开源工具 AIDA:给 AI 辅助开发加一个数据采集层,让 AI 从错误中自动学习(Glama 3A 认证)
一、痛点:AI 写代码很快,但总在同一个地方犯错
现在用 AI 写代码已经很普遍了 ------ Claude Code、Cursor、Copilot,效率确实高。但用过的人都知道一个问题:
AI 没有项目级记忆。 你今天告诉它"我们项目的 Table 组件外面要包一层 min-height 容器",明天它又忘了。你纠正了三次 API 调用方式,第四次它还是用错。
根本原因是:每次对话都是独立的,AI 不知道上次在你的项目里犯了什么错。
AIDA 就是为了解决这个问题而生的 ------ 它在 AI 开发过程中自动采集结构化数据,把 AI 的偏差模式沉淀成项目规则,让 AI 越用越准。
项目已通过 Glama.ai 平台的安全、许可和质量三重 A 级认证,MIT 开源。
二、30 秒接入
在项目根目录的 .mcp.json 加一行:
json
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["-y", "ai-dev-analytics", "mcp"]
}
}
}支持 Claude Code、Cursor、VS Code Copilot、Windsurf。加完配置后不需要任何其他操作,你照常用 AI 写代码就行。
npm 下载慢可以先全局安装:
npm install -g ai-dev-analytics,然后 command 改成"aida"。
三、架构与原理
你的 AI 工具 (Claude Code / Cursor)
↓ MCP 协议 (stdio)
AIDA MCP Server (10 个工具)
↓ 自动采集
.aidevos/run.json (结构化数据)
↓
数据看板 (localhost:2375) 规则库 (.aidevos/rules/)
↓
AI 下次读取规则 → 输出质量提升关键设计:
- MCP 协议通信:AIDA 不是让 AI 执行 shell 命令,而是通过 MCP(Model Context Protocol)提供原生工具,AI 直接函数调用,响应更快、更可靠
- 零运行时依赖:整个项目不依赖任何第三方包,纯 Node.js + TypeScript
- 100% 本地 :所有数据存在项目目录的
.aidevos/下,普通 JSON 文件,没有任何外部 HTTP 请求
10 个 MCP 工具
| 工具名 | 功能 | 触发时机 |
|---|---|---|
aida_task_start |
记录任务开始 | AI 开始编码时 |
aida_task_done |
记录任务完成 | AI 完成编码时 |
aida_log_bug |
记录 Bug | 发现缺陷时 |
aida_bug_fix |
记录 Bug 修复 | 修复完成时 |
aida_log_review |
记录代码自检 | 自检完成时 |
aida_log_deviation |
记录偏差 | AI 输出不符合预期时 |
aida_log_files |
记录文件变更 | 自动扫描 git diff |
aida_highlight |
记录亮点 | 有值得记录的优化时 |
aida_status |
查看当前状态 | 随时 |
aida_log_rule |
沉淀项目规则 | 用户确认后 |
所有工具都是 AI 自动调用的,开发者不需要手动操作。
四、核心机制:偏差 → 规则 → 反哺
这是 AIDA 的核心价值,用一个真实项目的数据说明:
第 1 轮开发: 47 个任务,产生 23 个偏差。
先看根因分布 ------ AI 为什么出错?
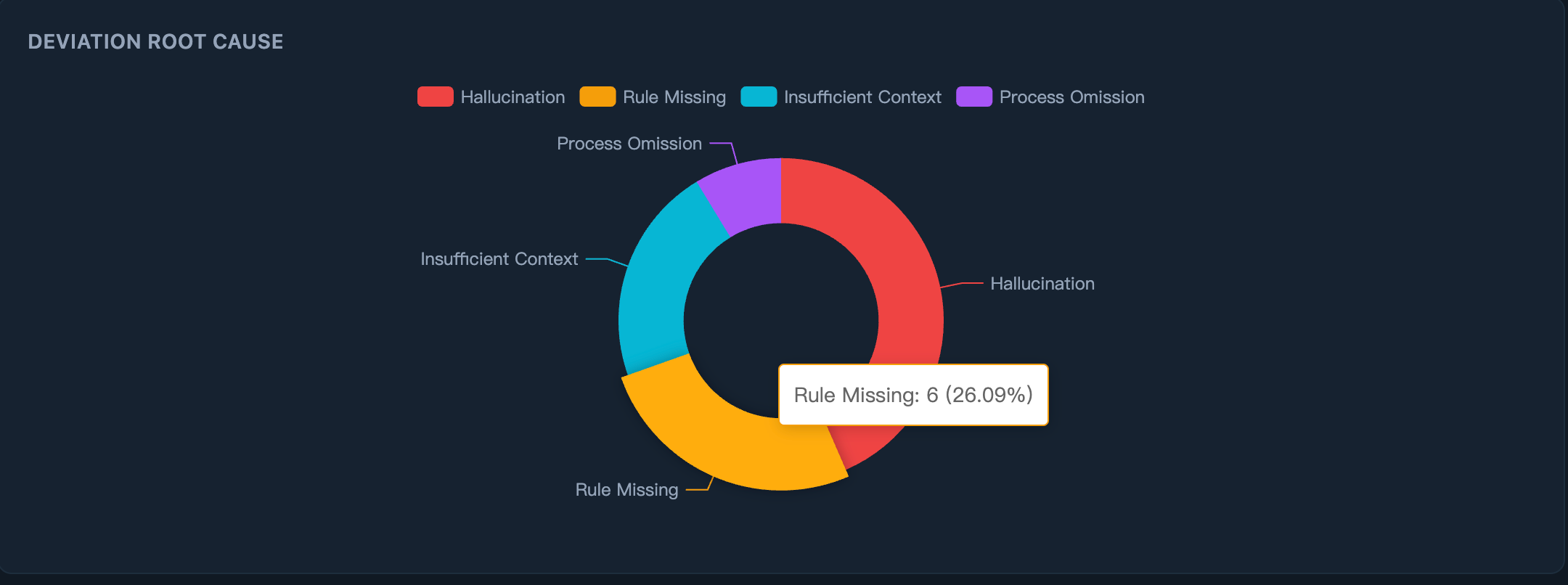
是 AI 幻觉(使用了不存在的 API / 组件),还是规则缺失(项目有规范但 AI 不知道)。
再看类别分布 ------ AI 在哪出错?
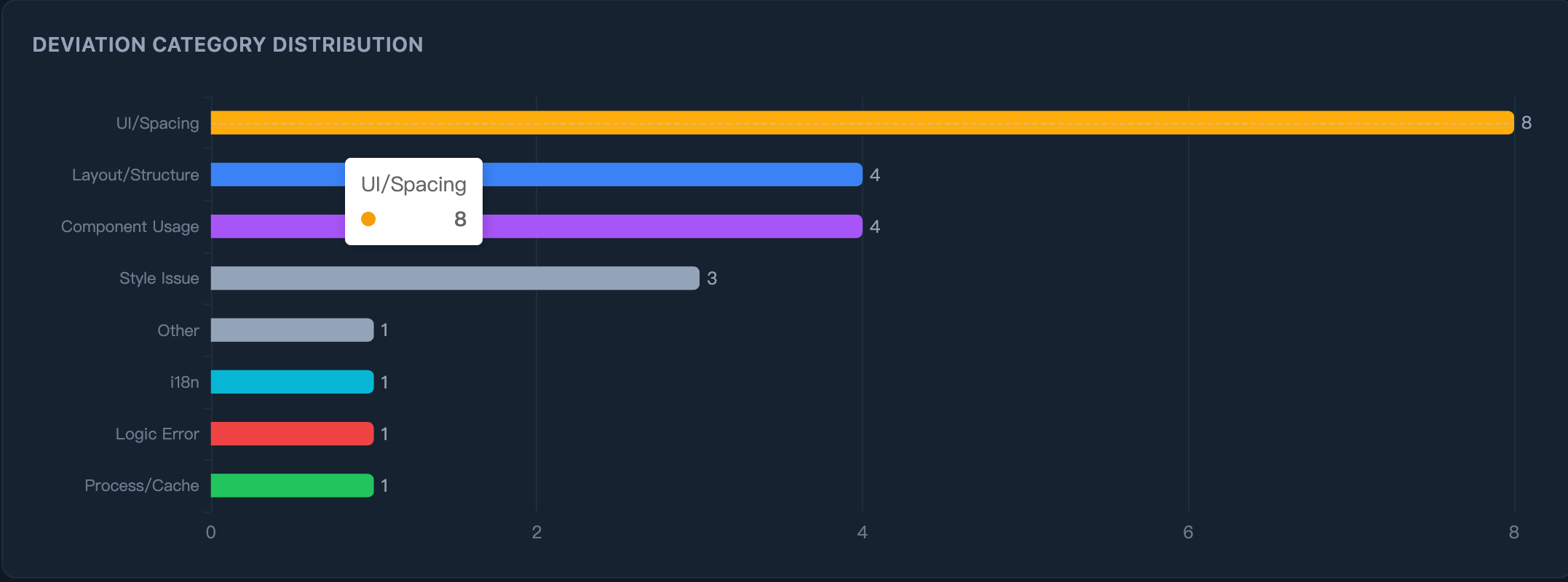
从中提取了 6 条项目规则,写入 .aidevos/rules/。
第 2 轮开发: 同类偏差 → 零复现。AI 读了规则,相同模式的错误被消除。
看偏差与规则趋势 ------ 绿色线是规则数量,随着规则积累,偏差持续下降:
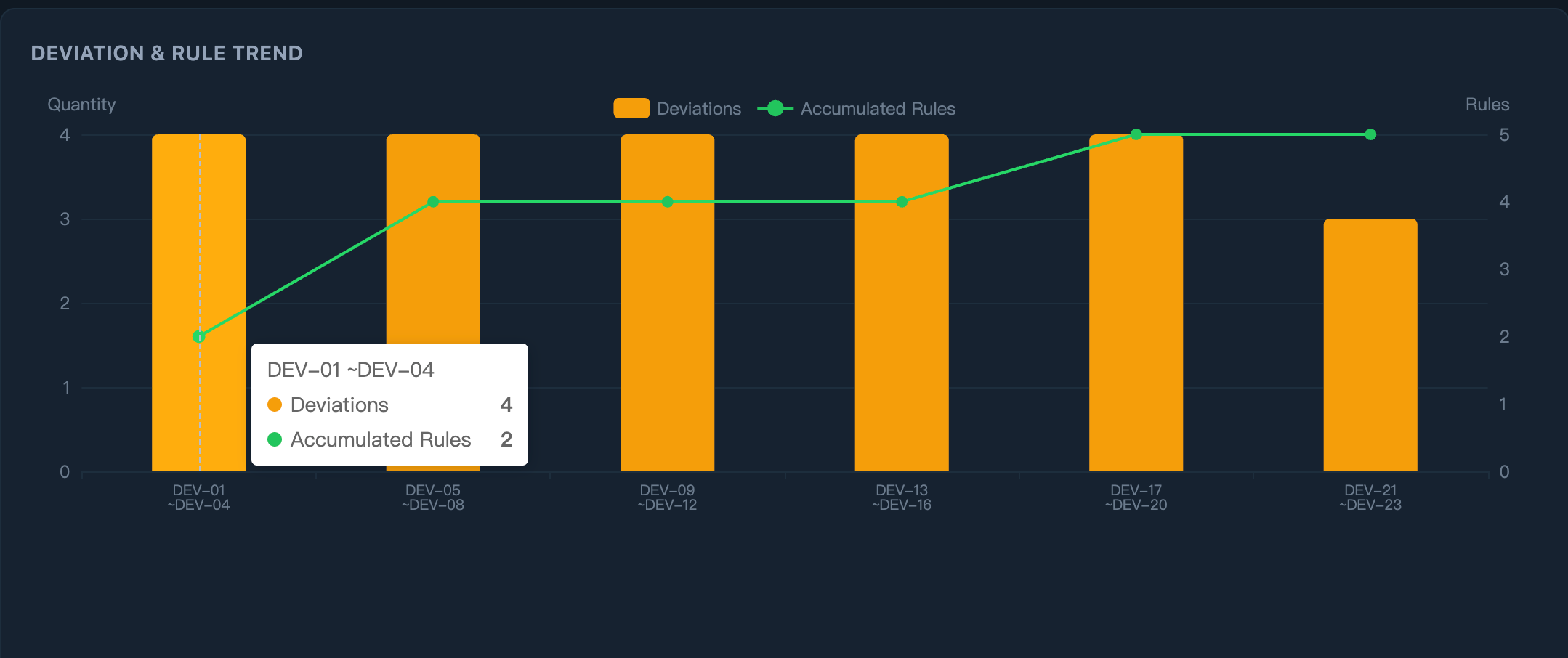
这就是数据驱动的复利效应。
规则沉淀流程
1. AI 编码 → 产出不符合预期
2. 记录偏差 → aida_log_deviation(自动分析根因)
3. 根因为 rule-missing → AI 建议沉淀规则
4. 开发者确认 → aida_log_rule 写入规则库
5. 规则库通过 fingerprint 自动去重
6. 下次 AI 读取规则 → 同类错误不再复现沉淀的规则举例:
- "el-dialog 内 Table 必须有 min-height 容器"
- "API 请求必须走 src/api/ 统一封装层"
- "日期组件必须传 format='YYYY-MM-DD'"
这些都是项目级技术规范,不涉及业务逻辑,适合沉淀为持久规则。
五、数据看板
bash
npx ai-dev-analytics dashboard打开 http://localhost:2375,看到所有采集的数据:
在线 Demo(真实脱敏数据):https://lwtlong.github.io/ai-dev-analytics/
看板包含:
| 模块 | 内容 |
|---|---|
| 偏差根因分布 | 饼图:幻觉 / 规则缺失 / 上下文不足 / 理解偏差 |
| 偏差类别分布 | 饼图:布局 / 组件 / API / 样式 |
| 偏差 & 规则趋势 | 折线图:偏差和规则的变化趋势 |
| Bug 严重度分布 | 各等级 Bug 统计 |
| 自检通过率 | 折线图:代码审查质量趋势 |
| 任务完成进度 | 各阶段任务状态 |
| 文件修改热点 | 哪些文件被反复修改 |
| 规则溯源表 | 每条规则关联到产生它的偏差 |
| 完整时间线 | 所有事件按时间排列 |
技术栈:React 19 + ECharts + Tailwind CSS 4,支持中英文切换,SSE 实时推送。
六、三种使用模式
AIDA 设计上是可以按需组合的,不是非得全套使用:
模式一:纯数据采集(最轻量)
只加 MCP 配置,正常 coding。AIDA 静默采集,想看数据时开看板。零学习成本,适合个人开发者先试试水。
模式二:数据采集 + 规则沉淀
在模式一基础上,当 AI 犯错时主动记录偏差,确认后沉淀规则。逐步建立项目专属的 AI 知识库。
模式三:完整 SOP 流程
bash
aida init # 选择 Full workflow
aida start # 创建开发运行获得 14 个 AI Skills,编排为标准开发流程:
PRD 接入 → 需求分析 → 任务拆分 → 代码生成 → 自检审查 → Bug 修复 → 偏差记录 → 规则沉淀适合团队标准化 AI 开发流程,每个环节有对应的 Skill 执行,中断后可从断点恢复。
七、绩效汇报:数据比感觉有说服力
所有数据都是结构化 JSON,可以直接拿来做汇报:
| 汇报场景 | AIDA 能提供的数据 |
|---|---|
| H1/H2 绩效 | 完成 XX 个任务、修复 XX 个 Bug、首次自检通过率 XX%、沉淀 XX 条规则、产出 XXXX 行代码 |
| Sprint 回顾 | 本轮偏差集中在哪个类别、新增了几条规则、质量指标变化 |
| 团队报告 | 各开发者任务量/偏差率/规则贡献对比 |
| 项目交接 | 完整开发历史 + 规则库,新人接手直接受益 |
bash
aida report # 生成汇总数据以前写绩效靠回忆,现在一条命令导出全部数据。
八、数据模型
.aidevos/
├── runs/
│ └── {分支名}/
│ ├── requirement.json # 分支聚合统计
│ └── {开发者}/
│ └── run.json # 核心数据文件
├── rules/
│ ├── rules.json # 规则注册表 (source of truth)
│ ├── component.md # 按分类自动生成的视图
│ └── api.md
├── index.json # 项目级索引
└── aida-guide.md # AI 行为引导run.json 包含:tasks、bugs、deviations、reviews、files、timeline、rules、highlights、metrics、cost 等完整维度。
九、项目信息
- GitHub:https://github.com/LWTlong/ai-dev-analytics
- npm:https://www.npmjs.com/package/ai-dev-analytics
- 在线 Demo:https://lwtlong.github.io/ai-dev-analytics/
- Glama:https://glama.ai/mcp/servers/LWTlong/ai-dev-analytics
- 认证:Glama.ai 安全 A / 许可 A / 质量 A
- 协议:MIT
- 技术栈:Node.js + TypeScript / React 19 + ECharts / MCP over stdio
- 测试:82 个用例,29 个测试套件,全部通过
- 依赖:零运行时依赖
总结
AIDA 解决的核心问题:AI 辅助开发缺乏可观测性。
你不知道 AI 在你的项目里表现怎么样、哪里容易出错、怎么才能让它变好。AIDA 把这些全量数据化:采集 → 可视化 → 沉淀规则 → 反哺 AI → 循环改进。
不是替代你的工作流,而是在你现有工作流上加一层数据采集。一行配置接入,想用多少用多少。
如果你也在用 AI 写代码,不妨试试。有问题欢迎交流。
没有数据的 Vibe Coding 只是在 Vibe。有了数据,你的 AI 每次运行都在进化。
如果觉得有用,欢迎 star 支持一下。有问题直接提 Issue,会认真回复。