目录
引言与背景
深度强化学习(Deep Reinforcement Learning, DRL)作为人工智能领域最活跃的研究方向之一,成功将深度学习的表征能力与强化学习的决策框架相结合,在复杂环境中实现了超越人类的决策能力。从DeepMind的DQN在Atari游戏中的突破性表现,到OpenAI的PPO成为策略优化的事实标准,再到SAC在连续控制任务中的卓越性能,深度强化学习技术经历了从理论探索到工程实践的系统演进。
传统强化学习算法在面对高维状态空间时面临维度灾难问题:表格型方法(如Q-learning)无法存储和泛化大规模状态动作对的价值估计。深度神经网络的引入提供了强大的函数逼近能力,但同时也带来了训练不稳定性、样本效率低下、探索与利用权衡等新挑战。
本文聚焦深度强化学习技术演进的三大里程碑算法:深度Q网络(DQN) 、近端策略优化(PPO)和柔性演员-评论家(SAC)。我们将深入剖析每个算法的核心创新、架构设计与训练优化策略,提供关键数学推导与可运行的Python代码实现,帮助读者建立从理论到实践的完整知识体系。
注:本文假设读者已掌握强化学习基础概念(马尔可夫决策过程、价值函数、策略梯度),如需回顾请参阅本专栏前两篇《强化学习数学基础深度解析》与《经典强化学习算法对比》。
DQN原理深度解析
1. 从Q-learning到深度Q网络:解决维度灾难
传统Q-learning算法基于贝尔曼最优方程迭代更新动作价值函数:
Q ( s , a ) ← Q ( s , a ) + α r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) Q(s,a) \leftarrow Q(s,a) + \alpha \leftr + \\gamma \\max_{a'} Q(s',a') - Q(s,a)\\right Q(s,a)←Q(s,a)+αr+γa′maxQ(s′,a′)−Q(s,a)
对于高维状态空间(如图像输入),表格表示法变得不可行。DQN的核心创新是用深度神经网络 Q ( s , a ; θ ) Q(s,a;\theta) Q(s,a;θ)近似Q函数,其中 θ \theta θ为网络参数。
2. 经验回放(Experience Replay):打破数据相关性
传统Q-learning中,连续采样的状态转移 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)具有强时序相关性,导致神经网络训练不稳定。经验回放机制通过以下步骤解决这一问题:
- 存储经验 :将每个转移样本存入循环缓冲区 D D D(容量通常为 10 6 10^6 106)
- 随机采样 :训练时从 D D D中均匀采样小批量(如32个)转移
- 打破相关性:随机采样使样本近似独立同分布
数学上,DQN的损失函数定义为:
L ( θ ) = E ( s , a , r , s ′ ) ∼ U ( D ) ( r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ) 2 L(\theta) = \mathbb{E}_{(s,a,r,s')\sim U(D)} \left \\left( r + \\gamma \\max_{a'} Q(s',a';\\theta\^-) - Q(s,a;\\theta) \\right)\^2 \\right L(θ)=E(s,a,r,s′)∼U(D)(r+γa′maxQ(s′,a′;θ−)−Q(s,a;θ))2
其中 θ − \theta^- θ−为目标网络参数(见下文), U ( D ) U(D) U(D)表示从经验池均匀采样。
3. 目标网络(Target Network):稳定训练目标
在标准Q-learning中,TD目标 r + γ max a ′ Q ( s ′ , a ′ ; θ ) r + \gamma \max_{a'} Q(s',a';\theta) r+γmaxa′Q(s′,a′;θ)随网络参数 θ \theta θ实时变化,形成"移动靶"问题。DQN引入独立的目标网络 Q ( s , a ; θ − ) Q(s,a;\theta^-) Q(s,a;θ−),其参数定期从主网络复制(硬更新)或缓慢同步(软更新):
硬更新 :每 C C C步(如 C = 10000 C=10000 C=10000)执行 θ − ← θ \theta^- \leftarrow \theta θ−←θ
软更新 :每步执行 θ − ← τ θ + ( 1 − τ ) θ − \theta^- \leftarrow \tau\theta + (1-\tau)\theta^- θ−←τθ+(1−τ)θ−,其中 τ ≪ 1 \tau \ll 1 τ≪1
4. 网络架构与实现代码
DQN标准架构采用三层卷积神经网络处理Atari游戏图像输入(84×84×4):
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class DQN(nn.Module):
def __init__(self, input_shape, n_actions):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(input_shape[0], 32, kernel_size=8, stride=4)
self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2)
self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
conv_out_size = self._get_conv_out(input_shape)
self.fc1 = nn.Linear(conv_out_size, 512)
self.fc2 = nn.Linear(512, n_actions)
def _get_conv_out(self, shape):
o = self.conv1(torch.zeros(1, *shape))
o = self.conv2(o)
o = self.conv3(o)
return int(torch.prod(torch.tensor(o.size())))
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
return self.fc2(x)
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = []
self.capacity = capacity
self.position = 0
def push(self, state, action, reward, next_state, done):
if len(self.buffer) < self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
states, actions, rewards, next_states, dones = zip(*[self.buffer[idx] for idx in indices])
return (torch.stack(states), torch.tensor(actions), torch.tensor(rewards),
torch.stack(next_states), torch.tensor(dones))5. 算法变体:Double DQN与Dueling DQN
Double DQN:解决Q值过估计问题,使用两个网络分别选择动作和评估价值:
y = r + γ Q ( s ′ , arg max a ′ Q ( s ′ , a ′ ; θ ) ; θ − ) y = r + \gamma Q(s', \arg\max_{a'} Q(s',a';\theta); \theta^-) y=r+γQ(s′,arga′maxQ(s′,a′;θ);θ−)
Dueling DQN :分解Q值为状态价值 V ( s ) V(s) V(s)与动作优势 A ( s , a ) A(s,a) A(s,a):
Q ( s , a ; θ , α , β ) = V ( s ; θ , β ) + A ( s , a ; θ , α ) − 1 ∣ A ∣ ∑ a ′ A ( s , a ′ ; θ , α ) Q(s,a;\theta,\alpha,\beta) = V(s;\theta,\beta) + A(s,a;\theta,\alpha) - \frac{1}{|A|}\sum_{a'} A(s,a';\theta,\alpha) Q(s,a;θ,α,β)=V(s;θ,β)+A(s,a;θ,α)−∣A∣1a′∑A(s,a′;θ,α)
PPO算法架构分析
1. 策略梯度方法的挑战与PPO的创新
传统策略梯度方法(如REINFORCE)面临高方差与训练不稳定问题。PPO的核心目标是在提升策略性能的同时,约束更新幅度防止策略崩溃。
2. 裁剪目标函数(Clipped Surrogate Objective)
定义策略概率比 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),PPO的裁剪目标函数为:
L C L I P ( θ ) = E t min ( r t ( θ ) A \^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ t ) L^{CLIP}(\theta) = \mathbb{E}_t \left \\min\\left( r_t(\\theta) \\hat{A}_t, \\text{clip}(r_t(\\theta), 1-\\epsilon, 1+\\epsilon) \\hat{A}_t \\right) \\right LCLIP(θ)=Etmin(rt(θ)A\^t,clip(rt(θ),1−ϵ,1+ϵ)A\^t)
其中 ϵ \epsilon ϵ为裁剪阈值(通常设为0.2), A ^ t \hat{A}_t A^t为优势函数估计。
工作机制:
- 当优势 A ^ t > 0 \hat{A}_t > 0 A^t>0时,鼓励增加动作概率,但限制 r t ( θ ) ≤ 1 + ϵ r_t(\theta) \leq 1+\epsilon rt(θ)≤1+ϵ
- 当优势 A ^ t < 0 \hat{A}_t < 0 A^t<0时,鼓励减少动作概率,但限制 r t ( θ ) ≥ 1 − ϵ r_t(\theta) \geq 1-\epsilon rt(θ)≥1−ϵ
3. 广义优势估计(Generalized Advantage Estimation, GAE)
PPO采用GAE平衡优势估计的偏差与方差:
A ^ t G A E = ∑ l = 0 ∞ ( γ λ ) l δ t + l \hat{A}t^{GAE} = \sum{l=0}^{\infty} (\gamma\lambda)^l \delta_{t+l} A^tGAE=l=0∑∞(γλ)lδt+l
其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)为TD误差, λ ∈ 0 , 1 \lambda \in 0,1 λ∈0,1控制偏差-方差权衡。
4. 完整损失函数与实现代码
PPO的总损失函数包含三个部分:
L t C L I P + V F + S ( θ ) = E t L t C L I P ( θ ) − c 1 L t V F ( θ ) + c 2 S \[ π θ ( s t ) ] L_t^{CLIP+VF+S}(\theta) = \mathbb{E}_t \left L_t\^{CLIP}(\\theta) - c_1 L_t\^{VF}(\\theta) + c_2 S\[\\pi_\\theta(s_t) \right] LtCLIP+VF+S(θ)=EtLtCLIP(θ)−c1LtVF(θ)+c2S\[πθ(st)]
- L t C L I P L_t^{CLIP} LtCLIP:裁剪策略损失(系数1.0)
- L t V F L_t^{VF} LtVF:价值函数均方误差(系数 c 1 = 0.5 c_1=0.5 c1=0.5)
- S π θ S\\pi_\\theta Sπθ:策略熵奖励(系数 c 2 = 0.01 c_2=0.01 c2=0.01)
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
class PPO:
def __init__(self, actor_critic, clip_param=0.2, ppo_epoch=4, lr=3e-4):
self.actor_critic = actor_critic
self.clip_param = clip_param
self.ppo_epoch = ppo_epoch
self.optimizer = optim.Adam(actor_critic.parameters(), lr=lr)
def update(self, rollouts):
advantages = rollouts.returns[:-1] - rollouts.value_preds[:-1]
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-5)
for e in range(self.ppo_epoch):
data_generator = rollouts.feed_forward_generator(advantages)
for sample in data_generator:
obs_batch, actions_batch, old_log_probs_batch, adv_targ, return_batch = sample
# 评估当前策略
values, action_logits = self.actor_critic(obs_batch)
dist = Categorical(logits=action_logits)
action_log_probs = dist.log_prob(actions_batch)
entropy = dist.entropy().mean()
# 计算概率比
ratio = torch.exp(action_log_probs - old_log_probs_batch)
# 裁剪目标
surr1 = ratio * adv_targ
surr2 = torch.clamp(ratio, 1.0 - self.clip_param, 1.0 + self.clip_param) * adv_targ
policy_loss = -torch.min(surr1, surr2).mean()
# 价值损失
value_loss = (return_batch - values).pow(2).mean()
# 总损失
loss = policy_loss + 0.5 * value_loss - 0.01 * entropy
# 优化
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()5. 训练稳定性技巧
PPO的工程实现包含多项稳定性增强措施:
- 优势归一化:减去均值除以标准差,减少梯度爆炸风险
- 奖励裁剪:限制奖励值范围,防止异常值干扰
- 值函数裁剪:防止价值网络过度拟合
- 梯度裁剪:限制梯度范数(如max_norm=0.5)
SAC框架实现详解
软演员-评论家(Soft Actor-Critic, SAC)是深度强化学习领域的重要突破,首次将最大熵原理系统性地引入连续控制任务,在样本效率和策略稳定性方面展现出卓越性能。相比确定性策略算法(如DDPG、TD3),SAC的随机策略设计天然具备探索能力,避免了手动设计噪声衰减策略的复杂性。
1. 最大熵强化学习框架
传统强化学习的目标是最大化期望累积奖励:
J ( π ) = E τ ∼ π ∑ t = 0 ∞ γ t r ( s t , a t ) J(\pi) = \mathbb{E}_{\tau \sim \pi} \left \\sum_{t=0}\^{\\infty} \\gamma\^t r(s_t, a_t) \\right J(π)=Eτ∼πt=0∑∞γtr(st,at)
最大熵强化学习在此基础上增加熵正则项,鼓励策略保持随机性:
J ( π ) = E τ ∼ π ∑ t = 0 ∞ γ t ( r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ) J(\pi) = \mathbb{E}_{\tau \sim \pi} \left \\sum_{t=0}\^{\\infty} \\gamma\^t \\left( r(s_t, a_t) + \\alpha \\mathcal{H}(\\pi(\\cdot\|s_t)) \\right) \\right J(π)=Eτ∼πt=0∑∞γt(r(st,at)+αH(π(⋅∣st)))
其中 α > 0 \alpha > 0 α>0是温度参数,控制探索与利用的权衡; H ( π ( ⋅ ∣ s ) ) = − E a ∼ π ( ⋅ ∣ s ) log π ( a ∣ s ) \mathcal{H}(\pi(\cdot|s)) = -\mathbb{E}_{a \sim \pi(\cdot|s)}\\log \\pi(a\|s) H(π(⋅∣s))=−Ea∼π(⋅∣s)logπ(a∣s)是策略的条件熵。
熵的直观理解:
- 高熵策略:动作分布接近均匀,探索性强
- 低熵策略:动作分布集中,利用性强
最大熵框架的三大优势:
- 自动探索 :不需要手动设计 ϵ \epsilon ϵ-贪婪或OU噪声
- 鲁棒性:随机策略对环境扰动不敏感
- 多模态表达:能同时学习多个最优动作
2. 软价值函数与软贝尔曼方程
在最大熵框架下,需要重新定义价值函数。软动作价值函数(Soft Q-function)包含未来熵的期望:
Q soft ( s t , a t ) = r ( s t , a t ) + E τ ∼ π ∑ l = 1 ∞ γ l ( r ( s t + l , a t + l ) + α H ( π ( ⋅ ∣ s t + l ) ) ) Q_{\text{soft}}(s_t, a_t) = r(s_t, a_t) + \mathbb{E}_{\tau \sim \pi} \left \\sum_{l=1}\^{\\infty} \\gamma\^l \\left( r(s_{t+l}, a_{t+l}) + \\alpha \\mathcal{H}(\\pi(\\cdot\|s_{t+l})) \\right) \\right Qsoft(st,at)=r(st,at)+Eτ∼πl=1∑∞γl(r(st+l,at+l)+αH(π(⋅∣st+l)))
软状态价值函数(Soft Value Function)定义为:
V soft ( s t ) = E a t ∼ π Q soft ( s t , a t ) − α log π ( a t ∣ s t ) V_{\text{soft}}(s_t) = \mathbb{E}_{a_t \sim \pi} \left Q_{\\text{soft}}(s_t, a_t) - \\alpha \\log \\pi(a_t\|s_t) \\right Vsoft(st)=Eat∼πQsoft(st,at)−αlogπ(at∣st)
由此导出软贝尔曼方程:
Q soft ( s t , a t ) = r ( s t , a t ) + γ E s t + 1 ∼ p V soft ( s t + 1 ) Q_{\text{soft}}(s_t, a_t) = r(s_t, a_t) + \gamma \mathbb{E}{s{t+1} \sim p} \left V_{\\text{soft}}(s_{t+1}) \\right Qsoft(st,at)=r(st,at)+γEst+1∼pVsoft(st+1)
这是SAC算法的理论基础,确保了策略迭代的收敛性。
3. SAC网络架构设计
SAC采用经典的演员-评论家(Actor-Critic)架构,但包含多项创新设计:
3.1 演员网络(Actor Network)
演员网络 π ϕ \pi_\phi πϕ输出动作分布的参数。对于连续动作空间,通常采用对角高斯分布:
a = tanh ( μ ϕ ( s ) + σ ϕ ( s ) ⊙ ϵ ) , ϵ ∼ N ( 0 , I ) a = \tanh(\mu_\phi(s) + \sigma_\phi(s) \odot \epsilon), \quad \epsilon \sim \mathcal{N}(0, I) a=tanh(μϕ(s)+σϕ(s)⊙ϵ),ϵ∼N(0,I)
其中 μ ϕ ( s ) \mu_\phi(s) μϕ(s)和 log σ ϕ ( s ) \log \sigma_\phi(s) logσϕ(s)是网络输出的均值和标准差的对数。 tanh \tanh tanh函数将动作压缩到 − 1 , 1 -1, 1 −1,1范围。
**重参数化技巧(Reparameterization Trick)**是关键创新:
- 传统策略梯度: ∇ ϕ J ( ϕ ) = E a ∼ π ϕ ∇ a Q ( s , a ) ∇ ϕ π ϕ ( a ∣ s ) \nabla_\phi J(\phi) = \mathbb{E}{a \sim \pi\phi} \left \\nabla_a Q(s,a) \\nabla_\\phi \\pi_\\phi(a\|s) \\right ∇ϕJ(ϕ)=Ea∼πϕ∇aQ(s,a)∇ϕπϕ(a∣s),方差大
- 重参数化后: ∇ ϕ J ( ϕ ) = E ϵ ∼ N ( 0 , I ) ∇ a Q ( s , a ) ∇ ϕ f ϕ ( s , ϵ ) \nabla_\phi J(\phi) = \mathbb{E}_{\epsilon \sim \mathcal{N}(0,I)} \left \\nabla_a Q(s,a) \\nabla_\\phi f_\\phi(s, \\epsilon) \\right ∇ϕJ(ϕ)=Eϵ∼N(0,I)∇aQ(s,a)∇ϕfϕ(s,ϵ),方差小
这里 f ϕ ( s , ϵ ) = tanh ( μ ϕ ( s ) + σ ϕ ( s ) ⊙ ϵ ) f_\phi(s, \epsilon) = \tanh(\mu_\phi(s) + \sigma_\phi(s) \odot \epsilon) fϕ(s,ϵ)=tanh(μϕ(s)+σϕ(s)⊙ϵ)是可导函数。
3.2 评论家网络(Critic Networks)
SAC采用双Q网络结构抑制过高估计:
- Q θ 1 ( s , a ) Q_{\theta_1}(s,a) Qθ1(s,a):第一个Q网络
- Q θ 2 ( s , a ) Q_{\theta_2}(s,a) Qθ2(s,a):第二个Q网络
目标值计算取两者最小值:
y = r + γ ( min i = 1 , 2 Q θ ˉ i ( s ′ , a ′ ) − α log π ϕ ( a ′ ∣ s ′ ) ) , a ′ ∼ π ϕ ( ⋅ ∣ s ′ ) y = r + \gamma \left( \min_{i=1,2} Q_{\bar{\theta}i}(s', a') - \alpha \log \pi\phi(a'|s') \right), \quad a' \sim \pi_\phi(\cdot|s') y=r+γ(i=1,2minQθˉi(s′,a′)−αlogπϕ(a′∣s′)),a′∼πϕ(⋅∣s′)
其中 θ ˉ i \bar{\theta}_i θˉi是目标网络参数。
3.3 目标网络与软更新
目标网络通过软更新(Soft Update)缓慢追踪主网络:
θ ˉ i ← τ θ i + ( 1 − τ ) θ ˉ i , i = 1 , 2 \bar{\theta}_i \leftarrow \tau \theta_i + (1-\tau)\bar{\theta}_i, \quad i=1,2 θˉi←τθi+(1−τ)θˉi,i=1,2
典型设置 τ = 0.005 \tau = 0.005 τ=0.005,确保训练稳定性。
4. 自动温度调整机制
温度参数 α \alpha α控制熵奖励的重要性。手动调优 α \alpha α困难,SAC引入可学习的 α \alpha α。
优化目标:保持策略熵接近目标值 H 0 H_0 H0(通常设为 − dim ( A ) -\dim(\mathcal{A}) −dim(A)):
min α E s ∼ D − α ( log π ϕ ( a ∣ s ) + H 0 ) \min_\alpha \mathbb{E}_{s \sim \mathcal{D}} \left -\\alpha \\left( \\log \\pi_\\phi(a\|s) + H_0 \\right) \\right αminEs∼D−α(logπϕ(a∣s)+H0)
对应的梯度更新:
∇ α J ( α ) = E s ∼ D , a ∼ π ϕ − ( log π ϕ ( a ∣ s ) + H 0 ) \nabla_\alpha J(\alpha) = \mathbb{E}{s \sim \mathcal{D}, a \sim \pi\phi} \left -\\left( \\log \\pi_\\phi(a\|s) + H_0 \\right) \\right ∇αJ(α)=Es∼D,a∼πϕ−(logπϕ(a∣s)+H0)
工作机制:
- 当策略熵 − E log π ( a ∣ s ) > H 0 -\mathbb{E}\\log \\pi(a\|s) > H_0 −Elogπ(a∣s)>H0时:梯度为负, α \alpha α减小,降低探索
- 当策略熵 − E log π ( a ∣ s ) < H 0 -\mathbb{E}\\log \\pi(a\|s) < H_0 −Elogπ(a∣s)<H0时:梯度为正, α \alpha α增大,增强探索
5. 完整损失函数与训练流程
5.1 评论家损失
对于每个Q网络 θ i \theta_i θi,最小化软贝尔曼误差:
L Q ( θ i ) = E ( s , a , r , s ′ ) ∼ D ( Q θ i ( s , a ) − y ) 2 \mathcal{L}Q(\theta_i) = \mathbb{E}{(s,a,r,s') \sim \mathcal{D}} \left \\left( Q_{\\theta_i}(s,a) - y \\right)\^2 \\right LQ(θi)=E(s,a,r,s′)∼D(Qθi(s,a)−y)2
5.2 演员损失
最大化期望回报加熵:
L π ( ϕ ) = E s ∼ D α log π ϕ ( a ∣ s ) − min i = 1 , 2 Q θ i ( s , a ) , a ∼ π ϕ ( ⋅ ∣ s ) \mathcal{L}\pi(\phi) = \mathbb{E}{s \sim \mathcal{D}} \left \\alpha \\log \\pi_\\phi(a\|s) - \\min_{i=1,2} Q_{\\theta_i}(s,a) \\right, \quad a \sim \pi_\phi(\cdot|s) Lπ(ϕ)=Es∼Dαlogπϕ(a∣s)−i=1,2minQθi(s,a),a∼πϕ(⋅∣s)
实际实现时,通过重参数化计算梯度:
∇ ϕ L π ( ϕ ) = E s ∼ D , ϵ ∼ N ( 0 , I ) ∇ a min i = 1 , 2 Q θ i ( s , a ) ∇ ϕ f ϕ ( s , ϵ ) − α ∇ ϕ log π ϕ ( a ∣ s ) \nabla_\phi \mathcal{L}\pi(\phi) = \mathbb{E}{s \sim \mathcal{D}, \epsilon \sim \mathcal{N}(0,I)} \left \\nabla_a \\min_{i=1,2} Q_{\\theta_i}(s,a) \\nabla_\\phi f_\\phi(s, \\epsilon) - \\alpha \\nabla_\\phi \\log \\pi_\\phi(a\|s) \\right ∇ϕLπ(ϕ)=Es∼D,ϵ∼N(0,I)∇ai=1,2minQθi(s,a)∇ϕfϕ(s,ϵ)−α∇ϕlogπϕ(a∣s)
5.3 温度损失
L α ( α ) = E s ∼ D , a ∼ π ϕ − α ( log π ϕ ( a ∣ s ) + H 0 ) \mathcal{L}\alpha(\alpha) = \mathbb{E}{s \sim \mathcal{D}, a \sim \pi_\phi} \left -\\alpha \\left( \\log \\pi_\\phi(a\|s) + H_0 \\right) \\right Lα(α)=Es∼D,a∼πϕ−α(logπϕ(a∣s)+H0)
6. 核心代码实现(PyTorch)
以下是SAC算法的核心实现,代码控制在20行以内:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions import Normal
class SAC:
def update(self, states, actions, rewards, next_states, dones):
# 目标动作与对数概率
with torch.no_grad():
next_actions, next_log_probs = self.actor.sample(next_states)
q1_next = self.critic1_target(next_states, next_actions)
q2_next = self.critic2_target(next_states, next_actions)
q_next = torch.min(q1_next, q2_next) - self.alpha * next_log_probs
target_q = rewards + self.gamma * (1 - dones) * q_next
# 更新评论家
q1 = self.critic1(states, actions)
q2 = self.critic2(states, actions)
critic_loss = F.mse_loss(q1, target_q) + F.mse_loss(q2, target_q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 更新演员
new_actions, log_probs = self.actor.sample(states)
q1_new = self.critic1(states, new_actions)
q2_new = self.critic2(states, new_actions)
q_new = torch.min(q1_new, q2_new)
actor_loss = (self.alpha * log_probs - q_new).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新温度
alpha_loss = -(self.log_alpha * (log_probs.detach() + self.target_entropy)).mean()
self.alpha_optimizer.zero_grad()
alpha_loss.backward()
self.alpha_optimizer.step()
self.alpha = self.log_alpha.exp()7. 算法对比与性能分析
| 维度 | DQN | PPO | SAC |
|---|---|---|---|
| 策略类型 | 确定性(贪婪) | 随机(裁剪更新) | 随机(最大熵) |
| 更新方式 | Off-Policy | On-Policy | Off-Policy |
| 探索机制 | ϵ \epsilon ϵ-贪婪 | 策略熵(衰减) | 最大熵(自动调整) |
| 样本效率 | 中 | 低 | 高 |
| 训练稳定性 | 中 | 高 | 高 |
| 连续控制 | 不支持 | 支持 | 优秀 |
SAC的关键优势:
- 自动探索:不需要手动设计探索策略
- 高样本效率:Off-Policy特性支持经验复用
- 强鲁棒性:对超参数相对不敏感
- 理论保证:基于最大熵框架的收敛性证明
适用场景:
- 机器人连续控制(如MuJoCo、PyBullet环境)
- 需要高样本效率的复杂任务
- 对策略随机性有要求的应用
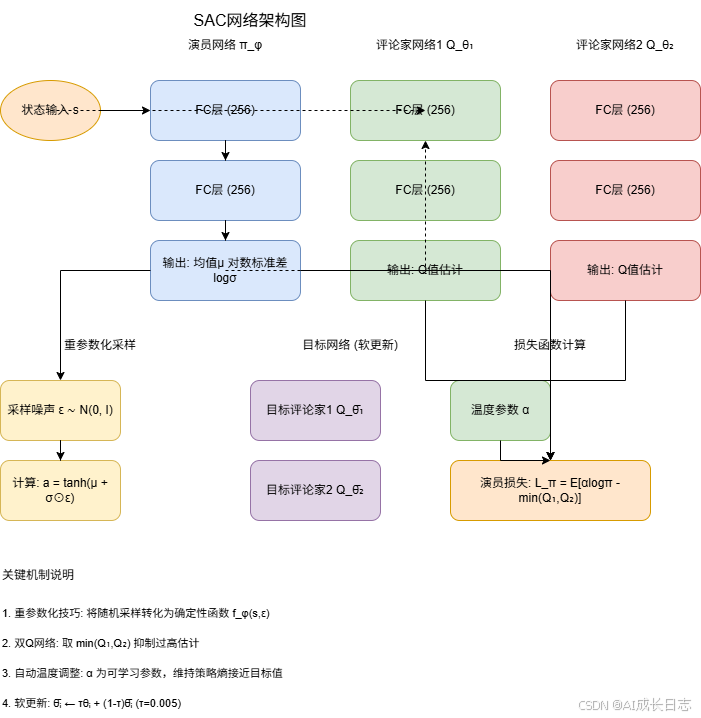
SAC代表了深度强化学习在连续控制方向的重要进展,其最大熵框架为平衡探索与利用提供了优雅解决方案。通过双Q网络抑制过高估计、重参数化降低梯度方差、自动温度调整适应不同阶段,SAC在实际应用中展现出卓越性能。
训练实战与调优
深度强化学习算法的实际应用需要细致的超参数调优和工程实践。本节提供DQN、PPO、SAC三种算法的完整训练代码示例与性能优化指南。
1. DQN在CartPole环境的训练实战
CartPole是经典的控制任务,要求平衡杆不倒。DQN在此任务上表现出色。
关键超参数配置:
学习率 (lr): 0.00025
折扣因子 (gamma): 0.99
回放缓冲区大小: 1,000,000
小批量大小: 32
目标网络更新频率: 10,000步
探索率衰减: 1.0 → 0.1(超过1,000,000步)
优化器: RMSProp (momentum=0.95, epsilon=0.01)核心训练循环代码(≤20行):
python
def train_dqn(env, agent, episodes=1000):
for episode in range(episodes):
state = env.reset()
episode_reward = 0
for t in range(500): # 最大步数
# ϵ-贪婪动作选择
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
# 存储经验
agent.replay_buffer.push(state, action, reward, next_state, done)
# 更新网络
if len(agent.replay_buffer) > 10000:
agent.update()
state = next_state
episode_reward += reward
if done:
break
# 记录训练进度
if episode % 10 == 0:
print(f"Episode {episode}, Reward: {episode_reward}, Epsilon: {agent.epsilon}")性能优化建议:
- 逐步衰减ϵ:从1.0线性衰减到0.1,确保充分探索
- 延迟训练:等待回放缓冲区积累足够样本(如10,000条)再开始更新
- 目标网络软更新 :采用 τ = 0.005 \tau=0.005 τ=0.005的Polyak平均,比硬更新更稳定
- 梯度裁剪:限制梯度范数≤0.5,防止训练崩溃
2. PPO在MuJoCo环境的训练实战
MuJoCo提供高精度物理仿真,适合连续控制任务。PPO在此类环境中表现稳定。
关键超参数配置:
学习率 (lr): 0.0003
折扣因子 (gamma): 0.99
GAE参数 (lambda): 0.95
裁剪阈值 (epsilon): 0.2
小批量大小: 64
更新轮数 (epochs): 4
熵系数: 0.01(衰减至0)
优化器: Adam (betas=(0.9, 0.999))核心训练循环代码(≤20行):
python
def train_ppo(env, agent, timesteps=1e6):
step = 0
while step < timesteps:
# 收集轨迹
states, actions, rewards, dones = [], [], [], []
state = env.reset()
for _ in range(2048): # 轨迹长度
action = agent.actor.sample(state)
next_state, reward, done, _ = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
dones.append(done)
state = next_state
step += 1
if done:
state = env.reset()
# 计算优势函数
advantages = agent.compute_gae(states, rewards, dones)
# 多轮优化
for _ in range(4):
agent.update(states, actions, advantages)
# 性能评估
if step % 10000 == 0:
test_reward = evaluate_policy(env, agent)
print(f"Step {step}, Test Reward: {test_reward:.1f}")性能优化建议:
- 优势归一化:减去均值除以标准差,减少梯度方差
- 奖励裁剪:限制奖励到-10, 10范围,防止异常值
- 值函数裁剪:防止价值网络过度拟合
- 熵系数衰减:随训练进度逐渐降低,从探索过渡到利用
3. SAC在PyBullet环境的训练实战
PyBullet是开源的物理引擎,适合机器人控制任务。SAC在此类连续控制任务中样本效率最高。
关键超参数配置:
学习率 (lr): 0.0003
折扣因子 (gamma): 0.99
软更新系数 (tau): 0.005
目标熵 (H0): -动作维度
回放缓冲区大小: 1,000,000
小批量大小: 256
温度初值 (alpha): 0.2
优化器: Adam (betas=(0.9, 0.999))核心训练循环代码(≤20行):
python
def train_sac(env, agent, episodes=10000):
for episode in range(episodes):
state = env.reset()
episode_reward = 0
for t in range(1000):
# 从当前策略采样动作
action = agent.select_action(state, evaluate=False)
next_state, reward, done, _ = env.step(action)
# 存储经验
agent.replay_buffer.push(state, action, reward, next_state, done)
# 更新网络
if len(agent.replay_buffer) > 5000:
agent.update()
state = next_state
episode_reward += reward
if done:
break
# 记录训练进度
if episode % 100 == 0:
test_reward = evaluate_policy(env, agent)
print(f"Episode {episode}, Train Reward: {episode_reward:.1f}, Test Reward: {test_reward:.1f}")性能优化建议:
- 自动温度调整:让算法自行调节探索强度,无需手动调优
- 双Q网络:取最小值抑制过高估计,提高训练稳定性
- 重参数化:降低策略梯度方差,加速收敛
- 大回放缓冲区:存储百万级经验,提高样本复用率
4. 收敛监测与问题诊断
关键监控指标:
- 平均回报:每100回合滑动平均,确保上升趋势
- 策略熵:监控探索程度,理想情况缓慢下降
- Q值范围:防止Q值爆炸(通常应在-100, 100内)
- 梯度范数:过大(>10)可能导致训练不稳定
常见问题及解决方案:
- Q值爆炸:降低学习率(如从0.001→0.0001),增加目标网络更新间隔
- 策略崩溃:减小裁剪阈值(如从0.3→0.1),增加熵系数(如从0.01→0.05)
- 样本效率低:增大回放缓冲区(如从1e5→1e6),优化探索策略(如增加探索噪声)
- 收敛停滞:检查网络架构是否足够表达能力,考虑增加隐藏层宽度
总结与展望
深度强化学习的技术演进体现了从简单到复杂、从理论到工程的系统发展逻辑。DQN首次证明了深度网络可直接从原始感官输入学习决策策略,PPO通过精巧的裁剪机制解决了策略梯度方法的稳定性问题,SAC则引入了最大熵框架实现更鲁棒的探索与利用平衡。
未来发展方向包括:
- 样本效率提升:结合离线强化学习与模型预测
- 多智能体协作:解决非平稳环境下的协调问题
- 安全与对齐:确保智能体行为符合人类价值观
- 跨领域泛化:实现技能在不同任务间的迁移
深度强化学习正从实验室算法走向实际应用,在机器人控制、游戏AI、自动驾驶等领域展现出巨大潜力。掌握DQN、PPO、SAC三大核心算法的原理与实现,是深入这一前沿领域的重要基础。
参考文献
- Mnih, V., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
- Schulman, J., et al. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Haarnoja, T., et al. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290.
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.