大家好,我是小锋老师,最近更新《2027版 基于LangChain的RAG与Agent智能体 开发视频教程》专辑,感谢大家支持。
本课程主要介绍和讲解RAG,LangChain简介,接入通义千万大模型 ,Ollama简介以及安装和使用,OpenAI 库介绍和使用,以及最重要的基于LangChain实现RAG与Agent智能体开发技术。
视频教程+课件+源码打包下载 :
链接:https://pan.baidu.com/s/1_NzaNr0Wln6kv1rdiQnUTg
提取码:0000
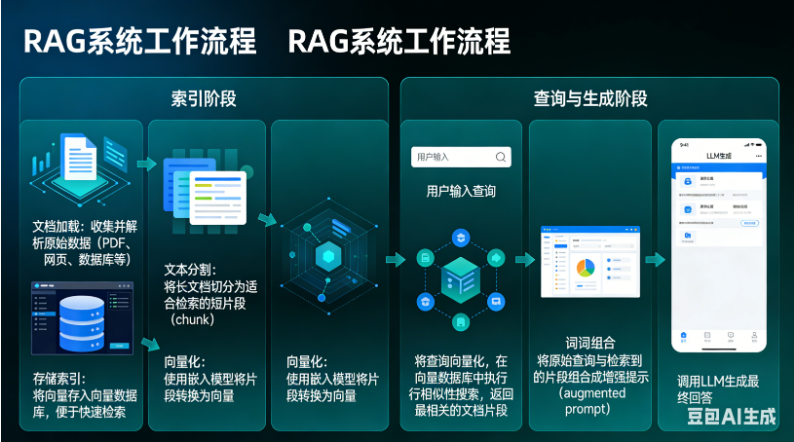
基于LangChain的RAG与Agent智能体开发 - 文档分割器

1️⃣ 什么是文档分割器(Document Splitter)?
在 LangChain 中,文档分割器是用来把一个大文档拆分成更小的部分的工具。这在处理 文本嵌入(embedding) 、向量数据库(vector database)检索 和 大语言模型问答(LLM QA) 时非常重要。
原因如下:
-
大多数 LLM 对输入长度有限制,如果文档太长,会报错或截断。
-
小块文本更容易与问题匹配,提高检索效率和准确率。
-
可以对文本进行分段处理,比如按句子、段落或自定义大小拆分。
2️⃣ LangChain 常用的文档分割器
LangChain 提供了几种常用的文档分割策略:
| 分割器 | 描述 |
|---|---|
| CharacterTextSplitter | 按字符数拆分,可以控制每块文本的最大长度和重叠长度。 |
| RecursiveCharacterTextSplitter | 递归字符拆分器,会先按大段落拆分,如果段落太长,再按句子拆分,层层递进。 |
| MarkdownHeaderTextSplitter | 按 Markdown 的标题层级拆分文本。 |
| Language-aware Splitters | 按语言特性拆分,如按句号、换行符等智能拆分。 |
CharacterTextSplitter字符文档分割器
CharacterTextSplitter 是 LangChain 框架中一个基础的文本分割工具,用于将长文档或文本切分成较小的块(chunks)。它主要基于指定的字符(如换行符、空格或任意自定义字符)进行分割,并允许设置块大小和重叠部分,以便在后续处理(如向量化嵌入、检索增强生成等)中保持语义连贯性,同时避免因文本过长而超出模型限制。
主要参数
-
separator :分割符,默认为
"\n\n"(两个换行符),也可以指定为其他字符或字符串。 -
chunk_size:每个文本块的最大字符数。
-
chunk_overlap:相邻块之间重叠的字符数,用于保持上下文的连续性。
-
length_function :计算文本长度的函数,默认为
len(按字符数计算)。
工作原理
-
按分隔符将文本初步分割成小段。
-
合并小段,直到达到
chunk_size大小,形成块。 -
如果合并后超过大小,则尝试从分隔符位置截断;若无法截断,则强制按字符数切割。
-
块之间按
chunk_overlap保留重叠内容。
我们看一个简单示例:
from langchain_text_splitters import CharacterTextSplitter
# 示例文本
text = """LangChain 是一个用于构建 LLM 应用的框架。它可以帮助你连接模型、管理对话状态和处理文档。
文档分割器是 LangChain 的重要工具,它能把长文本拆分为更小的片段,方便向量化和检索。
你可以根据字符数、段落或者 Markdown 结构进行拆分。"""
# 创建 CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n", # 按换行符拆分
chunk_size=50, # 每块文本最大长度
chunk_overlap=10 # 块之间重叠长度
)
# 拆分文本
chunks = text_splitter.split_text(text)
# 输出结果
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i + 1} ---")
print(chunk)运行下:

RecursiveCharacterTextSplitter递归字符拆分器文档分割器
RecursiveCharacterTextSplitter 是 LangChain 框架中最核心、最常用的文本分割器,也是官方推荐的通用文本分割工具。它采用递归算法和多级分隔符优先级策略,在满足大模型输入长度限制的同时,最大程度地保留文本的语义完整性。
核心工作原理
RecursiveCharacterTextSplitter 的工作方式可以概括为:按优先级顺序尝试多种分隔符进行递归分割。
-
多级分隔符列表 :它维护一个按优先级排序的分隔符列表,默认值为
["\n\n", "\n", " ", ""] -
递归分割过程:
-
首先尝试用最高优先级的分隔符(如段落分隔符
\n\n)分割文本 -
如果分割后某个块仍然超过
chunk_size,则对该块使用下一个优先级的分隔符(如句子分隔符\n)继续分割 -
如果仍然过大,继续使用更低优先级的分隔符(如空格、字符)分割
-
这个过程递归进行,直到所有块都满足大小要求
-
这种设计确保了语义相关性最强的文本片段尽可能保持在一起:优先保持段落完整,其次是句子,再次是词语,最后才按字符切割。
主要参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
separators |
Liststr | ["\n\n", "\n", " ", ""] |
按优先级排序的分隔符列表 |
chunk_size |
int | 4000 | 每个文本块的最大字符数 |
chunk_overlap |
int | 200 | 相邻块之间的重叠字符数,保持上下文连贯 |
length_function |
Callable | len |
计算文本长度的函数 |
is_separator_regex |
bool | False | 分隔符是否作为正则表达式处理 |
keep_separator |
bool | False | 是否在块中保留分隔符 |
核心优势
-
语义完整性:尽可能在自然边界(段落、句子)处分割,避免切断完整语义单元
-
灵活性高:支持自定义分隔符列表,适应不同语言和文档类型
-
自适应处理:递归机制自动处理各种长度的文本块,无需手动干预
-
上下文保持:通过重叠部分确保相邻块之间的语义连贯性
适用场景
-
长文档处理:文章、报告、书籍章节
-
RAG应用:检索增强生成中的文档分块
-
中文文本:特别适合中文,可自定义中文标点作为分隔符
-
混合格式文档:包含段落、列表、代码的复杂文本
-
多语言文本:通过调整分隔符适应不同语言特点
我们看一个示例:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 创建TextLoader对象
loader = TextLoader(
file_path="../data/langchain文档.txt",
encoding="utf-8",
)
# 一次性加载数据
documents = loader.load()
# print(len(documents), documents)
# print(documents[0].page_content)
# 针对中文优化的分隔符列表
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 块大小
chunk_overlap=50, # 重叠大小
length_function=len, # 长度函数
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""] # 优先按段落、句子、标点切
)
split_documents = text_splitter.split_documents(documents)
for i, doc in enumerate(split_documents):
print(f"--- Chunk {i + 1} ---")
print(doc.page_content)运行结果:

MarkdownHeaderTextSplitter文档分割器
MarkdownHeaderTextSplitter 是 LangChain 框架中专为 Markdown 文档设计的智能分割器。它能够根据 Markdown 的标题层级(如 #, ##, ### 等)来分割文档,同时保留文档的层级结构和元数据信息。
核心工作原理
MarkdownHeaderTextSplitter 的核心思想是:按标题层级维护文档的树状结构。它通过以下方式工作:
-
识别标题层级:解析 Markdown 文档中的各级标题(H1, H2, H3...)
-
构建层级关系:将内容组织为树状结构,保持父子标题的从属关系
-
生成分割块:根据指定的标题层级策略,将文档分割成带有完整上下文信息的块
-
保留元数据:每个分割块都包含其所属的标题层级路径作为元数据
这种设计确保了分割后的块不仅包含内容,还保留了文档的结构信息,对于需要理解文档上下文的 RAG 应用特别有价值。
主要参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
headers_to_split_on |
ListTuple\[int, str] | 必填 | 指定要分割的标题层级和名称,如 [("#", "H1"), ("##", "H2")] |
return_each_line |
bool | False | 是否逐行返回(用于调试) |
strip_headers |
bool | True | 是否从内容中移除标题文本 |
返回的 Document 对象属性
每个分割后的 Document 对象包含:
-
page_content:文本内容
-
metadata :包含标题层级路径的字典,如
{"H1": "第一章", "H2": "第一节"}
我们提供下md文档:
# 第一章:人工智能概述
人工智能是计算机科学的重要分支。
## 1.1 人工智能的定义
人工智能(AI)是让机器模拟人类智能的技术。
### 1.1.1 弱人工智能
专注于特定任务的AI系统,如语音助手。
### 1.1.2 强人工智能
具有人类级别通用智能的系统。
## 1.2 人工智能的发展历程
AI发展经历了三次浪潮。
# 第二章:机器学习基础
机器学习是实现AI的核心方法。
## 2.1 监督学习
使用标注数据训练模型。我们先获取md文档内容,然后精心md文档分割,我们看下示例:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 创建TextLoader对象
loader = TextLoader(
file_path="../data/人工智能.md",
encoding="utf-8",
)
# 一次性加载数据
documents = loader.load()
print(len(documents), documents)
print(documents[0].page_content)
# 创建分割器:按 H1 和 H2 层级分割
headers_to_split_on = [
("#", "H1"), # H1 标题,元数据键名为 "H1"
("##", "H2"), # H2 标题,元数据键名为 "H2"
]
# 创建分割器对象
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=False # 保留标题在内容中
)
split_documents = markdown_splitter.split_text(documents[0].page_content)
for i, doc in enumerate(split_documents):
print(f"--- Chunk {i + 1} ---")
print(doc.page_content)运行输出:
