本文将基于文档智能扫描、视频背景分割与运动目标检测、光流法运动跟踪、CSRT 单目标追踪四大实战场景,结合完整可运行的代码,深度解析 OpenCV 在实时视觉任务中的应用,带你从入门到实战,掌握计算机视觉的核心技能。
一、实战一:基于轮廓检测的智能文档扫描
日常办公中,我们经常需要拍摄纸质文档,但拍摄的照片往往存在倾斜、畸变、背景杂乱等问题。借助 OpenCV 的边缘检测 + 轮廓提取 + 透视变换,可以自动识别文档边缘,将倾斜文档矫正为规整的扫描件,实现媲美专业扫描仪的效果。
1. 核心原理
- 高斯模糊:去除图像噪声,避免边缘检测产生干扰;
- Canny 边缘检测:提取图像中所有物体的轮廓边缘;
- 轮廓筛选:通过面积、顶点数筛选出文档的四边形轮廓;
- 四点透视变换:将倾斜的四边形文档矫正为矩形。
2. 完整代码解析
python
import numpy as np
import cv2
# 图像显示函数:解决OpenCV窗口闪退问题
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(1)
# 对四个顶点排序:左上、右上、右下、左下
def order_points(pts):
rect = np.zeros((4, 2), dtype='float32')
s = pts.sum(axis=1) # 坐标和:左上最小,右下最大
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
diff = np.diff(pts, axis=1) # 坐标差:右上最小,左下最大
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
# 四点透视变换:矫正倾斜图像
def four_point_transform(image, pts):
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算目标图像的宽高
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 目标坐标
dst = np.array([[0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype='float32')
# 计算变换矩阵并执行透视变换
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
# 调用摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print('无法打开摄像头')
exit()
while True:
ret, image = cap.read()
if not ret:
print('无法读取画面')
break
orig = image.copy() # 保存原始图像
cv_show('image', image)
# 1. 图像预处理:灰度化+高斯模糊
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# 2. Canny边缘检测
edged = cv2.Canny(gray, 15, 45)
cv_show('1', edged)
# 3. 提取轮廓并排序(按面积从大到小)
cnts = cv2.findContours(edged, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:3]
image_contours = cv2.drawContours(image, cnts, -1, (0, 255, 0), 2)
cv_show('image_contours', image_contours)
# 4. 筛选文档轮廓:面积>30000且为四边形
screenCnt = None
for c in cnts:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.05 * peri, True) # 多边形逼近
area = cv2.contourArea(approx)
if area > 30000 and len(approx) == 4:
screenCnt = approx
break
# 5. 检测到文档后执行透视变换+二值化
if screenCnt is not None:
cv2.drawContours(image, [screenCnt], 0, (0, 255, 0), 2)
cv_show('image', image)
# 透视矫正
warped = four_point_transform(orig, screenCnt.reshape(4, 2))
cv_show('warped', warped)
# 二值化处理,生成黑白扫描件
warped_gray = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped_gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('ref', ref)
cap.release()
cv2.destroyAllWindows()3. 核心知识点总结
cv2.approxPolyDP():多边形逼近函数,通过控制精度将复杂轮廓简化为四边形,是文档检测的关键;- 透视变换 :通过
cv2.getPerspectiveTransform计算变换矩阵,cv2.warpPerspective实现图像矫正; - 大津阈值分割 :
THRESH_OTSU自动计算最佳阈值,将彩色矫正后的图像转为黑白扫描件,提升可读性。
该方案可直接用于手机文档扫描、试卷矫正、名片识别等场景,是 OpenCV 图像处理的经典应用。
二、实战二:视频背景分割与运动目标检测
在视频监控、人流统计、异常行为检测等场景中,我们需要从固定背景中提取运动目标。OpenCV 提供的MOG2 背景建模算法,可以自动学习视频背景,分离出前景运动目标,结合形态学操作和轮廓检测,实现运动目标的框选与统计。
1. 核心原理
- MOG2 背景减法:基于混合高斯模型建模背景,自动区分静态背景和运动前景;
- 形态学开运算:去除前景掩码中的噪声点,优化目标轮廓;
- 轮廓周长筛选:过滤微小干扰,只保留有效运动目标。
2. 完整代码解析
python
import cv2
import numpy as np
# 读取视频文件
cap = cv2.VideoCapture('test(1).avi')
# 定义形态学卷积核
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3))
# 创建MOG2背景分割器
fgbg = cv2.createBackgroundSubtractorMOG2()
while True:
ret, frame = cap.read()
if not ret:
break # 视频读取完毕则退出
cv2.imshow('frame', frame)
# 1. 背景分割:生成前景掩码
fgmask = fgbg.apply(frame)
cv2.imshow('fgmask', fgmask)
# 2. 形态学开运算:去噪(先腐蚀后膨胀)
fgmask_new = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
cv2.imshow('fgmask1', fgmask_new)
# 3. 提取前景轮廓
contours, _ = cv2.findContours(fgmask_new, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
perimeter = cv2.arcLength(c, True)
# 筛选周长大于188的目标,过滤噪声
if perimeter > 188:
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('fgmask_new_rect', frame)
# 按ESC退出
if cv2.waitKey(60) == 27:
break
cap.release()
cv2.destroyAllWindows()
3. 核心知识点总结
cv2.createBackgroundSubtractorMOG2():自适应背景建模,支持光照变化,比传统帧差法更稳定;- 形态学开运算 :
MORPH_OPEN有效去除前景掩码中的椒盐噪声,保留完整目标轮廓; - 应用场景:停车场车辆检测、商场人流统计、安防监控异常运动报警等。
该方案无需训练模型,实时性强,是工业级视频监控的基础技术。
三、实战三:基于 Lucas-Kanade 光流法的稀疏特征追踪
在目标运动轨迹分析、视频稳像、动作识别等场景中,我们需要跟踪图像中的关键特征点。Lucas-Kanade(LK)光流法是经典的稀疏光流算法,仅跟踪图像中的显著特征点,计算量小、实时性高,适合快速运动目标的轨迹绘制。
1. 核心原理
- Shi-Tomasi 角点检测:提取图像中稳定的角点作为跟踪目标;
- 金字塔 LK 光流:通过多尺度金字塔优化,跟踪大位移的特征点;
- 轨迹绘制:记录特征点的前后帧位置,绘制运动轨迹。
2. 完整代码解析
python
import numpy as np
import cv2
# 读取视频
cap = cv2.VideoCapture('test(1).avi')
# 随机生成100种颜色,用于绘制不同特征点的轨迹
color = np.random.randint(0, 255, (100, 3))
# 读取第一帧,转为灰度图
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
# Shi-Tomasi角点检测参数
feature_params = dict(
maxCorners=100, # 最大角点数量
qualityLevel=0.3, # 质量等级
minDistance=7 # 最小角点间距
)
# 提取初始特征点
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建轨迹绘制掩码
mask = np.zeros_like(old_frame)
# LK光流参数
lk_params = dict(
winSize=(15, 15), # 搜索窗口大小
maxLevel=2 # 金字塔层数
)
while True:
ret, frame = cap.read()
if not ret:
break
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算光流:跟踪特征点
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 筛选跟踪成功的特征点(st=1表示跟踪成功)
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制特征点轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel() # 新坐标
c, d = old.ravel() # 旧坐标
a, b, c, d = int(a), int(b), int(c), int(d)
# 绘制轨迹线
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
cv2.imshow('mask', mask)
# 绘制当前特征点
cv2.circle(frame, (a, b), 3, color[i].tolist(), -1)
# 合并原始帧和轨迹掩码
img = cv2.add(frame, mask)
cv2.imshow('frame', img)
if cv2.waitKey(150) == 27:
break
# 更新上一帧图像和特征点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cap.release()
cv2.destroyAllWindows()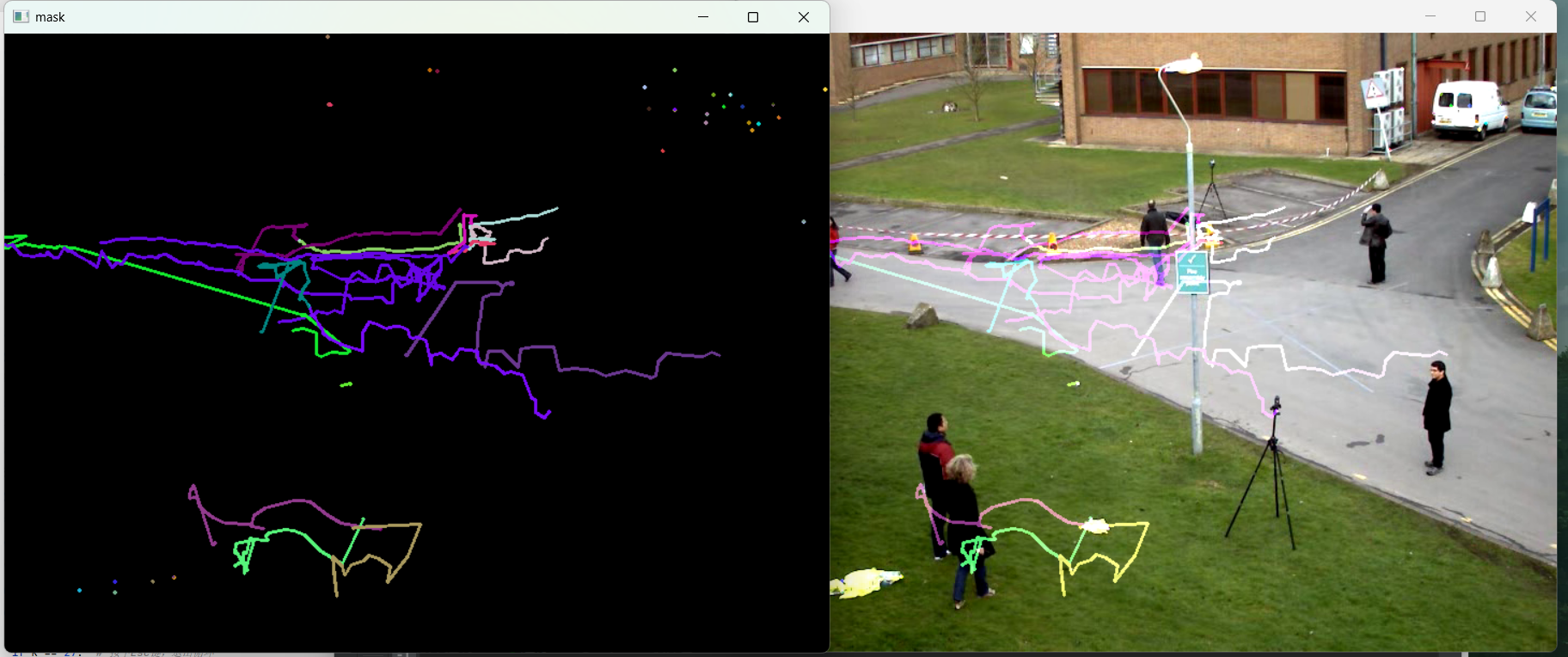
3. 核心知识点总结
cv2.goodFeaturesToTrack():Shi-Tomasi 角点检测,提取稳定性高的特征点,避免跟踪失效;cv2.calcOpticalFlowPyrLK():金字塔 LK 光流,解决大位移目标跟踪问题,精度更高;- 轨迹可视化:通过掩码叠加,直观展示目标运动轨迹,适合运动分析、行为识别等场景。
光流法无需手动框选目标,自动跟踪特征点,是无监督目标跟踪的核心算法。
四、实战四:基于 CSRT 的实时单目标追踪
在视频剪辑、自动驾驶、无人机跟踪等场景中,我们需要手动指定目标并持续跟踪。OpenCV 集成了多种专用追踪器,CSRT(Channel and Spatial Reliability Tracker) 是精度最高的追踪器之一,适合小目标、复杂背景下的精准跟踪。
1. 核心原理
- ROI 手动选取:通过鼠标框选需要跟踪的目标区域;
- CSRT 追踪器:基于空间可靠性的相关滤波算法,抗遮挡、抗形变能力强;
- 实时更新:逐帧计算目标位置,实时绘制追踪框。
2. 完整代码解析
python
import cv2
# 创建CSRT追踪器(高精度首选)
tracker = cv2.TrackerCSRT_create()
tracking = False # 追踪状态标志
cap = cv2.VideoCapture(0) # 调用摄像头
while True:
ret, frame = cap.read()
if not ret:
break
# 按下's'键开始追踪,手动框选目标
if cv2.waitKey(1) & 0xFF == ord('s'):
tracking = True
# 选取ROI区域:鼠标框选,回车确认
roi = cv2.selectROI('Tracking', frame, showCrosshair=False)
tracker.init(frame, roi)
# 启动追踪
if tracking:
success, box = tracker.update(frame)
if success:
# 解析追踪框坐标
x, y, w, h = [int(v) for v in box]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('Tracking', frame)
# 按下ESC退出
if cv2.waitKey(1) == 27:
break
cap.release()
cv2.destroyAllWindows()3. 核心知识点总结
cv2.selectROI():交互式目标选取函数,鼠标框选 + 回车确认,操作简单;- CSRT 追踪器优势:精度高于 KCF、MOSSE 等追踪器,适合复杂环境、小目标跟踪;
- 状态判断 :通过
success返回值判断目标是否丢失,提升系统鲁棒性。
该方案可直接用于无人机目标跟踪、视频人物追踪、运动物体监测等场景。
计算机视觉的应用场景无处不在,从日常办公的文档扫描,到安防监控的目标检测,再到无人机的自动追踪,OpenCV 都扮演着核心角色。希望本文的实战教程能帮助你快速掌握 OpenCV,打开计算机视觉的大门,在视觉领域不断探索与创新。