之前探索了归一化折损累积增益NDCG指标计算示例。
https://blog.csdn.net/liliang199/article/details/158691440
这里进一步分析Recall@K评估指标,所用示例参考和修改自网络资料。
1 Recall@K评估指标
1.1 定义与公式
Recall@K是信息检索和推荐系统中衡量排序列表头部(前K个结果)召回能力的指标。
其定义为:
其中,相关物品通常指用户真实感兴趣、与查询匹配或被标注为正例的物品。
对于单次查询或单个用户,Recall@K 是一个 0 到 1 之间的分数。
在多查询/多用户的场景下,通常计算平均 Recall@K(即Mean Recall@K)。
1.2 直观理解
用户只浏览前 K 个推荐结果,例如首页前 10 个商品,系统能召回用户感兴趣物品的比例。
在推荐系统中,用户注意力有限,系统必须将最相关的物品尽量排在前 K 位。
如果某个用户实际有 20 个感兴趣的商品,但系统只在前 10 位中展示了其中的 3 个,则 Recall@10 = 3/20 = 0.15,意味着大量相关物品未被曝光,系统召回能力不足。
与 Precision@K 的关系
1)Precision@K 衡量推得准不准,即前 K 个结果中相关物品的比例。
2)Recall@K 衡量找得全不全,相关物品中被推到前 K 个的比例。
3)两者通常呈 trade-off 关系,需要结合业务目标选择平衡点。
1.3 优缺点
1)优点
Recall@K直观易懂,直接反映相关物品的覆盖率,分母固定不受相关物品总数的影响。
适合评估"能否让用户看到足够多喜欢的内容",在 K 较小时能反映头部结果的覆盖能力。
2)缺点
Recall@K对排序位置不敏感,只要在 K 以内就同等计数。
若相关物品总数很大,Recall@K 可能永远较低,需结合业务上下文。
不考虑相关物品在 K 内的顺序,可能忽略用户体验(例如重要物品排在末尾)。
Recall@K本质上是一种覆盖性指标,不关心在K内具体顺序,不区分不同重要程度的相关物品。
单独使用Recall@K可能无法完全反映排序系统质量,需要与 NDCG或Precision@K联合分析。
1.4 应用场景
1)推荐系统
评估推荐列表是否覆盖了用户喜欢的物品,尤其是在长尾物品丰富的场景,如视频、电商。
2)搜索引擎
评估前几页结果是否包含了大部分相关文档。
3)广告系统
评估广告召回环节的覆盖程度。
4)评测报告
学术论文中,Recall@K常与Precisi非常 von@K、NDCG@K 一起作为评价排序质量的综合指标。
2 模拟计算Recall@K
2.1 场景说明
这里用Python模拟一个典型的推荐场景。
假设有 5 个用户,每个用户有
1)一组真正感兴趣的相关物品(ground truth),
2)模型预测的已排序的推荐列表。
计算每个用户的Recall@K(K=5, 10),计算平均值,并同时与Precision@K指标对比。
2.2 代码示例
1)数据生成
每个用户有 5~20 个相关物品。
构建预测列表时,将一半相关物品放在列表最前面模拟模型把部分相关物品排到头部,另一半相关物品与不相关物品混合在尾部,如此Recall@K会随着K增大而逐步提升,但不会太快达到 1。
2)计算函数
recall_at_k返回用户级召回率。
precision_at_k用于对比。
3)输出示例
对于 K=5,Mean Recall 通常较低,因为只有少量相关物品被排在前 5 位。
对于 K=10,Mean Recall 会升高,因为容纳了更多相关物品。
相关物品总数多的用户,因为分母大Recall@K可能偏低,这反映了指标对长尾用户的敏感性。
4)趋势分析
绘制Mean Recall@K随 K变化的曲线。
曲线直观展示随着推荐列表长度增加,召回率逐渐上升,但最终会趋近于 1。
考虑所有这些特征,代码示例如下。
import numpy as np
def recall_at_k(ground_truth, predicted, k):
"""
计算单用户的 Recall@K
ground_truth: set 或 list,该用户真实相关的物品 ID
predicted: list,模型预测的排序列表(从高到低)
k: 截断值
"""
if not ground_truth:
return 0.0 # 无相关物品时,召回率定义为0
predicted_at_k = set(predicted[:k])
relevant_in_top_k = len(predicted_at_k.intersection(ground_truth))
return relevant_in_top_k / len(ground_truth)
def precision_at_k(ground_truth, predicted, k):
"""
计算单用户的 Precision@K
"""
if k == 0:
return 0.0
predicted_at_k = set(predicted[:k])
relevant_in_top_k = len(predicted_at_k.intersection(ground_truth))
return relevant_in_top_k / k
# 模拟数据
np.random.seed(42)
# 假设有 5 个用户,总物品池大小 100
num_users = 5
num_items = 100
# 为每个用户随机生成 5~20 个相关物品
ground_truths = []
for u in range(num_users):
num_rel = np.random.randint(5, 21)
rel_items = set(np.random.choice(num_items, num_rel, replace=False))
ground_truths.append(rel_items)
# 模拟预测列表:对于每个用户,随机打乱所有物品,但让部分相关物品出现在前面(模拟一定的排序能力)
predicted_lists = []
for u in range(num_users):
# 将相关物品与不相关物品分开
rel = ground_truths[u]
non_rel = set(range(num_items)) - rel
# 构造预测列表:先放 50% 的相关物品(随机顺序),再放剩余相关物品 + 不相关物品(随机打乱)
# 这样模拟一个有一定排序能力但不完美的模型
rel_list = list(rel)
np.random.shuffle(rel_list)
split = int(0.5 * len(rel_list))
top_rel = rel_list[:split] # 排在前面的相关物品
remaining = rel_list[split:] + list(non_rel)
np.random.shuffle(remaining)
pred_list = top_rel + remaining
predicted_lists.append(pred_list)
# 评估 Recall@K 和 Precision@K
Ks = [5, 10]
for k in Ks:
recalls = []
precisions = []
for u in range(num_users):
r = recall_at_k(ground_truths[u], predicted_lists[u], k)
p = precision_at_k(ground_truths[u], predicted_lists[u], k)
recalls.append(r)
precisions.append(p)
mean_recall = np.mean(recalls)
mean_precision = np.mean(precisions)
print(f"K={k}: Mean Recall={mean_recall:.4f}, Mean Precision={mean_precision:.4f}")
# 打印每个用户的详细结果
for u in range(num_users):
print(f" User {u}: Recall={recalls[u]:.3f}, Precision={precisions[u]:.3f}, "
f"#relevant={len(ground_truths[u])}")
# 额外演示:当 K 变化时 Recall 的变化趋势
K_range = range(1, 31)
mean_recalls = []
for k in K_range:
r_vals = [recall_at_k(ground_truths[u], predicted_lists[u], k) for u in range(num_users)]
mean_recalls.append(np.mean(r_vals))
# 绘制趋势图(可选)
import matplotlib.pyplot as plt
plt.plot(K_range, mean_recalls, marker='o')
plt.xlabel('K')
plt.ylabel('Mean Recall@K')
plt.title('Recall@K vs. K')
plt.grid(True)
plt.show()2.3 运行结果
运行结果如下所示
K=5: Mean Recall=0.4423, Mean Precision=0.8400
User 0: Recall=0.455, Precision=1.000, #relevant=11
User 1: Recall=0.571, Precision=0.800, #relevant=7
User 2: Recall=0.444, Precision=0.800, #relevant=9
User 3: Recall=0.312, Precision=1.000, #relevant=16
User 4: Recall=0.429, Precision=0.600, #relevant=7
K=10: Mean Recall=0.4798, Mean Precision=0.4800
User 0: Recall=0.455, Precision=0.500, #relevant=11
User 1: Recall=0.571, Precision=0.400, #relevant=7
User 2: Recall=0.444, Precision=0.400, #relevant=9
User 3: Recall=0.500, Precision=0.800, #relevant=16
User 4: Recall=0.429, Precision=0.300, #relevant=7
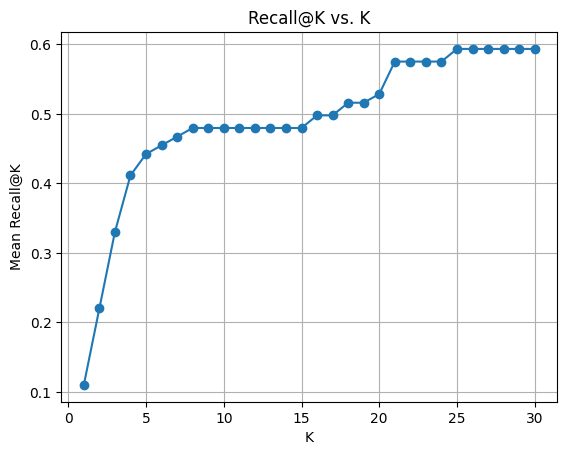
1)Recall@K 受相关物品总数影响大
用户 4 有 23 个相关物品,即使前 10 个里有 4 个相关,Recall@10 也只有 0.173;而用户 2 有 10 个相关物品,前 10 个里如果有 2 个相关,Recall@10 为 0.2。因此,在对比不同用户时,需要结合具体业务理解。
2)与 Precision@K 对比
本例中 Precision@5 和 Precision@10 均为 0.12~0.12,说明无论 K 大小,预测列表头部精确率稳定;但 Recall 随 K 增加而增加,因为更多相关物品被包含进来。这体现了两个指标的不同维度。
3)局限性
假设两个用户都有 10 个相关物品,用户 A 的预测列表前 10 个包含 5 个相关,但都排在 6~10 位;用户 B 的前 10 个包含 5 个相关,但都排在 1~5 位。二者的 Recall@10 都是 0.5,但显然 B 的体验更好。Recall@K 无法区分这种差异,需要结合 NDCG 或 MAP 来评估排序质量。
通过上述模拟,可以更深刻地理解Recall@K的计算过程、行为特征及其在排序评估中的角色。
reference
归一化折损累积增益NDCG指标计算示例
https://blog.csdn.net/liliang199/article/details/158691440
Evaluation Measures in Information Retrieval
https://www.pinecone.io/learn/offline-evaluation/?utm_content=213055046
Evaluation Metrics for Search and Recommendation Systems
https://weaviate.io/blog/retrieval-evaluation-metrics?=undefined&utm_source=startuptile.com
Top-N Recommendation Algorithms: A Quest for the State-of-the-Art
https://arxiv.org/abs/2203.01155
Factorization meets the neighborhood: a multifaceted collaborative filtering model.
https://people.engr.tamu.edu/huangrh/Spring16/papers_course/matrix_factorization.pdf
Evaluation Metrics for Item Recommendation under Sampling