神经网络的结构
一、 神经网络的核心本质与基本单元
神经网络的本质就是数学,就是函数。 在这个复杂的函数中,最基本的单元就是神经元。神经元是一个函数,他的输入是上一层的所有神经元的激活值,输出是一个【0,1】的激活值。每一个神经元都代表着一个特征或者信息,这个神经元就是一个容器。
二、 神经网络的整体结构
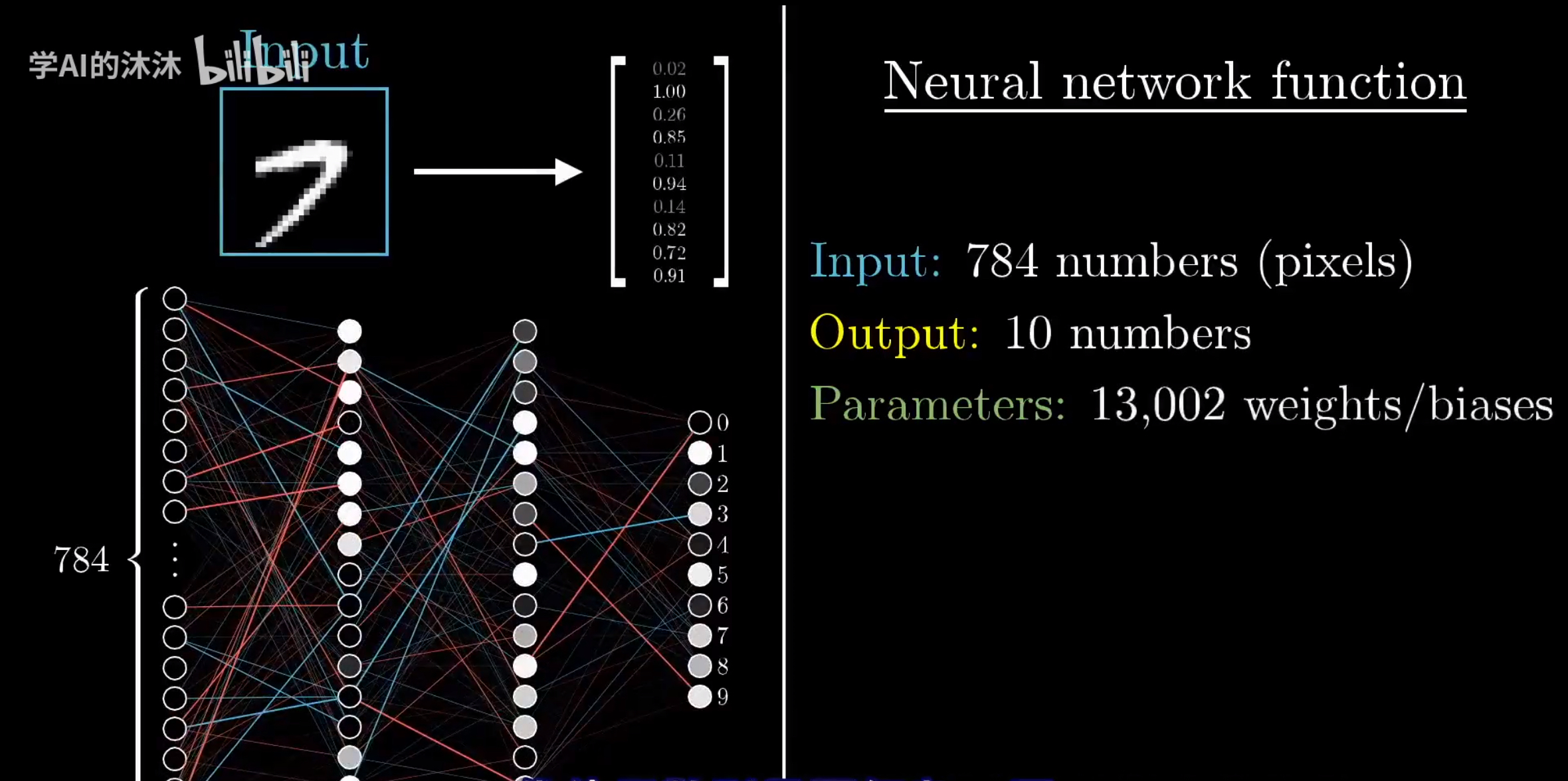
为了理解这些神经元是如何组织起来的,我们举一个例子:若某个神经网络的输入是一张 28*28 的汉字灰度图,输出是图像中的汉字。
输入层 :神经网络的第一层就是一个超长的列表,装着该图像所有的元素的灰度值。在这个例子中,输入就是一个 28281 = 1*784 的超长向量,每个向量中的元素就是一个神经元,这个神经元(容器)存储的是每个像素的灰度值。
隐藏层:中间的部分就是隐藏层,是一个黑盒,里面就进行着图像处理与汉字识别的工作。
输出层:最后一层就是输出的东西。如果是分类任务,那就会输出一个结果;如果是回归,那就是输出所有答案的可能性。在我们的例子中,输出就是 1*1 的向量,存储着该图像中的汉字。
三、 核心工作机制:激活值与权重偏置
上一层的激活值通过什么机制影响下一层的激活值?这也是神经网络工作的核心机制。
这是因为上一层的所有神经元都会与下一层的每一个神经元建立连接。每一根连接线上面都有一个权重。上一层的所有神经元与下一层的每一个神经元进行连接后,通过加权求和,自然就可以得到下一层的信息。
但在加权求和的过程中,会遇到两个数学细节:
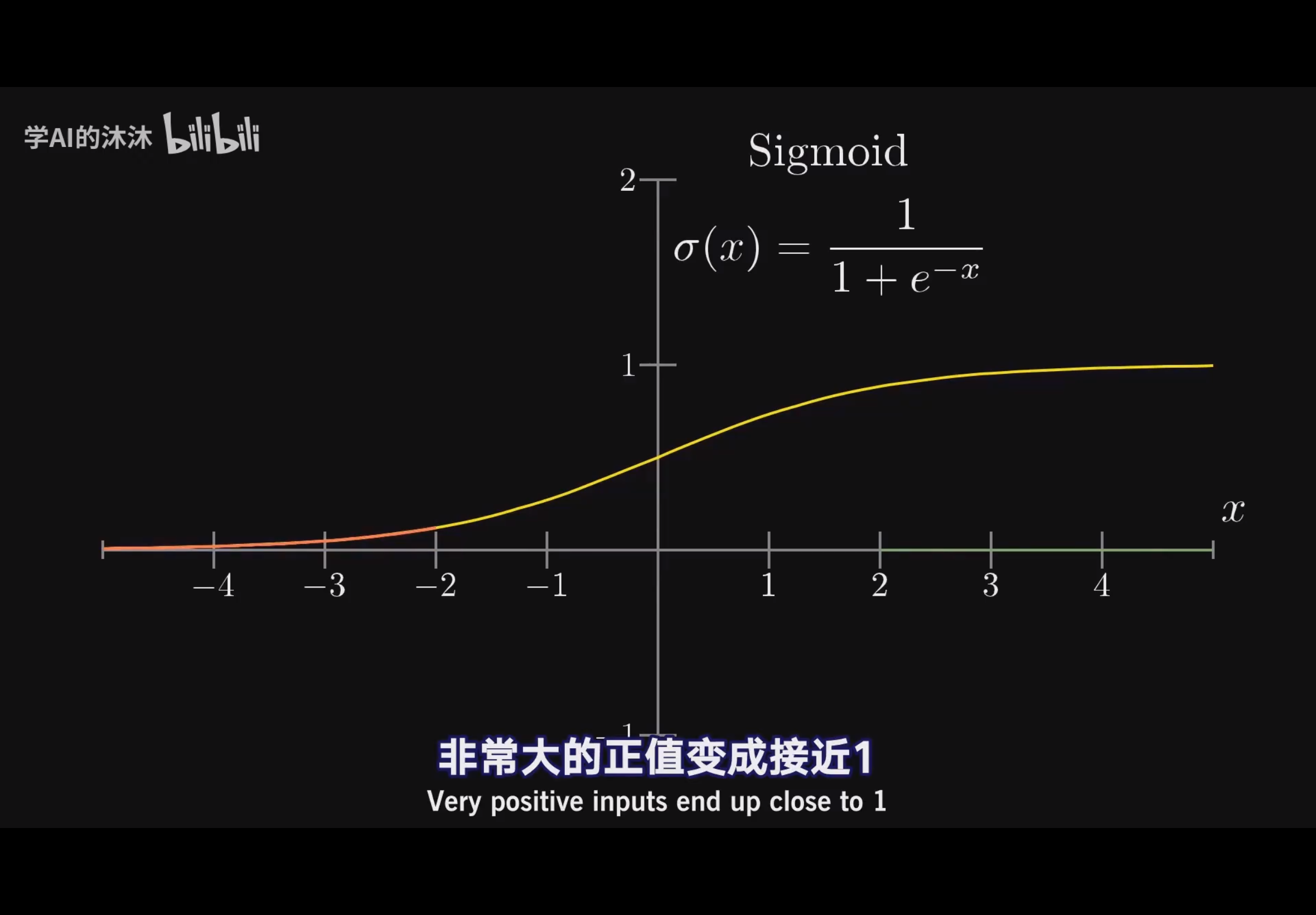
- 激活函数:加权求和得到的激活值可能不在 0,1 之间,所以这个时候我们会对这些激活值加上一层激活函数 sigmoid(也叫逻辑斯蒂函数),把激活值硬控在 0,1 之间。
- 偏置 (Bias):但是有时你会想要让这个加权求和得到的激活值大于一定值的时候才允许被激活,那么就会加上一个偏置。
四、 神经网络层数的意义与特征提取
神经网络层数的意义是什么? 我们用上面的例子可以知道,第一层是 1784 的向量,最后一层是 11 向量,我们可以知道,其实每过一层,维度就会越来越小,答案就会越来越"清晰"。
人类在识别汉字的时候,本质就是在查看各个组件是否存在。比如识别汉字"杰",是否有"木",是否是有"四点水",是不是上下组合结构。神经网络也是同理。
为什么第二层能够提取出更宏观一些的特征,比如说"横竖撇捺"? 因为第一层的所有神经元都与第二层的每一个神经元建立了连接。每条连接线上面有权重,通过加权求和,自然就可以得到更细节(宏观)的特征。
整个过程是这样层层递进的:
第一层的所有神经元存储的是图片的微观像素。
我们希望第二层可以提取出一些更宏观一些的特征,比如说**"横竖撇捺"**。
再到第三层,我们希望得到更宏观的特征。假设倒数第二层的每个神经元代表着各个偏旁部首,如"刀子旁"、"树心旁"、"三点水"、"四点水"、"草字头"、"木字旁"。
- 再到最后一层,提取到了最终的那个汉字。如果此时,"四点水"与"木字旁"神经元与输出层中的"杰"神经元的连接的权重是 1,其他神经元与"杰"神经元的连接的权重是 0,那么加权组合,自然就识别出了"杰"。
五、 模型训练的意义与最终总结
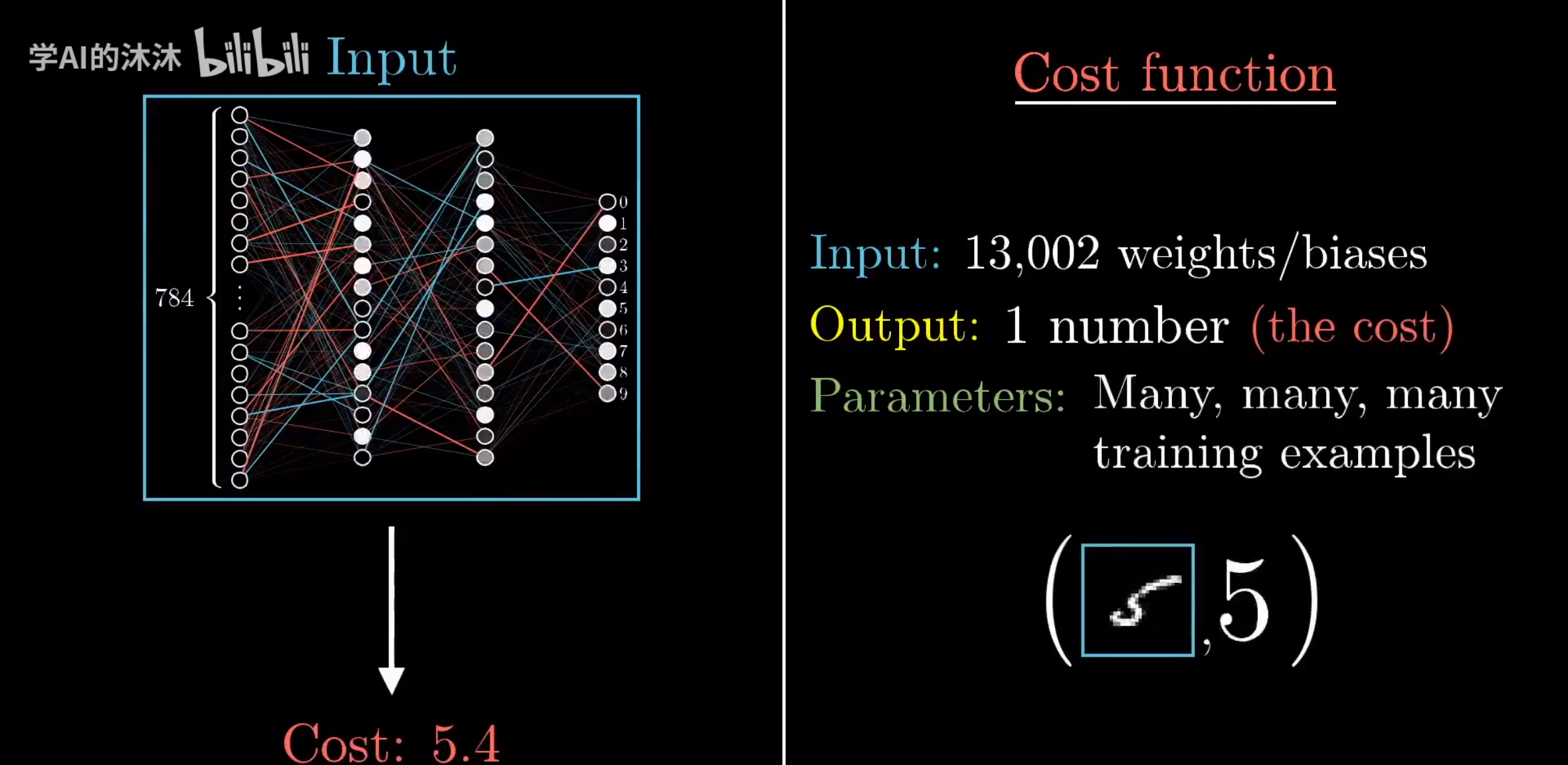
有了偏置与权重,一个模型可能就有成万上亿个参数,相当于成万上亿个开关。所以,当我们在讨论如何进行模型训练、如何学习得更好的时候,其实是在讲:如何选定好合适的参数,控制好合适的开关,才能让输入得到正确的输出。
总结而言: 神经网络的工作更像是一个拆解任务,从微观像素逐渐提取到宏观特征,更宏观特征,更更宏观特征,乃至答案的一个过程。神经网络的每一层就是一堆神经元,也就是提取到的宏观特征的集合,每一个神经元都代表着一个特征或者信息。上一层的所有神经元都会与下一层的每一个神经元进行连接,每一根连接线上面都有一个权重,通过学习到合适的权重,自然就能够通过上一层的神经元的加权求和,得到下一层更宏观的特征信息。



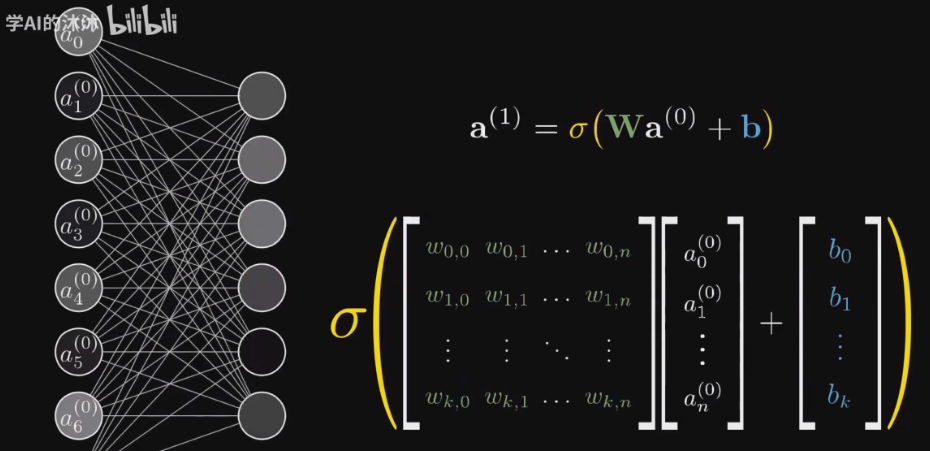

损失函数长什么样:
比如均方误差(MSE):
梯度下降法:
权重更像是表达上一层某些神经元对于下一层某个神经元的影响的强弱,偏置更像是表现该神经元被激活的难易程度
损失函数就是一个评价,评价当前模型的好坏,好坏是由人由场景决定的,你可以通过自己的需求,去修改损失函数,以实现你想象中的"好结果"
学习与训练的过程,实际上就是寻找到一组合适的参数,让我们的损失函数的值最小罢了
神经网络是一个函数,输入是784个像素,输出是10个数字的概率,参数是13002个参数
损失函数的输入是13002个参数,输出是代价,参数就是数据集
一、 梯度下降的核心公式
整个梯度下降法,全靠这一行极其优美的核心公式在循环运作:
让我们把这个公式拆解成"人话":
:当前位置。你现在站的地方(当前的权重值)。
二、 极简实战演练:一步步算给你看
为了让你看懂计算过程,我们设定一个最简单的任务:
假设我们的损失函数是一个简单的抛物线:
我们的目标是:找到一个
准备工作:
计算导数(求梯度公式):对
设定学习率:我们定步子大小
随机起点:假设机器刚开始瞎猜,瞎蒙了一个起始权重
开始下山(迭代计算):
第一步 (Iteration 1):
当前位置:
当前误差:
计算梯度:
套用公式更新:
结果:权重从 5 变成了 4,朝着谷底迈进了一大步。
第二步 (Iteration 2):
当前位置:
当前误差:
计算梯度:
套用公式更新:
结果:权重从 4 变成了 3.2。
第三步 (Iteration 3):
当前位置:
当前误差:
计算梯度:
套用公式更新:
...
三、 总结:从简单到复杂的飞跃
我们刚才演示的只有1个参数(一维空间)。
但在我们之前聊到的汉字识别,或者你之前接触的自动驾驶(CoIL 架构)中,神经网络可能有几千万个 权重参数
这个时候,梯度下降法的数学逻辑依然完全一样!只不过计算梯度时,用到的是偏导数 和链式法则(也就是传说中的"反向传播 Backpropagation")。机器会在同一个瞬间,算出这几千万个权重各自的"下坡方向",然后让几千万个开关同时咔哒一声,微调一点点角度,让整体的图像识别误差或自动驾驶误差变小一点。
反向传播:
下面我们以识别一个手写数字 "8" 为例,拆解这四个阶段的数学大循环:
第一阶段:前向传播(Forward Propagation)------ 瞎猜
一切的开始,源于一张 28x28 像素的手写"8"图片。
像素化(输入) :这张图在计算机眼里是一个
层层传递(加权求和) :这些像素值通过无数根连线(权重
最终输出:经过几层卷积或全连接层的计算(激活函数硬控),输出层会吐出 10 个数字。比如:
0: 0.1, 1: 0.05, ..., 8: 0.3, 9: 0.1 ...
网络心里想:"看这轮廓,大概有 30% 的可能是 8 吧。"
第二阶段:计算损失(Loss Calculation)------ 打脸
这个时候,老教练(专家)出场了。
标准答案 (Ground Truth) :人类专家给出的标答是一个 One-hot 向量:
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0](即:只有第 8 位是 1,其他全是 0)。算误差 (Loss):我们用一个损失函数(比如均方误差 MSE,虽然实际多用交叉熵,但 MSE 更直观)来算误差:
老教练狠狠拍了一下网络:"胡说!明明就是 100% 的 8,你才猜 30%?误差高达 0.6!"
第三阶段:反向传播(Backpropagation)------ 找责任人
这是最神奇的一步!教练不仅告诉你错了,还要精确地算出是哪个螺丝松了导致撞车的。
从后往前推 :老教练拿着 0.6 的误差,从输出层倒着往回走。
使用链式法则(数学修正刀) :教练会去计算每一个权重
教练会对输出层前的
教练会对隐藏层的
对偏置
结果 :网络中的几千万个
第四阶段:梯度下降(Gradient Descent)------ 拧螺丝
终于到了动手修正的时刻了!我们拿出之前聊到的核心公式:
设定学习率 (\\alpha) :我们设定迈步大小
全网更新:网络中的几千万个开关同时咔哒一声,根据刚才反向传播算出的梯度,执行减法:
输出层的
隐藏层的
偏置
🏁 终极循环:量变引起质变
拧完这一次螺丝,模型并没有变完美。
我们要做的,是把这个"瞎猜
随着训练的进行,网络内部的几千万个权重和偏置,就会慢慢脱离随机状态,形成一种极其精妙的平衡。当再次看到那张"8"时:
浅层卷积学成了找边缘。
深层全连接学成了拼圆圈。
输出层会自信地吐出:
8: 0.99。结论 :神经网络不是"懂"了什么是 8,而是通过反向传播和梯度下降,硬生生地把输入像素和输出答案之间的那条数学通道,给"拧"通了。
实际中参数是每用一张照片训练,就更新一次参数吗,还是把每一次参数变动记录下来,所有照片训练完之后,把参数变动求平均值,只更新一次?
1. 方案一:每用一张照片就更新一次
学术名称 :随机梯度下降 (SGD - Stochastic Gradient Descent)。
做法:看完一张图(比如数字"8"),立刻算梯度,立刻拧螺丝(更新参数)。
优缺点:
优点:非常快,模型立刻就能学到东西。
缺点 :极其不稳定。如果这一张照片刚好有噪点或者是张怪异的"8",模型会直接被带偏。就像一个没主见的司机,路边有个小石子就猛打方向盘,车开得歪歪扭扭。
2. 方案二:全部照片看完才更新一次
学术名称 :批量梯度下降 (Batch Gradient Descent)。
做法:把数据集里所有的照片(比如 6 万张)全部跑一遍,把每一张建议的"螺丝拧动方向"记录下来求平均值,最后只动一次手。
优缺点:
优点 :非常稳。算出来的梯度代表了全体数据的意志,方向极准。
缺点 :太慢了!对于现在的海量数据(比如自动驾驶的几百万帧图片),如果你跑一天才更新一次参数,猴年马月才能训好?而且对内存要求极高,显卡存不下这么多中间变量。
3. 工业界的"标准答案":分批更新
学术名称 :小批量随机梯度下降 (Mini-batch SGD)。
做法 :这是目前几乎所有深度学习(包括 CoIL)都在用的方法。我们把数据分成一小块一小块的,这一块叫做 Batch Size(常见大小是 32, 64, 128 或 256)。
比如 Batch Size = 64,机器先看 64 张图。
计算这 64 张图产生的平均梯度。
更新一次参数。
再看下一组 64 张图。
CV模型的常见架构:
一个标准的 CV (Computer Vision) 模型通常由以下三大类层级结构串联而成:
第一阶段:视觉感知与特征提取(Feature Extraction Block)
这一阶段主要负责处理立体的图像张量(例如
1. 卷积层 (Convolutional Layer - Conv)
硬件实体(长什么样) :卷积层并不是实体存在的"层",它的物理实体是一组可训练的滤波器(Filters / Kernels) 。这些滤波器通常是
计算机制 :滤波器以设定的步长(Stride)在输入图像上进行滑动窗口卷积运算(Dot Product)。
核心功能 :层级特征提取(Hierarchical Feature Extraction)。
浅层卷积核提取低层视觉特征(纹理、边缘)。
深层卷积核聚合低层特征,识别更高级的语义概念(车轮形状、车道线)。
输出 :多通道的特征图(Feature Maps)。
2. 池化层/下采样层 (Pooling/Downsampling Layer - Pool)
硬件实体:这是一种**无参数(Non-parametric)**的固定数学算子。不需要训练权重。
核心功能 :空间降维(Dimensionality Reduction)与平移不变性(Translation Invariance)。
例如
这能有效减少计算量,并让模型对物体在画面中的轻微抖动或偏移不敏感。
3. 激活层 (Activation Layer - Act)
注意 :激活函数(ReLU, LeakyReLU, ELU)通常在框架代码中被视为独立的层(如 PyTorch 的
nn.ReLU()),附着在 Conv 或 FC 层之后。硬件实体:逐元素(Element-wise)应用的非线性数学函数。
核心功能 :引入非线性(Non-linearity)。这打破了纯线性方程的叠加,使网络具有近似(Approximate)复杂决策边界的能力。Conv + Act 是标准的非线性特征提取单元。
第二阶段:信息转换与过渡(Transition Block)
4. 展平层 (Flatten Layer) 或 全局池化层 (Global Average Pooling - GAP)
核心功能 :从立体特征图到一维语义特征向量的转换。
Flatten :直接将
GAP(全局均值池化) :在每个通道 H' \\times W' 上求平均,输出一个长度为
Image comparison of flatten operation vs global average pooling
第三阶段:逻辑决策与控制输出(Decision Block)
这一阶段处理的是一维的隐含向量(Latent Vector)。
5. 全连接层/稠密层 (Fully Connected Layer - FC / Linear)
硬件实体 :一个巨大的、可训练的权重矩阵
计算机制 :输入向量
核心功能 :语义推理与高阶组合 。它将提取出的高级特征进行非线性组合,形成逻辑结论(例如:"Feature A 强烈 + Feature B 强烈
6. 输出层 (Output Layer / Head)
硬件实体:全连接层的最后一站。
核心功能 :将隐含的语义信息映射到物理动作空间(Actuation Space)。
如果是分类(Classification)任务 ,维度是类别数,最后通常接 Softmax 激活函数输出概率分布(如识别手写数字,输出 10 个类的概率)。
如果是回归(Regression)任务 ,维度通常很小(如 1 用于油门),最后通常接 Tanh 或 Sigmoid 限制输出范围。
CoIL 微调:在 CoIL 架构中,这一层会针对不同的高层指令(左转、直行、右转)分叉出不同的独立的 FC 输出头(Header)。