文章目录
前言
在日常工作和生活中,垃圾邮件一直是困扰我们的问题,用机器学习自动分类垃圾邮件是非常经典且适合新手入门的实战项目。
今天我将带大家从零开始,用 Python 实现垃圾邮件二分类任务,全程使用简单易懂的代码,包含数据读取、模型训练、混淆矩阵可视化、分类报告、特征重要性分析,新手也能轻松跑通!
一、项目环境准备
我们需要用到几个核心库,提前安装好:
c
pip install pandas scikit-learn matplotlib-
pandas:用于读取和处理数据
-
scikit-learn:机器学习核心库,提供随机森林、数据集划分、评估指标
-
matplotlib:用于可视化混淆矩阵和特征重要性
二、数据集说明
我们使用的是spambase.csv垃圾邮件数据集,这是公开的经典二分类数据集:
它具有以下几个特点
-
每行代表一封邮件
-
最后一列是标签:1= 垃圾邮件,0= 正常邮件
-
前面所有列是邮件的特征(如单词频率、字符频率等)
直接将数据集文件和代码放在同一文件夹即可读取。
数据集预览:
三、完整代码实现
c
import pandas as pd
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm =confusion_matrix(y,yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
df = pd.read_csv('spambase.csv')
from sklearn.model_selection import train_test_split
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
xtrain,xtest,ytrain,ytest = \
train_test_split(X,y,test_size = 0.2,random_state=100 )
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=100,
max_features = 0.8,
random_state = 0
)
rf.fit(xtrain,ytrain)
train_predicted = rf.predict(xtrain)
from sklearn import metrics
print(metrics.classification_report(ytrain,train_predicted,digits=9))
cm_plot(ytrain,train_predicted).show()
test_predicted = rf.predict(xtest)
print(metrics.classification_report(ytest,test_predicted))
cm_plot(ytest,test_predicted).show()
import matplotlib.pyplot as plt
importances = rf.feature_importances_
im = pd.DataFrame(importances,columns=["importances"])
clos = df.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[0:-1]
im['clos']=clos
im = im.sort_values(by=['importances'],ascending=False)[:10]
index = range(len(im))
plt.yticks(index,im.clos)
plt.barh(index,im['importances'])
plt.show()逐行讲解
- 导入库 + 定义混淆矩阵可视化函数
c
import pandas as pd
def cm_plot(y,yp):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm =confusion_matrix(y,yp)
plt.matshow(cm, cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',
verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt定义混淆矩阵可视化函数(通用版,直接复制用),同时实现绘制矩阵图的功能。
- 读取数据 + 划分训练集 / 测试集
这一步是机器学习标准流程:把数据分为训练集(训练模型)和测试集(评估模型)。
c
df = pd.read_csv('spambase.csv')
from sklearn.model_selection import train_test_split
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
xtrain,xtest,ytrain,ytest = \
train_test_split(X,y,test_size = 0.2,random_state=100 )
from sklearn.ensemble import RandomForestClassifier读取垃圾邮件数据集和划分训练集(80%)和测试集(20%),训练集和测试集的比率可自行调整。
- 训练随机森林模型
c
rf = RandomForestClassifier(
n_estimators=100,
max_features = 0.8,
random_state = 0
)
rf.fit(xtrain,ytrain)n_estimators=100, # 树的数量
max_features=0.8, # 特征使用比例
random_state=0 # 固定随机种子,结果可复现- 模型评估
查看模型在训练数据和测试数据上的表现,包含精确率、召回率、F1 分数。
测试集效果才是模型真正的泛化能力,这是我们最关心的结果。
c
train_predicted = rf.predict(xtrain)
from sklearn import metrics
print(metrics.classification_report(ytrain,train_predicted,digits=9))
cm_plot(ytrain,train_predicted).show()
test_predicted = rf.predict(xtest)
print(metrics.classification_report(ytest,test_predicted))
cm_plot(ytest,test_predicted).show()- 特征重要性分析
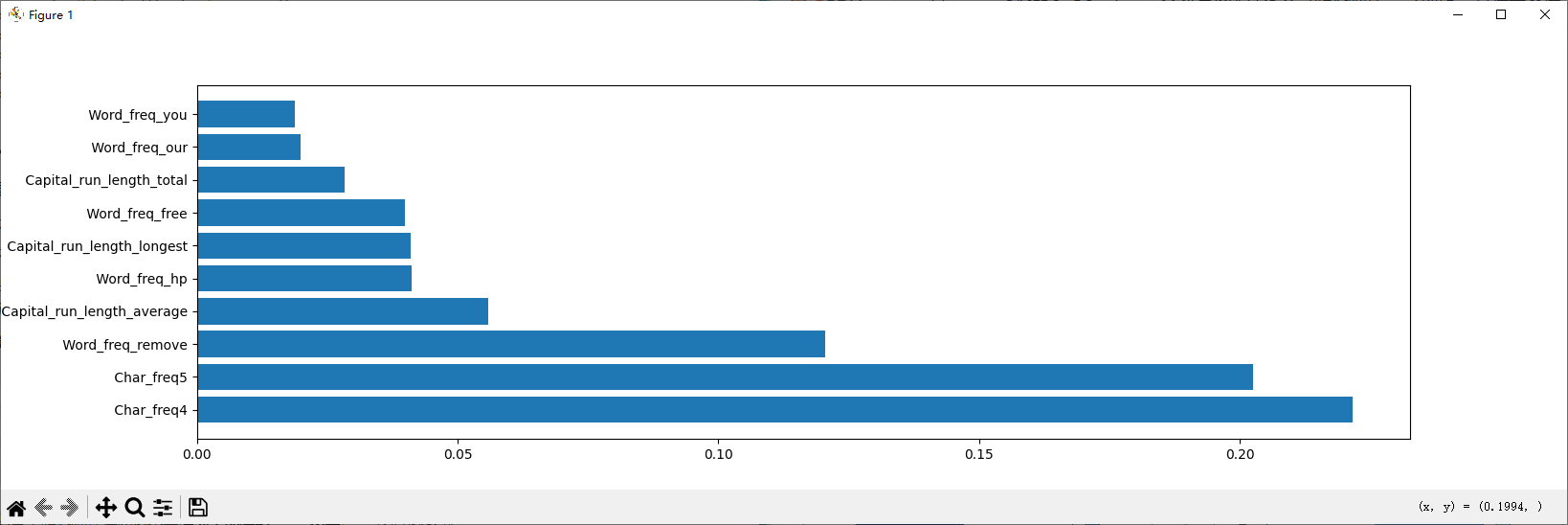
随机森林可以输出特征重要性,告诉我们哪些指标对判断垃圾邮件最关键。
c
import matplotlib.pyplot as plt
importances = rf.feature_importances_
im = pd.DataFrame(importances,columns=["importances"])
clos = df.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[0:-1]
im['clos']=clos
im = im.sort_values(by=['importances'],ascending=False)[:10]
index = range(len(im))
plt.yticks(index,im.clos)
plt.barh(index,im['importances'])
plt.show()首先获取特征重要性,然后整理成DataFrame,方便我们遍历获取,最后取TOP10为最重要的特征,绘制水平柱状图,便于我们可视化哪些指标对判断垃圾邮件最关键。
四、代码运行结果展现
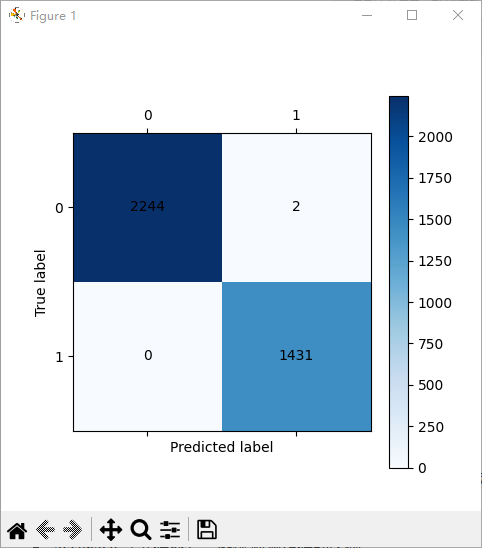
训练集混沌矩阵:
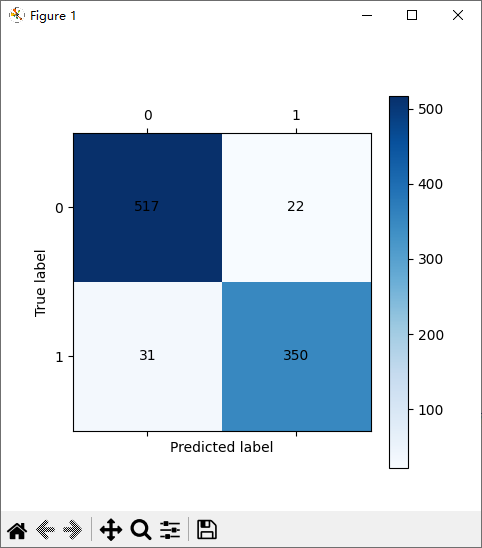
测试集混沌矩阵:
结果水平柱状图:
代码输出结果:
c
precision recall f1-score support
0 1.000000000 0.999109528 0.999554566 2246
1 0.998604327 1.000000000 0.999301676 1431
accuracy 0.999456078 3677
macro avg 0.999302163 0.999554764 0.999428121 3677
weighted avg 0.999456837 0.999456078 0.999456147 3677
precision recall f1-score support
0 0.94 0.96 0.95 539
1 0.94 0.92 0.93 381
accuracy 0.94 920
macro avg 0.94 0.94 0.94 920
weighted avg 0.94 0.94 0.94 920混淆矩阵
-
左上角:真实为正常邮件,预测为正常邮件(正确)
-
右下角:真实为垃圾邮件,预测为垃圾邮件(正确)
-
另外两个格子:分类错误的样本,颜色越深、对角数字越大,代表模型效果越好。
分类报告核心指标
-
precision(精确率):预测为某类的样本中,真正是该类的比例
-
recall(召回率):真实为某类的样本中,被正确预测的比例
-
f1-score:精确率和召回率的平衡值,越接近 1 效果越好
-
accuracy(准确率):整体预测正确的比例
我们看模型训练的好不好,主要看召回率,召回率越接近1,代表模型优秀。
总结
本项目用随机森林完成垃圾邮件二分类,简单高效,实现了数据集划分、模型训练、评估指标、可视化全套流程。
混淆矩阵和特征重要性让模型结果更直观、可解释。
代码可直接复用,替换数据集就能做其他二分类任务(如欺诈检测、疾病预测等)