加和法则:p(x)=∫p(x,y)dyp(x)=∫p(x,y)dyp(x)=∫p(x,y)dy乘积法则:p(x,y)=p(y∣x)p(x)p(x,y)=p(y|x)p(x)p(x,y)=p(y∣x)p(x)贝叶斯定理:p(y∣x)=p(x∣y)p(y)p(x)p(y|x)=\frac{p(x|y)p(y)}{p(x)}p(y∣x)=p(x)p(x∣y)p(y)其中,分母p(x)=∫p(x∣y)p(y)dyp(x)=∫p(x|y)p(y)dyp(x)=∫p(x∣y)p(y)dy
1 分布
概率密度必须满足p(x)≥1且∫p(x)dx=1p(x)≥1且∫p(x)dx=1p(x)≥1且∫p(x)dx=1
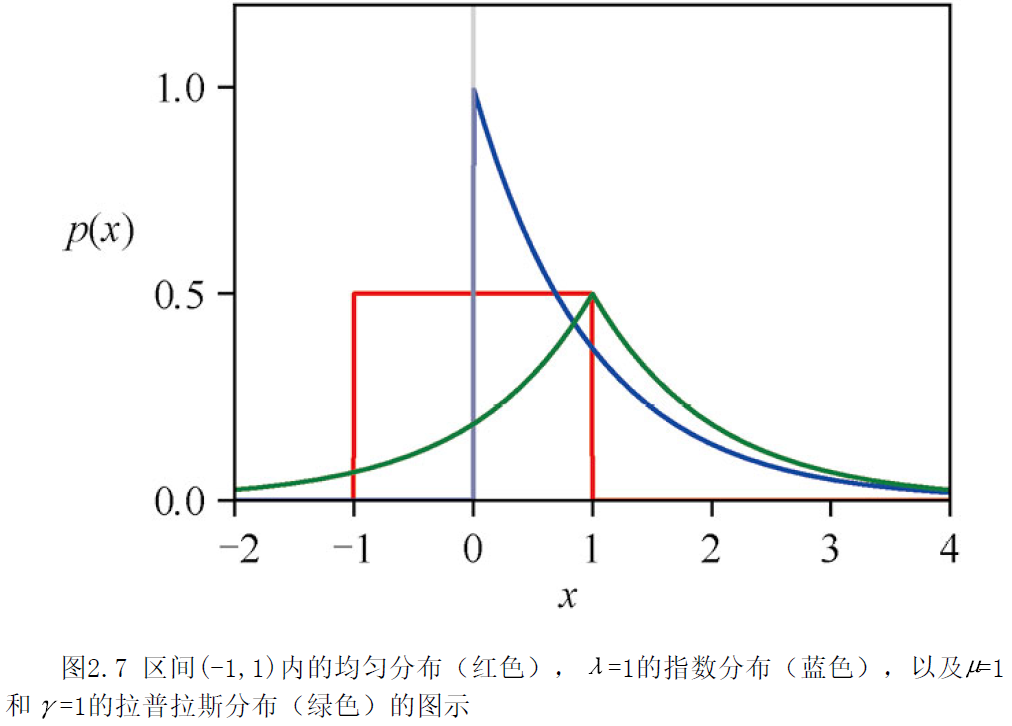
1.1 均匀分布
均匀分布在有限区间内是常数,其他地方为0,表达式为p(x)=1d−c,x∈(c,d)p(x)=\frac{1}{d-c},x∈(c,d)p(x)=d−c1,x∈(c,d)
1.2 指数分布
p(x∣λ)=λe−λx,x≥0p(x|λ)=λe^{-λx},x≥0p(x∣λ)=λe−λx,x≥0
1.3 拉普拉斯分布
p(x∣μ,γ)=12γe−∣x−μ∣γp(x|μ,γ)=\frac{1}{2γ}e^{-\frac{|x-μ|}{γ}}p(x∣μ,γ)=2γ1e−γ∣x−μ∣
1.4 狄拉克δ函数构造经验分布
狄拉克δ函数p(x∣μ)=δ(x−μ)p(x|μ)=δ(x-μ)p(x∣μ)=δ(x−μ)定义为在除了x=μx=μx=μ除的其他任意位置均为0,且具有积分为1的特性。可将其视为一个位于x=μx=μx=μ除的无限窄且无限高的峰,并具有单位面积的性质。若有个xxx的有限观测值集合D={x1,⋯,xN}D=\{ x_1,⋯,x_N\}D={x1,⋯,xN},可构造经验分布p(x∣D)=1N∑n=1Nδ(x−xn)p(x|D)=\frac{1}{N}\sum_{n=1}^Nδ(x-x_n)p(x∣D)=N1n=1∑Nδ(x−xn)
2 期望(expectation)
某函数f(x)f(x)f(x)在概率分布p(x)p(x)p(x)下的加权平均称为f(x)f(x)f(x)的期望,用E(f)E(f)E(f)表示。对于离散分布E(f)=∑xp(x)f(x)E(f)=\sum_xp(x)f(x)E(f)=x∑p(x)f(x)对于连续变量E(f)=∫p(x)f(x)dxE(f)=∫p(x)f(x)dxE(f)=∫p(x)f(x)dx不论哪种情况,若从概率分布或概率密度中得到NNN个有限数量的点,则期望可以近似为这些点的有限和E(f)≈1N∑n=1Nf(xn)E(f)≈\frac{1}{N}\sum_{n=1}^Nf(x_n)E(f)≈N1n=1∑Nf(xn)考虑多个变量的函数期望,可用下标表示哪个变量被平均Exf(x,y)E_xf(x,y)Exf(x,y)注意,该期望是关于yyy的函数。也可以考虑条件期望Exf∣y=∑xp(x∣y)f(x)E_xf\|y=\sum_xp(x|y)f(x)Exf∣y=x∑p(x∣y)f(x) Exf∣yE_xf\|yExf∣y也是关于yyy的函数。对于连续变量Exf∣y=∫p(x∣y)f(x)dxE_xf\|y=∫p(x|y)f(x)dxExf∣y=∫p(x∣y)f(x)dx
3 方差(variance)
f(x)f(x)f(x)的方差定义为varf=Ef(x)−E\[f(x)2]varf=E\leftf(x)-E\[f(x)^2\right]varf=Ef(x)−E\[f(x)2]这个式子度量了f(x)f(x)f(x)围绕其平均值Ef(y)Ef(y)Ef(y)的变化程度。平方展开后也可写成varf=Ef2(x)−Ef(x)2varf=Ef\^2(x)-Ef(x)^2varf=Ef2(x)−Ef(x)2变量xxx的方差,定义为varx=Ex2−E2xvarx=Ex\^2-E^2xvarx=Ex2−E2x
4 协方差(covariance)
协方差度量了两个变量一起变化的程度,定义为covx,y=Ex,y{x−E\[X}{y−Ey}]=Ex,yxyExEy\begin{align*} covx,y&=E_{x,y}\\{x-E\[X\}\{y-Ey\}] \\ &= E_{x,y}xyExEy \end{align*} covx,y=Ex,y{x−E\[X}{y−Ey}]=Ex,yxyExEy若x,yx,yx,y独立,则它们的协方差为零。
对于两个向量x,yx,yx,y,它们的协方差是由下式给出的矩阵covx,y=Ex,y{x−E\[X}{yT−EyT}]=Ex,yTxyExEyT\begin{align*} covx,y&=E_{x,y}\\{x-E\[X\}\{y^T-Ey\^T\}] \\ &= E_{x,y^T}xyExEy\^T \end{align*} covx,y=Ex,y{x−E\[X}{yT−EyT}]=Ex,yTxyExEyT