温馨提示:为了帮读者轻松理解,文中用了很多不正经的比喻。这些只是帮助想象的脚手架,并非真实的技术细节。请以官方论文和公式为准。
Transformer架构的核心是「注意力机制」。它解决了传统RNN "记不住和算得慢"的痛点,让模型真正读懂文本逻辑。可以说,它是所有大语言模型的开山鼻祖。
注意力机制在干什么?
举个例子:
"The animal didn't cross the street because it was too tired."
我们要理解这句话中 it 指的是什么? 直觉告诉你,it 是指 the animal 而不是 the street 。因为"太累了"只能形容动物,不能形容街道。对人来说这是常识,但对机器来说,它需要一种能力:把 it 和 animal 连起来,而不是和 street 连起来。注意力机制做的事,就是让模型自己学习出这种语义依赖
一、痛点
Transformer出场前,RNN 、LSTM是处理文本的主力。但俩硬伤太要命:
- 记不住远距离关系------像背书背到后面忘了开头,句子前后根本连不上。
- 只能串行计算------GPU的并行能力使不上劲,处理长文本慢得像蜗牛爬。
注意力机制一出手,直接一锅端:它不仅能记住遥远的信息,还能一口气把所有词同时计算,又快又准。
二、核心概念:Q、K、V
注意力机制的核心,全靠三个"打工人"协同干活:
- Query(查询) :每个词派出去的 "调查员",专门问:"我该
关注谁?" - Key(键) :每个词挂着的 "身份牌",告诉别人:"我有哪些
标签 - Value(值) :每个词藏着的"干货",是别人关注你时要拿走的
实际内容。
关键 :Q,K,V并不是凭空产生的,就像公司里没有天生的打工人------都是学着学着就上岗了 。
它们由输入矩阵 X 分别乘以三个可学习的矩阵 W Q 、 W K 、 W V 得到。 这些矩阵在训练中不断调整,直到三个打工人越来越老实听话 🤬。 \begin{array}{l} \text{ 它们由输入矩阵 } X \text{ 分别乘以三个可学习的矩阵 } W^Q、W^K、W^V \text{ 得到。} \\ \text{这些矩阵在训练中不断调整,直到三个打工人越来越老实听话 🤬。} \end{array} 它们由输入矩阵 X 分别乘以三个可学习的矩阵 WQ、WK、WV 得到。这些矩阵在训练中不断调整,直到三个打工人越来越老实听话 🤬。
下面,我们就用一个小例子,一步步揭开它们的神秘面纱。
官方核心流程图 The Transformer- model architecture:
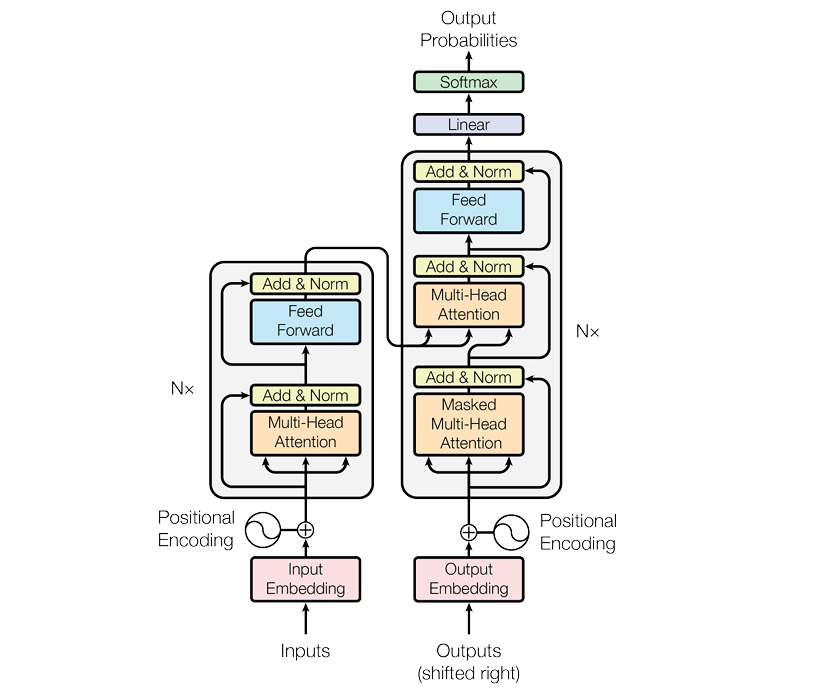
2.1 Embedding嵌入
机器不认识英语单词,只认识0和1,将单词转换成数字的过程就是Embedding嵌入。
为了好理解,我们用简化模拟方式(非官方真实逻辑,仅作演示):26个英文字母对应1-26(a=1、b=2...z=26),每个单词统一转成5维向量,不够维度就补0。
以句子"Tom loves apple"为例,拆成3个token(独立词元),转换后的向量及输入矩阵X如下:
-
Tom:T(20)、o(15)、m(13) → 20, 15, 13, 0, 0
-
loves:l(12)、o(15)、v(22)、e(5) → 12, 15, 22, 5, 0
-
apple:a(1)、p(16)、p(16)、l(12)、e(5) → 1, 16, 16, 12, 5
输入矩阵X(3行5列,3个词,每个词5维):
X = 20 15 13 0 0 12 15 22 5 0 1 16 16 12 5 X = \begin{bmatrix}20 & 15 & 13 & 0 & 0 \\12 & 15 & 22 & 5 & 0 \\1 & 16 & 16 & 12 & 5\end{bmatrix} X= 201211515161322160512005
2.2 Q、K、V
核心逻辑(划重点):Q、K、V不是固定数值,而是输入矩阵X分别乘以3个可学习线性矩阵(W^Q 、W^K、 W^V)得到的,公式如下:
Q = X ⋅ W Q , K = X ⋅ W K , V = X ⋅ W V Q = X \cdot W^Q,\quad K = X \cdot W^K,\quad V = X \cdot W^V Q=X⋅WQ,K=X⋅WK,V=X⋅WV
其中,W^Q 、W^K 、W^V均为5×5矩阵(非真实训练所得,仅为演示分工差异):
W Q = 1 1 1 1 1 1 2 1 2 1 3 2 1 2 3 1 2 1 2 1 1 1 1 1 1 , W K = 2 3 2 3 2 3 1 3 1 3 1 2 3 2 1 3 1 3 1 3 2 3 2 3 2 , W V = 3 2 3 2 3 2 4 2 4 2 4 3 2 3 4 2 4 2 4 2 3 2 3 2 3 W^Q = \begin{bmatrix}1 & 1 & 1 & 1 & 1 \\1 & 2 & 1 & 2 & 1 \\3 & 2 & 1 & 2 & 3 \\1 & 2 & 1 & 2 & 1 \\1 & 1 & 1 & 1 & 1\end{bmatrix},\quad W^K = \begin{bmatrix}2 & 3 & 2 & 3 & 2 \\3 & 1 & 3 & 1 & 3 \\1 & 2 & 3 & 2 & 1 \\3 & 1 & 3 & 1 & 3 \\2 & 3 & 2 & 3 & 2\end{bmatrix},\quad W^V = \begin{bmatrix}3 & 2 & 3 & 2 & 3 \\2 & 4 & 2 & 4 & 2 \\4 & 3 & 2 & 3 & 4 \\2 & 4 & 2 & 4 & 2 \\3 & 2 & 3 & 2 & 3\end{bmatrix} WQ= 1131112221111111222111311 ,WK= 2313231213233323121323132 ,WV= 3242324342322232434232423
下面分别计算Q、K、V矩阵(结果保留1位小数):
-
Q(查询) :
由 X ∗ W Q 得到,相当于每个词的需求查询员,负责主动找关联。 由X * W^Q 得到,相当于每个词的需求查询员,负责主动找关联。 由X∗WQ得到,相当于每个词的需求查询员,负责主动找关联。Q = X ⋅ W Q = 86.0 82.0 74.0 82.0 86.0 113.0 107.0 95.0 107.0 113.0 98.0 94.0 82.0 94.0 98.0 Q = X \cdot W^Q = \begin{bmatrix}86.0 & 82.0 & 74.0 & 82.0 & 86.0 \\113.0 & 107.0 & 95.0 & 107.0 & 113.0 \\98.0 & 94.0 & 82.0 & 94.0 & 98.0\end{bmatrix} Q=X⋅WQ= 86.0113.098.082.0107.094.074.095.082.082.0107.094.086.0113.098.0
-
K(键) :
由 X × W K 得到,相当于每个词的身份标签员,负责回应 Q 的查询。 由X×W^K得到,相当于每个词的身份标签员,负责回应Q的查询。 由X×WK得到,相当于每个词的身份标签员,负责回应Q的查询。K = X ⋅ W K = 95.0 91.0 95.0 91.0 95.0 127.0 119.0 127.0 119.0 127.0 109.0 101.0 109.0 101.0 109.0 K = X \cdot W^K = \begin{bmatrix}95.0 & 91.0 & 95.0 & 91.0 & 95.0 \\127.0 & 119.0 & 127.0 & 119.0 & 127.0 \\109.0 & 101.0 & 109.0 & 101.0 & 109.0\end{bmatrix} K=X⋅WK= 95.0127.0109.091.0119.0101.095.0127.0109.091.0119.0101.095.0127.0109.0
-
V(值) :
由 X × W V 得到,相当于每个词的核心内容员,是 Q 匹配到 K 后要提取的关键信息。 由X×W^V得到,相当于每个词的核心内容员,是Q匹配到K后要提取的关键信息。 由X×WV得到,相当于每个词的核心内容员,是Q匹配到K后要提取的关键信息。V = X ⋅ W V = 114.0 116.0 114.0 116.0 114.0 151.0 155.0 151.0 155.0 151.0 131.0 135.0 131.0 135.0 131.0 V = X \cdot W^V = \begin{bmatrix}114.0 & 116.0 & 114.0 & 116.0 & 114.0 \\151.0 & 155.0 & 151.0 & 155.0 & 151.0 \\131.0 & 135.0 & 131.0 & 135.0 & 131.0\end{bmatrix} V=X⋅WV= 114.0151.0131.0116.0155.0135.0114.0151.0131.0116.0155.0135.0114.0151.0131.0
注:真实场景中,W^Q、 W^K、 W^V是模型通过大量数据训练"学"来的矩阵,绝非我们手动设计的固定数值。此处设计差异化矩阵,只是为了让你看到:不同的矩阵会带出不一样的Q、K、V,更真实地体现三者的分工差异。
2.3 核心公式:缩放点积注意力
Transformer用的是"缩放点积注意力",核心公式就1个:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{Softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=Softmax(dk QKT)V
用人话说就是:
- 调查员(Q)和身份牌(K)握个手,算出每对词的"亲密分"。
- 把分数"降降温"(除以 √dk),防止数值太大。
- 用Softmax把分数变成"关注比例"(每个词分到的注意力百分比)。
- 按这个比例从干货(V)里提取信息,每个词都拿到一份融合了上下文的新表示。
三、实操计算
结合上面由输入X生成、且差异化明显的Q、K、V,一步步计算
步骤1:计算Q×Kᵀ------获取词与词的匹配度
先把K转置(行变列),K是3行5列,转置后Kᵀ是5行3列:
K T = 95.0 127.0 109.0 91.0 119.0 101.0 95.0 127.0 109.0 91.0 119.0 101.0 95.0 127.0 109.0 K^T = \begin{bmatrix}95.0 & 127.0 & 109.0 \\91.0 & 119.0 & 101.0 \\95.0 & 127.0 & 109.0 \\91.0 & 119.0 & 101.0 \\95.0 & 127.0 & 109.0\end{bmatrix} KT= 95.091.095.091.095.0127.0119.0127.0119.0127.0109.0101.0109.0101.0109.0
再计算Q与Kᵀ的点积,得到匹配度矩阵S(保留1位小数):
S = Q K T = 40788.0 54014.0 45942.0 54134.0 71726.0 61118.0 45358.0 60062.0 51330.0 S = QK^T = \begin{bmatrix}40788.0 & 54014.0 & 45942.0 \\54134.0 & 71726.0 & 61118.0 \\45358.0 & 60062.0 & 51330.0\end{bmatrix} S=QKT= 40788.054134.045358.054014.071726.060062.045942.061118.051330.0
解读:匹配度矩阵三行分别代表三个单词,每一列表示当前词和其他三个词的相似度分数:
-
Tom loves apple
-
Tom: 40788.0,54014.0,45942.0
-
loves:54134.0,71726.0,61118.0
-
apple:45358.0,60062.0,51330.0
数值越大,说明两个词的关联越紧密------比如loves(第2行)和自身(第2列)的匹配度71726.0最高,符合它作为句子核心动词的逻辑。
步骤2:除以√d_k------缩放匹配度
d_k = 5(向量的维度):√5 ≈ 2.236,把S中每个元素除以2.236(数值小了很多,防止后面爆炸):
S scaled ≈ 18241.5 24156.5 20546.5 24209.3 32077.8 27333.6 20285.3 26852.4 22956.2 S_{\text{scaled}} \approx \begin{bmatrix}18241.5 & 24156.5 & 20546.5 \\24209.3 & 32077.8 & 27333.6 \\20285.3 & 26852.4 & 22956.2\end{bmatrix} Sscaled≈ 18241.524209.320285.324156.532077.826852.420546.527333.622956.2
步骤3:Softmax归一化
Softmax的作用很简单:把每一行的匹配度变成概率(总和为1),保留2位小数:
A ≈ 0.24 0.51 0.25 0.23 0.54 0.23 0.24 0.52 0.24 A \approx \begin{bmatrix}0.24 & 0.51 & 0.25 \\0.23 & 0.54 & 0.23 \\0.24 & 0.52 & 0.24\end{bmatrix} A≈ 0.240.230.240.510.540.520.250.230.24
- 第一行(Tom):它把51%的注意力放在loves上,剩下24%和25%给自己和apple,完美匹配"Tom loves apple"的逻辑。
- 第二行(loves):给自己54%的注意力,因为它是句子的中心。
步骤4:权重 × V------提取融合信息
用 A去乘V,得到最终输出(保留1位小数):
Output = A ⋅ V ≈ 131.8 134.3 131.8 134.3 131.8 138.4 141.2 138.4 141.2 138.4 133.5 136.1 133.5 136.1 133.5 \text{Output} = A \cdot V \approx \begin{bmatrix}131.8 & 134.3 & 131.8 & 134.3 & 131.8 \\138.4 & 141.2 & 138.4 & 141.2 & 138.4 \\133.5 & 136.1 & 133.5 & 136.1 & 133.5\end{bmatrix} Output=A⋅V≈ 131.8138.4133.5134.3141.2136.1131.8138.4133.5134.3141.2136.1131.8138.4133.5
解读:每个词的输出都是整句话信息的加权组合:
-
Tom的输出 = 24% Tom的V向量 + 51% loves的V向量 + 25% apple的V向量
-
loves的输出 = 23% Tom的V向量 + 54% loves的V向量 + 23% apple的V向量
-
apple的输出 = 24% Tom的V向量 + 52% loves的V向量 + 24% apple的V向量
这个结果完美体现了注意力机制的加权融合逻辑:每个词的输出都融合了整句话的信息,不再是孤立的词向量,而且因为Q、K、V的差异化设计,每个词的关注比例和输出结果都有明显区别,更贴近真实场景。
四、多头注意力机制
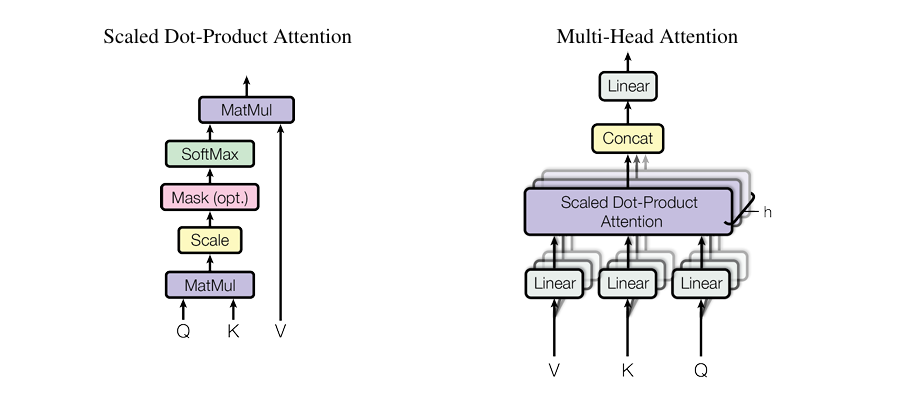
官方版核心公式 :
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , ... , head h ) W O head i = Attention ( Q W i Q , K W i K , V W i V ) \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \dots, \text{head}_h) W^O \\ \text{head}_i = \text{Attention}(Q W_i^Q, K W_i^K, V W_i^V) MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WOheadi=Attention(QWiQ,KWiK,VWiV)
补充说明:
① h表示注意力头的数量(如BERT的12头、GPT-3的96头);
② WQ、WK、W^V是第i个头的可学习线性矩阵(由模型训练得到);
③ W^O是最终的可学习线性映射矩阵,用于融合所有头的输出;
④ Attention仍为前文提到的缩放点积注意力,公式不变。
单头注意力 :就像只用一只眼看世界,只能看到一个角度。
多头注意力 :相当于给模型装了很多只眼睛------每只眼睛有自己的 WQ、WK、W^V,独立计算注意力,最后把结果拼在一起。
你可以这样理解每个 "头" 的职责:
- 头1(H1) :专门盯着主谓宾结构,看哪个词是主语、哪个是谓语。
- 头2(H2) :专门盯着褒贬色彩,判断这个词是夸还是骂。
- 头3(H3) :专门盯着时态,看看动词发生在过去、现在还是未来。
- 头4(H4) :专门盯着指代关系,搞清楚"它"到底指谁。
......每个头都有自己的"特长",大家一起分析,模型就能从多个层面理解一句话。这也是大模型能精准理解复杂文本的原因------头越多,看到的维度越丰富,理解越透彻。
五、三种常见变体
根据任务不同,注意力机制衍生出3种核心变体,分工明确、很好区分,而且都围绕输入向量展开,保留Q、K、V的差异化分工:
-
自注意力:Q、K、V都来自同一段输入X,Q查内部关联、K匹配关联标签、V提关联核心,适合文本理解,比如BERT用它读懂句子内部的关系
-
掩码自注意力:在自注意力上加了个"挡板",不让模型偷看未来的词。适合文本生成,比如GPT生成句子时,只能看到已经写好的部分。
-
交叉注意力:Q来自一个输入(比如翻译时的目标语言),K、V来自另一个输入(比如源语言)。适合跨序列任务,比如机器翻译、图文生成。
六、总结
核心逻辑一句话搞定:让每个词通过Q、K、V的分工协作,找到和自己最相关的词,按重要程度提取信息,最终读懂上下文,支撑模型完成理解、生成等任务。
流程:输入X(词嵌入向量)→ 分别乘以3个差异化可学习矩阵 → 得到Q、K、V→ 算匹配度、缩放、归一化 → 按比例提取V的核心内容 → 输出融合了上下文的新表示
再次提醒:文中用到的 W^Q 、W^K 、W^V是我们手动模拟出来的,只是为了演示。真实场景中,这些学习矩阵是模型自己从海量数据里学出来的,会根据任务自动调整。
Transformer的注意力机制中,Q与K的点积是一次内心选择------于信息洪流中,将有限精力投向真正值得回应的存在。Softmax是对生命有限性的坦然承认:无法关注一切,便学会放大重要的,弱化次要的。最终的加权求和,是将过往温柔地、按需地汇聚成当下的答案。算法教会我们:专注是一种能力,筛选是一种智慧,而真正的洞见,从来都源于对世界有选择的凝视。