英伟达发布的 NVL72 系统将 36 个 GraceCPU 和 72 个BlackwellGPU 集成到一个液冷机柜中,实现 720PFLOPS 的 AI 训练性能。 其最新推出的 DGX GB200NVL72 超节点采用 NVLink5.0 技术,单 GPU 支持 18个 NVLink 链接,总带宽达 1800GB/s,是 PCIe5 带宽的 14 倍以上。
本文浅析如下:
1、整机

1)Top Of Rack Switches 2)Power Shelfs
3)NVLink Switch Trays 中间9个 4)Compute Trays 上10下8共18个
5)Cable Cartridges 6)44U Rack Manifolds
- GB200 NVL72 系统的物理架构占据一个四十八单元的机架配置,容纳多个专用组件。
- 18个计算托盘,每个托盘包含2个 Grace CPU 和四个 Blackwell GPU,
- 9个 NVIDIA NVLink 交换托盘,负责机柜内所有GPU的全互联。
- 电力传输通过六到八个 33 千瓦的电源架,经由五十伏直流母线系统进行连接管理,而两个 SN2201 机架顶部交换机负责处理网络连接。
- 四十四单元机架液体歧管用于热管理,展示了如此高性能计算环境所需的全面整合能力。
2)计算节点

计算托盘托盘配备两个 Grace CPU,每个处理器装备七十二个 Arm Neoverse V2 核心,基础频率为 3.1 GHz。这些处理器配对 512 GB 焊接式 LPDDR5X 内存,其中 480 GB 可用于计算任务。
每个计算托盘还包括预配置的 PCIe 插槽,装载两个 BlueField-3 DPU 和两个 ConnectX-7 网络适配器,以及存储组件,包括八个 E1.S 固态硬盘和一个 M.2 硬盘,全部具备自加密器件能力,支持 OPAL 和 TCP 合规性。
Grace ARM 处理器架构通过现代化设计提供了出色的计算能力。每个处理器在 L1 级别为每个核心配备 64 KB 指令缓存和 64 KB 数据缓存,每个核心拥有 1 MB 的 L2 缓存,以及 114 MB 的共享 L3 缓存。这种分层缓存结构使得人工智能工作负载所需的高效数据访问模式得以实现,其中内存带宽和延迟对整体性能产生显著影响。处理器保持 3.0 GHz 的全核心 SIMD 频率,在机器学习应用中典型的并行计算操作中提供一致的性能表现。
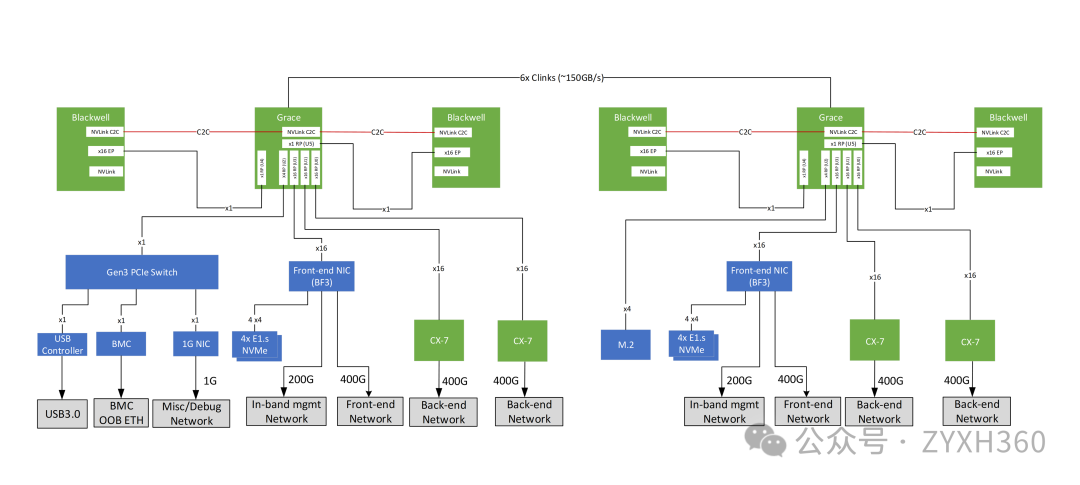
- 双路CPU C2C直连
- GPU的PCIE、NvLINK直连CPU
- NIC直连CPU
- BF3 DPU网卡部分对外连接用于机柜访问外部网络,部分做带内管理
- CX-7网卡用于连接IB/Eth计算网络
3)交换节点
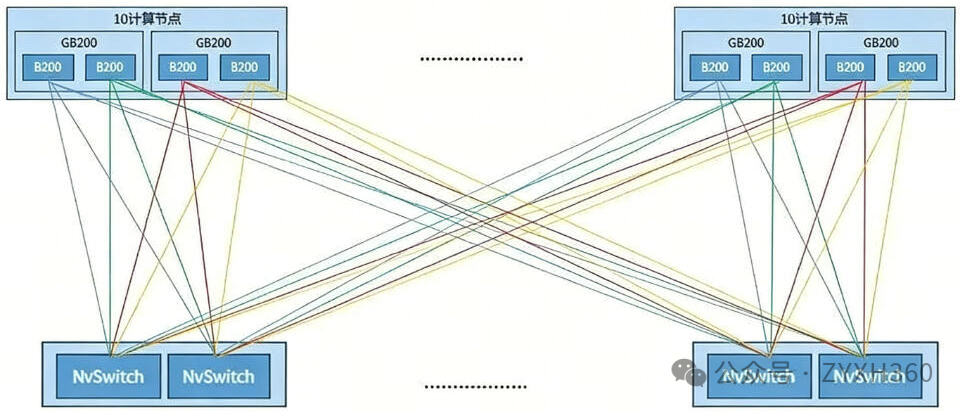
- GPU-NVSwitch连接:每颗B200/B300 GPU拥有18个NVLink通道。在NVL72系统中,这18个通道被平均分配到9个NVLink交换机托盘中的18颗NVSwitch芯片上。这意味着每颗GPU都直接连接到所有18颗NVSwitch。
- NVSwitch的作用:每颗NVSwitch芯片则连接到所有72颗GPU。这种设计形成了一个Clos网络,任何两颗GPU间的通信最多只需经过一跳(通过一颗NVSwitch),实现了极低的延迟和极高的带宽。
- 物理实现:如此高密度的连接通过铜缆背板实现。整个系统需要5184根差分对铜缆,总长度超过2英里。这些铜缆被预先安装在"线缆盒"中,通过盲插连接器与计算托盘和交换机托盘对接,简化了部署和维护。
整体而言,属于计算交换网络的整机系统整合,逻辑关系清晰,Cable高速互联,整机系统工程挑战较大。网络整机中常用的背板互联、Cable互联、正交互联,难度各有千秋,只不过突出难点做了相对的转移。