26年3月来自哈工大、理想汽车、智源研究院、新南威尔士大学、哈工大重庆研究院和北大的论文"Chain of World: World Model Thinking in Latent Motion"。
视觉-语言-动作 (VLA) 模型是通往具身智能的一条充满希望的路径,但它们通常忽略了视觉动态背后的预测性和时间因果结构。世界模型 VLA 通过预测未来帧来解决这个问题,但却浪费了资源来重建冗余的背景。潜动作 VLA 紧凑地编码帧间转换,但缺乏时间连续的动态建模和世界知识。为了克服这些局限性,引入 CoWVLA(世界链 VLA),一种新的"世界链"范式,它将世界模型的时间推理与分离的潜运动表示统一起来。首先,预训练的视频 VAE 作为潜运动提取器,将视频片段显式地分解为结构和运动潜变量。然后,在预训练阶段,VLA 从指令和初始帧中学习,推断出连续的潜运动链并预测片段的终止帧。最后,在协同微调阶段,通过在统一的自回归解码器中联合建模稀疏关键帧和动作序列,将这种潜动态与离散动作预测相匹配。这种设计保留时间推理和世界知识的世界模型优势,同时保持潜动作的紧凑性和可解释性,从而实现高效的视觉运动学习。
机器人世界模型。世界模型通常用于捕捉环境状态及其未来演变,并已广泛应用于自动驾驶48, 51、图像和视频生成5, 14, 31, 42, 45, 53以及机器人1, 7, 19, 38, 50, 56等领域。当与VLA模型结合使用时,大多数方法7, 8, 50, 52, 57, 58依赖于预测未来的视觉状态来提供隐世界知识,并在机器人操作中展现出更优的性能。UVA 29进一步利用扩散模型联合优化视频预测和动作预测,从而提高视觉推理和控制推理的效率。然而,这些方法需要重建完整的视觉帧序列,导致计算成本高昂且资源消耗巨大。
机器人潜动作。潜动作方法学习两帧之间紧凑的潜转换来模拟环境动态。LAPA 54 引入一个三阶段框架(包括潜动作量化、潜动作预训练和动作微调),利用大规模伪动作监督来改进对真实世界机器人控制的学习。MoTo 12 遵循这一范式,并在运动量化和真实动作质量方面进行改进。TLA 6 进一步解耦与任务相关和与任务无关的运动因素。然而,这些方法通常将潜动作建模限制在帧对上,限制它们捕捉长程时间动态的能力。尽管 Villa-X 11 将潜动作扩展到多帧设置,但它仍然为每个局部帧对生成一个潜动作,导致时间一致性有限。此外,潜动作表示不可避免地编码静态外观和上下文细节。虽然 TLA 6 通过解耦任务相关性来缓解这个问题,但理想的潜空间应该明确地将结构与运动分开,从而产生更清晰、更易于解释的动作表示。
世界模型预测未来的视觉帧,导致冗余的背景重建,如图(a)所示。从认知角度来看,这种视频帧预测与人类构建世界模型的方式并不一致:推理的是运动和交互,而不是在记忆中重建每一个像素。这一观察引出一个重要问题:能否构建一种更紧凑、更抽象、更动态的世界建模方式?潜动作范式6, 11, 12, 54提供令人信服的启发。如图(b)所示,它将帧间转换编码为潜动作,这些潜动作作为世界建模的抽象运动载体,从而能够利用从视频中构建的伪动作标签进行大规模预训练。
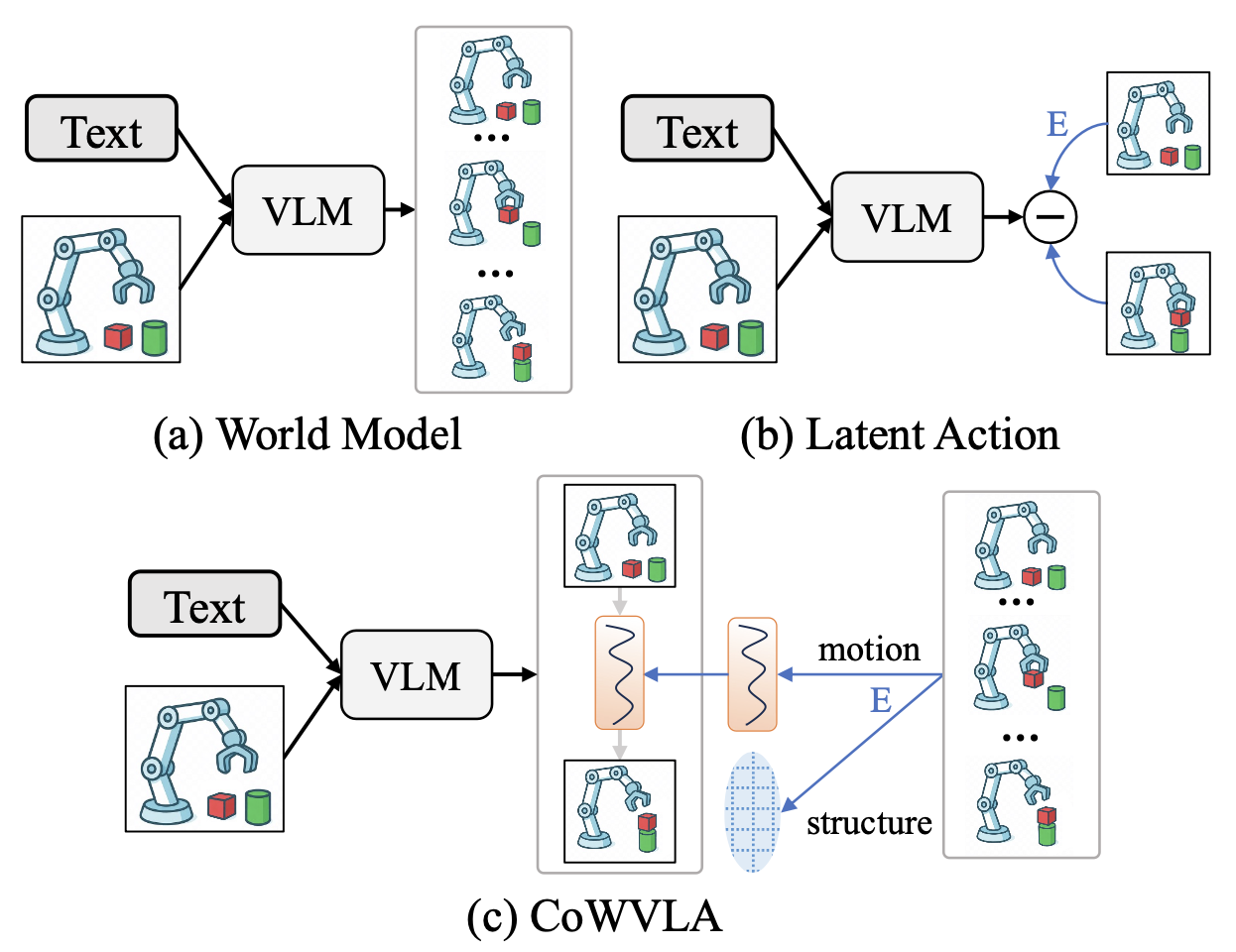
然而,与世界模型相比,当前的潜动作范式存在两个关键局限性。首先,世界模型执行的是时间连续的动态建模,而现有的潜动作通常只关注两帧之间的变化6, 12, 54。其次,世界模型通过对未来帧的预测,学习可用于任务执行的泛化知识以及关于世界的常识。相比之下,潜动作仅编码"如何移动",但缺乏对移动对象、运动发生位置以及运动后场景应如何演变的理解。
为了克服这些局限性,提出世界链VLA(CoWVLA),它建立一种新的范式,融合两种方法的优势,如图 © 所示。核心观点是,有效的世界建模既需要运动表征的紧凑性,也需要帧预测的时间连续性和世界知识。可以从视频片段中提取连续且紧凑的运动表征,这表明需要一个能够将视频中的内容结构和运动解耦的模型。这种运动表征可以作为感知关键动态变化的载体,并进一步使模型能够在时间演变后推断关键帧,从而保留重要的视觉地标。
总体框架
考虑一个机器人操作任务,该任务涉及根据语言指令和视觉观察执行一系列动作。指令表示为 T。原始动作序列为 A_1:t = {a_1, ..., a_t}。为了实现离散序列建模,动作序列 A_1:t 被分割成长度为 l_a 的连续块,即 A_1:t = U(Aj),Aj = {a_(j−1) l_a + 1, ..., a_j l_a},然后使用 FAST 35 算法将每个块 Aj 量化为离散token序列 Ajq。对应的原始视觉观察序列表示为 V_1:t = {v_1, ..., v_t},其中每一帧 v_i。将每个动作片段的第一帧提取为关键帧:Ṽ = {ṽ_j } = {v (j −1) l_a +1 },其中每个 ṽ_j 随后使用 VQGAN 15 量化为视觉token ṽj_q。此外,引入一个可学习的运动查询token Q 作为世界动态查询,其隐表示概括过去的上下文,并为生成后续的视觉或动作token提供一个未来动态-觉察的条件信号。
整个框架由两个模型和三个训练阶段组成。第一个模型是潜运动提取器(视频 VAE 范式),它将视频子序列 V_1:f 编码为中间潜特征 z,并将其分解为结构特征 z_s 和两个方向运动特征 zh_m 和 zw_m。两个运动分量连接起来形成一个统一的潜运动向量 z_m,作为真实值监督。第二个模型是 VLA 解码器(Transformer-解码器范式),它执行跨模态的统一自回归下一token预测。在预训练阶段,输入序列组织为 T, v^1^_q, Q, v^f^_q。从 VLA 解码器获得的与查询token Q 对应的最终隐表示被输入到 MLP 中,以预测潜运动 zˆ_m。此阶段使模型能够从语言和初始视觉输入中推断潜动态和未来观测结果。在协同微调阶段,用交替的关键帧和动作token,例如 T, ṽ^1^_q, Q, A^1^_q, ṽ^2^_q, A^2^_q,...。模型继续预测 Q 位置的潜运动向量 zˆ_m。因此,该模型在关键帧观测稀疏的情况下仍能保持显式的动态推理,并从紧凑的潜表示中生成稳定的多步动作。
潜运动提取器
为了在紧凑的潜空间中编码时间动态,用预训练的视频变分自编码器 49 作为潜运动提取器。如图所示,该提取器通过两个专用分支实现结构-运动解耦。给定一个视频片段 V_1:f,编码器生成一个潜张量 z。结构分支使用 Q-Former 27 模块和一组可学习的查询 {q_i} 来聚合时间维度上的全局语义和低频动态,从而得到 z_s,其中 n_q ≤ f。
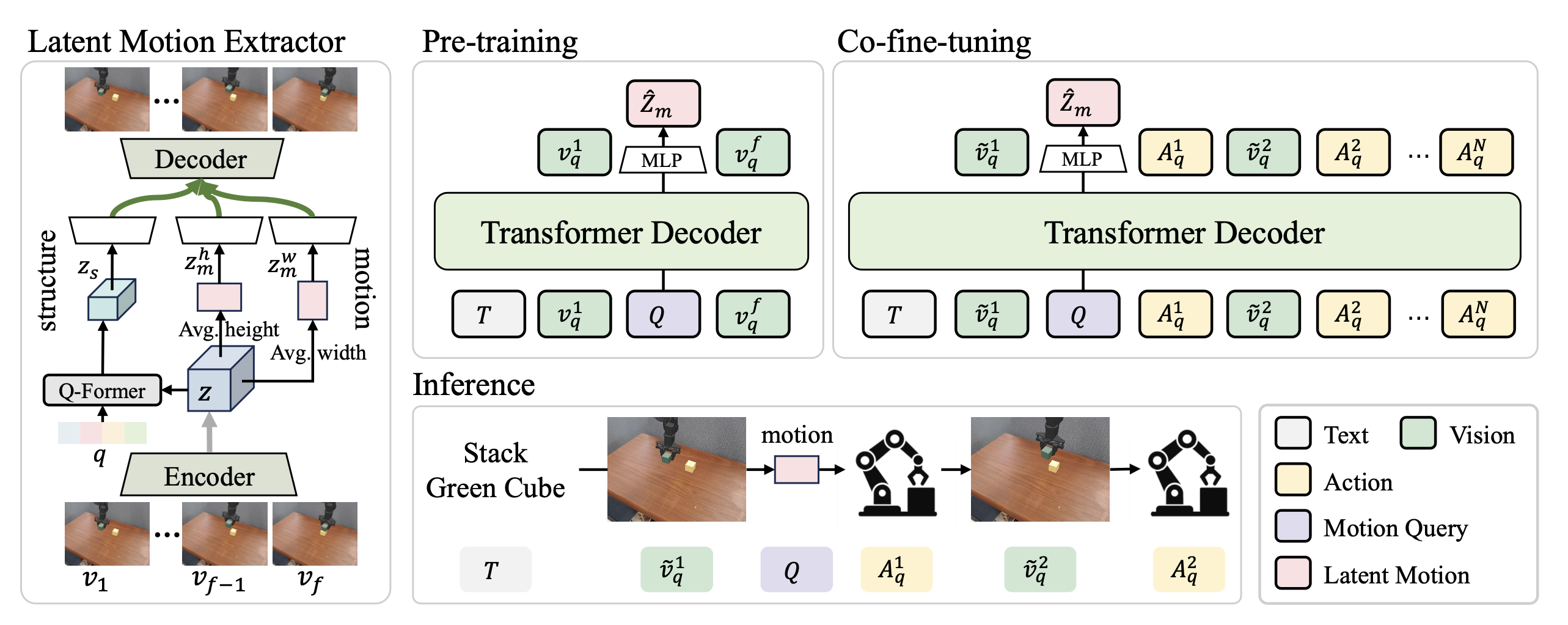
运动分支则沿空间维度进行操作:多个卷积层降低 z 的维度并生成 z′。然后,分别沿高度轴和宽度轴独立应用空间平均 μ(·) 来提取方向运动嵌入:zh_m = μ_h(z′),zw_m = μ_w(z′)。将这两个运动分量连接并展平,形成统一的潜运动表示:z_m, D_m = f × d_m × (h_m + w_m)。在解码器阶段,三个潜分量(z_s、zh_m、zw_m)通过卷积层和多层感知器(MLP)层上采样到相同的空间和时间尺度,然后相加,最后输入解码器以重建 Vˆ_1:f。训练目标遵循原始 VAE 设计 49,结合重建损失 L_rec、感知损失 L_p、对抗损失 L_GAN 和 KL 散度正则化损失 L_KL,以保持时间一致性和视觉真实感:
L_vae = L_rec + λ_p L_p + λ_GAN L_GAN + λ_KL L_KL. (1)
通过显式的结构-运动解耦和轻微的自适应,提取器生成紧凑、可解释且可迁移的潜表示,非常适合机器人场景,为下游 VLA 的预训练和协同微调提供有效的监督。
预训练在潜动作中思维
预训练阶段旨在将语言和初始视觉观察与潜运动表示对齐,使模型能够推理潜空间中的连续时间动态,并预测视频片段的最终帧。给定一个连续的视频片段 V_1:f = {v_1 ,..., v_f},潜运动提取器生成一个潜运动监督信号 z_m。它的第一个帧和最后一个帧被量化为离散的视觉token,分别表示为 v1_q 和 vf_q。
基于此,将VLA解码器的输入序列组织为:T, v^1^_q, Q, v^f^_q,其中T表示指令,v1_q表示初始观测值,Q是可学习的运动查询token,vf_q对应于应用从v_1到z_m的潜运动后达到的视觉状态。在前向传播过程中,查询位置的隐状态被输入到多层感知器(MLP)以预测潜运动 zˆ_m。
为了防止信息泄露,应用因果掩码,使得Q仅关注 {T, v1-q},同时屏蔽vf_q。训练目标 L_pretrain 包含潜运动监控和终帧视觉一致性,其中第一项确保在 Q 点提取的潜表示能够准确地概括从 v_1 到 v_f 的连续运动,而第二项则确保模型能够对最终状态做出连贯的预测。通过这一阶段,模型学习直接从语言和初始帧推断潜时间动态,从而为后续的动作建模建立动态-觉察先验。
协同微调以对齐潜动态与动作策略
在预训练阶段于潜运动空间建立动态-觉察先验之后,协同微调阶段在一个统一的自回归框架中进一步将潜运动推理与离散动作建模对齐,从而在关键帧观测稀疏的情况下实现稳定的多步控制。给定一个连续视频序列 V_1:f 及其对应的动作序列 A_1:f,提取 N = f/l_a 个关键帧,并将它们量化为视觉token:Ṽ_q = {ṽ1_q, . . . , ṽN_q},其中 ṽj_q = v^(j −1)l_a +1^_q。进一步使用 FAST 35 对动作序列进行量化:A_1:f −-FAST-− → {A1_q, ..., AN_q}。输入序列采用"全窗口的单-Q"设计:T, ṽ^1^_q, Q, A^1^_q, ṽ^2^_q, A^2^_q, ..., A^N^_q,其中查询token Q在第一个关键帧之后仅出现一次,并作为整个时间范围内潜动态的聚合器。解码器自回归地预测动作和视觉标记;Q的隐状态通过多层感知器(MLP)生成单个潜运动矢量zˆ_m,从而确保潜动态与后续预测之间的一致性。与预训练类似,因果掩码阻止Q关注未来的关键帧和动作,迫使模型基于潜动态进行推理,而不是直接窥探未来状态。
协同微调目标函数L_finetune包含三个项:第一项确保离散动作的精确执行,第二项鼓励查询token处的潜表示忠实地捕捉从 v_1 到 v_f 的连续动态,第三项将运动预测锚定到稀疏的视觉检查点,从而保持由预测动态驱动的一致状态转换。
基准测试
LIBERO。LIBERO 32 基准测试旨在研究多任务和终身机器人学习中的知识迁移,它既需要关于物体和空间关系的陈述性知识,也需要关于运动和行为的程序性知识。它包含四个任务套件:LIBERO-Spatial 通过根据碗的位置放置碗来强调空间推理;LIBERO-Object 通过拾取和放置不同的物体来侧重物体识别;LIBERO-Goal 在固定物体下测试具有不同任务目标的程序性学习;LIBERO-Long 包含十个具有不同物体、布局和目标的长期任务。
SimplerEnv。SimplerEnv 30 是一套用于常见真实世界机器人设置的操作评估环境,与真实机器人的性能具有很强的相关性。它能够评估在真实世界视频数据上训练的模型的迁移性和泛化能力。用 7 自由度 WidowX 机械臂在四个任务上进行评估。
实现细节
潜运动提取器基于预训练的视频VAE(VidTwin 49)构建,并在包含23.7万个视频的机器人数据集上进行进一步微调。每个视频片段均匀采样为16帧,并调整大小为224×224。结构潜嵌入z_s的形状为4×16×7×7,而方向运动嵌入zh_m和zw_m的形状为8×16×7。运动潜维度为D_m = 1792。
VLA模型骨干网络遵循UniVLA 50的设计,并基于85亿参数的VLM Emu3 47。视觉观测使用VQGAN 15量化为离散的token,而动作则被分割成块,并使用FAST算法 35离散化为token。在预训练阶段,用上述23.7万个视频,并采用预训练的Emu3初始化模型进行训练。从每个视频中,提取长度为f = 16的帧序列,其中首尾帧token用于监督视觉建模,而从VidTwin提取的潜运动则用于提供监督。用256的批大小训练1万步。在协同微调阶段,从预训练检查点初始化模型,并在基准测试数据集上进行训练。对于LIBERO基准测试,用OpenVLA 24 整理的四个任务套件混合数据,其中包括第三人称视角和腕戴式视角。用128的批大小训练8000次迭代,将所有图像调整为200 × 200像素,将动作块长度设置为l_a = 10,并使用λ_1 = 0.1和λ_2 = 0.01。对于 SimplerEnv,用 Bridge V2 数据集 43 训练模型,批大小为 128,迭代次数为 12k。单视图图像被调整为 256 × 256 像素,动作块长度设置为 la = 5,λ_1 = 0.1,λ_2 = 0。在协同微调阶段,设置 N = 2,其中使用两个视觉观察结果和两个对应的真实动作块。
实验装置。如图所示,用 Realman RM75B 机器人,该机器人配备 7 个自由度和一个单爪。用 Intel RealSense 摄像头采集 RGB 图像。设置一个抓取杯子的实验,共采集 127 个回合,包含 65,382 帧及其对应的动作。每个回合平均包含 515 帧,相当于现实世界中约 20 秒的时长。

数据集主要包含抓取四种不同颜色杯子的动作,每种颜色对应的回合数如下:红色 31 个,蓝色 39 个,黄色 24 个,紫色 33 个。图 (a) 展示了部分采集的数据。在训练过程中,所有图像均被裁剪并调整大小为 256×256 像素。动作块大小设置为 10。用 16 个 GPU,每个 GPU 的批大小为 8,对模型进行 2000 步的训练。数据在下午和晚上采集,然后用于模型训练。测试在第二天进行。如图所示,数据采集时的光照条件与实际部署时的光照条件存在一些差异。在不同的光照条件下,模型仍然能够正确执行指令。图 (b) 的前两行显示两个测试用例:抓取一个红色/紫色的杯子并将其放在盘子上。它们的背景光照与训练数据不同,但模型仍然能够成功执行任务。
