****论文题目:****An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling(用于序列建模的通用卷积和循环网络的经验评价)
会议:Arxiv预印arXiv:1803.01271v2
****摘要:****对于大多数深度学习从业者来说,序列建模就是循环网络的同义词。然而,最近的研究结果表明,卷积架构在音频合成和机器翻译等任务上可以胜过循环网络。给定一个新的序列建模任务或数据集,应该使用哪种架构?我们对序列建模的通用卷积和循环架构进行了系统的评估。这些模型在广泛的标准任务范围内进行评估,这些标准任务通常用于对循环网络进行基准测试。我们的研究结果表明,一个简单的卷积架构在不同的任务和数据集上优于典型的循环网络,如lstm,同时显示出更长的有效记忆。我们的结论是,应该重新考虑序列建模和循环网络之间的共同关联,卷积网络应该被视为序列建模任务的自然起点。
代码地址:http://github.com/locuslab/TCN
一、引言:一个被忽视的问题
在很长一段时间里,深度学习从业者几乎将"序列建模"与"循环神经网络(RNN)"画上等号。无论是 Goodfellow 等人的经典教材《Deep Learning》,还是 Andrew Ng 的"Sequence Models"课程,RNN 都被作为序列任务的默认起点介绍给每一位学习者。
然而,近年来陆续有研究表明,卷积架构在音频合成(WaveNet)、机器翻译(ConvS2S)、语言建模(Gated ConvNet)等任务上能够达到甚至超越 RNN 的水平。这不禁让人发问:卷积架构在序列建模上的成功,是特定领域的偶然,还是普遍规律?
Bai 等人(2018)正面回应了这个问题。他们设计了一个通用的时序卷积网络(Temporal Convolutional Network, TCN ),并在 RNN 最擅长的一系列基准任务上与 LSTM、GRU 进行了系统性的正面比较。结论出人意料却又令人信服:TCN 在绝大多数任务上显著优于经典 RNN 架构,且具有更长的有效记忆。
二、TCN 架构:三个核心设计
TCN 的设计哲学是"简洁但强大",它并非一个全新发明,而是将现代卷积网络的最佳实践整合为一个统一的序列建模框架。其核心由三部分构成。
2.1 因果卷积:杜绝未来信息泄露
序列建模的基本约束是:预测时刻 t 的输出,只能使用 t 及之前的输入。TCN 通过因果卷积(Causal Convolution) 满足这一约束------每一层只与前一层中时间上更早的元素进行卷积,不允许任何"未来信息"渗入当前预测。
在实现上,TCN 采用 1D 全卷积网络(FCN) 结构,通过对输入进行零填充(padding = kernel_size - 1),保证每一层的长度与输入序列等长,从而可以输出与输入等长的序列------这与 RNN 的行为是一致的。
一句话总结:TCN = 1D 全卷积网络 + 因果卷积
2.2 膨胀卷积:指数级扩大感受野
普通因果卷积存在一个明显缺陷:感受野大小仅与网络深度线性相关。要覆盖很长的历史,要么网络极深,要么卷积核极大,二者都代价高昂。
膨胀卷积(Dilated Convolution) 解决了这一问题。其数学定义为:
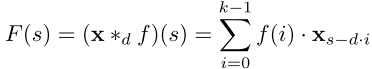
其中 d 为膨胀因子,k 为卷积核大小。通俗地说,膨胀卷积在相邻卷积核元素之间插入固定间隔,使得感受野不再随深度线性增长,而是指数级增长。
TCN 在第 i 层使用膨胀因子 d = 2^i,这样即使网络不太深,也能覆盖极长的历史序列。单层的有效历史长度为 (k-1)× d,而整个网络的感受野则随层数指数扩大。
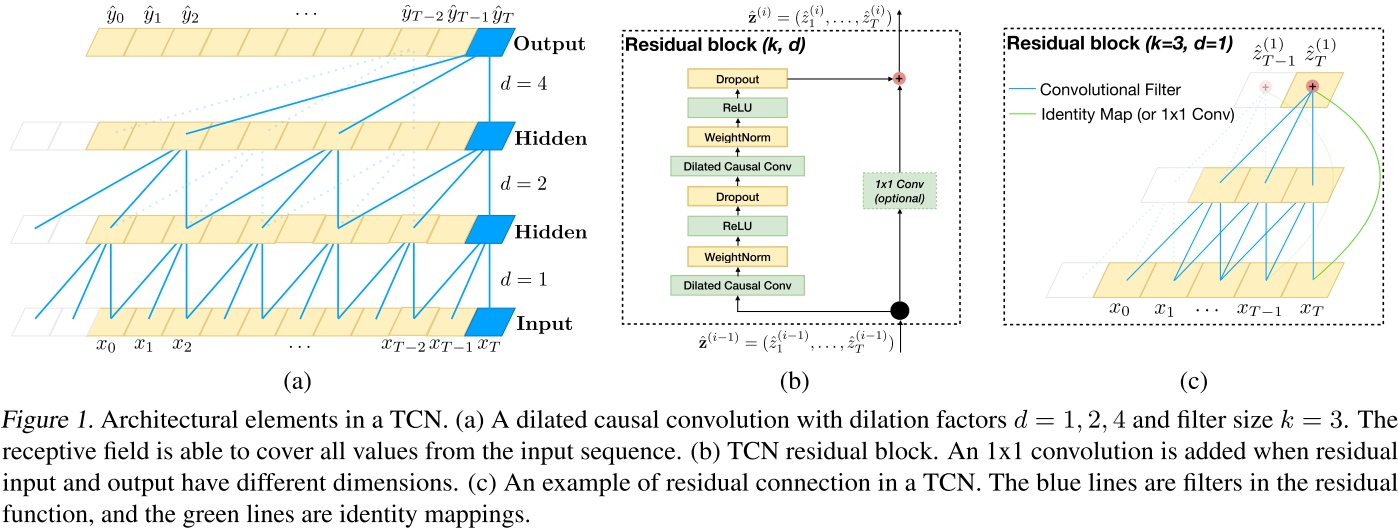
【此处配图:Figure 1------TCN中的架构元素。(a)一个扩张的因果卷积,其扩张因子d = 1,2,4,滤波器大小k = 3。感受野能够覆盖输入序列中的所有值。(b) TCN残余块。当剩余输入和输出具有不同的维数时,添加1x1卷积。(c) TCN中剩余连接的示例。蓝线是残差函数中的过滤器,绿线是恒等映射。】
2.3 残差连接:稳定深层网络的训练
TCN 借鉴 ResNet 的思想,引入残差块(Residual Block) 代替普通卷积层:
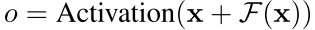
每个残差块内部包含:
- 两层膨胀因果卷积
- 权重归一化(Weight Normalization):用于训练加速
- ReLU 激活
- 空间 Dropout:每次训练步随机将整个通道置零,用于正则化
由于卷积网络中输入和输出的维度可能不同,TCN 额外使用 1×1 卷积来对齐残差路径的维度,保证逐元素相加的合法性。
残差连接使得即使网络很深(如需要覆盖 2^12 历史长度时,网络可能需要 12 层),梯度也能稳定回传,训练不会发散。
三、TCN vs RNN:优势与劣势分析
在正式介绍实验结果之前,我们先理性地梳理 TCN 相比 RNN 的优势和劣势。
优势
① 并行计算 RNN 的预测存在严格的时序依赖------t 时刻的输出必须等待 t-1 时刻完成。而 TCN 的卷积操作在各时间步之间完全独立,训练和推理均可完全并行化,在 GPU 上效率显著更高。
② 灵活可控的感受野 通过调整卷积核大小 k、膨胀因子 d、网络层数 n,TCN 可以精确控制感受野大小,适配不同任务对历史长度的需求。
③ 训练梯度更稳定 RNN 的梯度沿时间方向回传,极易出现梯度消失/爆炸(这正是 LSTM、GRU 被提出的根本原因)。TCN 的梯度沿网络深度方向回传,与时间轴解耦,从根本上规避了这一问题。
④ 更低的训练内存占用 LSTM/GRU 需要为其多个门控存储中间激活值。TCN 的卷积核在层内共享,反向传播路径仅依赖网络深度,实践中内存占用显著更低。
劣势
① 推理时需要保留原始序列 RNN 在推理时只需维护一个固定长度的隐状态向量 ht,可以丢弃历史序列本身。而 TCN 在推理时需要保留完整的历史序列(长度等于感受野大小),推理阶段的内存开销更大。
② 跨域迁移可能需要调整感受野 不同任务对历史长度的需求差异很大。将 TCN 从一个短历史任务迁移到长历史任务时,需要重新调整 k 和 d,而 RNN 理论上可以自适应。
四、实验设置
为了在 RNN 最擅长的"主场"上进行公平比较,论文选取了若干经典 RNN 基准任务,涵盖合成压力测试和真实语言/音乐数据集。
合成压力测试
- Adding Problem:长度为 n 的序列,找出被标记的两个随机数并求和,随机猜测的基线 MSE 约为 0.1767
- Copy Memory:记住序列开头的 10 个字符,在序列结尾(间隔 T 步后)准确复述
- Sequential MNIST / P-MNIST:将 784 像素点展开为一维序列进行数字分类;P-MNIST 还对顺序进行随机打乱,难度更高
真实数据集
- 多声部音乐建模:JSB Chorales(382 首巴赫四声部合唱曲)和 Nottingham(1200 首民谣),指标为负对数似然(NLL)
- 字符级语言模型:Penn Treebank(PTB)和 text8,指标为每字符比特数(bpc)
- 词级语言模型:PTB、Wikitext-103(约 1 亿词)、LAMBADA(专门测试长距离上下文理解的数据集),指标为困惑度(perplexity)
所有实验中,TCN 使用统一架构,仅调整网络深度 n 和卷积核大小 k 以保证感受野覆盖任务所需的上下文长度;模型参数量与对比的 RNN 保持一致。
五、实验结果
5.1 综合结果一览
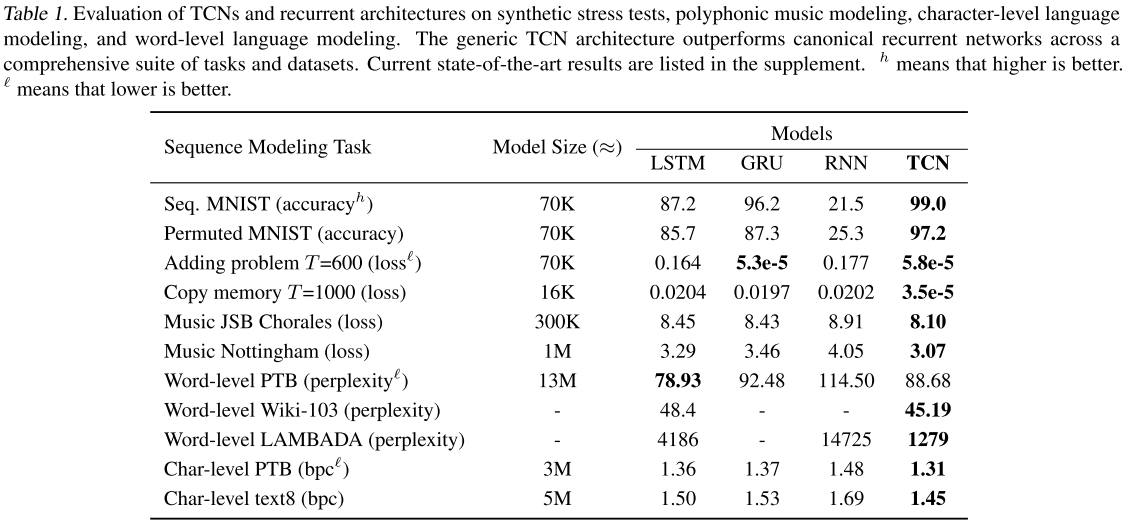
【此处配表:Table 1------各任务上 LSTM、GRU、Vanilla RNN、TCN 的综合对比结果表】
如表所示,TCN 在绝大多数任务上超越了所有 RNN 基线:
- Seq. MNIST :TCN 达到 99.0% 准确率,LSTM 仅 87.2%,Vanilla RNN 更是只有 21.5%
- P-MNIST :TCN 97.2%,超越当时基于 RNN 的 SOTA 结果(95.9%,来自 Zoneout + Recurrent BatchNorm)
- Copy Memory (T=1000) :TCN loss 仅 3.5e-5,而 LSTM(0.0204)和 GRU(0.0197)几乎等同于"全部猜零"的基线
- JSB Chorales :TCN 8.10,优于 LSTM(8.45)和 GRU(8.43)
- Char-level PTB :TCN 1.31 bpc,优于 LSTM(1.36)和 GRU(1.37)
- Word-level Wikitext-103 :TCN 45.19 ppl,LSTM 为 48.4
- LAMBADA :TCN 1279 ppl,LSTM 高达 4186,差距极为悬殊
唯一例外是词级 PTB 任务:使用了 recurrent dropout 等专门优化手段的 LSTM(78.93 ppl)优于 TCN(88.68 ppl)。但在更大规模的 Wikitext-103 和 LAMBADA 上,TCN 无需超参数搜索就取得了更优结果。
5.2 合成压力测试:TCN 快速收敛
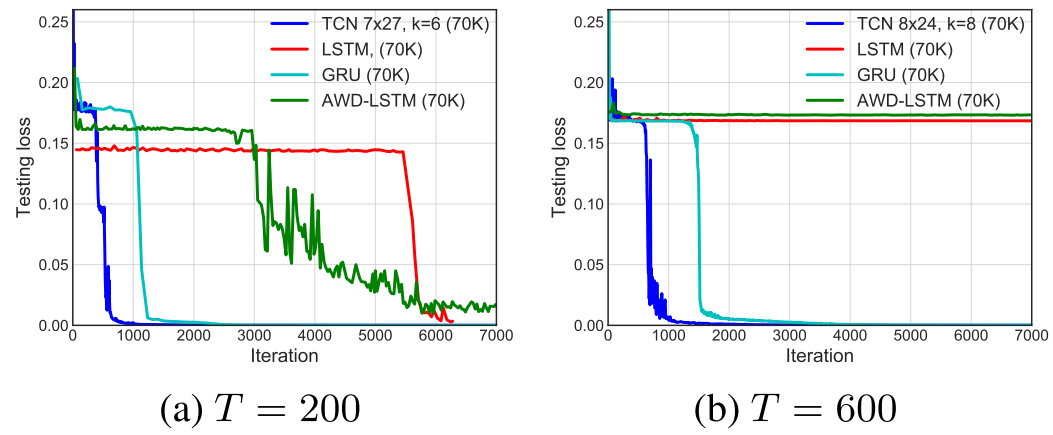
【此处配图:Figure 2------Adding Problem 在 T=200 和 T=600 时各模型的收敛曲线】
在 Adding Problem 上,TCN 迅速收敛到近乎完美的解(MSE ≈ 0)。GRU 也表现尚可但收敛更慢,LSTM 和 Vanilla RNN 则表现显著更差。
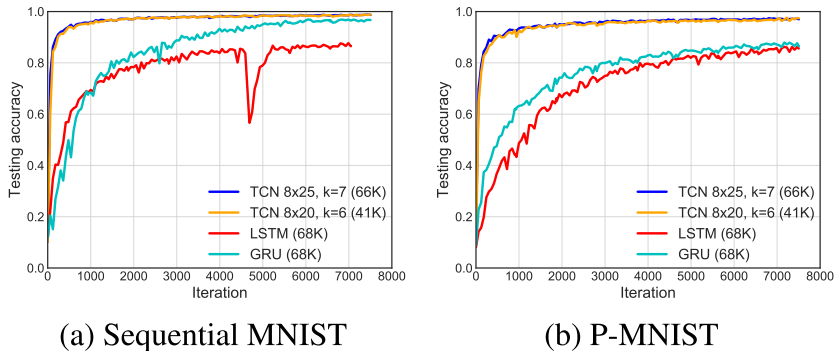
【此处配图:Figure 3------Sequential MNIST 和 P-MNIST 上的收敛曲线】
在 Sequential 和 Permuted MNIST 上,TCN 无论是收敛速度还是最终精度都全面领先于 RNN 架构。
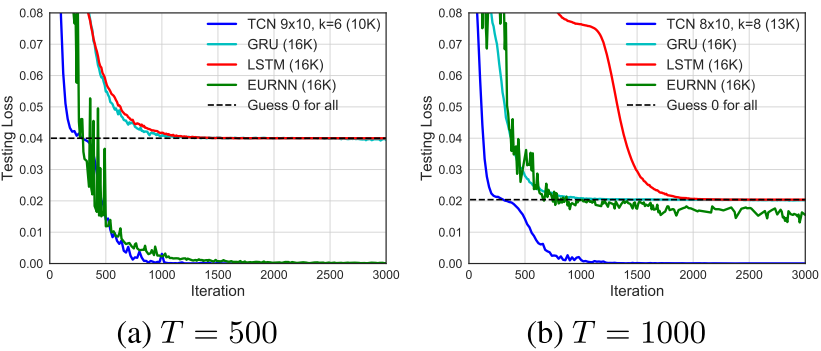
【此处配图:Figure 4------Copy Memory 任务在 T=500 和 T=1000 时的收敛曲线】
Copy Memory 任务上,TCN 快速收敛到正确答案,而 LSTM 和 GRU 则收敛至与"全部预测为零"相同的 loss,即完全失败。对比 EURNN(专为该任务设计的单元矩阵 RNN),TCN 在 T=500 时与其相当,在 T=1000 及更长时则具有明显优势。
5.3 记忆能力的深入分析
这是论文中最具洞察力的实验之一。RNN 的最大理论优势是"无限记忆"------隐状态向量理论上可以编码任意长度的历史信息。但实践中真的如此吗?
论文通过 Copy Memory 任务系统地测试了不同模型在不同序列长度 T 下对历史信息的保留能力:
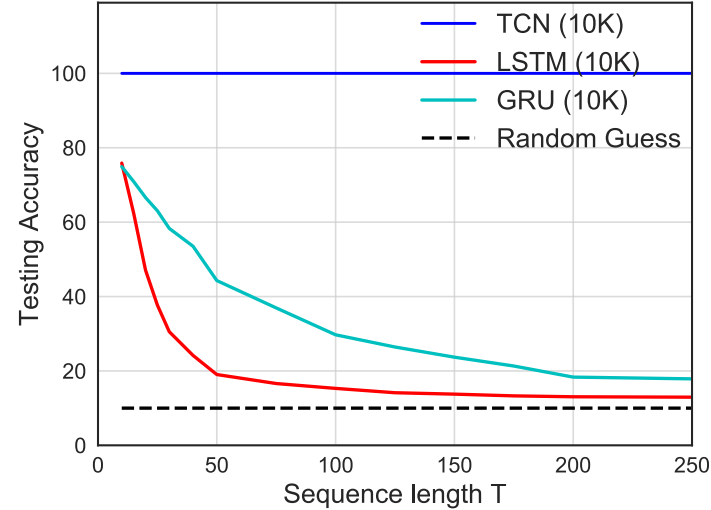
【此处配图:Figure 5------不同序列长度 T 下各模型在 Copy Memory 任务上的准确率曲线】
结果非常清晰:
- TCN 在所有序列长度下均保持 100% 准确率
- LSTM 在 T < 50 时准确率就跌破 20%,退化为随机猜测
- GRU 在 T < 200 时跌破 20%
这一结果有力地反驳了"RNN 具有无限记忆"的理论假设------这种优势在实践中几乎不存在,而 TCN 在相同参数量下反而展现出远更长的有效记忆。
LAMBADA 数据集上的结果(TCN 1279 ppl vs LSTM 4186 ppl)进一步在真实数据上验证了这一结论,因为 LAMBADA 正是专门为测试模型利用广泛上下文信息的能力而设计的。
六、消融实验
6.1 卷积核大小 k 的影响
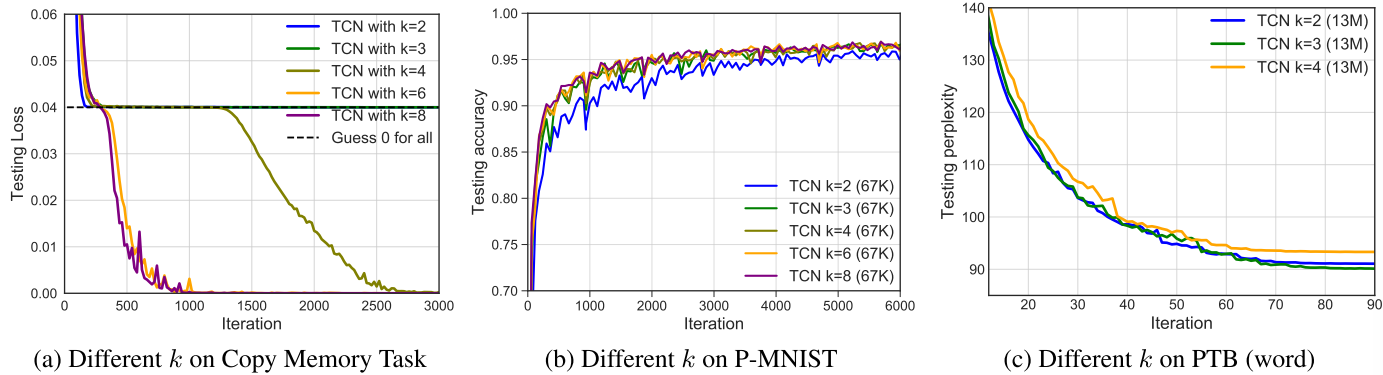
【此处配图:Figure 6(a)(b)(c)------不同 k 值在 Copy Memory、P-MNIST、词级 PTB 上的对比】
- Copy Memory 和 P-MNIST:较大的 k 更有利,k<=3 的 TCN 在 Copy Memory 上只能收敛到随机猜测水平
- 词级语言建模(PTB):k=3 效果最好。原因在于语言建模更依赖局部上下文(n-gram 模型的成功也印证了这一点),小卷积核更专注于短程依赖
6.2 残差连接的作用
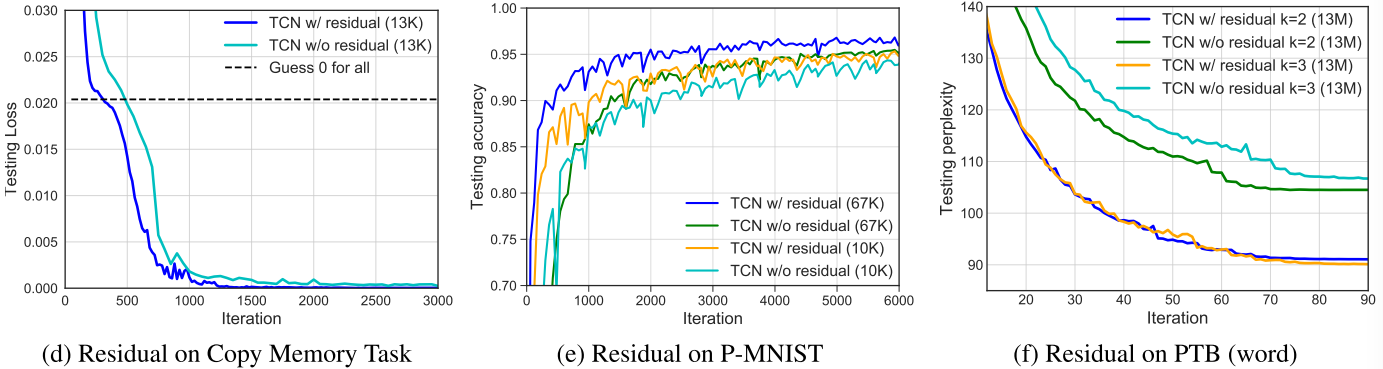
【此处配图:Figure 6(d)(e)(f)------有无残差连接在三个任务上的训练曲线对比】
在所有三个对比场景中,残差连接都能稳定训练过程并加速收敛。在语言建模任务上效果尤为显著。
6.3 门控激活的影响
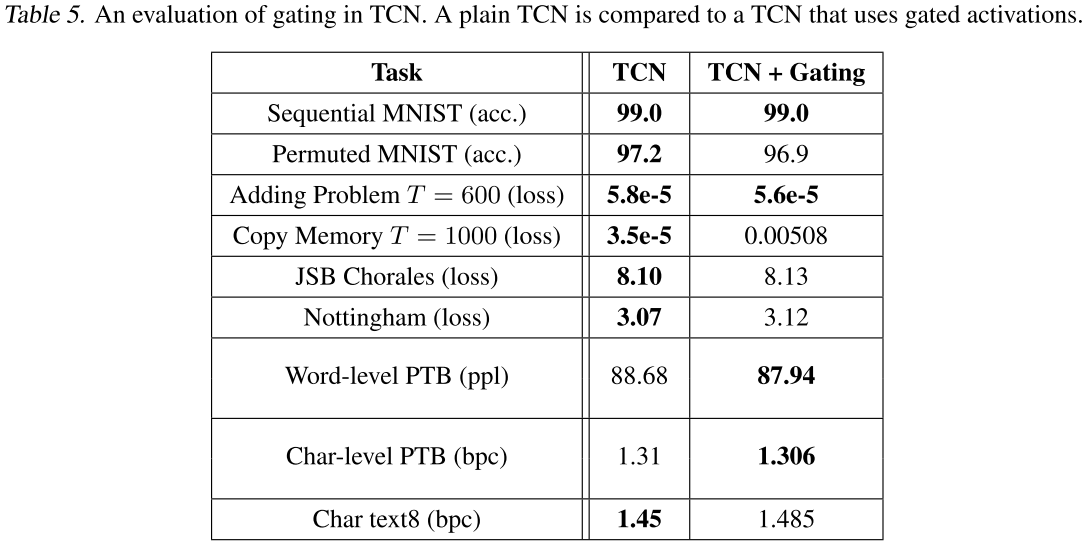
【此处配表:Table 5------普通 TCN(ReLU)与 TCN + 门控激活(GLU)的对比】
门控线性单元(GLU)在词级 PTB 上略有提升(88.68 → 87.94 ppl),但在需要长程记忆的任务(如 Copy Memory T=1000)上却造成了明显的性能下降(3.5e-5 → 0.00508)。因此,论文的通用 TCN 架构选择使用 ReLU 而非门控激活,保持简洁的同时在更多任务上表现更好。
七、与 SOTA 的对比
值得注意的是,论文的目标是比较通用的 CNN 和 RNN 架构,而非追求最优 SOTA。对于每个任务,都存在使用额外技巧(如 AWD-LSTM、Neural Cache 等)的专用架构,性能更优。
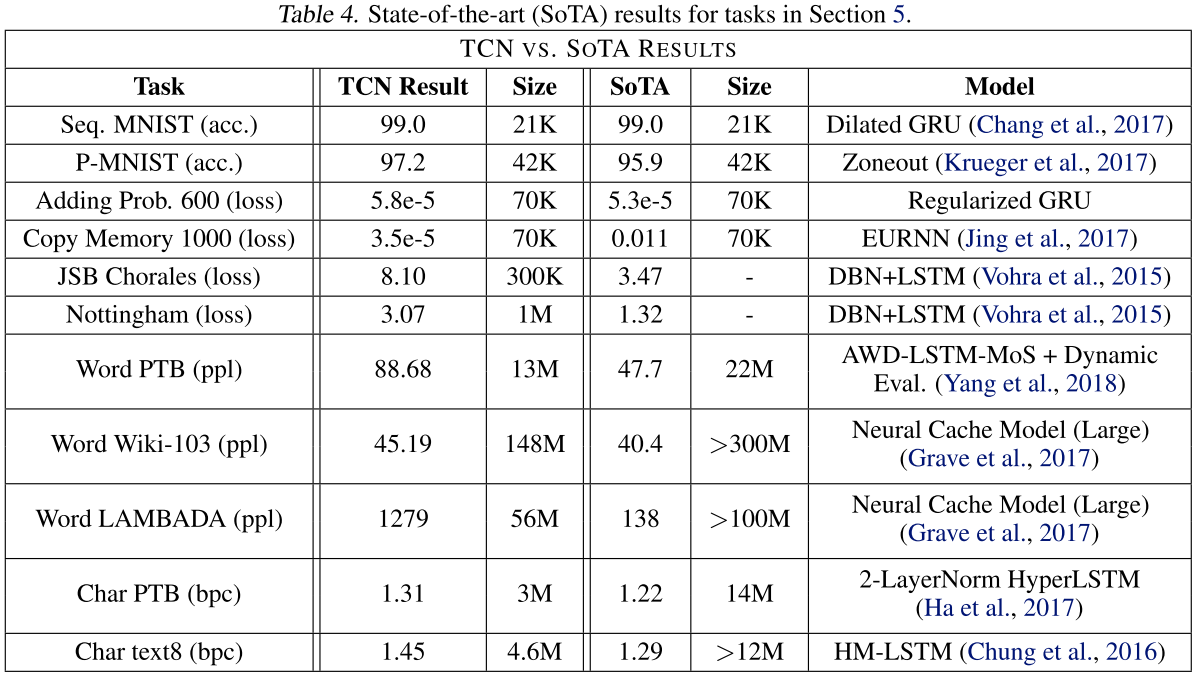
【此处配表:Table 4------TCN 结果与各任务 SOTA 结果的对比,包含模型规模信息】
以词级 PTB 为例:TCN 取得 88.68 ppl,而加入了 MoS(Mixture of Softmaxes)和动态评估的 AWD-LSTM 能达到 47.7 ppl。但作者指出,这些针对 LSTM 的优化方案同样可以类比到 TCN 上,TCN 还没有获得与 LSTM 同等程度的社区优化投入,未来有很大的提升空间。
八、结论与启示
这篇论文的核心贡献可以归纳为三点:
-
提出了一个简洁而强大的 TCN 通用架构,整合了因果卷积、膨胀卷积和残差连接三大要素,可以作为序列建模的通用基准
-
系统性地证明了 TCN 在 RNN 的主场任务上全面超越 LSTM、GRU,改变了"序列建模 = 循环网络"的固有认知
-
实证揭示了 RNN"无限记忆"优势在实践中的失效------TCN 具有比相同容量的 RNN 更长的有效记忆
作者在结论中写道:"循环网络在序列建模中的主导地位,可能在很大程度上只是历史的惯性。"在膨胀卷积和残差连接等现代架构元素出现之前,卷积网络确实较弱;但有了这些工具之后,TCN 不仅更准确,也更简洁、更易于理解和调试。
从今天的视角来看,这篇论文的意义不仅在于 TCN 本身,更在于它提醒我们:架构选择应当由实证证据而非历史惯性决定。Transformer 架构的全面崛起,正是这一精神的延续------它同样是基于卷积/注意力机制,而非循环结构,在更多序列任务上取得了新的突破。