缓存是性能优化的第一手段。但只用一层 Redis 就够了吗?当 QPS 从 1000 涨到 10 万,单层缓存的网络开销、热 Key 问题、缓存雪崩风险都会暴露出来。本文从"为什么需要多级缓存"讲起,到本地缓存 + 分布式缓存 + CDN 的三级架构落地,再到缓存一致性方案,帮你建立完整的缓存知识体系。
一、为什么单层 Redis 不够?
大部分项目的缓存方案是这样的:
请求 → 查 Redis → 命中返回 / 未命中查数据库 → 回填 Redis
这个方案在 QPS 几千的时候完全没问题。但当流量上来之后,几个问题会暴露:
以下是整理后的表格格式:
| 问题 | 场景 | 后果 |
|---|---|---|
| 网络开销 | 每次请求都要走一次网络 RTT(通常 0.5-2ms) | QPS 10 万时,Redis 网络 I/O 成为瓶颈 |
| 热 Key | 某个商品被疯狂访问,所有请求打到同一个 Redis 节点 | 单节点 CPU 打满,甚至宕机 |
| 雪崩风险 | Redis 集群故障或大面积 key 过期 | 数据库被打崩,服务雪崩 |
| 序列化开销 | 每次从 Redis 取出来都要反序列化 | CPU 消耗叠加,P99 延迟上升 |
多级缓存的核心思想:越靠近用户的缓存越快、命中率越高,越靠后的缓存容量越大、数据越全。
二、多级缓存架构全景
subunit
┌─────────────┐
│ 客户端 │
└──────┬──────┘
│
┌──────▼───────┐
│ CDN │ • 静态资源 + 接口缓存
│ │ • 延迟 < 5ms
│ 命中率60-80% │
└──────┬───────┘
│ 未命中
┌──────▼───────┐
│ 本地缓存 │ • Caffeine/Guava
│ │ • 延迟 < 0.1ms
│ 命中率30-50% │ • 容量:百MB级
└──────┬───────┘
│ 未命中
┌──────▼───────┐
│ 分布式缓存 │ • Redis Cluster
│ │ • 延迟 0.5-2ms
│ 命中率95%+ │ • 容量:百GB级
└──────┬───────┘
│ 未命中
┌──────▼───────┐
│ 数据库 │ • MySQL/PostgreSQL
│ │ • 延迟 5-50ms
└──────────────┘
三级命中后的综合效果 :假设总 QPS 10 万,CDN 挡住 70%,本地缓存再挡住剩余的 40%,Redis 再挡住 95%------最终打到数据库的请求只有 ++10 万 × 30% × 60% × 5% = 900 QPS++,数据库毫无压力。
三、第一级:本地缓存(Caffeine)
为什么把本地缓存放在第一个讲?因为 CDN 不是所有场景都有,但本地缓存几乎每个 Java 项目都用得上。
3.1 为什么选 Caffeine?
以下是整理后的表格格式:
| 对比项 | Guava Cache | Caffeine | HashMap |
|---|---|---|---|
| 淘汰算法 | LRU | W-TinyLFU | 无 |
| 性能 | 高 | 极高(Guava 的 2-3 倍) | 最高但无淘汰 |
| 过期策略 | 支持 | 支持 | 不支持 |
| 统计 | 支持 | 支持 | 不支持 |
| Spring 集成 | 支持 | 默认 CacheManager | 手动 |
Caffeine 是目前 Java 生态最强的本地缓存库。Spring Boot 默认的 `CacheManager` 实现就是 Caffeine。
3.2 W-TinyLFU:为什么 Caffeine 这么快
传统 LRU 的问题:**偶发访问会挤掉高频数据**。比如一次全表扫描会把热点数据全部挤出缓存。
Caffeine 用的 W-TinyLFU(Window TinyLFU)算法,本质是"频率 + 新鲜度"双维度淘汰:
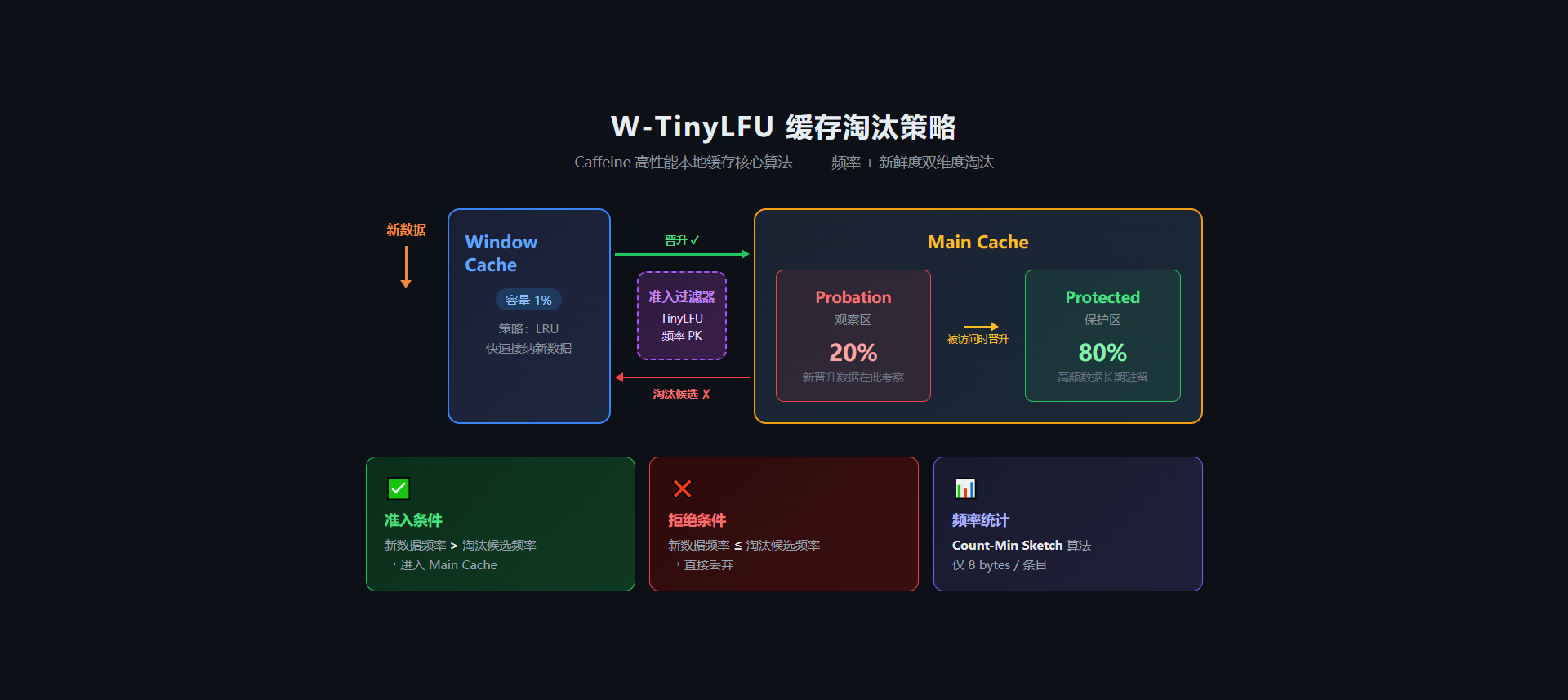
面试这样答:Caffeine 用 W-TinyLFU 算法,结合了 LRU 和 LFU 的优点。新数据先进入 Window 区(LRU),要晋升到 Main 区需要和候选淘汰项比频率,频率高的才能留下。这样既能快速接纳新数据,又不会让低频的突发访问挤掉高频热点。
3.3 Caffeine 实战代码
(1)基础用法:
java
// 1. 手动创建
Cache<String, User> cache = Caffeine.newBuilder()
.maximumSize(10_000) // 最大条目数
.expireAfterWrite(Duration.ofMinutes(5)) // 写入后 5 分钟过期
.expireAfterAccess(Duration.ofMinutes(1)) // 1 分钟没访问就过期
.recordStats() // 开启统计(命中率等)
.build();
// 写入
cache.put("user:1001", user);
// 读取(手动模式)
User user = cache.getIfPresent("user:1001");
// 读取(自动加载模式,缓存未命中时自动调用 loader)
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(Duration.ofMinutes(5))
.build(key -> userMapper.selectById(extractId(key))); // loader
User user = loadingCache.get("user:1001"); // 未命中时自动查库(2)Spring Boot 集成:
java
# application.yml
spring:
cache:
type: caffeine
caffeine:
spec: maximumSize=10000,expireAfterWrite=300s
java
@Service
public class UserService {
@Cacheable(value = "users", key = "#id")
public User getUser(Long id) {
// 缓存未命中时才执行
return userMapper.selectById(id);
}
@CacheEvict(value = "users", key = "#user.id")
public void updateUser(User user) {
userMapper.updateById(user);
}
}3.4 本地缓存的坑
问题表格整理
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 数据不一致 | 多个实例各自缓存,A 实例更新了 B 实例不知道 | 使用 Redis Pub/Sub 通知其他节点清除本地缓存 |
| 内存溢出 | 缓存对象太大或太多 | 设置 maximumSize/maximumWeight,避免将大对象存入本地缓存 |
| GC 压力 | 大量缓存对象增加 GC 负担 | 控制本地缓存总大小在堆内存的 10-20% 以内 |
| 冷启动 | 重启后本地缓存为空,流量全打到 Redis | 启动时预热:主动加载热点数据 |
四、第二级:分布式缓存(Redis)
Redis 的基础就不重复了(前面的文章已经讲过),这里聚焦在多级缓存架构中 Redis 的定位和优化。
4.1 Redis 在多级缓存中的角色
本地缓存未命中 → 查 Redis → 命中则回填本地缓存 → 未命中则查数据库 → 回填 Redis + 本地缓存
Redis 是**数据一致性的锚点**。多个应用实例的本地缓存可能各不相同,但 Redis 里的数据是统一的。
4.2 热 Key 问题与解决方案
什么是热 Key?
某个 key 被大量请求集中访问,所有请求打到 Redis 集群的同一个节点,单节点扛不住。
典型场景:秒杀商品详情、热搜榜单、明星八卦文章。
如何发现热 Key?
方法一:Redis 4.0+ 内置命令(线上慎用,会遍历所有 key)
redis-cli --hotkeys
方法二:monitor + 统计(采样分析)
redis-cli monitor | head -n 10000 > monitor.log
方法三:客户端统计(推荐)
在 RedisTemplate 中包装一层,统计每个 key 的访问次数
超过阈值的自动标记为热 Key
解决方案:
热 Key 解决思路
├── 方案一:本地缓存兜底(最推荐)
│ 热 Key 自动提升到本地缓存,不再走网络
│
├── 方案二:Key 分散
│ 将 hot_product:1001 拆成 hot_product:1001:0 ~ :9
│ 读取时随机选一个副本,写入时更新所有副本
│ 分散到不同 Redis 节点
│
└── 方案三:读写分离
热 Key 走从节点读,分散读压力
==> 方案一代码实现(本地缓存 + Redis 二级联动):
java
@Service
public class MultiLevelCacheService {
private final LoadingCache<String, String> localCache;
private final StringRedisTemplate redis;
private final JdbcTemplate jdbc;
public MultiLevelCacheService(StringRedisTemplate redis, JdbcTemplate jdbc) {
this.redis = redis;
this.jdbc = jdbc;
this.localCache = Caffeine.newBuilder()
.maximumSize(5000)
.expireAfterWrite(Duration.ofSeconds(30)) // 本地缓存过期短一点
.build(this::loadFromRedis); // 未命中走 Redis
}
/**
* 多级缓存读取:本地缓存 → Redis → 数据库
*/
public String get(String key) {
return localCache.get(key);
}
private String loadFromRedis(String key) {
// 第二级:查 Redis
String value = redis.opsForValue().get(key);
if (value != null) {
return value;
}
// 第三级:查数据库
value = loadFromDB(key);
if (value != null) {
// 回填 Redis,过期时间加随机偏移防雪崩
int ttl = 3600 + ThreadLocalRandom.current().nextInt(600);
redis.opsForValue().set(key, value, Duration.ofSeconds(ttl));
}
return value;
}
private String loadFromDB(String key) {
// 实际查数据库逻辑
return jdbc.queryForObject(
"SELECT data FROM product WHERE cache_key = ?",
String.class, key
);
}
}4.3 大 Key 问题
什么是大 Key?
-
String 类型 value > 10KB
-
Hash/List/Set/ZSet 元素数量 > 5000
大 Key 的危害:
1). 网络传输慢,阻塞其他请求
2). 删除大 Key 会导致 Redis 主线程阻塞(DEL 一个几百 MB 的 key 可能卡几秒)
3). 迁移和持久化变慢
解决方案:
java
// 拆分大 Key:将一个大 Hash 按维度拆成多个小 Hash
// 之前:user:1001 → {name, age, address, orders, cart, history, ...}
// 之后:
// user:1001:basic → {name, age, address}
// user:1001:orders → {order1, order2, ...}
// user:1001:cart → {item1, item2, ...}
// 删除大 Key:用 UNLINK 代替 DEL(异步删除,不阻塞主线程)
redis.unlink("big_key"); // Redis 4.0+五、第三级:CDN 缓存
5.1 CDN 能缓存什么?
不只是静态资源。动态接口也可以用 CDN 缓存:
缓存类型与应用场景对比表
| 缓存类型 | 示例 | 缓存时间 | 适用场景 |
|---|---|---|---|
| 静态资源 | JS/CSS/图片/字体 | 长期(配合文件指纹) | 所有前端项目 |
| 页面 HTML | 首页、活动页 | 分钟级 | 内容更新不频繁的页面 |
| API 响应 | 商品列表、热搜榜 | 秒级~分钟级 | 高 QPS + 容忍短暂延迟的接口 |
说明
- 静态资源 :通常采用文件哈希(如
main.a1b2c3.js)确保内容变更后缓存失效,适合长期缓存以提升加载性能。 - 页面 HTML:适用于内容更新频率较低的页面,短时间缓存可降低服务器负载。
- API 响应:针对高并发但允许短暂数据延迟的场景,如榜单类数据,缓存时间较短以保证数据时效性。
5.2 CDN 缓存控制
通过 HTTP 响应头控制 CDN 和浏览器的缓存行为:
(1)Cache-Control 常用指令
┌───────────────────────────────────────────────────────┐
│ public CDN 和浏览器都可以缓存 │
│ private 只有浏览器可以缓存,CDN 不缓存 │
│ max-age=300 缓存 300 秒 │
│ s-maxage=60 CDN 缓存 60 秒(覆盖 max-age) │
│ no-cache 每次都要回源验证(不是不缓存!) │
│ no-store 真正的不缓存 │
└───────────────────────────────────────────────────────┘(2)实际配置示例(Nginx)
静态资源:长缓存 + 文件指纹
nginx
location /assets/ {
add_header Cache-Control "public, max-age=31536000";
}API 接口:CDN 缓存 10 秒,浏览器不缓存
nginx
location /api/hot-list {
add_header Cache-Control "public, s-maxage=10, max-age=0";
}用户私有数据:不走 CDN
nginx
location /api/user/ {
add_header Cache-Control "private, no-store";
}六、缓存一致性:最难的部分
多级缓存最大的挑战不是性能,而是数据一致性。数据在数据库、Redis、本地缓存、CDN 四个地方都有副本,更新时怎么保持一致?
6.1 经典方案对比
| 方案 | 做法 | 一致性 | 性能 | 复杂度 |
|---|---|---|---|---|
| Cache Aside | 先更新 DB,再删缓存 | 最终一致 | 高 | 低(推荐) |
| Read/Write Through | 缓存层代理所有读写 | 强一致 | 中 | 中 |
| Write Behind | 只写缓存,异步刷 DB | 弱一致 | 最高 | 高 |
| 双写 | 先更新 DB,再更新缓存 | 问题多 | 中 | 中(不推荐) |
关键说明
-
Cache Aside 是业界最常用的模式,通过删除缓存而非更新缓存避免并发写导致的脏数据问题,适合大多数读多写少场景。
-
Read/Write Through 将缓存作为主要数据源,由缓存系统自行维护数据库同步,适合需要强一致性的业务场景,但会损失部分性能。
-
Write Behind 通过异步批量写入数据库获得最高吞吐量,但存在数据丢失风险,适合允许数据临时不一致的高吞吐场景(如点赞计数)。
-
双写模式因并发时易出现缓存与数据库不一致问题,通常不建议采用。
6.2 Cache Aside 详解(最常用)
读流程:
查缓存 → 命中返回 → 未命中查 DB → 回填缓存
写流程:
更新 DB → 删除缓存(不是更新缓存!)
(1)为什么是"删除"缓存而不是"更新"缓存?
因为"更新"在并发下有问题:
线程 A 更新 DB → price = 100
线程 B 更新 DB → price = 200
线程 B 更新缓存 → 缓存 = 200
线程 A 更新缓存 → 缓存 = 100 ← 脏数据!DB 是 200 但缓存是 100
删除缓存就没这个问题:不管谁先删,下次读取都会从 DB 重新加载最新数据。
(2)为什么是先更新 DB 再删缓存,而不是反过来?
如果先删缓存再更新 DB:
线程 A 删除缓存
线程 B 读缓存(未命中)→ 读 DB(旧值)→ 回填缓存(旧值)
线程 A 更新 DB(新值)
结果:DB 是新值,缓存是旧值 → 不一致
先更新 DB 再删缓存,这个问题出现的概率极低(需要"读请求在 DB 更新之前读到旧值,且在缓存删除之后才回填",条件非常苛刻)。
6.3 延迟双删
即使用了 Cache Aside,极端并发下仍有小概率不一致。延迟双删进一步降低风险:
java
public void updateProduct(Product product) {
// 第一次删除缓存
redis.delete("product:" + product.getId());
// 更新数据库
productMapper.updateById(product);
// 延迟第二次删除(等读请求的旧值回填完成后再删一次)
executor.schedule(() -> {
redis.delete("product:" + product.getId());
}, 500, TimeUnit.MILLISECONDS); // 延迟 500ms
}延迟时间怎么定?大于"一次读请求从 DB 加载并回填缓存"的时间即可,通常 200ms-1s。
6.4 多级缓存一致性方案
当有本地缓存时,问题更复杂:Redis 删了,但各个应用实例的本地缓存还是旧的。
方案:Redis Pub/Sub 广播失效通知
java
// ========= 缓存更新时发布通知 =========
public void updateProduct(Product product) {
productMapper.updateById(product);
redis.delete("product:" + product.getId());
// 广播通知所有实例清除本地缓存
redis.convertAndSend("cache:invalidate",
"product:" + product.getId());
}
// ========= 所有实例监听通知 =========
@Component
public class CacheInvalidateListener implements MessageListener {
@Autowired
private Cache<String, Object> localCache;
@Override
public void onMessage(Message message, byte[] pattern) {
String key = new String(message.getBody());
localCache.invalidate(key); // 清除本地缓存
log.info("本地缓存已清除: {}", key);
}
}
// ========= 配置 Redis 监听 =========
@Configuration
public class RedisListenerConfig {
@Bean
public RedisMessageListenerContainer container(
RedisConnectionFactory factory,
CacheInvalidateListener listener) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(factory);
container.addMessageListener(listener,
new ChannelTopic("cache:invalidate"));
return container;
}
}完整的多级缓存更新流程:
数据更新
│
├── 1. 更新数据库
├── 2. 删除 Redis 缓存
├── 3. 通过 Redis Pub/Sub 广播失效消息
├── 4. 各实例收到消息,清除本地缓存
└── 5.(可选)延迟再删一次 Redis
七、缓存预热与降级
7.1 缓存预热
应用启动时缓存是空的,如果流量一上来全部穿透到数据库,就是冷启动问题。
java
@Component
public class CacheWarmUp implements ApplicationRunner {
@Autowired
private StringRedisTemplate redis;
@Autowired
private ProductMapper productMapper;
@Autowired
private Cache<String, String> localCache;
@Override
public void run(ApplicationArguments args) {
log.info("开始缓存预热...");
// 预热热门商品 Top 1000
List<Product> hotProducts = productMapper.selectTopByViewCount(1000);
for (Product p : hotProducts) {
String key = "product:" + p.getId();
String value = JSON.toJSONString(p);
// 同时预热 Redis 和本地缓存
redis.opsForValue().set(key, value, Duration.ofHours(1));
localCache.put(key, value);
}
log.info("缓存预热完成,共预热 {} 条", hotProducts.size());
}
}7.2 缓存降级
当 Redis 不可用时,不能让服务直接挂掉:
java
public String getWithFallback(String key) {
// 第一级:本地缓存
String value = localCache.getIfPresent(key);
if (value != null) return value;
// 第二级:Redis(带降级)
try {
value = redis.opsForValue().get(key);
if (value != null) {
localCache.put(key, value);
return value;
}
} catch (Exception e) {
// Redis 不可用,降级:直查数据库,结果只放本地缓存
log.warn("Redis 不可用,降级到数据库直查: {}", e.getMessage());
}
// 第三级:数据库
value = loadFromDB(key);
if (value != null) {
localCache.put(key, value);
// Redis 可用时尝试回填
trySetRedis(key, value);
}
return value;
}八、生产环境参数配置参考
java
# ============ 本地缓存(Caffeine) ============
# 热点数据:容量小、过期快
caffeine.hot:
maximum-size: 5000
expire-after-write: 30s # 30 秒,容忍极短延迟
# 基础数据:容量大、过期慢
caffeine.base:
maximum-size: 50000
expire-after-write: 300s # 5 分钟
# ============ Redis ============
spring.data.redis:
cluster:
nodes: redis-1:6379,redis-2:6379,redis-3:6379
lettuce:
pool:
max-active: 50 # 最大连接数
max-idle: 20
min-idle: 5
max-wait: 2000ms # 获取连接最大等待
cluster:
refresh:
period: 30s # 集群拓扑刷新
adaptive: true
# Redis key 过期时间规范
# 热点数据:60-300s(+ 随机偏移)
# 普通数据:1800-3600s(+ 随机偏移)
# 基础配置:86400s(1天)九、面试高频问题
Q1:说说你们项目中的缓存架构?
> 我们用的是三级缓存架构。第一级是 Caffeine 本地缓存,存热点数据,过期时间 30 秒,命中后零网络开销。第二级是 Redis Cluster,做分布式缓存,过期时间几分钟到几小时。第三级是 CDN,缓存静态资源和部分接口响应。数据更新时采用 Cache Aside 模式,先更新数据库再删 Redis,同时通过 Redis Pub/Sub 广播失效消息清除各实例的本地缓存。
Q2:Cache Aside 为什么是先更新数据库再删缓存?
> 如果先删缓存再更新数据库,并发场景下读请求可能把旧值重新写回缓存,导致持续不一致。先更新数据库再删缓存虽然理论上也有不一致窗口,但需要的条件极其苛刻:读请求必须恰好在数据库更新之前读到旧值、且在缓存删除之后才完成回填。这个概率远低于前者。如果要进一步降低风险,可以加延迟双删。
Q3:本地缓存和 Redis 的数据不一致怎么办?
> 我们用 Redis Pub/Sub 做缓存失效广播。数据更新时,除了删 Redis 缓存,还会向一个固定 channel 发送失效消息,所有应用实例监听这个 channel,收到消息后清除对应的本地缓存。同时本地缓存的过期时间设得比较短(30 秒),即使广播丢失,最多 30 秒后也会自动过期重新加载。
Q4:热 Key 怎么处理?
> 首先通过客户端统计或 Redis monitor 采样发现热 Key。处理方案有三种:一是热 Key 自动提升到本地缓存,直接在进程内命中,不走网络;二是 Key 分散,把 `hot:1001` 拆成 `hot:1001:0` 到 `hot:1001:9`,读取时随机选一个,分散到不同 Redis 节点;三是读写分离,热 Key 走从节点读。我们一般优先用第一种,因为本地缓存 + Pub/Sub 失效通知的方案已经能覆盖大部分热 Key 场景。
Q5:缓存穿透、击穿、雪崩在多级缓存架构下怎么防?
> 多级缓存本身就大幅降低了这三个问题的风险。穿透方面,在 Redis 前加布隆过滤器,同时缓存空值。击穿方面,热 Key 已经在本地缓存了,即使 Redis 过期也有本地兜底。雪崩方面,过期时间加随机偏移防集中过期,本地缓存作为第二道防线,即使 Redis 全挂了本地缓存还能顶一阵。加上缓存降级逻辑,可以做到 Redis 故障对用户几乎无感知。
十、总结
多级缓存核心架构要点
(1)三级缓存体系架构
本地缓存(Caffeine) + Redis 分布式缓存 + CDN 边缘缓存构成三级防御体系,逐层拦截请求。
(2)缓存选型策略
本地缓存采用 Caffeine,基于 W-TinyLFU 淘汰算法,兼顾高频访问与空间利用率。Redis 作为分布式缓存层,支持高可用与数据持久化。
(3)数据一致性方案
Cache Aside 模式为主,结合延迟双删(写入后异步二次删除)确保最终一致性。通过 Redis Pub/Sub 实现节点间缓存失效广播。
(4)热 Key 处理机制
本地缓存主动加载热 Key 减轻 Redis 压力,采用 Key 哈希分散策略避免单点过热。动态识别热点数据并优先缓存。
(5)数据预热流程
系统启动时异步加载 Top N 高频访问数据至本地与 Redis 缓存,结合历史访问日志预测热点。
(6)降级容错设计
Redis 故障时自动降级至本地缓存与数据库查询,本地缓存设置短 TTL(如 30 秒)避免脏数据长期留存。
(7)过期时间优化
基础过期时间叠加随机偏移(如 ±10%)防止雪崩。本地缓存设为秒级(30s),Redis 设为分钟级(5-30min),形成阶梯过期。
缓存不是万能药,但在高性能架构中一定是第一个要考虑的手段。关键是分层设计、控制一致性、做好降级,让每一级缓存各司其职。
光看不练假把式。缓存架构、Redis 集群、一致性方案这些话题,面试官一定会追着问细节。推荐用 **面霸**(AI 模拟面试平台)实战模拟几轮,AI 面试官会根据你的回答深度追问"Cache Aside 并发下会不会不一致""热 Key 你们怎么发现的"这类问题,练到能自然表达出来才算真会。
体验地址:http://106.12.14.47:8090/
懒得注册?直接用测试账号体验:
手机号:`18088889999`
密码:`test123#$qaz`
*觉得有帮助的话,点赞收藏不迷路。有问题评论区见。*