Python后端开发之旅(五)------ DL
- Python进阶------Pytorch
-
- [1. 基础:张量(Tensor)操作](#1. 基础:张量(Tensor)操作)
-
- 常用函数与代码示例
- [⚠️ 关键注意事项](#⚠️ 关键注意事项)
- [2. 数据集处理:Dataset 和 DataLoader](#2. 数据集处理:Dataset 和 DataLoader)
-
- [(1) 自定义 Dataset 类](#(1) 自定义 Dataset 类)
- [(2) 使用 DataLoader 批量加载](#(2) 使用 DataLoader 批量加载)
- [⚠️ 关键注意事项](#⚠️ 关键注意事项)
- [3. 数据转换:torchvision.transforms](#3. 数据转换:torchvision.transforms)
-
- 常用转换组合(以图像为例)
- [⚠️ 关键注意事项](#⚠️ 关键注意事项)
- [4. 神经网络构建:torch.nn 模块](#4. 神经网络构建:torch.nn 模块)
-
- [(1) 常用层与损失函数](#(1) 常用层与损失函数)
- [(2) 定义神经网络模型(核心步骤)](#(2) 定义神经网络模型(核心步骤))
- [⚠️ 关键注意事项](#⚠️ 关键注意事项)
- [5. 训练循环:完整流程](#5. 训练循环:完整流程)
-
- [⚠️ 关键注意事项](#⚠️ 关键注意事项)
- [6. 模型保存与加载:最佳实践](#6. 模型保存与加载:最佳实践)
- [TensorFlow 简要对比](#TensorFlow 简要对比)
-
- [PyTorch vs TensorFlow 2.x 代码对比表](#PyTorch vs TensorFlow 2.x 代码对比表)
- [TensorFlow 2.x 极简示例(MNIST 分类)](#TensorFlow 2.x 极简示例(MNIST 分类))
- [Python进阶------Pytorch 优化](#Python进阶——Pytorch 优化)
-
- [集束搜索(Bean Search) 算法(https://www.cnblogs.com/geekbruce/articles/18876271)](#集束搜索(Bean Search) 算法)
- dropout
- torch.nn
- torch
-
- torch.ones()和torch.zeros()
- torch.zeros_like()
- torch.empty()
- squeeze()和unsqueeze()
- torch.arange()
- [torch.randn()、torch.randn()、 torch.randint()(https://blog.csdn.net/qq_41813454/article/details/136326473)](#torch.randn()、torch.randn()、 torch.randint())
- torch.repeat_interleave()、torch.repeat()、torch.tile()
- torch.cat()
- torch.mean()
- [Tensor 操作](#Tensor 操作)
-
- 广播机制(broadcast)
- 多维矩阵运算------⭐
- torch.dtype、torch.device和torch.layout
- [`torch.flatten()`、`x.view()`和`x.reshape()` 操作的区别](#
torch.flatten()、x.view()和x.reshape()操作的区别) -
- [`x.view()` - "视图":要求严格,效率高](#
x.view()- “视图”:要求严格,效率高) - [`x.reshape()` - "重塑":更智能、更宽容](#
x.reshape()- “重塑”:更智能、更宽容) - [`torch.flatten()` - "展平":一个专用的便捷函数](#
torch.flatten()- “展平”:一个专用的便捷函数)
- [`x.view()` - "视图":要求严格,效率高](#
- [.contiguous() 方法](#.contiguous() 方法)
- 有了view为什么还有tranpose?
- [两大转置函数 transpose() 和 permute()(https://zhuanlan.zhihu.com/p/1971711959251519384)](#两大转置函数 transpose() 和 permute())
- [target.scatter(dim, index, src)(https://zhuanlan.zhihu.com/p/629193473)](#target.scatter(dim, index, src))
- [.double().item() 方法(https://blog.csdn.net/qq_37297763/article/details/116714464)](#.double().item() 方法)
Python进阶------Pytorch
PyTorch 的核心优势是 "像写普通 Python 代码一样构建神经网络"。它的动态图机制(每一步操作实时执行)让调试变得极其简单------你不需要像 TensorFlow 1.x 那样先定义完整计算图再运行。我们从数据处理到模型部署逐步拆解。
1. 基础:张量(Tensor)操作
为什么重要? Tensor 是 PyTorch 的数据载体,类似 NumPy 的 ndarray,但支持 GPU 加速和自动求导。
常用函数与代码示例
python
import torch
import numpy as np
# 创建张量
x = torch.tensor([1.0, 2.0, 3.0]) # 从Python列表创建
y = torch.zeros(3, 3) # 3x3 零矩阵
z = torch.randn(2, 2) # 标准正态分布随机数
# 张量操作(与NumPy几乎一致)
a = torch.add(x, 10) # [11., 12., 13.]
b = x * 2 # [2., 4., 6.]
c = z.matmul(z) # 矩阵乘法(等价于 z @ z)
# 设备管理(CPU/GPU切换 - 关键!)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x_gpu = x.to(device) # 将张量移至GPU
print(f"张量设备: {x_gpu.device}, 是否在GPU上: {x_gpu.is_cuda}")
# 与NumPy互转(无缝衔接)
np_array = np.array([4, 5, 6])
torch_tensor = torch.from_numpy(np_array) # NumPy → Tensor(共享内存!)
back_to_np = torch_tensor.numpy() # Tensor → NumPy⚠️ 关键注意事项
- 设备一致性 :张量和模型必须在同一设备 (CPU/GPU)上操作,否则会报
RuntimeError。推荐在代码开头统一设置device。 - 内存共享 :
torch.from_numpy()创建的张量与原 NumPy 数组共享内存 ,修改一方会影响另一方。若需独立副本,用torch.tensor(np_array)。 - 数据类型 :默认
torch.float32,分类任务常用torch.long。用.dtype检查类型,避免float和int混合运算出错。 - 梯度追踪 :张量默认不跟踪梯度(
requires_grad=False)。需手动设置x = torch.tensor(..., requires_grad=True)用于自定义求导。
2. 数据集处理:Dataset 和 DataLoader
深度学习的核心是批量处理数据 。PyTorch 通过 Dataset 和 DataLoader 解耦数据加载逻辑。
(1) 自定义 Dataset 类
python
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self, data_path, transform=None):
# 步骤1:加载数据(例如CSV、图像路径列表)
self.data = np.loadtxt(data_path, delimiter=",")
self.labels = self.data[:, -1] # 假设最后一列是标签
self.features = self.data[:, :-1]
self.transform = transform # 数据转换(稍后讲解)
def __len__(self):
return len(self.data) # 必须实现!返回数据集大小
def __getitem__(self, idx):
# 步骤2:按索引获取单个样本(关键!)
feature = self.features[idx]
label = self.labels[idx]
# 转换为Tensor(PyTorch要求输入是Tensor)
feature = torch.tensor(feature, dtype=torch.float32)
label = torch.tensor(label, dtype=torch.long)
# 应用数据转换(如图像增强)
if self.transform:
feature = self.transform(feature)
return feature, label # 返回 (input, target)(2) 使用 DataLoader 批量加载
python
# 创建Dataset实例
train_dataset = MyDataset("train.csv", transform=transforms.ToTensor())
# 使用DataLoader生成批次(自动打乱、多进程加载)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=32, # 每批32个样本
shuffle=True, # 训练时务必打乱
num_workers=4, # 多进程加载(根据CPU核心数调整)
pin_memory=True # 加速GPU传输(如果使用GPU)
)
# 遍历DataLoader(训练循环中常用)
for batch_idx, (inputs, targets) in enumerate(train_loader):
print(f"批次 {batch_idx}: 输入形状 {inputs.shape}, 标签形状 {targets.shape}")
# 输出示例: 批次 0: 输入形状 torch.Size([32, 10]), 标签形状 torch.Size([32])⚠️ 关键注意事项
__getitem__是核心 :必须返回(input, target)元组,且需是 Tensor 类型(PyTorch 不接受 NumPy 或 Python 原生类型)。num_workers设置 :- Windows 系统:设为
0(多进程在 Windows 有兼容问题)。 - Linux/Mac:设为 CPU 核心数(如
4),但过高会导致内存爆炸。
- Windows 系统:设为
- 内存瓶颈 :大型数据集(如 ImageNet)避免在
__init__中加载全部数据到内存!应在__getitem__中按需读取文件。 - 验证集/测试集 :
shuffle=False(评估时需固定顺序),num_workers可适当调低。
3. 数据转换:torchvision.transforms
图像任务必备!用于预处理和数据增强(Data Augmentation),提升模型泛化能力。
常用转换组合(以图像为例)
python
from torchvision import transforms
# 训练时的转换(包含增强)
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # 统一图像尺寸
transforms.RandomHorizontalFlip(), # 随机水平翻转(增强)
transforms.ColorJitter(brightness=0.2), # 随机调整亮度(增强)
transforms.ToTensor(), # 转为Tensor(值域[0,1])
transforms.Normalize( # 标准化(重要!)
mean=[0.485, 0.456, 0.406], # ImageNet 均值
std=[0.229, 0.224, 0.225] # ImageNet 标准差
)
])
# 测试时的转换(仅基础处理)
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 使用示例(在Dataset的__getitem__中调用)
# feature = self.transform(feature) # 前面MyDataset代码中已体现⚠️ 关键注意事项
- 标准化顺序 :必须在
ToTensor()之后 进行!因为ToTensor()会将像素值缩放到[0,1],而 Normalize 需要此范围。 - 增强仅用于训练 :测试集禁止使用 RandomHorizontalFlip 等随机增强,否则评估结果不可靠。
- 自定义转换 :对于非图像数据(如文本、时序),需自行实现
__call__方法(参考 PyTorch 官方文档)。
4. 神经网络构建:torch.nn 模块
PyTorch 的灵魂!所有神经网络层都继承自 nn.Module。
(1) 常用层与损失函数
| 类别 | 常用函数/类 | 说明 |
|---|---|---|
| 线性层 | nn.Linear(in_features, out_features) |
全连接层(输入维度 → 输出维度) |
| 卷积层 | nn.Conv2d(in_channels, out_channels, kernel_size) |
2D 卷积(图像任务核心) |
| 激活函数 | nn.ReLU(), nn.Sigmoid(), nn.LeakyReLU() |
通常作为单独层添加(动态图优势:无需指定输出尺寸) |
| 池化层 | nn.MaxPool2d(kernel_size), nn.AvgPool2d() |
下采样 |
| 损失函数 | nn.CrossEntropyLoss(), nn.MSELoss(), nn.BCELoss() |
CrossEntropyLoss = LogSoftmax + NLLLoss(分类任务直接用它!) |
| 优化器 | optim.SGD(model.parameters(), lr=0.01), optim.Adam(...) |
传入模型参数和学习率 |
(2) 定义神经网络模型(核心步骤)
python
import torch.nn as nn
import torch.nn.functional as F
class MyCNN(nn.Module):
def __init__(self, num_classes=10):
super(MyCNN, self).__init__() # 必须调用父类初始化!
# 定义网络层(在__init__中声明所有层)
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1) # 输入通道3(RGB), 输出16
self.pool = nn.MaxPool2d(2, 2) # 2x2 最大池化
self.fc1 = nn.Linear(16 * 112 * 112, 128) # 输入尺寸需计算(224x224图像经卷积池化后)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
# 定义前向传播(在forward中连接各层)
x = self.pool(F.relu(self.conv1(x))) # 卷积 → ReLU → 池化
x = x.view(-1, 16 * 112 * 112) # 展平(关键!-1表示自动计算batch size)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x # 返回未归一化的logits(CrossEntropyLoss内部处理Softmax)
# 实例化模型并移动到GPU
model = MyCNN(num_classes=10).to(device)
# 查看模型结构(超实用!)
print(model)
"""
MyCNN(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=200704, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
"""⚠️ 关键注意事项
__init__vsforward:__init__:只声明层 (不执行计算),所有层必须作为self属性注册。forward:定义数据流动逻辑 ,可使用F.relu(函数式)或nn.ReLU()(层对象),但后者需在__init__中声明。
- 展平操作 :
x.view(-1, ...)或torch.flatten(x, 1)。必须手动计算输入尺寸(例如 224x224 图像经 3x3 卷积+padding 后尺寸不变,再经 2x2 池化 → 112x112)。 - 激活函数位置 :ReLU 等通常放在卷积/全连接层之后 (如
F.relu(conv(x))),但不要放在输出层(CrossEntropyLoss 要求原始 logits)。 - 避免常见错误 :
- 忘记
super().__init__()→ 模型无法注册参数。 - 在
forward中定义新层 → 梯度无法回传(必须在__init__中定义)。
- 忘记
5. 训练循环:完整流程
结合前面所有组件,实现训练-验证闭环。
python
# 初始化
model = MyCNN().to(device)
criterion = nn.CrossEntropyLoss() # 分类任务标准损失
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
model.train() # 切换到训练模式(启用Dropout/BatchNorm)
running_loss = 0.0
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
# 步骤1: 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 步骤2: 反向传播 + 优化
optimizer.zero_grad() # 清空上一步梯度(极其重要!)
loss.backward() # 自动计算梯度
optimizer.step() # 更新参数
running_loss += loss.item()
# 步骤3: 验证(每轮结束后)
model.eval() # 切换到评估模式(禁用Dropout/BatchNorm)
val_loss = 0.0
correct = 0
with torch.no_grad(): # 禁用梯度计算(节省内存)
for inputs, targets in val_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
val_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs, 1)
correct += (predicted == targets).sum().item()
print(f"Epoch {epoch+1}/{num_epochs} | "
f"Train Loss: {running_loss/len(train_loader):.4f} | "
f"Val Loss: {val_loss/len(val_loader):.4f} | "
f"Val Acc: {correct/len(val_dataset)*100:.2f}%")⚠️ 关键注意事项
optimizer.zero_grad():必须在每次反向传播前调用!否则梯度会累积(常见 bug:loss 不下降)。- 训练/评估模式切换 :
model.train():启用 Dropout 和 BatchNorm 的训练行为。model.eval():禁用 Dropout,使用 BatchNorm 的全局统计量。- 评估时务必用
with torch.no_grad():,避免保存不必要的梯度,节省大量内存。
- 准确率计算 :
torch.max(outputs, 1)返回 (最大值, 索引),索引即预测类别。 - 过拟合处理 :如果训练 loss ↓ 但验证 loss ↑,说明过拟合。可添加 Dropout (
nn.Dropout(0.5)) 或 L2 正则化(weight_decay参数传入优化器)。
6. 模型保存与加载:最佳实践
永远不要保存整个模型对象! 只保存 state_dict(参数字典),确保未来兼容性。
保存模型
python
# 保存训练好的模型
PATH = "my_model.pth"
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, PATH)
# 仅保存模型参数(最常用)
torch.save(model.state_dict(), "model_only.pth")加载模型
python
# 方法1:加载到相同结构的模型(推荐)
model = MyCNN(num_classes=10).to(device)
model.load_state_dict(torch.load("model_only.pth", map_location=device))
model.eval() # 确保切换到评估模式
# 方法2:加载完整训练状态(用于恢复训练)
checkpoint = torch.load(PATH, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']⚠️ 关键注意事项
map_location参数 :必须指定 !否则在 GPU 训练的模型在 CPU 上加载会报错。map_location=device自动适配当前设备。- 严格匹配结构 :加载的
state_dict必须与模型结构完全一致。如果修改了网络层名称/数量,需手动处理(用strict=False忽略不匹配键)。 - 评估前调用
model.eval():即使只做预测,也需切换模式(影响 BatchNorm 和 Dropout)。 - 保存整个模型的陷阱 :
torch.save(model, ...)会保存 Python 类定义,但未来 PyTorch 版本升级可能导致兼容问题。
TensorFlow 简要对比
- 你只需要知道核心差异,无需深入。
- PyTorch 是"命令式编程"(写代码即执行),TensorFlow 2.x 是"声明式编程"(先定义图再执行,但 Eager Mode 模仿了 PyTorch)。以下是等效代码对比:
PyTorch vs TensorFlow 2.x 代码对比表
| 功能 | PyTorch 代码 | TensorFlow 2.x 代码 | 关键区别 |
|---|---|---|---|
| 张量创建 | x = torch.tensor([1,2,3]) |
x = tf.constant([1,2,3]) |
几乎相同 |
| 自动求导 | x.requires_grad = True y.backward() |
with tf.GradientTape() as tape: grads = tape.gradient(y, x) |
PyTorch 更简洁;TF 需显式创建梯度记录器 |
| 模型定义 | 继承 nn.Module,写 forward() |
继承 tf.keras.Model,写 call() |
高度相似(Keras API 统一了 TF2 风格) |
| 训练循环 | 手动写训练循环(更灵活) | 通常用 model.fit()(高层API) |
PyTorch 调试更直观;TF fit() 简洁但自定义难 |
| 动态图支持 | 原生动态图(默认) | Eager Execution(默认开启) | 核心区别消失:TF2 默认 Eager 后与 PyTorch 体验接近 |
| 部署 | TorchScript / LibTorch | TF SavedModel / TF Lite | TF 生态更成熟(尤其移动端) |
| 调试 | 直接 print()/pdb 断点 | 需用 tf.print() 或关闭 Eager |
PyTorch 胜出:动态图让调试像普通 Python |
TensorFlow 2.x 极简示例(MNIST 分类)
python
import tensorflow as tf
# 1. 加载数据
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1).astype("float32") / 255.0
# 2. 定义模型(Keras 风格)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16, 3, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
# 3. 编译并训练(高度封装)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
# 4. 保存模型
model.save("tf_model") # SavedModel 格式(部署友好)Python进阶------Pytorch 优化
集束搜索(Bean Search) 算法
-
是Beam Search(束搜索)算法,这是一个在搜索空间中寻找近似最优解的算法,常用于解决组合优化问题和序列生成任务
-
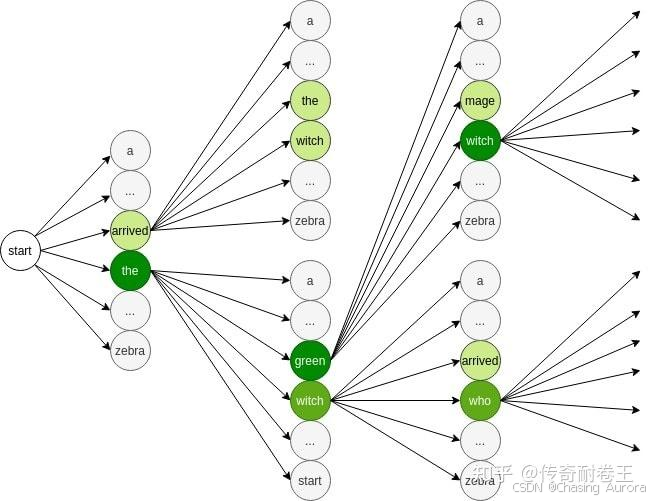
-
宽度参数 k:算法在每一步只保留 k 个最有希望的候选解(称为"束宽")
-
它是广度优先搜索的改进版本,通过保持固定数量的最佳候选解来控制搜索空间。
- 通俗解释:如果使用广度优先搜索,你需要探索每一条可能的路径。而使用 Beam Search,你只关注最有希望的几条路径
dropout
- dropout 是正则化技术,为了防止过拟合 ,随机丢弃一些神经元的输出,在训练时使用,在测试时不使用
- 在训练过程中随机"丢弃"一部分神经元,使其暂时不参与计算,从而减少神经元之间的的复杂共适应关系,提升模型的泛化能力。
- 在每次训练选代中,Dropout会以一定的概率(称为Dropout率)随机选择部分神经元,将其输出置为零,同时保留其他神经元的输出。这样,每次选代实你上是在训练一个不同的子网络,而最终的模型可以看作是这些子网络的集合平均
powershell
import torch
import torch.nn as nn
# 定义一个简单的神经网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(784, 256) # 全连接层
self.dropout = nn.Dropout(p=0.5) # Dropout层,丢弃率为50%
self.fc2 = nn.Linear(256, 10) # 输出层
def forward(self, x):
x = torch.relu(self.fc1(x)) # 激活函数
x = self.dropout(x) # 应用Dropout
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleNet()
print(model)torch.nn
nn.Parameter
nn.Parameter是PyTorch中的一个类,用于将不可训练的Tersor转换为可训练的参数,并将其绑定到模型中- 这意味着在模型训练过程中,这些参数会随着反向传播进行更新
powershell
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.weight = nn.Parameter(torch.randn(2, 2))
def forward(self, x):
return x * self.weight
model = MyModel()
print(model.weight)nn.Linear
nn.Linear默认只对张量的最后一个维度 进行线性变换,也就是只看张量的 最后一个维度,必须和 in_features 相等,前面所有维度,原封不动保留- 也就是 输出张量的形状 =
(前面所有维度, out_features)
- 也就是 输出张量的形状 =
- 本质是因为nn.Linear(in_features, out_features) 的核心操作是一个矩阵乘法加上一个偏置:
output = input @ weight.T + bias。这里的 @ 表示矩阵乘法- 比如:32, 10, 768 @ 768, 256.T = 32, 10, 256
torch
torch.ones()和torch.zeros()
powershell
x = torch.full(size=(2,3),fill_value=5)
# 返回创建size大小的维度,里面元素全部填充为fill_value
# 输出结果如下:
tensor([[5, 5, 5],
[5, 5, 5]])
a = torch.ones(2, 3)
# 返回创建size大小的维度,里面元素全部填充为1
# 输出结果如下:
(tensor([[1., 1., 1.],
[1., 1., 1.]])
a = torch.zeros(2, 3)
# 返回创建size大小的维度,里面元素全部填充为0
# 输出结果如下:
(tensor([[0., 0., 0.],
[0., 0., 0.]])torch.zeros_like()
- torch.zeros_like(tensor):是根据给定张量,生成与其形状相同的全0张量
- torch.zeros(size):其形状由变量参数size定义,返回一个由标量值0填充的张量
powershell
import torch
input = torch.rand(2, 3)
print(input)
# 生成与input形状相同、元素全为0的张量
a = torch.zeros_like(input)
print(a)
# 报错:类型错误TypeError
b = torch.zeros(input)
print(b)
# 生成大小为【3】的0张量
c = torch.zeros(3)
print(c)
# 生成大小为【2,3】的0张量
d = torch.zeros([2,3])
print(d)torch.empty()
torch.empty()函数是 PyTorch 中用于创建一个未初始化的张量的函数- 它创建一个指定大小的张量,但不会对张量的元素进行初始化,值取决于张量所在内存的状态,因此这个张量的值可能是随机的
- 如果创建一个初始化为零或其他特定值的张量,可以使用 torch.zeros() 或 torch.ones() 等函数
squeeze()和unsqueeze()
- squeeze(index)会将张量中第index维度,且大小为1的维度进行去除,从而减少张量的维度
- unsqueeze(index)会在该张量的第index维度上增加一个维度值为1的维度,例如维度是(3, 2, 1)
torch.arange()
torch.arange()是PyTorch中用于生成一维张量的函数 。该函数通过指定起始值、终止值和步长来生成一个等差数列的张量,返回的是左闭右闭[start,end]
powershell
import torch
# 默认以 0 为起点
tensor1 = torch.arange(5)
print(tensor1) # 输出: tensor([0, 1, 2, 3, 4])
# 指定起始值和结束值
tensor2 = torch.arange(1, 4)
print(tensor2) # 输出: tensor([1, 2, 3])
# 指定步长
tensor3 = torch.arange(1, 2.5, 0.5)
print(tensor3) # 输出: tensor([1.0000, 1.5000, 2.0000])torch.randn()、torch.randn()、 torch.randint()
torch.rand()函数用于生成具有均匀分布的随机数,这些随机数的范围在[0, 1)之间。它接受一个形状参数(shape),返回一个指定形状的张量(Tensor)- torch.randn()函数用于生成具有标准正态分布的随机数,即均值为0,标准差为1的随机数。它同样接受一个形状参数,并返回一个指定形状的张量
- torch.randint()函数用于生成指定范围内的整数随机数。它接受三个参数:low(最小值)、high(最大值)和形状(shape)
powershell
# 生成一个形状为(3, 4)的张量,元素值在[0, 1)之间
tensor = torch.rand((3, 4))
# 生成一个形状为(3, 4)的张量,元素值服从标准正态分布
tensor = torch.randn((3, 4))
# 生成一个形状为(3, 4)的张量,元素值在[0, 10)之间
tensor = torch.randint(0, 10, (3, 4))torch.repeat_interleave()、torch.repeat()、torch.tile()
repeat是在整个张量粒度上进行复制操作,而repeat_interleave是沿着张量某一维进行指定次数的复制操作- repeat()、tile() 传入一个元组的话, 表示 (行复制次数, 列复制次数)
torch.tile函数也是元素复制的一个函数, 但是在传参上和torch.repeat不同,但是也是以input为一个整体进行复制,当传入的参数少于需要复制的元素的维度时,从后填充,前边默认都是1
powershell
import torch
x = torch.randn(2, 2)
print(x)
>>> tensor([[ 0.4332, 0.1172],
[ 0.8808, -1.7127]])
print(x.repeat(2, 1))
>>> tensor([[ 0.4332, 0.1172],
[ 0.8808, -1.7127],
[ 0.4332, 0.1172],
[ 0.8808, -1.7127]])
print(x.repeat_interleave(2, dim=0))
>>> tensor([[ 0.4332, 0.1172],
[ 0.4332, 0.1172],
[ 0.8808, -1.7127],
[ 0.8808, -1.7127]])
print(x.repeat_interleave(2, dim=1))
>>> tensor([[ 0.4332, 0.4332, 0.1172, 0.1172],
[ 0.8808, 0.8808, -1.7127, -1.7127]])
# 如果不传dim参数, 则默认复制后拉平
print(x.repeat_interleave(2))
>>> tensor([ 0.4332, 0.4332, 0.1172, 0.1172, 0.8808, 0.8808, -1.7127, -1.7127])torch.cat()
- 于在给定维度上拼接张量序列,
torch.cat(tensors, dim=0, *, out=None) → Tensor
powershell
import torch
# 创建三个三维张量
tensor1 = torch.rand((2, 3, 4))
tensor2 = torch.rand((2, 3, 4))
tensor3 = torch.rand((2, 3, 4))
# 在第二维度上拼接张量
result = torch.cat((tensor1, tensor2, tensor3), dim=1)
print(result.shape) # torch.Size([2, 9, 4])torch.mean()
- input,输出是一个张量(tensor),注意如果不是tensor可以通过
torch.tensor转换为tensor - dim,取平均值的维度,默认值是对tensor里的所有元素取平均值
- keepdim,即保留张量的维度,因为取平均值后肯定是降维的,但是keepdim=True可以使得输出张量的维度与输入张量保持一致
powershell
import torch
matrix = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
tensor = torch.tensor(matrix),float()
torch.mean(tensor, dim=0) # tensor([4.,5.,6.])
torch.mean(tensor, dim=0, keepdim=True) # tensor([[4.,5.,6.]])Tensor 操作
广播机制(broadcast)
- 如果一个PyTorch操作支持广播,则其Tensor参数可以自动扩展为相等大小(不需要复制数据)。通常情况下,小一点的数组会被 broadcast 到大一点的,这样才能保持大小一致
- 从末尾随开始遍历,tensor维度不等且其中一个维度为1 ,是可以进行广播的,维度值取两个tensor中较大的那个值
- 有时候就会指定通过
squeeze以及unsqueeze具体 改变哪个维度 - 因为如果两个tensor的维度不同,则默认在维度较小的tensor的前面增加维度,使它们维度相等
- 有时候就会指定通过
powershell
# x 和 y 可以广播
x=torch.ones(5,3,4,1)
y=torch.ones( 3,1,1)
# 从尾部维度开始遍历
# 1st尾部维度: x和y相同,都为1。
# 2nd尾部维度: y为1,x为4,符合维度不等且其中一个维度为1,则广播为4。
# 3rd尾部维度: x和y相同,都为3。
# 4th尾部维度: y维度不存在,x为5,符合维度不等且其中一个维度不存在,则广播为5。
# x 和 y 不可以广播,因为3rd尾部维度x为2,y为3,不符合维度不等且其中一个维度为1。
x=torch.ones(5,2,4,1)
y=torch.ones( 3,1,1)多维矩阵运算------⭐
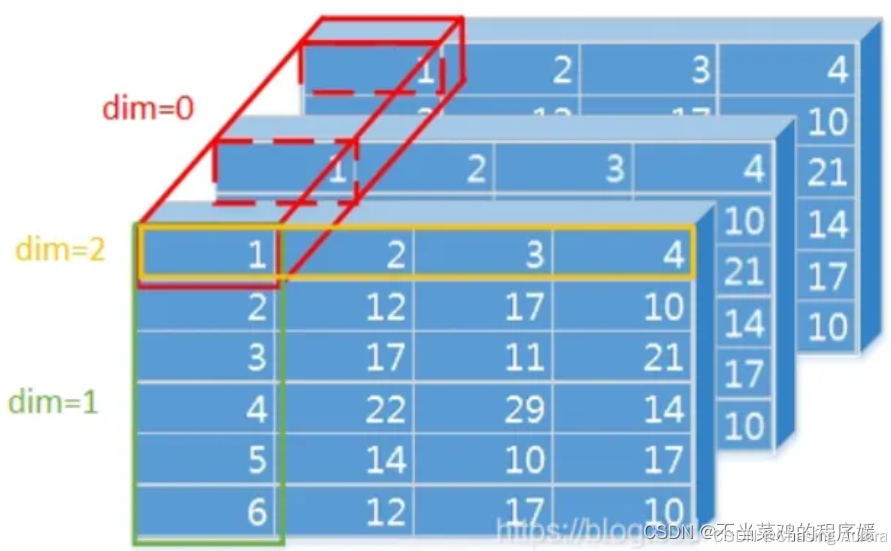
- 看维度的小技巧:想知道一个矩阵的维度是几维的,只需要看开头有几个"[",有1个即为1维,上面的两个就是两维,后面举到的三维和四维的例子,分别是有三个"["、四个"["的。
- 所有大于二维的,最终都是以二维为基础堆叠在一起的!!
- 所以在矩阵运算的时候,其实最后都可以转成我们常见的二维矩阵运算,遵循的原则是:在多维矩阵相乘中,需最后两维满足shape匹配原则,最后两维才是有数据的矩阵,前面的维度只是矩阵的排列而已!
- 对于转置:K: (32, 8, 10, 64) -> 转置 K 的最后两维 -> K^T: (32, 8, 64, 10),所以代码中就经常是
torch.matmul(query, key.transpose(-2, -1)) - 对于乘法:(32, 8, 10, 64) @ (32, 8, 64, 10) = (32, 8, 10, 10)
- 对于softmax,最后一维是特征维度,所以代码中经常就是
self_attn = F.softmax(scores, dim=-1)
torch.dtype、torch.device和torch.layout
- pytorch从0.4开始提出了Tensor Attributes,主要包含了torch.dtype,torch.device,torch.layout。pytorch可以使用他们管理数据类型属性
torch.flatten()、x.view()和x.reshape() 操作的区别
x.view() - "视图":要求严格,效率高
- 作用 :返回一个共享相同底层数据的新张量,但形状(shape)被改变了。
- 核心限制 :要求张量在内存中必须是连续的(contiguous),如果不连续,它会直接报错
- 比喻:就像你戴上一副不同形状的眼镜看同一个物体,物体本身没变,只是你观察它的方式变了。但前提是物体必须完好无损(内存连续)。
例子:
python
import torch
# 创建一个连续的张量
x = torch.arange(12) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
print(x.is_contiguous()) # 输出: True
# 使用 view 改变形状,完全没问题
y = x.view(3, 4)
print(y)
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# 现在进行一个会使内存非连续的操作
x_t = x.view(3, 4).transpose(0, 1) # 转置操作
print(x_t.is_contiguous()) # 输出: False!因为转置打乱了内存顺序
# 尝试对非连续张量使用 view,会报错!
try:
z = x_t.view(12)
except RuntimeError as e:
print(e)
# 报错信息:RuntimeError: view size is not compatible with input tensor's size and stride
# (at least one dimension spans across multiple contiguous subspaces).
# Use .reshape(...) instead.x.reshape() - "重塑":更智能、更宽容
- 作用:也是改变形状,并返回共享数据的新张量。
- 核心优势 :它不要求张量是连续的 。
- 如果张量是连续的,它的行为和
view()完全一样,返回一个视图(共享数据,高效)。 - 如果张量是非连续的,它会悄悄地创建一个数据的副本(使其连续),然后再改变形状。这保证了它总能成功,但可能会消耗更多内存
- 懒人首选!
- 如果张量是连续的,它的行为和
- 比喻:就像一个智能的魔术师。如果物体完好无损(连续),它就直接变个戏法(视图);如果物体碎了(非连续),它会先用胶水粘好(创建副本),再变戏法。
例子(接上面的代码):
python
# 对刚才转置后非连续的 x_t 使用 reshape
z = x_t.reshape(12) # 成功了!
print(z)
# tensor([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
# 检查 z 和 x_t 是否共享数据?
x_t[0, 0] = 999
print(z[0]) # 输出: 0。因为 reshape 创建了副本,所以修改 x_t 不会影响 z
# 而如果用 view 成功的情况,它们是共享数据的
a = torch.arange(12)
b = a.view(3, 4)
b[0, 0] = 999
print(a[0]) # 输出: 999。因为 view 共享数据,修改 b 就是修改 atorch.flatten() - "展平":一个专用的便捷函数
- 作用 :将张量展平成一维(1D tensor)。
- 本质 :它基本上是
reshape(-1)或view(-1)的一个封装,但语义更清晰,-1表示自动计算维度== - 参数 :可以指定从哪个维度开始展平。
flatten(input, start_dim=0):从第0维开始展平,整个张量变成一维。flatten(input, start_dim=1):保持第0维(batch维)不变,展平后面的所有维度。这在神经网络中非常常用!
例子:
python
x = torch.arange(12).view(2, 2, 3)
print(x)
# tensor([[[ 0, 1, 2],
# [ 3, 4, 5]],
#
# [[ 6, 7, 8],
# [ 9, 10, 11]]])
print(x.shape) # torch.Size([2, 2, 3])
# 完全展平
flat_all = torch.flatten(x)
print(flat_all) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
print(flat_all.shape) # torch.Size([12])
# 从第1维开始展平(保留batch维)
flat_from_dim1 = torch.flatten(x, start_dim=1)
print(flat_from_dim1)
# tensor([[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11]])
print(flat_from_dim1.shape) # torch.Size([2, 6]) <- 非常常用!.contiguous() 方法
- 经过某些操作(如 transpose)后,数据会在内存中的顺序被打乱了
- 作用 :返回一个内存连续的张量副本 。
- 如果原始张量已经是连续的,它直接返回自己(不创建副本)。
- 如果原始张量是非连续的,它会创建一个新的、内存连续的副本。
- 为什么需要它? 主要是为了配合
view()使用。因为view()严格要求内存连续,所以在对非连续张量(如transpose、permute后的结果)调用view()之前,必须先调用.contiguous()
经典例子(在多头注意力中就有!):
python
# 假设 x 是经过 transpose 后的非连续张量
x = torch.arange(12).view(3, 4).transpose(0, 1)
print(x.is_contiguous()) # False
# 直接 view 会报错
# x.view(12) # RuntimeError!
# 正确做法:先 contiguous,再 view
x_cont = x.contiguous() # 现在内存连续了
print(x_cont.is_contiguous()) # True
y = x_cont.view(12) # 成功!
print(y)有了view为什么还有tranpose?
view()的本质 只是重新 定义张量的形状,但是不会对 张量本身 做任何重新排列tranpose()会 改变张量的 排列顺序的 ,从而 达到真正的转置
powershell
import torch
a = torch.tensor([[[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12]]])
print(a.shape)
b = a.transpose(1, 2)
c = a.view((1, 3, -1))
print("Here is Tensor b:\n")
print(b)
print(b.shape)
print("Here is Tensor c:\n")
print(c)
print(c.shape)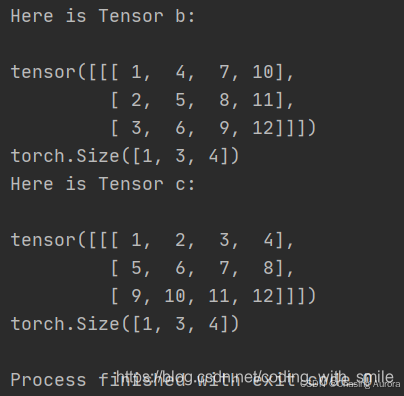
两大转置函数 transpose() 和 permute()
powershell
x = x.transpose(0,1) # 交换第0维度和第1维度
等价于
x.transpose_()
# 相当于x = x + 1 简化为 x+=1- 在pytorch中经常加后缀"_"来代表原地操作符,例:.add_()、.scatter()。in-place操作不允许tensor像广播那样改变形状
- transpose()只能一次操作两个维度 ;permute()可以一次操作多维数据,且必须传入所有维度数 ,因为permute()的参数是
int*- transpose()中的dim没有数的顺序区分;permute()中的dim可以看作重新排列对应维度
powershell
# 创造二维数据x,dim=0时候2,dim=1时候3
x = torch.randn(2,3) 'x.shape → [2,3]'
# 创造三维数据y,dim=0时候2,dim=1时候3,dim=2时候4
y = torch.randn(2,3,4) 'y.shape → [2,3,4]'
# 对于transpose
x.transpose(0,1) 'shape→[3,2] '
x.transpose(1,0) 'shape→[3,2] '
y.transpose(0,1) 'shape→[3,2,4]'
y.transpose(0,2,1) 'error,操作不了多维'
# 对于permute()
x.permute(0,1) 'shape→[2,3]'
x.permute(1,0) 'shape→[3,2], 注意返回的shape不同于x.transpose(1,0) '
y.permute(0,1) "error 没有传入所有维度数"
y.permute(1,0,2) 'shape→[3,2,4]'target.scatter(dim, index, src)
- scatter() 不会直接修改原来的 Tensor,而 scatter_() 会在原来的基础上对Tensor进行修改
- 在PyTorch中, scatter函数用于将一个源张量中的值根据索引写入到目标张量的指定位置
powershell
import torch
# 创建一个零张量
x = torch.zeros(3, 5, dtype=torch.long)
输出:
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
##记住这个例子中x是目标张量,也就是上面说的target
# 定义一个索引张量
index = torch.tensor([[0, 0, 0, 0, 0],
[2, 2, 2, 2, 2]])
##index就是在target张量中需要填充的位置。
# 定义一个源张量
src = torch.tensor([[10, 10, 10, 10, 10],
[20, 20, 20, 20, 20]])
y=x.scatter_(0, indices, src)
print(y)
输出:
tensor([[10., 10., 10., 10., 10.],
[ 0., 0., 0., 0., 0.],
[20., 20., 20., 20., 20.]]).double().item() 方法
- 是 PyTorch 中常用的链式操作,主要用于将张量转换为双精度浮点数(float64)并提取其标量值
.item()用于在只包含一个元素的tensor中提取值,注意是只包含一个元素,否则的话使用.tolist()- 在训练过程中,使用 loss.item() 可以防止张量无限叠加导致的显存爆炸,避免显存消耗过大
powershell
total_loss = 0
for data, target in dataloader:
output = model(data)
loss = criterion(output, target)
total_loss += loss.item()