前言
学习完前面的回归模型,现在我们来学习最重要的一个二分类模型,在后面的深度学习中我们也会是用到这个模型作为我们的激活函数,它其实也是基于前面的线性回归模型的得分,把值域限制到0,1之间,通常来说以0.5作为分类阈值来进行分类。
一、基础常数与函数核心规则
1. 自然常数e(逻辑回归专用)
数学公式:
-
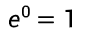 (所有数的 0 次幂均为 1,临界值计算核心)
(所有数的 0 次幂均为 1,临界值计算核心) -
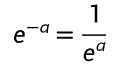 (e 的负 a 次幂 = 1÷e 的 a 次幂,Sigmoid 函数压缩的关键规则)
(e 的负 a 次幂 = 1÷e 的 a 次幂,Sigmoid 函数压缩的关键规则)
*注释*:
-
e:自然常数,无理数,近似值e≈2.71828
-
a:任意实数(逻辑回归中为线性分数z)
核心作用
仅支撑 Sigmoid 函数的概率压缩逻辑,是逻辑回归实现 "分数转概率" 的数学基础。
2. 自然对数log(核心运算规则)
数学公式:
-
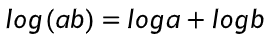
:对数的积 = 对数的和;
-
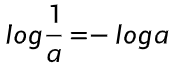
:倒数的对数 = 对数的相反数
注释:
-
log:自然对数(以e为底,逻辑回归中所有对数均为此类)
-
a、b:大于 0 的实数(逻辑回归中为预测概率
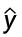 )
)
核心作用
将 "概率乘法运算" 转为 "加法运算",简化模型计算,且不改变结果极值,保证参数优化结果不变。
二、核心数学基础(为模型推导服务)
2.1 概率基础(条件 / 联合概率)
2.1.1 联合概率
定义 :多个独立事件同时发生的概率,用于计算 "所有样本同时预测准确" 的联合概率;
数学公式:
-
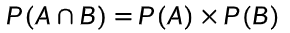
(A、B相互独立)
-
事件 A 和 B 同时发生的概率 = 事件 A 发生的概率 × 事件 B 发生的概率
核心作用
用于计算多个样本同时被正确预测的联合概率,是极大似然估计的计算基础。
2.1.2 条件概率
事件 B 已发生时,事件 A 发生的概率(P(A∣B)),是极大似然估计的理论基础。
数学公式:
-
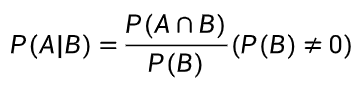
-
事件 B 发生后事件 A 发生的概率 = A 和 B 同时发生的概率 ÷ 事件 B 发生的概率
注释:
-
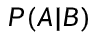
:事件 B 为条件的事件 A 的条件概率
-

:A、B 的联合概率;
核心作用
为概率相关的模型推导提供理论基础,是理解****极大似然估计****的前置知识。
2.2 极大似然估计(核心公式 + 推导逻辑)
2.2.1 核心思想
根据观测到的样本结果,反推*****最可能产生该结果的模型参数*****,即:找到参数θ(西塔),使样本观测结果出现的联合概率最大。
2.2.2 单样本似然公式
-
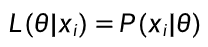
-
参数 θ 下样本
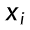 的似然值 = 参数 θ 已知时样本
的似然值 = 参数 θ 已知时样本 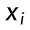 出现的概率
出现的概率
注释:
θ:模型待估计的参数(逻辑回归中为W和b)
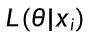 :参数 θ 下样本
:参数 θ 下样本 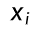 的似然值
的似然值
2.2.3 多样本联合似然公式(独立样本)
-
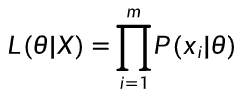
-
参数 θ 下所有样本的似然值 = 参数 θ 已知时每个样本出现的概率连乘
注释:
-
X:所有观测样本的集合
-
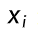 :单个样本
:单个样本 -
m:样本总数
-
∏(派):连乘符号
2.2.4 对数似然公式(逻辑回归常用)
-
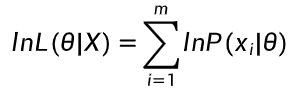
-
参数 θ 下的对数似然值 = 参数 θ 已知时每个样本出现概率的对数求和
注释:
∑(西格玛):求和符号
2.2.5 核心作用
逻辑回归交叉熵损失函数的理论推导依据,将 "求联合概率最大值" 转化为 "求对数似然最大值",最终等价于 "求交叉熵损失最小值"。
2.3 逻辑回归交叉熵损失函数(从极大似然推导)
2.3.1 推导前提
逻辑回归中,样本标签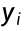 只有 0 和 1 两种取值:模型预测样本为类别 1 的概率是
只有 0 和 1 两种取值:模型预测样本为类别 1 的概率是 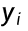 ,预测为类别 0 的概率是 1−
,预测为类别 0 的概率是 1−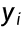 ,这两个概率可以用一个统一的公式来表示。
,这两个概率可以用一个统一的公式来表示。
数学公式:
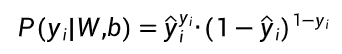
在参数 W 和 b 下:
-
样本i是正例时,它的预测概率就是「正例的概率」;
-
样本i是反例时,它的预测概率就是「反例的概率」。
注释:
-
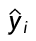 :样本 i 预测为正例的概率
:样本 i 预测为正例的概率 -
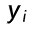 :样本 i 的真实标签(0 或 1)
:样本 i 的真实标签(0 或 1) -
W:权重向量
-
b:偏置项
2.3.2 多样本联合似然函数
数学公式:
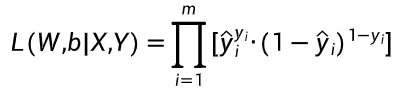
在参数 W 和 b 下,所有样本的联合似然值,就是把每个样本的「正确预测概率」连乘起来:
-
如果样本真实标签是 1(正例),就取「预测正例概率」
-
如果样本真实标签是 0(反例),就取「1 - 预测正例概率」
-
最后把所有样本的这个值相乘,得到当前参数下的总似然值
注释:
∏(派):连乘符号
2.3.3 对数似然函数(转化为加法)
数学公式:
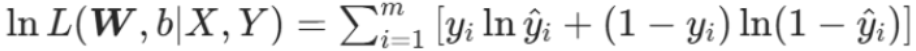
在参数 W 和 b 下,所有样本的总对数似然值 ,就是把每个样本的预测概率的对数值加在一起:
-
如果样本真实标签是 1(正例),就取 「预测正例概率的对数」
-
如果样本真实标签是 0(反例),就取 「1 减去预测正例概率的对数」
-
最后把所有样本的这个值相加,得到当前参数下所有样本的总对数似然值。
2.3.4 通用核心评估逻辑(所有似然值评估都遵循)
-
核心准则:似然值越大 → 参数越优(越能匹配真实数据);似然值越小 → 参数越差(与真实情况偏差越大);
-
极端情况:
-
- 似然值 = 1:仅当所有样本的 "正确预测概率 = 1"(完美预测),是理论最优情况(实际中极少出现);
- 似然值→0:当大量样本的 "正确预测概率→0"(严重误判),参数完全不可用;
-
核心用途:用于参数优化 (找使似然值最大的参数)和参数对比(哪个参数组合的似然值大,哪个更优),而非单独看绝对数值。
-
当似然函数被转化为 "损失函数" 时(比如逻辑回归的交叉熵损失),会取 "负的对数似然值":
-
- 此时评估标准反转:损失函数越小 → 原似然值越大 → 参数越优;
- 但这不是 "似然值的评估标准变了",只是为了适配 "梯度下降(最小化损失)" 的优化逻辑,本质还是在最大化似然值。
2.3.5 交叉熵损失函数(取负求最小)
数学公式:
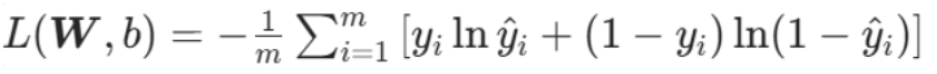
在参数 W 和 b 下,交叉熵损失,就是把每个样本的「预测偏差对数」先求和,再做两步转换得到最终损失:
-
如果样本真实标签是 1(正例),就取 「预测正例概率的对数」
-
如果样本真实标签是 0(反例),就取 「1 - 预测正例概率的对数」
-
先把所有样本的这个值相加,得到总偏差对数;再给总偏差对数取负号,最后除以样本总数,得到当前参数下的平均交叉熵损失
核心逻辑:损失值越小,说明当前参数 W 和 b 对应的模型预测越贴近真实标签。
注释:
-
m:样本总数
-
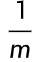 :求平均损失,消除样本数影响
:求平均损失,消除样本数影响 -
负号:将 "最大化对数似然" 转化为 "最小化损失",适配梯度下降优化逻辑
核心作用
直接量化模型预测概率与真实标签的差异,是逻辑回归模型训练的核心优化目标(损失越小,模型越优)。
三、逻辑回归核心模型推导(按流程拆解)
步骤 1:线性回归计算无界原始分数(Logits)
单个样本
数学公式:
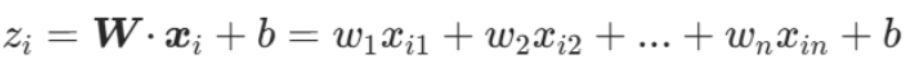
样本 i 的线性分数 = 特征值 1× 权重 1 + 特征值 2× 权重 2+...+ 特征值 n× 权重 n + 偏置项
注释 :

批量样本(矩阵形式)
数学公式:
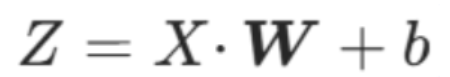
所有样本的分数矩阵 = 特征矩阵 × 权重向量 + 偏置项
核心作用
将样本特征按 "重要程度" 加权整合,生成代表 "分类倾向" 的无界数值,为后续概率转换做基础。
步骤 2:Sigmoid 函数(分数→0-1 概率,二分类核心)
公式
数学公式:
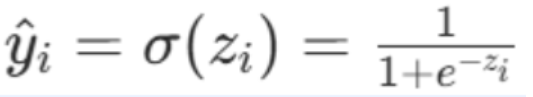

核心特性(分数→概率的压缩逻辑)
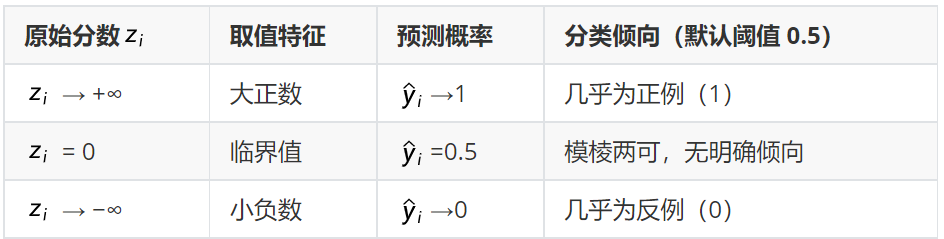
分类判断规则

核心作用
将无界的线性分数精准映射为 0-1 的概率值,实现从 "数值回归" 到 "概率分类" 的核心跨越,是逻辑回归实现二分类的关键。
步骤 3:梯度下降优化模型参数(求最优W和b)
优化目标
找到一组最优的权重W ∗和偏置b∗ ,使得训练集交叉熵损失L(W,b)达到最小值,此时模型预测误差最小。
核心逻辑
将总损失L(W,b)视为以W和b为自变量的 "损失曲面",优化过程是从随机初始参数出发,沿损失下降最陡的方向(梯度反方向)逐步调整参数,直到损失不再明显下降(收敛)。
核心概念
- 梯度 :损失函数对参数的偏导数(
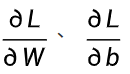 ),代表损失在当前参数下 "变化最快的方向和速率";
),代表损失在当前参数下 "变化最快的方向和速率"; - 学习率α:超参数(一般取 0.001、0.01、0.1),控制参数每次调整的 "步长",是梯度下降收敛的关键。
公式 1:计算梯度(损失变化的最快方向)
偏置b的梯度
数学公式:
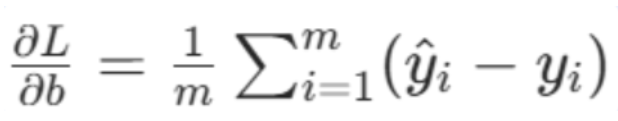
在参数 W 和 b 下,损失对偏置的梯度 ,就是把每个样本的「预测概率与真实标签的差值」先求和,再取平均值:

用途 :这个梯度用于梯度下降更新偏置 b,梯度的正负和大小,指导我们如何调整 b 才能让交叉熵损失最小化。
权重W的梯度(矩阵形式)
数学公式:
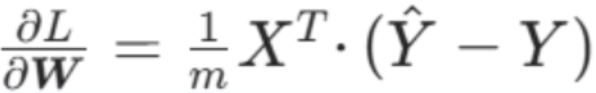

公式 2:参数迭代更新(核心优化步骤)
偏置b的更新
数学公式:
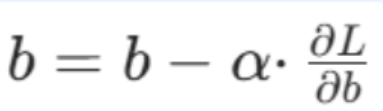
新偏置 = 原偏置 - 学习率 × 损失对偏置的梯度
权重W的更新
数学公式:
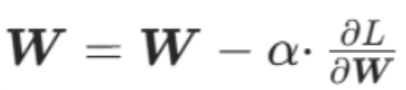
新偏置 = 原偏置 - 学习率 × 损失对偏置的梯度
迭代训练过程
将「线性分数计算→Sigmoid 概率转换→损失计算→梯度计算→参数更新」重复执行N次(迭代次数,如 1000、5000 次),直到满足收敛条件:
- 总损失L(W,b)的变化量小于预设阈值(如10−6);
- 达到预设的最大迭代次数。
学习率α的关键注意
- α过小:参数调整步长太小,训练迭代次数过多,模型收敛速度极慢;
- α过大:参数调整步长太大,易 "冲过" 损失最小值,导致损失震荡甚至无法收敛;
- 核心原则:小步慢走,逐步收敛。
核心作用
沿损失下降方向迭代调整权重W和偏置b,找到使总损失最小的最优参数,实现模型的自我优化。
四、二分类模型评估指标(基于混淆矩阵)
评估的核心是基于混淆矩阵 的 4 个基础指标,衍生出适配不同业务场景的评估指标,准确率并非万能指标(类别不平衡时会失真)。
前置:混淆矩阵 4 个基础指标(定义)
针对二分类(正例 = 1,反例 = 0),总样本数 = TP+FN+FP+TN:
- TP(真正例):真实为 1,预测为 1;
- FN(伪反例):真实为 1,预测为 0(漏判);
- FP(伪正例):真实为 0,预测为 1(误判);
- N(真反例):真实为 0,预测为 0。
| 预测正例 | 预测反例 | |
|---|---|---|
| 真实正例 | TP(真正例) | FN(伪反例) |
| 真实反例 | FP(伪正例) | TN(真反例) |
1. 准确率(Accuracy)
数学公式:
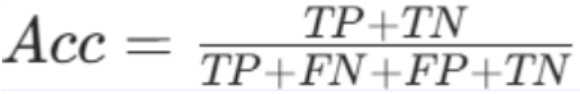
准确率 =(真正例 + 真反例)÷ 总样本数
注释:
Acc:准确率,取值0,1,越接近 1,整体预测越准
适用场景
仅适用于正 / 反例样本数量相近的类别平衡场景,类别不平衡时无参考价值。
2. 精确率(Precision / 查准率)
数学公式:
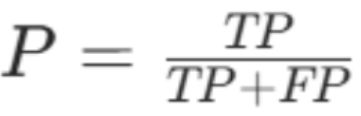
精确率 = 真正例 ÷(真正例 + 伪正例)
注释:
P:精确率,取值0,1,越接近 1,正例预测越准
适用场景
核心解决**"误判"**问题(如健康人被诊断为癌症、正常用户被判定为欺诈)。
3. 召回率(Recall / 查全率)
数学公式:
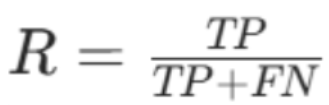
召回率 = 真正例 ÷(真正例 + 伪反例)
注释:
R:召回率,取值0,1,越接近 1,正例召回越全
适用场景
核心解决**"漏判"**问题(如癌症患者未被诊断、欺诈用户未被识别)。
4. F1-score(综合精确率 + 召回率)
数学公式:
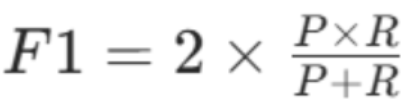
F1 分数 = 2×(精确率 × 召回率)÷(精确率 + 召回率)
注释:
F1:F1 分数,取值0,1,越接近 1,模型综合性能越好
核心特性
精确率和召回率的调和平均数,比算术平均更侧重两个指标的低值(一个指标低,F1 分数必然低),能平衡 "误判" 和 "漏判" 问题。
5. ROC 曲线与 AUC 指标(类别不平衡场景核心)
基础衍生指标
真正率(TPR)
数学公式:
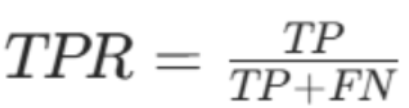
真正率 = 真正例 ÷(真正例 + 伪反例)
注释:
-
TPR:真正率,代表正例被正确预测的比例
-
TPR 与召回率完全一致,取值0,1,越接近 1,正例召回越全
假正率(FPR)
数学公式:
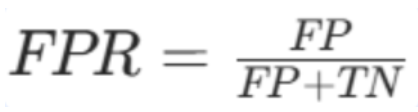
假正率 = 伪正例 ÷(伪正例 + 真反例)
注释:
FPR:假正率,代表反例被错误预测为正例的比例
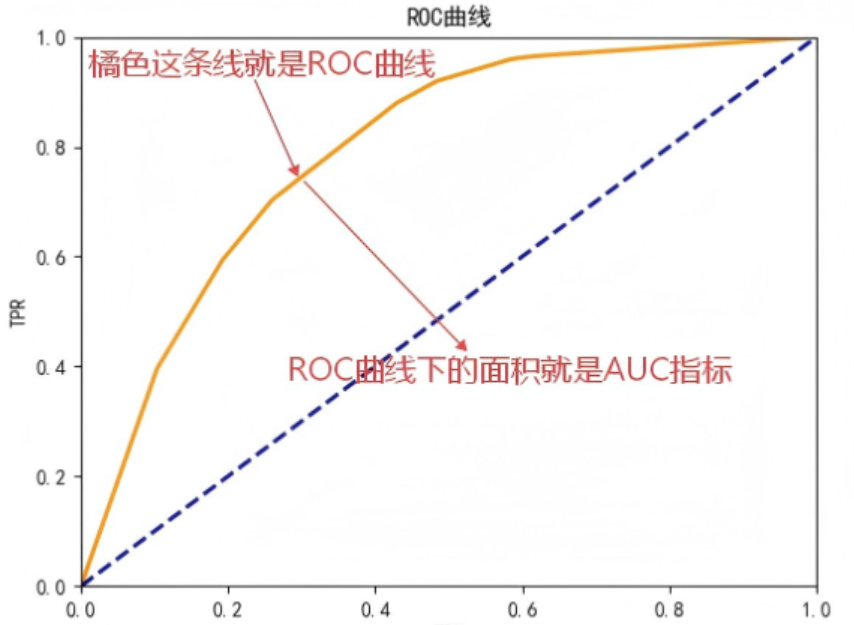
ROC 曲线
-
横轴:假正率(FPR),纵轴:真正率(TPR);
-
含义:反映模型在不同概率阈值θ下的分类性能,曲线越靠近左上角 (0,1),模型性能越好;
-
随机猜测的 ROC 曲线:过 (0,0) 和 (1,1) 的对角线(AUC=0.5)。
AUC 指标(Area Under ROC Curve)
- 含义:ROC 曲线与坐标轴围成的面积,取值范围0,1;
指标解读:
-
- AUC=1:完美分类器,能完全正确区分正 / 反例;
-
- 0.5<AUC<1:模型有一定分类能力,AUC 越大性能越好;
-
- AUC=0.5:模型分类能力等同于随机猜测;
-
- AUC<0.5:模型分类能力差于随机猜测(可反向预测改善)。
- 核心优势:对类别不平衡的样本具有鲁棒性,是类别不平衡场景下的核心评估指标。
五、Sklearn 核心 API(参数 + 方法 + 评估)
1. 逻辑回归核心 API
Python
from sklearn.linear_model import LogisticRegression
# 实例化模型
estimator = LogisticRegression(solver='liblinear', penalty='l2', C=1.0, random_state=None)关键参数说明(核心必看)
| 参数 | 取值 / 核心说明 |
|---|---|
| solver | 优化器(梯度下降相关):1. liblinear:小数据集首选,支持 L1/L2 正则;2. sag/saga:大数据集首选,sag 仅支持 L2,saga 支持 L1/L2 |
| penalty | 正则化类型:l1/l2,防止模型过拟合,需与 solver 匹配 |
| C | 正则化力度的倒数,C 越小→正则化越强,C 越大→正则化越弱 |
| random_state | 随机种子,保证实验结果可复现 |
| max_iter | 最大迭代次数,默认 100,若模型未收敛可增大(如 1000) |
模型常用方法
-
estimator.fit(X_train, y_train):用训练集训练模型(自动完成参数优化); -
estimator.predict(X_test):预测测试集的类别标签(0/1); -
estimator.predict_proba(X_test):预测测试集的概率(返回每个样本为 0 和 1 的概率); -
estimator.score(X_test, y_test):计算测试集的准确率; -
estimator.coef_:获取训练后的权重向量****W; -
estimator.intercept_:获取训练后的偏置项b。
2. 评估相关 API
Python
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, roc_auc_score, classification_report
# 1. 混淆矩阵
confusion_matrix(y_true, y_pred) # y_true=真实标签,y_pred=预测标签
# 2. 精确率/召回率/F1-score(pos_label指定正例标签,如1)
precision_score(y_true, y_pred, pos_label=1)
recall_score(y_true, y_pred, pos_label=1)
f1_score(y_true, y_pred, pos_label=1)
# 3. AUC值(y_score可为预测概率或预测分数)
roc_auc_score(y_true, y_score)
# 4. 分类报告(输出所有指标,含样本数)
classification_report(y_true, y_pred, target_names=['反例', '正例'])六、核心总结
1. 关键结论(必记)
-
- 逻辑回归是分类算法,核心是 "线性回归 + Sigmoid 激活函数",通过概率实现二分类,并非回归算法;
- 交叉熵损失函数由极大似然估计推导而来,模型训练的本质是寻找最优权重W和偏置b,使交叉熵损失最小;
- Sigmoid 函数的唯一作用是将无界线性分数映射为 0-1 概率,自然常数e为其提供数学支撑,对数函数用于简化概率连乘计算;
- 类别不平衡场景下,准确率无参考价值,需重点关注召回率、F1-score 或 AUC 指标,其中 AUC 对不平衡样本鲁棒性最强;
- 梯度下降的核心是学习率α的选择,小步慢走是保证模型收敛的关键,学习率过大易震荡、过小收敛慢;
- Sklearn 中 LogisticRegression 默认将少数类作为正例,正则化类型(penalty)必须与优化器(solver)匹配,否则会报错。
七、电信客户流失预测案例
案例流程
-
- 数据清洗:处理缺失值、类别特征one-hot编码
- 特征筛选:分析特征与标签的关系,选择重要特征
- 模型训练:处理样本不平衡问题,交叉验证调参
- 模型评估:精确率、召回率、AUC指标
完整代码
Python
"""
案例:电信用户流失预测
目的: 1 演示逻辑回归的相关操作,二分类(流失 正样本 ,不流失 负样本 )
2 演示逻辑回归的评估操作, 混淆矩阵 准确率 精准率 召回率 F1 ROC曲线的AUC值, 分类评估报告
"""
# 引入相关库
import pandas as pd # 引入DataFrame
import seaborn as sns # 基于matplotlib的高级统计可视化库
import matplotlib.pyplot as plt # 引入matplotlib
from sklearn.linear_model import LogisticRegression # 引入逻辑回归模型
from sklearn.model_selection import train_test_split # 引入数据集划分
from sklearn.metrics import (accuracy_score, # 准确率
precision_score, # 精准率
recall_score, # 召回率
f1_score, # F1
confusion_matrix, # 混淆矩阵
roc_curve, # ROC曲线 绘制ROC曲线
roc_auc_score, # 计算 ROC 曲线下的面积 衡量的是模型在不同的二分类阈值下的分类性能 下方面积越大,模型性能越好
classification_report) # 详细分类评估报告
from sklearn.preprocessing import StandardScaler # 引入标准化
## 数据准备 ######
# 读取数据集
churn_data = pd.read_csv("file/churn.csv")
# 查看数据集信息
# print(churn_data.info())
"""
当前发现 churn 和 gender列为字符串类型,将其转为 bool型
gender --> gender_male gender_femail
male 1 0
female 0 1
pd.get_dummies() 自动识别object类型 并对每个类别生成一个二进制列
"""
churn_data = pd.get_dummies(churn_data) # 对数据集进行one-hot编码
# print(churn_data.info())
# 去除冗余列
"""
One-hot 编码后,对于二分类的类别 (churn : yes /no ),只要保留一列即可
gender列 同理
本项目中,选择删除 Churn_no 以及 gender_male 列。
"""
# 删除列, axis=1 表示删除列, inplace=True 表示直接修改DataFrame
churn_data.drop(columns=['Churn_No', 'gender_Male'], inplace=True, axis=1)
# print(churn_data.info())
# 重命名标签列,使其语义更为清晰,为了方便画柱状图
# 将 churn_yes 列重命名为 flag,作为模型的目标变量(1=流失,0=未流失)
churn_data.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
# print(churn_data.info())
# 打印标签类别统计信息
# normalize=True 表示将标签类别的个数转化为百分比,打印归一化的类别比例
value_counts = churn_data.value_counts(normalize= True)
# 画柱状图 绘制(月度会员)的流失情况
sns.countplot(data=churn_data, x='Contract_Month', hue='flag')
plt.show() # 显示
##################################################################################
######### 逻辑回归模型训练
## 特征工程
# 特征提取
X = churn_data[['Contract_Month','internet_other', 'PaymentElectronic']] # 特征列,必须二维
# 目标变量--标签列
y = churn_data['flag'] # 标签列, 二分类, 0=正常,1=流失
# 数据集划分
# 划分比例: 80% 训练集,20% 测试集
# 划分数据集, stratify=y :按照标签列的分布进行划分,保证训练集和测试集的标签分布一致
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# # 数据标准化,提升模型性能;数据量纲一致,所以不需要标准化
# # 创建标准化对象
# transfer = StandardScaler()
# transfer.fit_transform(X_train[['MonthlyCharges']]) # 仅对月度会员的月度费用进行标准化
# transfer.transform(X_test[['MonthlyCharges']]) # 仅对月度会员的月度费用进行标准化
# 逻辑回归模型训练
# 定义模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
print("模型预测结果:\n", y_pred)
print("真实结果:\n", y_test)
# 模型评估
'''
accuracy_score, # 准确率 (TP+TN)/(TP+TN+FP+FN) 适合类别平衡时的模型分类性能评估
precision_score, # 精准率 TP/(TP+FP) 所有检测出的阳性样本中,有多少是正确的,衡量模型的误报
recall_score, # 召回率 TP/(TP+FN) 实际的正例中,有多少被模型检测出, 衡量的是模型的漏报
f1_score, # F1 (2*precision*recall)/(precision+recall) F1= 准确率,召回率的调和平均值
confusion_matrix, # 混淆矩阵
roc_curve, # ROC曲线 绘制ROC曲线
roc_auc_score, # 计算 ROC 曲线下的面积 衡量的是模型在不同的二分类阈值下的分类性能 下方面积越大,模型性能越好
classification_report # 生成详细的分类评估报告
'''
print("准确率(方法一):\n", model.score(X_test, y_test))
print("准确率(方法二):\n", accuracy_score(y_test, y_pred))
print("精准率:\n", precision_score(y_test, y_pred))
print("召回率:\n", recall_score(y_test, y_pred))
print("F1:\n", f1_score(y_test, y_pred))
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
print("ROC曲线:\n", roc_curve(y_test, y_pred))
print("ROC曲线下的面积:\n", roc_auc_score(y_test, y_pred))
print("详细分类评估报告:\n", classification_report(y_test, y_pred))
# 绘制ROC曲线,观察模型在各种二分类阈值下的分类性能
# 调用 predict_proba 输出测试集的预测概率
y_pred = model.predict_proba(X_test)
y_pred = y_pred[:, 1] # 获取预测标签列
# 获取ROC曲线
# 参数1:真实标签
# 参数2:预测标签
# 返回结果:fpr, tpr, thresholds:假正例率,真正例率,阈值
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
print("阈值:", thresholds)
# 绘制ROC曲线
# 横坐标(x):假正例率-fpr
# 纵坐标(y):真正例率-tpr
# 参数1:横坐标
# 参数2:纵坐标
# 参数3:曲线颜色
# 参数4:线宽
# 参数5:曲线标签
plt.plot(fpr, tpr, color="darkorange", linewidth=2, label="ROC")
# 绘制对角线
plt.plot([0, 1], [0, 1], color="navy", linewidth=2, linestyle="--")
# 设置坐标轴
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
# 添加标题
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.title("ROC曲线")
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()
print("AUC值:\n", roc_auc_score(y_test, y_pred))