前言
博主在一个医疗制造公司做IT,有一天,一个同事给我说,坏了,最近一批原材料又出问题了。我问她,为什么会出现这种问题,好像也不是第一次。她回答说,最近做了一个变更,但是负责的团队没有识别到这个物料的风险,所以忽略了这个物料的变更。我那时就在想,现在AI的发展,早就可以在这块领域提前发现风险,或者退一步来说,可以帮助发现风险。于是,我就产生了这个想法,做一个企业级的知识库协作平台,实现以下目标:
1、第一阶段完成知识库的搭建,支持上传文档到知识库,通过对话的方式完成对应知识的搜索与呈现
2、进一步扩充知识域,通过各个信息系统的集成,将物料主数据、BOM、技术图纸、注册文件、项目文档、生产文件、库存等信息全部集成起来,通过数据抽取和建模到知识库,形成一个围绕产品级别的知识库,不仅实现知识检索,同时可以基于规则设置、知识理解发现风险、预知风险或者提供建议
3、第三阶段我想更进一步,在左右的资料完善的情况下,可以完成智能写作/修改文档
1、第一版,使用WeKnora搭建一个初始版本
1.1 初试
我一开始使用的fastgpt来做向量搜索,但是每次搜索的内容确实差强人意。主要原因我分析是没有语义理解,而且,向量相似度的值每次还要去调整。后面刚好腾讯发布了WeKnora,我马上勾起了兴趣。
我的思路就变成了,通过WeKnora来搭建比较完整的企业知识库平台底座。具备"知识导入 + 检索问答 + Agent 扩展 + 多模型/多索引后端 + 前端管理界面"这一整套能力。
1.2 项目现在的主要框架
整体是前后端分离,核心分成 4 层:
前端:Vue 3 + Vite + Pinia + Vue Router,负责知识库管理、会话聊天、Agent、组织/设置等页面,入口在 main.ts 和 index.ts。
后端主服务:Go + Gin,负责 API、业务编排、权限、多租户、模型管理、知识库管理、会话问答,启动入口在 main.go。
文档解析服务:独立的 Python gRPC 服务 docreader,负责 PDF/Word/图片/URL/Markdown 等解析、OCR、多模态切块,入口在 main.py。
基础设施:Postgres、Redis、DocReader、Qdrant、MinIO、Neo4j、Jaeger 等通过 docker-compose.yml 组装起来。
后端内部又是比较标准的分层:
router:注册 API 路由
handler:接 HTTP 请求
service:业务主流程
repository:数据库/检索引擎访问
container:依赖注入装配
这一层的总装配在 container.go。
1.3 现在项目的主流程
最核心其实就两条:导入流程、问答流程。
1.3.1 知识导入流程
用户从前端上传文件、导入 URL,或者手工录入 Markdown。
后端在 knowledge.go 里先创建知识记录、保存原文件、做去重和配额校验。
然后把"文档处理任务"丢给 Asynq 异步队列,队列注册在 task.go。
异步任务 ProcessDocument 再调用 docreader 去解析文档、切 chunk、抽图片/OCR/结构信息。
解析后的 chunk 会落库,并调用 embedding 模型向量化,再写入检索引擎;如果开了图谱,也会写入图相关数据。
最终形成"原始文件 + chunk + 向量索引 + 可选图谱索引"的可检索知识。
这一条就是典型的"导入 -> 解析 -> 切块 -> 向量化 -> 建索引"。
1.3.2 检索问答流程
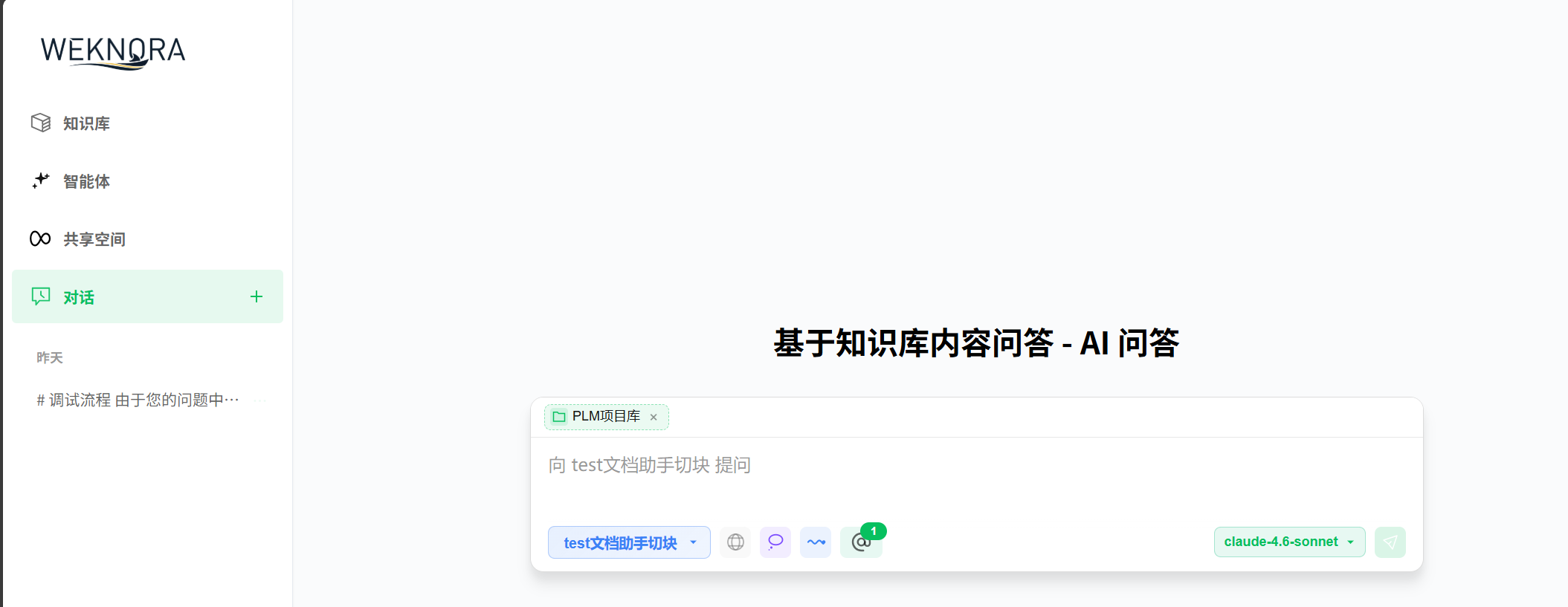
前端发起会话请求,后端走 session.go。
普通知识问答入口是 KnowledgeQA,Agent 模式入口是 AgentQA。
普通问答不是一坨代码直接写死的,而是走一个插件化 chat pipeline,在 chat_pipline.go。
pipeline 里会按阶段执行:
查询改写 rewrite
历史加载 load_history
检索 search
重排 rerank
合并上下文 merge
组装消息 into_chat_message
调大模型生成回答 chat_completion / chat_completion_stream
检索本身支持"知识库检索 + Web Search 并行",这部分在 search.go。
查询改写会结合历史对话,把"它/这个/上一个"这类省略信息补全,在 rewrite.go。
最后通过 SSE 流式把思考过程、工具调用、最终答案回给前端,session handler 里这块做得比较完整,在 handler/session 下面。
1.4 现在已经实现的主要功能
当前已具备这些能力:
- 多租户、用户、认证、组织/共享空间
- 知识库管理:创建、复制、删除、标签、共享
- 文档知识导入:文件、URL、手工 Markdown FAQ
- 知识库:FAQ 条目导入、相似问、批量管理
- 检索问答:知识搜索、知识问答、流式输出 Agent 模式:工具调用、MCP 集成、Web Search、技能系统
- 模型管理:聊天模型、Embedding、Rerank 模型统一管理
- 多种检索后端:Postgres/pgvector、Elasticsearch、Qdrant,代码上是可插拔的
- 图谱/实体关系相关能力:已经有实体抽取、关系抽取、GraphRAG 的铺垫
- 异步任务:文档处理、FAQ 导入、摘要/问题生成、知识库复制等
1.5 项目大致原理讲解
本质上还是一个增强版 RAG 平台,只是做得比普通 RAG 更完整:
文档理解:先通过 docreader 把复杂文档转成结构化 chunk
语义索引:用 embedding 模型把 chunk 向量化
混合检索:关键词检索 + 向量检索 + 可选图谱检索
重排过滤:用 rerank 提升召回精度
上下文拼装:把最相关片段组织成 prompt
大模型回答:让 LLM 基于检索结果作答
Agent 扩展:当不是纯问答,而是需要多步推理/调用工具时,切到 Agent 路径
1.6 演示效果
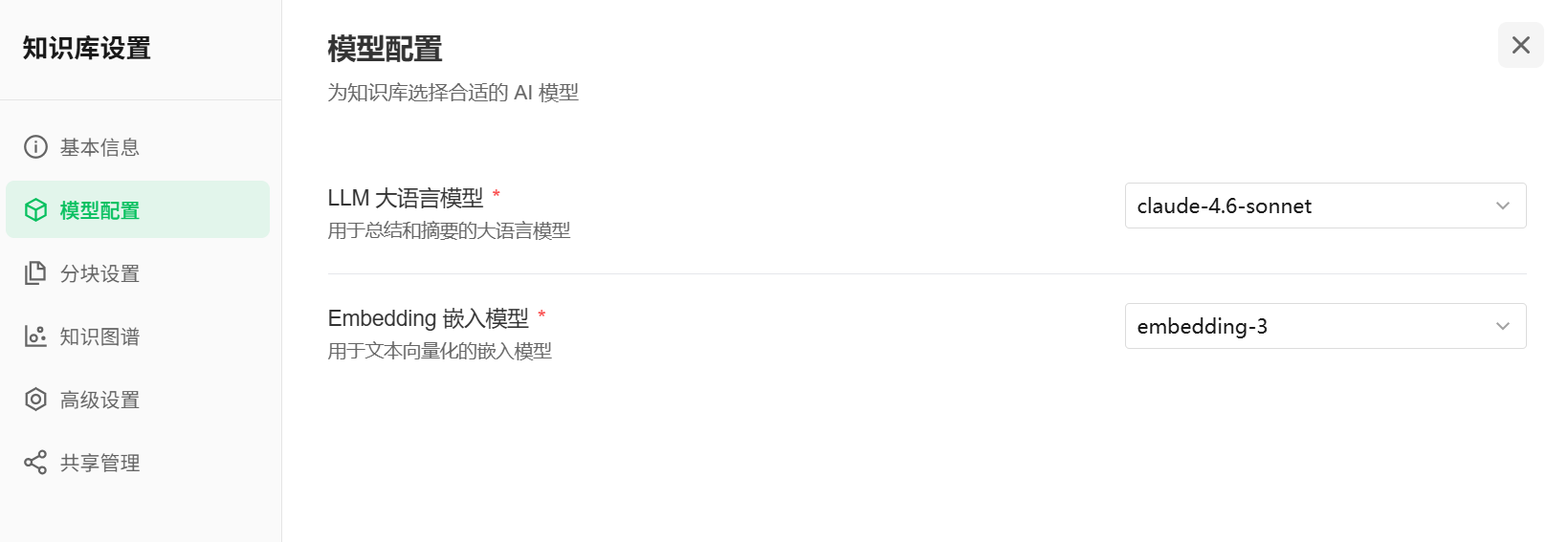
1)知识库模型配置:
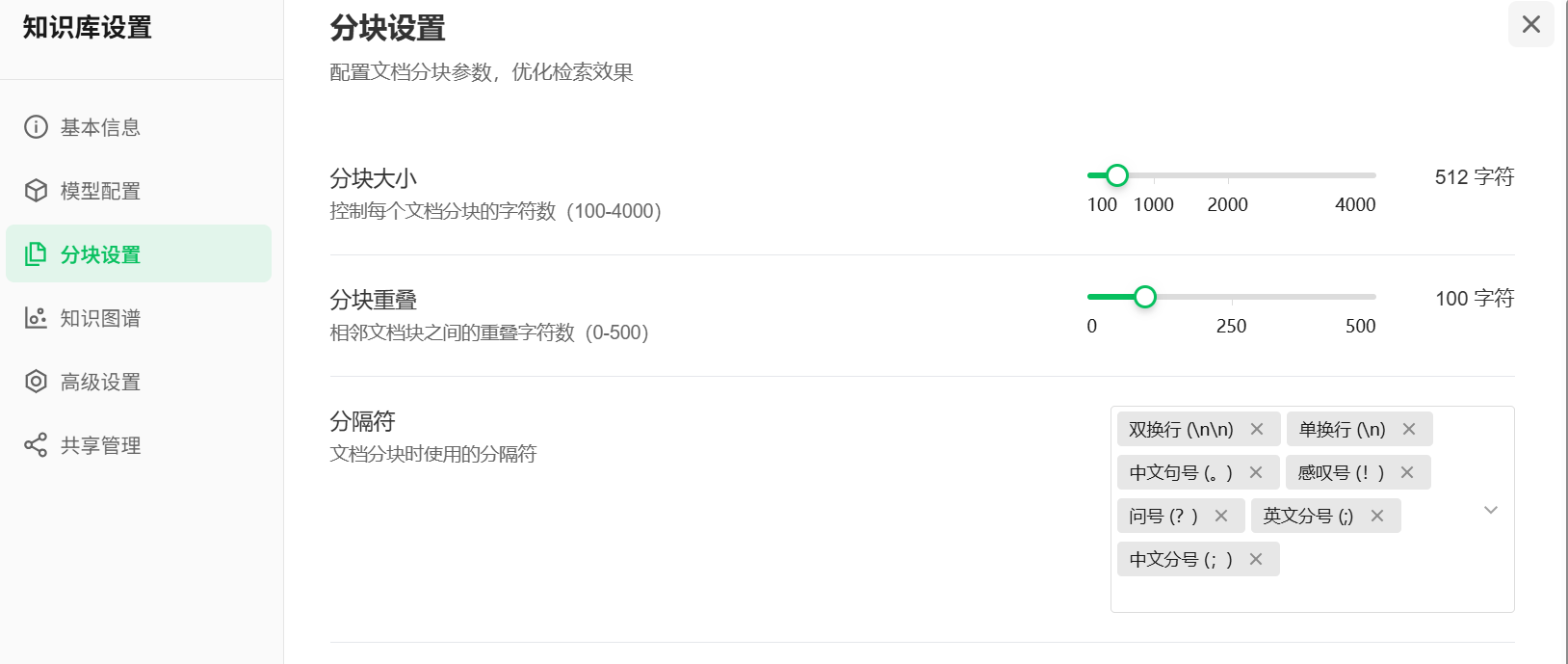
2)知识库分块设置:
3)智能体搭建
4)问答与知识库检索
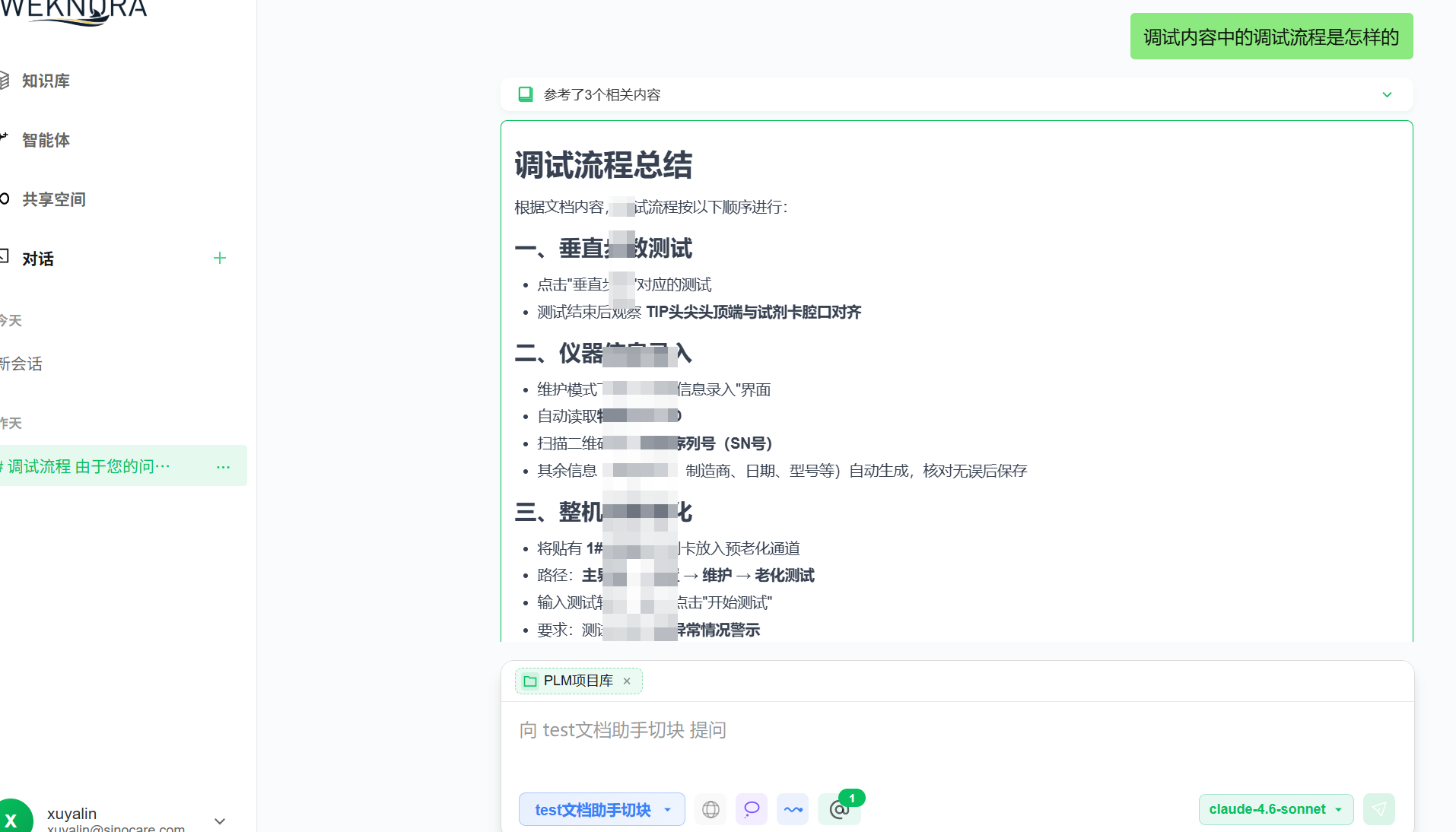
2 遇到一个有意思的问题
2.1 问题描述
上面大家可以看到,切块那里,都是按照指定符号或者分隔符来切割的,而实际我们的word是这样的:

和这样的:

所以,
1)如果用之前的章节去切块,首先我们的表格肯定是乱的,因为表格的首行首列一般都是标题,而表格的名称也一般是在表格前或者表格尾部位置,如果直接使用文字分隔符来切换,势必无法去理解表格的内容。
2)我们的word都是有章节的,而且不同章节之间的内容也是不同的,如果切块把不同章节内容放到一起,被我们检索到,用户会看到很多不需要的答案
2.2 我们来看看weknora初始的文档解析是怎么做的
2.2.1 总流程
上传文件 -> 创建 knowledge 记录 -> 异步任务 ProcessDocument -> 调 docreader.ReadFromFile -> docreader 选择 Word 解析器 -> 提取纯文本/图片 -> 按知识库 ChunkingConfig 切块 -> 后端把 chunk 落库 -> 调 embedding -> 写入检索引擎索引
2.2.2 入口:Word 文件什么时候开始被解析
用户上传 Word 后,后端先在 knowledge.go 的 CreateKnowledgeFromFile 里做几件事:
校验文件类型、重名/去重、配额
保存原始文件
创建一条 knowledge 记录,状态先是 pending
投递异步任务给 Asynq
真正开始解析是在同文件里的 ProcessDocument。这里会把文件内容读出来,然后调用 docReaderClient.ReadFromFile(...),并把当前知识库的切块配置一起传过去:
cpp
ChunkSize
ChunkOverlap
Separators
EnableMultimodal也就是这里决定了"一个 Word 切多大、重叠多少、优先按什么分隔符切"。这些参数来自知识库自己的 knowledgebase.go 里的 ChunkingConfig。
2.2.3 docreader 怎么识别 Word 并解析
docreader 的统一入口在 parser.py。
它按扩展名选解析器:
cpp
docx -> Docx2Parser
doc -> DocParser这里对 .docx 很关键的一点是:它不是只走一种解析方式,而是用 docx2_parser.py 定义的 FirstParser 链:
先用 MarkitdownParser
失败后再回退到 DocxParser
对应逻辑在 chain_parser.py。
所以 .docx 的策略其实是:
先试更通用的 markitdown 转文本/markdown
如果结果无效,再用项目自己写的 DocxParser
2.2.4 Word 文本到底是怎么抽出来的
.docx 的深度解析在 docx_parser.py。
它的主逻辑是:
读取 docx 二进制
用 Docx 处理器解析段落、表格、图片
把所有 section 的文本拼成一个大文本 text
同时收集图片信息,形成 document.images
如果复杂解析失败,还会 fallback 到 _parse_using_simple_method:
用 python-docx 直接遍历 paragraphs
再遍历 tables
把段落和表格文本拼起来
所以对一个 Word 文档来说,docreader 先做的是"抽取结构化文本内容",不是直接边读边索引。
.doc 则在 doc_parser.py 里,优先尝试:
转成 docx 再解析
不行就用 antiword
再不行用 textract
2.2.5 切块是在什么时候发生的
切块不是在 Go 后端做的,而是在 docreader 的 BaseParser.parse() 里统一做,代码在 base_parser.py。
流程是:
parse_into_text(content) 先把 Word 转成一个 Document
如果 document.chunks 为空,就进入统一切块逻辑
创建 TextSplitter(chunk_size, chunk_overlap, separators)
调 split_text(document.content)
得到 (start, end, text) 列表
转成标准 Chunk(seq, content, start, end)
这里用的切块器是 splitter.py。
2.2.6 TextSplitter 是怎么切的
这个切块器不是简单 substring,而是"递归分隔 + overlap 合并":
先按 separators 递归切
优先用大的分隔符,比如 \n\n、\n、。
如果某一段还是太长,再继续往下切
最后实在不行,退化到按字符切
核心逻辑:
_split():递归拆成不超过 chunk_size 的小片段
_merge():把这些小片段重新拼成 chunk,同时保留 chunk_overlap
_split_protected() / _join():尽量保护某些内容不要被切坏,比如:
Markdown 图片
链接
表格
数学公式
代码块
所以它的思路更像:
"先按语义边界拆散,再按 chunk size 重新拼装成最终块"。
2.2.7 TextSplitter 是怎么切的Word 文件切完块之后,后端怎么处理
docreader 返回的 chunk 会回到 Go 后端 ProcessDocument,然后调用 processChunks(...),代码也在 knowledge.go。
这里做的事情是:
先删掉旧的 chunks 和旧索引,避免重复数据
把 proto.Chunk 转成数据库里的 types.Chunk
文本 chunk 直接生成一条记录
如果 chunk 里还有图片,会额外拆出:
ImageOCR chunk
ImageCaption chunk
给文本 chunk 建前后关系 PreChunkID / NextChunkID
生成 indexInfoList
indexInfoList 的核心字段是:
cpp
Content
SourceID
ChunkID
KnowledgeID
KnowledgeBaseID也就是说,建索引的最小单位就是 chunk。
2.2.8 TextSplitter 是怎么切的建索引具体怎么做
建索引发生在 processChunks 末尾:
先 chunkService.CreateChunks(...) 把 chunk 落库
再 retrieveEngine.BatchIndex(ctx, embeddingModel, indexInfoList)
检索引擎是组合式的,实现在:
composite.go
keywords_vector_hybrid_indexer.go
BatchIndex 的逻辑是:
取每个 chunk 的 Content
调 embedding 模型批量向量化
把 SourceID -> embedding 组织起来
写入具体的索引后端
具体后端可以是:
cpp
PostgreSQL / pgvector
Elasticsearch
Qdrant所以"建索引"本质上就是:
"把 chunk 内容转 embedding,并把 chunk 元数据 + 向量一起写进检索后端"。
2.2.9 TextSplitter 是怎么切的如果是一个 Word 文件,最终会形成什么数据
以一个普通 .docx 为例,最终通常会生成三层数据:
原始文件记录 knowledge
多条文本块 chunk
对应 chunk 的索引项 indexInfo -> vector index
如果开启多模态,还会再多:
OCR chunk
图片 caption chunk
图片元信息
2.3 思路
2.3.1 初始思路
我觉得现在切块策略整体还是不能符合我的最终需求的,所以下一步我就在想:
现有 docx_parser -> base_parser -> splitter 链路中,哪里最适合注入章节化切块
怎样识别:
标题
条款编号
表格
目录
变更记录
附录
2.3.2 方案
整体思考:
最适合注入"章节化切块"的位置,不是在后端 knowledge.go,而是在 docreader 这一侧,优先放在 docx_parser -> base_parser 之间,具体说是:
文本结构识别放在 docx_parser.py
章节化切块编排放在 base_parser.py
splitter.py 保留为"兜底的二级切块器"
核心原则是:先做"结构识别和分段",再做"长度控制"。不要一上来就按通用 separator 切。
一、注入点
新增一层"结构化块构建器",位置在 BaseParser.parse() 里、调用 TextSplitter 之前。
现状大致是:
cpp
docx_parser.parse_into_text() 输出 Document(content, images)
base_parser.parse() 直接 TextSplitter.split_text(document.content)改成未来的设计链路:
cpp
docx_parser.parse_into_text() 输出 Document(content, images, structural_blocks?)base_parser.parse() 先判断是否有 structural_blocks
如果有,就先按结构块生成 chunk
单个结构块过大时,再调用 TextSplitter 做二次拆分
如果没有结构块,再走现有通用切块逻辑
这样有几个好处:
docx_parser 最了解 Word 原始结构,适合识别标题、表格、目录、附录
base_parser 适合做统一 chunk 编排,避免把章节逻辑写死在某一个 parser
splitter 继续负责超长块切分,不需要彻底推翻
所以职责建议是:
docx_parser:识别"这是什么块"
base_parser:决定"这些块怎么组 chunk"
splitter:解决"块太大怎么再切"
二、怎样识别这些结构
一开始先不追求 100% 语义模型识别,第一版用"样式 + 正则 + 局部规则"组合就够了。
标题
识别信号:
Word 段落样式名包含 Heading, 标题, Heading 1/2/3
字号更大、加粗、独立成段、上下空行明显
文本短且不以句号结尾
匹配编号标题:
1
1.1
1.1.1
第一章
一、
(一)
1)
输出:
cpp
block_type=heading
heading_level
heading_text
section_path
条款编号
识别信号:
段首正则:
^\d+(\.\d+){0,5}
^第[一二三四五六七八九十百]+[章节条款]
^[一二三四五六七八九十]+、
^([一二三四五六七八九十0-9]+)
^\([0-9a-zA-Z]+\)
Word 的编号列表属性
建议和标题区分:
标题通常短、独立
条款正文通常"编号 + 一整句/一整段"
可拆成:
clause_title
clause_body输出:
cpp
block_type=clause
clause_no
section_path表格
识别信号:
docx_parser 已经能拿到 tables,这里最适合直接结构化输出
每个表格作为一个独立 block,不建议先拍平成普通文本再让 splitter 切
建议表格保留三种表示:
原始二维结构 table_cells
行拼接文本 table_text
可索引摘要 table_summary_text
输出:
cpp
block_type=table
table_title
table_index
table_headers
row_count
col_count
目录识别信号:
标题为 目录
连续多行出现"标题 + 页码"模式
Word TOC 样式
行尾大量页码、点线、制表符
处理:
默认识别但不作为主要检索正文
可存储,但索引降权或默认不索引
输出:
cpp
block_type=toc
is_indexable=false
变更记录
识别信号:
标题包含:
修订记录
变更记录
版本记录
Revision History
Change Log紧随其后常见表格列:
版本号
日期
修订内容
修订人
审批人
处理建议:
识别为独立 section
允许单独索引,后续对"版本差异、法规变更、文件追溯"很有价值
输出:
cpp
block_type=change_log
version
effective_date
附录
识别信号:
附录
附录A/B/C
Appendix A
Annex I/II/III常伴随大段表格、术语、模板、样例
处理:
识别 section 边界
section_type=appendix
后续检索时可单独过滤
输出:
cpp
block_type=appendix_heading 或正文仍按 paragraph/clause/table
section_category=appendix三、新增的中间抽象
在 docreader 内部新增两层抽象,而不是直接把所有逻辑塞进 Chunk:
StructuralBlock
表示文档中的结构块,例如:
cpp
heading
clause
paragraph
table
toc
change_log
appendix字段:
cpp
id
block_type
text
start
end
page_no
heading_level
heading_text
clause_no
section_path
section_title
section_type
is_indexable
table_data
images
ChunkPlan表示"这个结构块最终如何生成 chunk"
比如:
标题单独成块
条款标题和后续一段合并
大表格单独块
超长正文再二次 splitter
这样后面可以逐步迭代策略,而不动最终存储结构。
四、chunk 建议增加哪些 metadata
建议优先把 metadata 加在 chunk 上,而不是一开始改索引表结构。
最值得加的字段:
cpp
chunk_type
text
heading
clause
table
toc
change_log
appendix
image_ocr
image_caption
section_path
例:1 > 1.2 > 1.2.3
section_level
标题层级
section_title
当前所属标题名
section_category
main_body
appendix
toc
change_log
clause_no
例:3.2.1
block_role
title
body
table
note
list_item
table_title
table_index
table_headers
table_row_count
table_col_count
version_tag对变更记录/制度文件很有用
cpp
is_indexable是否参与向量/关键词索引
cpp
importance可作为后续 rerank 或召回加权依据
cpp
source_style原 Word 样式名,便于调试和回溯
五、如何兼容现有索引结构
项目现在的索引主键逻辑是:
cpp
Content
SourceID
ChunkID
KnowledgeID
KnowledgeBaseID所以后续兼容方案分两层:
存储层兼容
不破坏现有 Chunk 主表和 IndexInfo 主流程。
做法:
chunk 仍然照常生成
新 metadata 先放到 Chunk 扩展字段里
索引仍按 IndexInfo.Content 建,不改核心接口
检索层渐进增强
在不改底层索引接口的前提下,先做两件事:
关键词/向量内容增强
IndexInfo.Content 不只放正文
可拼入轻量结构前缀,例如:
标题路径
条款号
表格标题
例:
章节: 3.2 灭菌流程\n条款: 3.2.1\n内容: ...
检索后过滤/加权
在数据库 chunk 记录中读 metadata
对 toc 降权
对 heading/clause/table/change_log 提权
对 appendix 可按场景决定是否参与
2.3.3 总之一句话:
第一版完全不改向量库 schema,只改"chunk metadata + 送去 embedding 的文本拼装方式 + 检索后排序逻辑"。