前言
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型成为弱学习器(基学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是 生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
一、集成学习分类
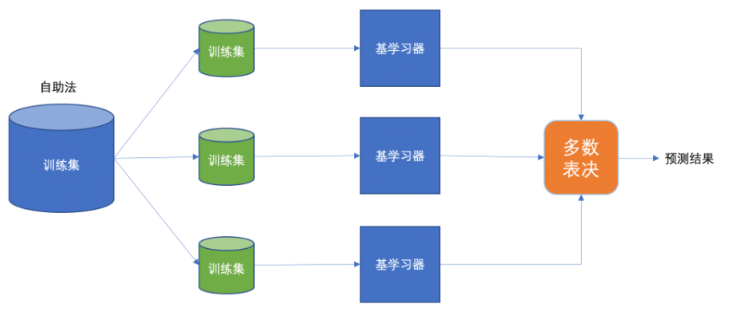
1.bagging集成
Baggging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
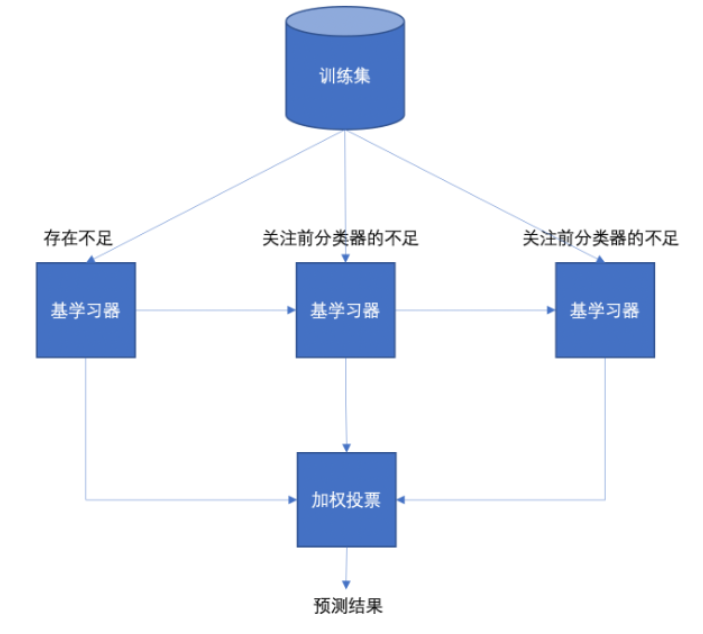
2.boosting集成
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
Boosting是一组可将弱学习器升为强学习器算法。这类算法的工作机制类似:1.先从初始训练集训练出一个基学习器
2.在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续得到最大的关注。
3.然后基于调整后的样本分布来训练下一个基学习器;
4.如此重复进行,直至基学习器数目达到实现指定的值T为止。
5.再将这T个基学习器进行加权结合得到集成学习器。
3.Bagging 与 Boosting的区别
区别一:数据方面
- Bagging:有放回采样
- Boosting:全部数据集, 重点关注前一个弱学习器不足
区别二:投票方面
- Bagging:平权投票
- Boosting:加权投票
区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系
- Boosting学习是串行,学习有先后顺序
二、随机森林
随机森林是基于 Bagging 思想实现的一种集成学习算法,它采用决策树模型作为每一个基学习器。
构造过程:
- 训练:
- 有放回的产生训练样本
- 随机挑选 n 个特征(n 小于总特征数量)
- 预测:平权投票,多数表决输出预测结果

首先,对样本数据进行有放回的抽样,得到多个样本集。具体来讲就是每次从原来的N个训练样本中有放回地随机抽取m个样本(包括可能重复样本)。
然后,从候选的特征中随机抽取k个特征,作为当前节点下决策的备选特征,从这些特征中选择最好地划分训练样本的特征。用每个样本集作为训练样本构造决策树。单个决策树在产生样本集和确定特征后,使用CART算法计算,不剪枝。
最后,得到所需数目的决策树后,随机森林方法对这些树的输出进行投票,以得票最多的类作为随机森林的决策。
三、Adaboost
Adaptive Boosting(自适应提升)基于 Boosting思想实现的一种集成学习算法核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。弱分类器的性能比随机猜测强就行,即可构造出一个非常准确的强分类器。其特点是:训练时,样本具有权重,并且在训练过程中动态调整。被分错的样本的样本会加大权重,算法更加关注难分的样本。
1.AdaBoost算法推导:

2.AdaBoost 模型公式:
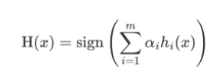
- α 为模型的权重
- m 为弱学习器数量
- hi(x) 表示弱学习器
- H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。
3.AdaBoost 权重更新公式:
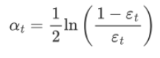
εt 表示第 t 个弱学习器的错误率
4.AdaBoost 样本权重更新公式:
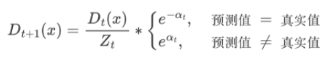
- Zt 为归一化值(所有样本权重的总和)
- Dt(x) 为样本权重
- αt 为模型权重。
四、GBDT
梯度提升树(Gradient Boosting Decision Tre)是提升树(Boosting Decision Tree)的一种改进算法,所以在讲梯度提升树之前先来介绍一下提升树。
1.提升树:
假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。最后将每次拟合的岁数加起来便是模型输出的结果。
2.梯度提升树:
思想:GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是一种迭代的集成学习算法,它通过串行训练多个弱学习器(通常是CART回归树),每个弱学习器拟合前一个弱学习器的损失函数的负梯度(在回归问题中常为残差),从而逐步降低整体预测误差。
改进:不再直接拟合残差,而是拟合损失函数的负梯度。
优点:适用于任意损失函数(不仅是平方损失)。
对于平方损失:负梯度恰好等于残差。
五、XGBoost
XGBoost(Extreme Gradient Boosting)全名叫极端梯度提升树,XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost。
XGBoost在绝大多数的回归和分类问题上表现的十分顶尖
1. 核心思想
对 GBDT 的极致优化 ,核心是最小化带正则化的损失函数,通过泰勒二阶展开简化求解,加入树复杂度正则化防止过拟合,是工业界 / 竞赛常用算法。
2. 核心改进(对比 GBDT)
- 损失函数:加入正则化项(叶子节点数 + 叶子节点值的 L2 正则),控制模型复杂度;
- 求解方式:对损失函数做泰勒二阶展开,同时利用一阶导(gi)和二阶导(hi),拟合更精准;
- 树构建:通过增益(Gain) 选择最优分裂点,Gain>0 才分裂,更科学;
- 泛化能力:支持缺失值处理、特征并行,训练速度更快。
3. 核心公式
- 目标函数:(损失项衡量预测误差,正则项惩罚树复杂度);
- 分裂增益:,Gain 越大,分裂效果越好;
- 叶子节点最优值:
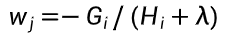
(Gj 为节点样本一阶导和,Hj 为二阶导和)。
4. 目标函数推导(核心)

5. 树的构建(分裂增益)
- 分裂前后的增益:
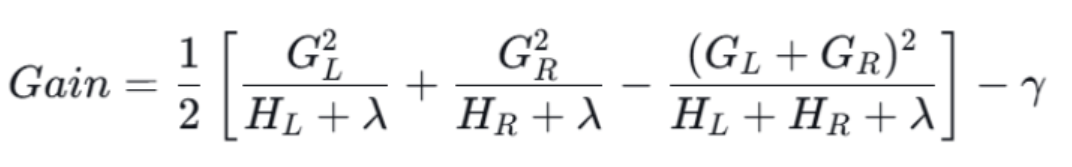
- 当 Gain>0 时,考虑分裂,否则停止。
6. XGBoost API
python
import xgboost as xgb
# 分类器
model = xgb.XGBClassifier(
n_estimators=100, # 树的数量
max_depth=3, # 最大深度
learning_rate=0.1, # 学习率
objective='multi:softmax', # 多分类
eval_metric='merror', # 评估指标
reg_lambda=1, # L2正则系数
reg_alpha=0, # L1正则系数
gamma=0, # 分裂所需最小损失减少量
random_state=42
)7. 案例:红酒品质分类
(一)需求说明
任务目标
利用红酒的11个理化特征(如固定酸度、酒精含量等),预测其品质等级,属于多分类问题。
数据概况
- 样本总数:3269条
- 特征维度:11个数值型特征
- 目标变量:quality(取值3~8,共6个等级)
- 特点:样本分布不均衡,中等品质(5、6)占绝大多数,优质(8)和劣质(3)样本极少。
| 字段名 | 中文含义 | 数据类型 | 说明 |
|---|---|---|---|
| fixed acidity | 固定酸度 | float | 酒石酸含量,影响酸味 |
| volatile acidity | 挥发性酸度 | float | 醋酸含量,过高会产生不良风味 |
| citric acid | 柠檬酸 | float | 少量可增添 freshness |
| residual sugar | 残糖 | float | 剩余糖分,影响甜度 |
| chlorides | 氯化物 | float | 盐分含量 |
| free sulfur dioxide | 游离二氧化硫 | float | 抗菌抗氧化 |
| total sulfur dioxide | 总二氧化硫 | float | 包括游离和结合态 |
| density | 密度 | float | 与糖分、酒精相关 |
| pH | pH值 | float | 酸性强度 |
| sulphates | 硫酸盐 | float | 防腐剂,可能影响香气 |
| alcohol | 酒精 | float | 酒精度(% vol) |
| quality | 品质 | int | 评分,范围3~8 |
业务意义
识别高品质和低品质红酒,辅助质量控制和生产工艺改进。
(二)处理思维流程
- 数据理解与加载
读取CSV文件,查看数据基本信息(行数、列数、缺失值、重复值)。
统计quality的分布,确认不均衡程度。
初步分析各特征的统计描述(均值、范围等)。
- 数据预处理
缺失值处理:若存在缺失,采用均值/中位数填充或删除。
重复值处理:删除完全相同的样本,避免数据泄露。
标签映射:若quality为38,可映射为05,便于模型处理(但非必需)。
- 数据集划分
按8:2比例划分训练集和测试集,使用分层采样(stratify)确保训练/测试集中各类别比例与原始数据一致。
可选从训练集中再划分验证集,或直接使用交叉验证进行调参。
- 处理样本不均衡
方法选择(二选一或结合):
类别权重:计算各类别权重,在模型训练时传入sample_weight或设置scale_pos_weight(需手动计算)。
重采样:对少数类进行过采样(如SMOTE)或对多数类欠采样。
评估指标选用加权F1或宏平均F1,避免准确率的误导。
- 模型选择与训练
选用XGBoost作为核心算法,因其对多分类和不均衡数据有良好支持。
设置目标函数:multi:softmax,类别数 num_class=6。
使用默认参数训练一个基线模型,观察初步效果。
- 模型评估
在测试集上预测,输出分类报告(精确率、召回率、F1)和混淆矩阵,分析各类别识别情况。
计算特征重要性,了解哪些理化属性对品质影响最大,为业务提供可解释性。
- 超参数调优
使用网格搜索或随机搜索结合交叉验证,优化关键参数:
-
- n_estimators(树的数量)
- max_depth(树的最大深度)
- eta(学习率)
- subsample(样本采样比例)
- colsample_bytree(特征采样比例)
- reg_lambda(L2正则项)
- 优化目标可选择宏平均F1,对不均衡更鲁棒。
- 模型保存与部署
将最终模型保存为文件(如.pkl或.json),便于后续对新红酒样本进行预测。
可封装为API或批处理脚本,供业务使用。
(三)完整代码
python
# 导入必要的包
import pandas as pd # 导入数据处理包
from sklearn.model_selection import train_test_split # 导入数据集划分包
from xgboost import XGBClassifier # 导入XGBoost模型包
from sklearn.utils import class_weight # 导入类权重包,用于处理样本不均衡
from sklearn.metrics import accuracy_score # 导入准确率包
from sklearn.metrics import classification_report # 导入分类报告包
import joblib # 保存模型
from sklearn.model_selection import StratifiedKFold # 创建分层采样工具
from sklearn.model_selection import GridSearchCV # 创建网格搜索+交叉验证对象
# 定义函数,对数据进行预处理,进行查看,并且划分训练集和测试集,保存到文件中
def preprocess():
##### 1. 数据加载与理解
# 加载数据集
data = pd.read_csv('file/红酒品质分类.csv')
# 查看数据基本信息(行数、列数、缺失值、重复值)
print("数据结构:", data.shape) # (1599行, 12列)
print("字段信息:", data.info())
print("缺失值:", data.loc[:,data.isnull().any()].sum()) # 仅显示有缺失值的字段
print("重复值:", data.duplicated().sum())
print("数据预览:", data.head())
# 统计 qualiy(品质)的分布情况,确认不均衡程度
print("quality(品质)分布:\n", data['quality'].value_counts())
# 初步分析各特征的统计描述(均值、范围等)
print("数据描述:\n", data.describe())
##### 2. 数据预处理
# 数据预处理暂时不执行了,因为数据去重后,模型的准确率下降了
# # 缺失值处理,若存在缺失,采用中位数填充或删除。
# data.fillna(data.median(), inplace=True) # 填充缺失值
# # 重复值处理,删除完全相同的样本,避免数据泄露。
# data.drop_duplicates(inplace=True) # 删除重复行
# 标签映射:若quality为3~8,可映射为0~5,便于模型处理(但非必需)。
data['quality'] = data['quality'].apply(lambda x: x - 3) # 映射标签
##### 3. 数据集划分
# 定义特征向量 X 和标签向量 y
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 按 8:2 比例划分训练集和测试集,
# 使用分层采样(stratify)确保训练/测试集中各类别比例与原始数据一致。
x_train, x_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=22,stratify=y
)
# 将【训练集/测试集】的特征和标签 拼接起来,保存数据集到文件
train_data = pd.concat([x_train, y_train], axis=1) # 拼接特征和标签
test_data = pd.concat([x_test, y_test], axis=1) # 拼接特征和标签
train_data.to_csv('file/红酒品质分类_train.csv', index=False) # 保存训练集
test_data.to_csv('file/红酒品质分类_test.csv', index=False) # 保存测试集
print("数据集保存完成!")
# 定义函数,读取处理好数据集,进行模型训练和评估,并保存训练好模型
def train_and_evaluate():
# 读取数据集,并拆分训练集和测试集、划分特征向量和标签向量
train_data = pd.read_csv('file/红酒品质分类_train.csv')
test_data = pd.read_csv('file/红酒品质分类_test.csv')
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
print("数据集加载完成!")
### 4.处理样本不均衡
# 类别权重:计算各类别权重,
# 在模型训练时传入sample_weight或设置scale_pos_weight(需手动计算)。
if train_data['quality'].nunique() > 2: # 多分类问题
weight_ = class_weight.compute_sample_weight(
class_weight='balanced', y=y_train
)
### 5.模型训练和评估
# 创建模型对象:XGBoostClassifier:XGBoost分类模型
# 选用XGBoost作为核心算法,因其对多分类和不均衡数据有良好支持。
model = XGBClassifier(
n_estimators=200, # 弱学习器的数量
learning_rate=0.1, # 学习率
max_depth=10, # 树的最大深度
objective='multi:softmax', # 多分类问题
# num_class=6, # 类别数
random_state=22 # 随机数种子
)
# 模型训练
model.fit(x_train, y_train, sample_weight=weight_)
##### 6.模型评估
# 在测试集上预测,输出分类报告(精确率、召回率、F1)和混淆矩阵,分析各类别识别情况。
# 预测测试集标签
y_predict = model.predict(x_test)
print('模型评估分类报告:\n', classification_report(y_test, y_predict))
print('模型准确率:', accuracy_score(y_test, y_predict))
# 保存模型
joblib.dump(model, 'file/红酒品质分类.pkl')
print("模型保存完成!")
# 定义函数,测试模型,调优模型参数
##### 7.模型超参数调优
# 创建网格搜索+交叉验证对象,找到模型最优参数组合
def tune_model():
# 读取数据集,并拆分训练集和测试集、划分特征向量和标签向量
train_data = pd.read_csv('file/红酒品质分类_train.csv')
test_data = pd.read_csv('file/红酒品质分类_test.csv')
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
print("数据集加载完成!")
# 定义参数和搜索范围
param_dict = {
'max_depth':[5,10,15,20], # 树最大深度
'n_estimators':[80,100,120,150], # 弱学习器的数量
'learning_rate':[0.1,0.2] # 学习率
}
# 加载模型
model = joblib.load('file/红酒品质分类.pkl')
# 创建分层采样工具
skf = StratifiedKFold(
n_splits=5, # 交叉验证的折数
shuffle=True, # 是否打乱数据
random_state=22 # 随机数种子
)
# 创建网格搜索+交叉验证对象
# cv 填入 StratifiedKFold的对象
gs_model = GridSearchCV(model, param_grid=param_dict, cv=skf)
# 模型训练 模型测试
gs_model.fit(x_train, y_train)
# 预测测试集标签
y_predict = gs_model.predict(x_test)
print('模型评估分类报告:\n', classification_report(y_test, y_predict))
print('模型准确率:', accuracy_score(y_test, y_predict))
print('模型最优参数:', gs_model.best_params_)
if __name__ == '__main__':
preprocess() # 数据预处理
train_and_evaluate() # 模型训练和评估
tune_model() # 模型超参数调优