1. 介绍
在机器人、自动驾驶和三维建图等前沿领域,LiDAR点云已经成为感知环境的核心数据形式。随着激光雷达传感器以每秒数十帧的速度不断采集高精度三维点云,如何实时、高效地压缩这些海量数据,已成为支撑设备端存储、网络传输和协同决策的关键问题。
传统基于规则的LiDAR点云压缩方法,在压缩效率与处理延迟之间往往难以兼顾。以MPEG推出的G-PCC标准为例,它通过复杂的启发式规则实现了较高的压缩性能,但距离实时处理仍有较大差距。而Google开源的Draco虽然延迟较低,压缩速度较快,但率失真性能明显不足。另一类基于距离图像的方法,利用传感器物理特性将三维点云投影到二维平面,从而简化压缩流程,但这种投影过程会引入不可逆的失真,影响重建质量,并可能削弱下游任务(如目标检测)的表现。
近年来,基于学习的神经编解码器在点云压缩任务上展现出了出色的率失真性能。然而,这些神经模型通常伴随着高昂的计算复杂度和内存开销,难以满足实时应用的需求。例如,当前最先进的方法之一Unicorn,在RTX 3090 GPU上压缩一帧14比特精度的LiDAR点云仍然需要约2秒。这引出一个关键问题:为什么现有神经编解码器难以实现实时处理,我们又能如何突破这一瓶颈?
通过对现有方法的深入分析,我们发现主要瓶颈来自两个方面:一是许多方法依赖八叉树结构,为每一帧点云构建八叉树本身就是一个耗时的过程;二是多尺度稀疏张量表示中,为了利用跨尺度上下文,通常需要多阶段逐步推理子体素的占用状态,这种串行化的处理方式严重拖慢了运行速度。
针对上述问题,我们提出了RENO------首个面向三维LiDAR点云的实时神经编解码器。RENO的核心设计思想包括:
- 跳过八叉树构建:直接基于多尺度稀疏张量表示,避免了八叉树生成带来的复杂计算;
- 稀疏占用码与一次性推断:在每个尺度上,我们定义了稀疏占用码来显式描述体素的占用状态,并采用一次性方式完成推断,无需多阶段处理;
- 跨尺度上下文建模:通过低尺度的占用码和坐标信息,辅助当前尺度的占用码压缩,在保证实时性的同时提升压缩效率。
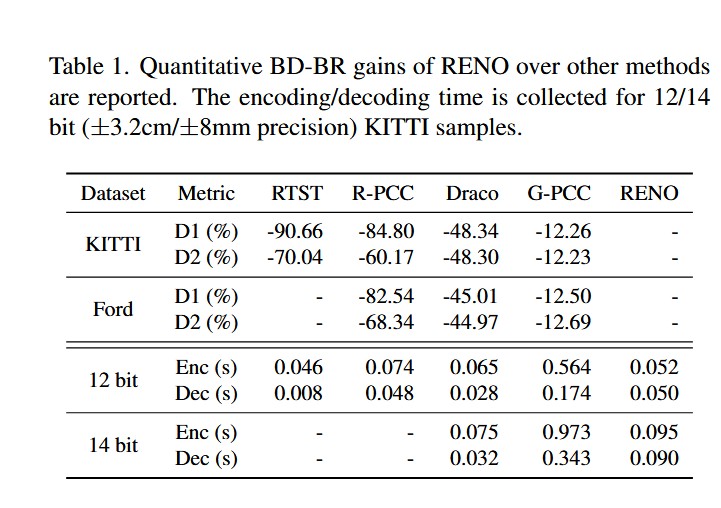
实验结果表明,RENO在桌面平台(单张RTX 3090 GPU)上,对14比特深度数据的编码和解码均可达到每秒10帧的实时速度。在同等重建质量下,相比G-PCC v23和Draco,分别节省了12.25%和48.34%的码率。更令人印象深刻的是,整个模型大小仅为1 MB,极具工业部署价值。源码已公开于:https://github.com/NJUVISION/RENO。
2. 相关工作
LiDAR点云压缩领域的研究主要围绕如何利用点云天然的稀疏性来组织数据,从而为后续的上下文建模和熵编码打下基础。现有方法大致可以归为三类:基于树结构的、基于多尺度稀疏张量的,以及基于距离图像的。
树结构方法
最简单的树结构是KD树,Google的Draco实时压缩器就采用了这种方式,获得了极低的延迟,但率失真效率有限。相比之下,八叉树因其对三维空间的规则划分而受到了更广泛的研究,并被MPEG采纳为G-PCC标准的基础。G-PCC利用手工设计的启发式规则挖掘邻域信息,构造熵编码所需的上下文,从而取得了比Draco好得多的压缩性能,但其参考软件实现尚未优化,远未达到实时处理的要求。
近年来,研究者尝试将深度学习引入八叉树上下文建模。OctSqueeze和OctAttention率先提出了可学习的上下文模型,后续的ECM-OPCC、EHEM等工作进一步提升了编码效率。然而,这些基于学习的八叉树方法仍然需要为每一帧输入点云构建完整的八叉树结构,这一过程本身就会带来显著的运行时开销,成为实时压缩的障碍。
多尺度稀疏张量方法
为了避开八叉树的构建代价,多尺度稀疏张量表示被提出。其核心思想是:通过对原始点云坐标进行固定的二倍下采样,逐层生成不同分辨率的稀疏张量,所有操作都在原生的笛卡尔空间中进行,无需额外的树结构。SparsePCGC及其后续版本(如SparsePCGCv2、Unicorn)在此基础上构建神经编解码器,取得了很好的压缩性能。
然而,这类方法在推断当前尺度的体素占用时,通常需要依赖低尺度信息进行多阶段处理。具体来说,为了判断上采样后哪些子体素被占用,往往需要分组、逐步计算,即使像Unicorn那样去除了自回归依赖,仍然难以实现实时处理。一些工作尝试将八叉树的占用码与稀疏张量表示相结合,期望提高计算效率,但本质上仍然受困于多阶段推理或八叉树预先生成的开销。
距离图像方法
另一条技术路线利用LiDAR传感器的物理扫描特性,将三维点云投影为二维距离图像(range image)。基于这种表示,许多压缩方法被提出,例如R-PCC和RTST。这类方法的最大优势在于压缩延迟极低,能够满足实时要求。然而,3D到2D的投影过程会引入明显的几何失真,导致重建点云的质量下降,并且这种损失会进一步影响到下游任务(如三维目标检测)的精度。因此,尽管距离图像方法速度快,但难以提供高保真的重建结果,在精度敏感的应用场景中受到较大限制。
综上所述,现有的LiDAR点云压缩方法要么在压缩效率和速度之间难以两全,要么牺牲重建精度换取实时性能。RENO的提出正是为了打破这一困境:它在多尺度稀疏张量表示的基础上,通过稀疏占用码和一次性推断,同时实现了实时速度和优异的率失真性能,且模型体积极小,有望真正落地到自动驾驶、机器人等时间敏感型应用中。
3. 方法
RENO 的设计目标是:在保持高压缩效率的同时,实现 LiDAR 点云几何信息的实时编码与解码。为此,我们选择多尺度稀疏张量表示作为基础,而不是传统的八叉树。下图(原文图3)展示了整体框架,下面我们逐步拆解其中的关键设计。
3.1 多尺度稀疏张量与稀疏占用码
给定一帧 LiDAR 点云,我们将其表示为最细尺度(最高分辨率)上的稀疏坐标张量 CDC^DCD,其中 DDD 是总尺度层数。通过反复执行二倍下采样 ,我们可以逐层得到更粗糙的稀疏张量 CD−1,CD−2,...,C0C^{D-1}, C^{D-2}, \dots, C^0CD−1,CD−2,...,C0。这种表示方式直接操作于笛卡尔空间,完全避开了八叉树的构建过程。
为了在不同尺度之间建立联系,我们定义了稀疏占用码 。想象一下:在八叉树中,一个父节点有 8 个子节点,每个子节点要么被占用(1)要么为空(0),父节点的占用符号就是一个 0~255 的整数。稀疏占用码扮演了完全类似的角色,但它不需要树结构------我们直接用固定权重的稀疏卷积,将 8 个相邻体素"压缩"成一个码值 o∈1,255o \in 1,255o∈1,255。
形式上,从尺度 ddd 到 d−1d-1d−1 的转换可以写作:
(Cd−1,Od−1)=FOG(Cd) (C^{d-1}, O^{d-1}) = \text{FOG}(C^d) (Cd−1,Od−1)=FOG(Cd)
其中 FOG(Fast Occupancy Generator)就是那个固定卷积。反过来,从粗糙尺度恢复到精细尺度:
Cd=FCG(Cd−1,Od−1) C^d = \text{FCG}(C^{d-1}, O^{d-1}) Cd=FCG(Cd−1,Od−1)
FCG(Fast Coordinate Generator)将每个码值展开为 8 个二进制位,再剪除空节点,即可得到精细坐标。
通过递归展开,原始点云可以无损表示为:
CD=(((((C0,O0),O1),O2),... ),OD−1) C^D = (((((C^0, O^0), O^1), O^2), \dots), O^{D-1}) CD=(((((C0,O0),O1),O2),...),OD−1)
这意味着:我们只需要压缩初始的 C0C^0C0 和所有稀疏占用码序列 O0,O1,...,OD−1O^0, O^1, \dots, O^{D-1}O0,O1,...,OD−1 即可。其中 C0C^0C0 非常稀疏(只有几个体素),压缩代价可忽略,所以核心任务就变成了压缩稀疏占用码序列。
3.2 快速占用转换器(FOG 与 FCG)
FOG:从精细坐标生成占用码
FOG 使用一个核大小为 2、步幅为 2 的稀疏卷积,卷积核权重被手工固定 为:
1,2,4,8,16,32,64,128\] \[1, 2, 4, 8, 16, 32, 64, 128\] \[1,2,4,8,16,32,64,128
操作过程非常简单:将精细尺度上的每个体素坐标赋值为"1",然后滑动这个卷积核。每 8 个相邻体素(一个 2×2×22\times2\times22×2×2 的块)会被加权求和,得到一个 1~255 的整数。这个整数正是这 8 个体素占用状态的唯一编码。由于权重是固定的且卷积是稀疏的,该过程可以高度并行化,计算负担极轻。
FCG:从占用码恢复精细坐标
FCG 分为两步:展开 与剪枝 。首先,将每个稀疏占用码 ooo 转换为 8 位二进制表示,每一位对应一个子体素的位置(例如 bit0 对应 (0,0,0),bit7 对应 (1,1,1))。然后,只保留二进制位为 1 的那些位置,得到精细尺度的坐标张量。这一步同样没有复杂的计算,只是简单的位运算和坐标生成。
通过 FOG 和 FCG,我们可以在不同尺度之间快速切换,既无需构建树结构,也无需任何神经网络推理------它们是完全确定的、轻量级的操作。
3.3 目标占用预测器(TOP)
虽然占用码本身可以通过上述转换器获得,但为了高效压缩,我们需要估计每个占用码的概率分布,然后交给算术编码器。这就是 TOP 的职责。
TOP 的核心思想是利用跨尺度相关性 :当前尺度的占用码 OdO^dOd 与低尺度的坐标 Cd−1C^{d-1}Cd−1 和占用码 Od−1O^{d-1}Od−1 存在强相关性。因此,TOP 接收三个输入:Cd−1C^{d-1}Cd−1、Od−1O^{d-1}Od−1 和当前尺度目标坐标 CdC^dCd,输出 OdO^dOd 的概率分布。
TOP 的工作流程分为三步:
-
占用特征提取 :将离散的占用码 Od−1O^{d-1}Od−1 通过嵌入层转换为连续向量,再经过一个残差块(ResNet Block),得到聚合特征 Fd−1F^{d-1}Fd−1。
-
目标嵌入 :将低尺度特征传递到当前尺度的目标坐标上。首先,采用直接复制 :父体素的特征直接复制给它的 8 个子体素。然后,注入相对位置信息 :子体素相对于父体素的位置(八分体索引,0~7)也被嵌入并加到特征上。最后再经过一个残差块,得到当前尺度的特征 FdF^dFd。
-
概率预测 :利用 FdF^dFd,通过一个多层感知机(MLP)和 SoftMax 层,预测每个占用码的概率分布。
按位两阶段预测
直接预测 8 比特码(255 个类别)是可行的,但我们在实现中发现,按位两阶段策略更优:
- 将 8 比特占用码拆分为高 4 比特 S1dS_1^dS1d 和低 4 比特 S2dS_2^dS2d。
- 先预测 S1dS_1^dS1d 的概率分布,然后以 S1dS_1^dS1d 为条件预测 S2dS_2^dS2d。
- 最终概率为 P(Od)=P(S2d∣S1d)P(S1d)P(O^d) = P(S_2^d \mid S_1^d) P(S_1^d)P(Od)=P(S2d∣S1d)P(S1d)。
这样做有两个好处:第一,预测 4 比特(16 类)比预测 8 比特(255 类)更容易,模型精度更高;第二,在 CPU 上进行算术编码时,需要将概率张量从 GPU 传输到 CPU。两阶段方案下,传输的数据量从 N×255N \times 255N×255 降为 2×N×162 \times N \times 162×N×16,带宽需求降低约 8 倍,显著加速了熵编码过程。
3.4 损失函数
由于我们关注的是稀疏占用码的无损压缩 ,优化目标就是最小化预测分布与真实分布之间的交叉熵:
L=EO∼P(O)−logPθ(O)=∑d=1D−1EOd∼P(Od)−logPθ(Od) \mathcal{L} = \mathbb{E}{O \sim P(O)}-\\log P_\\theta(O) = \sum{d=1}^{D-1} \mathbb{E}_{O^d \sim P(O^d)}-\\log P_\\theta(O\^d) L=EO∼P(O)−logPθ(O)=d=1∑D−1EOd∼P(Od)−logPθ(Od)
在训练过程中,我们使用教师强制(teacher forcing),即用真实的占用码作为输入来预测概率,并计算交叉熵损失。推理时,则用算术编码器根据预测的概率分布对实际出现的占用码进行编码。
通过以上设计,RENO 实现了三个关键目标:
- 实时性:跳过八叉树构建,用固定卷积生成占用码,一次性推断概率。
- 高压缩效率:利用跨尺度上下文和按位两阶段预测,显著优于传统实时方法。
- 轻量级:整个模型仅 1 MB,易于部署。
4. 实验与讨论
4.1 实验设置
4.1.1 数据集
实验采用两个广泛认可的数据集:KITTI 12 和 Ford 28。
- KITTI:包含 14,999 帧由 Velodyne HDL-64E 扫描的 LiDAR 点云。官方划分:3,712 帧用于训练,3,769 帧用于验证,7,518 帧用于测试。
- Ford:由 3 个序列组成,每个序列 1,500 帧,用于 MPEG 标准化测试。按常见测试条件,序列 01 用于训练,序列 02 和 03 用于评估。
4.1.2 实现细节
RENO 使用 Python 3.9 和 PyTorch 1.10 实现,并利用 TorchSparse++ 33 进行高效稀疏卷积。优化器采用 Adam 18,初始学习率为 5×10−45\times10^{-4}5×10−4,批大小为 1。模型训练 100,000 步,训练样本被量化到 16 比特精度。所有实验均在 Intel Xeon Silver 4314 CPU 和一块 NVIDIA GeForce RTX 3090 GPU 上进行。由于不同方法的实现细节存在差异(如 CPU/GPU 使用方式不同),文中的运行时间对比旨在提供计算复杂度的直观参考。
4.1.3 对比基线
本文对比了以下方法:
- 实时压缩器:Draco 13、R-PCC 39、RTST 10。
- 非实时但高性能标准:G-PCC v23 41。
- 与更多学习型方法(Unicorn 37、EHEM 31 等)的比较见补充材料。
4.2 对比实验
4.2.1 率失真性能
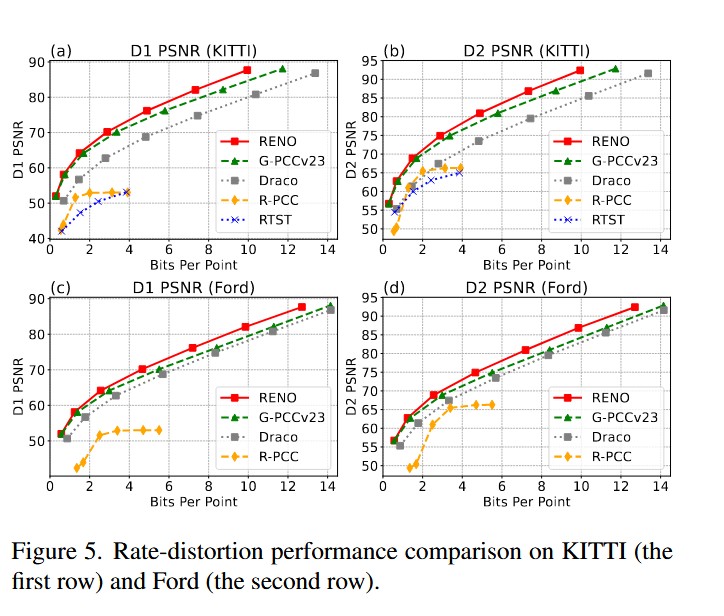
如表 1 和图 5 所示,RENO 在点到点(D1)与点到平面(D2)两种指标下,在整个码率范围内均一致地优于所有对比方法。G-PCC v23 虽然率失真性能令人信服,但由于其熵编码采用复杂规则且参考软件未优化,不具备实时能力 41。而实时方法(Draco、R-PCC、RTST)的性能明显较弱。R-PCC 和 RTST 依赖距离图像表示,仅支持较窄的码率范围且重建保真度较差,根本原因在于 3D 到 2D 投影引入了显著失真 42。
4.2.2 计算复杂度
表 1 中的编码/解码时间证明了 RENO 的实时能力。对于 12 比特 LiDAR 点云,RENO 编码 0.052 秒,解码 0.050 秒,与基于规则的实时方法相当甚至更优。对于 14 比特样本,RENO 仍能达到平均实时延迟(例如 10 帧/秒),匹配主流 LiDAR 传感器的采集频率。
4.2.3 定性可视化
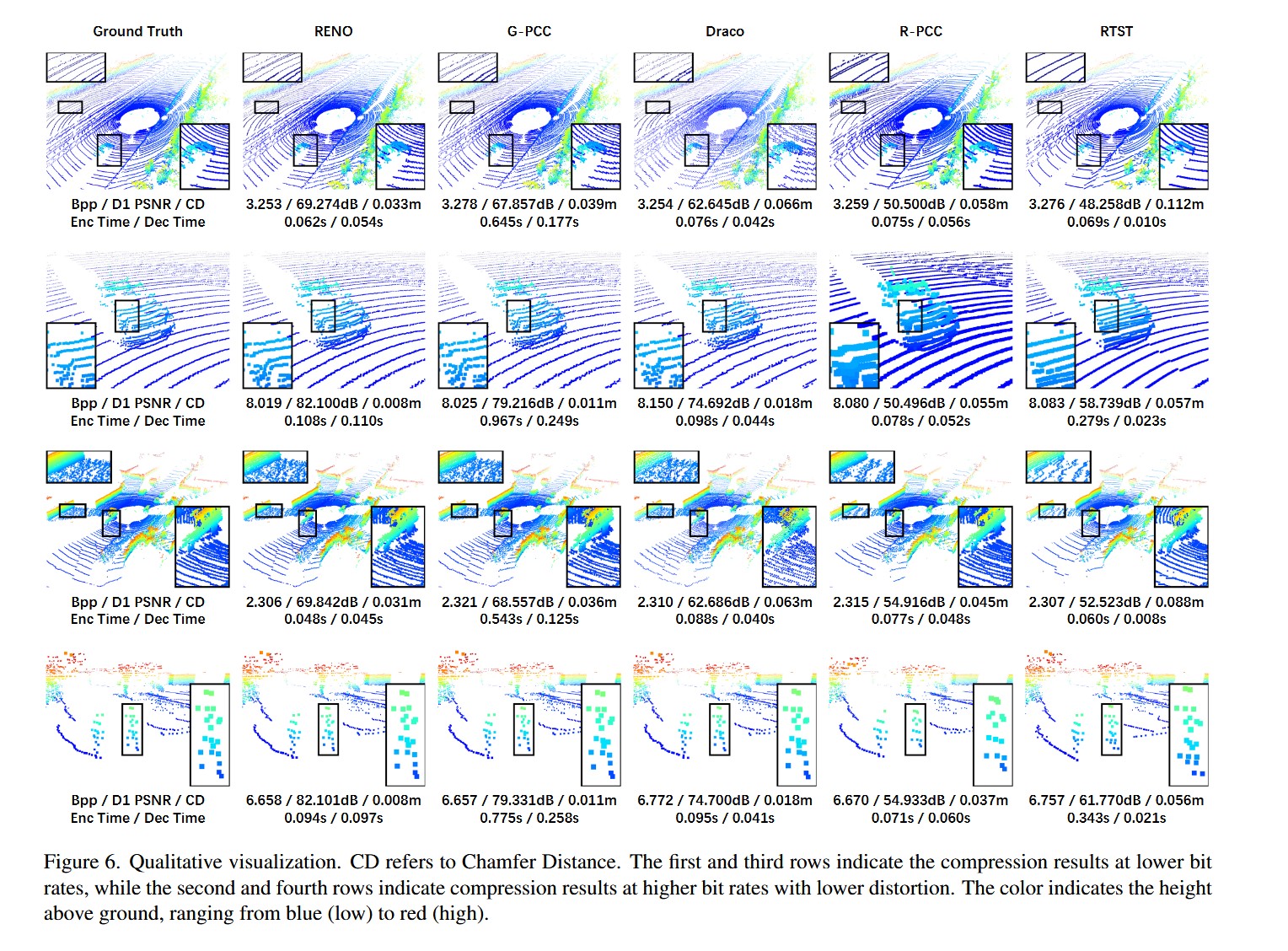
图 6 展示了低码率与高精度场景下的重建样本(来自两个 KITTI 点云)。RENO 显著优于其他实时方法:
- 低码率下,RENO 能有效重建扫描条纹和车辆轮廓;Draco 结果模糊,RTST 和 R-PCC 均表现出扫描完整性缺失。
- 高码率下,RENO 实现更精确的点重建,Chamfer Distance 仅为 8 mm,不到 Draco 的一半。基于距离图像的方法即使在高码率下仍难以准确重建,印证了 2D 投影引入的显著失真。
5. 结论
本文提出了 RENO------一种建立在多尺度稀疏表示之上的 LiDAR 编码器。在每一个尺度上,它通过压缩稀疏占用码,以一次性推断的方式确定体素的占用状态;其中,稀疏占用码的生成利用了固定权重的稀疏卷积,无需诉诸复杂的八叉树构建过程,而这些占用码的压缩则通过条件编码来利用跨尺度相关性。RENO 在实现实时压缩速度的同时,仍提供了优异的性能,因此对诸如自主机械等应用具有吸引力,可用于即时保存和交换刚采集到的LiDAR 数据,以支持更优的决策。