导读:Redis 官方给出的基准数据是单节点 10 万+ QPS,实际生产环境中跑到 8~15 万 QPS 也是家常便饭。一个没有什么"黑科技"的 C 语言程序凭什么能这么快?这篇文章从内存模型、数据结构、IO 模型、线程模型四个维度把 Redis 的性能根因拆开讲透。读完之后,你不仅能在面试中从容应答"Redis 为什么快",更能在实际项目中做出正确的 Redis 性能优化决策。
一、先给结论:五大核心原因
Redis 的高性能不是靠某一个银弹,而是五个层面协同作用的结果:
| 层面 | 核心机制 | 对性能的贡献 |
|---|---|---|
| 存储介质 | 纯内存操作 | 消除了磁盘 IO 瓶颈,读写延迟从 ms 级降到 μs 级 |
| 数据结构 | 精心设计的底层编码 | 同一个 API 后面会根据数据规模自动切换最优编码 |
| IO 模型 | epoll 多路复用 | 单线程处理数万并发连接,避免 select/poll 的线性扫描 |
| 线程模型 | 核心单线程 | 无锁设计,消除上下文切换和竞争开销 |
| 协议设计 | RESP 协议 | 文本协议,解析简单快速,支持 Pipeline 批量操作 |
这五个原因不是并列关系,而是有层次递进的。内存是地基,数据结构是建筑材料,IO 模型是施工方案,线程模型是施工队组织形式,协议设计是运输通道。
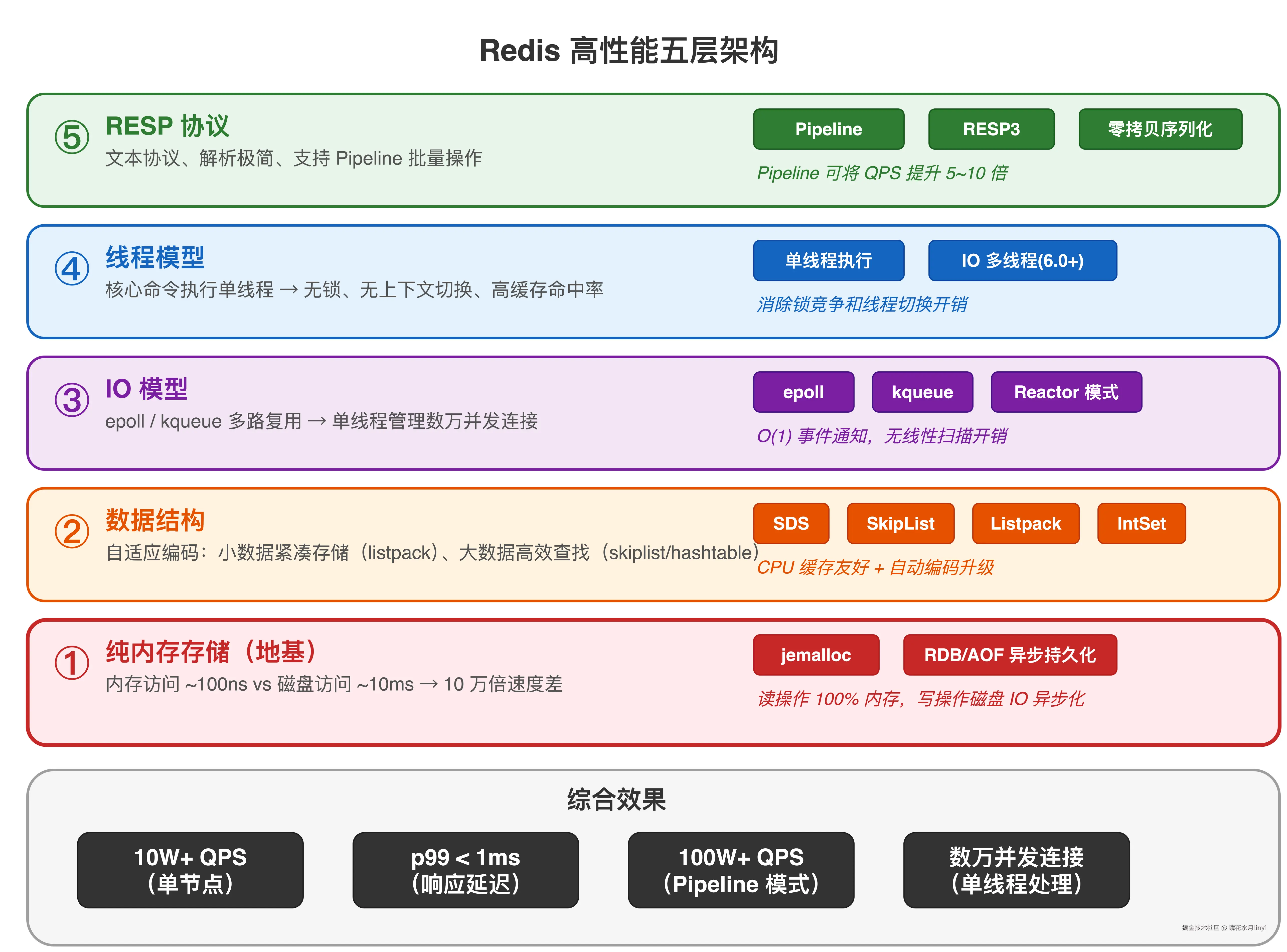 图1 展示了 Redis 高性能的五层架构。从底层的内存存储到上层的 RESP 协议,每一层都在为极致性能做贡献。理解这个分层关系,是理解 Redis 性能优化的基础。
图1 展示了 Redis 高性能的五层架构。从底层的内存存储到上层的 RESP 协议,每一层都在为极致性能做贡献。理解这个分层关系,是理解 Redis 性能优化的基础。
下面逐一深入。
二、纯内存操作:10 万倍的速度差
2.1 内存 vs 磁盘的本质差异
Redis 所有数据都在内存中,这是它快的第一性原理。来看一组硬件延迟数据(来自 Jeff Dean 的经典 "Numbers Every Programmer Should Know"):
| 操作 | 延迟 | 相对倍数 |
|---|---|---|
| L1 缓存引用 | 0.5 ns | 1× |
| L2 缓存引用 | 7 ns | 14× |
| 主内存引用 | 100 ns | 200× |
| SSD 随机读取 | 16,000 ns(16 μs) | 32,000× |
| 机械磁盘寻道 | 10,000,000 ns(10 ms) | 20,000,000× |
内存访问和磁盘访问之间有5 个数量级的差距。对于一个 GET 操作:
- Redis(内存):查找哈希表 → 返回值,耗时约 1~10 μs
- MySQL(磁盘 + B+ 树):索引查找 → 磁盘 IO → 数据页加载 → 返回值,耗时约 1~10 ms
这就是为什么 Redis 能比 MySQL 快 100~1000 倍的根本原因。
2.2 Redis 的内存布局
Redis 使用自定义的内存分配器(默认是 jemalloc)来管理内存。每个键值对在内存中的存储结构如下:
c
// Redis 中每个键值对的核心数据结构
typedef struct redisObject {
unsigned type:4; // 数据类型(string/list/hash/set/zset)
unsigned encoding:4; // 内部编码方式(int/embstr/raw/ziplist/...)
unsigned lru:24; // LRU 时间戳(用于内存淘汰)
int refcount; // 引用计数
void *ptr; // 指向实际数据的指针
} robj;
// sizeof(robj) = 16 字节注意 encoding 字段------Redis 的每种数据类型都有多种内部编码方式。这是 Redis 高性能的第二个秘密:自适应编码。
2.3 内存操作不意味着"没有IO"
一个常见的误区是"Redis 在内存中所以没有 IO"。实际上 Redis 的持久化机制(RDB/AOF)会产生磁盘 IO,但关键在于:
- RDB 快照:fork 子进程做持久化,利用操作系统的 COW(Copy-On-Write)机制,不阻塞主线程
- AOF 追加:每次写操作追加到 AOF 缓冲区,由后台线程异步刷盘
- 读操作:100% 在内存中完成,零磁盘 IO
也就是说,读操作完全不涉及磁盘,写操作的磁盘 IO 被异步化了。用户感知到的延迟只有内存操作的延迟。
三、数据结构:同一个命令,不同的引擎
Redis 最让人叹服的设计之一,是对外暴露简单的 5 种数据类型,内部却有十几种编码方式,并且会根据数据的实际情况自动选择最优编码。
3.1 类型与编码的映射关系
| 数据类型 | 内部编码 | 触发条件 |
|---|---|---|
| String | int | 值为 64 位整数 |
| embstr | 字符串 ≤ 44 字节 | |
| raw | 字符串 > 44 字节 | |
| List | listpack(旧版 ziplist) | 元素数 ≤ 128 且每个元素 ≤ 64 字节 |
| quicklist | 超出上述阈值 | |
| Hash | listpack | 键值对数 ≤ 128 且每个值 ≤ 64 字节 |
| hashtable | 超出上述阈值 | |
| Set | intset | 所有元素均为整数且元素数 ≤ 512 |
| listpack | 元素数 ≤ 128 且每个元素 ≤ 64 字节 | |
| hashtable | 超出上述阈值 | |
| ZSet | listpack | 元素数 ≤ 128 且每个元素 ≤ 64 字节 |
| skiplist + hashtable | 超出上述阈值 |
以上阈值基于 Redis 7.x 默认配置,可通过
list-max-listpack-size、hash-max-listpack-entries等参数调整。
可以用 OBJECT ENCODING <key> 命令查看任意 key 的实际编码:
bash
# String 类型的三种编码
127.0.0.1:6379> SET counter 42
OK
127.0.0.1:6379> OBJECT ENCODING counter
"int" # 整数直接用 int 编码
127.0.0.1:6379> SET name "hello"
OK
127.0.0.1:6379> OBJECT ENCODING name
"embstr" # 短字符串用 embstr
127.0.0.1:6379> SET bio "a]very-long-string-that-exceeds-44-bytes-limit-for-embstr-encoding"
OK
127.0.0.1:6379> OBJECT ENCODING bio
"raw" # 长字符串用 raw
# Hash 类型的编码升级
127.0.0.1:6379> HSET user:1 name "Alice"
(integer) 1
127.0.0.1:6379> OBJECT ENCODING user:1
"listpack" # 少量字段用 listpack(紧凑)
# 当字段数超过阈值后自动升级为 hashtable
127.0.0.1:6379> # (插入 129 个字段后)
127.0.0.1:6379> OBJECT ENCODING user:1
"hashtable" # 大量字段用 hashtable(快速查找)3.2 为什么小数据要用紧凑编码?
以 Hash 类型为例,当字段少的时候用 listpack,字段多了才用 hashtable。为什么不一直用 hashtable?
hashtable 的开销:
ini
每个 dictEntry = 24 字节(key指针 + value指针 + next指针)
每个 redisObject = 16 字节
每个 SDS 字符串 = header(3~17字节) + 内容 + '\0'
一个只存 3 个字段的 Hash,用 hashtable 编码:
3 × (24 + 16×2 + SDS×2) ≈ 300+ 字节的元数据开销listpack 的做法:
把所有字段名和值连续存储在一块内存中,没有指针、没有额外的对象头:
css
[总字节数][字段1名][字段1值][字段2名][字段2值]...[结束标记]3 个字段只需要 50~100 字节。内存省了 3~5 倍,而且由于数据连续存储,对 CPU 缓存非常友好------L1/L2 缓存命中率高,遍历速度反而比 hashtable 更快(在数据量小的时候)。
这就是 Redis 数据结构设计的核心哲学:小数据用紧凑编码省内存、提升缓存命中率;大数据切换到复杂结构保证查询效率。
 图2 展示了 Redis 数据结构的双层设计。上层是用户看到的 5 种数据类型,下层是实际使用的底层编码。随着数据量增长,编码会自动升级(但不会降级)。小数据用紧凑编码优化内存和缓存命中,大数据用高级结构优化查询复杂度。
图2 展示了 Redis 数据结构的双层设计。上层是用户看到的 5 种数据类型,下层是实际使用的底层编码。随着数据量增长,编码会自动升级(但不会降级)。小数据用紧凑编码优化内存和缓存命中,大数据用高级结构优化查询复杂度。
3.3 跳表(Skip List):ZSet 的高性能排序引擎
ZSet(有序集合)是 Redis 最复杂的数据结构,底层使用跳表 + 哈希表的组合:
- 跳表 负责按分数排序,支持范围查询(
ZRANGEBYSCORE) - 哈希表 负责 O(1) 查找单个元素的分数(
ZSCORE)
跳表的核心思想是"空间换时间"------通过建立多层索引,将链表的 O(n) 查找优化到 O(log n):
yaml
Level 3: 1 ────────────────────────────> 9 ──────> NULL
Level 2: 1 ────────> 4 ────────────────> 9 ──────> NULL
Level 1: 1 ───> 3 ─> 4 ───> 6 ────────> 9 ──────> NULL
Level 0: 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 -> 9 -> NULL
查找元素 7 的路径:
Level 3: 1 → 9(9 > 7,下降)
Level 2: 1 → 4 → 9(9 > 7,下降)
Level 1: 4 → 6 → 9(9 > 7,下降)
Level 0: 6 → 7(找到!)
只访问了 7 个节点,而普通链表需要访问全部 9 个节点Redis 的跳表实现有几个精心的设计:
c
typedef struct zskiplistNode {
sds ele; // 元素值
double score; // 排序分数
struct zskiplistNode *backward; // 后退指针(方便逆序遍历)
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度(用于快速计算排名)
} level[]; // 柔性数组,每个节点的层数随机决定
} zskiplistNode;为什么选跳表不选红黑树? Redis 的作者 antirez 给出的理由:
- 实现简单:跳表代码量约 300 行,红黑树需要 500+ 行,且旋转操作容易出 bug
- 范围查询高效:跳表找到起点后沿链表遍历即可,红黑树需要中序遍历
- 内存可控:跳表平均每个节点 1.33 个指针(概率 p=0.25),红黑树固定 3 个指针
- 并发友好:跳表的局部修改比红黑树的全局旋转更适合加锁(虽然 Redis 单线程不需要,但 ConcurrentSkipListMap 就是这个思路)
3.4 SDS(Simple Dynamic String):比 C 字符串快在哪?
Redis 没有直接使用 C 语言的 char* 字符串,而是自己实现了 SDS:
c
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 已使用长度
uint8_t alloc; // 分配的总长度
unsigned char flags; // 类型标记(sdshdr5/8/16/32/64)
char buf[]; // 实际的字符数组
};SDS 比 C 字符串快的三个原因:
| 操作 | C 字符串 | SDS |
|---|---|---|
| 获取长度 | O(n) --- 遍历到 \0 |
O(1) --- 直接读 len 字段 |
| 追加字符串 | 每次 realloc | 预分配策略,减少 realloc 次数 |
| 二进制安全 | 遇到 \0 截断 |
用 len 判断结尾,可存任意二进制数据 |
SDS 的预分配策略尤其巧妙:
c
// 当 SDS 需要扩容时
if (newlen < 1MB) {
// 小于 1MB:分配 2 倍空间
newlen *= 2;
} else {
// 大于 1MB:每次多分配 1MB
newlen += 1MB;
}这样做的效果是:对一个 SDS 多次追加操作(比如 APPEND 命令),大概率只需要一次 realloc,后续追加直接写入预分配的空间。
四、IO 多路复用:一个线程撑起万级连接
4.1 问题的本质:网络 IO 的等待
Redis 是网络服务,每个客户端请求都是一次 TCP 通信。如果用最朴素的方式------一个连接一个线程------那 1 万个并发连接就需要 1 万个线程。线程数一多,上下文切换的开销就会吞噬掉大量 CPU 时间。
IO 多路复用的核心思想是:用一个线程同时监听多个文件描述符(socket),哪个 socket 有数据可读就处理哪个。
4.2 三代 IO 多路复用的演进
Linux 上的 IO 多路复用经历了 select → poll → epoll 三代演进:
| 维度 | select | poll | epoll |
|---|---|---|---|
| 最大连接数 | 1024(FD_SETSIZE) | 无限制 | 无限制 |
| 就绪检测 | O(n) 线性扫描全部 fd | O(n) 线性扫描 | O(1) 回调通知 |
| 数据拷贝 | 每次调用都要复制整个 fd 集合到内核 | 同 select | 只需注册一次 |
| 触发方式 | 水平触发 | 水平触发 | 支持边缘触发 + 水平触发 |
| 典型场景 | 连接数 < 100 | 连接数 < 1000 | 连接数 > 1000 |
Redis 在 Linux 上默认使用 epoll ,在 macOS 上使用 kqueue ,在 Solaris 上使用 evport。
4.3 epoll 为什么比 select 快?
select 的工作方式是"轮询":每次调用 select() 时,内核要遍历所有注册的 fd,逐一检查是否有事件就绪。如果有 1 万个连接,每次检查就要遍历 1 万次。
epoll 的工作方式是"回调":当 socket 有数据到达时,内核通过回调函数将这个 fd 加入就绪队列。epoll_wait() 只需要检查就绪队列即可,不需要遍历所有 fd。
c
// select 模型(伪代码)------ O(n) 每次调用
while (true) {
fd_set readfds;
FD_ZERO(&readfds);
for (int fd : all_client_fds) { // 每次都要重新设置
FD_SET(fd, &readfds);
}
select(maxfd + 1, &readfds, NULL, NULL, NULL); // 内核遍历所有 fd
for (int fd : all_client_fds) { // 用户态再遍历一次
if (FD_ISSET(fd, &readfds)) {
handle_request(fd);
}
}
}
// epoll 模型(伪代码)------ O(1) 获取就绪事件
int epfd = epoll_create(1);
// 只需注册一次
for (int fd : all_client_fds) {
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &event); // 注册到内核
}
while (true) {
// 只返回就绪的 fd,不需要遍历所有连接
int n = epoll_wait(epfd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++) { // 只遍历有事件的 fd
handle_request(events[i].data.fd);
}
}假设 1 万个连接中只有 10 个有数据到达:
- select:遍历 1 万个 fd → 发现 10 个就绪 → 处理 10 个请求
- epoll:直接返回 10 个就绪 fd → 处理 10 个请求
连接数越多,epoll 的优势越明显。这就是 Redis 能用单线程处理数万并发连接的关键。
 图3 展示了 select 与 epoll 的核心区别。select 每次调用都需要将整个 fd 集合拷贝到内核并线性扫描;epoll 通过注册机制和就绪队列,实现了 O(1) 的事件获取效率。
图3 展示了 select 与 epoll 的核心区别。select 每次调用都需要将整个 fd 集合拷贝到内核并线性扫描;epoll 通过注册机制和就绪队列,实现了 O(1) 的事件获取效率。
4.4 Redis 的事件循环(Event Loop)
Redis 在 IO 多路复用之上构建了一个事件驱动的主循环,这是它的运行核心:
c
// Redis 事件循环(ae.c 简化版)
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 1. 执行 beforesleep 回调(处理一些周期性任务)
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 2. 调用多路复用 API 等待事件(epoll_wait / kqueue / ...)
// 同时处理定时事件的超时
aeProcessEvents(eventLoop, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP);
}
}
// aeProcessEvents 内部逻辑
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 计算最近的定时器到期时间作为 epoll_wait 的超时
struct timeval *tvp = getShortestTimerTimeout();
// 调用底层的多路复用 API
numevents = aeApiPoll(eventLoop, tvp); // epoll_wait()
for (int i = 0; i < numevents; i++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[i].fd];
// 可读事件 → 读取客户端命令
if (fe->mask & AE_READABLE) {
fe->rfileProc(eventLoop, fd, fe->clientData, mask);
}
// 可写事件 → 发送响应给客户端
if (fe->mask & AE_WRITABLE) {
fe->wfileProc(eventLoop, fd, fe->clientData, mask);
}
}
// 处理到期的定时事件(如过期键清理、持久化触发等)
processTimeEvents(eventLoop);
return numevents;
}整个流程可以概括为:等待事件 → 处理网络请求 → 处理定时任务 → 回到等待。这就是经典的 Reactor 模式。
五、单线程模型:没有锁才是最快的锁
5.1 "单线程"到底是什么意思?
一个常见的误解是"Redis 整个进程只有一个线程"。实际上 Redis 有多个线程,但处理客户端命令的核心路径是单线程的。
vbnet
Redis 进程中的线程分工:
主线程(单个):
├── 接收客户端连接
├── 读取客户端命令
├── 执行命令(操作内存中的数据结构)
└── 将响应写回客户端
后台线程(多个):
├── bio_close_file:异步关闭大文件
├── bio_aof_fsync:AOF 文件异步刷盘
└── bio_lazy_free:异步释放大对象内存(UNLINK、FLUSHDB ASYNC)
IO 线程(Redis 6.0+,可选):
├── io_thread_1:辅助读取客户端请求
├── io_thread_2:辅助写入客户端响应
└── ...(可配置多个)关键点:命令执行永远是单线程的。即使开启了 IO 多线程,命令的解析和执行仍然在主线程中串行完成。
5.2 单线程为什么反而快?
这是 Redis 面试中最高频的问题。答案是:对于 Redis 的场景,单线程避免的开销 > 多线程带来的收益。
多线程带来的开销:
-
锁竞争 :多线程操作共享数据结构需要加锁。一个
INCR操作在多线程下变成:加锁 → 读值 → +1 → 写值 → 解锁。锁本身就是一次原子操作(CAS 或 mutex),在高并发下会导致大量线程阻塞和唤醒。 -
上下文切换:线程切换一次的成本约 1~10 μs,包括保存/恢复寄存器、刷新 TLB、切换内核栈。如果有 100 个线程竞争同一把锁,上下文切换的开销会远超实际业务操作。
-
缓存失效:线程切换后,新线程的工作集大概率不在 L1/L2 缓存中,导致 cache miss。Redis 的数据结构遍历(如 ziplist 扫描)非常依赖缓存命中率。
单线程的优势:
scss
单线程执行一个 GET 命令的完整路径:
1. epoll_wait 返回可读事件 ~0 ns(事件已就绪)
2. read() 系统调用读取请求 ~1 μs
3. 解析 RESP 协议 ~0.1 μs
4. 在哈希表中查找 key ~0.1 μs
5. write() 系统调用发送响应 ~1 μs
总计:约 2~3 μs,全程无锁、无切换、缓存热数据常驻 L1Redis 的命令执行时间极短(通常在 1 μs 以下),瓶颈根本不在 CPU 计算上,而在网络 IO 上。用多线程来加速一个 0.1 μs 的哈希查找没有意义,反而引入了锁的开销。
5.3 Redis 6.0 的 IO 多线程
既然瓶颈在网络 IO,Redis 6.0 引入了 IO 多线程------用多个线程并行处理网络读写,但命令执行仍然是单线程。
 图4 对比了 Redis 6.0 前后的线程模型。6.0 之前完全单线程处理所有网络 IO 和命令执行;6.0 之后可以开启 IO 多线程,将网络读写分散到多个线程,但命令执行仍然是主线程串行处理,保持了无锁的简洁性。
图4 对比了 Redis 6.0 前后的线程模型。6.0 之前完全单线程处理所有网络 IO 和命令执行;6.0 之后可以开启 IO 多线程,将网络读写分散到多个线程,但命令执行仍然是主线程串行处理,保持了无锁的简洁性。
开启方式:
conf
# redis.conf
io-threads 4 # IO 线程数(建议设为 CPU 核数的一半)
io-threads-do-reads yes # 同时开启读操作的多线程(默认只有写是多线程的)IO 多线程的工作流程:
markdown
1. 主线程通过 epoll 收集所有就绪的客户端连接
2. 主线程将这些连接分配给 N 个 IO 线程
3. IO 线程并行读取请求数据并解析协议(无锁,因为各线程处理不同连接)
4. 主线程等待所有 IO 线程读取完成
5. 主线程串行执行所有命令(核心单线程,无锁)
6. 主线程将响应分配给 IO 线程
7. IO 线程并行将响应写回客户端
8. 主线程等待所有 IO 线程写入完成
9. 回到步骤 1根据 Redis 官方的基准测试,开启 IO 多线程后,吞吐量可以提升一倍(从 10 万 QPS 到 20 万 QPS),同时保持了命令执行的单线程简洁性。
5.4 单线程的代价:慢查询的致命影响
单线程是把双刃剑。它的代价是:一个慢命令会阻塞所有后续请求。
以下操作在生产中需要格外小心:
| 危险命令 | 问题 | 替代方案 |
|---|---|---|
KEYS * |
O(n) 遍历所有键 | SCAN 渐进式遍历 |
HGETALL(大 Hash) |
一次性返回全部字段 | HSCAN 分批获取 |
DEL(大 key) |
同步释放大量内存 | UNLINK 异步释放 |
FLUSHDB |
同步清空整个库 | FLUSHDB ASYNC |
SORT |
大数据集排序 | 业务层排序或限制排序范围 |
| Lua 脚本(长时间运行) | 脚本执行期间阻塞一切 | 控制脚本复杂度,使用 redis.replicate_commands() |
一个血泪教训:某次线上故障,开发在 Redis 中存了一个 500 万元素的 Set,然后调了一次 SMEMBERS。这一个命令耗时 3 秒,直接导致 3 秒内所有请求超时,告警炸了一屏。
最佳实践 :使用 redis-cli --bigkeys 定期扫描大+ key,使用 slowlog get 监控慢查询。
六、RESP 协议:简单就是快
6.1 RESP 协议格式
Redis 客户端与服务端之间使用 RESP(Redis Serialization Protocol) 通信。它是一个基于文本的协议,人眼可读,解析极简:
bash
客户端发送 SET name Alice:
*3\r\n ← 数组,包含 3 个元素
$3\r\n ← 第 1 个元素:长度为 3 的字符串
SET\r\n ← "SET"
$4\r\n ← 第 2 个元素:长度为 4 的字符串
name\r\n ← "name"
$5\r\n ← 第 3 个元素:长度为 5 的字符串
Alice\r\n ← "Alice"
服务端响应:
+OK\r\n ← 简单字符串响应RESP 的解析只需要逐字节读取,遇到 \r\n 就知道当前元素结束了。没有复杂的转义、嵌套或编码问题,解析速度极快。
6.2 Pipeline:批量操作的大杀器
普通模式下,每个命令都是一次完整的 RTT(Round Trip Time):
arduino
普通模式(100 个 SET 命令):
Client → SET k1 v1 → Server → +OK → Client
Client → SET k2 v2 → Server → +OK → Client
...(重复 100 次)
总耗时 ≈ 100 × RTT(如果 RTT = 1ms,则 100ms)Pipeline 模式下,客户端一次性发送所有命令,服务端一次性返回所有响应:
vbscript
Pipeline 模式(100 个 SET 命令):
Client → SET k1 v1
SET k2 v2
...
SET k100 v100
→ Server(批量执行)
→ +OK +OK ... +OK → Client
总耗时 ≈ 1 × RTT + 执行时间(约 1~2ms)性能对比(基于局域网 RTT ≈ 0.1ms 的环境):
| 模式 | 100 条命令耗时 | QPS |
|---|---|---|
| 逐条执行 | ~10 ms | ~10,000 |
| Pipeline | ~0.5 ms | ~200,000 |
Pipeline 的加速倍数取决于网络延迟:延迟越高(比如跨机房),加速效果越明显。
java
// Jedis Pipeline 示例
try (Jedis jedis = jedisPool.getResource()) {
Pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 10000; i++) {
pipeline.set("key:" + i, "value:" + i);
}
// 一次性发送所有命令并接收所有响应
List<Object> results = pipeline.syncAndReturnAll();
}七、性能实测:用数据说话
理论分析之后,用 redis-benchmark 做一组实际测试。测试环境:macOS M1 Pro、Redis 7.2、默认配置。
bash
# 测试 GET/SET 操作,100 个并发连接,10 万次请求
redis-benchmark -t get,set -c 100 -n 100000 -q典型结果:
sql
SET: 135,135.14 requests per second, p50=0.367 msec
GET: 142,857.14 requests per second, p50=0.351 msec开启 Pipeline 后的对比:
bash
# Pipeline 模式,每次批量发送 16 条命令
redis-benchmark -t get,set -c 100 -n 100000 -P 16 -q
sql
SET: 1,052,631.58 requests per second, p50=0.543 msec
GET: 1,176,470.59 requests per second, p50=0.487 msecPipeline=16 时吞吐量提升了约 8 倍,突破百万 QPS。
不同数据大小的影响
bash
# 不同 value 大小对 SET 性能的影响
redis-benchmark -t set -c 50 -n 100000 -d 10 -q # 10 字节
redis-benchmark -t set -c 50 -n 100000 -d 1000 -q # 1 KB
redis-benchmark -t set -c 50 -n 100000 -d 10000 -q # 10 KB
redis-benchmark -t set -c 50 -n 100000 -d 100000 -q # 100 KB| Value 大小 | QPS | 说明 |
|---|---|---|
| 10 B | ~130,000 | 基线性能 |
| 1 KB | ~110,000 | 轻微下降,影响不大 |
| 10 KB | ~60,000 | 明显下降,网络带宽开始成为瓶颈 |
| 100 KB | ~12,000 | 大幅下降,内存拷贝和网络传输成为主要开销 |
结论:Redis 最适合小数据高并发场景。Value 超过 10 KB 后性能显著下滑,超过 100 KB 则不建议使用 Redis。
八、性能优化实践清单
基于以上分析,整理一份可直接落地的优化清单:
数据结构层面
bash
# 1. 监控大 key,避免超大数据结构
redis-cli --bigkeys
# 2. 检查慢查询日志
redis-cli SLOWLOG GET 10
# 3. 确保小数据使用紧凑编码
# 如果你的 Hash 只有几十个字段,确认阈值设置合理
CONFIG GET hash-max-listpack-entries # 默认 128
CONFIG GET hash-max-listpack-value # 默认 64网络层面
bash
# 4. 使用 Pipeline 批量操作(减少 RTT)
# 5. 使用连接池,避免频繁创建/销毁连接
# 6. 开启 IO 多线程(Redis 6.0+,高并发场景)
io-threads 4
io-threads-do-reads yes命令层面
| 场景 | 避免 | 使用 |
|---|---|---|
| 遍历所有 key | KEYS * |
SCAN 0 MATCH * COUNT 100 |
| 获取大 Hash 全部字段 | HGETALL |
HSCAN 或 HMGET 指定字段 |
| 删除大 key | DEL |
UNLINK(异步删除) |
| 清空数据库 | FLUSHDB |
FLUSHDB ASYNC |
| 集合运算 | SUNION(大集合) |
业务层分批处理 |
架构层面
bash
# 7. 读写分离(主节点写,从节点读)
# 8. 集群分片(Redis Cluster),水平扩展吞吐量
# 9. 客户端缓存(Redis 6.0+ 的 Client-Side Caching),进一步减少网络请求