为什么改了配置,Pod 却没重启?Kubernetes 真相来了
很多人平时会说"Pod 重启了",但在 Kubernetes 里,这个说法其实并不严谨。
因为大家口中的"Pod 重启",往往混淆了两件完全不同的事:一种是 同一个 Pod 内的容器重启了 ,另一种是 旧 Pod 被删除后,又创建了一个新的 Pod。
本文想讲清楚的,正是 Kubernetes 在不同场景下,到底会触发哪一种行为。本文是基于 Kubernetes 1.35 GA 验证过的生产环境内部机制指南。
配套仓库:github.com/opscart/k8s-pod-restart-mechanics
术语问题
工程师们经常说"Pod 重启了",但这个说法其实并不严谨。在 Kubernetes 里,大家口中的"Pod 重启",通常混淆了几种完全不同的情况。
| 现象 | Pod UID 变化? | Pod IP 变化? | Restart Count 变化? | 更准确的说法 |
|---|---|---|---|---|
| 同一个 Pod 内部的容器进程被重新拉起 | 否 | 否 | +1 | 容器重启 |
| 旧 Pod 被删除,控制器重新创建一个新 Pod | 是 | 通常会变 | 新 Pod 从 0 开始 | Pod 重建 / Pod 被替换 |
| Pod 原地调整 CPU | 否 | 否 | 0 | 原地 resize |
Pod 原地调整内存,且策略为 RestartContainer |
否 | 否 | +1 | 同 Pod 内容器重启 |
一个最实用的判断方法是:先看 Pod UID 有没有变,再看 restartCount 有没有增加。
- UID 变了 :说明旧 Pod 已被替换,这是 Pod 重建
- UID 没变,但 restartCount 增加了 :说明这是 同一个 Pod 内的容器重启
- UID 和 restartCount 都没变:那很可能 Pod 根本没动,只是配置、路由或权限等外围机制发生了变化
核心洞察:kubelet 实际上在看什么
kubelet 观察的是 Pod Spec ,而不是 ConfigMap、Secret,或者 Istio 的 CRD。 如果 Pod Spec 没有变化,kubelet 就不会触发任何动作。
这个事实能解释生产环境里大多数"为什么我的配置没有更新"的排障问题。
需要注意的是:
- Mutating Admission Webhook 可以在 创建时 修改 Pod Spec
- 但在 admission 之后,它不能再修改 Pod Spec
- 因此它也不能在 Pod 创建后触发容器重启
决策矩阵
| 变更项 | 同 Pod 内容器会重启? | 会触发 Pod 重建 / 替换? | 是否自动发生? |
|---|---|---|---|
| 容器镜像 | 不会 | 会 | 会 ------ 由 Deployment / StatefulSet 等控制器触发 |
| 环境变量(Pod Spec 中定义) | 不会自动发生 | 通常需要 | 否 ------ 需要手动 rollout |
| ConfigMap(volume 挂载) | 不会 | 不会 | 部分自动 ------ 文件会更新,但是否生效取决于应用是否热加载 |
ConfigMap(envFrom / valueFrom) |
不会自动发生 | 通常需要 | 否 ------ 需要手动 rollout 或借助 Reloader |
| Secret(volume 挂载) | 不会 | 不会 | 部分自动 ------ 文件会更新,但是否生效取决于应用是否热加载 |
Secret(envFrom / valueFrom) |
不会自动发生 | 通常需要 | 否 ------ 需要手动 rollout 或借助 Reloader |
| Projected ServiceAccount Token | 不会 | 不会 | 会 ------ kubelet 自动轮转 |
| CPU resize(K8s 1.35+) | 不会 | 不会 | 否 ------ 手动 patch |
| Memory resize(K8s 1.35+) | 取决于 resizePolicy |
不会 | 否 ------ 手动 patch |
| Istio VirtualService / DestinationRule | 不会 | 不会 | 会 ------ xDS push |
| NetworkPolicy | 不会 | 不会 | 会 ------ CNI Agent |
| Service ports | 不会 | 不会 | 会 ------ kube-proxy |
| RBAC | 不会 | 不会 | 会 ------ API Server |
| 节点 drain / eviction | 不会在原 Pod 内重启 | 会 | 会 ------ Pod 被驱逐后由控制器补出新 Pod |
下面这张流程图把同一个矩阵转成了更适合线上排障时使用的决策路径。
图1:完整的决策流程图------此更改是否需要重启 pod?
场景 1:ConfigMap ------ 为什么同样的变更会有两种行为
图 2:ConfigMap 环境变量与卷挂载------环境变量 pod 冻结,卷 pod 通过 kubelet 符号链接交换自动同步
1)环境变量模式(envFrom / valueFrom)
内核会在 execve() 时把环境变量复制进 /proc/<pid>/environ。这段内存归进程自己所有,外部系统无法再修改它。你更新 ConfigMap 后,kubelet 看不到 Pod Spec 变化,于是什么都不会做。进程会无限期保留旧值。
2)卷挂载模式
在卷挂载模式下,kubelet 同步配置的方式不是"改文件内容",而是通过 原子性的符号链接切换(symlink swap):
text
/etc/config/
├── ..2025_12_19_11_30_00/ ← 新数据目录(由 kubelet 创建)
│ └── APP_COLOR ← "red"
├── ..data ─────────────────▶ ..2025_12_19_11_30_00/ ← 原子切换 symlink
└── APP_COLOR ──────────────▶ ..data/APP_COLOR这个符号链接切换会在 ..data 上产生 IN_CREATE,而不是在文件本身上产生 IN_MODIFY。如果应用是在一个已经打开的文件描述符上监听 IN_MODIFY,它会完全错过这次变化。这就是为什么 nginx 在没有显式 inotify 处理时,不会因为 ConfigMap 变化而自动 reload。
实验结果(配套仓库 01-configmap/)
ini
ConfigMap 更新:APP_COLOR blue → red
Pod A(环境变量): APP_COLOR=blue ← 值被冻结,restart count: 0
Pod B(volume 挂载): APP_COLOR=red ← 自动同步,restart count: 0正确的 inotify 模式:监听目录,而不是文件
scss
watcher.Add(filepath.Dir(configPath)) // 监听 /etc/config/,能捕获 IN_CREATE
// watcher.Add(configPath) // 会完全错过 symlink 切换
for event := range watcher.Events {
if event.Op&fsnotify.Create == fsnotify.Create {
reloadConfig()
}
}场景 2:镜像更新 ------ 重建、容器重启和 CrashLoop 的区别
这三种现象看起来很像,但本质完全不同。
成功的镜像更新:Pod 被重建
yaml
BEFORE: Pod UID aaa-bbb, IP 10.244.1.5, nginx:1.25, restarts: 0
AFTER: Pod UID xxx-yyy, IP 10.244.1.6, nginx:1.27, restarts: 0
↑ UID 变了 ------ 这是重建,不是容器重启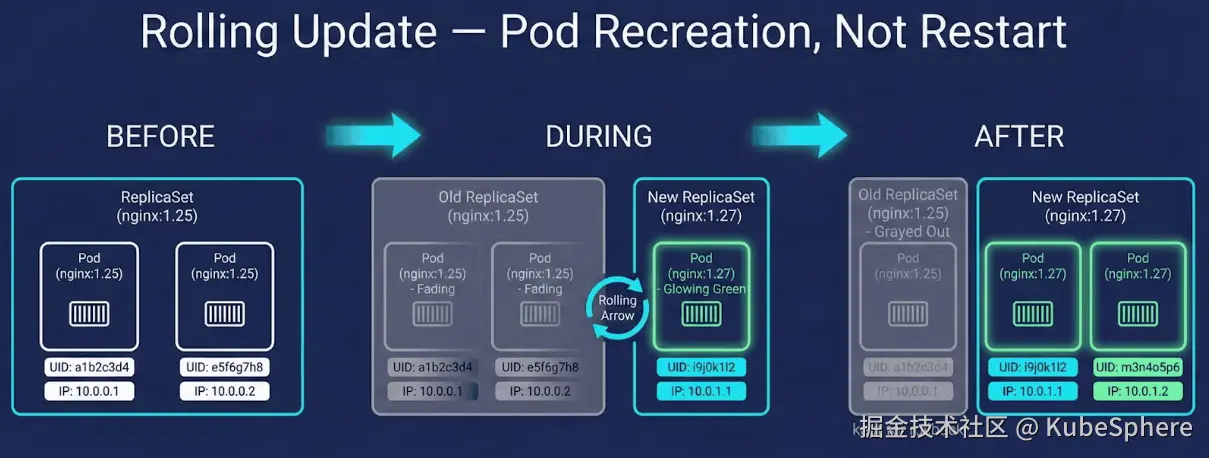 图 3:滚动更新流程,显示新的 ReplicaSet 的创建、pod 的重建以及保留旧的 RS 以进行回滚。
图 3:滚动更新流程,显示新的 ReplicaSet 的创建、pod 的重建以及保留旧的 RS 以进行回滚。
ImagePullBackOff:旧 Pod 会被保留
sql
Old pod: Running ← Kubernetes 会让它继续存活
New pod: ImagePullBackOff ← 新 Pod 拉镜像失败卡住,旧 Pod 不会被删掉CrashLoopBackOff:还是同一个 Pod,重启次数持续增加
yaml
Pod UID: aaa-bbb ← 没变
Restart count: 0 → 1 → 2 → 3 ← 同一个 Pod 对象内,容器不断崩溃诊断规则
Restart Count 持续上升,UID 不变:这是 CrashLoop。
Restart Count 为 0,但 UID 变了:这是 滚动更新 / Pod 重建。
StatefulSet 说明
StatefulSet 说明:StatefulSet 的 Pod 在镜像变化时同样会被重建,但序号身份(pod-0、pod-1)和 PVC 绑定会被保留。容器重启语义与 Deployment 完全一致------身份持久化并不意味着容器是原地重启。
场景 3:原地资源调整(K8s 1.35 GA)
Kubernetes 1.35 让 Pod 原地 resize 进入 GA。CPU 和内存都可以在不重建 Pod 的情况下调整,因此:原地 resize 是否可用,取决于 CRI 和节点 OS 支持;文中是在 containerd 1.7+ 配合 Linux cgroups v2 上完成验证的。容器会发生什么,取决于你显式定义的 resizePolicy:
yaml
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired # 只更新 cgroup quota,不碰进程
- resourceName: memory
restartPolicy: RestartContainer # 在同一个 Pod 内重启容器实验结果(05-resource-resize/,要求 K8s 1.35+)
objectivec
CPU resize 200m → 500m (NotRequired):
UID: d7c99204 IP: 10.244.0.7 Restarts: 0 ← 全部不变
Memory resize 256Mi → 512Mi (RestartContainer):
UID: d7c99204 IP: 10.244.0.7 Restarts: 1
↑ 同一个 Pod ↑ 同一个 IP ↑ 这是我们的策略选择,不是 K8s 强制要求重要:memory 的默认 resizePolicy 是 NotRequired。如果你省略它,memory resize 会静默更新 cgroup,而不会重启容器------你的 JVM heap 仍然保持旧大小。对于 memory,请始终显式定义 resizePolicy。
如何执行 resize
css
kubectl patch pod my-pod -n my-namespace \
--subresource resize \
-p '{"spec":{"containers":[{"name":"app","resources":{
"requests":{"cpu":"250m","memory":"128Mi"},
"limits":{"cpu":"500m","memory":"256Mi"}
}}]}}'
# 注意:不要加 --type=merge,否则和 --subresource resize 一起会触发校验错误场景 4:Istio 路由 ------ 通过 xDS 实现零重启
Istio VirtualService 和 DestinationRule 的变更永远不会触发容器重启。Istiod 会与每个 Envoy sidecar 保持一条持久的双向 gRPC 流------路由更新会在毫秒级被推送,以内存中的方式切换,不碰任何 Pod,也不会写文件。
实验结果(配套仓库 04-istio-routing/)
yaml
四个 Pod,三次路由变更:
100% v1 → 80/20 canary → 100% v2
Restart counts: BEFORE 0 0 0 0 / AFTER 0 0 0 0
Pod age: 三次变更过程中始终不变场景 5:Stakater Reloader ------ 把手工步骤自动化
当应用通过环境变量消费 ConfigMap 时,每次 ConfigMap 更新后,都需要有人执行:kubectl rollout restart Reloader 的作用就是把这一步自动化。它基于 Kubernetes Watch 事件工作,因此检测几乎是实时的,而不是轮询。
vbnet
metadata:
annotations:
reloader.stakater.com/auto: "true"生产环境里的坑:Helm 默认安装参数是:watchGlobally=false ,这意味着:Reloader 只监听它自己所在的 namespace。其他 namespace 里即使 Deployment 打了注解,也会被静默忽略,不会报错。所以建议安装时显式开启:
arduino
helm install reloader stakater/reloader \
--namespace reloader \
--set reloader.watchGlobally=true图 4:Stakater Reloader 内部工作流
实验结果(配套仓库中的 07-stakater-reloader/)
arduino
ConfigMap 已更新,未执行 kubectl rollout restart
新 Pod APP_MESSAGE: "Hello from OpsCart v2 --- auto reloaded!"
滚动容器重启被自动触发当热加载出问题时
热加载并不总是比容器重启更安全。它有两类典型故障模式。
1)语义错误的配置被静默接受
表现为:
- 文件变了
- inotify handler 也触发了
- 没有报错
- 但新配置逻辑上是错的
- Pod 仍然通过健康检查,却在错误状态下运行数小时
而如果采用"坏配置 + 容器重启"的方式,失败往往会立刻暴露出来。所以:
- 热更新的坏配置:静悄悄地晚失败
- 重启加载的坏配置:快速、显式地失败
建议: 在原子替换配置前,先做校验。
2)Envoy 悄悄拒绝 xDS 推送
Istiod 推送了一个 RouteConfiguration,但它引用的 cluster 还没有传播完成。Envoy 会拒绝这次更新,并继续沿用旧的路由规则。不会有任何 Pod event 被触发。建议:监控 pilot_xds_push_errors,并使用 istioctl proxy-status。
可观测性:每个运维都该知道的三个命令
ini
1)判断到底是"容器重启"还是"Pod 重建"
kubectl get pod <pod> -o custom-columns=\
"NAME:.metadata.name,UID:.metadata.uid,IP:.status.podIP,RESTARTS:.status.containerStatuses[0].restartCount"
2)查看 Pod 上的事件
kubectl describe pod <pod> | grep -A 20 "Events:"`
3)查看原地 resize 状态
kubectl get pod <pod> -o jsonpath='{.status.resize}'结论
容器重启具有破坏性,但它是诚实的------失败模式会立即且可见地暴露出来。hot-reload 优先优化可用性,但把失败变得更延迟、更隐蔽。两种策略都合理。关键在于,你要有意识地做选择。目标不是把重启自动化得更快。目标是理解得足够深:只有在进程确实需要死亡时,才去触发一次容器重启;在不需要的时候,则使用其他一切机制。
配套仓库:github.com/opscart/k8s-pod-restart-mechanics
作者:Shamsher Khan --- 高级 DevOps 工程师,IEEE 高级会员。