文章目录
一、引言
登录一台卡顿的服务器,面对满屏的数字和日志,最怕的不是找不到命令,而是没有头绪地乱敲。系统卡顿、客户端频繁断线,这类问题往往不是单一因素导致的。CPU、内存、磁盘、网络,任何一个环节成为瓶颈,都可能引发连锁反应。但很多人在排查时,要么一头扎进应用日志,要么随机执行几个命令,结果被海量信息淹没,迟迟找不到根因。
其实,高效的排查遵循一套固定的逻辑:先看全局资源,再定位瓶颈点,最后深挖具体进程。这套方法论可以帮你快速缩小范围,避免在噪音中迷失。本文聚焦 Linux 系统层面的排查,围绕 CPU、内存、磁盘、网络四个维度,给出每个环节的关键命令、核心指标解读,以及常见问题的判断依据。
二、top全局:系统在忙什么?
top命令 是系统体检的"血常规",一眼看清全局。
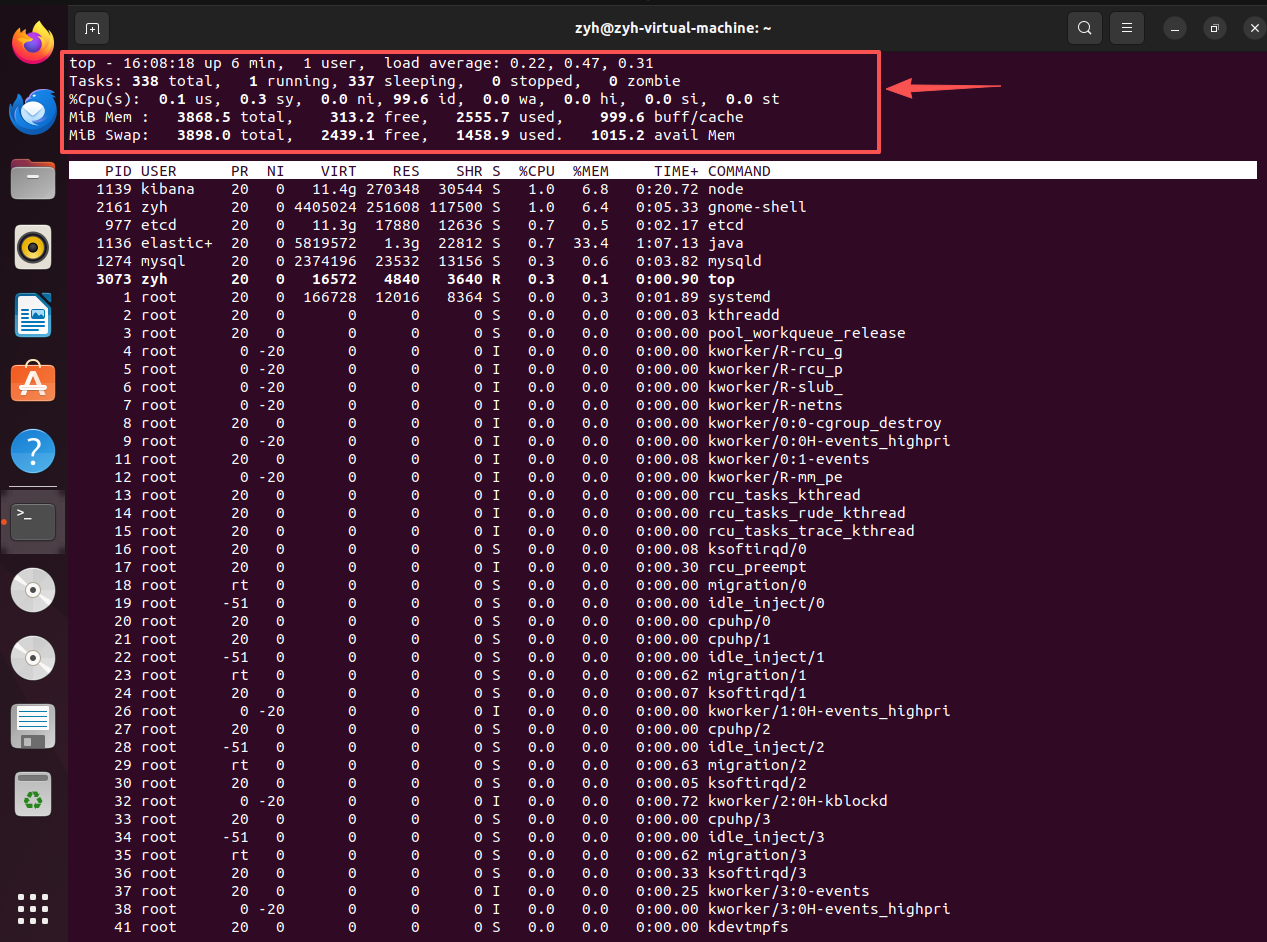
第一行:系统概况
包括当前时间、系统已运行的时间、用户数量、以及平均负载(load average)
load average:过去1分钟、5分钟、15分钟的平均负载;平均负载是指系统在特定时间间隔内处于可运行状态或不可中断睡眠状态的进程的平均数量。简单来说,它反映了系统的繁忙程度,而不仅仅是CPU的使用率。并且其数值是平均值,而不是整数计数,例如:
负载0.5表示系统在这段时间内有50%的时间是繁忙的
负载1.0表示正好有一个进程持续占用资源
负载1.5表示平均有1.5个进程在竞争资源
若 load average 超过 CPU 核心数(例如4核,负载>4),说明有进程在排队,系统"过载"。注意:负载高不一定是CPU忙,也可能是I/O等待(进程在等磁盘)。
第二行:进程概括
包括进程总数、正在运行的进程数、休眠进程数、被暂停进程数、僵尸进程数
对于该行,尤其需要注意zombie进程数,如果僵尸进程过多,说明可能存在父进程存在缺陷。
第三行:CPU 状态
- us (user) - 用户空间进程的CPU时间百分比,过高说明应用程序消耗CPU。
- sy (system) - 内核空间进程的CPU时间百分比,过高可能涉及频繁的上下文切换或驱动问题。
- ni (nice) - 调整过优先级的用户进程的CPU时间百分比
id (idle) - CPU空闲时间百分比,如果长期 <10% 且 us+sy 高,则CPU饱和。- wa (I/O wait) - CPU等待I/O操作完成的时间百分比,这是重点关注项。如果 wa > 10% 且持续,说明磁盘或网络I/O成为瓶颈,进程在等I/O完成。
- hi (hardware interrupts) - 处理硬件中断的CPU时间百分比
- si (software interrupts) - 处理软件中断的CPU时间百分比
- st (steal) - 在虚拟化环境中,被宿主机"偷走"的CPU时间百分比。
最后则是进程列表:
默认按CPU使用率排序,关注 %CPU 列。
按 P 键按CPU排序,按 M 键按内存排序。
RES 列是实际物理内存占用,S 列是进程状态(R运行,S睡眠,D不可中断睡眠------常在I/O等待时出现,若大量 D 状态进程,说明磁盘或网络卡住了)。
汇总一下可能的问题:
- us 高 + 负载高:应用代码问题(死循环、大量计算)。
- sy 高:可能系统调用频繁(如大量读写小文件、网络请求过多)。
- wa 高:磁盘I/O慢,或有进程在大量读写。
- 进程出现大量 D 状态:通常是存储或网络挂起,可能导致客户端断线(因为服务无法响应)
三、内存与磁盘:是物理瓶颈吗?
如果 top 中 wa 高,或者你怀疑内存不足,需要深入查看内存和磁盘。
使用命令free -h进行查看:

available:真正的可用内存(包括可回收的缓存),比 free 列更有参考价值。如果 available 接近0,内存紧张。
Swap used:如果 swap 使用量高,说明物理内存不足,系统在频繁换页,这会严重影响性能。
buff/cache:Linux 会尽可能利用空闲内存做缓存。如果 buff/cache 很大但 available 还很多,那是正常的。
- available 持续很低,swap 使用高 → 内存不足,需要加内存或优化应用。
- 若 available 充足但系统卡顿,则卡顿可能不是内存原因。
磁盘 I/O:iostat -x 1(需要安装 sysstat)

目前我这里没有进行磁盘IO,因此没有显示设备,但这几个参数列还是可以关注一下
- %util:磁盘忙的百分比。如果持续接近 100%,说明磁盘已达到 I/O 饱和。
- await:平均每次 I/O 请求的等待时间(毫秒)。如果 > 10ms 且 %util 高,磁盘响应慢;如果 await 高但 %util 不高,可能是磁盘本身性能差或队列深。
- r/s, w/s:每秒读写次数(IOPS)。
- rkB/s, wkB/s:每秒读写带宽。
- avgqu-sz:平均 I/O 队列长度。如果持续大于 1,说明有 I/O 堆积。
可能遇到的问题:
%util 100% + await 高 → 磁盘性能瓶颈,可能是应用频繁随机读写或磁盘故障。
如果应用是数据库,高 IOPS 或高带宽是正常的,但若超过磁盘极限,就需要优化查询或换 SSD。
综合内存与 I/O:vmstat 1

procs 列:
r:运行队列中的进程数(正在使用或等待CPU)。如果持续大于 CPU 核心数,CPU 不足。
b:处于不可中断睡眠的进程数(通常是在等待 I/O)。如果 b 持续大于 0,说明有进程在等待磁盘/网络 I/O。
swap 列:
si, so:每秒从 swap 换入/换出的内存量。如果非零且持续,说明内存不足,系统在频繁 swap,性能会骤降。
io 列:
bi, bo:每秒读/写的块数量(通常 1 块=512 字节)。高 bi/bo 说明磁盘繁忙。
cpu 列:与 top 类似,关注 wa 和 id。
四、网络与连接:为什么会频繁断线?
客户端断线通常与网络连接状态、端口耗尽、或网络延迟有关。
查看连接状态:ss -tunap(推荐替代 netstat)
-t:TCP
-u:UDP
-n:不解析域名(更快)
-a:显示所有
-p:显示进程

关键状态解读:
- ESTABLISHED:正常连接数。如果突然激增,可能有流量突增或连接未释放。
- TIME_WAIT:主动关闭连接后等待的一方。大量 TIME_WAIT 是正常的(特别是短连接场景),但如果达到数万且系统出现端口不足,可能需要调整内核参数。
- CLOSE_WAIT:需要重点关注。这是被动关闭后,应用没有主动调用 close(),导致连接悬空。如果 CLOSE_WAIT 持续增多,说明应用代码有 bug(没有正确释放连接),最终会导致文件描述符耗尽,新连接无法建立,客户端断线。
- SYN_RECV:如果大量,可能遭受 SYN Flood 攻击或服务处理不过来。
计数命令:ss -s
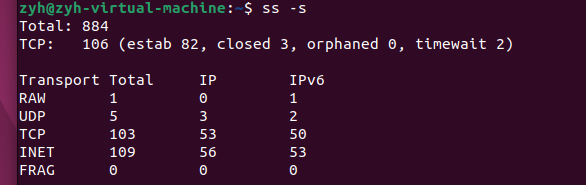
可能的问题:
- CLOSE_WAIT 过多 → 代码未关闭连接(常见于 HTTP 客户端、数据库连接池泄漏)。
- TIME_WAIT 过多导致端口耗尽 → 可调整 net.ipv4.tcp_tw_reuse 等内核参数(但现代 Linux 默认已优化)。
- 若 ESTABLISHED 连接数远超过业务预期,可能是连接泄漏或流量异常。
关于网络,还有一些命令简单介绍一下:
实时流量查看:iftop 或 nload
关注:
流量是否打满网卡(比如千兆网卡跑到 900Mbps)。
哪些 IP 或端口占用最多流量,是否异常(如被攻击)。
网络延迟与丢包:ping 和 mtr
如果客户端断线是间歇性的,可能是网络丢包或延迟过高,需要从服务器向外探测。
五、小结
-
先用 top 看全局:load average, wa, us, sy,以及是否有大量 D 状态进程。
-
若 wa 高 → 执行 iostat -x 1 确认磁盘 %util 和 await,同时 vmstat 1 看 b 列和 bi/bo。
-
若可用内存低 + swap 使用高 → 内存不足,用 free -h 确认,并排查应用内存泄漏(后续结合应用日志)。
-
若网络断线 → 用 ss -tunap 看连接状态,重点关注 CLOSE_WAIT;用 iftop 看流量是否打满;用 ping 看延迟丢包。
-
综合判断:通常系统卡顿是多种资源相互影响的结果,例如内存不足导致 swap,swap 又导致磁盘 I/O 飙升,进而引发 wa 高和进程阻塞,最终客户端超时断线。这时需要找到根因(通常是内存),而非盲目加磁盘。