一、基础背景
1.线性注意力的核心定义
线性注意力机制(Linear Attention)是针对标准注意力机制(Softmax Attention)平方复杂度瓶颈提出的优化方案,核心目标是将注意力计算复杂度从标准注意力的O(N²d)(N为序列长度,d为特征维度)降至O(Nd²),通过数学结构优化,在保证一定表达能力的前提下,大幅提升长序列场景下的计算效率和显存利用率,适用于需要实时处理、长序列建模的场景(如4K视频处理、DNA序列分析等)。
2. 标准Softmax注意力的核心逻辑
-
计算流程:先计算查询向量(Q)与键向量(K)的转置乘积,得到N×N的注意力矩阵,再经过Softmax归一化得到注意力权重,最后与值向量(V)相乘输出结果。
QKT→Softmax→VQK^T \rightarrow \text{Softmax} \rightarrow VQKT→Softmax→V,时间/空间复杂度为 O(n2)O(n^2)O(n2)(nnn为序列长度)。当序列长度N增大(如达到100万)时,N²会呈现指数级增长(100万序列对应1万亿个元素),导致计算量激增、显存占用过高,甚至出现内存溢出,无法处理超长序列任务,这也是线性注意力应运而生的核心原因。 -
Softmax的核心作用:
- 归一化将相似度转换为概率分布
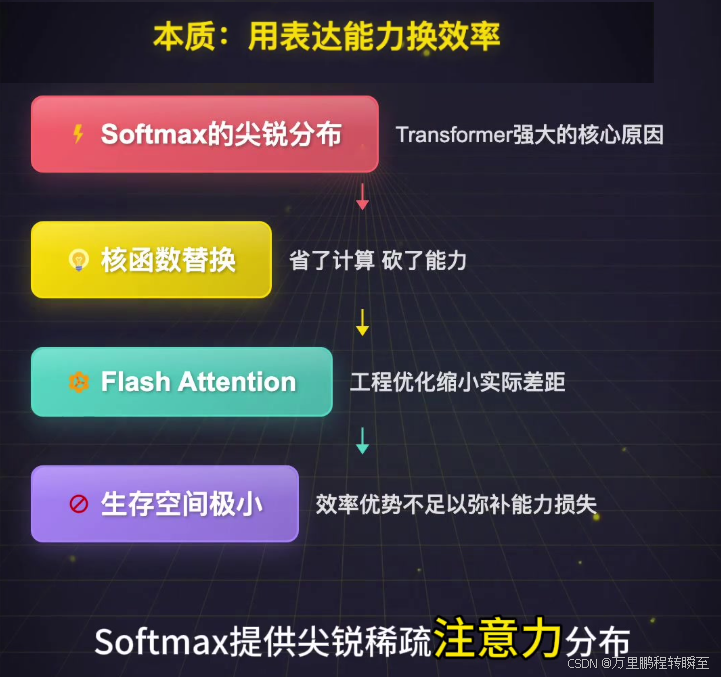
- 指数放大效应是核心 :通过指数函数极端放大原始相似度的差距,形成赢者通吃的尖锐稀疏注意力分布 ,让模型能够精准聚焦最相关的少数token,这是Transformer性能强大的核心原因之一
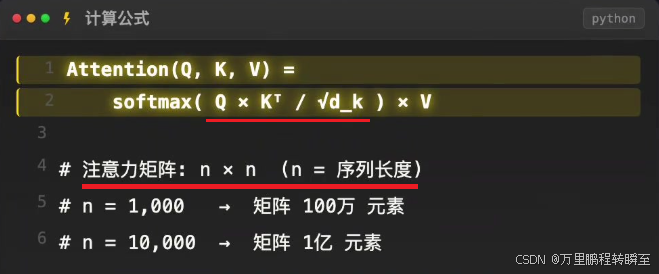


3. 线性注意力的核心原理
线性注意力放弃了标准注意力中用于放大相似度差距的Softmax函数,改用核函数(特征映射函数)对Q和K进行处理,常见核函数如ϕ(x)=elu(x)+1(确保输出非负),核心目的是将Q和K分别映射到新的特征空间,使后续计算可拆分、可复用,同时保留"衡量Q与K相似度"的核心功能。
与Softmax的区别:Softmax通过指数函数极端放大Q与K的相似度差距,形成"赢者通吃"的尖锐注意力分布;核函数的非线性放大效应更温和,仅对原始相似度做适度变换,虽能保留全局交互能力,但会弱化关键特征的区分度。
- 优化目标:解决标准注意力的O(n2)O(n^2)O(n2)复杂度问题
- 核心思路:将Softmax中的指数函数替换为可分离的核函数 ,利用矩阵乘法结合律调整计算顺序:先计算变换后KKK的转置乘VVV,得到大小固定的d×dd \times dd×d中间矩阵(ddd为单个注意力头的维度,通常仅64/128,远小于原来的n×nn \times nn×n序列长度通常在几千以上),再用变换后的QQQ乘该矩阵,最终复杂度降为O(n)O(n)O(n)
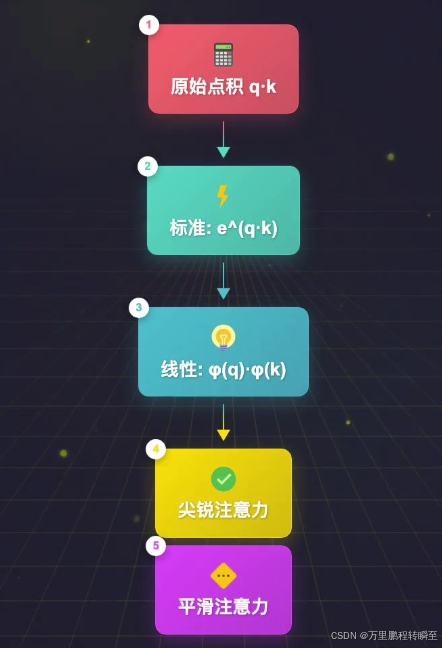
- 具体步骤:标准注意力中,Q与K的转置乘积被Softmax"锁定",无法拆分,必须先计算完所有Q与K的两两相似度(即N×N矩阵),才能进行后续操作;而线性注意力中,核函数处理后的Q(记为ϕQ)和K(记为ϕK),其点积计算可利用矩阵乘法结合律调整计算顺序:
-- 标准注意力顺序(不可拆分):(Q @ K.T) @ V → 先算N×N矩阵,再与V相乘
-- 线性注意力顺序(可拆分):Q @ (K.T @ V) → 先算K.T @ V(得到d×d小矩阵,d为特征维度,通常为64或128),再与Q相乘
当d=64时,d²=4096,远小于N²(如N=1000时N²=100万),无论序列长度N如何增大,d×d中间矩阵的大小始终不变,从而将计算复杂度从O(N²d)降至O(Nd²),实现线性化。

示意代码
py
# 线性注意力伪代码(线性复杂度)
def linear_attention(Q, K, V, kernel=lambda x: elu(x)+1):
# 1. 核函数处理Q和K,映射到新特征空间
phi_Q = kernel(Q)
phi_K = kernel(K)
# 2. 先计算中间小矩阵(d×d),复用计算结果
intermediate = phi_K.T @ V
# 3. 最终输出,避免构建N×N矩阵
output = phi_Q @ intermediate
return output3.1 计算效率与显存优势显著
复杂度降至O(Nd²)后,序列长度N翻倍时,计算量仅翻倍(而非标准注意力的4倍),显存占用也从O(N²)降至O(Nd),可轻松处理超长序列(如N=100万),在4K视频实时处理、DNA序列分析等场景中,延迟和显存占用远低于标准注意力(如4K图像处理时,计算量可降低千倍)。
3.2 天然支持自回归推理
线性注意力中,核函数处理后的K.T @ V可看作一个"压缩状态",每新增一个token,无需回头重新计算所有历史token的注意力,仅需更新这个压缩状态即可,自回归推理时每一步为常数时间,大幅提升推理效率,适配移动端AR滤镜等实时推理场景。
3.3 适配GPU并行计算
线性注意力的核心计算的是矩阵乘法(phi_K.T @ V、phi_Q @ intermediate),而矩阵乘法是GPU最擅长的计算模式,可充分利用GPU算力,进一步提升运行速度。
二、线性注意力未成为主流的核心原因
1. 核心缺陷:存在可感知的效果损失
线性注意力本质是用表达能力换效率 :核函数的放大效应远弱于Softmax,无法形成"赢者通吃"的尖锐注意力分布,导致注意力被迫分散到多个token,无法精准聚焦关键信息。此外,部分核函数(如elu(x)+1)不具备单射性(不同输入可能映射到相同输出),会导致语义混淆(如猫狗特征映射后难以区分),在人脸眼部识别、长文关键句定位等需要精准聚焦的任务中,精度远低于标准注意力(如人脸眼部识别,标准注意力精度92%,线性注意力仅62%)。
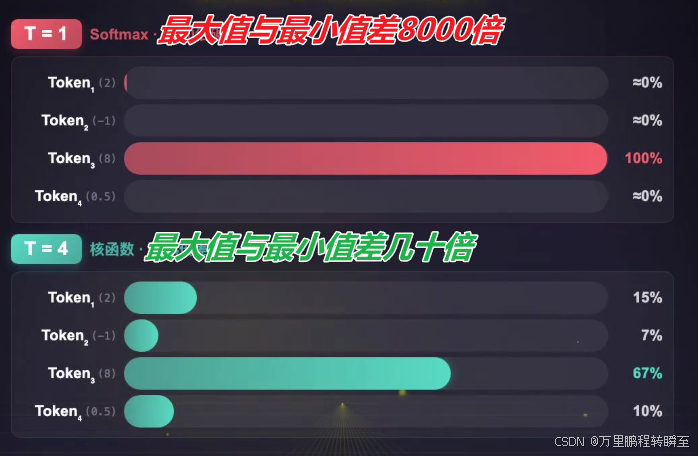

实际影响:在需要精准定位上下文的任务(如长文本信息检索、上下文复制)性能下降明显,困惑度通常上涨1-2个点,生成质量有肉眼可见的差距。

2. 工程对手变强:Flash Attention大幅缩小效率差距
线性注意力提出时对标朴素实现的标准注意力,后者确实存在速度慢、显存占用高的问题;但Flash Attention通过IO感知等工程优化,将标准注意力的显存占用降到O(n)O(n)O(n),实际速度提升数倍。
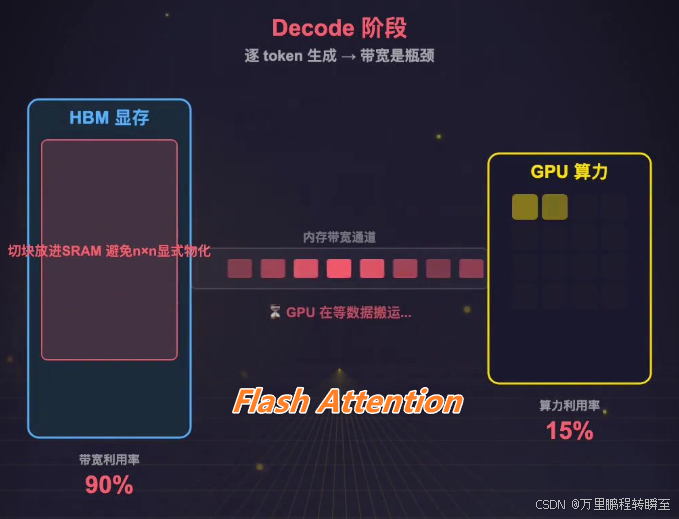
在主流大模型的常用序列长度区间(2k-8k)已经足够快,线性注意力的理论效率优势不再突出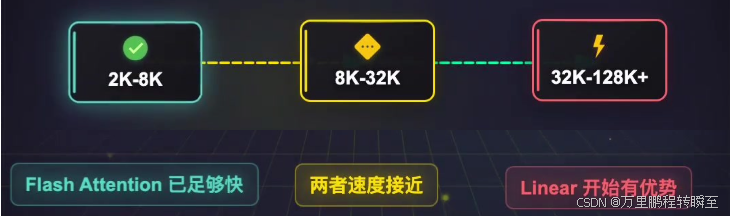
3. 隐藏复杂度代价,硬件适配性差
- 线性注意力实际复杂度为 O(n⋅d2)O(n \cdot d^2)O(n⋅d2),d2d^2d2的常数项不可忽略
- 训练时需要维护d×dd \times dd×d压缩状态的梯度,并行效率低于标准注意力(这一阶段虽然计算量低,但并未重复利用显卡计算能力)
- 标准注意力的核心计算是大规模矩阵乘法,刚好契合GPU的硬件特性,硬件利用率远高于线性注意力
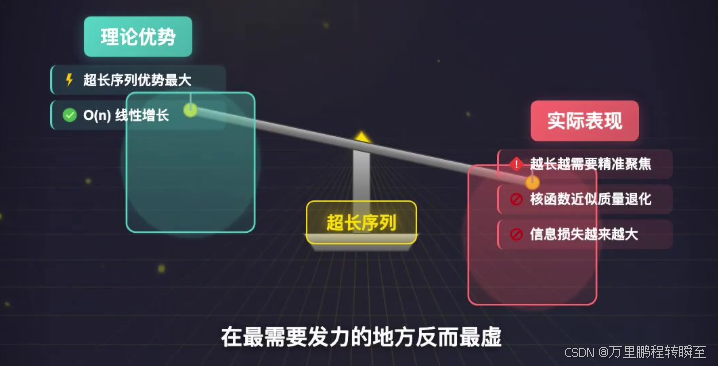
4. 最需要发力的场景反而效果退化
线性注意力理论上最适配超长序列场景,但序列越长,越需要模型精准聚焦关键token,线性注意力模糊分布带来的信息损失就越严重,近似质量退化越明显。
三、总结
线性注意力通过牺牲Softmax带来的精准聚焦能力换取更低的理论复杂度,在效果和实际工程效率上都没有明显优势,再加上Flash Attention对标准注意力的工程优化,生存空间被大幅压缩。这也推动后续研究转向Mamba这类完全重构序列建模框架的SSM模型,而非对Softmax注意力做近似。
四、线性注意力改进方案
4.1 核函数优化
通过ReLU过滤负值、L2归一化增强特征区分度,设计专用聚焦函数,提升注意力权重的集中度,可使权重集中度提升,有效缓解语义混淆问题,其核心代码如下:
py
def focus(x):
x = relu(x) # 过滤负值,强化有效特征
return x / norm(x, 2) # L2归一化,增强特征区分度4.2 深度卷积补偿(DWC)
在 linear attention 后添加深度卷积层,补足局部感知能力,像给"轰炸机"加"显微镜",兼顾全局效率和局部精度,适配4K视频处理等需要兼顾效率和细节的场景。
4.3. 动态核函数与混合架构
采用动态核函数(如Performer的随机映射),根据输入内容自动选择合适的核函数,平衡精度与效率;或采用"线性注意力+标准注意力"混合架构,在长序列场景用线性注意力保证效率,在关键局部用标准注意力保证精度,兼顾两者优势。