Elasticsearch(简称 ES)是当前最流行的分布式搜索引擎,具备强大的全文检索与数据分析能力。而 Spring Data Elasticsearch 基于 Spring Data API 对 ES 客户端进行了封装,极大简化了 Spring Boot 项目与 ES 的整合开发流程。
本文基于官方文档与实战经验,系统总结 Spring Boot 整合 Elasticsearch 8.x 的核心要点、版本选型、三种主流实现方式(ElasticsearchRepository、ElasticsearchTemplate、ElasticsearchClient)及完整代码示例,并附知识体系梳理,助力开发者快速上手、高效落地。
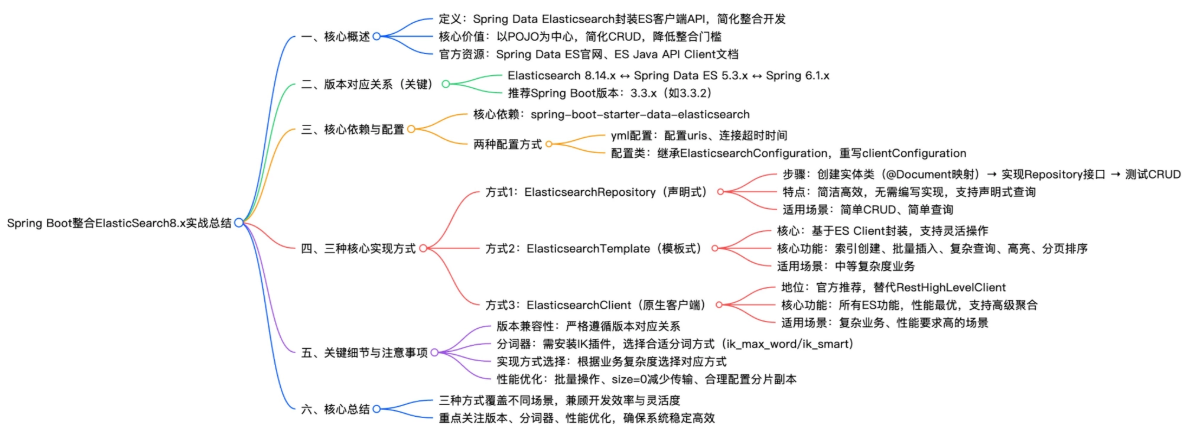
一、Spring Data Elasticsearch 核心概述
1.1 核心定位与价值
- Spring Data Elasticsearch 是 Spring Data 项目的子模块,对 Elasticsearch 官方 Java 客户端进行封装,提供统一、简洁的编程模型。
- 开发者无需直接调用复杂的 REST API,即可完成索引管理、文档 CRUD、高级搜索等操作。
- 以 POJO 为中心,通过注解将 Java 实体类与 ES 文档自动映射,显著降低整合门槛。
- 在提升开发效率的同时,保留 Elasticsearch 的核心特性与高性能优势。
1.2 版本对应关系(关键重点!务必严格遵守)
版本不匹配是整合失败的最常见原因。官方明确的兼容关系如下:
| Elasticsearch | Spring Data Elasticsearch | Spring Framework | 推荐 Spring Boot |
|---|---|---|---|
| 8.14.x | 5.3.x | 6.1.x | 3.3.x(如 3.3.2) |
✅ 若使用 Spring Boot 3.3.2,Maven/Gradle 会自动引入
spring-data-elasticsearch:5.3.2,无需手动指定版本。
❌ 切勿混用 7.x 与 8.x 客户端,API 差异巨大,极易导致运行时错误。
1.3 核心依赖与官方资源
1.3.1 核心依赖(Maven 示例)
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<!-- Spring Boot 3.3.2 自动引入 compatible 版本 -->
</dependency>⚠️ 无需额外引入
elasticsearch-java客户端,starter 已包含。
1.3.2 官方资源
- Spring Data Elasticsearch 官网
- Elasticsearch Java API Client 8.14 官方文档
- Spring Data Elasticsearch 查询方法文档
二、Spring Boot 配置 Elasticsearch 的两种方式
2.1 方式一:application.yml 配置(推荐)
配置简单、维护方便,适用于大多数场景。
yaml
spring:
elasticsearch:
uris: <http://localhost:9200>
connection-timeout: 1s
socket-timeout: 30s支持多个 URI(集群部署):
uris: ["<http://es1:9200>", "<http://es2:9200>"]
2.2 方式二:@Configuration 自定义配置类(灵活可控)
适用于需要 认证、SSL、自定义 HTTP 客户端 等高级场景。
java
@Configuration
public class ElasticsearchConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
// .withBasicAuth("user", "password") // 基础认证
// .useSsl() // 启用 HTTPS
.build();
}
}✅ 继承
ElasticsearchConfiguration可复用 Spring Data 的自动装配逻辑。
三、三种核心实现方式(实战详解)
3.1 方式一:ElasticsearchRepository(声明式开发,最简)
适合:基础 CRUD、简单条件查询
步骤 1:创建实体类(与 ES 索引映射)
java
@Document(indexName = "employee")
public class Employee {
@Id
private String id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Keyword)
private String department;
@Field(type = FieldType.Double)
private Double salary;
// getters & setters
}🔑 关键注解说明:
@Document:指定索引名,索引不存在时可自动创建(需开启自动创建)。@Id:对应 ES 文档_id。@Field:控制字段类型、分词器(如ik_max_word/ik_smart)。
步骤 2:定义 Repository 接口
java
public interface EmployeeRepository extends ElasticsearchRepository<Employee, String> {
List<Employee> findByDepartment(String department);
List<Employee> findByNameContaining(String name);
}✅ 无需实现类 !Spring Data 自动生成实现,支持 方法名派生查询(见下表)。
| 方法名示例 | 生成的 ES 查询 |
|---|---|
findByDepartmentAndSalaryGreaterThan |
bool.must(department=?, range(salary > ?)) |
findByNameLike |
wildcard(name: *?*) |
findBySalaryBetween |
range(salary: [?, ?]) |
步骤 3:测试使用
java
@Autowired
private EmployeeRepository employeeRepo;
// 保存
Employee emp = new Employee("1", "张三", "研发部", 15000.0);
employeeRepo.save(emp);
// 查询
List<Employee> list = employeeRepo.findByDepartment("研发部");3.2 方式二:ElasticsearchTemplate(模板式开发,灵活)
适合:批量操作、复杂查询、高亮、聚合等中等复杂场景
💡 注意:新版ElasticsearchTemplate已基于官方ElasticsearchClient实现 ,不再依赖废弃的RestHighLevelClient。
核心操作示例
java
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
// 创建索引(带 mapping)
elasticsearchTemplate.createIndex(Employee.class);
// 批量插入
List<IndexQuery> queries = employees.stream()
.map(emp -> new IndexQueryBuilder().withId(emp.getId()).withObject(emp).build())
.collect(Collectors.toList());
elasticsearchTemplate.bulkIndex(queries);
// 复杂查询(Match + 高亮)
Query query = NativeQuery.builder()
.withQuery(q -> q.match(m -> m.field("name").query("工程师")))
.withHighlight(h -> h.fields(Map.of("name", HighlightField.of(hf -> hf)))))
.build();
SearchHits<Employee> hits = elasticsearchTemplate.search(query, Employee.class);✅ 支持原生 DSL 构建,灵活性远超 Repository。
3.3 方式三:ElasticsearchClient(官方推荐原生客户端)
适合:高级聚合、极致性能优化、完全控制请求细节
Spring Boot 3.3+ 中可直接注入:
java
@Autowired
private ElasticsearchClient esClient;核心操作示例
java
// 索引文档
Product product = new Product("p1", "山地自行车", 2999.0);
esClient.index(i -> i
.index("products")
.id(product.getId())
.document(product)
);
// 搜索(Match 查询)
String keyword = "自行车";
SearchResponse<Product> response = esClient.search(s -> s
.index("products")
.query(q -> q.match(m -> m.field("name").query(keyword))),
Product.class
);
// 聚合查询(按价格区间分组)
SearchResponse<Void> aggResp = esClient.search(b -> b
.index("products")
.size(0) // 不返回文档,只返回聚合结果
.aggregations("price_ranges", a -> a
.range(r -> r
.field("price")
.ranges(
r1 -> r1.from(0).to(1000),
r2 -> r2.from(1000).to(5000)
)
)
),
Void.class
);✅ 完全兼容 Elasticsearch 8.x 新 API,语法简洁、类型安全、性能最优。
四、核心注意事项与关键细节
4.1 版本兼容性
- 必须严格对齐:ES 8.14 → Spring Data ES 5.3 → Spring Boot 3.3。
- 使用
mvn dependency:tree或gradle dependencies检查依赖冲突。
4.2 分词器配置
- 使用
ik_max_word/ik_smart前,必须在 ES 服务器安装 IK 分词器插件。 - 未安装会导致启动报错或分词失效。
4.3 三种方式对比与选型建议
| 实现方式 | 核心特点 | 适用场景 |
|---|---|---|
ElasticsearchRepository |
声明式、零实现、开发最快 | 简单 CRUD、基础查询 |
ElasticsearchTemplate |
模板封装、支持复杂操作 | 批量、高亮、条件组合查询 |
ElasticsearchClient |
官方原生、功能最全、性能最优 | 高级聚合、自定义 DSL、极致控制 |
✅ 新项目建议优先使用
ElasticsearchClient,长期维护性最佳。
4.4 其他关键细节
- 批量操作 :避免循环单条插入,使用
bulkAPI 提升性能 10 倍 +。 - 聚合查询 :设置
size: 0避免返回无用文档,减少网络开销。 - 单节点开发环境 :创建索引时设置
"number_of_replicas": 0,防止副本分配失败。 - 日志调试 :开启
logging.level.org.elasticsearch.client=DEBUG查看实际请求。
五、总结
Spring Boot 整合 Elasticsearch 8.x 的核心在于 合理选型 + 规范配置 + 场景化使用:
- 简单场景 →
ElasticsearchRepository,开发效率最高; - 中等复杂度 →
ElasticsearchTemplate,平衡灵活性与便捷性; - 复杂/高性能场景 → **ElasticsearchClient(官方推荐)**,掌控全局。
📌 牢记三点:
- 版本必须严格匹配;
- IK 分词器需提前安装;
- 批量操作用 bulk,聚合查询设 size=0。