你是不是经常听人聊AI时蹦出这些词:LLM、Token、Context、Prompt、Tool、MCP、Agent?听着好像都认识,但真要问"这到底是啥",又有点懵。今天把这些词一个个拆开揉碎,讲清楚它们到底是啥、有啥用、又是怎么串起来的。
LLM:(大模型)
LLM 概述
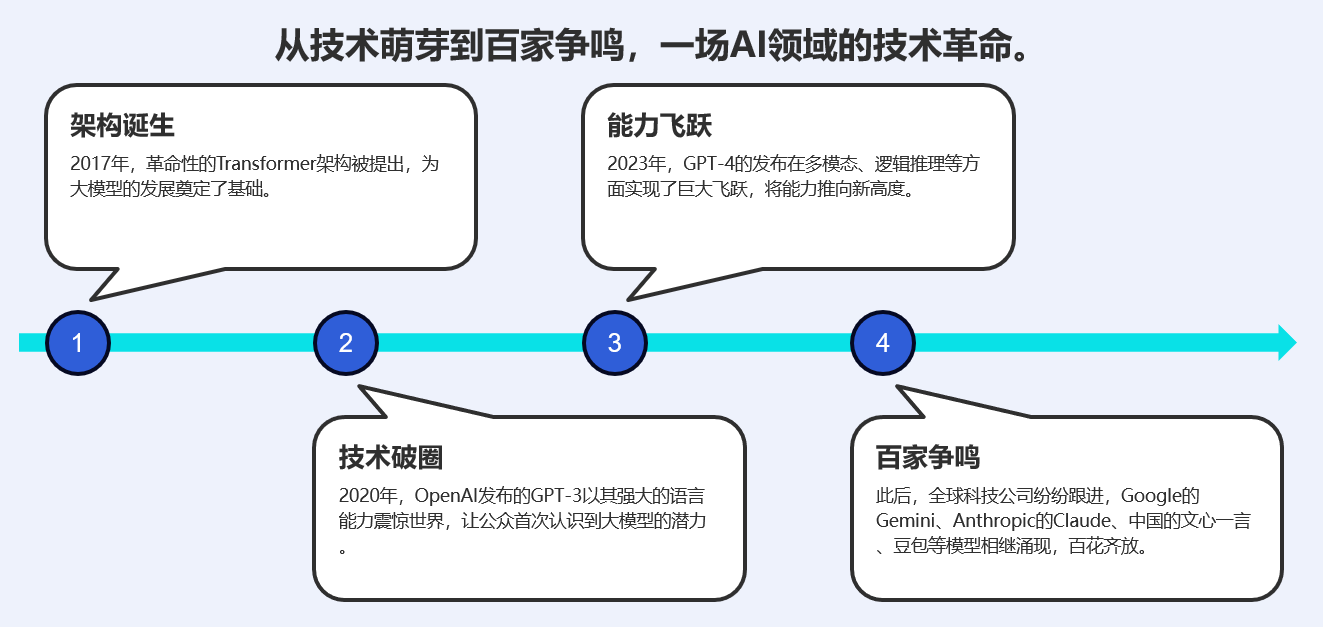
LLM的来历 :2017年Transformer架构诞生,OpenAI将其发扬光大;
历程 :从GPT-3.5破圈,到GPT-4飞跃,再到百家争鸣;
用途:从聊天起步,正在成为一切数字交互的"万能接口"。
LLM 是什么?
LLM(大语言模型)通俗来讲,就是一个极其擅长"文字接龙"的超级智能程序。
你可以把它想象成一个玩接龙游戏的高手:
- 它只做一件事:给你一句话,它根据这句话,猜出下一个最可能出现的字或词。
- 它一个字一个字地"吐"出来:它先猜第一个字,然后把这个字加回原来的句子里,再猜下一个字。就这样一个字一个字地往外蹦,直到它觉得一句话说完整了。
- 它不懂文字,只懂数字:在它内部,所有的文字都会被转换成它认识的数字(也就是"Token"),运算完再把数字变回文字告诉你。
举个例子 :
你问它"这篇文章怎么样?",它不会一次性想好"特别棒"三个字。它的内部流程是:
- 先猜出第一个字:"特"
- 然后把"特"加回问题,变成"这个视频怎么样特",再猜出:"别"
- 再把"别"加进去,变成"这个视频怎么样特别",再猜出:"棒"
- 最后发现话说完了,输出"特别棒"。
你平时用的像GPT、Claude、豆包、文心一言这些产品,底层都是这种"接龙"模型。它们之所以显得"聪明",是因为它们用海量的数据训练过,猜下一个字的"经验"极其丰富,所以接出来的话看起来像是有逻辑、有思考一样。
简单理解,就是大模型就像一个读过全世界所有书、但只会玩"文字接龙"的超级学霸------它每时每刻只关心"下一个字该接什么",但因为接了几万亿次,它的"语感"好到让人觉得它真的在思考,当我们给它装上"工具"和"长记忆"后,它就从只会玩接龙游戏的玩家变成了能帮忙干活、做决策的搭档。
Token:(大模型处理数据的最基本单元)
Token 通俗来讲,就是大模型"眼中的文字"------它是模型处理文本时最小的"积木块"。
它不是"字",也不是"词",而是"模型自己定义的积木"
我们看文字,是一个字一个字看的。
但大模型看文字,是先把一段话切成一小块一小块 ,每一块就叫一个 Token。
- 有时候一个 Token 就是一个汉字,比如"我""你""好"。
- 有时候一个 Token 是一个词,比如"苹果""电脑"。
- 但更多时候,一个词会被切成多个 Token。
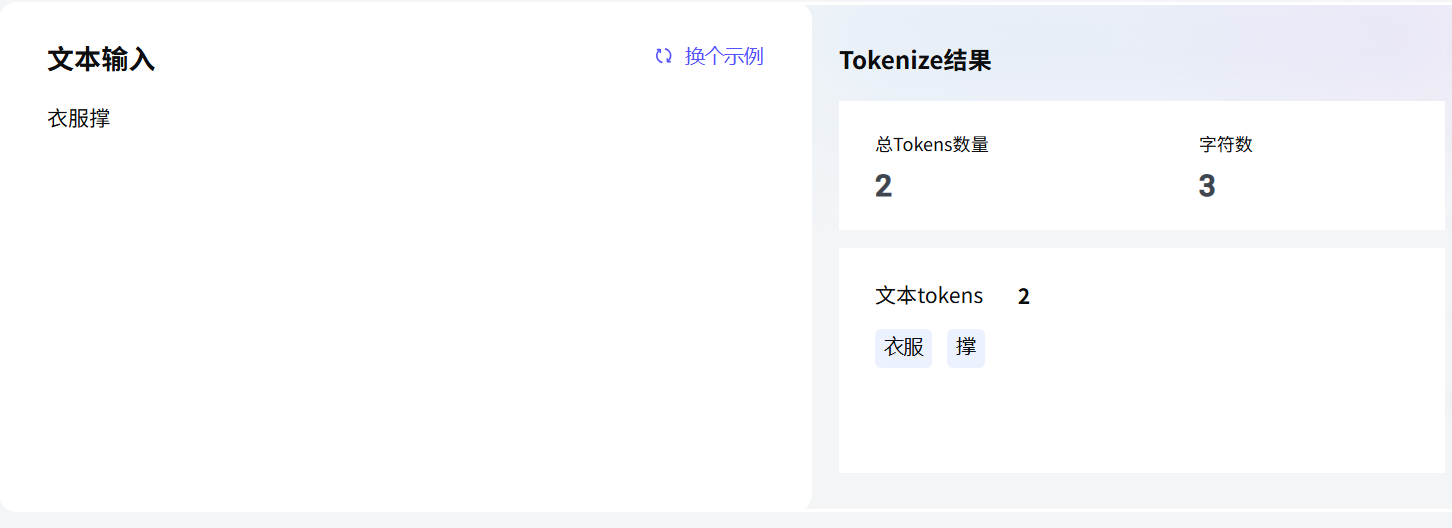
比如"衣服撑"这个词,在大模型眼里可能是两个 Token:"衣服"和"撑"。
再比如"Helpful"这个英文单词,可能会被切成"Help"和"ful"两个 Token。
一句话总结:Token 是模型自己学会的一套"切分规则",每个 Token 就是它一次能"看"或"吐"的最小单位。
国内可查 token 工具: https://console.volcengine.com/ark/region:ark+cn-beijing/tokenCalculator
OpenAI 分词器:platform.openai.com/tokenizer
为什么要有 Token?------因为模型只认数字
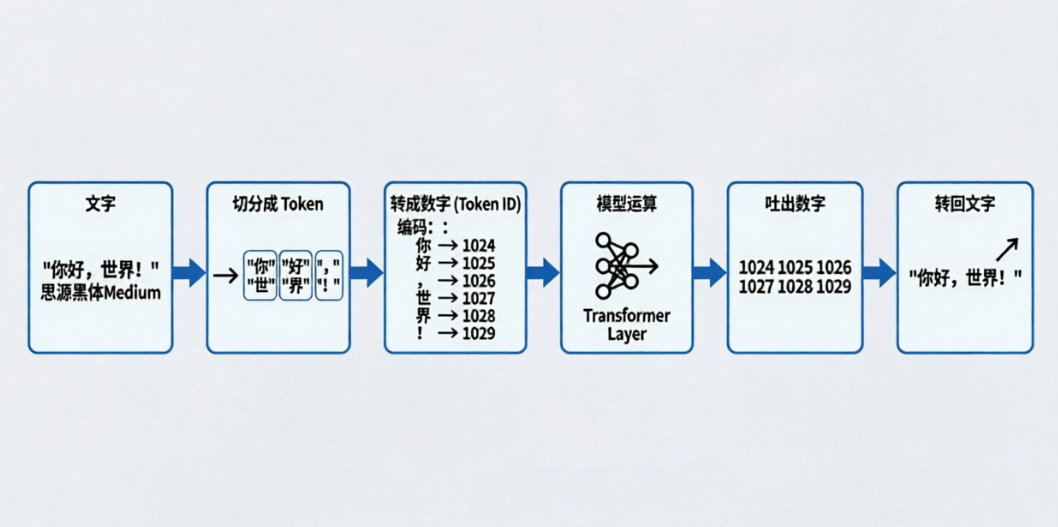
大模型内部全是数学运算,它不认识"你""我""他",只认识数字。
所以需要有一个"翻译官",把文字变成数字,这个数字就是 Token ID。
流程是这样的:
- 切分:把你说的话切成一个个 Token。
- 映射:每个 Token 对应一个唯一的编号(Token ID)。
- 运算:模型只处理这些数字。
- 还原:模型吐出一个数字(Token ID),再把它变回文字。
举个例子:
你问"这篇文章到底怎么样?"
它可能被切成 3 个 Token:"这篇文章" "到底" "怎么样"。
每个 Token 都有一个数字编号,模型看到的其实是 [1234, 5678, 9011,] 这样一串数字。
Token 和字数有什么关系?
这是一个很实用的知识点:
- 英文:平均 1 个 Token ≈ 0.75 个单词。比如"hello"是一个 Token,"helpful"是两个 Token。
- 中文:平均 1 个 Token ≈ 1.5 到 2 个汉字。一个常见汉字通常是一个 Token,但生僻字可能需要 2~3 个 Token。
为什么你要关心这个?
因为所有大模型产品都是按 Token 数量 计费的。
你提问时消耗 Token,模型回答时也消耗 Token。一段 1000 字的中文,大概会消耗 1500~2000 个 Token。
Token 决定了"它能记住多少"------上下文窗口
每个大模型都有一个"上下文窗口"(Context Window),它的大小就是用 Token 数量 衡量的。
- 比如一个模型说"上下文窗口是 100 万 Token",意思就是它一次最多能处理 100 万个 Token 的内容。
- 100 万 Token 大约相当于 150 万个汉字,或者《水浒传》整本那么多。
你每次和大模型聊天,它之所以能"记住"前面说的话,就是因为程序会把整个对话历史(用 Token 表示)一直塞给它。如果对话太长,超出了窗口,最早的对话就会被"挤出去",模型就"忘"了。
用一张图帮你记住 Token
中间那一步"转成数字"之后,模型处理的就不再是"文字",而是"数字积木"。它所有的"思考",其实都是在计算"下一个数字积木应该是什么"。
Token 就是大模型"看"和"写"文字时使用的最小积木块。它既不是字也不是词,而是模型自己学会的一种切分方式。你用大模型花的每一分钱、它能记住的每一句话,都是用 Token 来衡量的。
下次你再看到"这个模型有 100 万 Token 上下文",你就知道:它能一次吞下整本《水浒传》,然后跟你聊里面的任何细节。
Context: (大模型每次处理任务时接收到的信息总和)
Context 通俗来讲,就是大模型每次处理任务时能"看到"的所有信息的总和。
你可以把它想象成一个临时工作台:
- 你问模型一个问题,这个问题会放到工作台上。
- 你们之前的聊天记录,也会放到工作台上。
- 开发者在后台给它设定的"人设"和"规则"(System Prompt),也会摆在工作台上。
- 甚至模型自己刚才"吐"出来的每一个字,也会被立刻放回工作台上,供它预测下一个字时参考。
- 如果模型被允许调用工具(比如查天气、算数学),那么可用的工具列表也放在工作台上。
总之,模型每一次"思考"下一个字该接什么时,工作台上的所有内容就是它的 Context。
为什么要有 Context?
因为大模型本身没有记忆。它不是一个有意识的人,而是一个数学函数------你给它输入,它给你输出。
为了让模型"记住"你刚才说过的话,程序必须把对话历史也塞进当前的输入里 。
这个"被塞进来的对话历史",就是 Context 中最重要的部分之一。
举个例子:
你说"我叫小明",模型回答"你好小明"。
然后你问"我叫什么?"
如果没有 Context,模型只看到"我叫什么?"这五个字,它只能瞎猜。
但有了 Context,程序会把上一轮对话"我叫小明 / 你好小明"也加到输入里,模型看到的是完整的对话记录,所以它知道你叫小明。
Context 里具体有什么?
根据你提供的课程原文,Context 包含但不限于:
- 用户问题(User Prompt)------你当前输入的消息。
- 对话历史------之前你和模型的若干轮问答。
- 模型正在输出的每一个 token------每生成一个字,就追加到 Context 里,用于预测下一个字。
- System Prompt------开发者在后台设置的人设或规则(比如"你是一个耐心的数学老师")。
- 工具列表------模型可以调用的外部能力(天气 API、计算器等)。
所以 Context 是一个动态累积的信息集合,每次模型要输出一个新字时,它都会基于这个集合做计算。
Context Window:工作台的大小
Context 能放多少东西,是有限制的,这个限制就叫 Context Window (上下文窗口)。
它代表模型一次能处理的最大 Token 数量。
- 早期模型:Context Window 只有几千 Token,聊几句就"失忆"了(最早的对话被挤出去)。
- 现在主流模型:Context Window 可以达到 100 万 Token 甚至更多。
100 万 Token 大约相当于 150 万个汉字,能装下整本的《水浒传》。
注意 :Context Window 不是硬盘,而是"工作台内存"。如果对话太长超出窗口,模型就会忘记窗口之外的内容。
所以当你和模型聊了很久之后,它突然"不记得"开头说了什么,很可能就是因为 Context Window 满了,早期的对话被丢弃了。
Context window: (大模型的 Context 最多能够存储的 Token 量)
Context Window 通俗来讲,就是大模型的 Context(上下文)最多能装下多少 Token。
你可以把它理解为一块工作台的大小------工作台上能同时摆放多少"信息积木"(Token)。
为什么要有 Context Window?
因为大模型在处理任务时,需要把所有的相关信息(对话历史、用户问题、系统指令、工具列表等)一次性放进 Context 里,然后才能开始做"文字接龙"。
但模型的计算能力是有限的,它不能无限地往 Context 里塞东西。Context Window 就是这个"能塞多少"的上限,单位是 Token。
具体数值意味着什么?
-
早期的大模型(如 GPT-3 初代):Context Window 只有 2048 个 Token 左右。
大约相当于 3000 个汉字。聊几句就满了,最早的对话会被"挤出去",模型就会失忆。
-
现在的主流模型:Context Window 已经非常大。
- GPT-4(部分版本):128K Token(约 20 万汉字)
- GPT-4o:128K 或更高
- Claude 3.5 Sonnet:200K Token(约 30 万汉字)
- Gemini 1.5 Pro:200 万 Token(惊人!约 300 万汉字,能一次装下《三体》三部曲)
- 国产模型如 DeepSeek-V3:128K Token 或更高
举个例子 :
100 万 Token 大约相当于 150 万个汉字,相当于整本《鹿鼎记》。
这意味着你可以把一整本小说丢给模型,让它基于全书内容回答你的问题,而不会"忘记"开头。
Context Window 不是越大越好吗?
越大越好,但有两个代价:
- 计算成本:Context Window 越大,模型处理一次请求需要做的计算量就越大(大致是平方级增长)。所以超大窗口的模型通常更贵、更慢。
- 注意力稀释:当 Context 里有 100 万 Token 时,模型要从中找出最相关的信息来预测下一个字,就像在图书馆里找一句话------它可能会"走神",忽略掉真正重要的细节。不过现在的模型架构(如注意力机制改进)正在缓解这个问题。
一个形象的类比
想象你有一个白板 ,每次和模型对话,你都会把对话历史、问题、系统提示都写在白板上。
Context Window 就是这块白板的面积。
- 面积小(比如几千 Token):写几个句子就满了,最早的句子只能擦掉。
- 面积大(比如 100 万 Token):白板有一面墙那么大,你可以写上整本百科全书,模型每次都能看到全部内容。
对你的实际影响
- 长文档处理:如果你需要让模型分析一本几百页的书,就要确保模型的 Context Window 能装下整本书(或者用 RAG 技术分段处理)。
- 多轮对话:Context Window 决定了你能和模型聊多久而不让它"忘记"开头。窗口越大,对话可以越长。
- 费用:按 Token 计费的模型,虽然 Context Window 大,但如果你每次真的塞满 100 万 Token,那一次的请求费用会很高。
Context Window 就是大模型"工作台"的大小------它决定了模型一次最多能"看到"多少 Token 的信息。窗口越大,能记住的对话越多,能处理的文档越长,但计算成本和费用也会相应增加。
现在当你看到"支持 200K 上下文"时,你就知道:这块模型的白板,可以一次写下半本《三体》了。
Prompt: (用户或系统当前给大模型下达的具体指令或问题)
Prompt 通俗来讲,就是你(或系统)当前对大模型说的那一句话------它代表了一个具体的指令或问题。
想象你有一个能力超强但需要明确指令的助手。你开口说的第一句话,就是 Prompt。
比如:"今天天气怎么样?""帮我写一首关于秋天的诗。""把下面这段话翻译成英文。"
Prompt 的两种类型
根据来源和用途,Prompt 分为两种:
-
User Prompt(用户提示词)
- 由你------使用者------直接输入。
- 代表你当前的具体需求。
- 例如你在对话框里打的"3 + 5 等于几?"
-
System Prompt(系统提示词)
- 由开发者在后台预先设置,你作为用户看不到。
- 它定义了大模型的"人设"或"行为规则",会一直潜在地影响模型对 User Prompt 的回应。
- 例如:"你是一个耐心的数学老师,不要直接给答案,要引导学生思考。"
当模型收到一次请求时,它实际看到的是 System Prompt + User Prompt + 对话历史 等组合而成的 Context。但最核心、最直接的任务描述,就是 User Prompt。
Prompt 为什么重要?
因为大模型本质上是"文字接龙机器",它根据当前看到的全部文字来预测下一个字。
Prompt 就是给它定的"方向" 。
如果 Prompt 模糊不清,比如只说"帮我写点东西",模型可能写诗、写散文、写代码......你无法控制。
但如果 Prompt 清晰具体,比如"帮我写一封请假的邮件,主题是感冒,语气正式",模型就能给出你期望的结果。
所以有一门"学问"叫 Prompt Engineering(提示词工程) ------研究如何把话说清楚,让模型精准理解你的意图。
不过随着模型越来越聪明,现在对 Prompt 精细度的要求已经大大降低了。
一个直观的例子
-
没有 System Prompt,只有 User Prompt :
你问"3 + 5 等于几?" → 模型可能直接回答"8"。
-
加了 System Prompt (后台设置):"你是一个数学老师,要引导学生思考。"
你问同样的 User Prompt"3 + 5 等于几?" → 模型会回答:"我们可以这样想:你手里有 3 个苹果,又拿来 5 个,一共多少个呢?"
看到了吗?同一个 User Prompt,因为 System Prompt 不同,回答完全不同。
而 User Prompt 本身,就是你每次发起对话时那句最直接的指令。
- Prompt 就是大模型当前收到的具体任务或问题。
- User Prompt 是你给的,System Prompt 是开发者预设的规则
- 没有 Prompt,模型就不知道要做什么。
当你和 ChatGPT 说话时,你输入的那句话------就是 Prompt。
Tool: (大模型用来感知和影响外部环境的函数)
Tool 通俗来讲,就是大模型用来感知和影响外部世界的"函数"------它让只会做文字接龙的模型,能够真正动手做事。
为什么需要 Tool?
大模型有一个致命弱点:它无法感知外部环境 。
你问它"今天上海的天气怎么样?"它会老实回答:"抱歉,我无法获取实时天气信息。"
因为它的知识只来自训练时的数据,它不会真的去查天气预报网站,也不会帮你发邮件、订机票。
但如果我们给模型配上一套 Tool (工具),它就能突破这个限制。
Tool 本质上是一个函数 ------你给它输入,它执行操作,然后返回结果。
比如:
- 天气查询工具:输入城市和日期,输出天气信息。
- 计算器工具:输入数学表达式,输出计算结果。
- 发送邮件工具:输入收件人、主题、正文,执行发送并返回成功/失败。
有了这些工具,大模型就不再是一个"只会说话的鹦鹉",而是一个能动手干活的助手。
Tool 是如何工作的?
整个流程需要四个角色配合:用户、大模型、工具、平台(平台是一段负责传话的代码)。
- 用户提问:"上海今天天气怎么样?"
- 平台把问题和可用工具列表(比如"天气查询工具")一起发给大模型。
- 大模型"思考" :用户想知道天气,我没有实时数据,但有个天气工具可用。于是它输出一段指令(不是直接答案),比如:"调用天气工具,参数:城市=上海,日期=今天"。
- 平台拿到指令后,真的去执行:调用天气工具对应的函数,拿到结果,比如"晴天,15-25度"。
- 平台把结果返回给大模型。
- 大模型把结果整理成一句人话:"今天上海天气不错,晴天,温度15到25度。"然后输出给平台,平台再转给你。
关键点:
- 大模型只负责生成调用工具的指令(一段特殊格式的文本)。
- 真正去执行工具的,是平台(代码)。
- 大模型不能自己打开网页、调API,它只能"说"出自己想调哪个工具、传什么参数。
Tool 的典型例子
- 天气查询:输入城市 → 输出天气
- 计算器:输入"3.5 * 7.2" → 输出结果
- 搜索引擎:输入关键词 → 输出相关网页摘要
- 数据库查询:输入SQL → 输出查询结果
- 发送消息:输入接收者和内容 → 输出发送状态
- 控制智能家居:输入"关灯" → 输出执行结果
Tool 让大模型从"嘴炮"变成"实干家"
没有 Tool 的模型:只能聊天、写文章、编故事。
有 Tool 的模型:可以查天气、订票、发邮件、控制设备、分析数据......
Tool 的本质就是给大模型提供一套可以调用的外部能力,让它能够感知和影响外部环境。
而当多个 Tool 组合起来,配合模型自主规划调用顺序,就形成了 Agent(智能体)------能够自主完成复杂任务。
Tool 是大模型伸向外界的一只手------它是一个函数,模型通过"说出"调用指令,让平台去执行,从而获得实时信息或完成实际操作。没有 Tool,模型只能纸上谈兵;有了 Tool,模型就能改变世界。
现在你明白了:当你问 Siri"明天几点日出"时,背后就是大模型调用了天气/天文工具;当你让 ChatGPT 帮你算一道微积分,它可能调用了计算器工具。这就是 Tool 的魅力。
MCP: (统一了工具接入格式的标准协议)
MCP 的全称是 Model Context Protocol(模型上下文协议)。
通俗来讲,它就是一套统一的标准 ,规定了"工具应该长什么样、怎么被大模型调用"。只要一个工具按照 MCP 标准开发,它就能被所有支持 MCP 的大模型平台直接使用,一次开发,到处运行。
为什么需要 MCP?
回顾一下 Tool 的调用流程:大模型要使用一个工具(比如天气查询),平台需要知道这个工具叫什么、需要哪些参数、怎么去调用它。
但问题在于:每个大模型平台的接入规范都不一样。
- 你要让一个工具支持 ChatGPT,就得按照 OpenAI 的规范写一套接入代码。
- 要让同一个工具支持 Claude,又得按 Anthropic 的规范再写一套。
- 要让工具支持 Gemini,还得按 Google 的规范再写一套。
同一个工具,写三遍代码------这就是重复劳动,非常低效。
MCP 做了什么?
MCP 就像工具界的 Type-C 接口。
- 在 Type-C 普及之前,手机充电口五花八门(Micro-USB、Lightning、各种方形口),你换一部手机就得换一根线。
- Type-C 统一了标准:一根线能充所有手机。
MCP 做的也是同样的事:
它定义了一套统一的工具接入格式。
工具开发者只需要按照 MCP 规范开发一次,然后任何支持 MCP 的大模型平台(ChatGPT、Claude、Gemini......)都可以直接调用这个工具,无需为每个平台单独适配。
MCP 解决了什么问题?
- 对工具开发者:一次编码,全网通用。大大降低了重复开发成本。
- 对平台方:只要支持 MCP,就能立刻接入海量现成的工具,丰富自己的生态。
- 对用户:大模型能调用的工具会越来越多,体验越来越好。
例如:
| 场景 | 没有 MCP | 有 MCP |
|---|---|---|
| 充电线 | 每个品牌一种接口,换手机就得换线 | Type-C 统一接口,一根线充所有 |
| 工具接入 | 每个平台一套规范,工具要写多份代码 | 一套 MCP 规范,写一次到处用 |
MCP 是统一工具接入格式的标准协议。它让工具开发者只需写一次代码,就能被所有支持 MCP 的大模型平台使用,就像 Type-C 让一根充电线能充所有手机一样。
如果你想深入了解 MCP 的技术细节(比如协议的具体格式、消息类型、传输方式等),可以查阅官方文档。但作为概念理解,记住"Type-C 接口"这个比喻就够了。
MCP 官方文档:What is the Model Context Protocol (MCP)? - Model Context Protocol
Agent: (能自主规划和调用工具、直至解决用户问题的程序)
Agent 通俗来讲,就是一个能够自主规划步骤、反复调用工具,直到帮你把问题彻底解决的程序。
你可以把它想象成一个聪明的数字员工------你给它一个目标,它会自己思考怎么拆解任务、分几步完成、需要用到哪些工具,然后一步步去执行,最后给你结果。
Agent 和普通大模型有什么区别?
- 普通大模型:你问一句,它答一句。遇到需要查天气、算数学、发邮件的事,它只能说"我做不到"。即使给了它工具,也需要你在对话中手动引导它一步步做。
- Agent:你给一个复杂的目标(比如"帮我规划一次去北京的三天旅行"),它会自己把任务拆成"查机票、查酒店、查景点、算预算、排行程......"然后自动调用相应的工具,一步步完成所有子任务,最后给你一个完整的旅行方案。
一句话:大模型是"嘴",Agent 是"嘴 + 手 + 大脑"。
一个具体的例子
假设你有一个 Agent,它可用的工具有:天气查询工具、定位工具、店铺搜索工具。
你给它一个任务:"今天上海天气怎么样?如果下雨,帮我找找附近卖雨伞的店。"
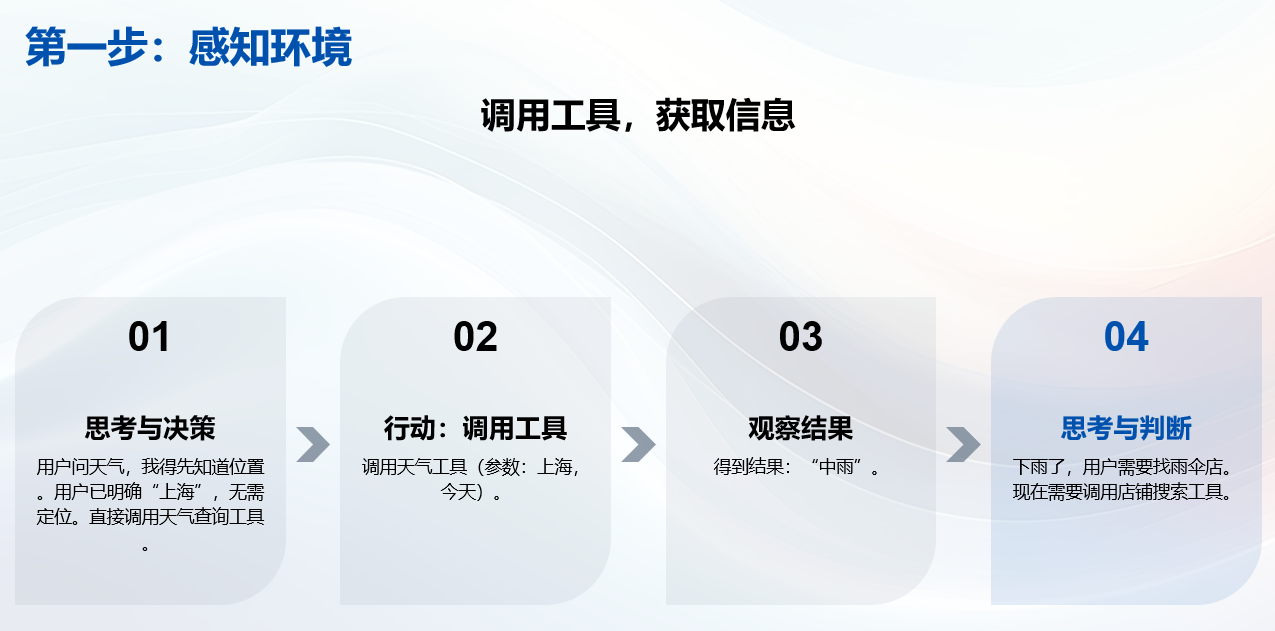
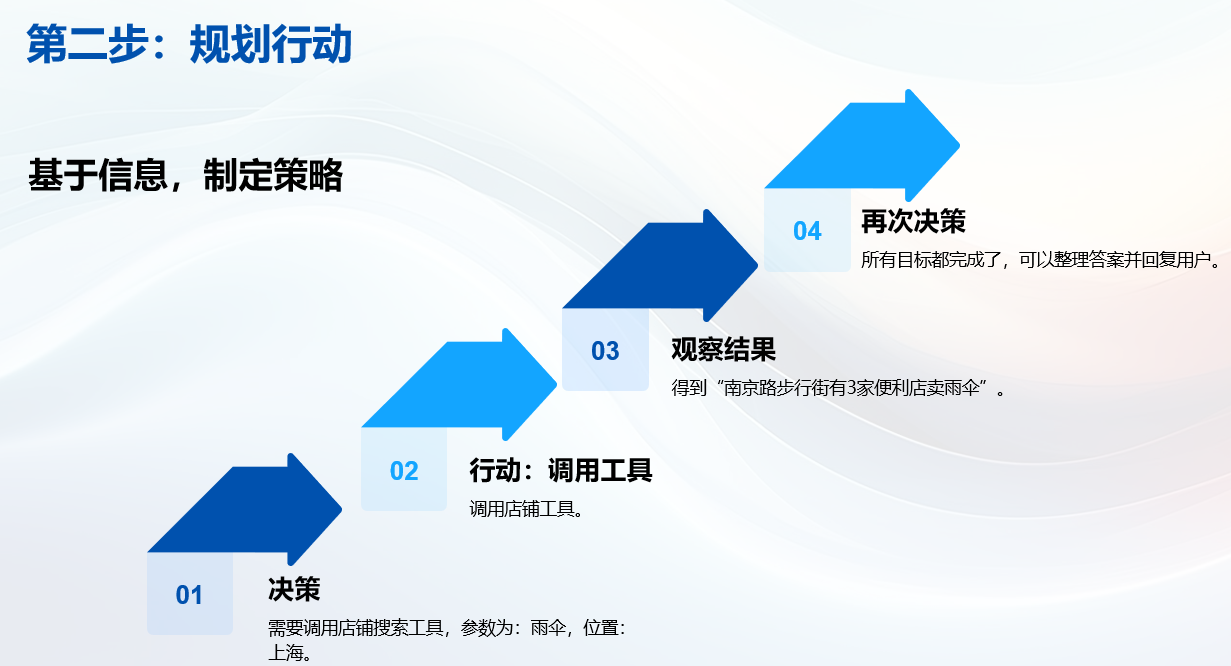
Agent 的"内心活动"如下:
- 思考:用户问天气,我得先知道位置?用户已经说了"上海",不需要定位。直接调天气工具。
- 行动:调用天气工具(参数:上海,今天) → 得到结果"中雨"。
- 观察:下雨了,用户还要找雨伞店。
- 思考:需要店铺搜索工具,参数:雨伞,位置:上海。
- 行动:调用店铺工具 → 得到"南京路步行街有3家便利店卖雨伞"。
- 思考:所有目标都完成了,可以整理答案了。
- 回答:"今天上海中雨,建议带伞。附近南京路步行街有便利店可以买到雨伞。"
整个过程,Agent 不需要你一步步指挥它"先查天气......再查店铺......"。它自己会规划、会判断、会决定下一步做什么,直到任务完成。


Agent 的核心能力
- 自主规划:把一个大目标拆成若干小步骤,决定先做什么、后做什么。
- 工具调用:在需要的时候,自动选择合适的工具并传入正确的参数。
- 循环执行:调用工具 → 获取结果 → 分析结果 → 决定下一步 → 再调用工具......直到任务完成。
- 容错与调整:如果某一步失败(比如天气工具无响应),Agent 可以换一种方式或告诉用户问题出在哪里。
常见的 Agent 例子
- 编程助手(如 Cursor、Claude Code):你说"帮我写一个登录页面",它会自己创建文件、写代码、运行测试、修复 bug。
- 自动化办公:你说"把这封邮件的附件整理成表格",它会下载附件、解析内容、生成 Excel、回复邮件。
- 智能家居管家:你说"我睡觉了",它会关灯、锁门、调空调、设闹钟。
- 旅行规划:你说"下周去杭州玩两天",它会查高铁票、订酒店、推荐景点、排行程、算总预算。
Agent 和普通大模型 + 工具的区别
- 普通大模型 + 工具:你问"今天天气怎么样?"它可能直接调工具给你结果。但如果你问一个多步任务,它只会回答"我需要先查天气,再查店铺,你要我一步步做吗?"------它不会自己循环。
- Agent:内置了循环机制 和规划能力。它会在内部不断重复"思考→行动→观察"这个循环,直到用户的目标达成。
Agent 是一个会自己动脑子拆解任务、会自己动手调用工具、会一步步循环执行直到问题彻底解决的程序。它不像普通大模型那样需要你每一步都指挥,而是像一个真正的数字员工------你给目标,它给结果。
现在应该明白了:当你听说"AI Agent 是下一个风口",其实就是说,未来的 AI 不再只是聊天机器人,而是能独立完成工作的智能体。
Agent Skill: (给 Agent 看的说明文档)
Agent Skill 通俗来讲,就是一份提前写好的说明文档------专门给 Agent 看的,告诉它"遇到这类任务时,应该按什么规则、什么步骤去做"。
你可以把它想象成一份员工手册 或岗位操作指南 。
你不需要每次给 Agent 布置任务时都啰嗦一遍规则,只要把规则写进 Skill 里,Agent 就会自动遵守。
为什么需要 Agent Skill?
假设你想让 Agent 做你的"出门小助手":每次出门前提醒你带什么东西。
你的习惯很具体:下雨带伞、刮风戴帽子、雾霾戴口罩、风大穿防风外套,而且手机必带。
你还希望它回答时别啰嗦,按固定格式:先一句总结,再列一个清单。
如果没有 Agent Skill,你每次出门前都要输入一大段提示词:
"请帮我查天气,如果下雨就提醒带伞,刮风提醒戴帽子,雾霾提醒戴口罩,风大提醒穿防风外套,而且无论什么天气都要提醒带手机。回答格式:先总结天气,然后列出需要带的物品清单。"
太反人类了,有了 Agent Skill,你只需要把这些规则提前写成一份文档 ,告诉 Agent:"以后出门提醒就用这个 Skill。"
之后你只需要说"我要出门了",Agent 就会自动按规则执行。
Agent Skill 长什么样?
Agent Skill 本质上是一个 Markdown 文档,分为两层:
-
元数据层(文档的"身份证")
name:这个 Skill 的名字,比如"go_out_checklist"description:简短描述,说明这个 Skill 是做什么的
-
指令层(具体怎么做)
- 目标:要完成什么任务
- 执行步骤:先做什么、后做什么(比如先调天气工具,再根据天气判断物品)
- 判断规则:什么天气对应什么物品(下雨→伞,刮风→帽子......)
- 输出格式:必须按什么结构输出(总结 + 清单)
- 示例:给一个完整的例子,让 Agent 更明白
示例:Agent Skill 文件,出行必备清单助手
markdown
---
name: go_out_checklist
description: 根据用户目的地的天气情况,智能生成出行必备物品清单。
---
# 出行必备清单助手
## 目标
你的任务是查询用户指定目的地的天气情况,并根据天气状况,为用户提供一份精准的出行必备物品清单。
## 执行步骤
1. **获取天气信息**:首先,调用 `weather_query` 工具,查询用户指定地点的实时天气或预报。
2. **分析天气状况**:读取工具返回的结果,重点关注天气现象(如晴、雨、雪、大风)和温度。
3. **匹配物品规则**:根据"判断规则"部分,确定需要推荐的物品。
4. **生成最终回答**:按照"输出格式"的要求,整合天气信息和物品清单,输出最终结果。
## 判断规则
请严格根据以下天气现象匹配对应的物品:
- **下雨/阵雨/暴雨**:必须推荐 [雨伞/雨衣]。
- **大风/强风**:必须推荐 [防风外套/帽子]。
- **晴天/紫外线强**:必须推荐 [防晒霜/墨镜/遮阳帽]。
- **气温低于 10°C**:必须推荐 [厚外套/围巾]。
- **气温高于 30°C**:必须推荐 [小风扇/补水喷雾]。
- **其他情况**:推荐 [舒适的鞋子/充电宝]。
> 注意:如果同时满足多个条件(例如既下雨又低温),请合并推荐物品。
## 输出格式
请严格按照以下 Markdown 格式输出:
### 📍 [地点] 出行建议
**天气概况**:[天气状况],气温 [温度]
**🎒 必备清单**:
- [物品1]
- [物品2]
- [物品3]
## 示例
**用户输入**:
"我明天要去杭州出差,需要带什么?"
**工具调用**:
`weather_query(location="杭州")` -> 返回:{"weather": "小雨", "temp": "15°C"}
**最终回答**:
### 📍 杭州 出行建议
**天气概况**:小雨,气温 15°C
**🎒 必备清单**:
- 雨伞(因为下雨)
- 厚外套(因为气温较低)
- 舒适的鞋子Agent Skill 和 System Prompt 的区别?
- System Prompt:全局的、固定的人设或规则,比如"你是一个耐心的数学老师"。一般由开发者设置,所有对话都生效。
- Agent Skill :针对特定任务场景的详细操作手册,可以由用户或开发者编写,按需加载。一个 Agent 可以有多个 Skill,对应不同的能力(出门提醒、邮件写作、数据分析......)。
Agent Skill 就是给 Agent 看的"说明书"或"操作手册"------你提前把规则、步骤、格式都写清楚,Agent 遇到相关任务时就会自动照着做,省去你每次重复输入的麻烦。
现在你明白了:Agent 是"能干活的员工",Agent Skill 就是"教这个员工怎么干活的培训手册"。
总结
| 英文术语 | 中文名称 | 核心定义 |
|---|---|---|
| LLM | 大模型 | 大模型本身(Large Language Model) |
| Token | 词元/令牌 | 大模型处理数据的最基本单元 |
| Context | 上下文 | 大模型每次处理任务时接收到的信息总和 |
| Context Window | 上下文窗口 | 大模型的 Context 最多能够存储的 Token 量 |
| Prompt | 提示词 | 用户或系统当前给大模型下达的具体指令或问题 |
| Tool | 工具 | 大模型用来感知和影响外部环境的函数 |
| MCP | 模型上下文协议 | 统一了工具接入格式的标准协议 |
| Agent | 智能体 | 能自主规划和调用工具、直至解决用户问题的程序 |
| Agent Skill | 智能体技能 | 给 Agent 看的说明文档 |
简单说明:
- LLM (大模型) :那个超级聪明的"大脑"。
- Token:大脑认识的最小"积木块"(文字切分后的单位)。
- Context (上下文) :大脑此刻"脑子里装着的所有信息"(包括你的提问和之前的聊天记录)。
- Context Window (上下文窗口) :大脑的"短期记忆容量上限"(最多能装多少 Token)。
- Prompt (提示词) :你给大脑出的"题目"或"指令"。
- Tool (工具) :大脑的"手和眼"(比如联网搜索、计算器,帮它看世界和做事情)。
- MCP:工具的"通用插座标准"(让所有工具都能插在大脑上用)。
- Agent (智能体) :一个有"大脑"且有"手脚"的完整办事员(它不只聊天,还能帮你把事办成)。
- Agent Skill (技能) :办事员手里的"操作说明书"(告诉它怎么用工具)。