1 Numpy
1.1 Numpy介绍
numpy是Python中科学计算的基础包。
它是一个Python库,提供多维数组对象、各种派生对象(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种方法,包括数学、逻辑、形状操作、排序、选择、1O、离散傅里叶变换、基本线性代数、基本统讠运算、随机模拟等等。
numpy的部分功能如下:
- ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅里叶变换功能。
- 用于集成由C、C++、Fortran等语言编写的代码的API。
- .......
numpy是所有数据分析库的基石,核心在于ndarray(N维数组对象)。
1.2 ndarray
(1) ndarray的核心概念
核心概念:
**ndarray:**同类型数据的集合,支持向量化运算(比Python原生列表快得多).
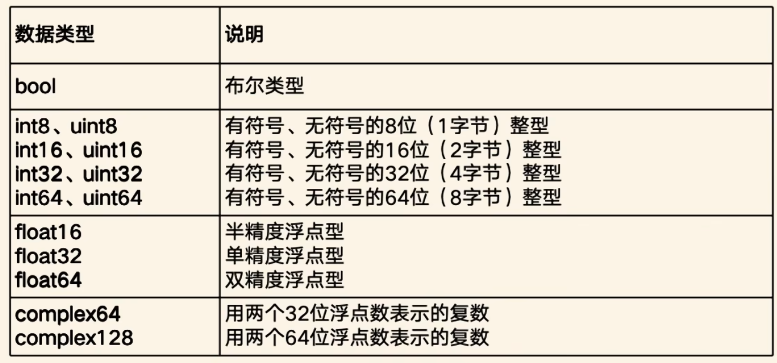
**数据类型(dtype):**int、float、bool等
**轴(Axis):**0轴代表行(纵向),1轴代表列(横向)。
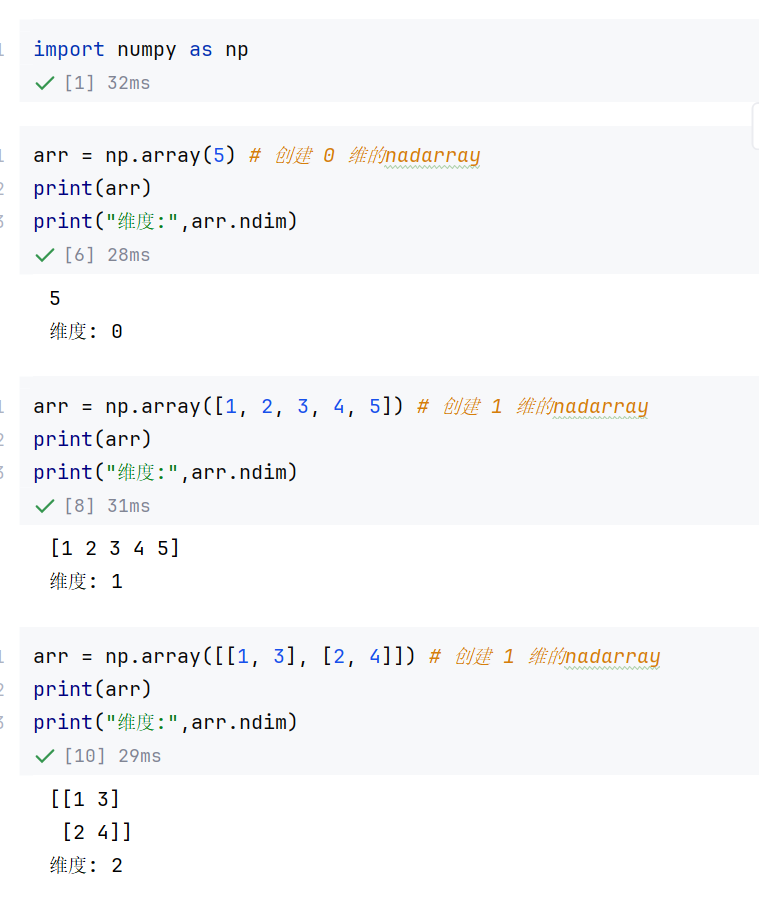
Numpy数组的核心特性:
- 高效性:基于连续内存块存储,支持向量话运算
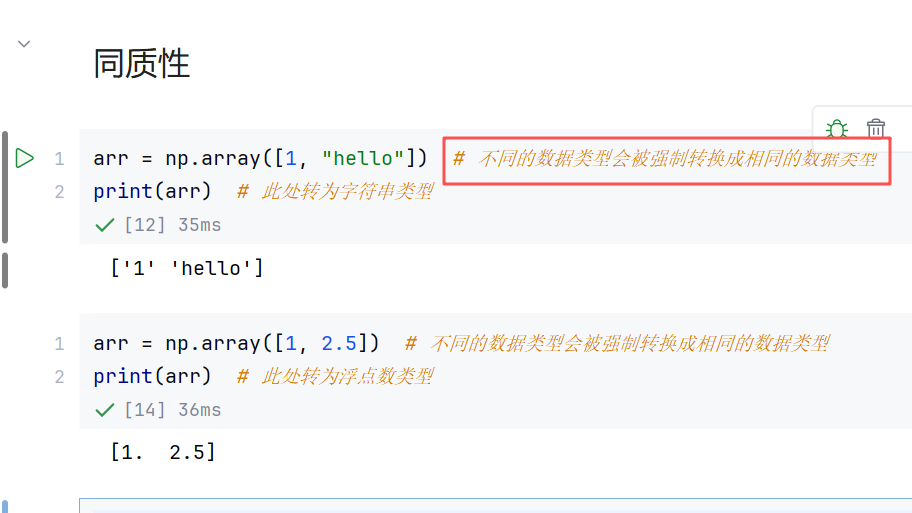
- 同质性:所有元素类型必须一致(通过dtype指定)
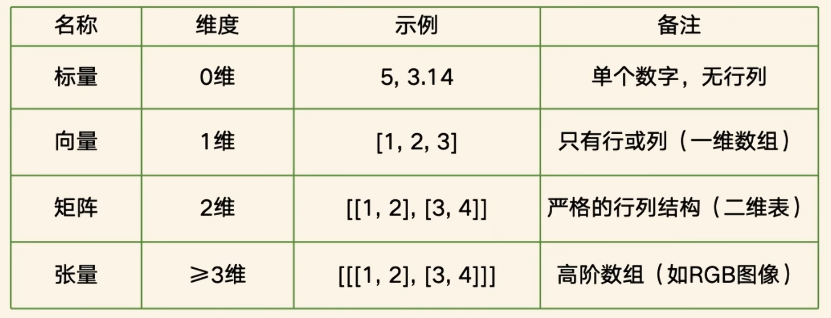
- 多维性:支持0维(标量)、1维(向量)、2维(矩阵)及更高维数组
//示例1:多维性(左)与同质性(右)
(2)属性


//示例:
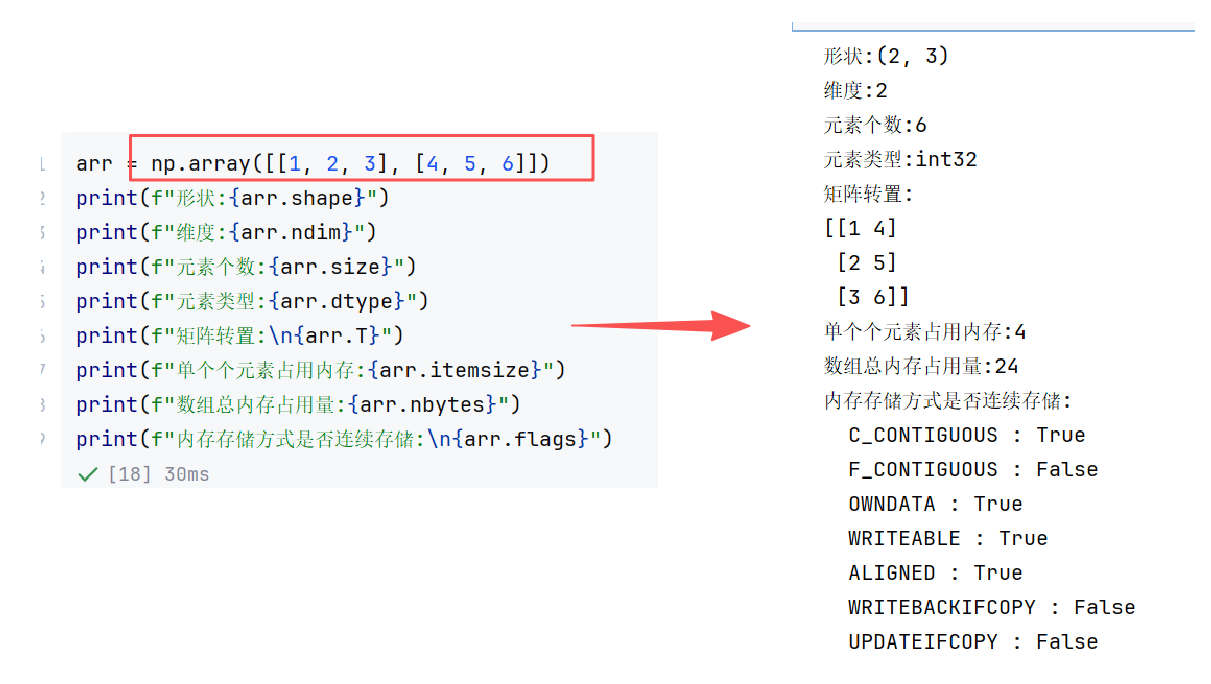
1.3 ndarray的创建
- **1.基础构造:**适用于手动构建小规模数组或复制已有数据。
- **2.预定义形状填充:**用于快速初始化固定形状的数组(如全0占位、全1初始化)。
- **3.基于数值范围生成:**生成数值序列,常用于模拟时间序列、坐标网格等。
- **4.特殊矩阵生成:**数学运算专用(如线性代数中的单位矩阵)。
- **5.随机数组生成:**模拟实验数据、初始化神经网络权重等场景。
- **6.高级构造方法:**处理非结构化数据(如文件、字符串)或通过函数生成复杂数组。

//示例1:基础构造
//示例2:预定义形状生成


//示例3:基于数值范围生成


//示例4:特殊矩阵生成
np.diag的参数 k 表示对角矩阵从第几列开始, v表示填充的值。

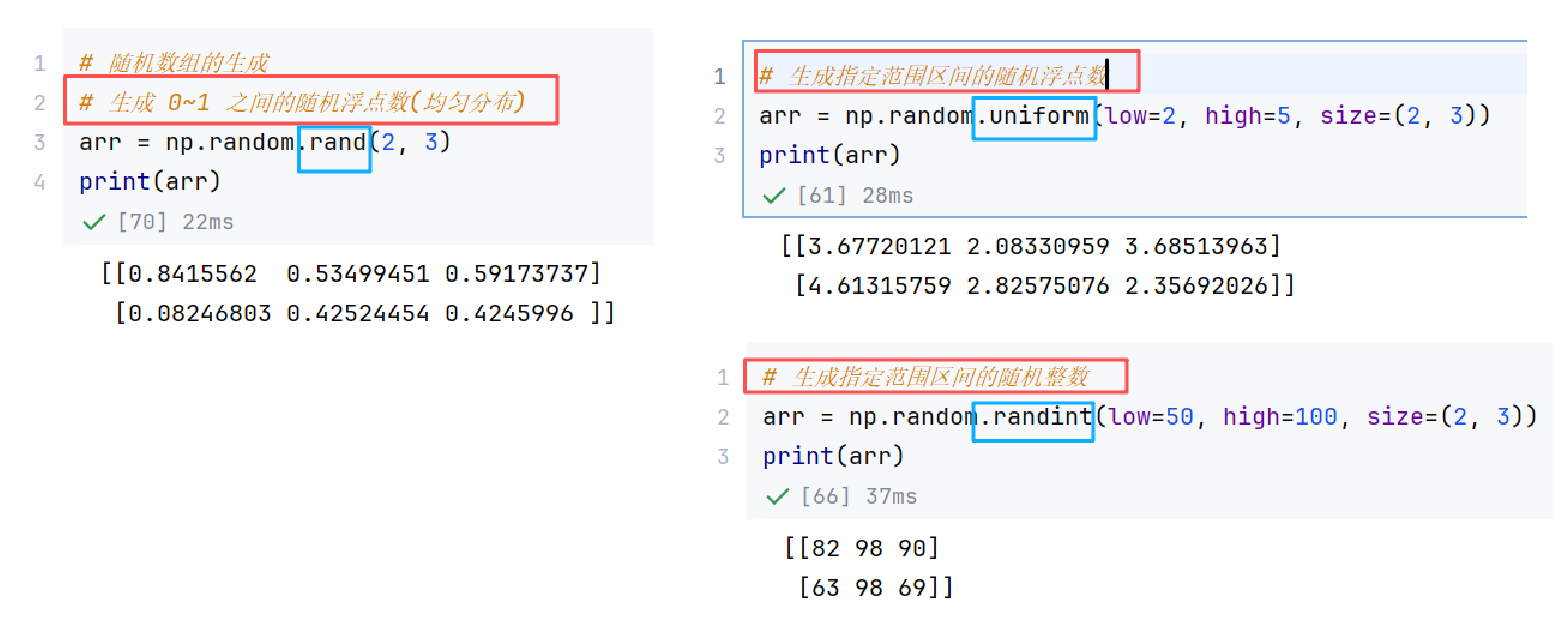
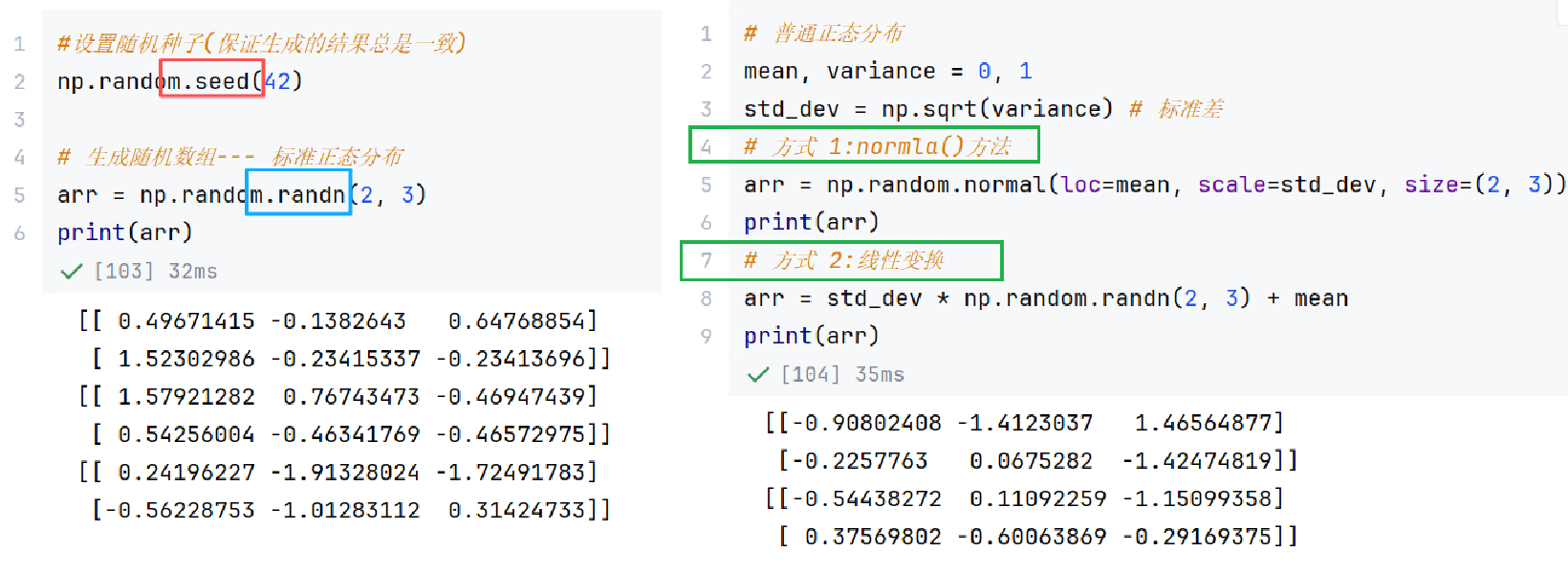
//示例5:随机数组生成
1.4 ndarray的数据类型
1.5 索引与切片

//示例1:一维数组的索引与切片

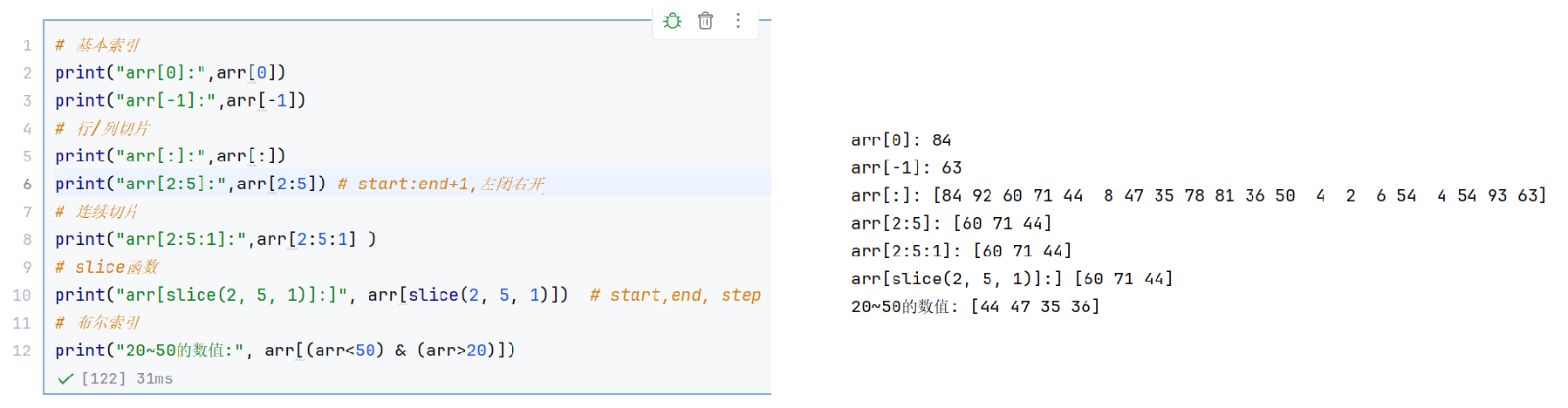
//示例2:二维数组的索引与切片

1.6 ndarray的运算
//示例1:一维向量的运算

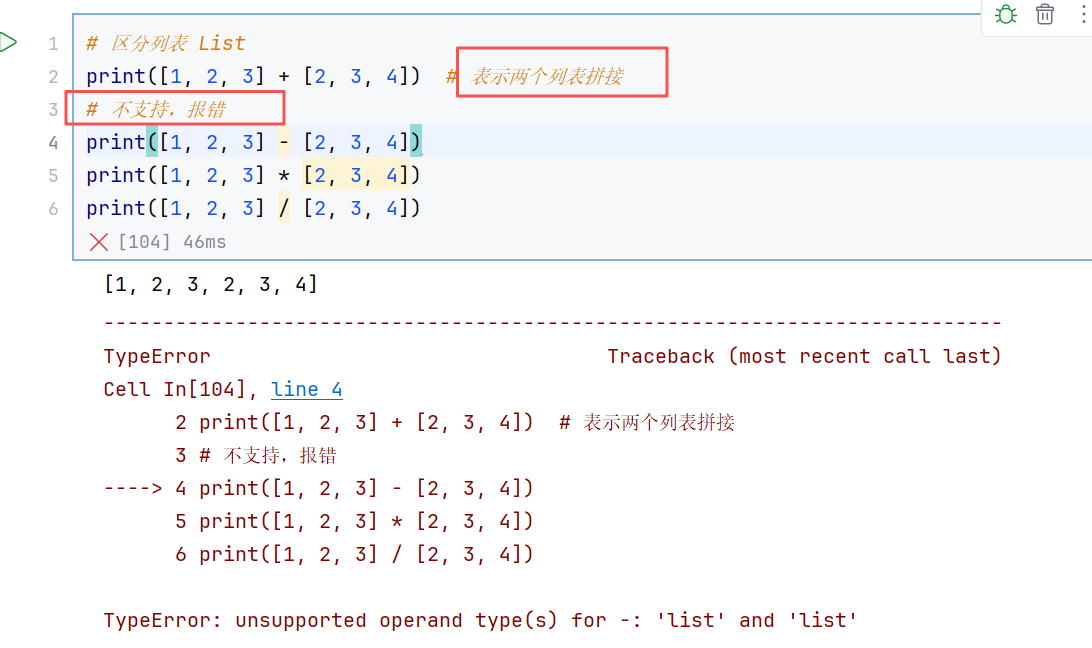
注意区分列表:
list不支持直接进行上述的数学运算(可以通过for循环操作),会报错:
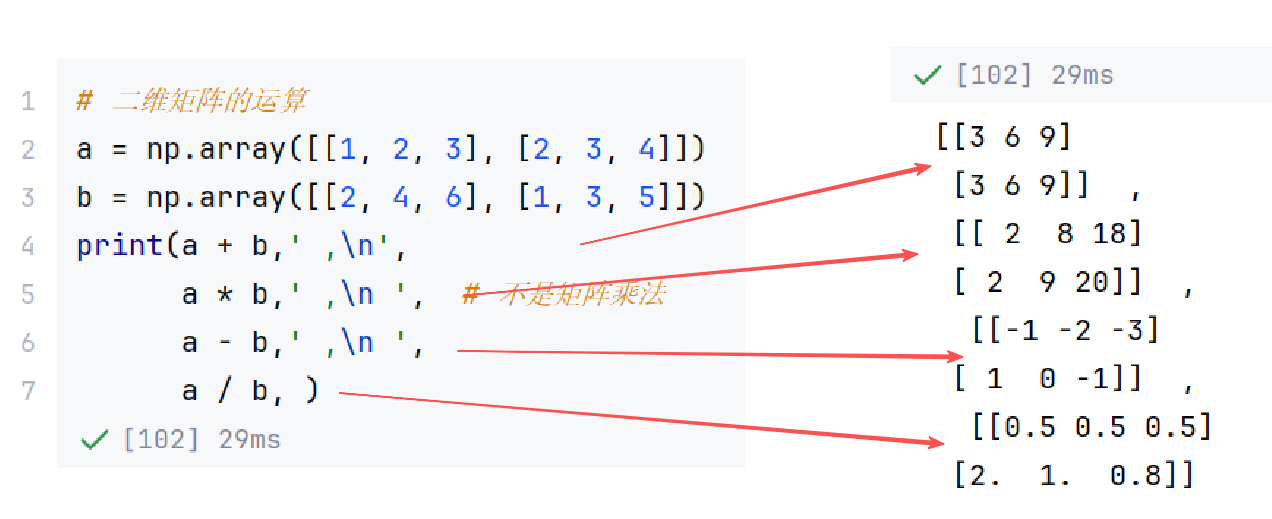
//示例2:二维矩阵的运算
(形状相同,对应位置直接计算结果)
矩阵乘法要求:a的列数=b的行数

//示例3:矩阵 与 标量的计算

//示例4:广播机制
1.获取形状 2.判断是否广播。广播要求:同一维度相同/为1
成功案例:

失败案例:

1.7 numpy常用函数

(1)基本数学
//示例:

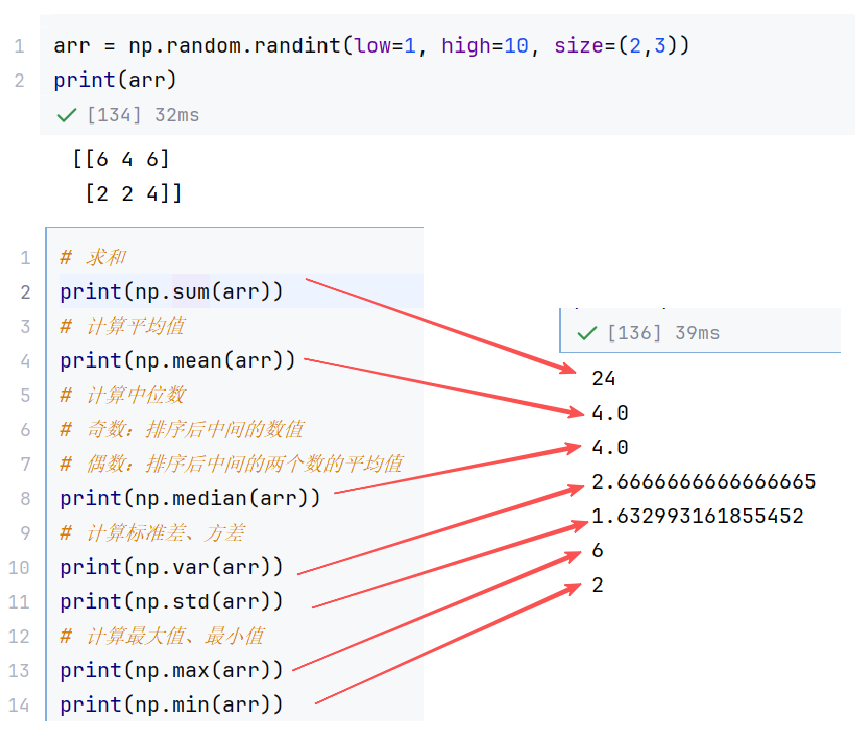
(2)统计
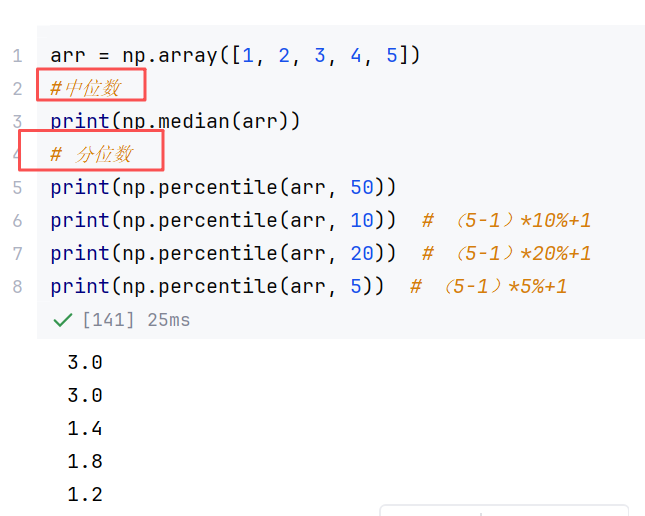

(3)比较
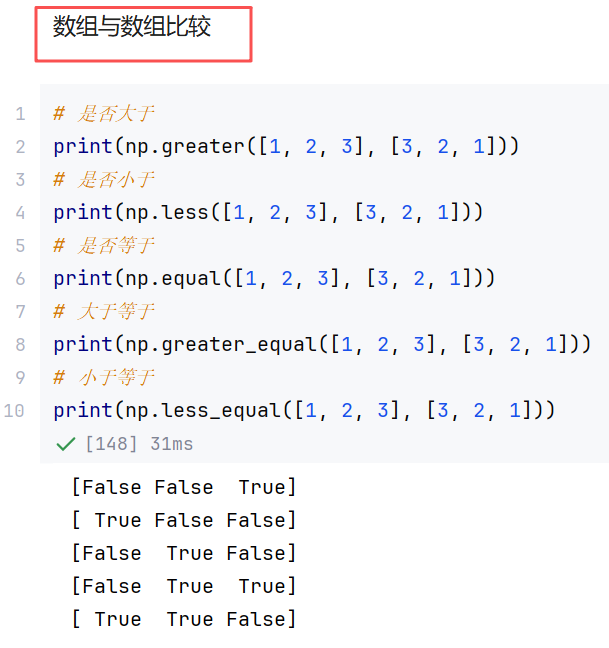
数组与标量比较使用了广播机制(本质上还是数组与数组比较------对应位置元素独立比较)
//示例1:比较函数

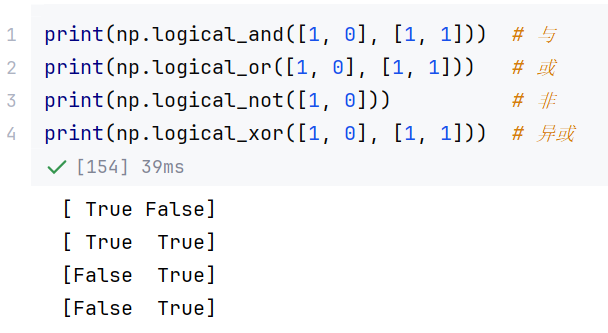
//示例2:逻辑运算(与或非)
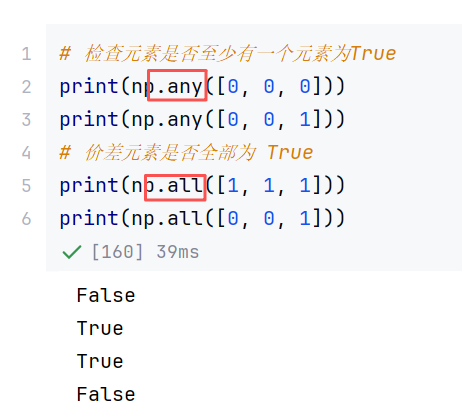
//示例3:存在量词和全称量词
//示例4:自定义条件


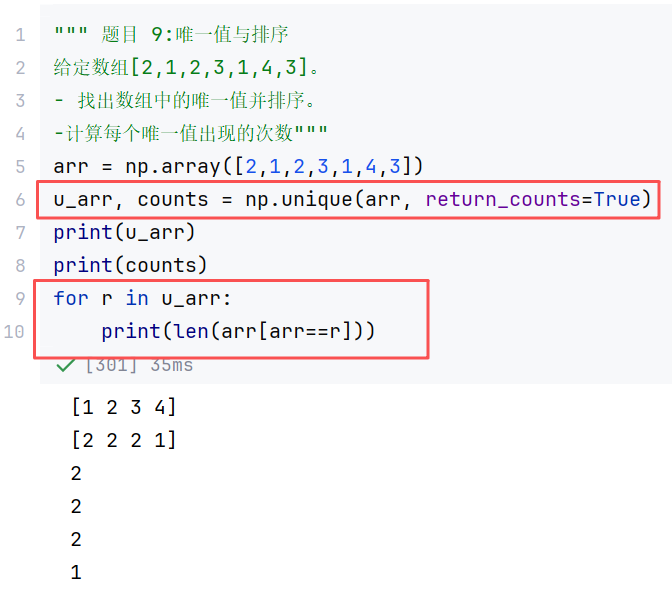
(4)去重

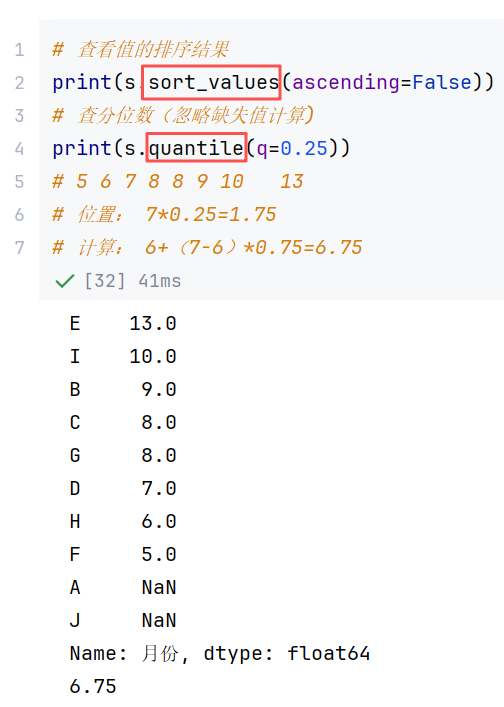
(5)排序

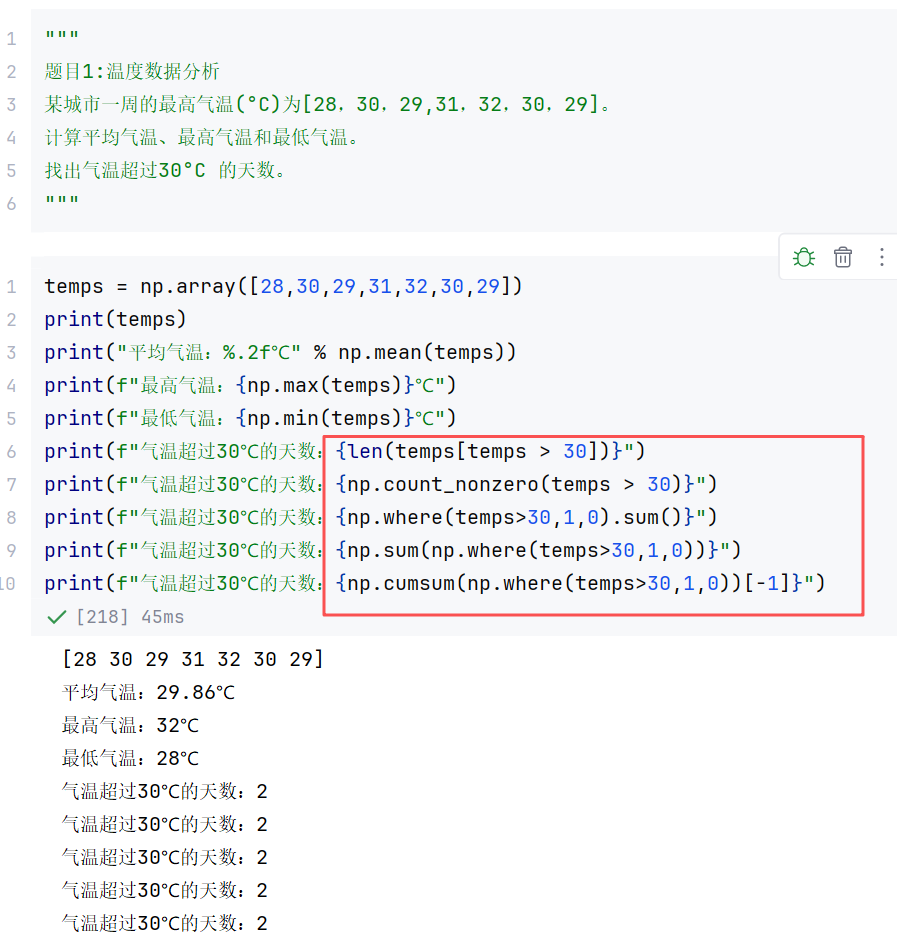
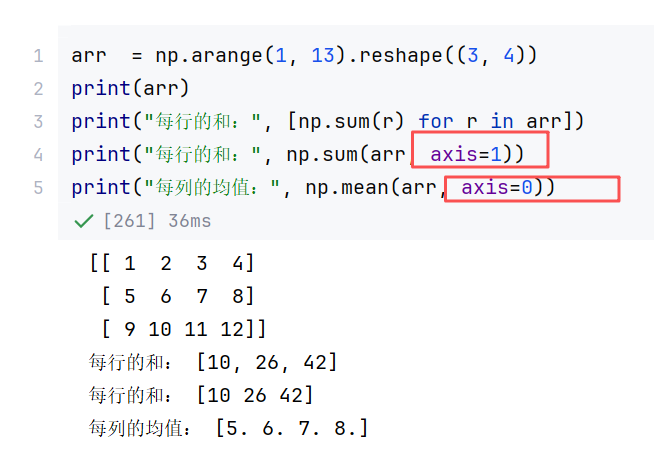
(6)其他


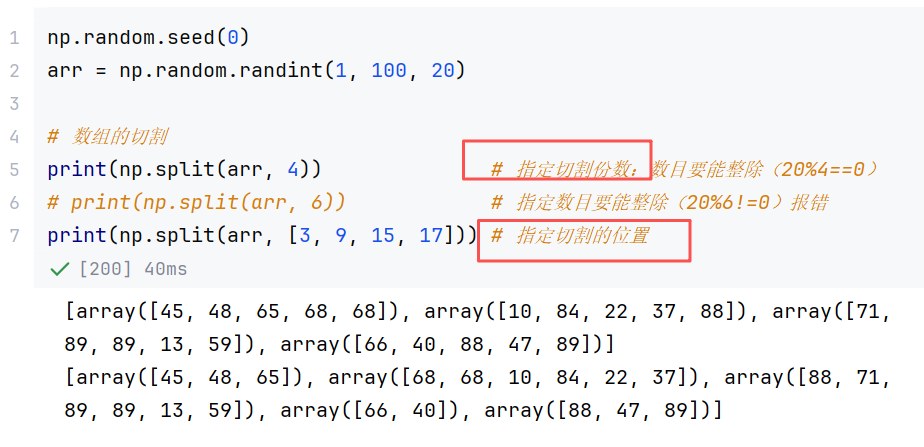
综合案例

2 Pandas 数据处理
2.1 Pandas介绍
为什么学Pandas?
- Pandas是Python数据分析工具链中最核心的库,充当数据读取、清洗、分析、统计、输出的高效工具。
- Pandas提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
- Pandas是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
核心设计理念:它是基于NumPy构建的专门为处理表格 和混杂数据设计的Python库,核心设计理念包括:
- 标签化数据结构:提供带标签的轴
- 灵活处理缺失数据:内置NaN处理机制
- 智能数据对齐:自动按标签对齐数据
- 强大IO工具:支持从CSV、Excel、SQL等20+数据源读写
- 时间序列处理:原生支持日期时间处理和频率转换
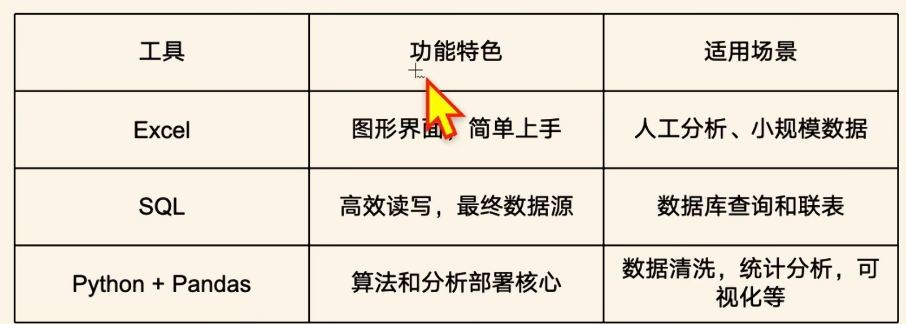
数据分析的工具对比:
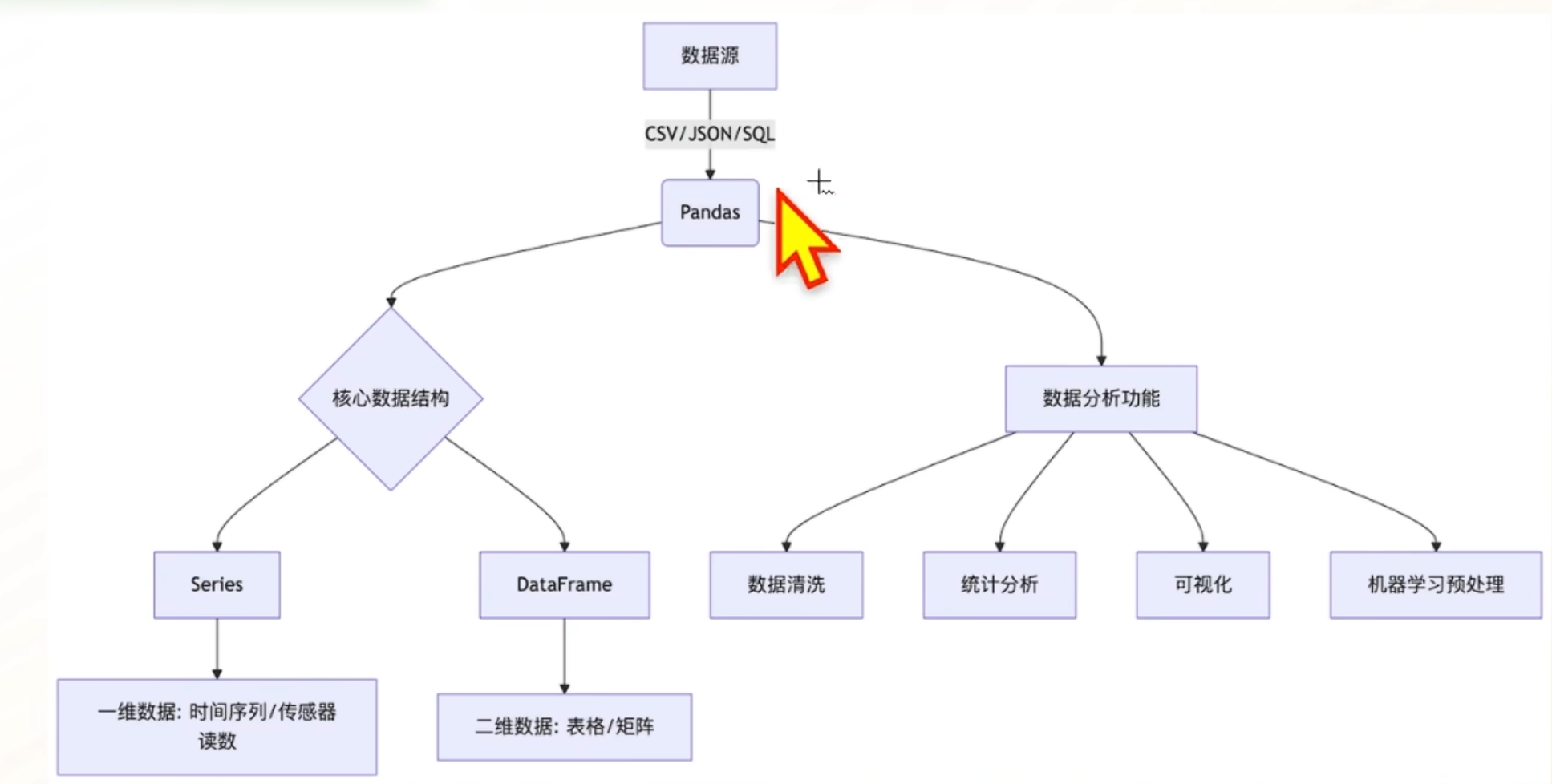
pandas的核心数据结构是series和dataframe,不同于numpy(可创建多维的数组),它针对一维和二维数据进行处理。
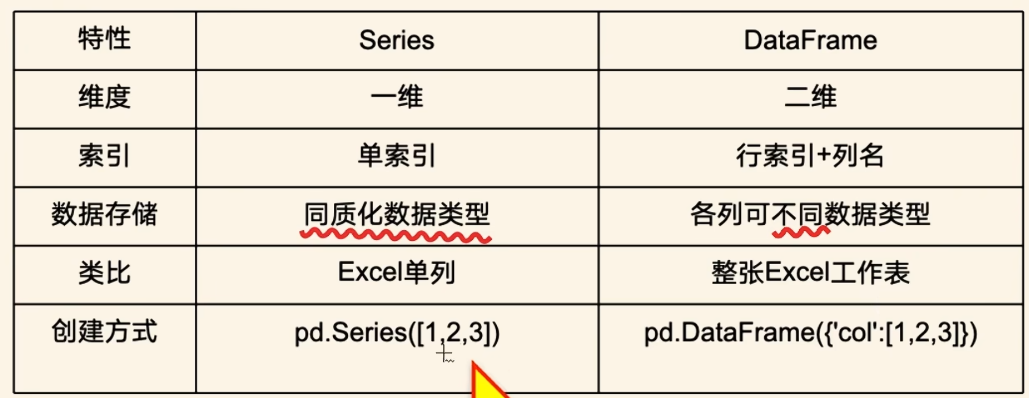
2.2 Series
(1)Series的创建
//示例1:通过列表(list)创建
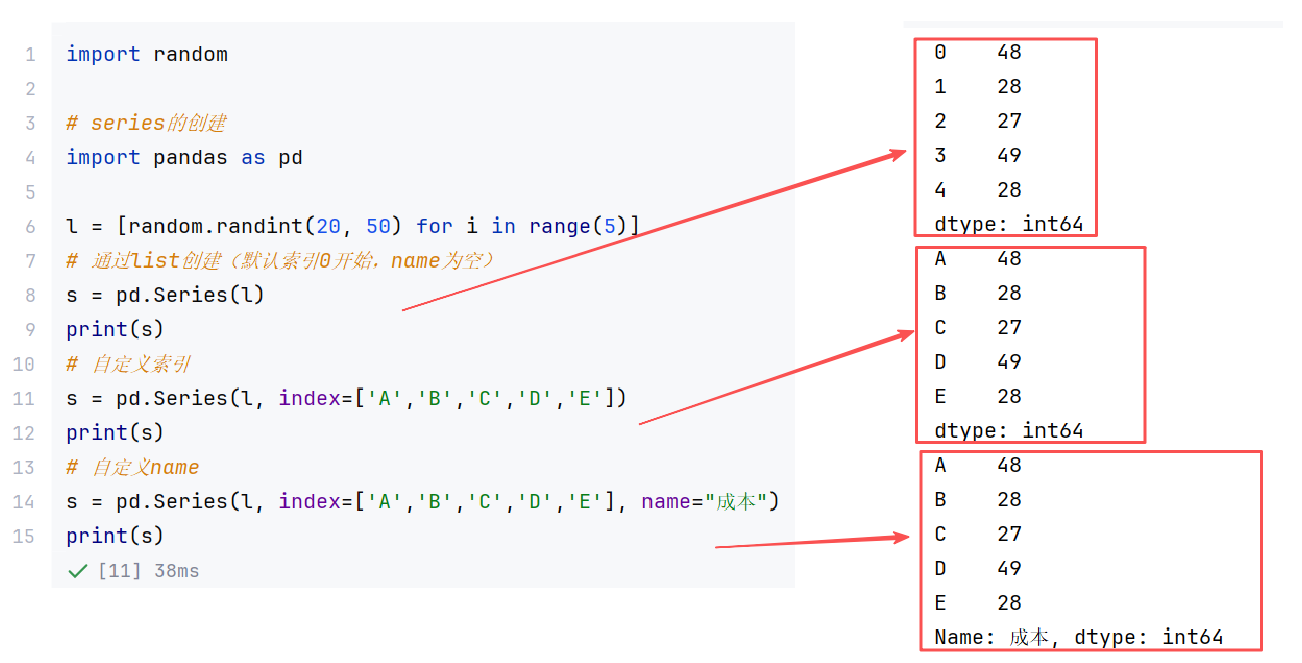
//示例2:通过字典(dict)创建
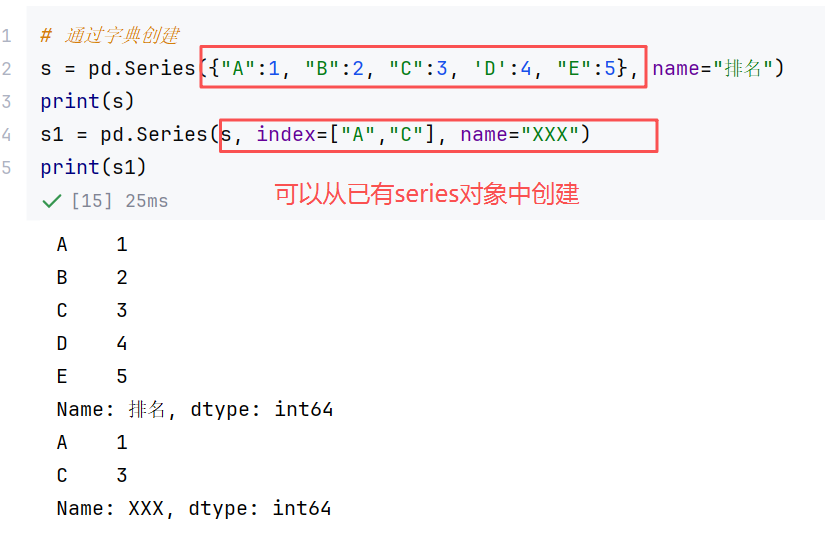
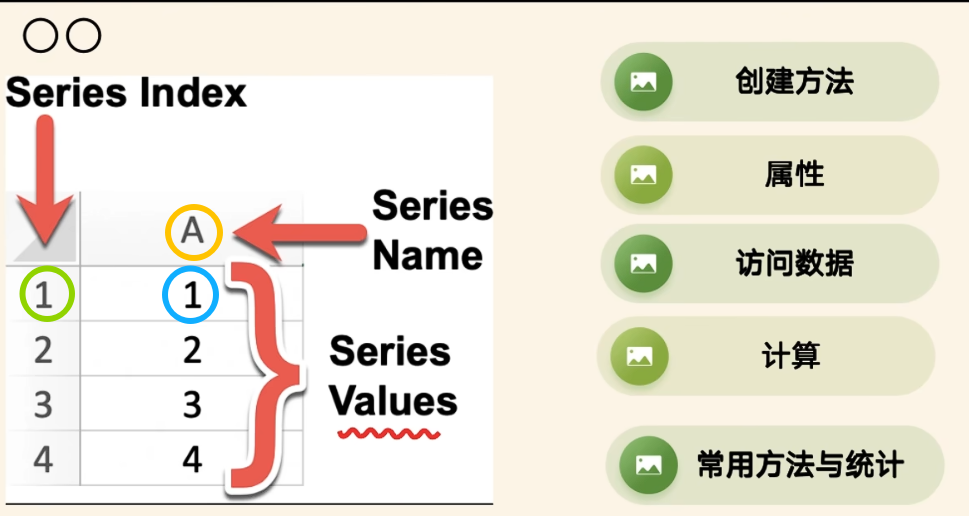
(2)Series的属性
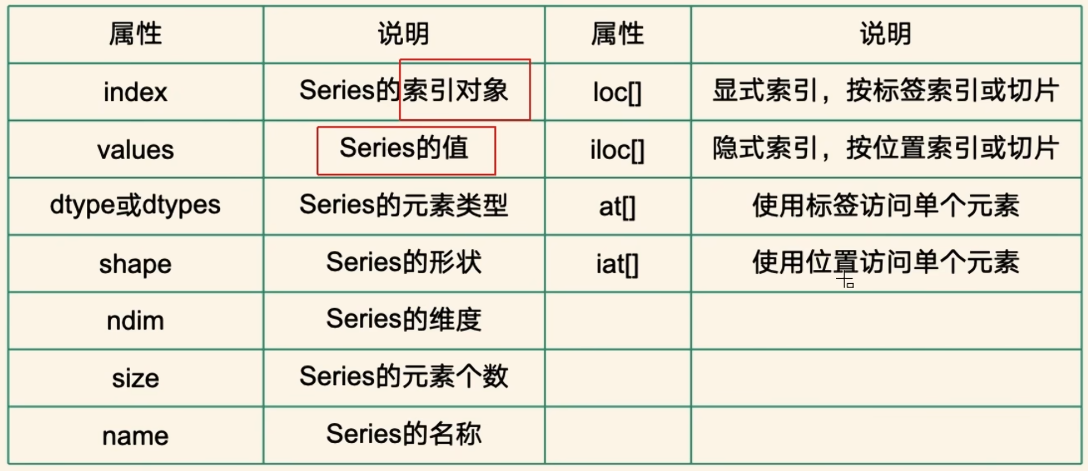
index:Series的索引对象
values:Series的值
dtype或dtypes:Series的元素类型
shape:Series的形状
ndim:Series的维度
size:Series的元素个数
name:Series的名称
Loc[]: 显式索引,按标签索引或切片
iloc[] : 隐式索引,按位置索引或切片
at[]:使用标签访问单个元素
iat[]:使用位置访问单个元素//示例1:查看属性
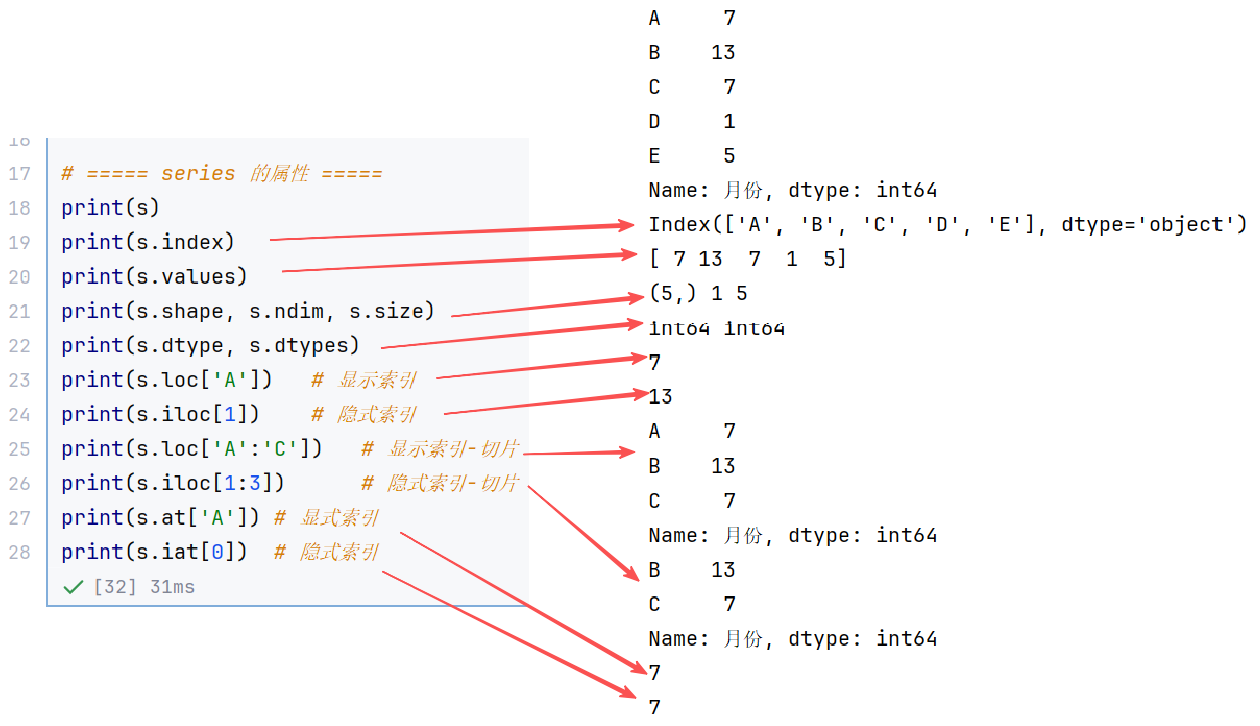
//示例2:访问数据

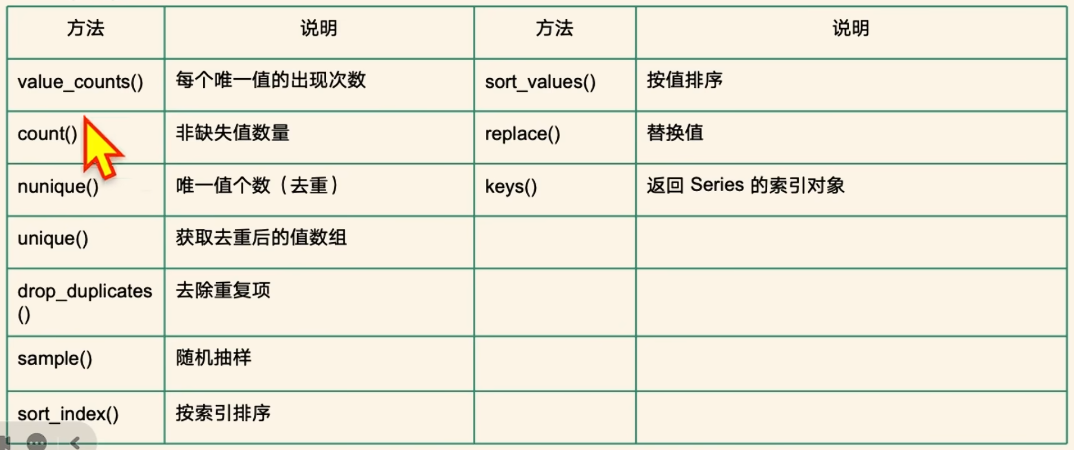
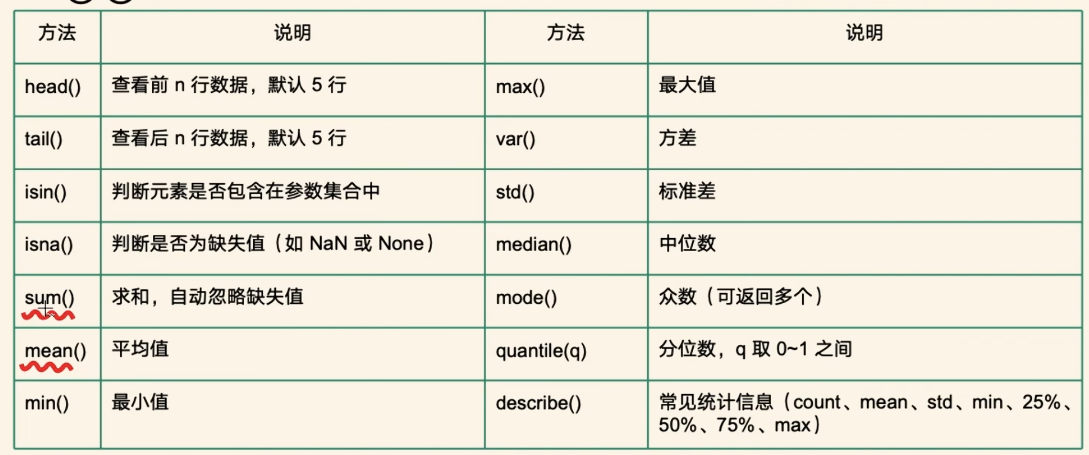
(3)Series 的常用方法
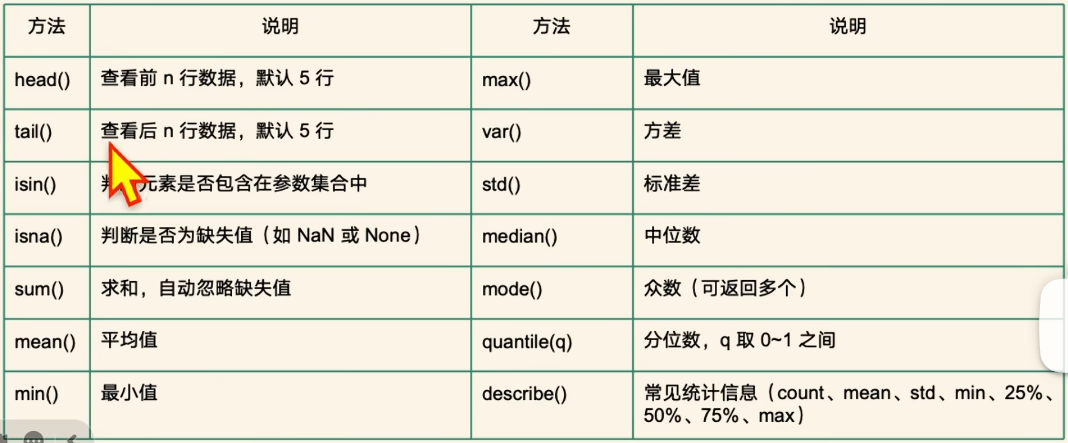
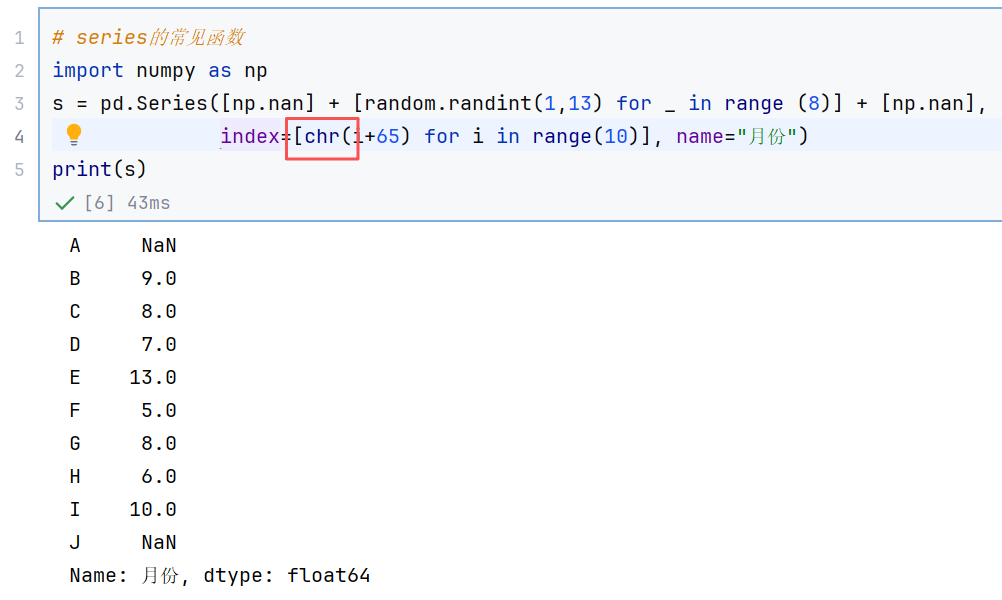
//示例1:查看数据


//示例2:统计分析



//示例3:排序
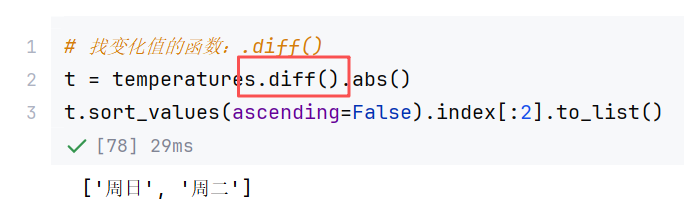
//案例:
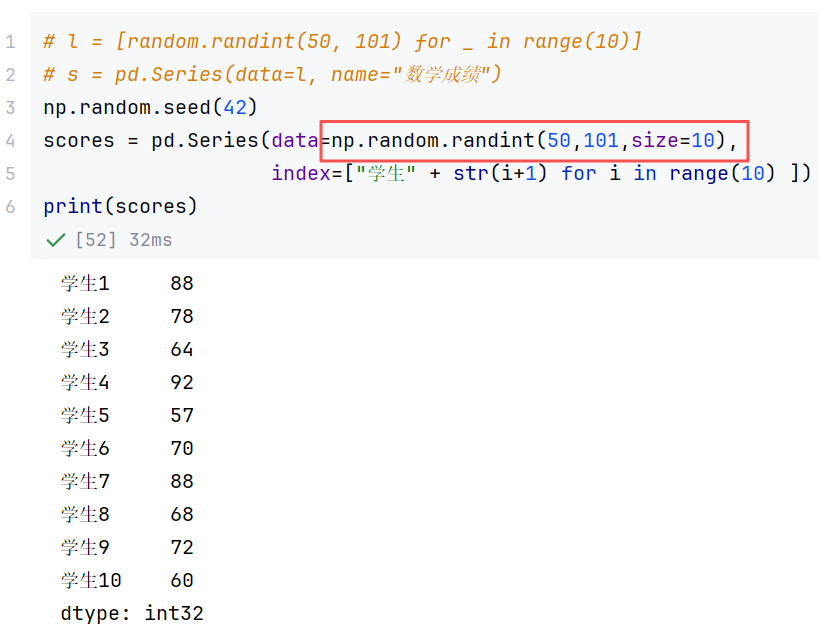
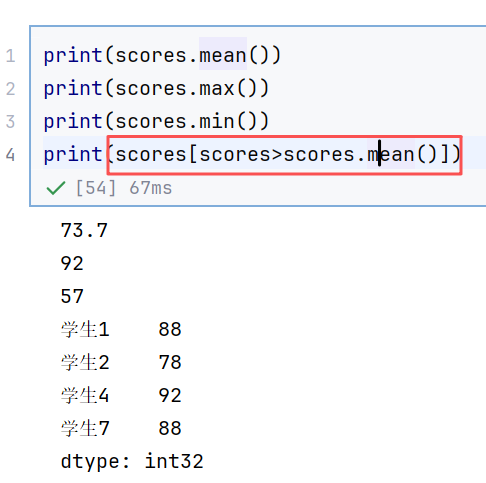
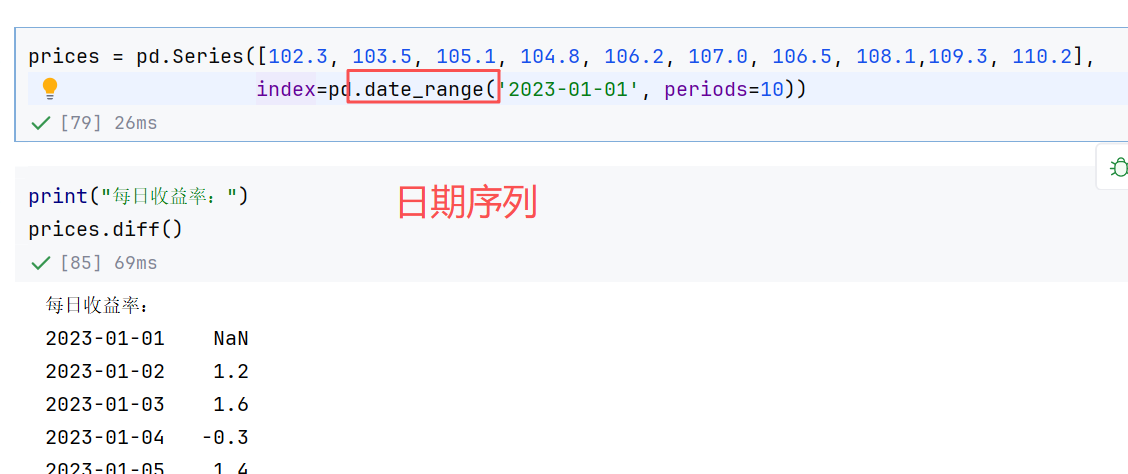
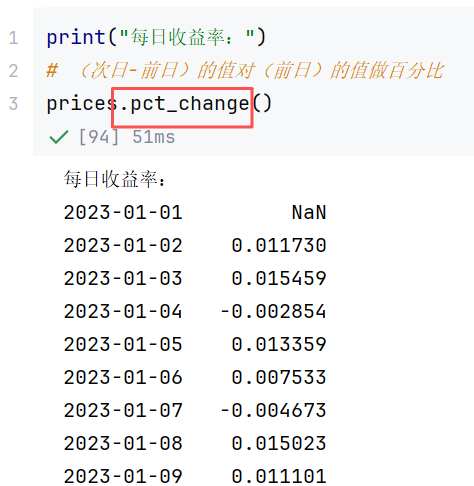

//案例2:滑动窗口
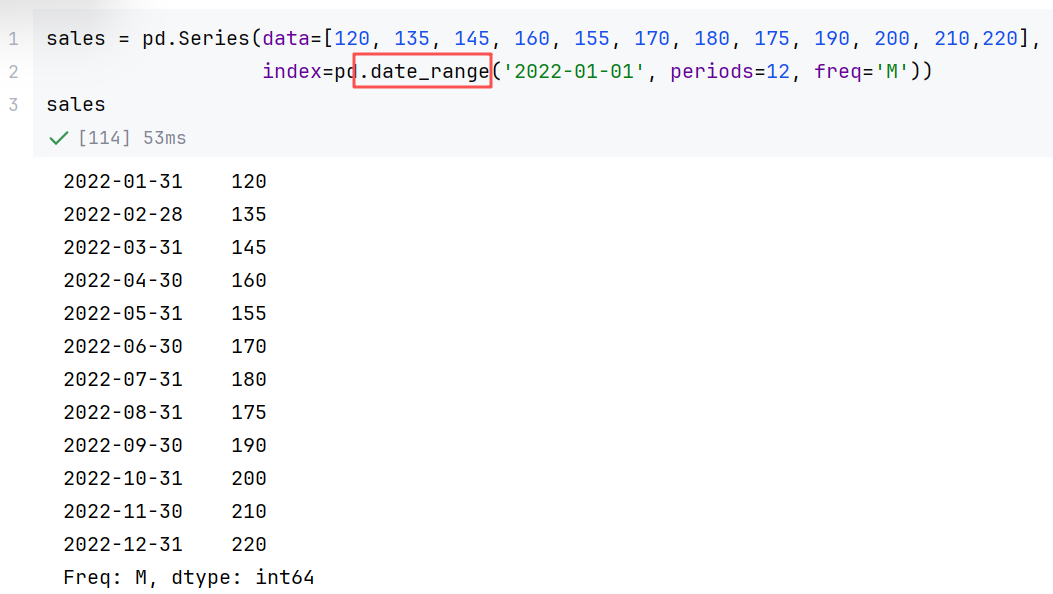
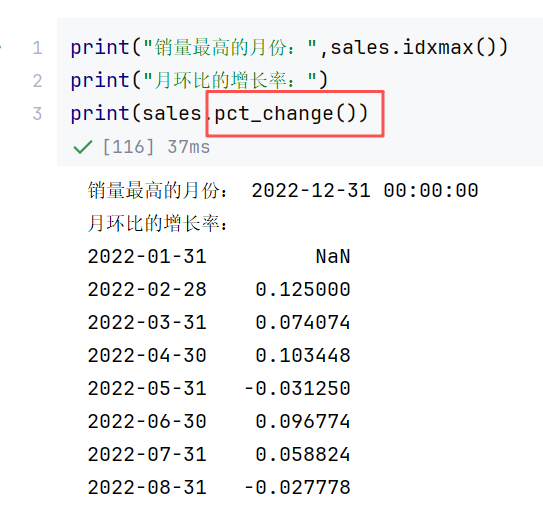
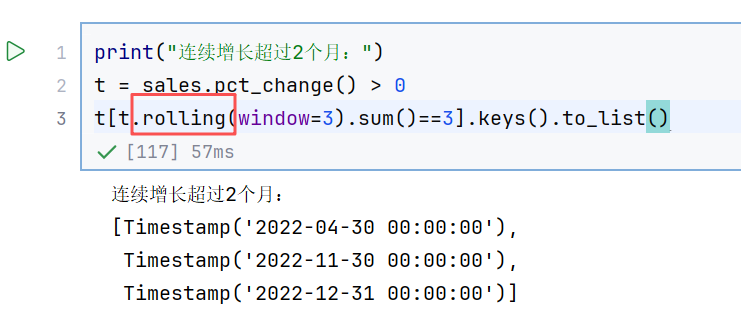
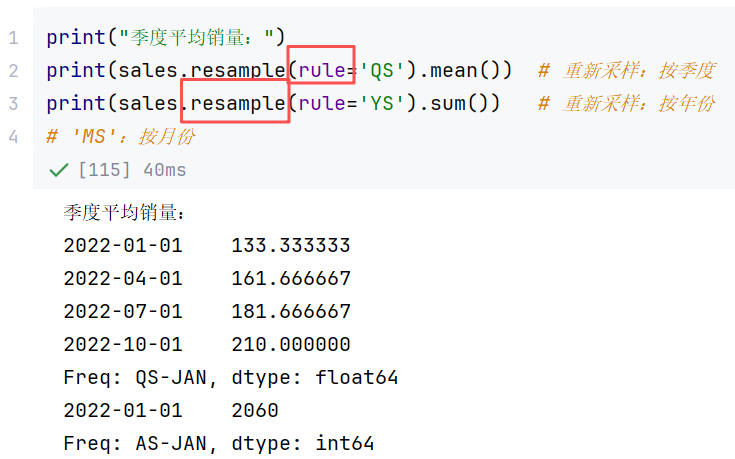
//案例3:销售额分析
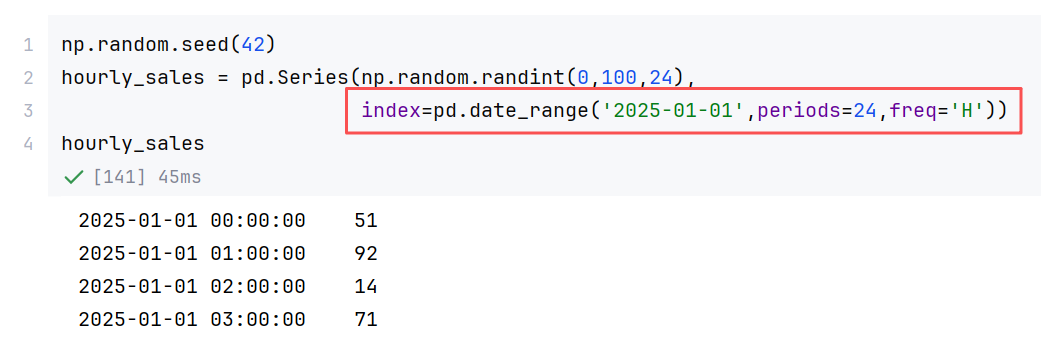
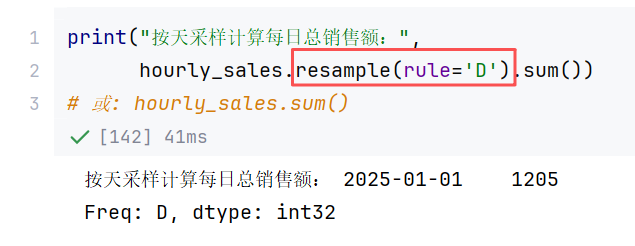
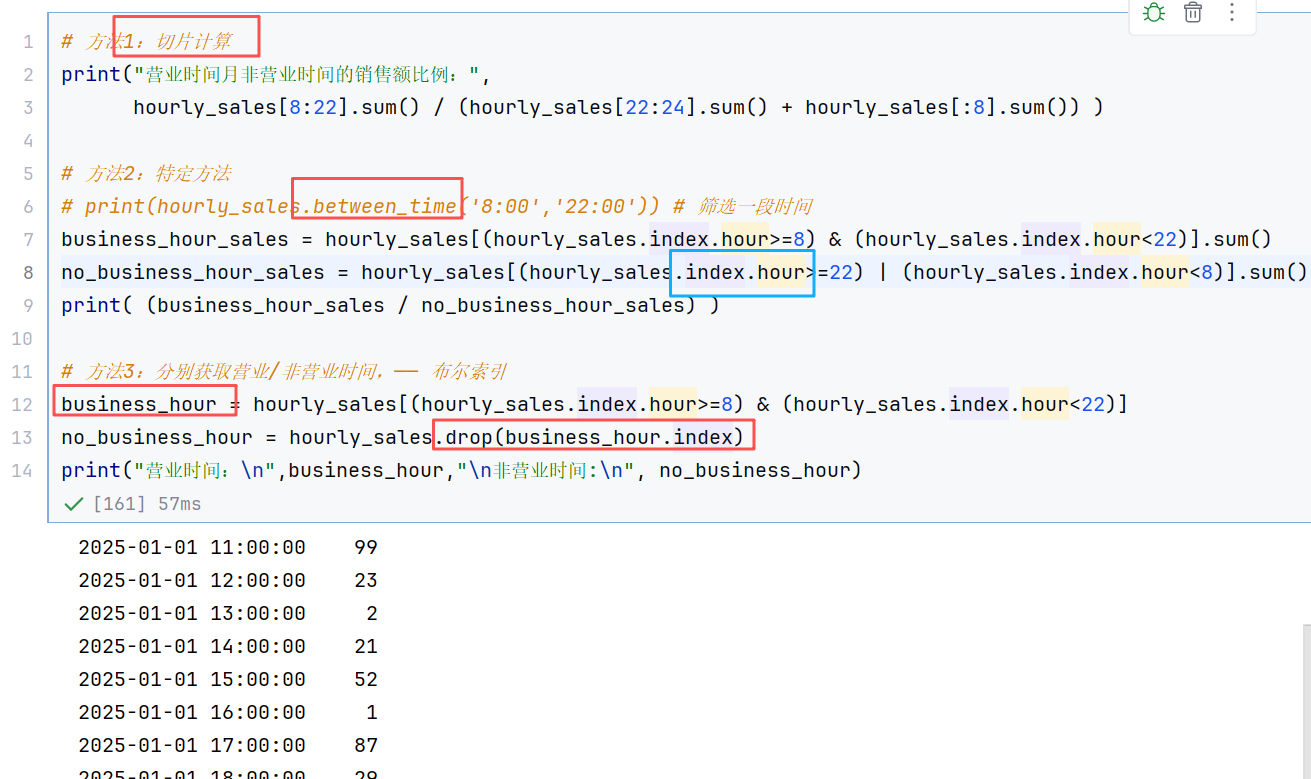
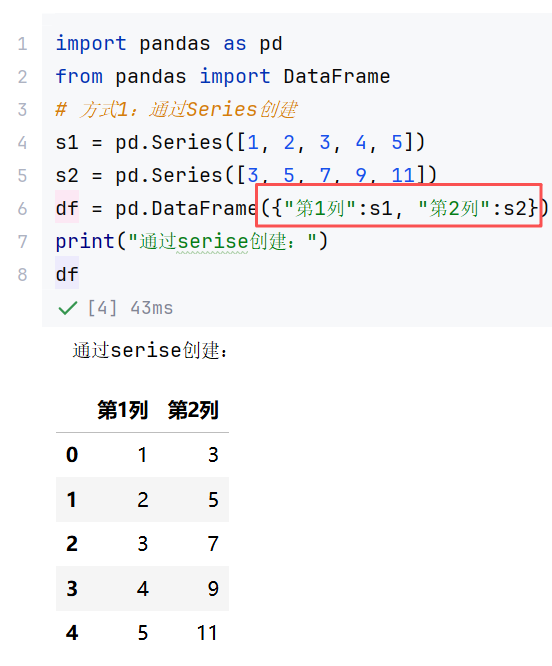
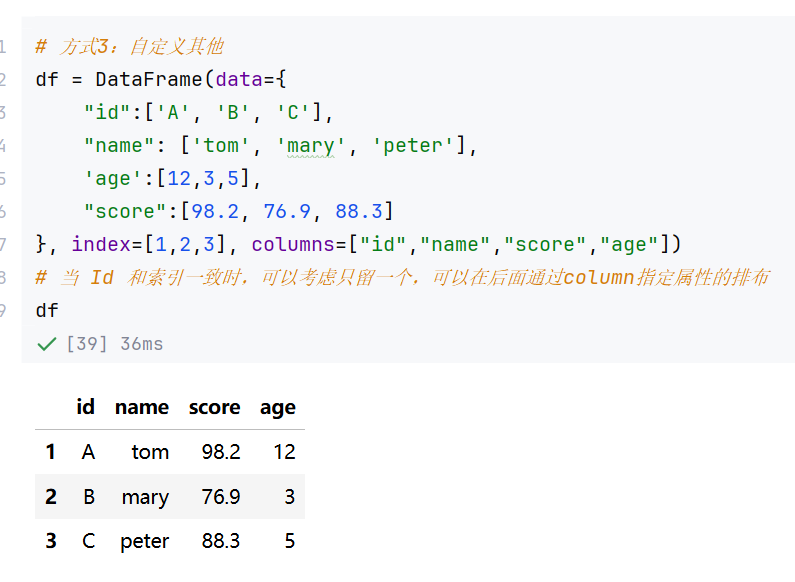
2.2 DataFrame
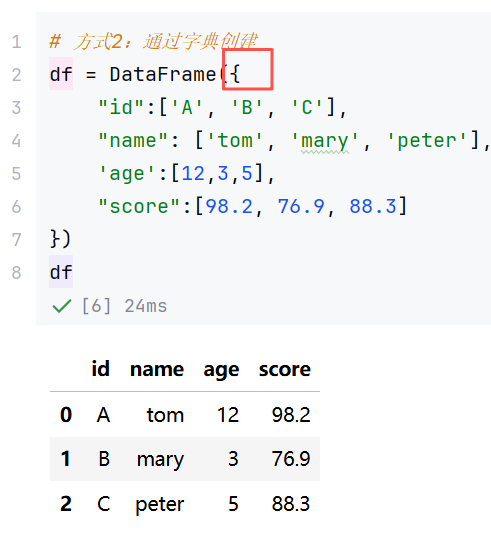
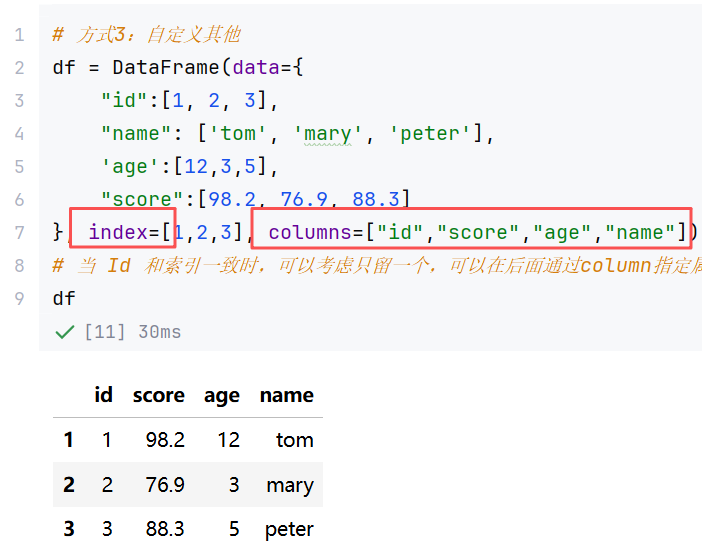
(1)DataFrame的创建
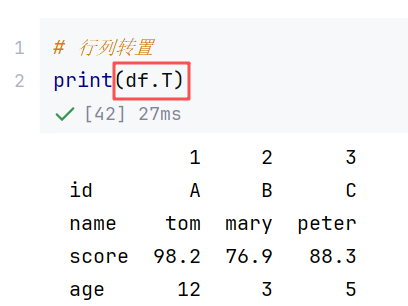
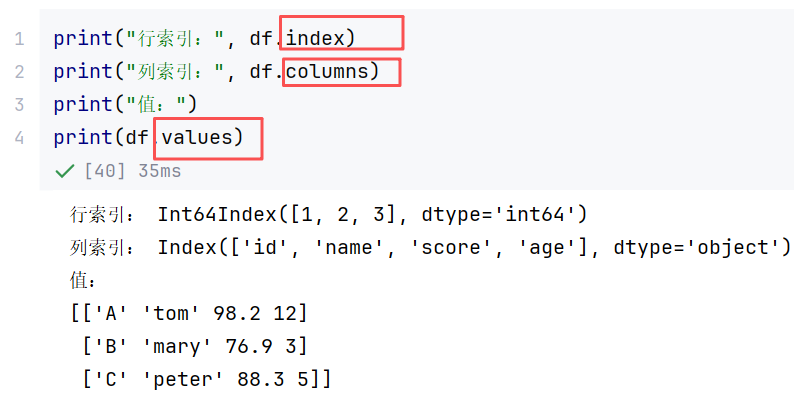
(2)属性
//示例1:读取索引与属性
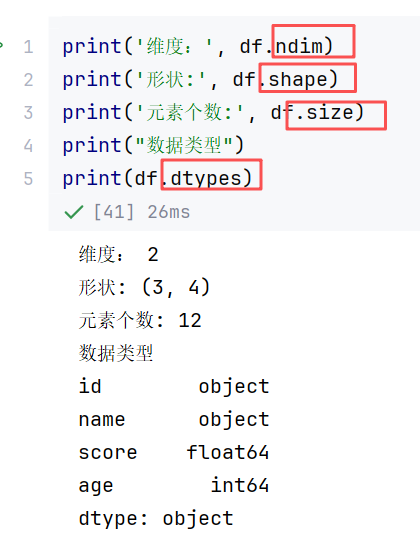
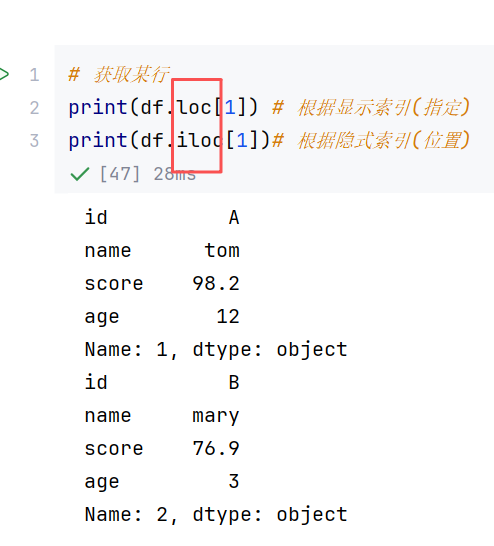
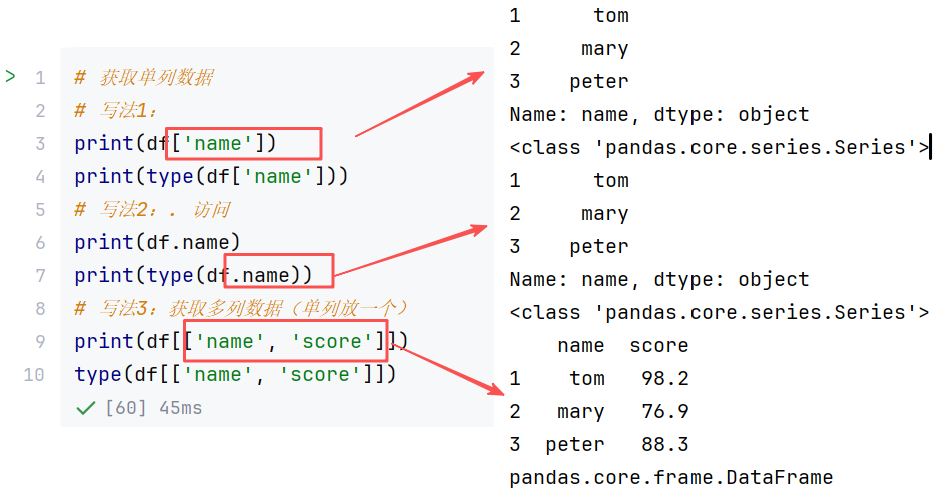
//示例2:获取某行/某列/单个元素
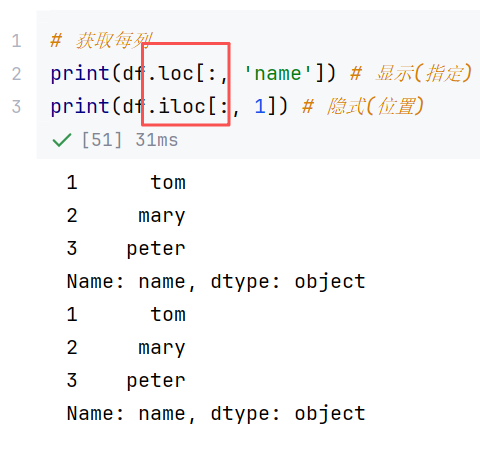
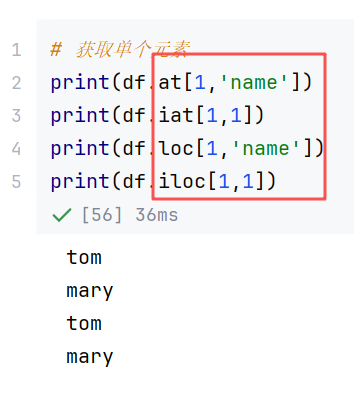
//示例3:访问数据其他方法
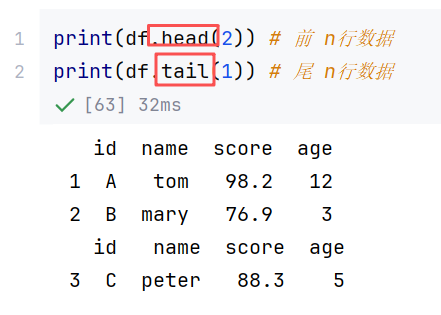
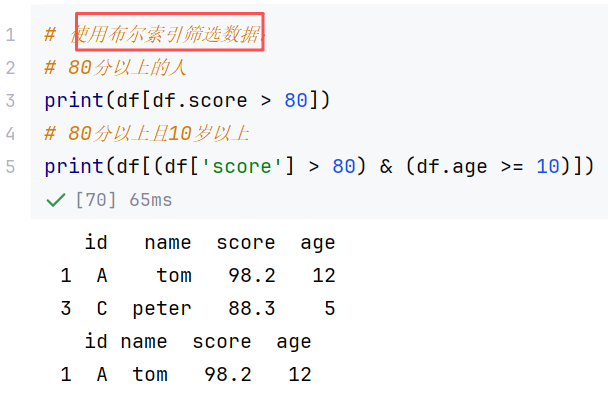
(3)常用方法
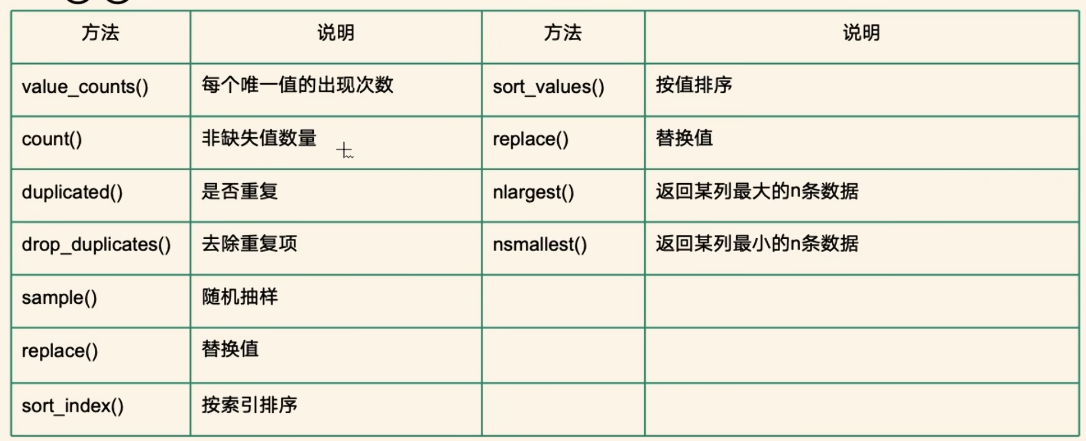 //
//
//读取csv文件-获取df对象:
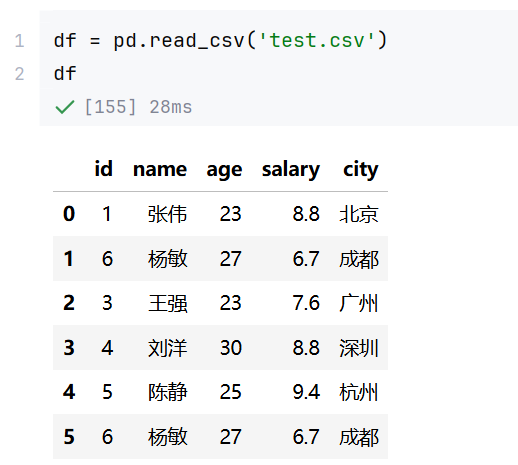
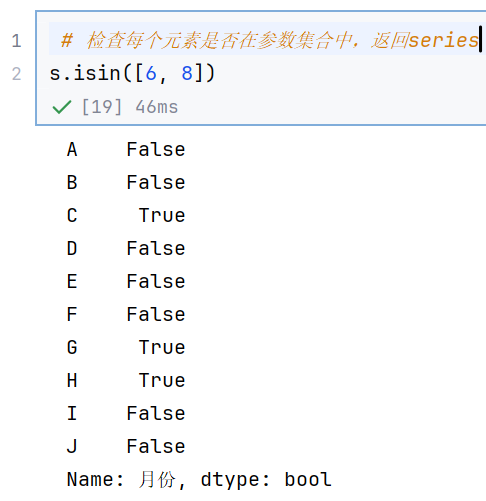
//示例1:df.isin()成员资格检验
(反选:not)

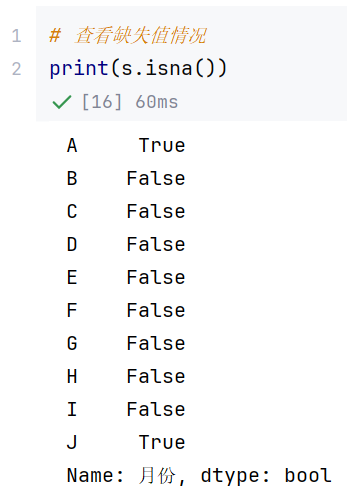
查看元素是否是缺失值:df.isna()或df.isnull()


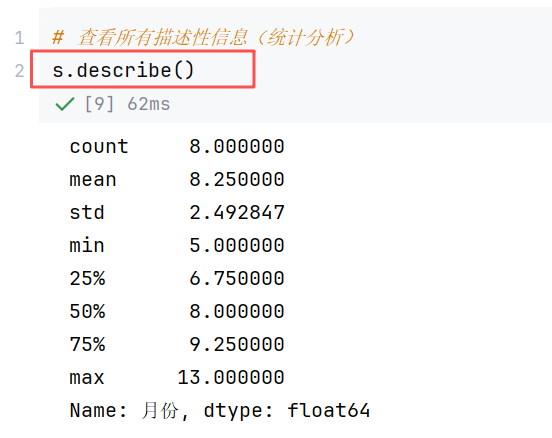
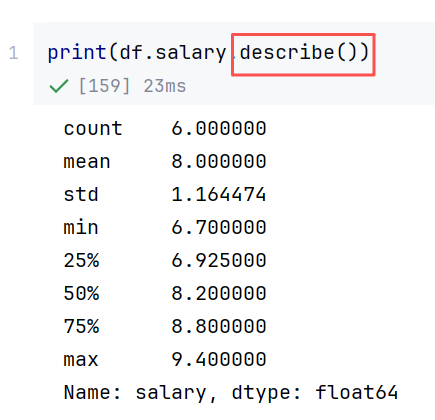
//示例2:统计信息

(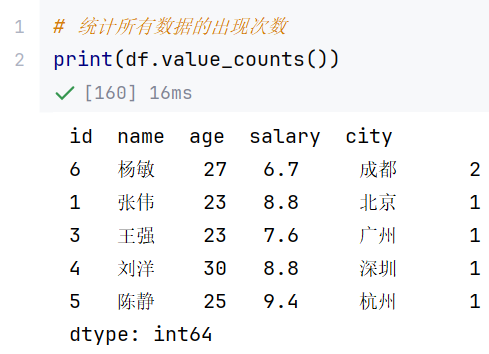
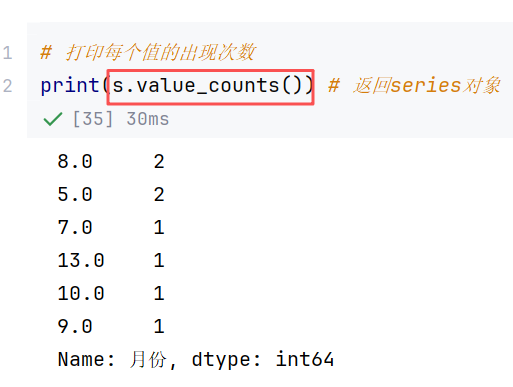
//示例3:.value_counts()-统计唯一值出现频次


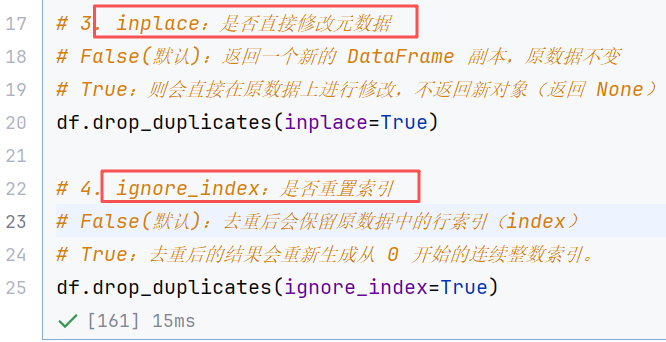
//示例4:drop_duplicates-删除重复行(只检测不删除: duplicated**)**

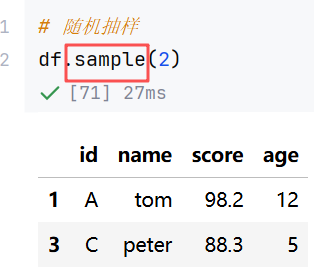
//示例5:smaple-随机抽取数据
python
# 1. n 和 frac:指定抽取的数量或比例
# 1)随机抽取 3 行数据
df.sample(n=3)
# 2)随机抽取 50% 的数据
df.sample(frac=0.5)
# 2. replace:是否允许重复抽样(放回抽样)
# False(默认):不放回抽样(抽中的行不会再次被抽到);
# True:允许同一行被多次抽中
df.sample(n=10, replace=True)
# 3.random_state:设置随即种子
# 设置一个固定的整数(如 42),可以保证每次运行代码时抽样的结果完全一致,方便后续的复现和调试。
df.sample(n=3, random_state=42)
"""
4. weights:指定抽样权重
默认为等概率抽样。你可以通过传入一个与 df 行数相同的数组或 Series,来指定每一行被抽中的概率。Pandas 会自动对权重进行归一化处理。
"""
# 1)假设我们想让 'score' 分数越高的行,被抽中的概率越大
df.sample(n=5, weights=df['score'])
# 2)或者手动指定每一行的权重(长度必须与 df 行数一致)
import numpy as np
df.sample(n=5, weights=np.random.rand(len(df)))
"""
5.axis:指定抽样的维度
默认为 0:表示沿行方向抽样(抽取行);
设置为 1:则表示沿列方向抽样(随机抽取列)
"""
# 随机抽取 2 列数据(而不是行)
df.sample(n=2, axis=1)
"""
6. ignore_index:是否重置索引
默认False:抽取出来的数据会保留原有的行索引;
设置为True:抽取结果的索引会被重置为从 0 开始的连续整数。
"""
# 抽取 3 行,并将索引重置为 0, 1, 2
df.sample(n=3, ignore_index=True)//示例6:replce-替换
python
# 1. 基础替换:所有值替换
print(df.replace(15, 12))
# 2. 批量替换:使用列表
# 1)多对多替换
print(df.replace([12, 15], [23, 32]))
# 2)多对1替换
print(df.replace([12, 15], 1215))
# 3.精确替换:使用字典
# 1) 全局字典映射
print(df.replace({12: 15, 23: 32}))
# 2) 指定列替换:只在city列中将"北京"替换为'上海'
print(df.replace({'city':'北京'}, '上海'))
# 3) 嵌套字典(指定列+指定值)
print(df.replace({'salary': {6.7: 8.9},
'age': {23: 45}
}))
# 4.模糊替换:使用正则表达式
# 将 city 列中所有包含 "州" 字的城市名,统一替换为"xx"(需要开启 regex=True)
print(df.replace(to_replace=r'.*州',value='江心洲',regex=True))
# 5.缺失值填充:配合 method 参数
import numpy as np
print(df.replace(np.nan, method='bfill'))//示例7:cumxxx-累加计算
python
# 每列做累加计算:
# 默认:axis=0(按列)
df.cumsum()
df.cummax()
# 指定:axis=1(按行)
df.cummin(axis=1) # 需要注意必须类型一致,否则会报错//示例8:排序
python
"""
1. sort_index():按索引(行名或列名)排序
默认 axis=0,即按行索引(index)排序;
设置 axis=1,则按列名(columns)排序。
"""
# 1)按行索引进行降序排列
print(df.sort_index(ascending=False))
# 2)按列名(columns)的字母顺序进行升序排列
print(df.sort_index(axis=1))
"""
2. ascending:控制升序与降序
默认为 True(升序);
设置为 False(降序);
多列排序时,可传入布尔值列表分别控制。
"""
# 1)单列排序:按年龄(age)从大到小降序排列
print(df.sort_values(by='age', ascending=False))
# 2)多列排序:先按年龄(age)升序,年龄相同时再按分数(score)降序
print(df.sort_values(by=['age', 'score'], ascending=[True, False]))
"""
3. na_position:缺失值(NaN)的位置控制
默认为 'last'(放在最后);
设置为 'first'(放在最前)。
"""
# 按分数(score)排序,并将缺失分数的行放在最前面
print(df.sort_values(by='score', na_position='first'))
"""
4. inplace:是否直接修改原数据
默认为 False(返回排序后的新副本,原 df 不变);
设置为 True(直接在原 df 上修改,不返回新对象)。
"""
# 直接在原数据上按城市(city)排序
df.sort_values(by='city', inplace=True)
"""
5. ignore_index:是否重置索引
默认为 False(保留原有的行索引);
设置为 True(丢弃原索引,重置为 0, 1, 2... 的连续整数)。
"""
# 按年龄排序后,将行索引重置为从 0 开始的连续数字
print(df.sort_values(by='age', ignore_index=True))
"""
6. key:自定义排序规则(高阶用法)
传入一个向量化函数,在排序前先对数据进行映射处理。
常用于忽略大小写排序、按字符串长度排序等场景。
"""
# 1)按城市(city)名称的拼音首字母忽略大小写进行排序
print(df.sort_values(by='city', key=lambda x: x.str.lower()))
# 2)按姓名(name)的字数长度进行排序
print(df.sort_values(by='name', key=lambda x: x.str.len()))//示例9:快速获取某列或多列数值最大的前 N 行数据
python
"""
1. n:指定要获取的前 N 条记录
这是一个必填参数,表示你想获取降序排列后最靠前的几行数据。
"""
# 获取薪资(salary)最高的前 3 名员工数据
df.nlargest(3, columns='salary')
"""
2. columns:指定用于排序的列
可以是单个列名(字符串),也可以是多个列名(列表)。
传入列表时,Pandas 会按列表中列的顺序依次进行降序排列。
"""
# 1)单列排序:获取年龄(age)最大的前 5 行
df.nlargest(5, columns='age')
# 2)多列排序:先按薪资(salary)降序,薪资相同时再按年龄(age)降序,取前 2 行
df.nlargest(2, columns=['salary', 'age'])
"""
3. keep:处理重复值的策略
当第 N 名出现数值并列(相同)时,决定如何保留数据。
默认 'first':保留并列值中第一次出现的行;
'last':保留并列值中最后一次出现的行;
'all':保留所有并列的行(此时返回的总行数可能会超过 n)。
"""
# 1)默认策略:薪资并列第2名时,只保留最先出现的那一条
df.nlargest(2, columns='salary', keep='first')
# 2)保留所有并列:如果第2名有多人薪资相同,全部都会展示出来(结果可能超过2行)
df.nlargest(2, columns='salary', keep='all')2.3 pandas数据处理

(1)数据的导入与导出
//示例1:处理csv文件
python
# 数据的导入
import pandas as pd
df = pd.read_csv('data/employees.csv')
# 数据处理
# ...
# 数据导出
df.to_csv('data/new_employees.csv')//示例2:处理json文件
若json文件本身那就是一行一行的,使用 read_json,否则先读取json为python数据容器格式,再依此数据创建DataFrame。
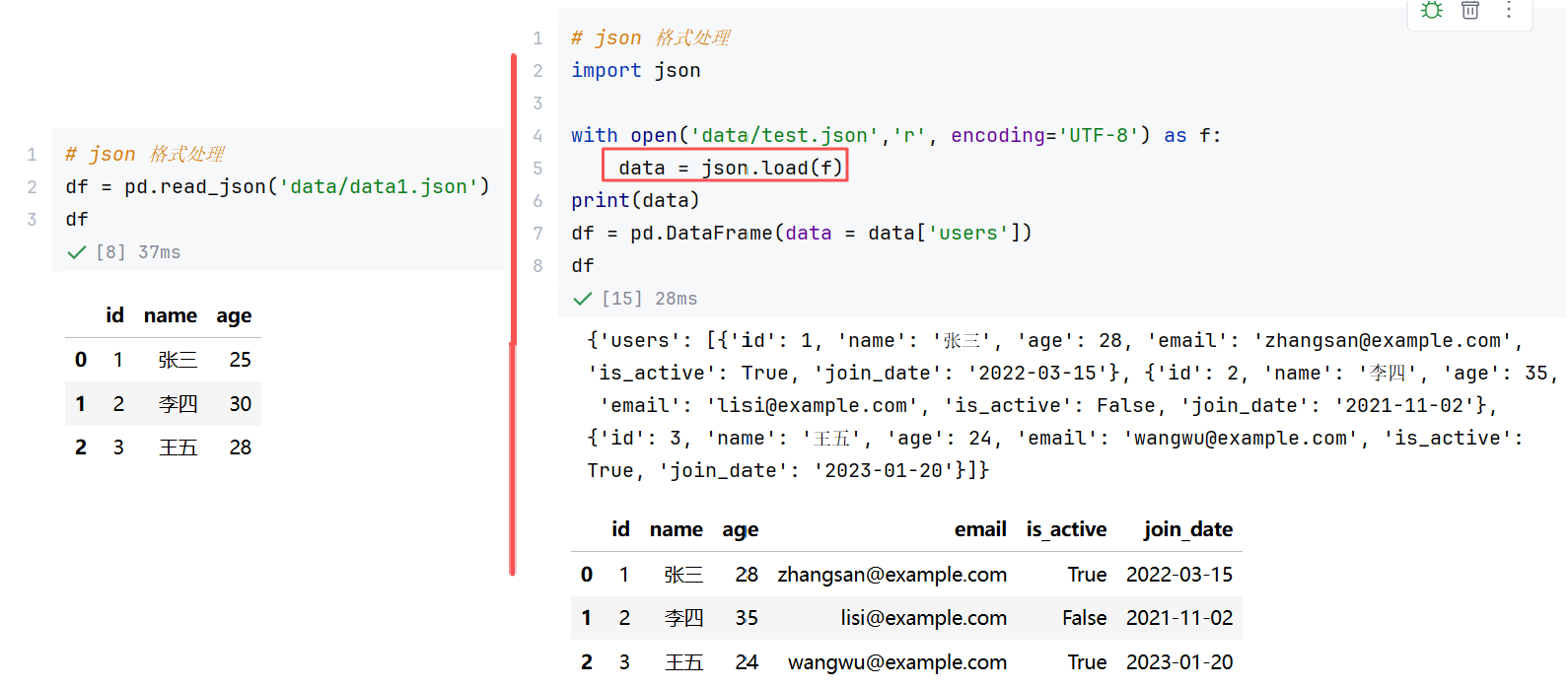
(2)数据清洗
1)缺失值处理
//示例1:剔除缺失值

//示例2:填充缺失值

2) 去重处理
python
df.duplicated() # 完整匹配判重
df.drop_duplicates() # 完整匹配去重,保留第一条
df.drop_duplicates(subset="name") # 指定列去重,保留第一条
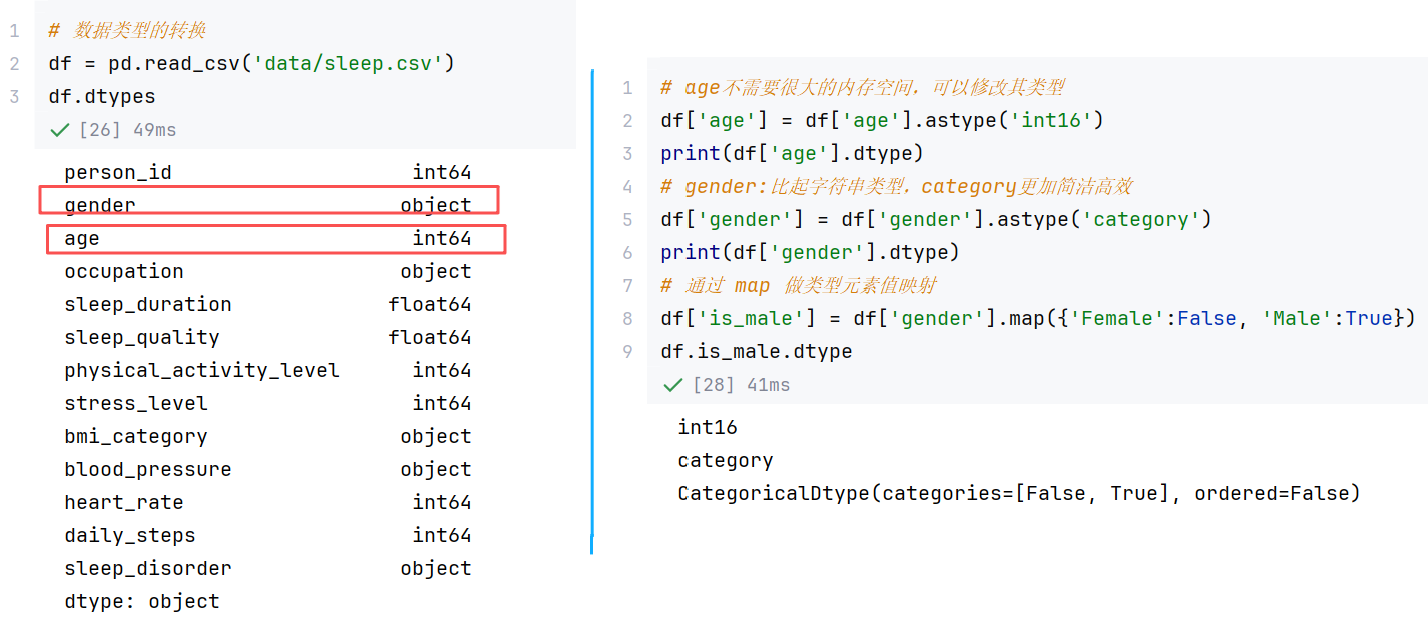
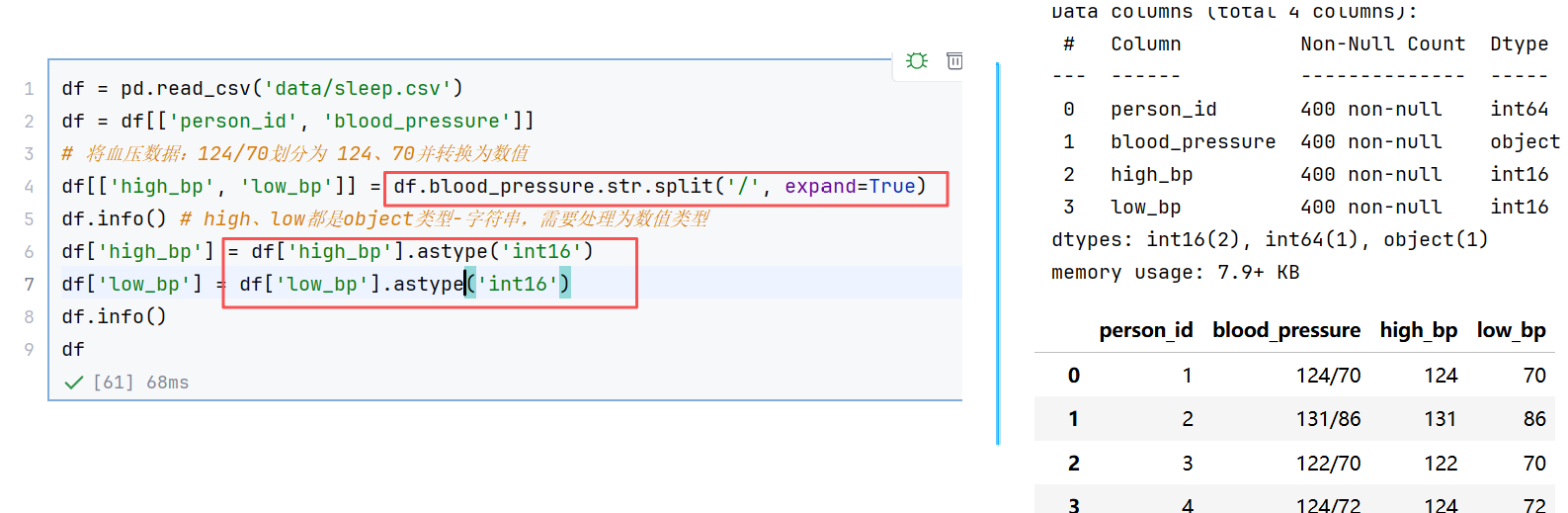
df.drop_duplicates(subset="name", keep="last") # 指定列去重,保留最后一条3)数据类型转换
(4)数据变形
python
data = {
'ID': [1,2],
'name':['alice smith', 'bob smith'],
'Math':[90,85],
'English':[88,92],
'Science':[95,89]
}
df = pd.DataFrame(data)
df
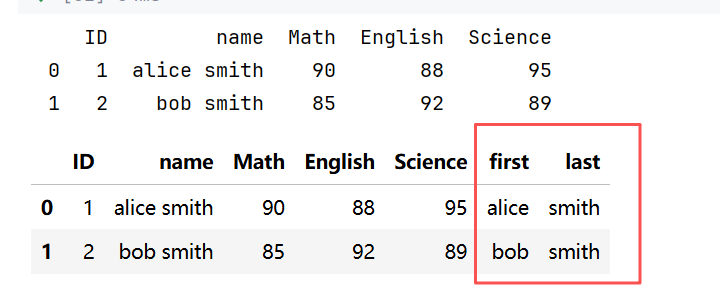
# 分列
# 设置 first、last列,值取name值分割后的前后两部分
df[['first', 'last']] = df['name'].str.split(" ", expand=True)
df//示例1:姓名分列
//示例2:
//示例3:表格属性修改
python
df = pd.DataFrame(
{'name':['Jack', 'Marry', 'Lucy'],
'age':[20,30,40],
'gender':['female','male','female']
})
""" inplace:False(默认):不修改当前对象,返回修改新对象; True:修改当前对象 """
# 1)通过方法设置
# df.set_index:索引重设置
df.set_index("name",inplace=True)
# df.reset_index:恢复默认设置
df.reset_index(inplace=True)
# df.rename:重命名
df.rename(columns={'age':"年龄"},index={0:4}, inplace=True)
# 2)通过修改属性设置
df.index = [1,2,3] # 注意要写全,否则会出错
df.columns = ["姓名", '年龄', '性别']
df(5)数据分箱
python
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
# 生成一组模拟的年龄数据
data = pd.DataFrame({'age': np.random.randint(18, 80, size=100)})
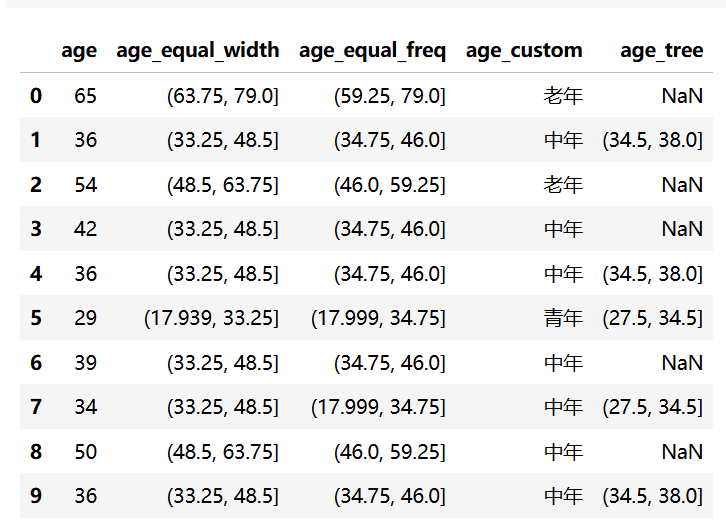
# 1. 等宽分箱:将年龄分为 4 个等宽的区间
data['age_equal_width'] = pd.cut(data['age'], bins=4)
# 2. 等频分箱:将年龄分为 4 个区间,每个区间人数大致相等
data['age_equal_freq'] = pd.qcut(data['age'], q=4)
# 3. 自定义分箱:根据业务需求自定义边界 (如青年、中年、老年)
bins = [0, 30, 50, 100]
labels = ['青年', '中年', '老年']
data['age_custom'] = pd.cut(data['age'], bins=bins, labels=labels)
# 4. 决策树分箱(有监督):假设有目标变量 target
target = np.random.randint(0, 2, size=100)
tree_model = DecisionTreeClassifier(max_leaf_nodes=4)
tree_model.fit(data[['age']], target)
# 提取决策树的分割点作为分箱边界
thresholds = np.sort(tree_model.tree_.threshold[tree_model.tree_.threshold != -2])
data['age_tree'] = pd.cut(data['age'], bins=thresholds)
data.head(10)//分箱统计(数值区间/类别数量):字符串→分类→统计;数值→分箱→统计
(6)时间数据处理
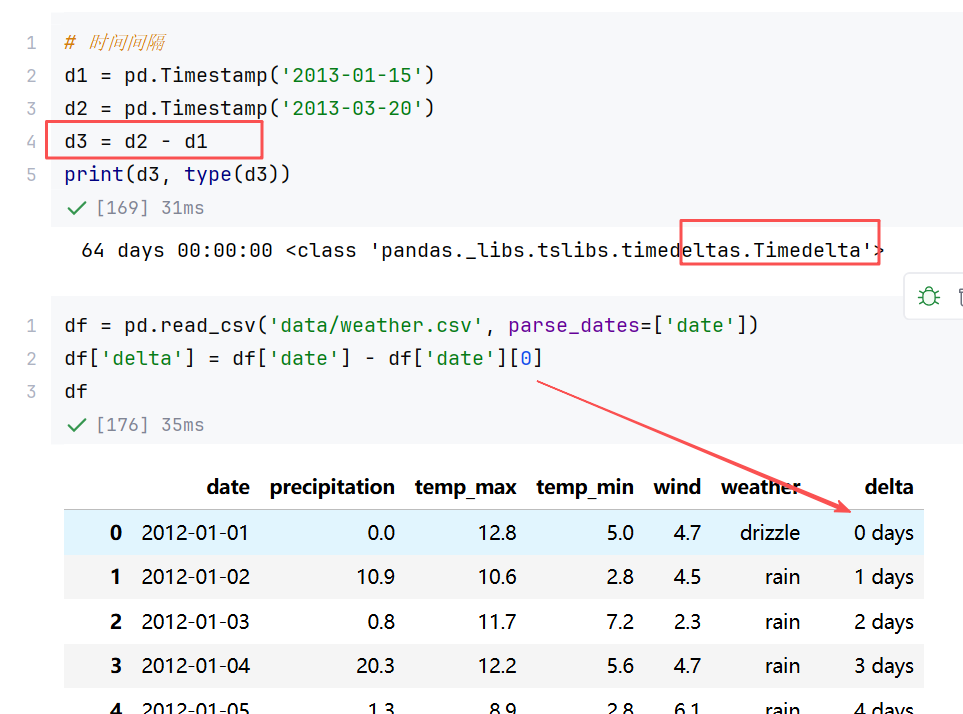
//示例1:日期数据类型转换
python
# 1)字符串 → 日期
a = pd.to_datetime(('2026-05-31 10:52'))
# 2)dataFrame 日期转换
df = pd.DataFrame({
'sales': [100,200,300],
'date':['20160501','20160512','20160531']
})
df['datetime'] = pd.to_datetime(df.date)
print(df.info())
print(df.date.dtype) # datetime64[ns]
print(type(df['datetime'])) # <class 'pandas.core.series.Series'>
# 在DF中使用日期属性需要注意:.dt 使用
df['week'] = df['datetime'].dt.day_name()
df['datetime'].dt.year
# 3) csv 日期转换
# df = pd.read_csv('data/weather.csv')
# df['date'] = pd.to_datetime(df.date) # 转换日期
# ----- 简便写法:指定 date 列按照日期格式解析
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
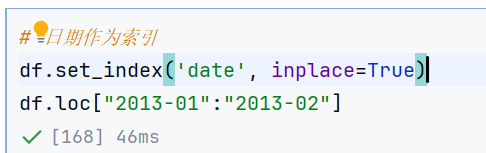
df.date = df.date.dt.day_name()//示例2:日期作为索引
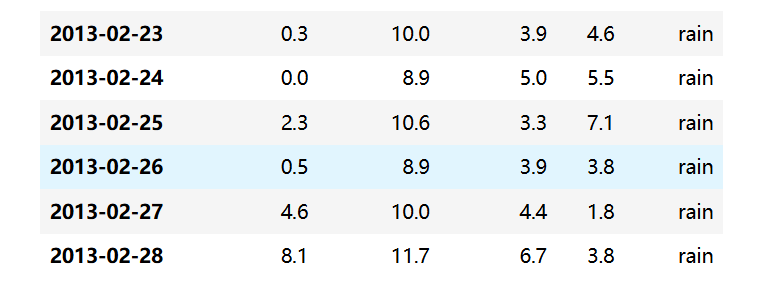
-截取:2013-01~2013-02的数据
//示例3:pd.date_range()-生成固定频率日期时间索引
| 参数 | 说明 |
|---|---|
| start | 生成日期的左侧边界(字符串或日期格式) |
| end | 生成日期的右侧边界(字符串或日期格式) |
| periods | 需要生成的时间周期数量(整数) |
| freq | 频率字符串,默认为 'D'(日历日),支持复合频率如 '2H30min' |
| tz | 时区名称(如 'Asia/Shanghai'),用于生成本地化时间索引 |
| normalize | 布尔值,默认为 False。若为 True,会将起止时间标准化为午夜零点 |
| inclusive | 边界包含规则,可选 {"both", "neither", "left", "right"},默认为 "both" |
| name | 为生成的 DatetimeIndex 指定名称 |
python
import pandas as pd
# 1. 基础用法:生成默认按天递增的日期
print(pd.date_range('20230101', '20230105'))
# 2. 指定周期和频率:生成5个每隔2天的日期
print(pd.date_range(start='20230101', periods=5, freq='2D'))
# 3. 复合频率与边界控制:每2小时30分钟,且左闭右开
print(pd.date_range('20230101 12:00', '20230102 12:00', freq='2H30min', inclusive='left'))
# 4. 特殊频率:生成每月第二个星期一的日期
print(pd.date_range('20230101', '20230401', freq='WOM-2MON'))
# 5. 配合 asfreq 改变频率并填充数据
ts = pd.Series(range(4), index=pd.date_range('20230101', periods=4))
print(ts.asfreq('12H', method='ffill'))//示例4:时间序列降采样-resample
| 参数 | 说明 |
|---|---|
| rule | 频率字符串,如 'D'(天)、'W'(周)、'M'(月)、'YS'(年初)、'5T'(5分钟)等 |
| axis | 重采样的轴,默认为 0(按行/索引重采样) |
| closed | 指定时间区间的哪一端闭合。默认为 'right'(左开右闭),常用于金融数据 |
| label | 指定用哪一端的边界作为聚合后的索引标签(如用9:35标记9:30-9:35的数据) |
| origin | 调整时间分组的起点,如 'start_day'(当天零点)、'epoch'(1970-01-01) |
| on | 如果不想用索引重采样,可指定 DataFrame 中某一列时间类型的列名 |
| offset | 对时间分组的起点添加一个偏移量(如 offset='2min') |
python
import pandas as pd
df = pd.read_csv('data/weather.csv', parse_dates=['date'])
df.set_index('date', inplace=True)
# 1. 降采样:计算每月的最高温均值、最低温均值和温差最大值
monthly_stats = df[['temp_max', 'temp_min']].resample('M').agg({
'temp_max': 'mean',
'temp_min': ['mean', 'max']
})
print(monthly_stats)
print('='*30)
# 2. 降采样:提取每年年初第一天的气温数据
yearly_first = df[['temp_max', 'temp_min']].resample('YS').first()
print(yearly_first)
print('='*30)
# 3. 升采样:将日数据转换为小时数据,并用线性插值填充缺失值
# (注意:实际天气数据升采样插值需谨慎,此处仅作方法演示)
hourly_data = df[['temp_max']].resample('H').interpolate(method='linear')
print(hourly_data.head())
print('='*30)
# 4. 升采样:将日数据转换为小时数据,并向前填充
hourly_ffill = df[['temp_max']].resample('H').ffill()
print(hourly_ffill.head())(7)分组聚合

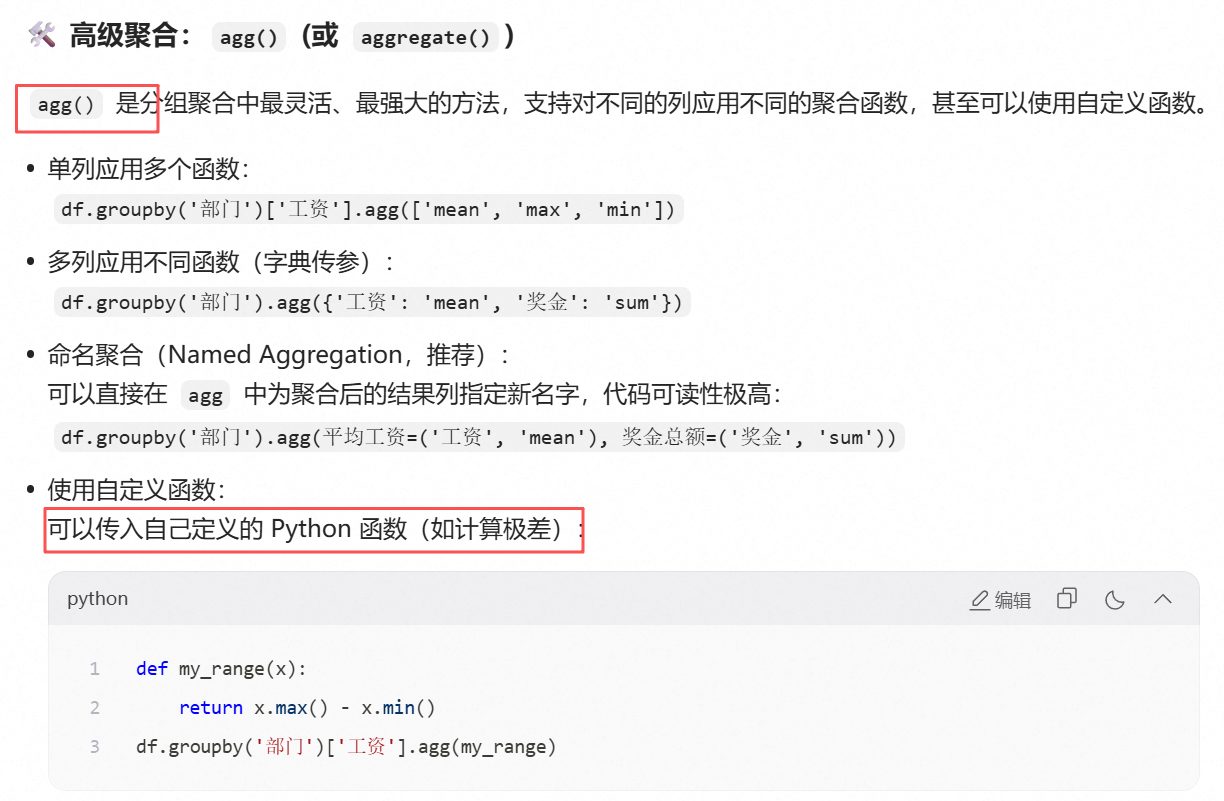

python
import pandas as pd
import numpy as np
# 假设 df 已经加载了数据
# df = pd.read_csv('employees.csv')
# 1. 基础分组:计算每个部门的平均工资
avg_salary = df.groupby('部门')['工资'].mean()
# 2. 多列分组 + 命名聚合:按部门和性别分组,统计工资的均值和奖金的总和
result = df.groupby(['部门', '性别']).agg(
平均工资=('工资', 'mean'),
奖金总和=('奖金', 'sum'),
人数=('姓名', 'count')
).reset_index() # 重置索引,让分组列变回普通列
# 3. 数据转换:为原表新增一列"部门内工资排名"
df['部门内工资排名'] = df.groupby('部门')['工资'].rank(ascending=False)
# 4. 分组过滤:只保留总人数超过 10 人的大部门
big_departments = df.groupby('部门').filter(lambda x: x['姓名'].count() > 10)
# 5. 提取 Top N:获取每个部门工资最高的前 3 名员工
top3_per_dept = df.groupby('部门').apply(lambda x: x.nlargest(3, '工资')).reset_index(drop=True)
print(result)综合案例
//案例1:企鹅数据分析
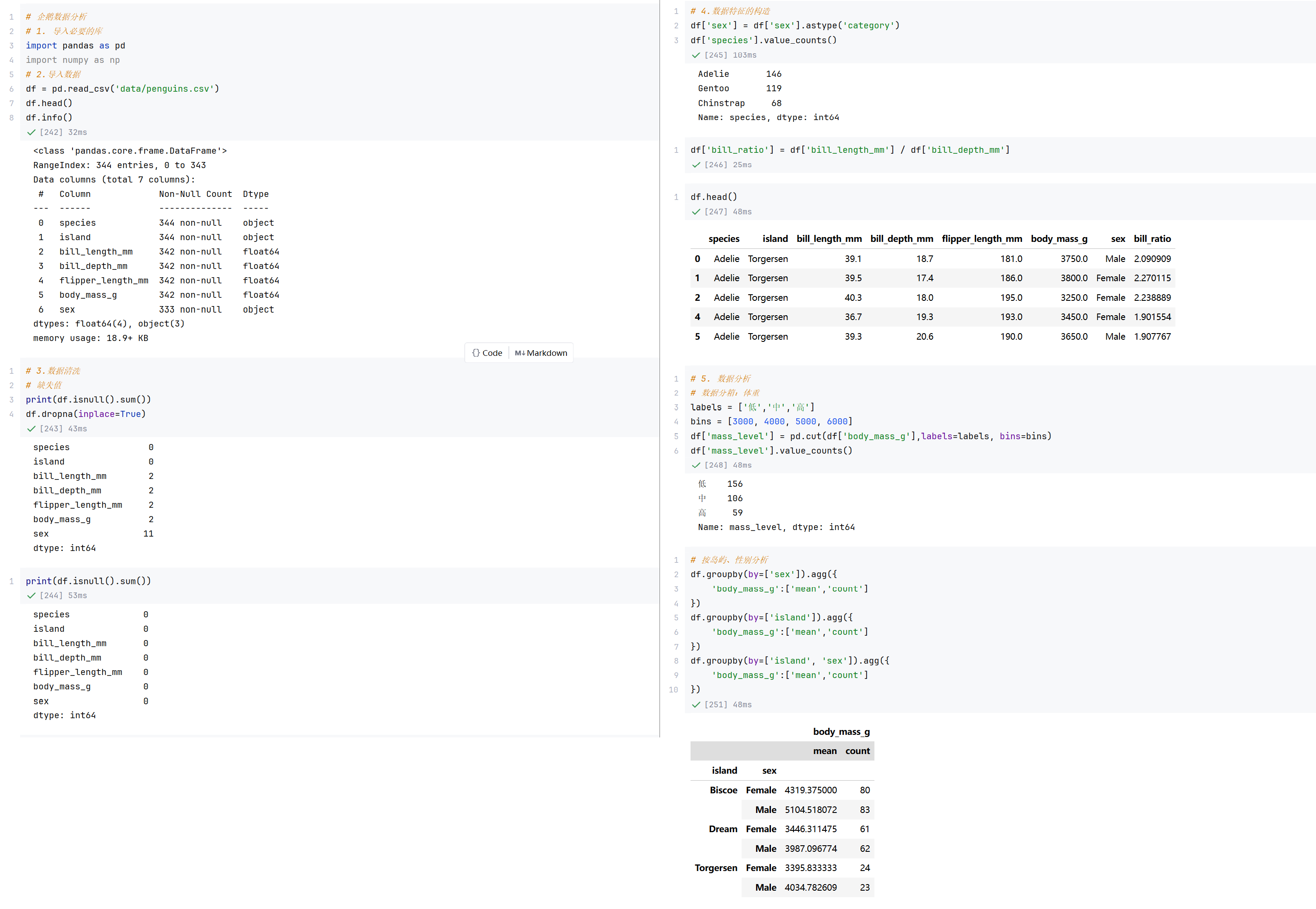
//案例2:睡眠质量分析
3 数据可视化
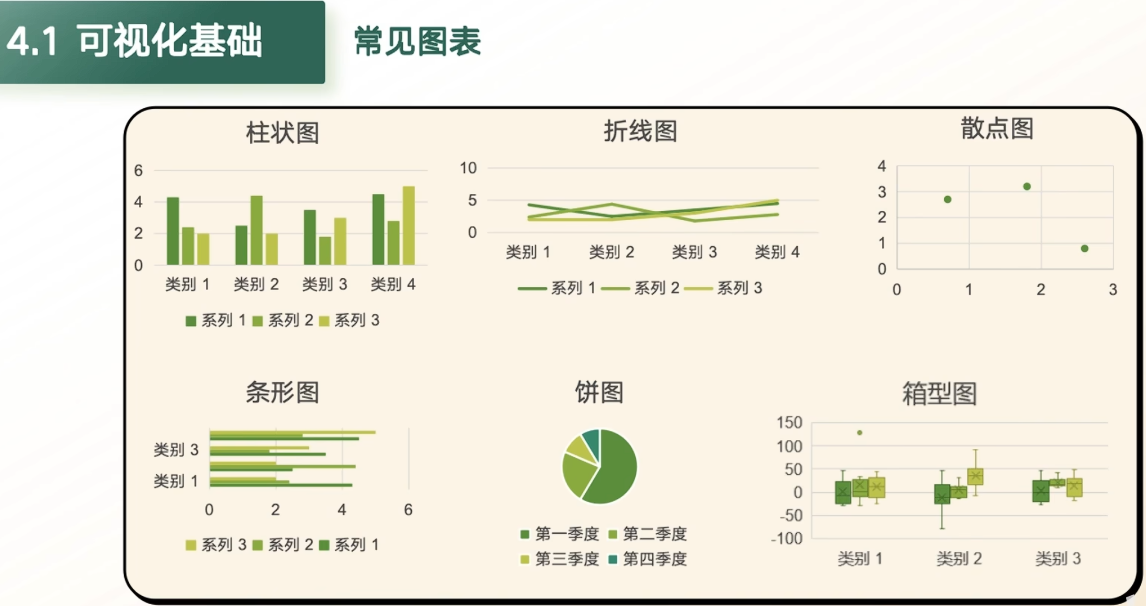
3.1 可视化基础
让数据背后的规律、异常、趋势一目了然。

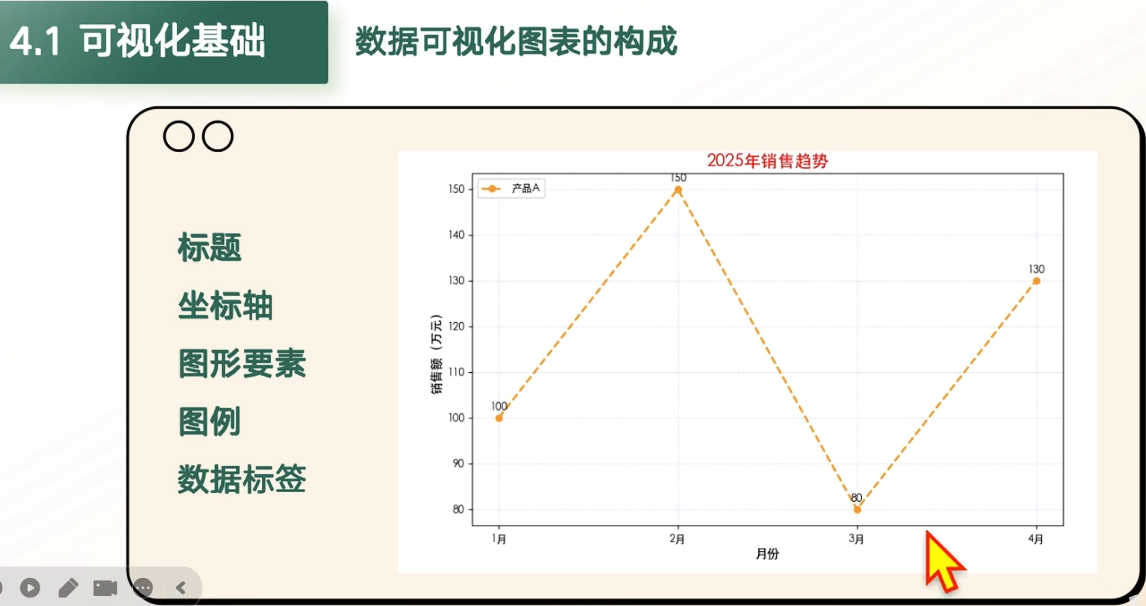

3.2 Matplotlib
(1)折线图
python
# 绘制折线图
import matplotlib.pyplot as plt
from matplotlib import rcParams
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 5))
month = ['1月','2月','3月','4月','5月','6月']
sales = [100,200,150,180,230,195]
# 绘制折线图
plt.plot(month,sales,label='产品A',color='orange',
linewidth=2, linestyle='--',marker='o')
# 添加标题
plt.title('2025年上半年销售趋势', color='red')
plt.xlabel('月份', fontsize=10) # 设置 x轴标签
plt.ylabel('销售额(万元)',fontsize=10) # 设置 x轴标签
plt.legend(loc='upper left') # 图例位置
# 添加网格线:True:横纵都有;axis='x':只有横轴;axis='y':只有纵轴
plt.grid(True,alpha=0.3,color='purple', linestyle='-.')
# 设置刻度字体大小
plt.xticks(rotation=15,fontsize=12)
plt.yticks(rotation=0,fontsize=12)
# 设置 y 轴范围
plt.ylim(50,300)
# 为每个数据点添加数值标记
for x,y in zip(month,sales):
plt.text(x=x, y=y, s=str(y), ha='center', va='bottom', fontsize=12)
# 显示图标
plt.show()
(2)柱状图与条形图
python
# 绘制柱状图
import matplotlib.pyplot as plt
from matplotlib import rcParams
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 5))
subjects = ['语文','数学','英语','科学']
scores = [80, 90, 95, 97]
# 绘制柱状图
plt.bar(subjects,scores,label='小红',color='purple',
width=0.5)
# # 添加标题
plt.title('明明2025年成绩分布', color='red',fontsize=20)
plt.xlabel('科目', fontsize=10) # 设置 x轴标签
plt.ylabel('分数',fontsize=10) # 设置 x轴标签
plt.legend(loc='upper right') # 图例位置
# # 添加网格线:True:横纵都有;axis='x':只有横轴;axis='y':只有纵轴
plt.grid(axis='y',alpha=0.3,color='purple', linestyle='-.')
# # 设置刻度字体大小
plt.xticks(rotation=15,fontsize=12)
plt.yticks(rotation=0,fontsize=12)
# # 设置 y 轴范围
plt.ylim(0,100)
# # 为每个数据点添加数值标记
for x,y in zip(subjects,scores):
plt.text(x=x, y=y, s=str(y), ha='center', va='bottom', fontsize=12)
# 自动优化排版
plt.tight_layout()
# 显示图标
plt.show()
python
# 绘制条形图
import matplotlib.pyplot as plt
from matplotlib import rcParams
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 5))
countries = ['United States', 'China', 'Japan','Germany', 'India']
gdp = [85, 92, 12, 64, 32]
# # 绘制条形图
plt.barh(countries,gdp,color='orange')
# # # 添加标题
plt.title('2025年GDP排名', color='red',fontsize=20)
plt.xlabel('gdp', fontsize=10)
plt.ylabel('国家',fontsize=10)
# 自动优化排版
plt.tight_layout()
# 显示图标
plt.show()
(3)饼图
//饼图:
python
# 绘制饼图
import matplotlib.pyplot as plt
from matplotlib import rcParams
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 5))
# 数据
things = ['学习', '娱乐', '运动','其他', '睡觉']
times = [7,3,1,5,8]
colors = ['#D8BFD8', '#FFF8E7', '#FBCEB1', '#F0FFF0', '#B0C4DE']
# 绘制饼图
plt.pie(times,labels=things,
autopct="%.2f%%", # 显示占比
# startangle=90 # 调整起始角度
colors=colors, # 设置饼图的配色
)
# 添加标题
plt.title("一天的时间分配(饼图)", color="orange", fontsize=15)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()//环形图:
python
# 绘制环形图
import matplotlib.pyplot as plt
from matplotlib import rcParams
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 5))
# 数据
things = ['学习', '娱乐', '运动','其他', '睡觉']
times = [7,3,1,5,8]
colors = ['#D8BFD8', '#FFF8E7', '#FBCEB1', '#F0FFF0', '#B0C4DE']
# 绘制环形图
plt.pie(times,labels=things,
autopct="%.2f%%", # 显示占比
# startangle=90 # 调整起始角度
colors=colors, # 设置饼图的配色
wedgeprops={'width':0.7}, # 设置圆环半径
pctdistance=0.8 # 设置数值与圆心距离
)
# 添加标题
plt.title("一天的时间分配(环形图)", color="orange", fontsize=15)
# 在指定位置添加文字:
plt.text(x=0,y=0,s="总计:\n100%",ha='center',va='center',fontsize=12)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()//爆炸式饼图:
python
# 绘制爆炸式饼图
import matplotlib.pyplot as plt
from matplotlib import rcParams
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 5))
# 数据
things = ['学习', '娱乐', '运动','其他', '睡觉']
times = [7,3,1,5,8]
colors = ['#D8BFD8', '#FFF8E7', '#FBCEB1', '#F0FFF0', '#B0C4DE']
explode = [0.15,0,0,0.1,0] # 设置突出位置
# 绘制爆炸式饼图
plt.pie(times,labels=things,
autopct="%.2f%%", # 显示占比
# startangle=90 # 调整起始角度
colors=colors, # 设置饼图的配色
explode=explode, # 设置突出块
shadow=True
)
# 添加标题
plt.title("一天的时间分配(爆炸式饼图)", color="orange", fontsize=15)
# 自动优化排版
plt.tight_layout()
# 显示图表
plt.show()(4)散点图
python
# 绘制散点图
# 绘制爆炸式饼图
import matplotlib.pyplot as plt
from matplotlib import rcParams
import random
# rcParams['font.family'] = 'SimHei' # 设置字体
rcParams['font.sans-serif'] = 'SimHei' # 设置字体
# 创建图表,设置大小
plt.figure(figsize=(10, 8))
# 数据
x = []
y = []
for i in range(1000):
tmp = random.uniform(0, 10)
x.append(tmp)
y.append(tmp*2 + random.gauss(0,2))
# 绘制散点图
plt.scatter(x=x,y=y,
color='blue',
alpha=0.5,
s=20,
label='数据')
# 添加标题
plt.title("Y变量与X变量的关系", color="orange", fontsize=20)
plt.xlabel(xlabel="x自变量",fontsize=10)
plt.ylabel(ylabel="y因变量",fontsize=10)
# 添加图例
plt.legend(loc='upper left')
# 添加网格线
plt.grid(True,color='#D0F0C0')
# 设置刻度字体大小
plt.xticks(rotation=0.2, fontsize=12)
plt.yticks(rotation=0, fontsize=12)
# 设置y轴的范围
plt.ylim(0, 30)
# 回归线(可选)
plt.plot([0,10], [0,20],color='red',linewidth=2)
# 自动优化排版
plt.tight_layout()
# 显示图标
plt.show()
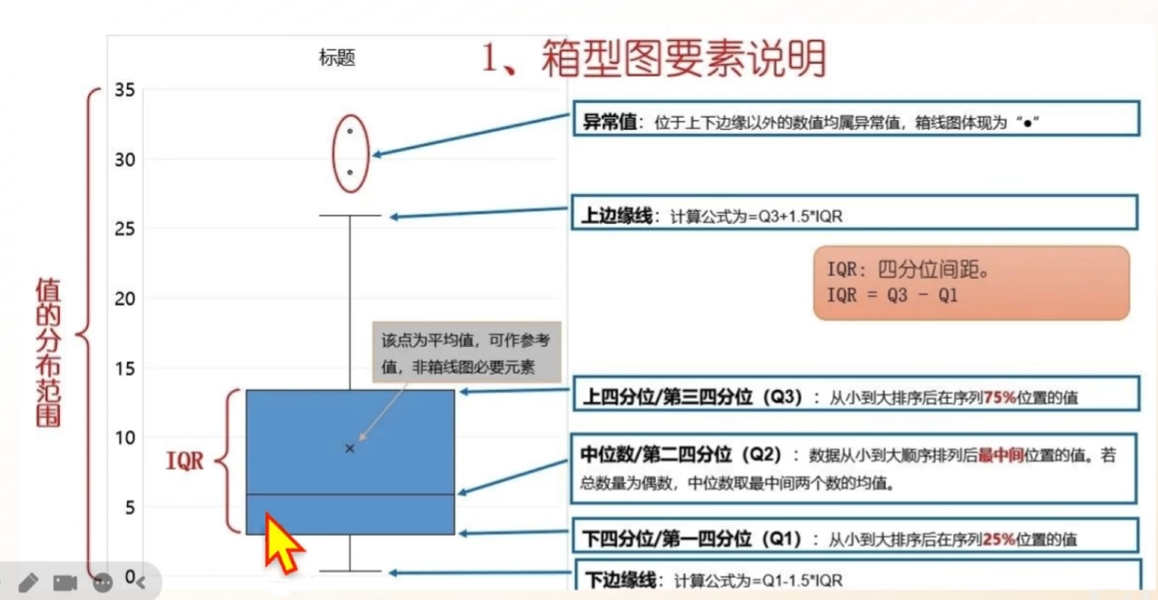
(5)箱x型图
python
# 箱型图
import matplotlib.pyplot as plt
# 模拟 3 门课的成绩
data = {
'语文': [82, 85, 88, 70, 90, 76, 84, 83, 95],
'数学': [75, 80, 79, 93, 88, 82, 87, 89, 92],
'英语': [70, 72, 68, 65, 78, 80, 85, 90, 95]
}
plt.figure(figsize=(8,6))
plt.boxplot(x=data.values(), labels=data.keys())
plt.title("各科成绩分布(箱型图)")
plt.ylabel("分数")
plt.grid(True, axis='y', linestyle='--', alpha=0.5)
plt.show()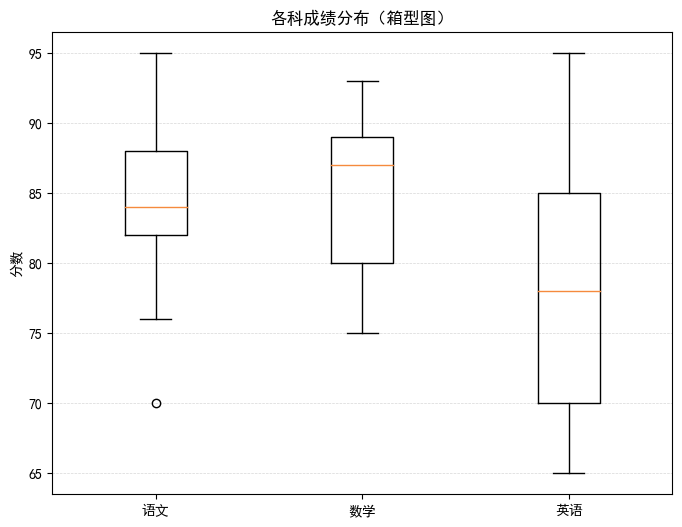
(6)一张画布多个子图
python
# 一张画不上绘制多个图的方法
import matplotlib.pyplot as plt
# 数据
month=['1月','2月','3月','4月']
sales = [100,150,80,130]
# 生成一个子图:划分2行2列,取第x个位置
f1 = plt.subplot(2,2,1)
f1.plot(month,sales)
# f2 = plt.subplot(2,2,2)
f2 = plt.subplot(222) # 写法2
f2.bar(month,sales)
f3 = plt.subplot(2,2,3)
f3.pie(sales,labels=month)
f4 = plt.subplot(2,2,4)
f4.scatter(x=month,y=sales)
plt.show()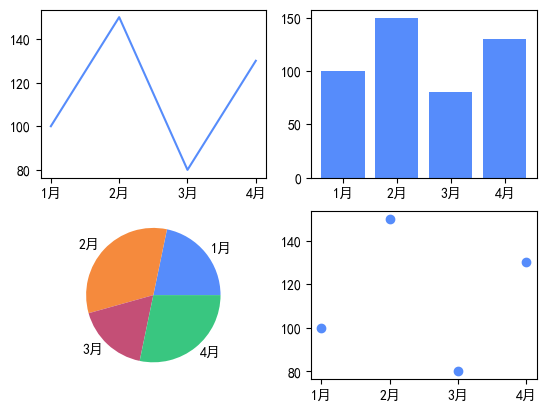
综合案例:
python
# 分析案例:温度分析
# 1.导入库
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import rcParams
# 设置中文字体
rcParams['font.sans-serif'] = 'SimHei'
# 解决负号显示异常的问题(关键步骤)
rcParams['axes.unicode_minus'] = False
# 2.导入数据
df = pd.read_csv('data/weather.csv',na_values=['None','NAN','NA'])
df.head()
# df.isnull().sum()
plt.figure(figsize=(20, 10))
# 1)绘制气温的趋势变化图
# 数据
df['date'] = pd.to_datetime(df['date'])
df = df[df['date'].dt.year == 2015]
date = df['date']
temp_max, temp_min = df['temp_max'], df['temp_min']
temp_mean = (temp_max + temp_min) / 2
# 绘制折线图
plt.plot(date,temp_max, label='最高气温')
plt.plot(date,temp_min, label='最低气温')
plt.plot(date,temp_mean, label='平均气温')
plt.title("2015年气温趋势变化图", fontsize=30)
# 坐标标签
plt.xlabel('日期',fontsize=15)
plt.ylabel('降水量(cm)', fontsize=20)
# 设置刻度字体大小
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.legend(loc='upper left')
# 显示图表
plt.show()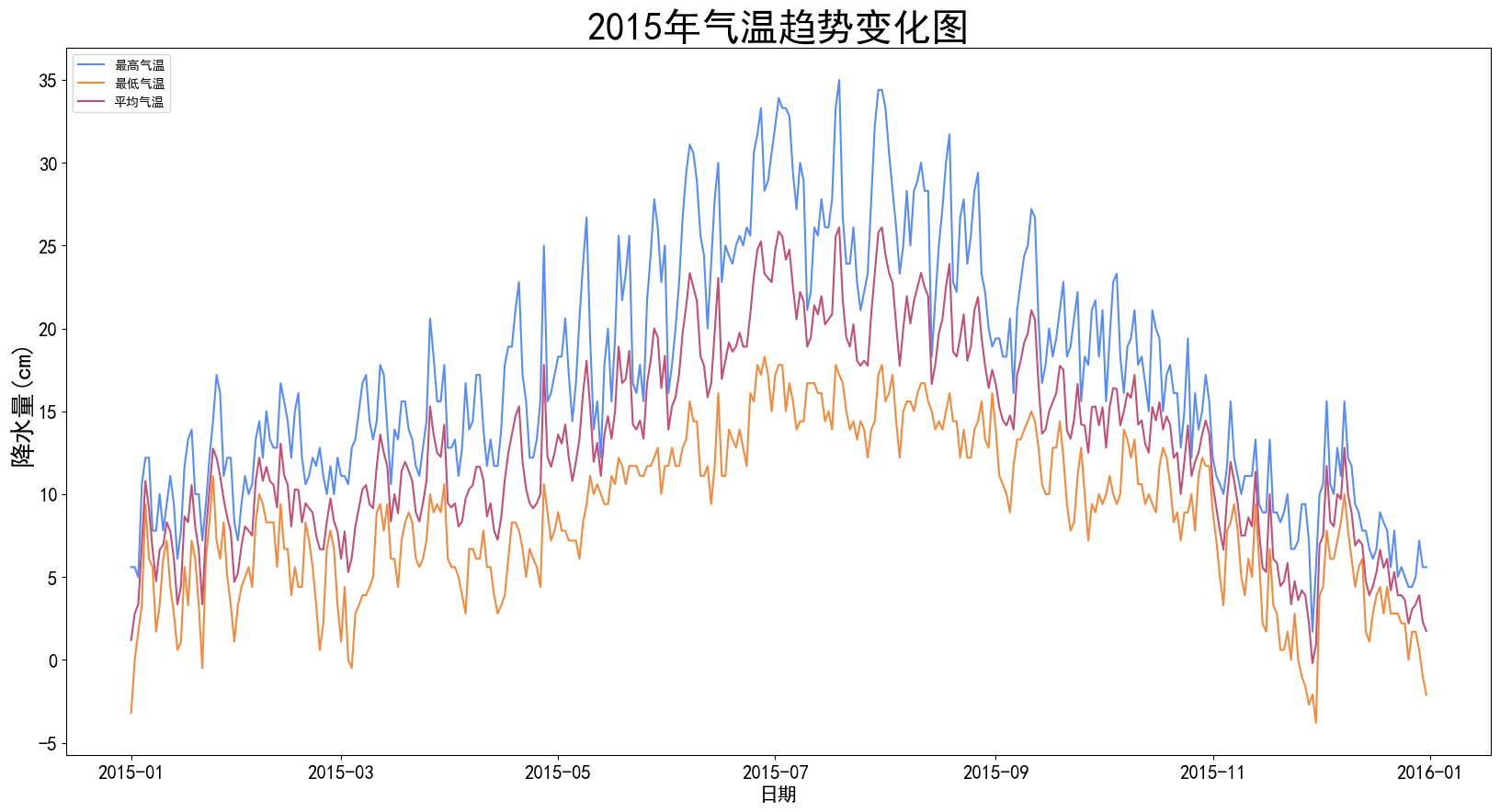
//直方图:
python
# 2)绘制降水量的直方图
plt.hist(df['precipitation'], bins=5)
# 效果:对数据做分箱处理后分区间显示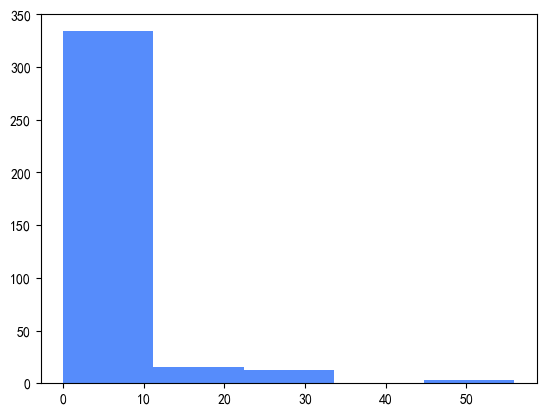
3.3 Seaborn
导包与数据准备:
python
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 设置全局主题为带白色网格的风格
sns.set_style("whitegrid")
penguins = pd.read_csv('data//penguins.csv')
penguins.dropna(inplace=True)
penguins.info()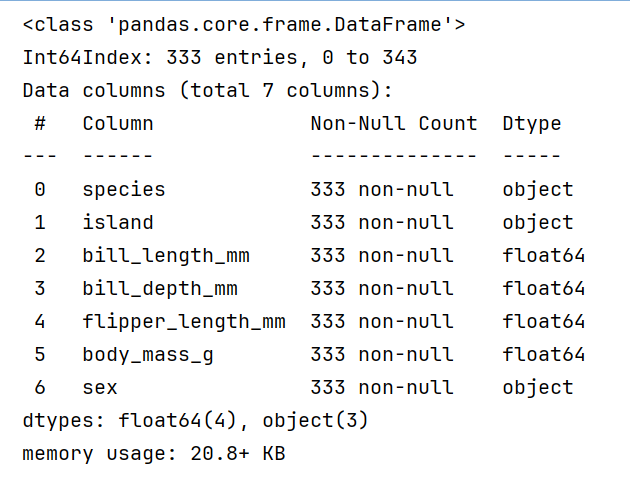
Seaborn 提供了非常丰富的绘图接口,通常被划分为五大类。
(1)关系类图表
主要用于展示两个连续变量之间的关系。
①折线图
python
# 折线图 (lineplot):常用于展示数据随时间或连续变量的变化趋势。
sns.lineplot(data=penguins, x='bill_length_mm', y='body_mass_g')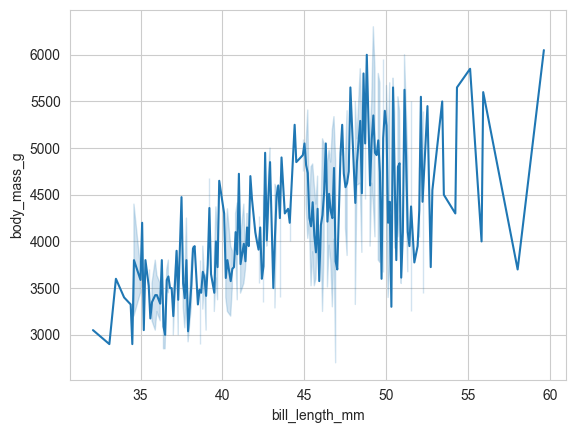
②散点图
python
# 散点图 (scatterplot):观察变量间的分布和相关性。
sns.scatterplot(data=penguins, x='bill_length_mm', y='body_mass_g', hue='species')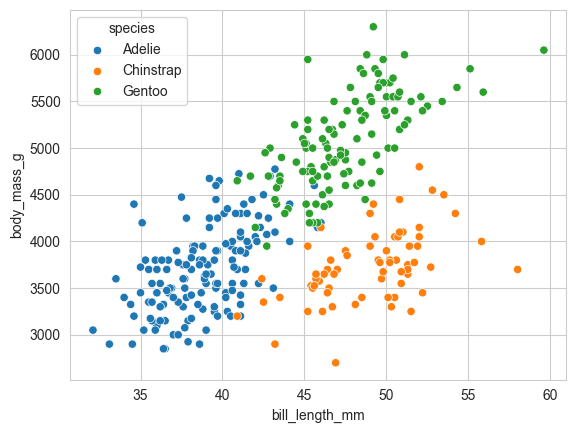
(2)分类图表
主要用于展示一个分类变量和一个(或两个)数值变量之间的关系。
①箱线图
python
# 箱线图 (boxplot):展示数据的分布情况(中位数、四分位数、异常值等)。
sns.boxplot(data=penguins, x='species',y='flipper_length_mm')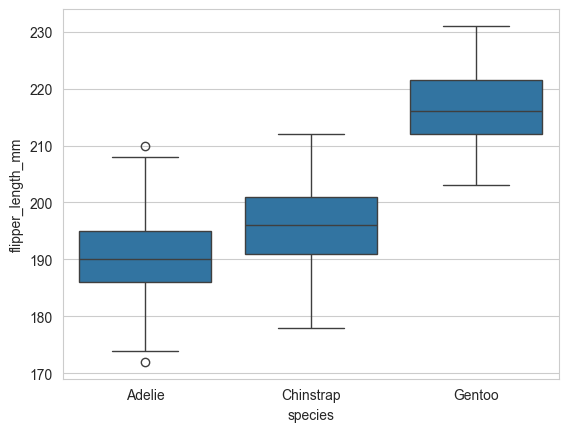
②条形图
python
# 条形图 (barplot):展示分类数据的平均值及置信区间。
sns.barplot(data=penguins, x='species', y='body_mass_g', hue='sex')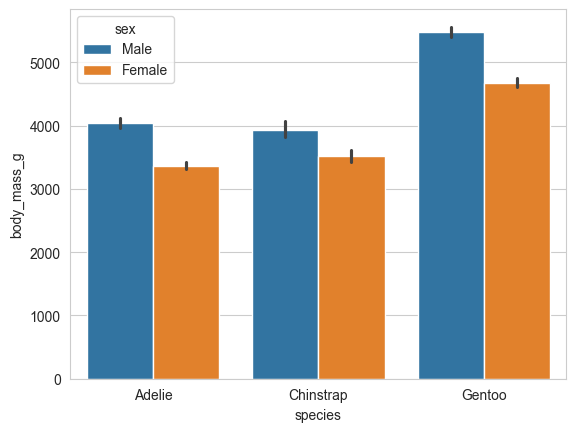
③小提琴图
python
# 小提琴图 (violinplot):结合了箱线图和核密度估计,能更好地展示数据分布形态。
sns.violinplot(data=penguins, x='species', y='flipper_length_mm')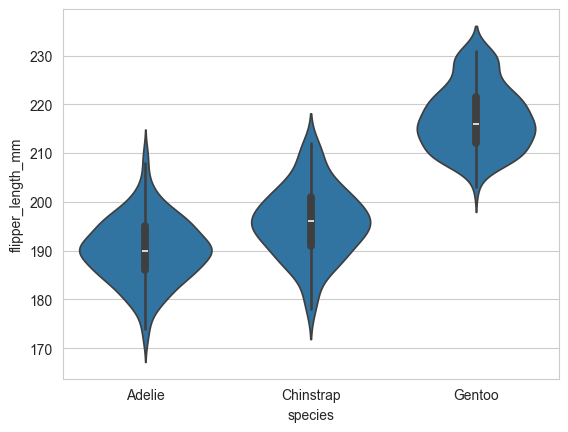
④计数图
python
# 计数图 (countplot):直接统计并展示每个分类下的样本数量。
sns.countplot(data=penguins, x='island')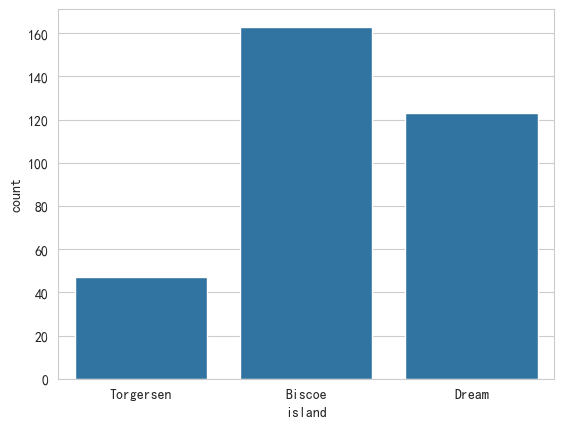
⑤分簇散点图
python
# 分簇散点图 (swarmplot):展示所有数据点,且点之间不重叠,适合样本量不大的情况。
sns.swarmplot(data=penguins, x='species', y='flipper_length_mm')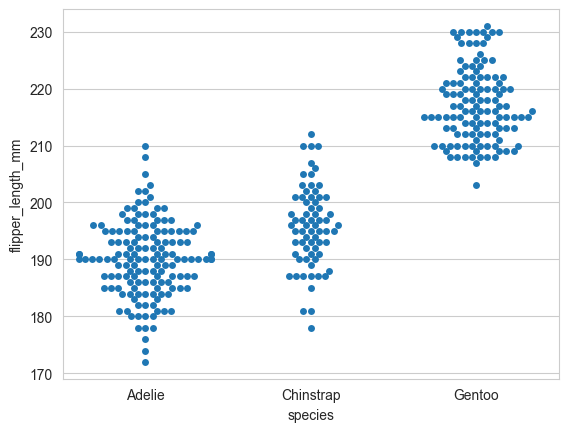
(3)分布图表
主要用于观察单变量或双变量的数据分布情况。
①直方图
python
# 直方图 (histplot):展示单变量的频数分布。
sns.histplot(data=penguins, x='species')
python
# # kde=True 叠加核密度曲线
sns.histplot(data=penguins, x='bill_length_mm', kde=True)
②核密度估计图
python
# 核密度估计图 (kdeplot):用平滑的曲线来展示数据的概率密度分布。
sns.kdeplot(data=penguins, x='bill_length_mm')
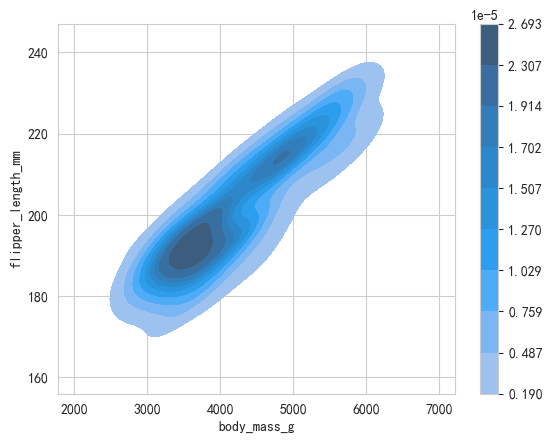
- 二维核密度估计图
python
# 二维核密度估计图(2D KDE Plot):是一种用于展示双变量联合分布的统计图表。它通过平滑的颜色渐变或等高线,直观地呈现数据在二维空间中的聚集程度和分布形态。
sns.kdeplot(data=penguins, x='body_mass_g', y='flipper_length_mm')
# 设置填充(变形式):
sns.kdeplot(data=penguins, x='body_mass_g',
y='flipper_length_mm',fill=True, cbar=True)
③双变量关系图
python
# 双变量关系图 (jointplot):同时展示两个变量的联合分布以及各自边缘的单变量分布。
sns.jointplot(data=penguins, x='body_mass_g',
y='flipper_length_mm', hue='species')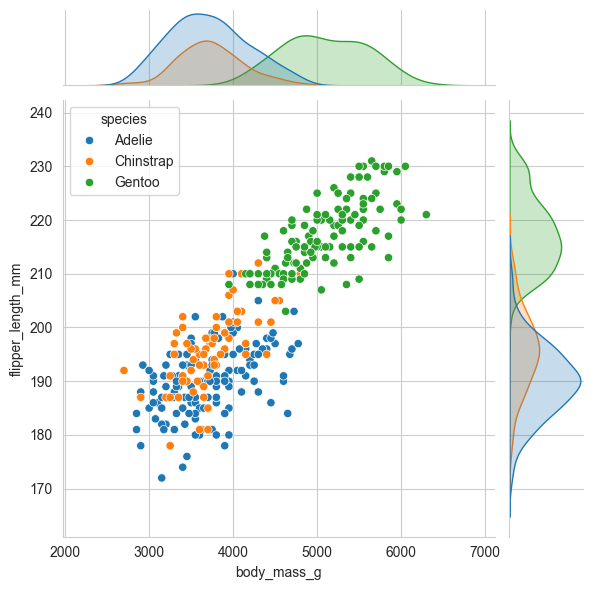
④变量关系图
python
# 变量关系组图 (pairplot):一次性绘制数据集中所有数值变量两两之间的关系。
sns.pairplot(data=penguins, hue='species')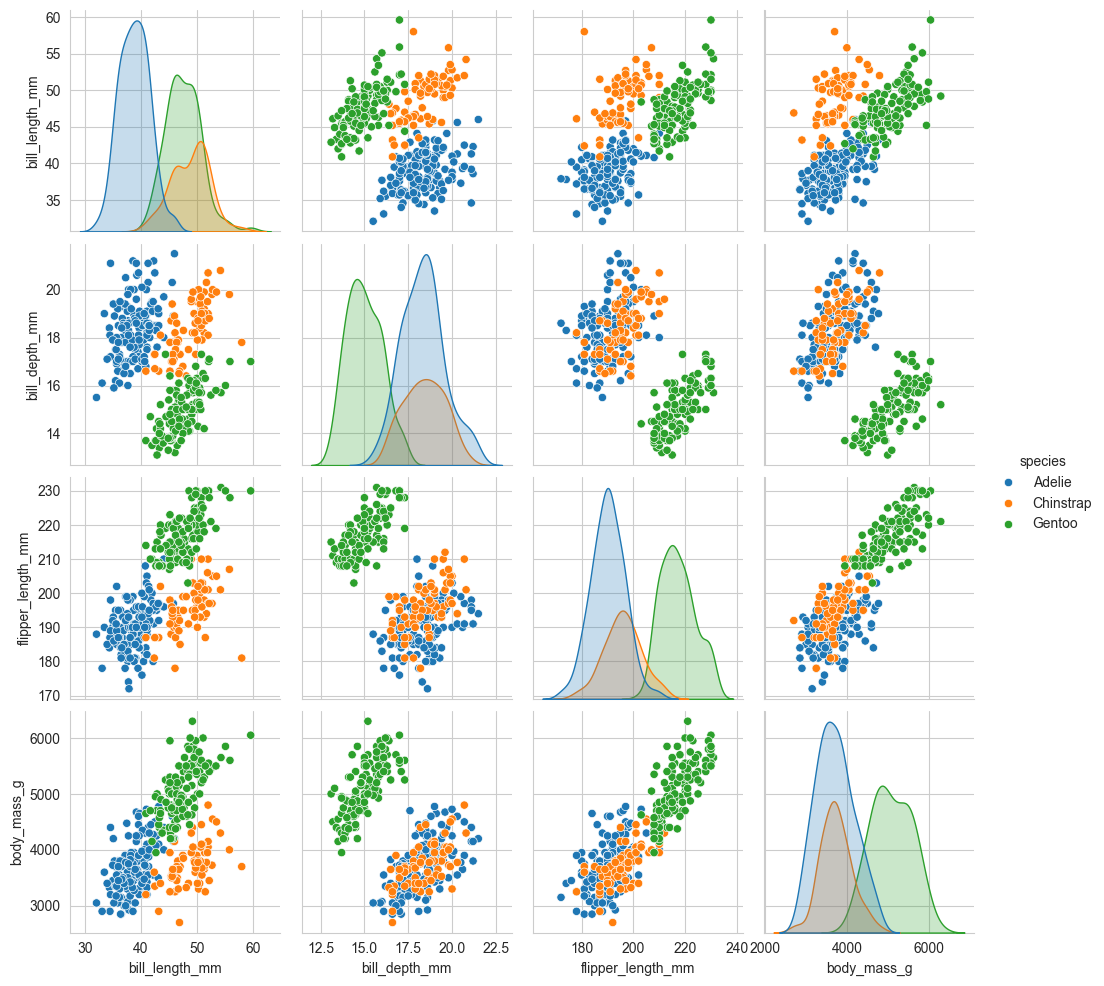
⑤蜂窝图
python
# 蜂窝图:蜂窝图非常适合在数据量巨大、散点图出现严重重叠时使用。它通过将平面划分为六边形网格,并用颜色的深浅来展示该区域内数据点的密度。
# 通过jontplot()函数,设置Kind='hex'来绘制蜂窝图
sns.jointplot(data=penguins, x='body_mass_g',
y='flipper_length_mm', kind='hex')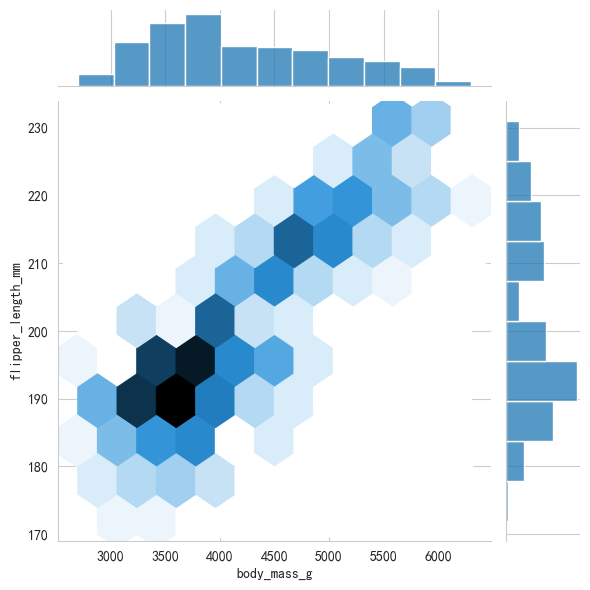
(4)回归图表
①线性回归图
python
# 线性回归图 (regplot):绘制散点图并拟合一条线性回归线。
sns.regplot(data=penguins, x='body_mass_g', y='flipper_length_mm')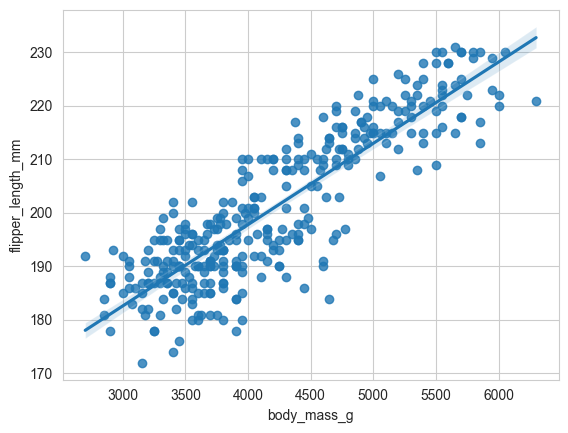
②回归模型图
python
# 回归模型图 (lmplot):在 regplot 的基础上增加了分面(Facet)功能,可以按分类变量绘制多张图。
sns.lmplot(data=penguins, x='body_mass_g', y='flipper_length_mm', hue='species')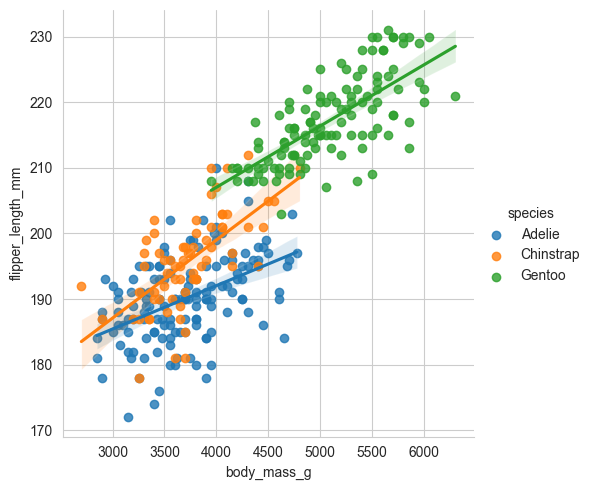
(5)矩阵图表
主要用于展示矩阵形式的数据。
- 热力图
python
# 热力图 (heatmap):通过颜色深浅来展示矩阵数据的大小,常用于相关性分析。
corr = penguins.select_dtypes(include='number').corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')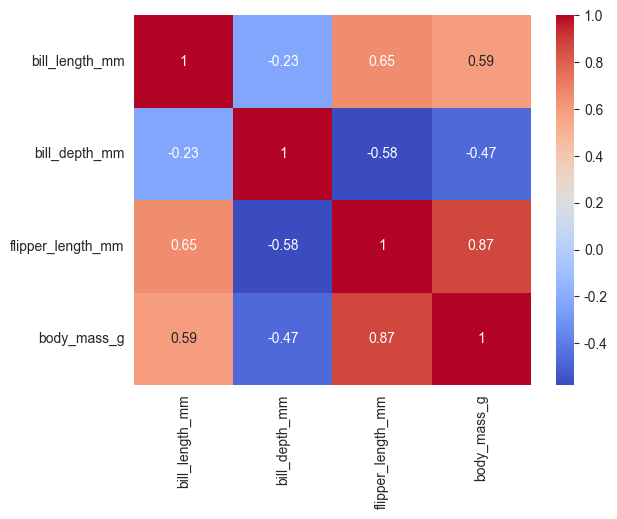
Seaborn 常用图表适用场景
(1)数据的分布情况(单变量分析)
- 直方图 (
histplot):最基础的分布图。想看数据主要集中在哪个区间、是否有偏态(左偏/右偏)时使用。- 核密度估计图 (
kdeplot): 想看平滑的分布趋势,或者想在一个图里优雅地对比多个类别的分布形态(比直方图更简洁)。- 箱线图 (
boxplot):找异常值的神器。想看数据的中位数、四分位数,以及快速识别出哪些数据点是离群的"极端值"。- 小提琴图 (
violinplot): 箱线图的"升级版"。既想看汇总统计(中位数),又想看数据的真实密度形状(比如数据是不是双峰分布)。(2)两个变量得到关系(双变量分析)
- **散点图 (
scatterplot):**数据量适中时,想看两个连续变量(如身高和体重)之间有没有线性关系、聚类趋势。- 蜂窝图 (
jointplot, kind='hex'):大数据集(成千上万条数据)。当散点图重叠严重变成"一团黑"时,用它通过六边形网格的深浅来展示密度。- 二维核密度图 (
kdeplot填充模式): 同样用于大数据集,但想看平滑连续的联合概率分布,而不是蜂窝状的网格。- 回归图 (
regplot/lmplot): 在散点图的基础上,想看拟合的线性趋势线以及置信区间,判断变量间的相关性强弱。(3)对比不同类别的差异(分类数据分析)
- 条形图 (
barplot): 对比不同类别(如不同部门、不同年份)的平均值或总和的大小。- 计数图 (
countplot): 其实就是"分类数据的直方图"。想看每个类别下有多少条数据(比如统计男女各有多少人)。- 蜂群图 (
swarmplot):小样本数据 。想在展示分类分布的同时,清晰地看到每一个具体的数据点,且点与点之间不重叠。(4)整体规律与趋势(多变量/时间序列)
- 相关性热力图 (
heatmap):特征工程必备。一次性查看数据集中所有数值变量之间的相关系数,快速找出哪些特征高度相关(颜色越深越相关)。- **配对图 (
pairplot):**探索性数据分析(EDA)的"核武器"。一次性画出所有特征两两之间的关系图,快速发现数据中的聚类或线性模式。- 折线图 (
lineplot):时间序列数据。想看某个指标随时间(如月份、年份)变化的趋势和波动。
4 项目实战:房地产市场洞察与价值评估
数据分析流程
- 采集数据→确定分析方向→导入数据→数据清洗→数据分析→数据可视化
4.1 数据源介绍
|------------|--------|-------------------------|
| 字段名 | 含义 | 说明 |
| city | 城市 | 房屋所在的城市名称,例如"合肥"、"重庆"等。 |
| province | 省份 | 房屋所在的省份或直辖市名称。 |
| address | 详细地址 | 房屋的具体位置,包含街道、交叉口等信息。 |
| name | 小区名称 | 房屋所在的小区或楼盘名称。 |
| area | 面积 | 房屋的面积,单位为平方米(㎡)。 |
| floor | 楼层 | 房屋所在的楼层信息,例如"中层(共18层)"。 |
| rooms | 户型 | 房屋的户型结构,例如"3室2厅"。 |
| toward | 朝向 | 房屋的朝向,例如"南北向"、"南向"等。 |
| year | 建造年份 | 房屋的建造年份,例如"2013年建"。 |
| price | 价格 | 房屋的总价,单位为"万"或"元"。 |
| unit | 单价 | 房屋的单价,单位为"元/㎡"。 |
| origin_url | 原始链接 | 房屋信息的来源网页链接。 |
4.2 分析及统计问题
| 编号 | 问题 | 分析主题 | 分析目标 |
|---|---|---|---|
| A1 | 哪些变量最影响房价?面积、楼层、房间数哪个影响更大? | 特征相关性 | 了解房屋各特征对房价的影响程度,明确核心影响因素 |
| A2 | 全国房价总体分布是怎样的?是否存在极端值? | 描述性统计 | 概览数值型字段的分布特征,识别异常值与数据整体情况 |
| A3 | 哪些城市房价最高?直辖市与非直辖市差异如何? | 城市对比 | 比较不同城市房价水平,分析直辖市与非直辖市的房价差异 |
| A4 | 高价房在面积、楼层等方面有什么特征? | 价格分层 | 识别不同价位房屋的核心特征,明确高价房的典型属性 |
| A5 | 哪种户型最受欢迎?三室比两室贵多少? | 户型分析 | 分析不同户型的市场热度,量化不同户型的价格差异 |
| A6 | 南北向是否真比单一朝向贵?贵多少? | 朝向溢价 | 评估不同朝向的价格差异,量化南北向的溢价水平 |
| A7 | 新房比 10 年老房贵多少?折旧规律如何? | 楼龄效应 | 研究建筑年份对房价的影响,明确房龄的折旧规律与价格差异 |
| A8 | 哪些区域交易最活跃?新区和老城区哪个更贵? | 区域热度 | 识别各城市热门交易区域,对比新区与老城区的房价差异 |
| A9 | 哪个面积段的性价比最高?超大户型有溢价吗? | 面积区间 | 分析不同面积段的价格表现,评估各面积段的性价比与溢价情况 |
| A10 | 中层真的比高层贵吗?差价是多少? | 楼层差异 | 比较不同楼层的价格表现,量化不同楼层的价格差异 |
4.3 数据分析与可视化
(1)导入库
python
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import rcParams
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False(2)导入数据
python
df = pd.read_csv('data/house_sales.csv')(3)数据概览
python
print("总记录数:", len(df))
print("字段数量:",df.columns.size)
df.head()
df.info()
(4)数据清洗
//1:删除无用列
python
# 删除无用列
df.drop(columns=['origin_url'], inplace=True)//2:缺失值处理
python
# 缺失值检查
print("缺失值情况:\n", df.isnull().sum())
python
# 删除缺失值
df.dropna(inplace=True)//3:重复值处理
python
# 重复值检查
df.duplicated().sum()
# 删除重复值
df.drop_duplicates(inplace=True)//4:数据类型转换
python
# 数据类型转换
df['area'] = df['area'].str.replace('㎡','').astype(float) # 面积
df['price'] = df['price'].str.replace('万','').astype(float) # 售价
df['toward'] = df['toward'].astype('category')
df['unit'] = df['unit'].str.replace('元/㎡','').astype(float)
df['year'] = df['year'].str.replace('年建','').astype('int16')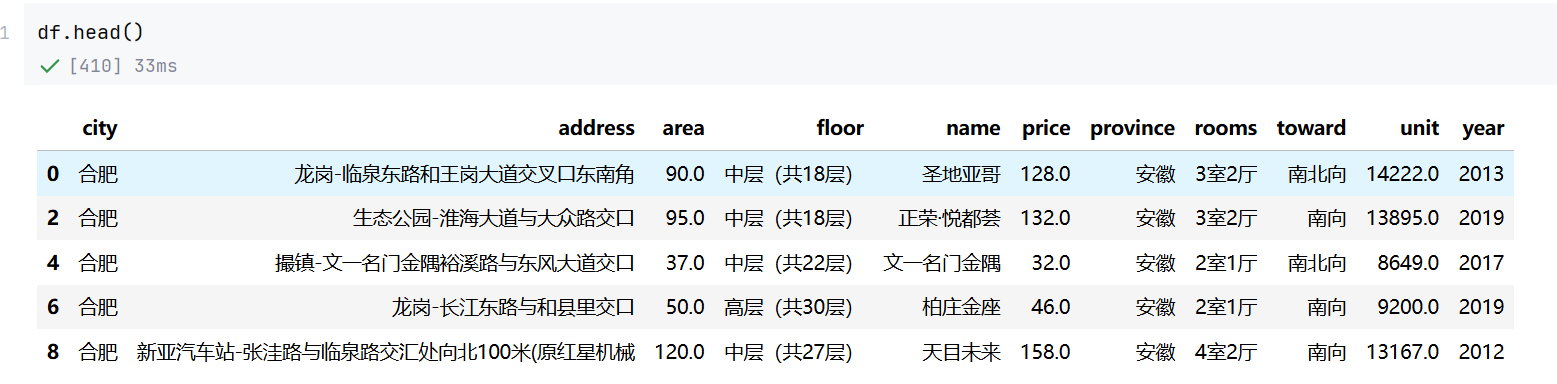
//5:异常值处理
python
# 异常值的处理
# 房屋面积的异常处理(经验值)
df = df[(df['area'] > 20) & (df['area'] < 600)]
# 房屋售价的异常处理(异常值IQR)
Q1 = df['price'].quantile(0.25)
Q3 = df['price'].quantile(0.75)
IQR = Q3 - Q1
low_price = Q1 - 1.5 * IQR
high_price = Q3 + 1.5 * IQR
df = df[(df['price'] >low_price) & (df['price']<high_price)](5)数据特征构造
python
# 1)地区 district
df['distric'] = df['address'].str.split('-').str[0]
# 2)楼层的类型 floor_type
# 写法1:
df['floor_type'] = df['floor'].str.split('(').str[0]
# 写法2:
# df['floor_type'] = df['floor'].str[:2]
# 写法3:
# def func(s):
# if '低' in s:
# return '低层'
# elif '中' in s:
# return '中层'
# elif '高' in s:
# return '高层'
# else:
# return '未知'
# df['floor'].apply(func)
# 转为分类类型
df['floor_type'] = df['floor_type'].astype('category')
# 3)是否是直辖市 zxs
df['zxs'] = df['city'].apply(lambda x: x in ['重庆','天津','上海','北京'])
# 4)卧室的数量bedrooms
df['bedrooms'] = df['rooms'].str.split('室').str[0].astype(int)
# 5)客厅的数量 livingrooms
df['livingrooms'] = df['rooms'].str.extract(r'(\d+)厅').astype(int)
# 6)楼龄 building_age
df['building_age'] = 2026 - df['year']
# 7)价格的分段 price_labels
df['price_labels'] = pd.cut(df['price'], labels=['低价','中价','高价', '豪华'], bins=4)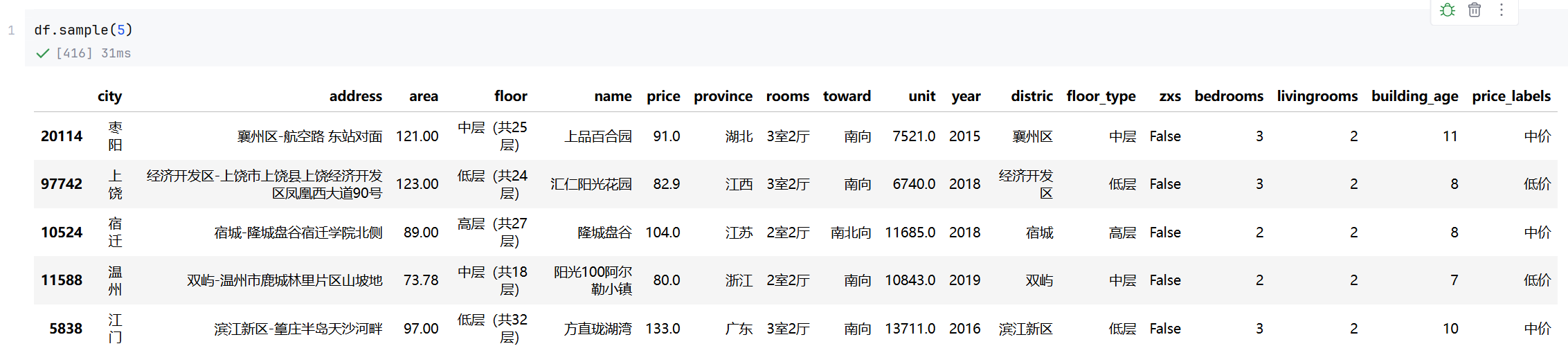
(6)问题分析与可视化
python
"""
问题编号:A1
问题:哪些变量最影响房价?面积、楼层、房间数哪个影响更大?
分析主题:特征相关性
分析目标:了解房屋各特征对房价的线性影响
分组字段:无
指标/方法:皮尔逊相关系数
"""
# 选择数值型特征
corr_v = df[['area', 'price', 'unit', 'building_age']].corr()
# 对房价的影响最大的几个因素的排序
corr_v['price'].sort_values(ascending=False)[1:]
# 相关性的热力图
plt.figure(figsize=(5,5))
sns.heatmap(corr_v, cmap='coolwarm')
plt.title('房屋特征相关性热力图')
plt.tight_layout()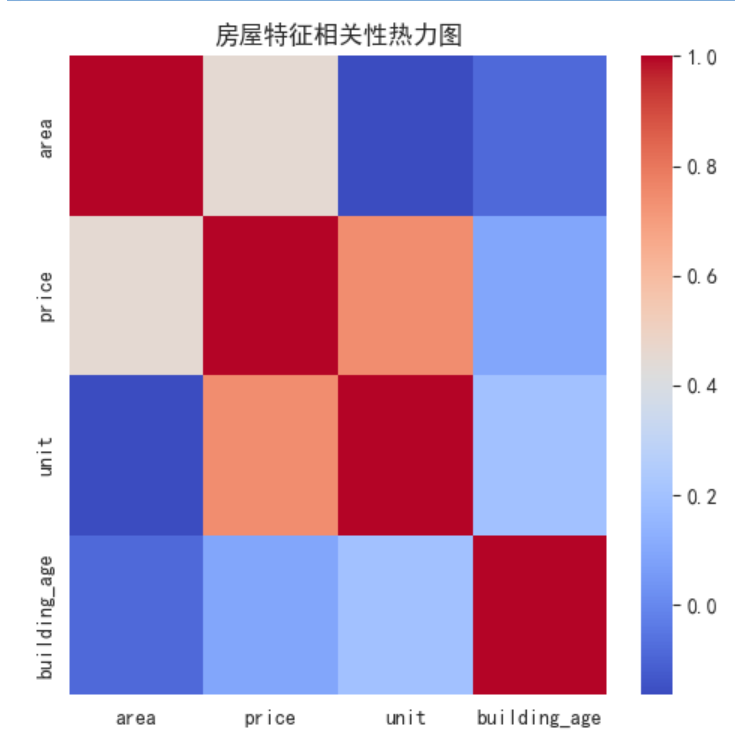
python
"""
问题编号:A2
问题:全国房价总体分布是怎样的?是否存在极端值?
分析主题:描述性统计
分析目标:概览数值型字段的分布特征
分组字段:无
指标/方法:平均数/中位数/四分位数/标准差"""
df['price'].describe()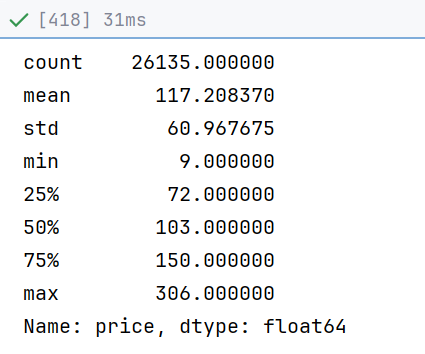
python
# 房价分布的直方图
plt.subplot(111)
plt.hist(df['price'], bins=10)
python
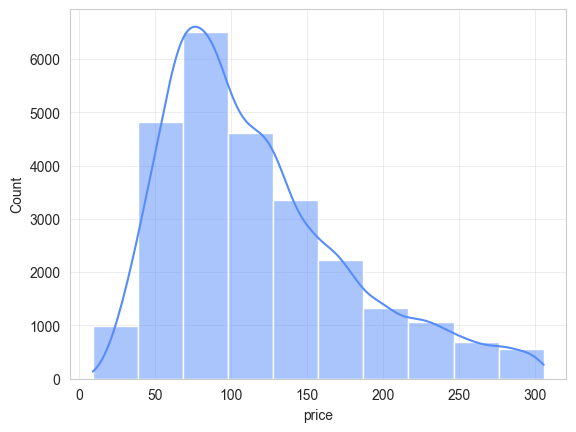
# 设置核密度曲线的直方图
sns.histplot(data=df, x='price',bins=10, kde=True)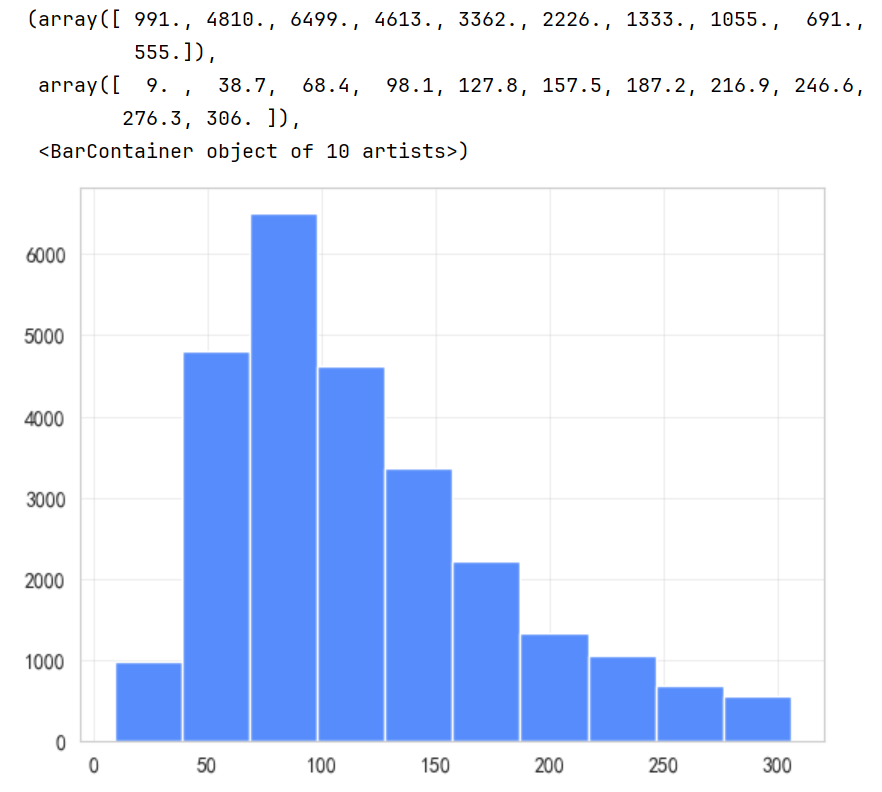
python
"""
问题编号:A6
问题:南北向是否真比单一朝向贵?贵多少?
分析主题:朝向溢价
分析目标:评估不同朝向的价格差异
分组字段:toward
指标/方法:方差分析/多重比较
"""
df['toward'].value_counts()
df.groupby(by=['toward']).agg({
'price':['mean', 'median'],
'unit': ['median'],
'building_age': 'mean'
})
# sns.barplot(data=df, x='toward', y='price')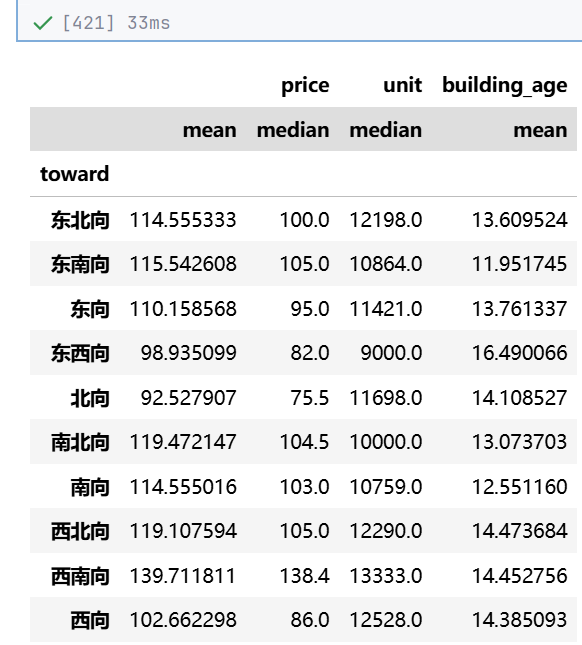
python
# 数据可视化
plt.figure(figsize=(10, 8))
sns.boxplot(data=df, x='toward', y='price')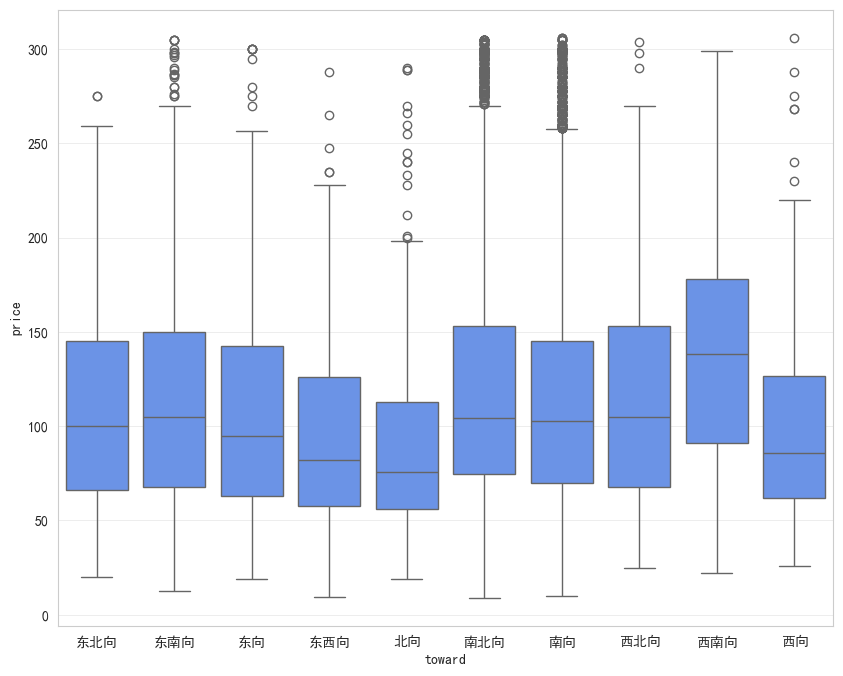
总结
如果把数据分析比作一场烹饪,那么:
- NumPy 是最基础的食材处理与刀工(提供高性能的多维数组与底层数学运算);
- Pandas 是备菜与配菜(提供类似 Excel 的二维表格,负责数据的清洗、整理与结构化);
- Matplotlib 是最基础的画笔(提供像素级的绘图控制,是可视化的底层引擎);
- Seaborn 是高级的绘画风格与模板(基于 Matplotlib 封装,专为统计图表设计,一键生成美观的专业图表)。
| 库 | 核心定位 | 一句话描述 | 典型适用场景 |
|---|---|---|---|
| NumPy | 底层计算引擎 | 多维数组与矩阵运算的基石 | 大规模数值计算、矩阵运算、作为其他库的数据输入 |
| Pandas | 数据处理工具 | 像操作 Excel 一样操作数据 | 数据清洗、ETL流程、结构化数据分析、特征工程 |
| Matplotlib | 通用绘图基石 | 完全控制图表像素级细节 | 需要高度定制化的图表、非统计类工程图纸、底层绘图 |
| Seaborn | 统计可视化接口 | 让统计图表更简单、更美观 | 探索性数据分析(EDA)、快速展示变量关系与分布、商业/学术报告 |
~~完结撒花~~~