至少要把四件事写清楚:什么时候触发、任务目标是什么、分步骤的操作流程要具体到每一步用什么工具传什么参数、边界情况和常见错误。最后这部分往往是从踩坑经验中提炼出来的,也是最值钱的。
2)当Skills数量上来之后,需要合理的目录结构。按领域分目录,每个Skill独立一个文件夹,里面放SKILL.md和可能需要的模板文件:
java
skills/
├── coding/
│ ├── create-api/
│ ├── code-review/
│ └── refactor/
├── devops/
│ ├── deploy/
│ └── monitoring/
└── project/
├── create-pr/
└── write-docs/Skills的匹配策略
Skills 匹配策略
当Skill库里有几十上百个Skills时,怎么高效匹配到对应的Skil就成了关键问题。
常见的匹配策略有三种。
关键词规则匹配
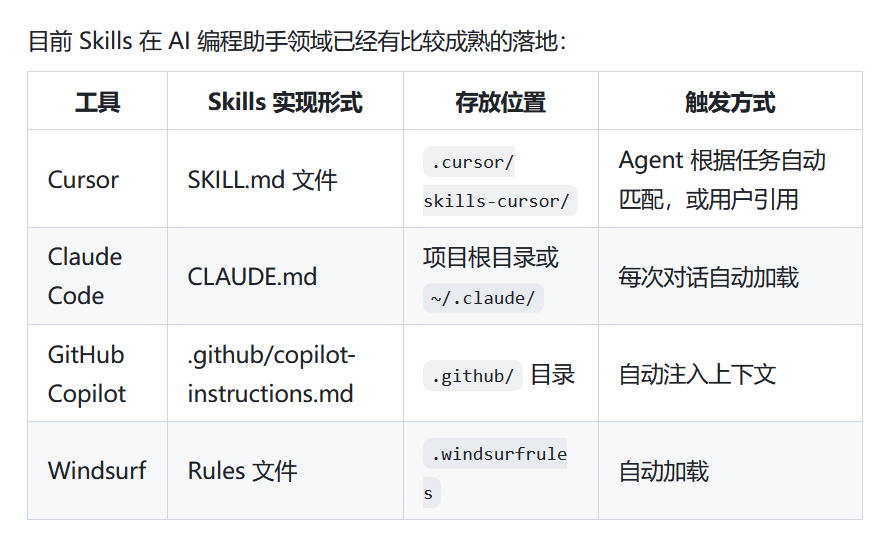
在Agent 的System Prompt中列出所有可用 Skills 的简短描述和触发关键词,让LLM自行判断是否需要加载某个Skill。Cursor 目前就是这么做的,在SystemPrompt里放一个Skills清单,每个条目包含名称、路径和一句话描述。实现简单但Skills数量多了之后会占用大量上下文窗口。
语义检索匹配
对所有Skill的描述信息做Embedding,当用户输入任务时,通过语义相似度检索最匹配的Skills。本质上就是把RAG的思路用在了Skill匹配上。可以支持大规模Skill库,但有检索准确率的问题,可能漏掉重要的Skill或者匹配到不相关的。
分层路由
先用一个轻量模型做粗筛,判断任务属于哪个大类 ,比如编码、运维、写作,再从对应类别下精确匹配具体的Skil。类似于搜索引擎的"先分类再检索",是目前比较有景的方案,能兼顾效率和准确率。
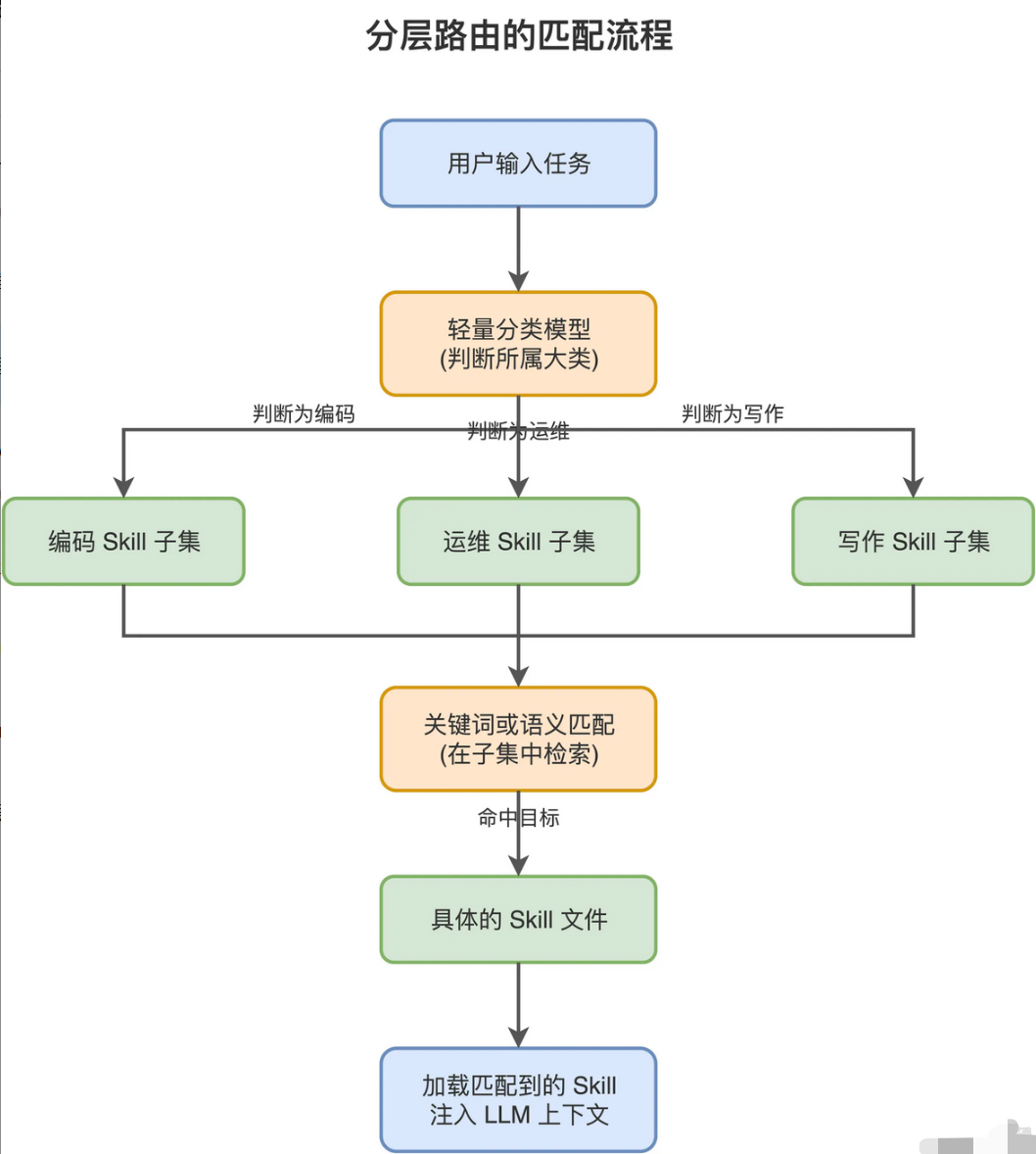
分层路由的匹配流程:用户输入任务后,先经过一个轻量分类模型,判断任务属于个个大类 ,如编码、运维、写作。然后在对应类别的Skill子集中,通过关键词或语义匹配找到具体的Skill文件 。最后加载匹配到的Skill注入LLM上下文。
Skill文件内容长时出现问题
如果Skil文件内容特别长,塞进上下文会不会有问题?
回答:肯定有问题。**LLM的上下文窗口是有限的,**比如Claude的上下文是200Ktoken,一个Skill文件如果写了好几千token,再加上用户的对话历史和系统提词,很容易把上下文撑满。
一般解决办法有两个:
- 一是控制Skill文件的长度,把非核心内容拆成子文件按需加载;
- 二是做分层加载,先加载一个精简版的摘要,Age 下判断需要更多细节时再加载完整内容 。Cursor 就是这么干的,鼓励你把大Skill拆分成多个小文件。
其他挑战
实际项目中的常见挑战
Skil冲突
当多个Skills同时被加载,且指令存在矛盾时,Agent会产生困惑 。比如一个Skill说"代码要加详细注释",另一个说"代码应该自解释,少写注释"。比较好的做法是设计优先级机制 ,项目级Skill优先于全局Skill,具体 Skill优先于通用Skil。也可以把Skill的作用域隔离。
Skill的时效性
技术更新很快,去年写的Skil里引用的API可能已经废弃了,推荐的依赖版本可能有安全漏洞。如果Agent按过时的Skill执行,产出的结果就有问题了。好的做法是给Skill加上版本号和最后更新日期,定期Review。对于变化快的领域,比如前端框架,可以在Skill里引用外部链接,不要硬编码具体版本号。
Skill效果评估
怎么衡量一个Skill好不好用?不像模型微调有Loss曲线可以看,Skill的效果更难量化。需要建立评估指标,比如任务完成率、用户修改率也就是Agent产出的结果被用户改了多少、执行步骤数等。收集足够多的数据后,持续迭代优化Skill内容。
Skill和RAG
Skills和RAG都是往上下文里塞内容,具体区别在哪?
- RAG检索的是知识片段 ,目的是让模型基于这些信息回答问题,属于"给AI喂资料"。Skills加载的是操作指令,目的是让模型按照固定流程执行任务,属于"给AI定规矩"。
- RAG的检索粒度通常是段落级别 ,一次可能检索5-10个相关文档片段;Skills通常是整份文件加载,一次加载1-2个Ski ll。另外RAG需要向量数据库做语义检索 ,Skills一般靠简单的关键词匹配或者让LLM自己选就够了。
和RAG本质区别
- RAG是检索知识片段,目的是回答问题
- Skill加载的是操作命令,目的是指导行动
SKill和MCP
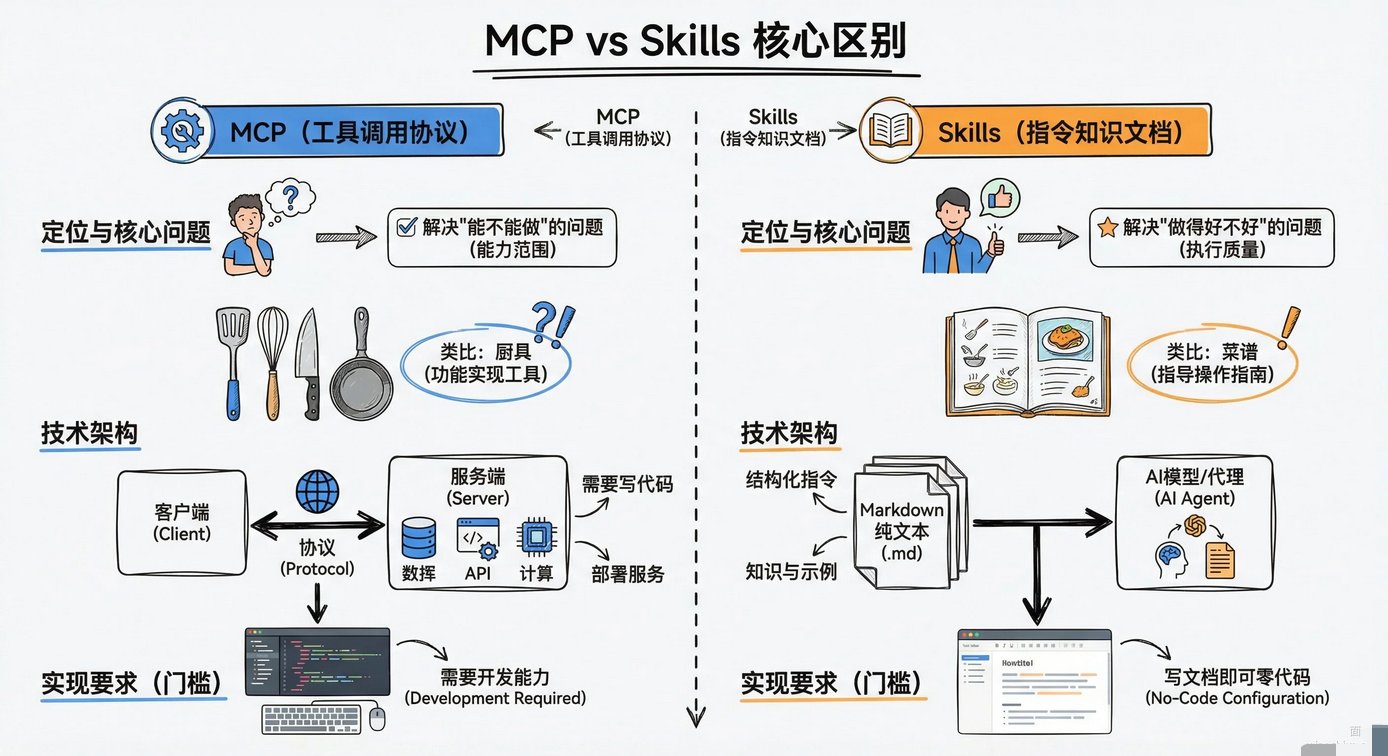

MCP给Agent提供"工具",Skills给Agent提供"方法论",两者解决的是完全不同层面的问题。
MCP全称Model Context Protocol,是一套标准化的工具调用协议 ,让AI Agent能调用外部服务。查数据库、调API、读文件系统 ,都是通过MCP来实现的。它解决的是Agent"能不能做"的问题。
Skills是一套指令文档 ,告诉Agent遇到某类任务应该怎么做、按什么顺序做、要注意什么。它解决的是Agent"会不会做"和"做得好不好"的问题。
【通俗易懂理解】
MCP相当于给厨师配了一套厨具,锅碗瓢盆、烤箱微波炉;
Skills相当于给厨师一本菜谱,红烧肉先焯水再上色,火候多大放多少料。光有工具不知道怎么用,做不出好菜;光有菜谱没有工具,也做不了饭。
【怎么选择】
给一个简单的判断标准:
- 1)想让Agent能做某件事,比如读数据库、发邮件、操作浏览器,上MCP
- 2)想让Agent把某件事做好 ,比如按照团队规范写代码、按标准流程做CodeReview, 上 Skills
- 3)大多数实际场景两者都需要,组合使用就对了


Skill和Function Calling
Function Calling和 MCP 类似,都是让 LLM能调用外部函数。
Skills 和 FunctionCalling处于不同层次:
Function Calling是能力层,管的是"能做什么";
Skills 是策略层,管的是"怎么做"。
Skill和Workflow
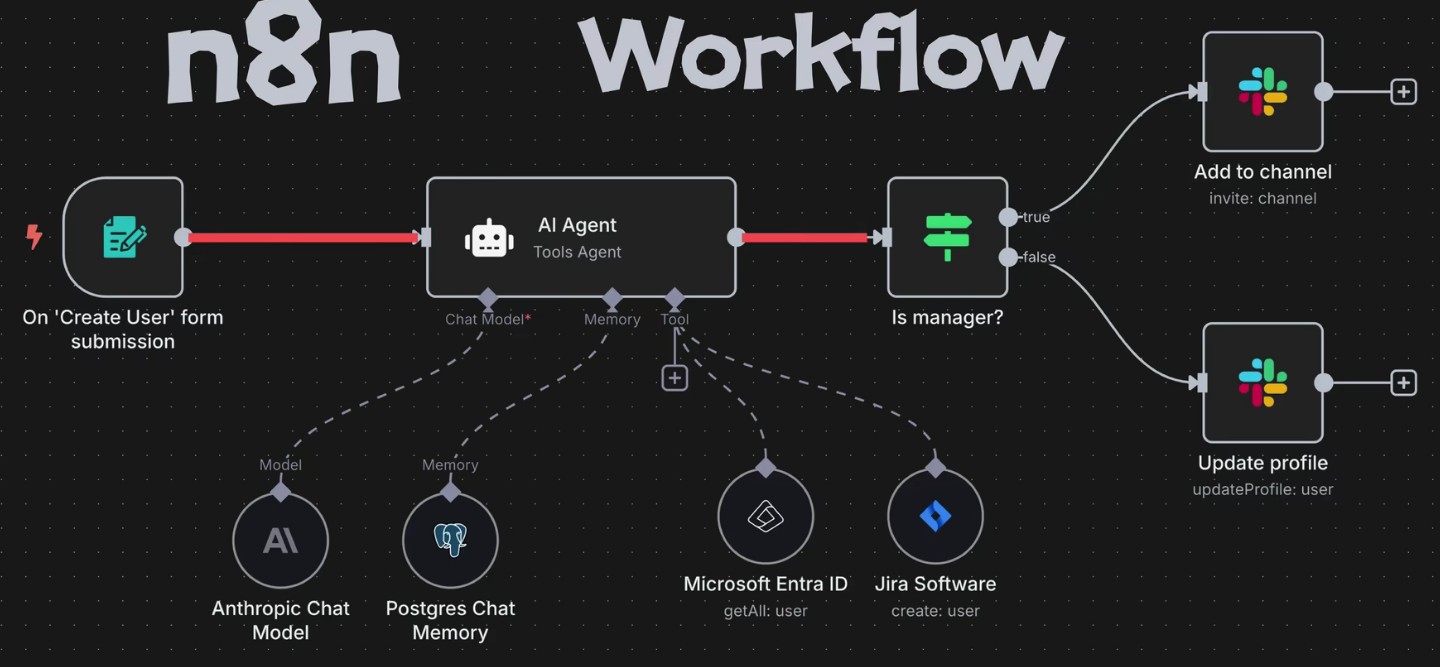
- Skill :是单个原子能力(一个工具 / 函数),只做一件具体的事,比如 "加法计算""查天气"。
- Workflow :是多个 Skill / 步骤的编排流程,按顺序 / 条件串联多个原子能力,完成复杂任务。