目录
1.前言
小车倒立摆是经典控制基准模型:环形轨道上的小车+竖直可摆动摆杆,核心目标是通过Q-Learning强化学习控制小车环形运动,让摆杆保持竖直平衡。
2.算法测试效果图预览
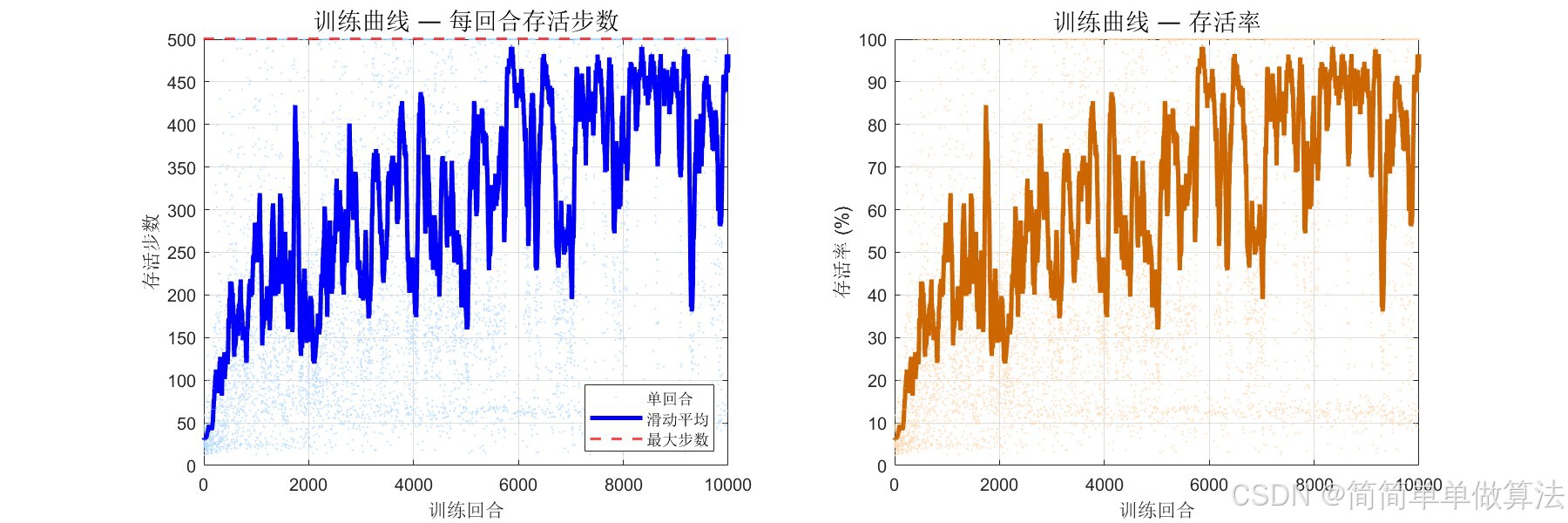
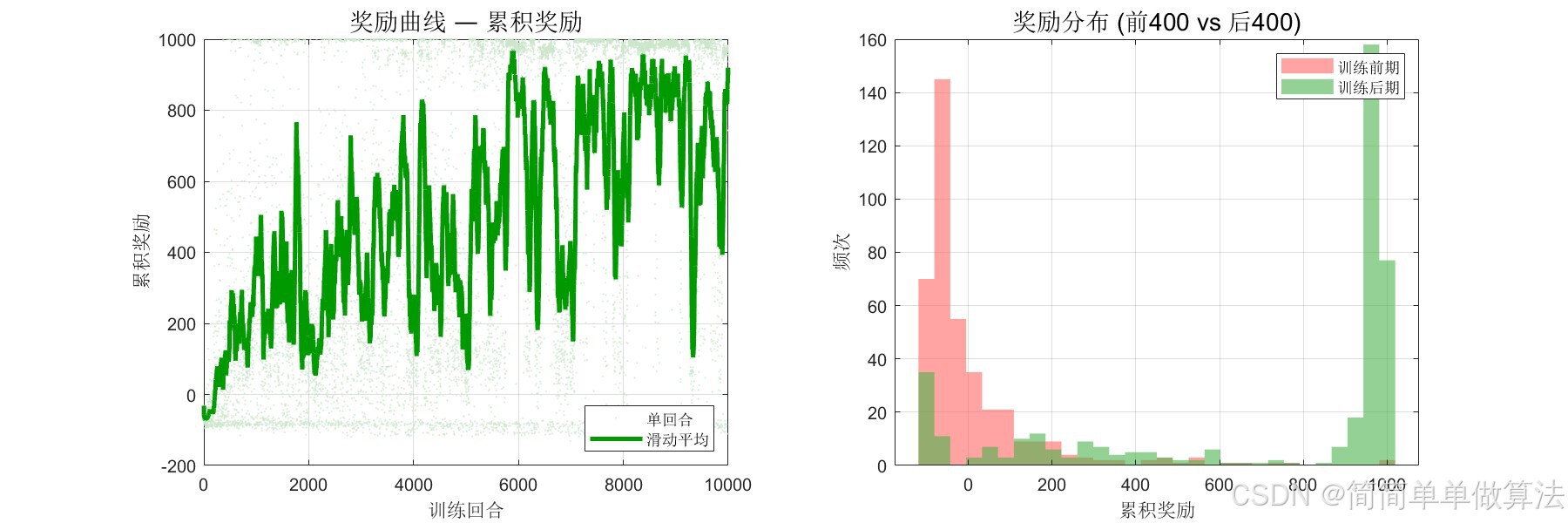

3.算法运行软件版本
matlab2024b
4.部分核心程序
............................................................
for fi = 1:length(frame_idx)
k = frame_idx(fi);
clf;
cx = dat(k,1); cy = dat(k,2); cz = dat(k,3);
tx = dat(k,4); ty = dat(k,5); tz = dat(k,6);
% 更新轨迹
cart_trail = [cart_trail(2:end,:); cx,cy,cz];
top_trail = [top_trail(2:end,:); tx,ty,tz];
hold on;
% 地面
surf(Gx,Gy,Gz-0.05,'FaceAlpha',0.08,'EdgeColor',[.85 .85 .85],...
'FaceColor',[0.9 0.9 1]);
% 轨道
plot3(trk_x,trk_y,trk_z,'k--','LineWidth',1.5);
% 轨迹
valid_c = ~isnan(cart_trail(:,1));
if sum(valid_c)>1
plot3(cart_trail(valid_c,1),cart_trail(valid_c,2),cart_trail(valid_c,3),...
'-','Color',[0.2 0.5 1 0.5],'LineWidth',1.5);
end
valid_t = ~isnan(top_trail(:,1));
if sum(valid_t)>1
plot3(top_trail(valid_t,1),top_trail(valid_t,2),top_trail(valid_t,3),...
'-','Color',[1 0.3 0.3 0.5],'LineWidth',1.5);
end
% ---- 绘制小车(立方体) ----
cart_w = 0.4; cart_h = 0.2; cart_d = 0.3;
phi_now = omega_c*(k-1)*dt;
draw_cart_3d(cx,cy,cz, phi_now, cart_w,cart_h,cart_d);
% ---- 绘制摆杆 ----
plot3([cx tx],[cy ty],[cz tz],'-','Color',[0.8 0.2 0],'LineWidth',5);
% 铰接点
plot3(cx,cy,cz,'ko','MarkerSize',8,'MarkerFaceColor',[0.3 0.3 0.3]);
% 摆杆顶端球
plot3(tx,ty,tz,'o','MarkerSize',12,'MarkerFaceColor',[1 0.2 0.2],...
'MarkerEdgeColor','k','LineWidth',1);
% ---- 绘制轮子 ----
draw_wheel(cx,cy,cz, phi_now, cart_w, cart_h);
hold off;
xlabel('X (m)'); ylabel('Y (m)'); zlabel('Z (m)');
title(sprintf('\\bf 三维环形运动倒立摆平衡控制 t = %.1f s \\theta = %.2f°',...
(k-1)*dt, dat(k,7)*180/pi),'FontSize',14);
axis equal;
xlim([-5 5]); ylim([-5 5]); zlim([-0.5 1.8]);
view(35+0.15*(k-1)*dt*180/pi, 25); % 缓慢旋转视角
grid on; box on;
set(gca,'FontSize',10);
lighting gouraud; camlight('headlight'); camlight('right');
drawnow;
pause(0.01);
end
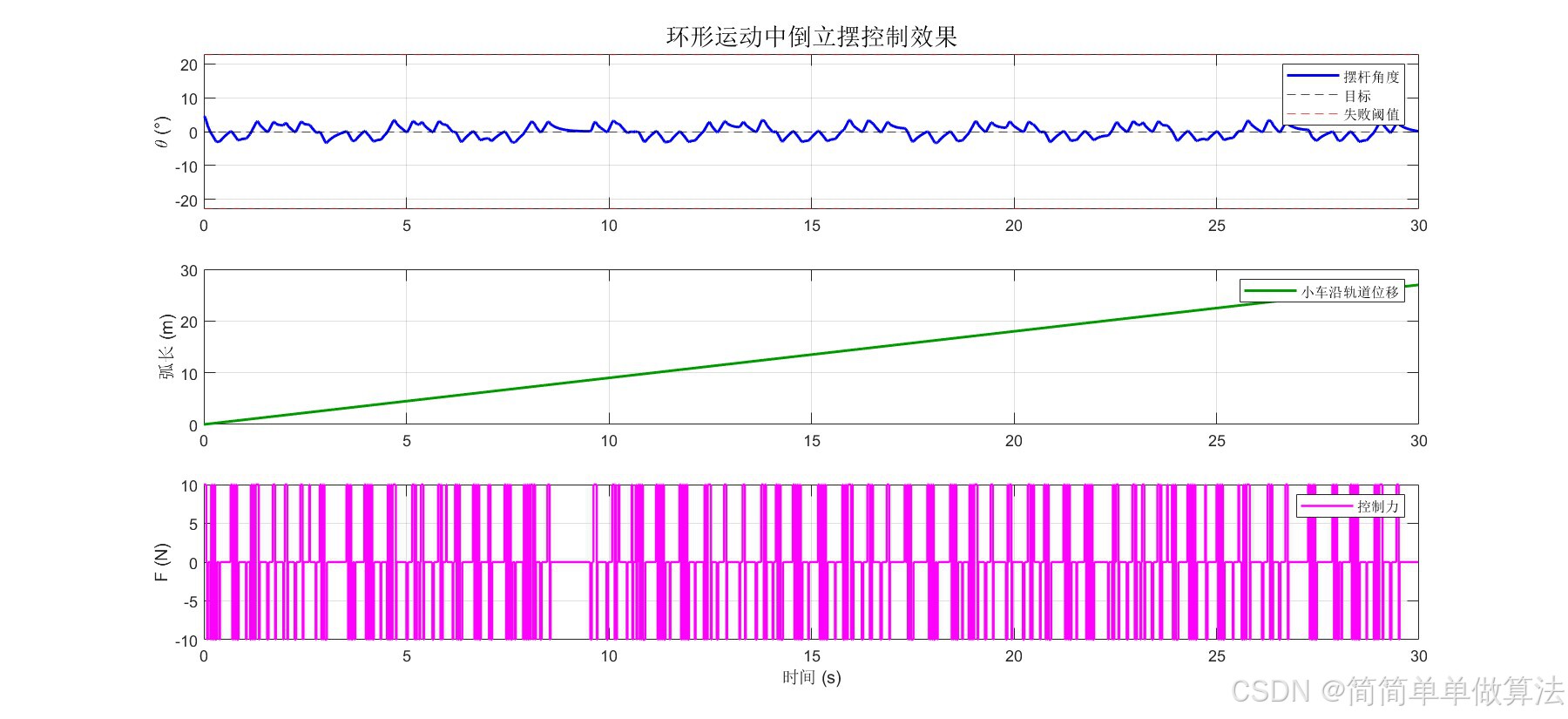
%% ===================== 图4: 控制效果时域曲线 =====================
figure('Position',[100 50 1200 550],'Color','w');
tvec = (0:Nsim-1)*dt;
subplot(3,1,1);
plot(tvec, dat(:,7)*180/pi, 'b-','LineWidth',1.5); hold on;
yline(0,'k--'); yline([-1 1]*th_fail*180/pi,'r--');
ylabel('\theta (°)'); title('环形运动中倒立摆控制效果','FontSize',14);
legend('摆杆角度','目标','失败阈值','Location','ne'); grid on;
subplot(3,1,2);
phi_all = omega_c*tvec;
plot(tvec, R_c*phi_all,'Color',[0 .6 0],'LineWidth',1.5);
ylabel('弧长 (m)'); grid on;
legend('小车沿轨道位移');
subplot(3,1,3);
stairs(tvec, dat(:,8), 'm-','LineWidth',1.2);
xlabel('时间 (s)'); ylabel('F (N)');
legend('控制力'); grid on;
2505.算法理论概述
Q-Learning 是基于价值的无模型强化学习算法,也是强化学习领域最经典、最基础的核心算法之一,由Watkins在1989年提出。它不依赖环境的先验转移概率,通过智能体与环境不断交互试错,学习一个状态 - 动作价值函数(Q函数),最终依靠Q值选择最优动作,实现从任意状态出发获得最大累积奖励的目标,广泛应用于机器人控制、游戏AI、路径规划、资源调度等场景。
强化学习的基本框架包含智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward) 五大核心要素。智能体是执行决策的主体,环境是智能体所处的外部世界;在每一个时间步,智能体感知当前环境的状态,选择一个动作执行,环境会反馈新的状态和即时奖励,智能体的目标就是通过长期学习,最大化未来的总奖励。Q-Learning正是围绕这一框架,通过迭代更新Q值来刻画 "在某一状态下采取某一动作,后续能获得多少长期收益"。
Q-Learning 的核心是Q表,这是一个二维表格,行代表所有可能的状态,列代表所有可选的动作,表格中的每个数值就是对应状态 - 动作对的Q值。初始时Q表中所有值均为0,智能体对环境一无所知,只能随机选择动作;随着交互次数增加,智能体根据奖励信号不断更新Q表,让Q值逐渐逼近真实的长期价值,最终智能体只需在每个状态下选择Q值最大的动作,即为最优策略。
倒立摆动力学模型
小车倒立摆由可水平移动的小车和铰接其上的摆杆组成。设小车位置𝑥,摆杆与竖直方向夹角𝜃,小车质量𝑀,摆杆质量𝑚,摆杆半长𝑙,控制力𝐹,重力加速度𝑔。由拉格朗日方程建立动力学模型:

Q-Learning原理
Q-Learning是无模型、离策略的时序差分强化学习算法,通过学习状态-动作值函数𝑄(𝑠,𝑎)最大化累积回报。Q值迭代更新规则:
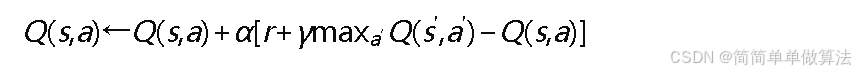
其中𝛼为学习率,𝛾为折扣因子,时序差分误差为:
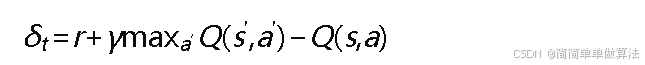
动作空间定义
离散动作集合为施加在小车上的力:

奖励函数设计

ε-贪婪策略
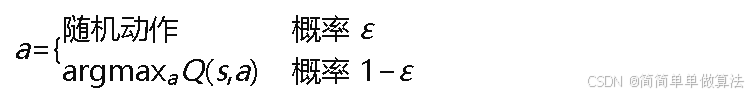
环境状态转移
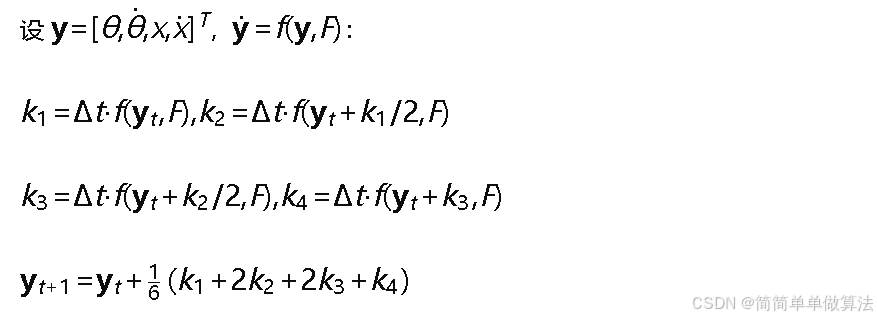
三维环形运动
小车沿半径𝑅圆形轨道运动,参数化坐标:
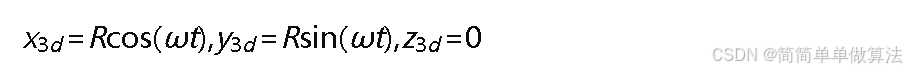
6.算法完整程序工程
OOOOO
OOO
O
关注GZH后输入回复:0033