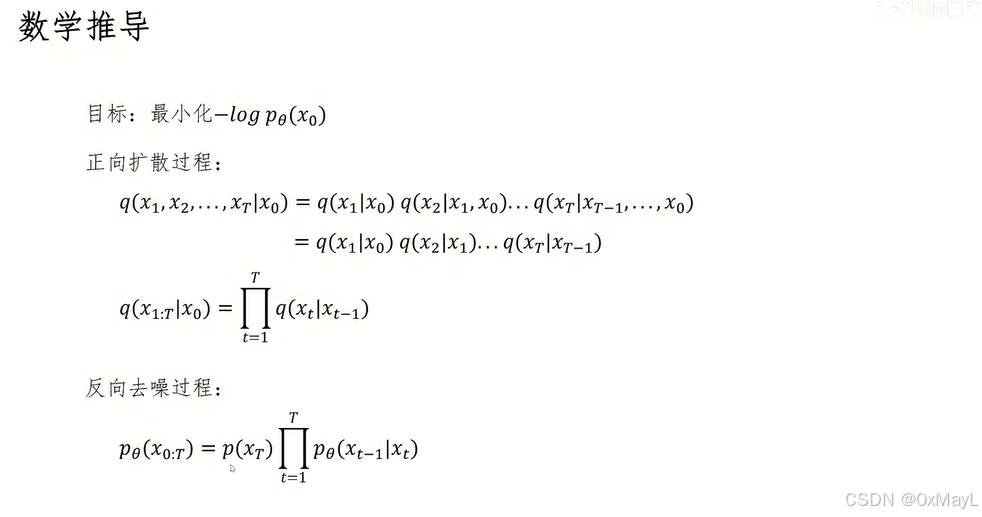文章目录
- DDPM
- 一、前向加噪(已知过程)
-
- [1️⃣ 单步加噪](#1️⃣ 单步加噪)
- [2️⃣ 多步闭式(最关键)](#2️⃣ 多步闭式(最关键))
- 二、反向去噪(模型学习的对象)
-
- [3️⃣ 模型定义](#3️⃣ 模型定义)
- 三、训练目标(ELBO)
-
- [4️⃣ 原始目标](#4️⃣ 原始目标)
- [5️⃣ 变分下界(ELBO)](#5️⃣ 变分下界(ELBO))
- [四、最关键的一步(KL 形式)](#四、最关键的一步(KL 形式))
- 五、最终训练目标(实际用的)
-
- [6️⃣ 噪声预测目标(核心)](#6️⃣ 噪声预测目标(核心))
- 这一公式的真正含义:
- 六、为什么是"预测噪声"而不是"预测图像"
- 七、生成过程(训练完成后)
-
- [7️⃣ 采样公式](#7️⃣ 采样公式)
- 八、核心逻辑总结
- 九、最关键的三条(建议记忆)
-
-
- [1️⃣ 加噪公式](#1️⃣ 加噪公式)
- [2️⃣ 模型输出](#2️⃣ 模型输出)
- [3️⃣ 训练目标](#3️⃣ 训练目标)
-
- 一句话总结
DDPM
一、前向加噪(已知过程)
1️⃣ 单步加噪
q ( x t ∣ x t − 1 ) = N ( x t ; ; α t x t − 1 , ; ( 1 − α t ) I ) q(x_t \mid x_{t-1}) = \mathcal{N}\big(x_t;; \sqrt{\alpha_t}x_{t-1},; (1-\alpha_t)I\big) q(xt∣xt−1)=N(xt;;αt xt−1,;(1−αt)I)
含义:
- 每一步 = "缩小原图 + 加一点高斯噪声"
- α t \alpha_t αt 控制保留多少原信息
2️⃣ 多步闭式(最关键)
q ( x t ∣ x 0 ) = N ( x t ; ; α ˉ t x 0 , ; ( 1 − α ˉ t ) I ) q(x_t \mid x_0) = \mathcal{N}\big(x_t;; \sqrt{\bar{\alpha}_t}x_0,; (1-\bar{\alpha}_t)I\big) q(xt∣x0)=N(xt;;αˉt x0,;(1−αˉt)I)
等价写法:
x t = α ˉ t x 0 + 1 − α ˉ t , ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t},\epsilon,\quad \epsilon \sim \mathcal{N}(0,I) xt=αˉt x0+1−αˉt ,ϵ,ϵ∼N(0,I)
含义(非常重要):
任意一步的加噪,可以直接由"原图 + 一次高斯噪声"得到
二、反向去噪(模型学习的对象)
3️⃣ 模型定义
p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1} \mid x_t) pθ(xt−1∣xt)
含义:
- 学习从"更噪的图"恢复"稍微干净一点的图"
- 这是整个生成过程的核心
三、训练目标(ELBO)
4️⃣ 原始目标
min − log p θ ( x 0 ) \min -\log p_\theta(x_0) min−logpθ(x0)
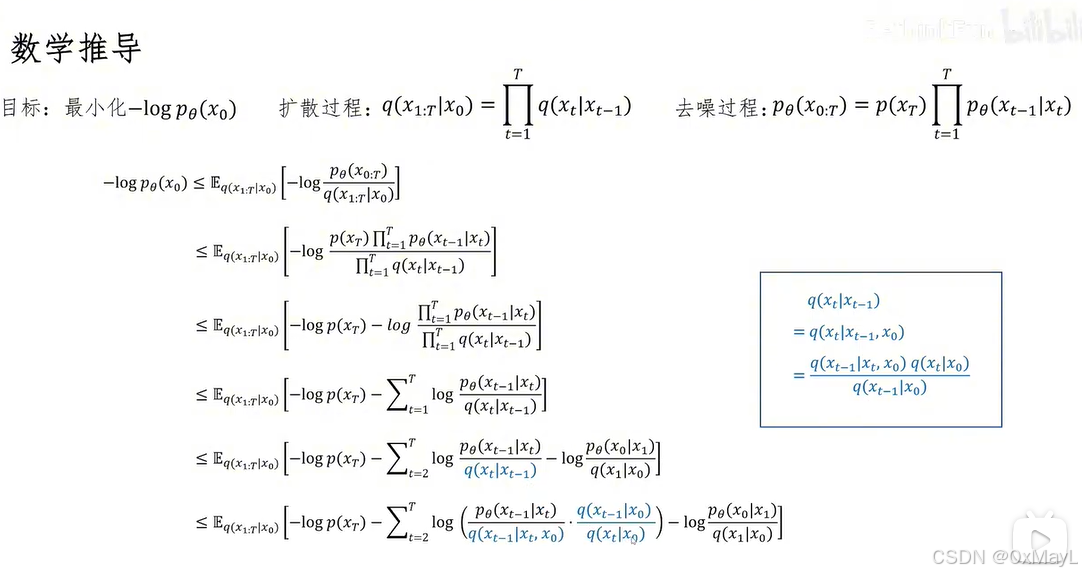
5️⃣ 变分下界(ELBO)
L E L B O = E ∗ q ( x ∗ 1 : T ∣ x 0 ) log q ( x 1 : T ∣ x 0 ) log p θ ( x 0 : T ) \mathcal{L}_{ELBO}= \mathbb{E}*{q(x*{1:T}\mid x_0)} \left \\log q(x_{1:T}\\mid x_0) \\log p_\\theta(x_{0:T}) \\right LELBO=E∗q(x∗1:T∣x0)logq(x1:T∣x0)logpθ(x0:T)
含义:
用一个"可计算的上界"去优化原本不可计算的似然
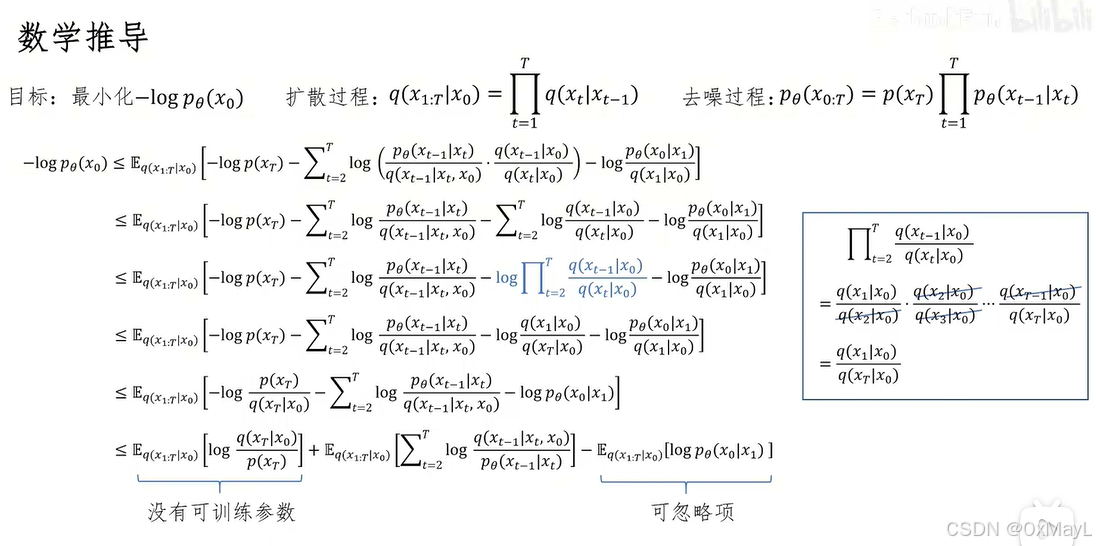
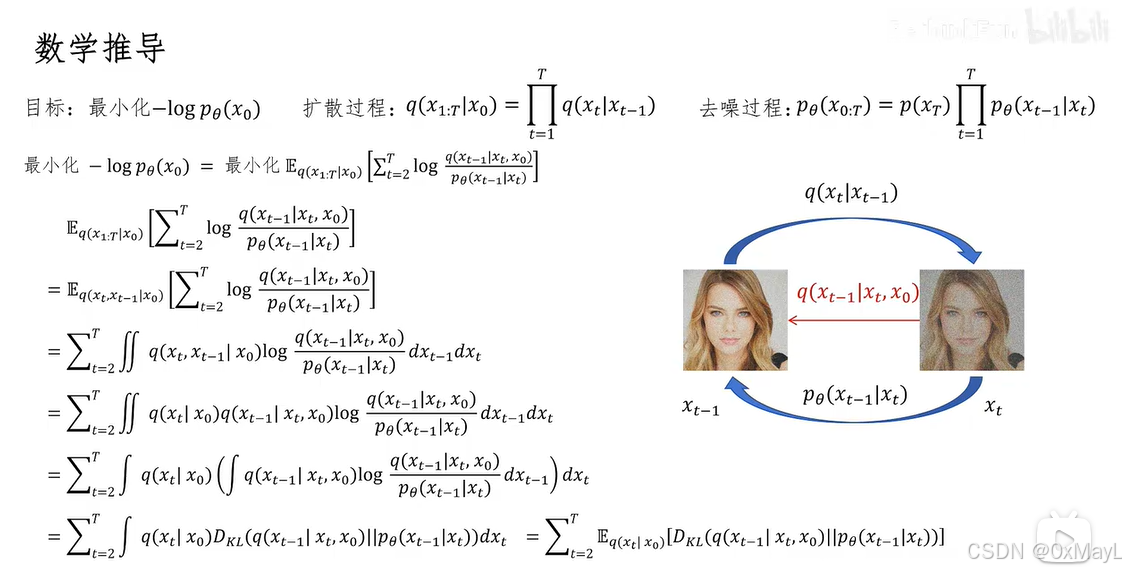
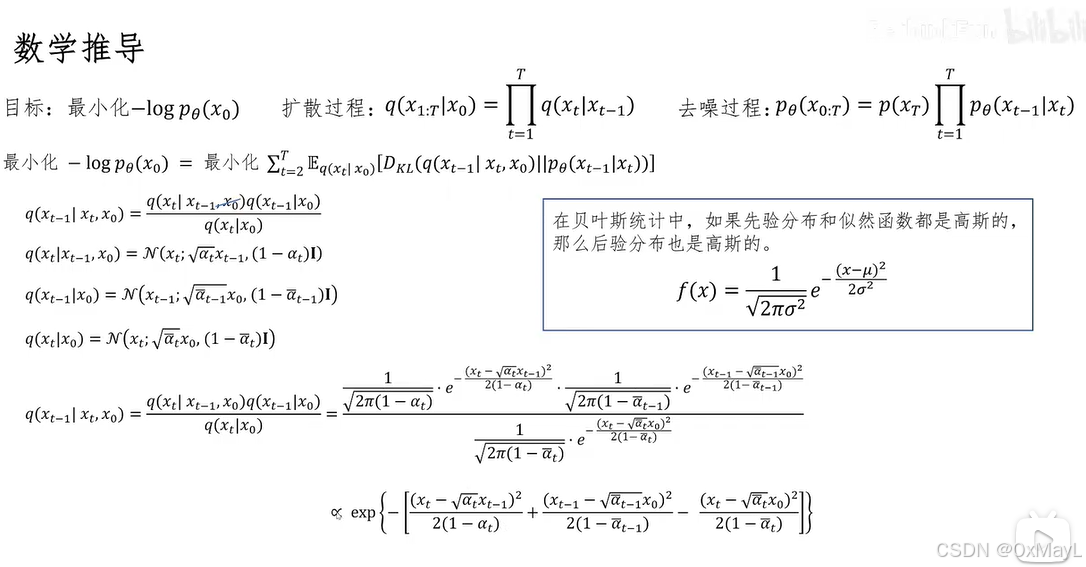
四、最关键的一步(KL 形式)
训练本质变成:
E ∗ q K L ( q ( x ∗ t − 1 ∣ x t , x 0 ) ; ∣ ; p θ ( x t − 1 ∣ x t ) ) \mathbb{E}*q\left \\mathrm{KL}\\big(q(x\*{t-1}\\mid x_t,x_0);\|;p_\\theta(x_{t-1}\\mid x_t)\\big) \\right E∗qKL(q(x∗t−1∣xt,x0);∣;pθ(xt−1∣xt))
含义:
让模型学到"真实的去噪过程"
五、最终训练目标(实际用的)
6️⃣ 噪声预测目标(核心)
L = E t , x 0 , ϵ ∣ ϵ − ϵ ∗ θ ( x t , t ) ∣ 2 \mathcal{L} =\mathbb{E}^{t,x_0,\epsilon} \left \|\\epsilon - \\epsilon\*\\theta(x_t,t)\|\^2 \\right L=Et,x0,ϵ∣ϵ−ϵ∗θ(xt,t)∣2
这一公式的真正含义:
- ϵ \epsilon ϵ:真实加进去的噪声(已知)
- ϵ θ \epsilon_\theta ϵθ:模型预测的噪声
- 目标:让两者尽可能一致
六、为什么是"预测噪声"而不是"预测图像"
关键等价关系:
x 0 1 α ˉ t ( x t − 1 − α ˉ t , ϵ ) x_0 \frac{1}{\sqrt{\bar{\alpha}_t}} \left( x_t - \sqrt{1-\bar{\alpha}_t},\epsilon \right) x0αˉt 1(xt−1−αˉt ,ϵ)
含义:
只要知道噪声,就可以恢复原图
因此:
- 预测 x 0 x_0 x0 ⇔ 预测 ϵ \epsilon ϵ
- 但预测 ϵ \epsilon ϵ 更稳定、更容易训练
七、生成过程(训练完成后)
7️⃣ 采样公式
x t − 1 由 x t 和 ϵ θ ( x t , t ) 计算 x_{t-1} \text{由 } x_t \text{ 和 } \epsilon_\theta(x_t,t) \text{ 计算} xt−1由 xt 和 ϵθ(xt,t) 计算
(具体形式略)
含义:
- 从纯噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0,I) xT∼N(0,I) 开始
- 一步步去噪,最终得到图像
八、核心逻辑总结
前向过程(已知)
x 0 → x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_0 \rightarrow x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon x0→xt=αˉt x0+1−αˉt ϵ
训练目标
ϵ θ ( x t , t ) ≈ ϵ \epsilon_\theta(x_t,t) \approx \epsilon ϵθ(xt,t)≈ϵ
生成过程
x T → x T − 1 → ⋯ → x 0 x_T \rightarrow x_{T-1} \rightarrow \cdots \rightarrow x_0 xT→xT−1→⋯→x0
九、最关键的三条(建议记忆)
1️⃣ 加噪公式
x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon xt=αˉt x0+1−αˉt ϵ
👉 任意步加噪
2️⃣ 模型输出
ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)
👉 模型预测噪声
3️⃣ 训练目标
∣ ϵ − ϵ θ ∣ 2 |\epsilon - \epsilon_\theta|^2 ∣ϵ−ϵθ∣2
👉 实际优化目标
一句话总结
DDPM 的核心数学本质:用高斯加噪构造一个可控的概率路径,并训练模型去预测该路径中的噪声,从而学习其逆过程。
推导过程