本文主要讨论索引。
索引,也就是目录;我们平时会使用目录直接定位到想要的位置,数据库也类似地通过索引直接定位到想要的数据。
什么是索引?
MySQL的索引是一种数据结构;索引通过一定的规则排列数据表中的记录,使得对表的查询可以通过对索引的搜索来加快速度。索引的查询会占用额外的存储空间。
索引的分类、创建与使用
1、主键索引(primary key)
当我们定义表时,会定义一个主键;而这个时候会自动创建一个索引,该索引就是主键索引;索引的值就是主键列的值。
主键索引是聚簇索引(innoDB),数据本身就和索引一起存在,叶子节点就是完整的数据行。
一张表只能有一个主键,那同样的,一张表也只能有一个主键索引。
主键索引的使用就是查询主键。例如我们创建id为主键,那么对id的查询也就是主键查询:
sql
-- 自动使用主键索引
SELECT * FROM user WHERE id = 100;如果在建表时没有创建主键,会自动找到唯一索引作为聚集索引。聚集索引我们在后面会谈到。
2、普通索引(normal index)
这是最基本的索引类型,没有唯一性的限制。
没有限制,也就是说,普通索引可以实现下面的事情:
- 字段值可以重复,也可以为NULL
- 一张表可以创建多个普通索引
创建普通索引时需要使用关键字index。
在创建索引时和视图比较类似,也是要起别名然后替代。例如我们在建表时:
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
-- 给 name 建普通索引
INDEX idx_name(name)
);这样就能为name字段添加普通索引。如果建表时没有追加index,也可以使用下面的方式来追加:
sql
CREATE INDEX idx_name ON user(name);之后在查询时遇到name字段就能自动使用普通索引了:
sql
-- 自动走普通索引 idx_name
--idk_name只是索引的名字,在查询时依然使用name字段
SELECT * FROM user WHERE name = '张三';3、唯一索引
唯一索引就是在普通索引的基础上加上唯一的约束(不能重复),但可以允许NULL。一张表也可以建多个唯一索引。
创建唯一索引时使用unique关键字:
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引
phone VARCHAR(20) UNIQUE, -- 唯一索引(自动创建)
name VARCHAR(50)
);或者像上面样起别名:
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
phone VARCHAR(20),
UNIQUE INDEX idx_phone(phone) -- 明确创建唯一索引
);当然也可以建表之后创建:
sql
CREATE UNIQUE INDEX idx_phone ON user(phone);使用方法也和之前的一样,在查询时自动使用:
sql
-- 自动走唯一索引
SELECT * FROM user WHERE phone = '13800138000';4、全文索引
全文索引用于查询部分关键字,有点像like关键字。
全文索引有以下特点:
- 只能用于文本字段(CHAR、VARCHAR、TEXT)
- 比like更快
- 一张表可以有多个
创建如下:
sql
CREATE TABLE article (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(100),
content TEXT,
-- 给 title + content 建全文索引
FULLTEXT INDEX ft_title_content(title, content)
);在查询时语法如下:
sql
SELECT * FROM article WHERE content LIKE '%数据库%';通过输入部分字符就能使用全文索引。这个查询方式就是全文索引。
5、复合索引
在上面的例子中,
sql
FULLTEXT INDEX ft_title_content(title, content)这条就是复合索引,即一个索引中包含了多个字段。
复合索引要满足最左前缀原则:复合索引必须从左到右依次使用。如果跳过了左边的字段,那么后面的字段就用不到索引。什么意思?如果我们在查询时:
sql
select * from user where content = 'exp';这行代码就直接跳过了title字段去查询后面的content字段,这样就会导致查询失败。
sql
select * from user where title = 'exp1';
select * from user where title = 'exp1' and content = 'exp2';这样的写法才能查询成功。
6、alter table添加索引
在表已经建立之后,还想添加索引除了使用create之外,还可以使用alter table:
添加普通索引
sql
ALTER TABLE 表名 ADD INDEX 索引名(字段名);添加唯一索引
sql
ALTER TABLE 表名 ADD UNIQUE INDEX 索引名(字段名);添加主键
sql
ALTER TABLE 表名 ADD PRIMARY KEY(字段名);因此,alter table不仅可以用来修改表结构,也可以添加索引。
7、聚集索引(聚簇索引)
主键索引就是聚集索引!
一张表有且仅有一个聚集索引;如果在创建表时没有创建主键,MySQL就会自动找到唯一索引,如果没有就会隐式创建一个 rowid 作为聚集索引。
若表中没有为表定义 PRIMARY KEY ,InnoDB会使用第一个 UNIQUE 和 NOT NULL 的列作为聚集索引;如果既没有 PRIMARY KEY ,也没有 UNIQUE 索引,InnoDB会为新插入的行生成一个行号并使用6字节的 ROW_ID 的字段记录,该字段是单调递增的,并使用该字段为索引。
8、非聚集索引
聚集索引之外的索引称为非聚集索引或者二级索引。
二级索引中的每条记录都包含该行的主键列,以及二级索引指定的列。
回表查询
先查普通索引后拿到主键,再去查主键索引搜索完整数据;这个第二次查询的过程就称为回表查询。
来看例子:
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 聚集索引
name VARCHAR(50),
INDEX idx_name(name) -- 普通索引(二级索引)
);当我们执行:
sql
SELECT * FROM user WHERE name = '张三';在这个过程中就发生了回表查询,当我们查询name时,会自动查询 idx_name 索引找到该行对应的 id ;再根据这个id进行主键索引,拿到整行数据。
在前面我们知道,主键索引的叶子结点存储的是整行数据;而普通索引的叶子节点存储的只是索引值 + 主键,不会存储完整数据。所以要想拿到想要的整行数据就需要再查一次主键索引。
索引覆盖
索引覆盖可以避免回表查询 。如果查询的字段全部在索引里 ,就不需要回表查询。例如:
sql
SELECT name FROM user WHERE name = '张三';因为在索引中已经有name了,因此可以直接返回而不回表查询。
关于回表
是否使用回表要考虑夹具体场景。在一般的使用中和不用避免回表,优缺点如下表:
| 方式 | 优点 | 缺点 |
|---|---|---|
| 回表(普通索引) | 索引小、省空间、增删改快 | 需要多一次查询,查询相比更慢 |
| 不回表(覆盖索引) | 查询更快 | 索引大、占空间、增删改慢 |
在普通的业务查询中使用回表是可行的。在高并发、大数据量和慢查询的情况下会考虑优化掉回表。
查看索引
'如果想查看创建的索引,使用 show index:
sql
SHOW INDEX FROM 表名;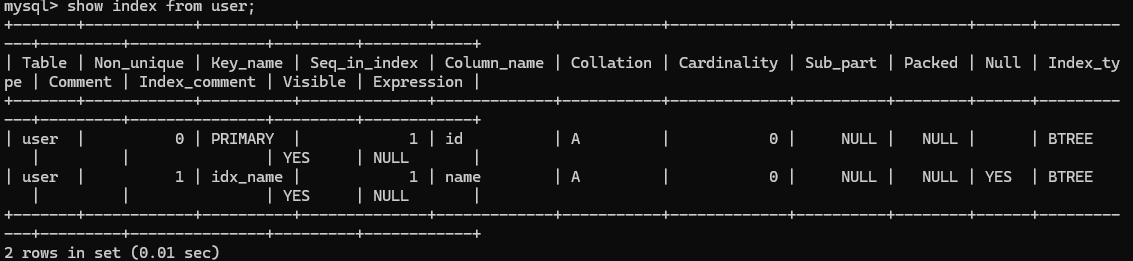
或者 show keys 也能查看:
sql
SHOW KEYS FROM 表名;也可以使用desc来查看:
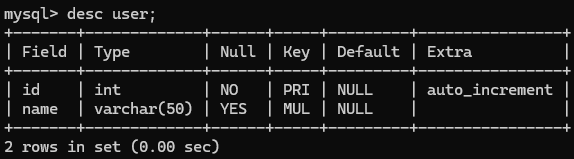
key下面的PRI就是主键索引,MUL就是普通索引。
- PRI:主键
- UNI:唯一
- MUL:普通
删除索引
最后来讲如何删除索引。删除的标准书写如下:
sql
DROP INDEX 索引名 ON 表名;例如在上面的例子中,我们在user表中为name创建了普通索引,删除的语法就如下:
sql
DROP INDEX idx_name ON user;不过需要注意的是,如果想要删除主键索引,语法和上面的不同。应该这么删:
sql
ALTER TABLE 表名 DROP PRIMARY KEY;因为主键只有一个,没有索引名。
在删除索引时一定要写的是索引的名字,而不是字段名!
不过在正常情况下,是不会删除主键索引的。只有在主键设计错误、表结构改变和导入数据批量优化时才会考虑删除主键索引。