一、指标体系搭建
OSM 是一套目标 - 策略 - 度量的结构化思考框架,常和 AARRR 模型结合,用来搭建完整的业务指标体系。

1、1 OSM框架
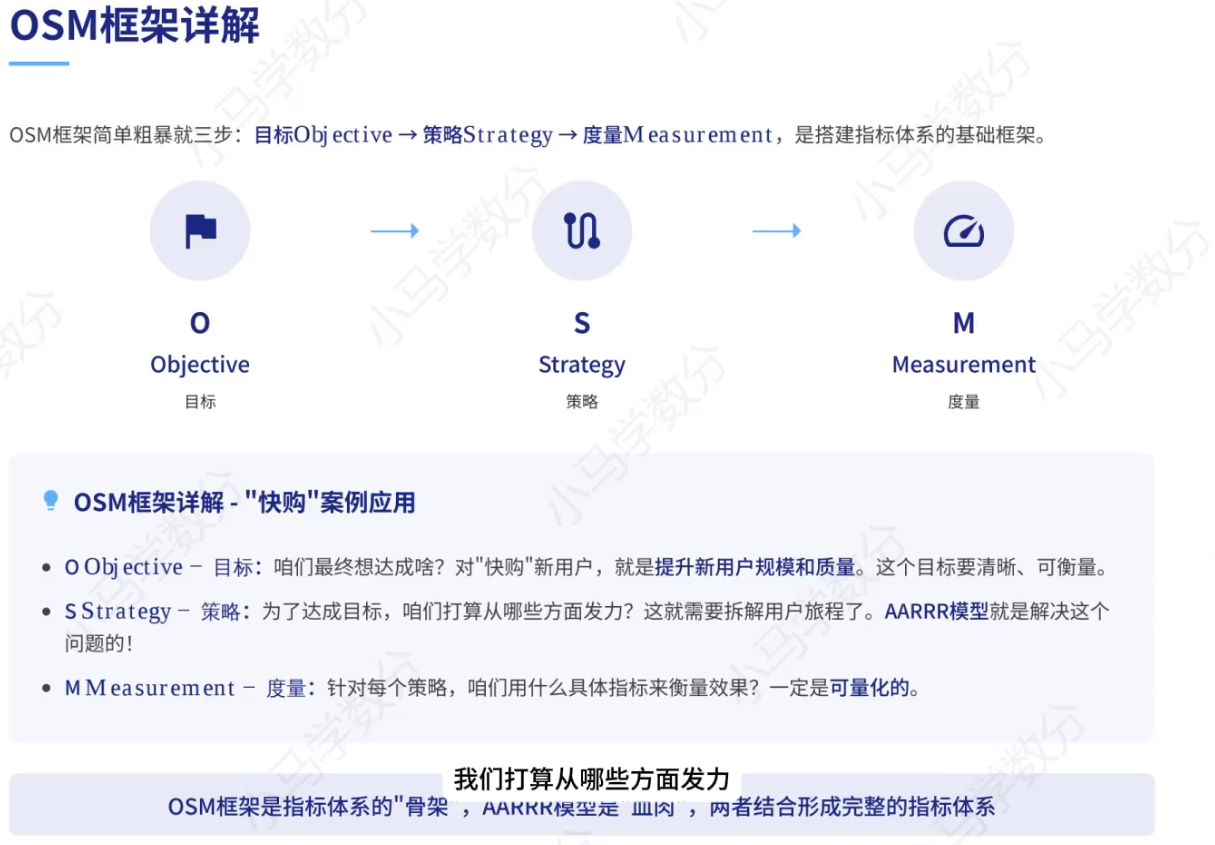
1、o 目标
要明白我们最终要达成的、清晰可衡量的业务结果
2、s 策略
为了达成目标,拆解用户旅程后制定的行动方向
典型结合:用 AARRR 海盗模型 (漏斗模型)拆解用户全生命周期,作为策略落地的路径:
AARRR 模型
Acquisition(获取) :怎么让更多人知道并注册?
Activation(激活):怎么让新用户快速体验核心价值?

Retention(留存):怎么让用户持续回来使用?

Revenue(变现):怎么让用户开始付费转化?

Referral(推荐):怎么让用户主动分享拉新?

3、m 度量

1、2 术语
1、GMV、DAU
GMV = 流量 * 转化率/成交率 * 客单价 = DAU * CVR * 客单价(在一定周期内所有的订单的标价总额---卖了多少,卖的好不好)
DAU (一天内登陆或使用产品的去重用户数---当天有多少活人用户)
2、次日留存率
当日新增用户中,在次日再次打开 / 使用产品的用户占比。
3、新用户生命周期 LTV
一个新用户从注册到流失的整个生命周期内,为企业创造的累计总收入(或利润)
一个新用户从注册到流失,预计能给"快购"带来多少总收入?
4、K因子
每个活跃用户平均能带来的新用户数量 ,反映产品的自传播能力
二、异动分析

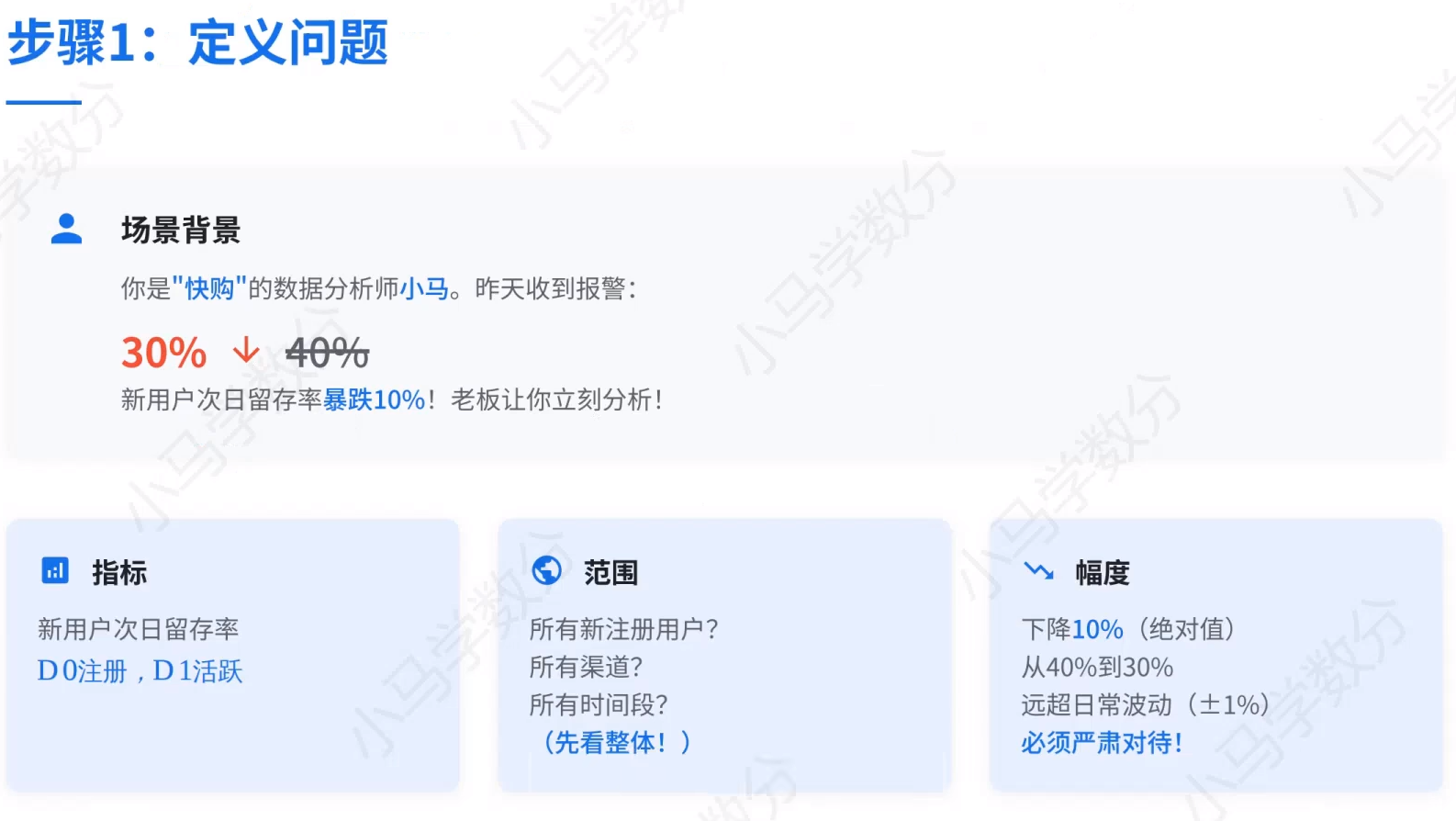
1、定义问题
2、数据验证

3、维度拆解
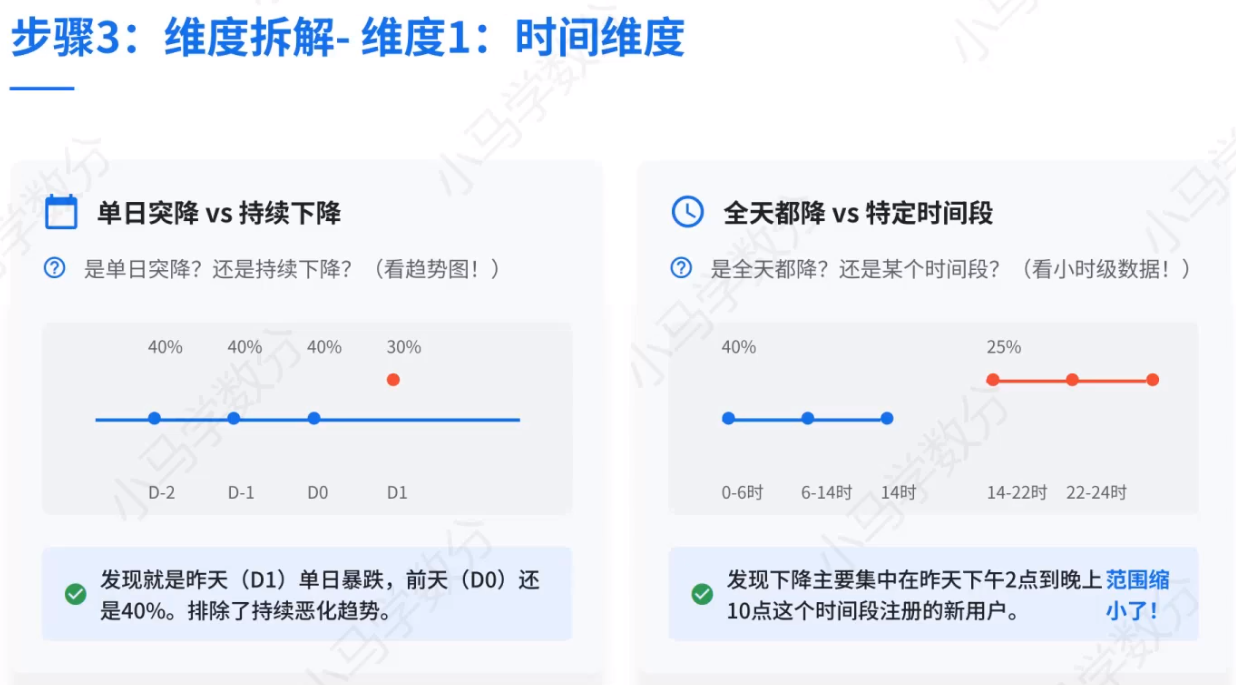
3、1 时间维度
3、2 用户维度

3、3 行为维度

4、原因假设
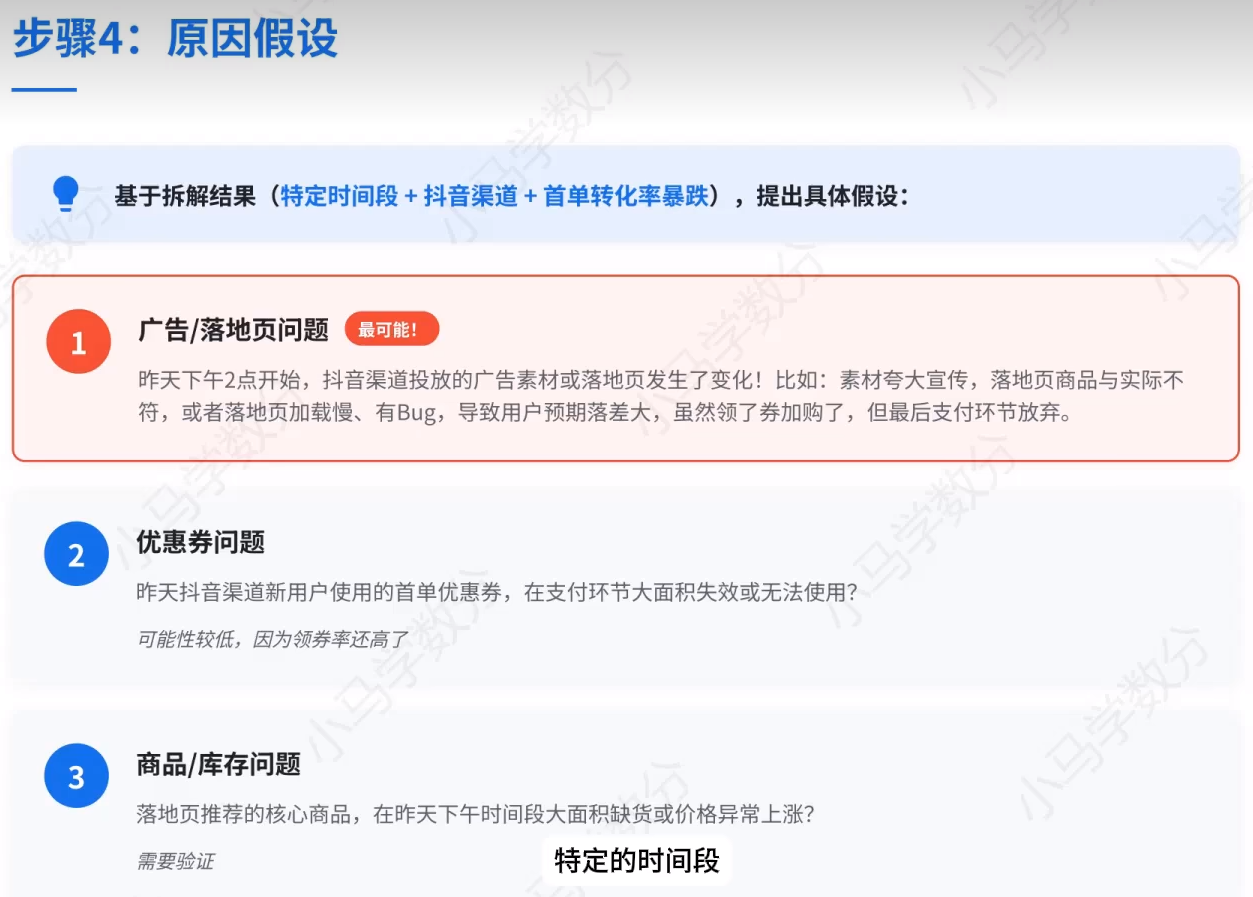
5、数据验证

6、根因定位

补充:
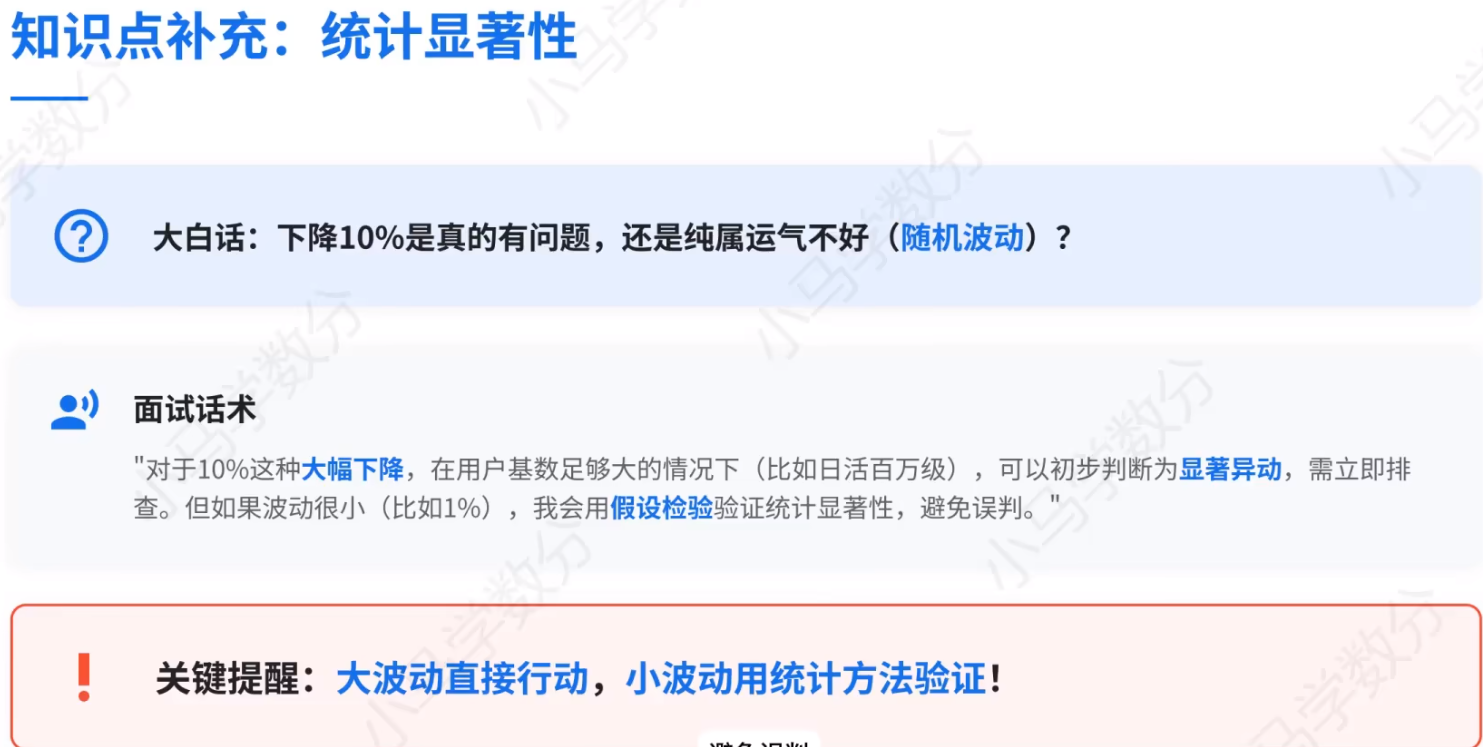
1、统计显著性
核心含义 :判断样本中观察到的差异 / 效应,是真实存在 ,还是仅由随机波动 / 抽样误差导致的统计方法。
- 判断逻辑 :通过假设检验(如 t 检验、卡方检验)计算 p 值 :
- 若 p < 显著性水平(通常 0.05):拒绝 "无差异" 的原假设,认为差异具有统计显著性,即差异大概率不是偶然。
- 若 p ≥ 0.05:无法拒绝原假设,认为差异可能由随机因素导致,不具备统计显著性。
- 业务意义:在 A/B 测试、用户行为分析中,避免把 "偶然波动" 误判为 "策略有效",保证决策的可靠性。
2、对比分析

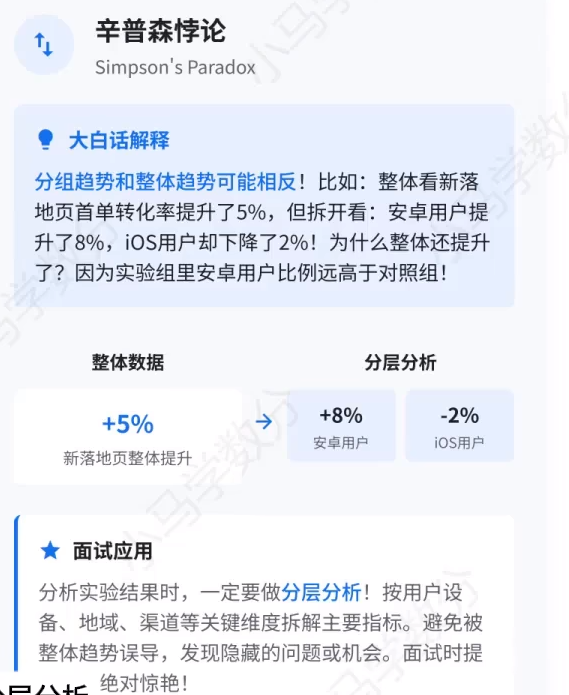
3、辛普森悖论
核心含义 :在分组数据中呈现的趋势,在合并数据后会完全反转的统计现象。
- 典型场景 :
- 分组时:A 组的某项指标(如转化率、成功率)优于 B 组;
- 合并后:整体数据却显示 B 组优于 A 组。
- 成因 :混杂变量(Confounding Variable) 的存在,不同组的样本构成 / 权重差异极大,掩盖了真实的分组趋势。
- 经典例子 :
- 某医院两种治疗方案:
- 分组看:轻症患者中,方案 A 治愈率 > 方案 B;重症患者中,方案 A 治愈率 > 方案 B。
- 合并看:方案 B 整体治愈率 > 方案 A。
- 原因:方案 A 多用于重症患者(样本占比高、基础治愈率低),方案 B 多用于轻症患者(样本占比高、基础治愈率高),导致整体数据被样本结构误导。
- 某医院两种治疗方案:
- 业务警示 :分析数据时必须关注分组结构和样本分布,避免被汇总数据误导,要拆解到合理的细分维度(如用户分层、渠道、场景)再下结论。

两者在数据分析中的关联
- 统计显著性:帮你判断 "差异是不是真的";
- 辛普森悖论:提醒你 "差异的方向可能被数据结构误导"。两者结合,才能避免数据分析中的常见陷阱,得出更可靠的业务结论。
三、AB实验入门

随机分流
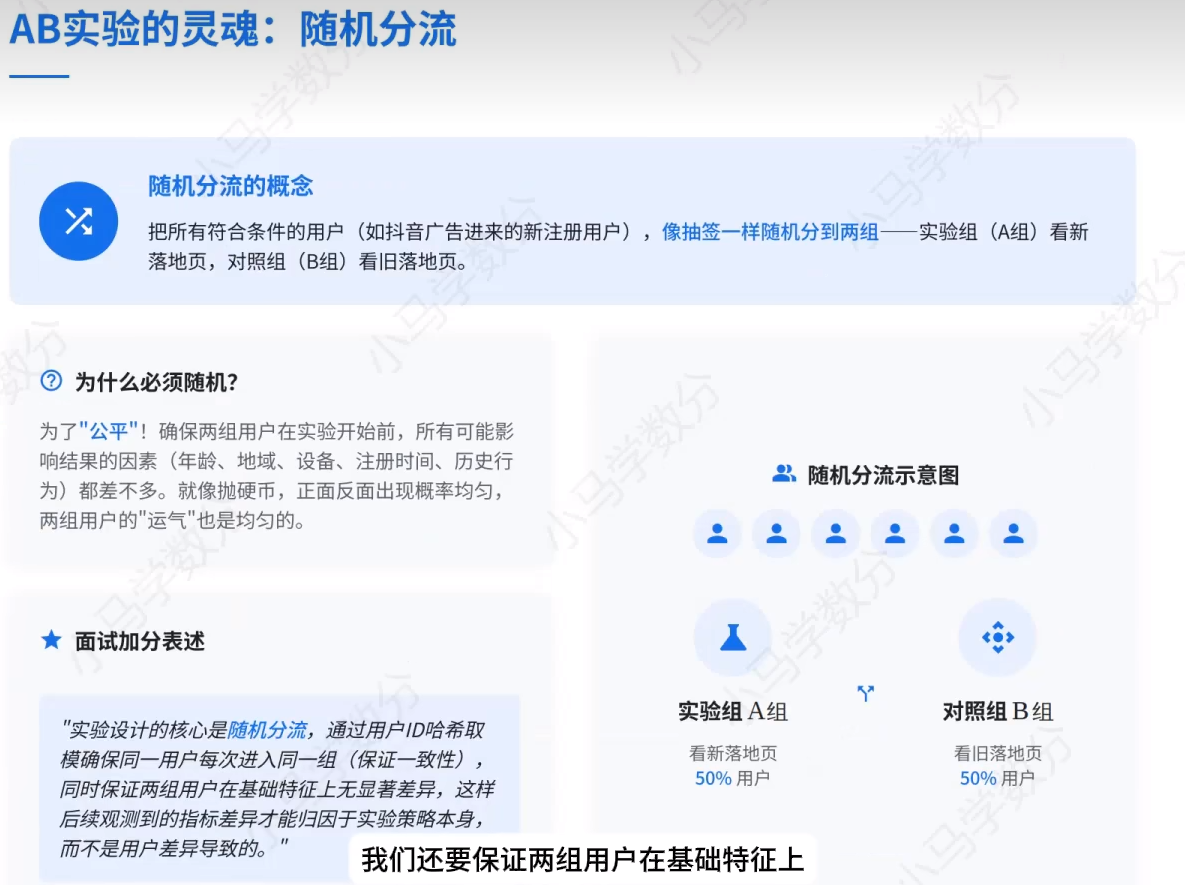
AB实验关键要素



实验方案概述
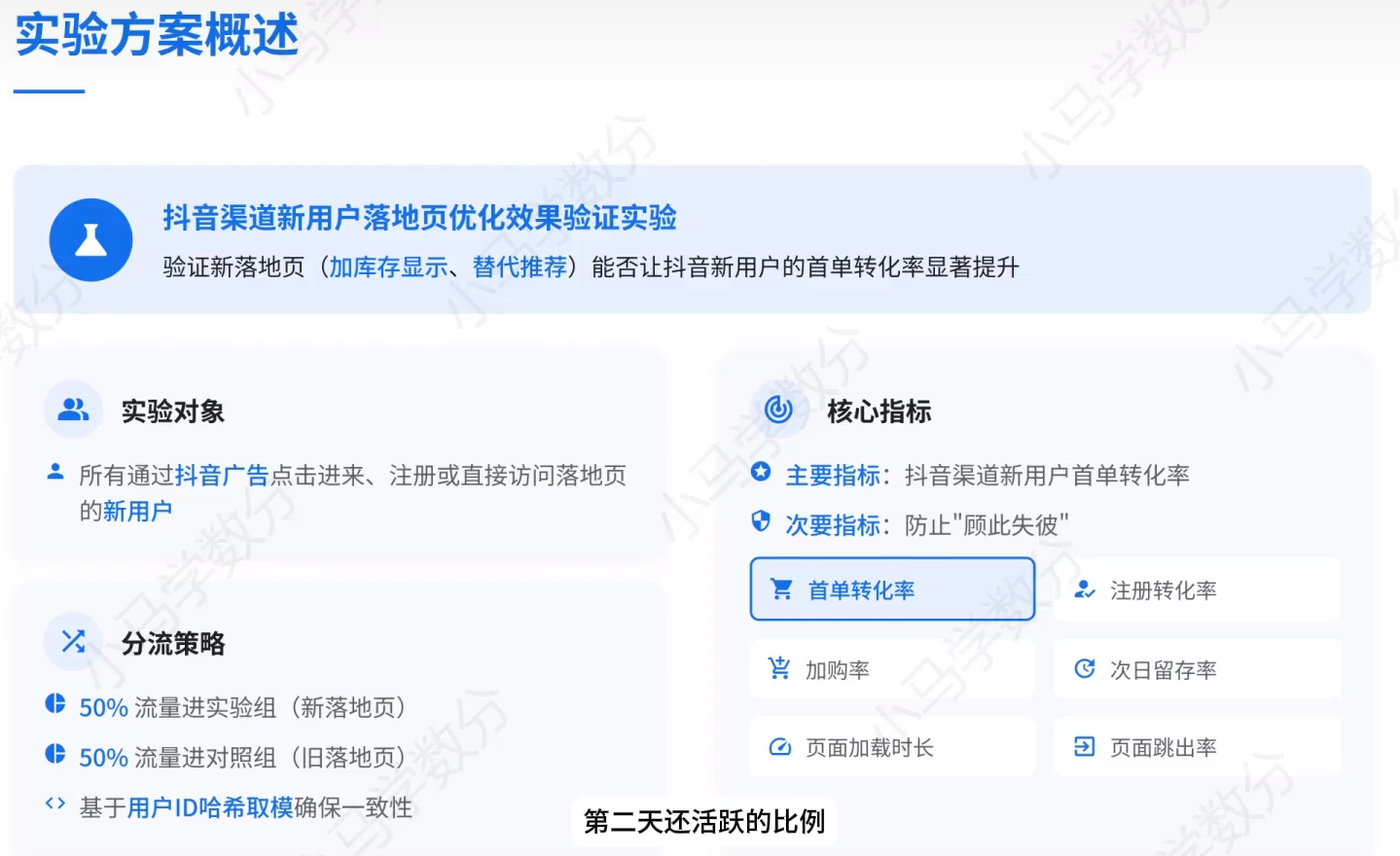
实验方案细节
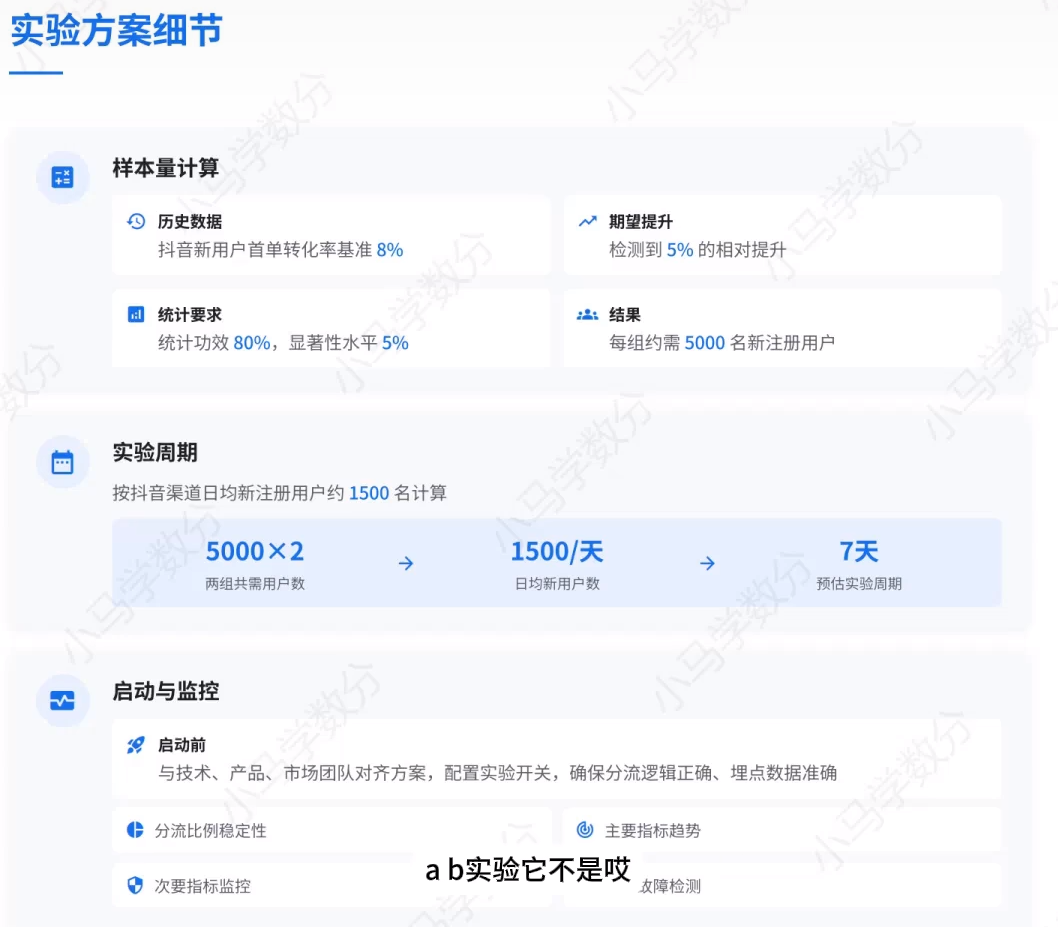
补充
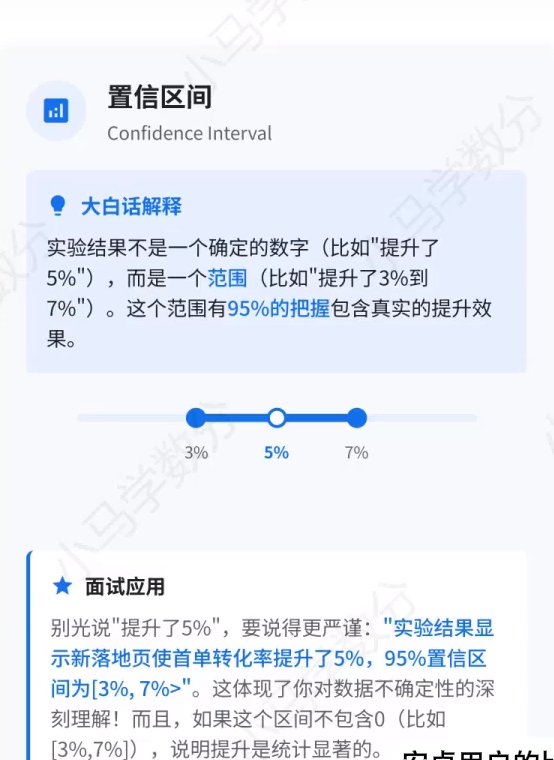
1、置信区间
置信区间不是给出一个 "精确结果",而是一个包含真实效应的范围,并附带置信水平(最常用的是 95%)。
- 例:实验结果显示 "转化率提升了 5%,95% 置信区间为 3%, 7%"
- 含义:我们有 95% 的把握认为,真实的提升幅度在 3% 到 7% 之间,5% 只是样本观测到的点估计值。
- 意义:体现了数据的不确定性,避免把样本结果当成绝对真理。
- 关键判断规则
- 区间不包含 0(如 3%,7%):说明结果在统计上是显著的,即这次提升大概率不是随机波动导致的。
- 区间包含 0(如 -2%, 8%):说明结果不具备统计显著性,无法确定真实效应是正向还是负向,实验结论不