目录
[一、 核心定位重构:为 Agent(智能体)而生的系统级模型](#一、 核心定位重构:为 Agent(智能体)而生的系统级模型)
[二、 突破物理界限:原生操控电脑的革命](#二、 突破物理界限:原生操控电脑的革命)
[三、 跨越专家门槛:复杂脑力劳动的系统性接管](#三、 跨越专家门槛:复杂脑力劳动的系统性接管)
[四、 高保真视觉感知与文档解析引擎](#四、 高保真视觉感知与文档解析引擎)
[五、 编程能力的闭环:引入可视化交互测试](#五、 编程能力的闭环:引入可视化交互测试)
[六、 工具搜索机制(ToolSearch):破解上下文爆炸难题](#六、 工具搜索机制(ToolSearch):破解上下文爆炸难题)
[七、 中途可干预的思考模式:告别"盲盒式"交互](#七、 中途可干预的思考模式:告别“盲盒式”交互)

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 深度解析 GPT-5.4
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在过去的一年里,大模型赛道风起云涌,各家厂商在上下文长度、逻辑推理得分上你追我赶。然而,在实际的商业落地和复杂的工业级场景中,企业用户往往会发现一个尴尬的现实:无论模型在测试集上多么聪明,当需要它去独立完成一项跨越多个软件、涉及多步查证的真实工作时,依然显得笨拙且极易出错。
面对这一行业瓶颈,OpenAI 推出的 GPT-5.4 给出了一份截然不同的答卷。此次发布的 GPT-5.4 没有仅仅停留在"更强的文本生成器"这一角色上,而是将视觉感知、逻辑推理、代码编写与原生操作能力进行了系统级的深度整合。它不再是一个需要人类不断"投喂"精确指令才能勉强运转的工具,而是一个能够自主打开浏览器、操作业务系统、自我测试并交付最终成果的"数字员工"。
本文将抛开枯燥的营销概念,从技术架构、能力突破与应用场景三个维度,深度拆解 GPT-5.4 的核心演进逻辑。
一、 核心定位重构:为 Agent(智能体)而生的系统级模型
在 GPT-5.4 之前,大语言模型(LLM)的进化逻辑往往是"缺哪补哪":数学不行就专项强化数学数据,写代码不行就推出专门的代码模型(如 Codex 系列)。但真实世界的工作并非单维度的。一个初级分析师撰写行业报告,需要查阅网页、下载财报、在 Excel 中进行数据清洗与建模,最后将图表粘贴到 PowerPoint 中并排版。
**GPT-5.4 的最大意义在于,它将所有的单项能力整合成了一个有机的"工作系统"。**它首次将原生计算机操控能力融入通用模型,同时支持高达 100 万 Token 的超长上下文窗口,并引入了全新的动态工具搜索机制。据官方披露,这种深度的多模态整合并没有以牺牲任何单项推理能力为代价。这种系统级的优化,标志着大模型正式从"被动回答问题的顾问"迈向了"主动执行任务的代理(Agent)"。
二、 突破物理界限:原生操控电脑的革命
一直以来,让 AI 像人类一样操作电脑都是学术界和工业界孜孜以求的圣杯。传统的 RPA(机器人流程自动化)高度依赖固定的页面元素和预设的脚本,一旦网页改版或弹出一个未知对话框,流程就会彻底崩溃。而此前的大模型通常需要借助复杂的中间件(如特定的 API 或 DOM 解析器)才能勉强与软件交互。
GPT-5.4 首次将计算机操控能力进行了"原生整合"。这意味着它不仅能输出 Python 脚本,更能直接"看懂"屏幕截图,将视觉像素精准转化为坐标,并直接下发鼠标移动、点击、拖拽和键盘输入等系统级指令。
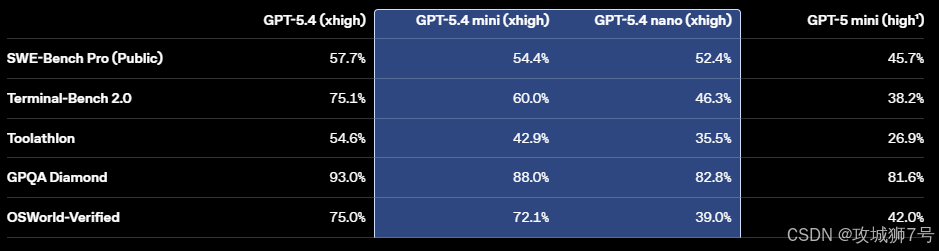
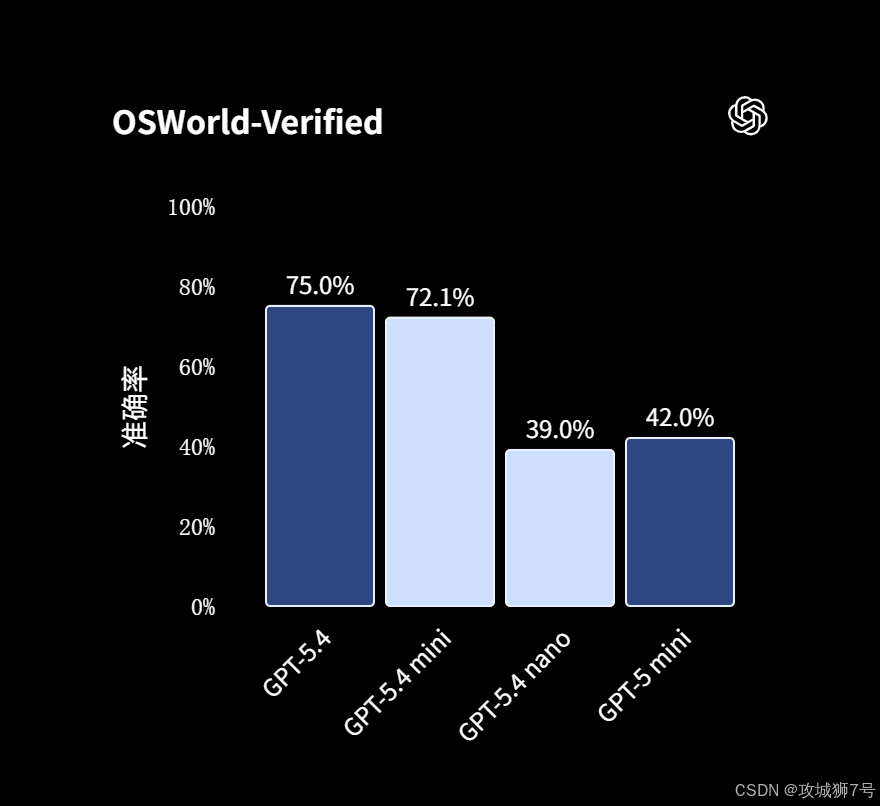
在极具权威性的 OSWorld-Verified(桌面操作系统级操控)基准测试中,GPT-5.4 达成了 75.0% 的任务成功率。这是一个极具历史意义的数据,因为人类在该测试中的平均基线成绩为 72.4%。这是 AI 首次在真实的电脑综合操控上超越人类平均水平,且远超前代模型 GPT-5.2 的 47.3%。
在实际应用中,这种能力的商业价值不可估量。以美国房地产数据公司 Mainstay 的大规模实测为例,在面对多达三万个不同界面、不同逻辑的房产税门户网站时,GPT-5.4 展现出了惊人的鲁棒性:首次尝试成功率达 95%,三次重试内的成功率高达 100%。相较于以往的方案,任务完成速度提升了三倍,而 Token 消耗减少了近 70%。这预示着传统的 GUI 自动化测试和数据录入工作,即将迎来一次降维打击式的重构。
三、 跨越专家门槛:复杂脑力劳动的系统性接管
如果说操作电脑是"动手能力",那么在专业领域的深度推理则是不可或缺的"硬核脑力"。为了准确衡量 AI 在真实职场中的价值,OpenAI 引入了全新的 GDPval 基准测试。该测试不再局限于简单的客观题问答,而是要求模型完成美国 GDP 贡献最大的 9 个行业中的 44 种高价值职业任务,如建立复杂的财务会计模型、撰写专业的法律简报、安排医院急诊排班等。这些任务通常由具备十几年经验的资深从业者设计。
测试结果显示,GPT-5.4 在 83.0% 的任务中达到了甚至超越了人类行业专家的水平,将前代模型 70.9% 的成绩远远甩在身后。
在具体细分领域,其表现同样令人瞩目:
**(1)投行级电子表格建模:**在模拟初级投资银行分析师的任务中,GPT-5.4 的得分达到 87.3%(前代为 68.4%),展现了极强的数据关联与公式逻辑推演能力。
**(2)长周期交付物生成:**在生成完整的演示文稿(PPT)时,它不仅能提供结构清晰的大纲,还能进行成熟的视觉设计与图文排版。盲测中,人类评测者在 68% 的情况下更偏好 GPT-5.4 生成的商业文档。
更令企业用户安心的是,GPT-5.4 在"幻觉"控制上取得了实质性进展。面对包含陷阱或极易混淆的专业知识提示词时,其产生事实性错误的概率大幅降低了 33%。这种对事实准确性的苛求,使得 AI 从"仅供参考的草稿生成器",变成了在法律、医疗、金融等低容错率行业中真正可信赖的生产力中枢。
四、 高保真视觉感知与文档解析引擎
要让 AI 在复杂的办公环境中游刃有余,精准的视觉感知是底层基石。无论是识别复杂的工程图纸、密密麻麻的后台控制面板,还是扫描模糊的财务票据,都需要模型具备极高的图像分辨率处理能力。
GPT-5.4 在视觉架构上进行了大幅升级,首次引入了"原始(Original)"和"高(High)"两种图像输入细节模式。在最高配置下,它能够直接摄入和解析高达 1024 万总像素(或最大边长 6000 像素)的全保真图像。
在脱离任何外部 OCR(光学字符识别)工具辅助的 MMMU-Pro 纯视觉理解测试中,GPT-5.4 取得了 81.2% 的准确率。在专门针对复杂文档解析的 OmniDocBench 测试中,其平均归一化编辑距离误差降至极低的 0.11。这意味着,面对包含多重嵌套表格、手写批注和不规则排版的商业文档时,GPT-5.4 能够以极低的错误率将其精准还原为结构化数据,极大提升了企业非结构化数据数字化的效率。
五、 编程能力的闭环:引入可视化交互测试
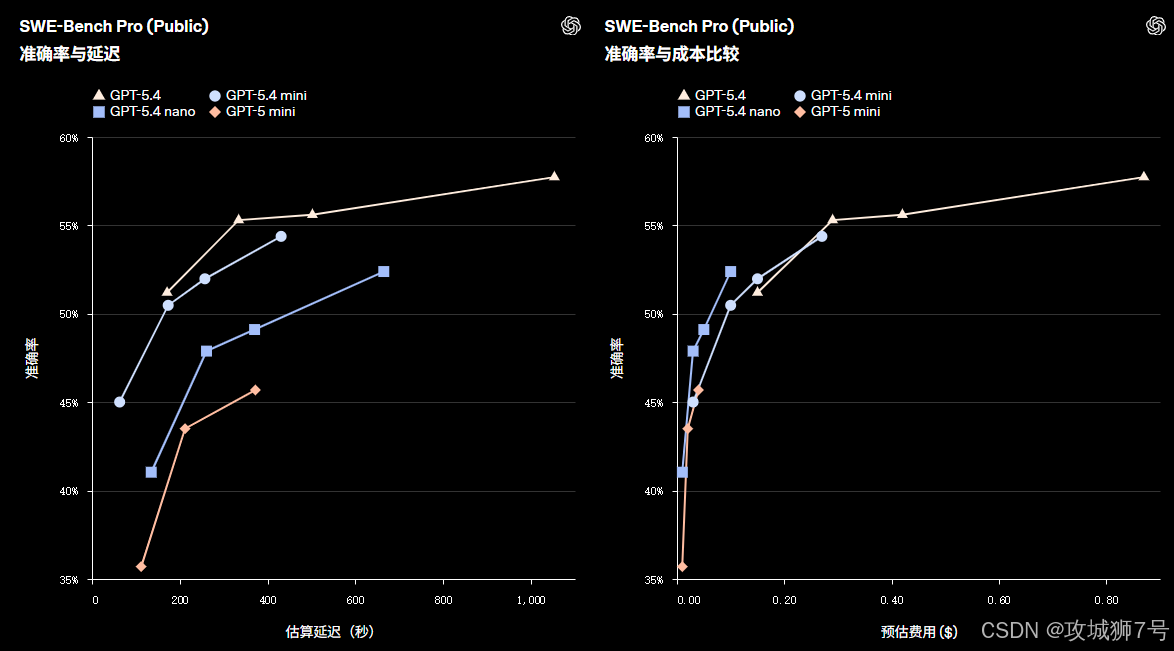
对于开发者群体而言,GPT-5.4 带来的震撼绝不仅仅是"它写的代码更优雅了"。虽然在 SWE-Bench Pro 测试中,其 57.7% 的得分已经稳居业界第一(甚至超越了专精代码的 GPT-5.3-Codex),但真正的革命性突破在于它引入了自我调试的闭环机制。
OpenAI 随之发布了一项名为 Playwright Interactive 的实验性技术。简单来说,以往的代码大模型在输出完一堆前端代码后,任务就宣告结束,代码能不能跑、界面有没有错位,必须由人类程序员去部署检查。而 GPT-5.4 能够在编写完 Web 应用代码后,自动在后台拉起一个虚拟浏览器,亲自运行自己写的代码。
在官方演示中,GPT-5.4 仅凭一句简短的提示词,就从零开始构建了一个包含寻路算法、资源管理、UI 动态更新的等距视角主题公园模拟游戏。在开发过程中,它像一个不知疲倦的测试工程师,自动对生成的界面进行多次渲染巡航,检查游客寻路是否卡死、UI 数据面板是否实时刷新。发现 Bug 后,它会自主修改底层的 JavaScript 或着色器代码,直到游戏完美运行。
**这种"代码生成 -> 视觉验证 -> 自主调试"的完整工程闭环,彻底打破了 AI 在软件工程中的应用边界。**它意味着未来的前端开发或小型应用构建,人类只需扮演产品经理和验收者的角色,繁琐的调试与排错将由模型全权代劳。
六、 工具搜索机制(ToolSearch):破解上下文爆炸难题
在构建复杂的企业级 Agent 时,开发者通常面临一个棘手的技术挑战:为了让模型具备调用内部接口的能力,必须在 System Prompt 中详细声明所有可用的 API 及其参数格式(即 MCP,Model Context Protocol)。如果企业有几十上百个系统接口,这些定义文档会瞬间撑爆上下文窗口,不仅导致极高的 Token 消耗(成本剧增),还会使得模型注意力分散,响应变慢。
**GPT-5.4 巧妙地通过"工具搜索(ToolSearch)"机制解决了这一难题。**现在,开发者只需向模型提供一个轻量级的可用工具目录索引。在推理过程中,当模型判定需要某个工具时,它会自动在后台即时检索并动态加载该工具的详细定义规范。
根据基准测试,在同时挂载 36 个复杂的企业级 MCP 服务器的情况下,这一新机制在保持调用准确率不变的前提下,将总 Token 使用量狂砍了 47%。这对于企业级的大规模部署而言,意味着单位计算成本的腰斩。在衡量多步骤现实工具调用能力的 Toolathlon 测试中,GPT-5.4 取得了 54.6% 的高分,证明了其在面对长流程、多系统交互时,不仅省钱,而且走得更稳。
七、 中途可干预的思考模式:告别"盲盒式"交互
传统的生成式 AI 交互往往是一种"盲盒体验":用户输入一段复杂的长篇指令,然后只能盯着屏幕等待模型吐出几千字的结果。如果中间某个理解方向跑偏了,用户只能无奈地推倒重来,反复修改提示词,这在处理长周期研究任务时极大地消耗了人类的时间和耐心。
GPT-5.4 引入了革命性的"前置思路概述"功能。在处理复杂请求时,模型会首先呈现它对任务的拆解逻辑和工作计划。更为关键的是,在这套全新的 GPT-5.4 Thinking 模式中,用户不再是旁观者。当模型正在按步骤执行时,用户可以随时介入,指出"这部分的逻辑不对,请换用另一种分析框架",模型会立即吸收反馈并无缝调整方向,而不会打断原有的上下文记忆。
这种从"单向指令下发"到"实时结对共创(Co-pilot)"的交互范式转移,使得人机协作的效率实现了质的飞跃。一次深度的交互就能获得满意的最终成果,彻底终结了过去来回拉扯、反复试错的低效沟通。
结语
从文本补全到逻辑推理,再到如今的原生设备操控与自主工程闭环,GPT-5.4 的登场无疑是通往通用人工智能(AGI)道路上的一个关键节点。它用无可争议的数据证明:AI 已经跨越了"好用的辅助工具"的范畴,正式进化为具备强执行力、能自主纠错、可独立接管系统性业务流的"数字员工"。
**然而,正如技术总是伴随着新的命题。**当 75% 的计算机操控成功率摆在面前时,我们固然惊叹于它的强大,但也必须清醒地意识到,在严苛的企业生产环境中,剩余的 25% 失败率仍需通过完善的监管沙盒与回滚机制来兜底。
对于广大科技从业者和企业管理者而言,GPT-5.4 抛出的最大拷问已不再是"AI 能不能干活",而是面对这个已经卷起袖子准备接管流程的"超级实习生",我们是否已经准备好重构现有的业务运转逻辑,将真正的职责信任地交托出去?拥抱变革,将是这个智能时代的唯一答案。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!