前言
大家好呀~ 👋 欢迎来到《从0到1实现AI Agent》系列的第一篇!
这段时间 AI Agent 真的超级火 🔥,不管刷什么平台,都能看到 ReAct、Agentic Workflow、Tool Calling 这些词。听起来特别高大上,但很多朋友看完理论后还是有点懵:Agent 到底是个啥?它究竟是怎么自己"思考"又自己"行动"的?
我写这个系列的目的,就是想拉着大家一起动手。我们将抛开晦涩的论文,从最基础的一行行代码开始,一步步把一个完整的 AI Agent 敲出来。在我们一起跑 Demo、踩坑、Debug 的过程中,你会发现那些高深的概念,其实本质都非常直观有趣。
这个系列我们使用 Python ,因为它的 AI 生态最成熟,上手也最快。第一篇,我们先拿下最核心的两样武器:大模型(LLM)的对话能力 + 本地工具调用(Tool Calling) 。
🎯 今天的小目标:让你的 Agent 能够准确回答"明天纽约天气怎么样?"这种大模型原本不知道的实时问题!
📌 阅读说明
本系列主打 实战动手,重点在于"把 Agent 做出来"。文章不会事无巨细地科普所有基础理论。
如果你希望深入理解某些理论(比如 ReAct、Tool Calling、Agent Workflow、MCP 等),我会在文章合适的位置穿插一些 高质量官方文档、优秀博客和视频教程 作为延伸阅读,方便你按需深入。
可以把这个系列理解为:
主线写代码 + 支线补理论资源 😊
如果你希望在动手前先对 Agent 有个直观的认知,强烈推荐观看这个视频:
当然,直接跟着本文往下敲代码,也完全没问题!
准备好了吗?我们发车!🚀
第一步:创建项目环境 (agent-playground)
写代码第一步,先把环境搭好。这里强烈安利 uv 这个极速 Python 包和环境管理工具,用过就回不去了 😊。
如果你还没安装 uv,只需一行命令:
bash
# macOS & Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"接着,我们初始化项目并激活虚拟环境:
bash
uv init agent-playground
cd agent-playground
uv venv
source .venv/bin/activate # Windows 用户用 .venv\Scripts\activate环境搞定!接下来进入正题。
第二步:让大模型开口说话
Agent 的大脑是大模型。我们先实现最基础的一步 ------ 让程序能和 DeepSeek 顺畅聊天。
💡 为什么选 DeepSeek? 速度快、推理强(特别是 deepseek-reasoner 模型)、性价比极高,而且它的 API 完全兼容 OpenAI 格式,这就意味着你今天写的代码,以后可以无缝切换给 GPT-4 或其他任何主流模型!
1. 准备 API Key
- 登录 DeepSeek 开放平台。
- 创建并复制你的 API Key。
- 在项目根目录新建一个
.env文件,贴入你的 Key:
env
DEEPSEEK_API_KEY=sk-XXXXXXXXXXXXXXXXXXXXXXXX小贴士:实际开发中不要把 Key 直接写在代码里哦~ 用 python-dotenv 加载更安全(后面我们会加上)。
2. 编写 LLM 基础接口
为了让代码更优雅、方便以后接入其他模型,我们先建一个抽象类。 创建文件夹 llm,并在里面新建 base.py:
Python
from abc import ABC, abstractmethod
from typing import Optional
class LLM(ABC):
"""所有大模型的统一接口,方便后面切换不同模型"""
@abstractmethod
async def generate(
self,
prompt: str,
system_prompt: Optional[str] = None,
temperature: float = 0.7,
max_tokens: int = 1024,
) -> str:
"""生成文本回复"""
pass3. 实现 DeepSeek 客户端
接下来实现 DeepSeek 的具体调用。新建 llm/deepseek.py:
Python
import os
from typing import Optional
from openai import AsyncOpenAI
from .base import LLM
class DeepSeekLLM(LLM):
"""DeepSeek 大模型实现"""
def __init__(self, model: str = "deepseek-chat"):
self.model = model
self.client = AsyncOpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com", # 官方推荐 base_url
)
async def generate(
self,
prompt: str,
system_prompt: Optional[str] = None,
temperature: float = 1.3, # DeepSeek 比较适合稍高一点的温度,创意更好
max_tokens: int = 1024,
) -> str:
"""调用 DeepSeek 生成回复"""
# 记住历史消息一起传给大模型,这样才能让模型知道上下文
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = await self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
stream=False,
)
text = response.choices[0].message.content
if not text:
raise RuntimeError("DeepSeek 返回了空回复 😅")
return text.strip()4. 组装聊天主入口
在根目录新建 main.py,并安装所需依赖:
bash
# 安装用到的两个库
uv add openai python-dotenv
Python
import asyncio
import os
from dotenv import load_dotenv # 后面我们会安装这个
from llm.deepseek import DeepSeekLLM
# 加载 .env 文件
load_dotenv()
async def main():
# 这里我们先用 deepseek-reasoner(思考模式),效果通常更好
llm = DeepSeekLLM(model="deepseek-reasoner")
print("🤖 DeepSeek Agent 已启动!(输入 exit 或 quit 退出)")
print("来和我聊聊天吧~ 💬\n")
while True:
try:
user_input = input("👤 You: ").strip()
if user_input.lower() in ["exit", "quit", "bye"]:
print("👋 拜拜啦!下次再一起玩~")
break
if not user_input:
continue
print("\n🤖 DeepSeek 正在思考...")
output = await llm.generate(prompt=user_input)
print("\n🤖 DeepSeek says:")
print(output)
print("-" * 60)
except Exception as e:
print(f"😢 出错了:{e}")
if __name__ == "__main__":
asyncio.run(main())现在我们可以启动项目验证一下效果啦:
bash
uv run python main.py这里是我本地的运行演示:
我们已经可以开始和 DeepSeek 进行简单的聊天了~ 🎉
但是有一个小问题:回复的时候要等好几秒才能一次性看到全部内容,我们只能干巴巴地等着,有点无聊 😅
所以接下来,我们来优化一下,把回复改成 流式输出(Streaming) ,让文字像 ChatGPT 一样一个字一个字蹦出来,体验立刻提升!
5. 优化:实现流式输出(Streaming)
修改 llm/deepseek.py,给 DeepSeekLLM 类增加一个流式生成方法:
Python
# 在 deepseek.py 中新增以下方法(可以和原来的 generate 并存)
async def stream_chat(
self,
messages: list,
tools: list = [],
temperature: float = 1.3,
max_tokens: int = 1024,
) -> AsyncGenerator[str, None]:
"""流式生成回复(一个字一个字返回)"""
async for chunk in await self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=tools,
temperature=temperature,
max_tokens=max_tokens,
stream=True,
):
delta = chunk.choices[0].delta
if delta.content:
yield delta.content更新 main.py 文件(推荐直接替换):
Python
import asyncio
from dotenv import load_dotenv
from llm.deepseek import DeepSeekLLM
load_dotenv()
async def main():
llm = DeepSeekLLM(model="deepseek-reasoner")
# 记住历史消息一起传给大模型,这样才能让模型知道上下文
messages = []
print("🤖 DeepSeek Chat 已启动 (输入 exit 退出)")
while True:
# 1️⃣ 从终端读取输入(阻塞)
user_input = input("\n👤 You: ")
# 2️⃣ 退出条件
if user_input.lower() in ["exit", "quit"]:
print("👋 Bye!")
break
messages.append({"role": "user", "content": user_input})
full_reply = ""
print("\n🤖 DeepSeek says: ", end="", flush=True)
async for chunk in llm.stream_chat(messages=messages):
full_reply += chunk
print(chunk, end="", flush=True)
messages.append({"role": "assistant", "content": full_reply})
print()
if __name__ == "__main__":
asyncio.run(main())运行测试流式效果
bash
uv run python main.py
现在输入问题后,你会看到文字像打字机一样慢慢出现,感觉舒服多了~ ✨
其实我们可以继续上一个问题继续和大模型聊下去,因为我们已经把所有历史消息的记录都传给大模型了:messages
DeepSeek 官方文档参考
想更深入了解 DeepSeek API 的用法,可以直接参考官方文档:
- DeepSeek API 总文档 (中文):api-docs.deepseek.com/zh-cn/ 这里有获取 API Key、Base URL、支持模型等基础信息。
- 对话补全(Chat Completions)详细接口 (包含流式说明): api-docs.deepseek.com/zh-cn/api/c...
特别说明流式传输:
- 只需在请求中设置 "stream": true 即可开启流式输出。
- 响应会以 SSE (Server-Sent Events) 形式返回,每一块数据是一个 chunk,最后以 data: DONE 结束。
- 使用 OpenAI SDK 时,和我们上面写的代码一样,设置 stream=True 后用 async for 迭代即可。
文档里提到 DeepSeek API 高度兼容 OpenAI 接口,所以我们用 openai 库 + 修改 base_url 就能无缝使用,非常方便~
目前进度小结:
- ✅ LLM 抽象接口(base.py)
- ✅ DeepSeek 具体实现(支持普通调用 + 流式输出)
- ✅ 交互式命令行聊天(带实时流式效果)
第三步:打破"幻觉",给 Agent 装备工具(Tool Calling)
现在我们的 Agent 已经能正常聊天了,但说实话,它目前还只是一个"很会说话的大模型"而已~
我们来试试一个更实际一点的问题吧:
在聊天界面输入:
明天纽约天气怎么样?
你大概率会收到类似这样的回复:
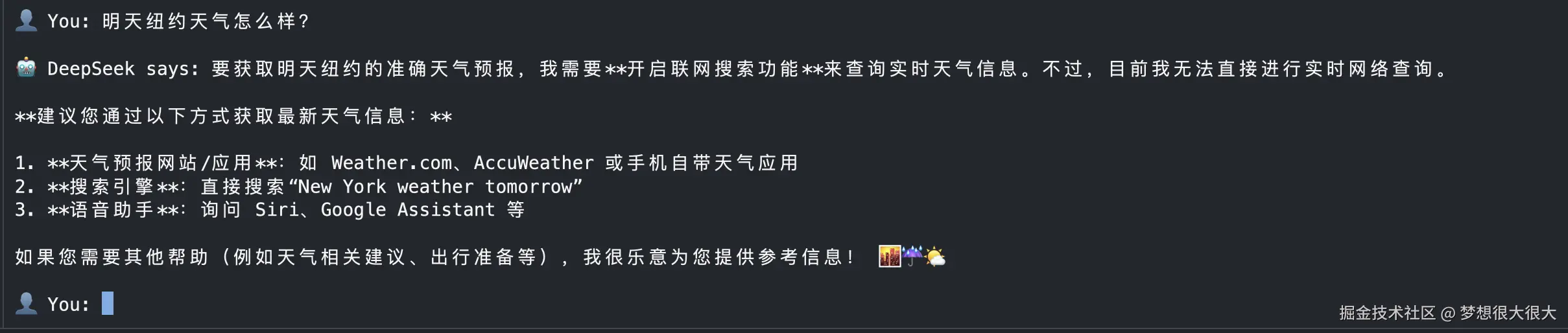
也可能它会直接给你编一段"听起来挺合理"的天气(这在大模型里叫幻觉),但其实并不准确 😂
怎么样,是不是有点小失望?
其实这不是 DeepSeek 的问题,而是几乎所有大模型共同的局限:它们只能靠训练时学到的知识回答问题,没办法主动去获取最新的外部信息。
那我们该怎么解决呢?
给 Agent 配上「工具」(Tool)
要让我们的 Agent 真正聪明起来,就要给它装备工具!
想象一下:你有一个很聪明但从来不出门的朋友,现在我们给他一部手机,让他可以自己去查天气、搜索信息、做计算......这样他就能帮我们解决更多实际问题啦~
在这一篇里,我们要实现的就是最基础却非常重要的能力 ------ Tool Calling(工具调用) 。
简单来说,Tool Calling 就是让大模型学会"调用外部工具"的能力。它不再只是被动回答问题,而是可以主动决定:"我需要查天气 → 那我就调用 get_weather 这个工具"。
这也是目前主流 Agent 框架(如 LangChain、LlamaIndex、CrewAI 等)的核心机制之一。甚至更进一步,业界已经广泛讨论 MCP(Model Context Protocol) ------ 一种让模型和工具之间交互更标准化、更高效的协议。
听起来是不是有点小激动?我们现在就要从最基础的 Tool Calling 开始,一步步把这些东西变成自己能跑起来的代码啦~ 🚀
我们的小目标是:
当用户问「明天纽约天气怎么样」时,Agent 能自动决定调用天气工具,拿到信息后,用自然又友好的语气回答:
🤖 Agent: 纽约明天天气晴朗,最高 18°C,最低 10°C,微风,空气很好,适合出门走走哦~ ☀️
是不是瞬间感觉厉害多了?
准备好一起给 Agent 装上第一个工具了吗?
接下来,我们就一步步来实现!
1. 编写真实的本地工具
新建目录 tools,然后在里面创建一个真实的天气查询脚本 tools/weather.py。
这里我们直接调用美国国家气象局的免费公开 API,这部分代码比较长,重点是知道它能查天气和预警即可
Python
from typing import Any
import httpx
NWS_API_BASE = "https://api.weather.gov"
USER_AGENT = "weather-app/1.0"
async def make_nws_request(url: str) -> dict[str, Any] | None:
"""Make a request to the NWS API with proper error handling."""
headers = {"User-Agent": USER_AGENT, "Accept": "application/geo+json"}
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json()
except Exception:
return None
def format_alert(feature: dict) -> str:
"""Format an alert feature into a readable string."""
props = feature["properties"]
return f"""
Event: {props.get("event", "Unknown")}
Area: {props.get("areaDesc", "Unknown")}
Severity: {props.get("severity", "Unknown")}
Description: {props.get("description", "No description available")}
Instructions: {props.get("instruction", "No specific instructions provided")}
"""
async def get_alerts(state: str) -> str:
"""Get weather alerts for a US state.
Args:
state: Two-letter US state code (e.g. CA, NY)
"""
url = f"{NWS_API_BASE}/alerts/active/area/{state}"
data = await make_nws_request(url)
if not data or "features" not in data:
return "Unable to fetch alerts or no alerts found."
if not data["features"]:
return "No active alerts for this state."
alerts = [format_alert(feature) for feature in data["features"]]
return "\n---\n".join(alerts)
async def get_forecast(latitude: float, longitude: float) -> str:
"""Get weather forecast for a location.
Args:
latitude: Latitude of the location
longitude: Longitude of the location
"""
# First get the forecast grid endpoint
points_url = f"{NWS_API_BASE}/points/{latitude},{longitude}"
points_data = await make_nws_request(points_url)
if not points_data:
return "Unable to fetch forecast data for this location."
# Get the forecast URL from the points response
forecast_url = points_data["properties"]["forecast"]
forecast_data = await make_nws_request(forecast_url)
if not forecast_data:
return "Unable to fetch detailed forecast."
# Format the periods into a readable forecast
periods = forecast_data["properties"]["periods"]
forecasts = []
for period in periods[:5]: # Only show next 5 periods
forecast = f"""
{period["name"]}:
Temperature: {period["temperature"]}°{period["temperatureUnit"]}
Wind: {period["windSpeed"]} {period["windDirection"]}
Forecast: {period["detailedForecast"]}
"""
forecasts.append(forecast)
return "\n---\n".join(forecasts)💡 插播小知识:熟悉 MCP(Model Context Protocol)的朋友会发现,这两个函数其实就是官方教程里用来演示的。我们剥离了复杂的通信协议,直接拿来当本地函数用,既真实又轻量!
2. 让大模型认识工具:Tool Schema
有了函数,大模型怎么知道该怎么用呢?我们需要给它一份 "工具说明书(Schema)" 。
这就像是你递给模型一份菜单,告诉它:"我这有 get_forecast 这道菜,你需要给我提供 latitude 和 longitude 两种配料,我才能给你做出来。"
我在这里先给出最新的完整代码,方便你直接本地复制替换,后面我们会再详细介绍。
llm/deepseek.py:
Python
# 其它内容保持一致
async def stream_chat(
self,
messages: list,
tools: list = [],
temperature: float = 1.3,
max_tokens: int = 1024,
) -> AsyncGenerator[Union[str, Dict], None]:
"""
流式聊天,支持 tool calls
Yield:
str: 普通文本内容(直接展示给用户)
dict: 当检测到 tool calls 时,yield {"type": "tool_calls", "tool_calls": [...]}
"""
response = await self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=tools,
temperature=temperature,
max_tokens=max_tokens,
stream=True,
)
# 用于累积 tool calls(支持多个 tool call)
tool_calls: List[Dict] = []
async for chunk in response:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# 1. 普通文本内容(直接 yield 给前端/用户)
if delta.content:
yield delta.content
# 2. 处理 tool calls(流式增量)
if delta.tool_calls:
for tool_delta in delta.tool_calls:
idx = tool_delta.index
# 如果这个 index 的 tool_call 还没创建,就先初始化
while len(tool_calls) <= idx:
tool_calls.append(
{
"id": None,
"type": "function",
"function": {"name": None, "arguments": ""},
}
)
# 当前正在处理的 tool call
tc = tool_calls[idx]
# 累积 id(通常只出现一次)
if tool_delta.id:
tc["id"] = tool_delta.id
# 累积 function name(通常只出现一次)
if tool_delta.function and tool_delta.function.name is not None:
tc["function"]["name"] = tool_delta.function.name
# 关键:累积 arguments(会分很多小块传来,必须 += 拼接)
if tool_delta.function and tool_delta.function.arguments:
tc["function"]["arguments"] += tool_delta.function.arguments
# ====================== 流式结束后处理 ======================
# 检查是否有有效的 tool call
valid_tool_calls = [
tc
for tc in tool_calls
if tc.get("function", {}).get("name") # 有函数名才算有效
]
if valid_tool_calls:
yield {"type": "tool_calls", "tool_calls": valid_tool_calls}main.py:
Python
import asyncio
from dotenv import load_dotenv
from google.genai.types import json
from llm.deepseek import DeepSeekLLM
from tools.weather import get_forecast
load_dotenv()
# 明天纽约的天气怎么样
tools_map = {"get_forecast": get_forecast}
tools = [
{
"type": "function",
"function": {
"name": "get_forecast",
"description": "weather: Get weather forecast for a location.\n\nArgs:\n latitude: Latitude of the location\n longitude: Longitude of the location\n",
"strict": False,
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"description": "",
"title": "Latitude",
},
"longitude": {
"type": "number",
"description": "",
"title": "Longitude",
},
},
"required": ["latitude", "longitude"],
"additionalProperties": False,
},
},
},
]
# ================= Agent Loop =================
async def run_agent(llm, messages):
"""
处理一次用户输入后的完整 Agent 推理流程
支持无限工具调用
"""
while True:
print("\n🤖 DeepSeek says: thinking...\n\n", end="", flush=True)
full_reply = ""
tool_calls = None
# 3️⃣ 调用 LLM & 流式接收
async for chunk in llm.stream_chat(messages=messages, tools=tools):
if isinstance(chunk, str):
full_reply += chunk
print(chunk, end="", flush=True)
elif isinstance(chunk, dict) and chunk.get("type") == "tool_calls":
tool_calls = chunk["tool_calls"]
print("[工具调用中...]", end="", flush=True)
break
print()
# ====================== 如果有 full_reply,则添加消息并继续对话 ======================
if full_reply and not tool_calls:
messages.append({"role": "assistant", "content": full_reply})
return
# ====================== 如果有 tool_calls,则执行工具并继续对话 ======================
if tool_calls:
# 1. 把 assistant 的 tool_calls 加入历史
messages.append({"role": "assistant", "tool_calls": tool_calls})
# 2. 执行所有工具(支持并行)
for tc in tool_calls:
print(f"tool_call: {tc} \n")
tool_name = tc["function"]["name"]
try:
tool_args = (
json.loads(tc["function"]["arguments"])
if tc["function"]["arguments"]
else {}
)
except json.JSONDecodeError:
tool_args = {}
print(f"[Warning] 参数解析失败: {tc['function']['arguments']}\n")
print(f"→ 调用工具: {tool_name}({tool_args})\n")
too_func = tools_map[tool_name]
result = await too_func(**tool_args)
print("📨 工具返回:", result, "\n")
messages.append(
{"role": "tool", "tool_call_id": tc["id"], "content": result}
)
async def main():
llm = DeepSeekLLM(model="deepseek-reasoner")
messages = []
print("🤖 DeepSeek Chat 已启动 (输入 exit 退出)")
while True:
# 1️⃣ 从终端读取输入(阻塞)
user_input = input("\n👤 You: ")
# 2️⃣ 退出条件
if user_input.lower() in ["exit", "quit"]:
print("👋 Bye!")
break
messages.append({"role": "user", "content": user_input})
await run_agent(llm, messages)
if __name__ == "__main__":
asyncio.run(main())在 main.py 顶部添加这些定义:
Python
# 这是真实的 Python 函数映射
tools_map = {"get_forecast": get_forecast}
# 这是给大模型看的"菜单说明书" (符合 OpenAI Tool Schema 标准)
tools = [
{
"type": "function",
"function": {
"name": "get_forecast",
"description": "weather: Get weather forecast for a location.",
"strict": False,
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"title": "Latitude",
},
"longitude": {
"type": "number",
"title": "Longitude",
},
},
"required": ["latitude", "longitude"],
"additionalProperties": False,
},
},
},
]接下来还有一个关键问题:
模型什么时候会决定调用工具?
答案是:
👉 当模型发现 自己没法凭空回答,但工具说明书里刚好有能解决问题的工具时。
比如用户问:
明天纽约天气怎么样?
模型在推理时会意识到:
- 这是一个实时信息问题
- 我不能编(不应该幻觉)
- 工具列表里刚好有
get_forecast - 参数需要 latitude + longitude
- 所以 → 调用工具
这一步,其实就是 Agent 的第一次"行动"。
这里补充一下说明,这个 JSON Schema 其实不是我们随便设计的格式,而是目前整个 LLM Tool Calling 生态里的 OpenAI Tool Schema 标准。
这里你可以阅读一下 DeepSeek 的 Tool Calls 文档:
3. 解析流式 Tool Calls(最容易踩坑的地方)
很多新手在做流式 Tool Calling 时会崩溃,因为大模型决定调用工具时,它的参数也是一个字一个字流式吐出来的!我们需要在代码里把它拼凑成完整的 JSON。
把 llm/deepseek.py 的 stream_chat 方法更新成这样:
Python
async def stream_chat(
self,
messages: list,
tools: list = [],
temperature: float = 1.3,
max_tokens: int = 1024,
) -> AsyncGenerator[Union[str, Dict], None]:
"""
流式聊天,支持 tool calls
Yield:
str: 普通文本内容(直接展示给用户)
dict: 当检测到 tool calls 时,yield {"type": "tool_calls", "tool_calls": [...]}
"""
response = await self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=tools,
temperature=temperature,
max_tokens=max_tokens,
stream=True,
)
# 用来拼接碎片的收集器
tool_calls: List[Dict] = []
async for chunk in response:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# 1. 普通文本内容(直接 yield 给前端/用户)
if delta.content:
yield delta.content
# 2. 如果模型决定调用工具,会返回 tool_calls 数据块
if delta.tool_calls:
for tool_delta in delta.tool_calls:
idx = tool_delta.index
# 初始化收集器
while len(tool_calls) <= idx:
tool_calls.append(
{
"id": None,
"type": "function",
"function": {"name": None, "arguments": ""},
}
)
# 当前正在处理的 tool call
tc = tool_calls[idx]
# 累积 id(通常只出现一次)
if tool_delta.id:
tc["id"] = tool_delta.id
# 累积 function name(通常只出现一次)
if tool_delta.function and tool_delta.function.name is not None:
tc["function"]["name"] = tool_delta.function.name
# ⚠️ 关键点:把一段段传过来的 JSON 参数字符串拼接起来
if tool_delta.function and tool_delta.function.arguments:
tc["function"]["arguments"] += tool_delta.function.arguments
# ====================== 流式结束后处理 ======================
# 流式传输结束后,如果有完整的 tool calls,就把它抛出去
valid_tool_calls = [
tc
for tc in tool_calls
if tc.get("function", {}).get("name") # 有函数名才算有效
]
if valid_tool_calls:
yield {"type": "tool_calls", "tool_calls": valid_tool_calls}Tool Calling 的本质:模型输出 JSON,而不是文字
很多同学第一次接触 Tool Calling 时,会以为:
模型是不是会"真的调用函数"?
答案是:不会。
大模型其实永远只会做一件事:
👉 生成文本(token)
Tool Calling 本质上只是让模型在某些情况下,不要输出自然语言,而是输出一段符合规范的 JSON。
比如当用户问:
明天纽约天气怎么样?
模型可能会输出(概念上):
Python
{
"tool_calls": [
{
"name": "get_forecast",
"arguments": {
"latitude": 40.7128,
"longitude": -74.0060
}
}
]
}注意 ⚠️
这一步仍然是 模型生成文本 ,只是这段文本被 SDK 解析成了 tool_calls 结构。
真正执行函数的,其实是我们的代码。
这就是一个非常重要的认知转变:
| 角色 | 负责什么 |
|---|---|
| LLM | 决定 要不要用工具 + 用哪个工具 + 给什么参数 |
| 我们的程序 | 真的执行工具 + 把结果再喂回模型 |
这就是 Agent 的核心循环雏形了。
第四步:注入灵魂 ------ 实现 Agent 推理循环 (Agent Loop)
接下来就是整篇文章的灵魂部分了。
大家常听说的 ReAct (Reasoning + Acting) ,本质上就是一个 while 循环:
- 模型思考(我要不要用工具?)
- 行动(调用工具拿结果)
- 观察(把结果告诉模型,继续思考)
- 输出最终答案。
但其实它们的底层本质就只有一件事:
🔁 循环调用 LLM,直到任务完成
我们把这个循环称为:
⭐ Agent Loop
它的工作流程其实非常简单:
objectivec
用户提问
↓
LLM 思考
↓
是否需要调用工具?
↓ YES ↓ NO
调用工具 直接回答用户
↓
把工具结果喂回 LLM
↓
继续思考...是不是突然感觉 Agent 没那么神秘了?😄
让我们在 main.py 中把这个闭环写出来:
这是整篇文章最重要的函数,请慢慢看 👇
Python
async def run_agent(llm, messages):
"""
Agent 的核心推理循环
"""
while True:
print("\n🤖 DeepSeek says: thinking...\n\n", end="", flush=True)
full_reply = ""
tool_calls = None
# 1. 询问大模型(带上工具说明书)
async for chunk in llm.stream_chat(messages=messages, tools=tools):
if isinstance(chunk, str):
full_reply += chunk
print(chunk, end="", flush=True)
elif isinstance(chunk, dict) and chunk.get("type") == "tool_calls":
tool_calls = chunk["tool_calls"]
print("[工具调用中...]", end="", flush=True)
break # 暂停文本输出,去执行工具
print()这里发生了一件非常重要的事情:
LM 的返回现在有两种可能
情况 ①:模型直接回答
Python
chunk = "纽约明天天气..."说明模型觉得 不需要工具,直接能回答。
情况 ②:模型请求调用工具
Python
chunk = {
"type": "tool_calls",
...
}说明模型决定:
🧠 "我需要查天气!"
这就是 模型自己做决策的瞬间。
当模型决定调用工具
接下来就是 Agent 和工具真正开始协作了。
Python
if tool_calls:
# 把 tool_calls 加入历史
messages.append({"role": "assistant", "tool_calls": tool_calls})这一句非常关键:
👉 我们把「模型决定调用工具」这件事写进聊天历史。
为什么要这样做?
因为下一次再调用 LLM 时,它需要知道:
"我刚刚已经调用过工具了。"
这一步叫做:
让模型记住自己的行动。
执行工具 🔧
接下来是真正执行 Python 函数:
Python
for tc in tool_calls:
tool_name = tc["function"]["name"]
tool_args = json.loads(tc["function"]["arguments"])
too_func = tools_map[tool_name]
result = await too_func(**tool_args)这里完成了一个超级重要的转换:
| LLM 世界 | 现实世界 |
|---|---|
| "call get_forecast" | 调用 Python 函数 |
| JSON 参数 | Python kwargs |
| Tool response | 函数返回值 |
换句话说:
🤖 LLM 在"写代码",我们在"执行代码"。
把工具结果喂回模型
这一步就是 Agent 的魔法时刻 ✨
Python
messages.append(
{
"role": "tool",
"tool_call_id": tc["id"],
"content": result
}
)现在聊天历史变成了这样:
text
user: 明天纽约天气?
assistant: (我要调用工具)
tool: 天气结果...下一轮再调用 LLM 时,它就能看到:
"哦!工具已经帮我查到天气了,我可以回答用户了!"
于是模型就会生成最终答案 🎉
Agent Loop 完整闭环
现在再回头看这个 while True:
Python
while True:这意味着什么?
意味着:
- 模型可以连续调用多个工具
- 可以调用工具 → 再调用工具 → 再回答
- 理论上可以无限推理
这就是一个最小可用的 ReAct Agent。
你已经亲手实现了 😎
见证奇迹的时刻 🎉
敲入这行命令,启动你的 Agent:
bash
uv run python main.py输入: "明天纽约天气怎么样?"
你会看到惊艳的一幕发生:
- 🤖 模型收到问题,分析出它不知道答案,但发现你有查天气的工具。
- 🛠️ 模型吐出一段 JSON 告诉你的程序:帮我调
get_forecast。 - 👉 你的 Python 代码拦截到了这个请求,发送 HTTP 请求查询到了纽约(纬度40.71,经度-74.00)的天气,并把 JSON 返回给模型。
- 🤖 模型看到真实的数据后,用非常自然、拟人的口吻,结合天气情况回答了你的问题。
💡 这就是 Agent! > 大模型不再是被动回答的百科全书,它有了手脚,能感知周围的环境,调用外部资源来达成你交代的任务。这也是普通 ChatBot 向 Agent 跨出的最关键一步。
这里是我本地的运行演示:
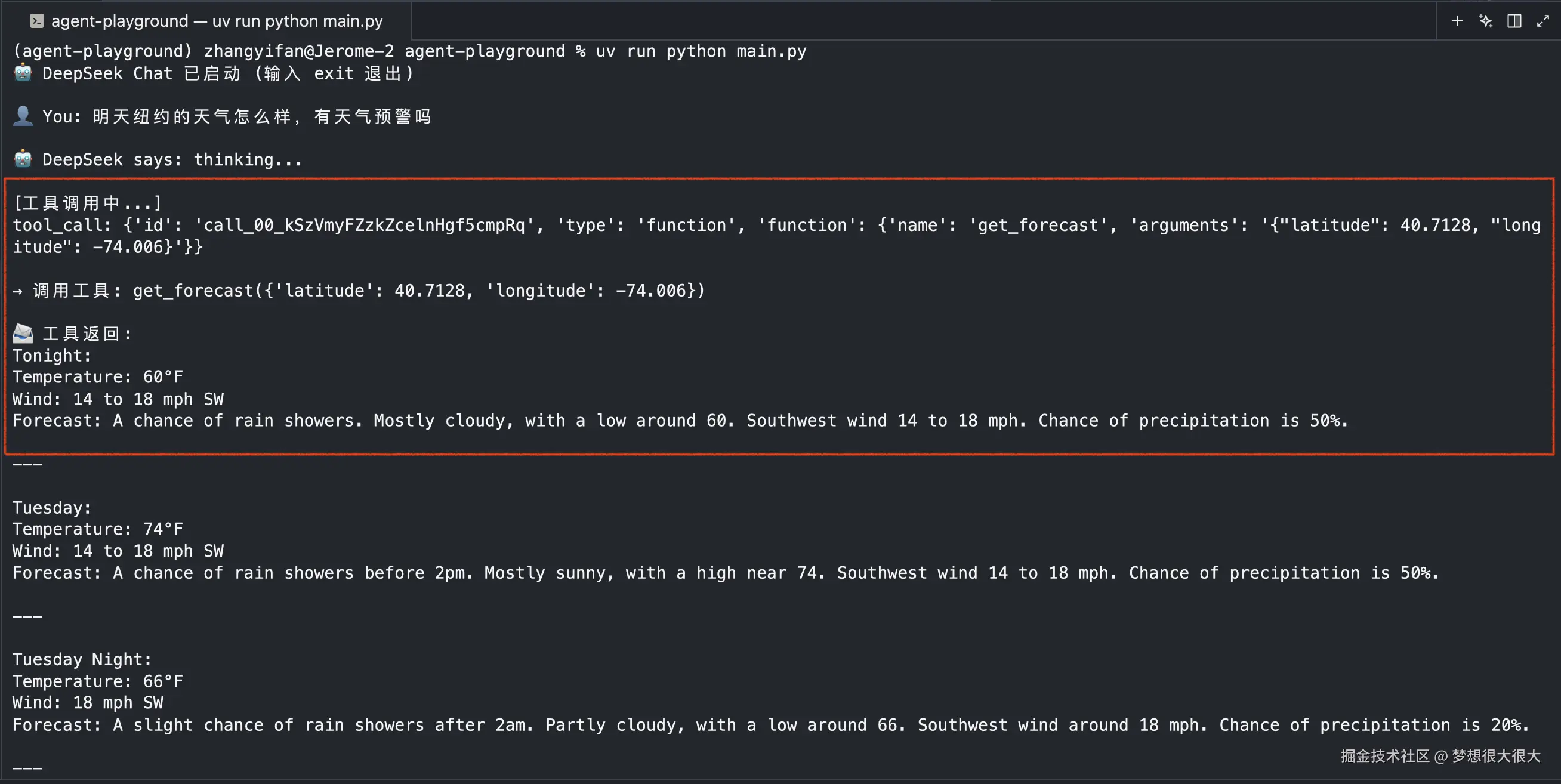
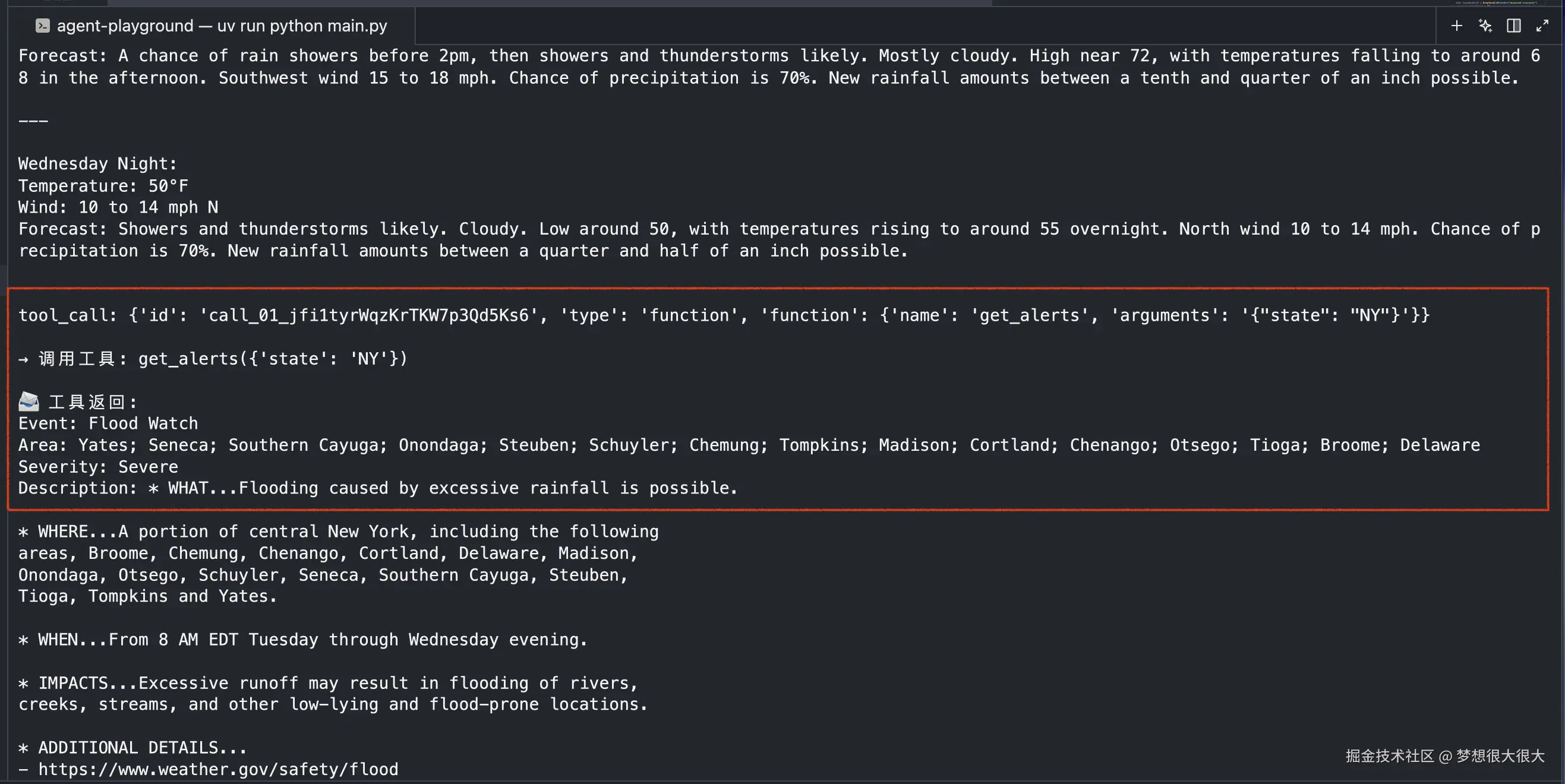
我们再试试另一个问题:明天纽约的天气怎么样,有天气预警吗,看多个工具的调用是否也正常。
main.py需要更改一下:
Python
# 注册 get_alerts 工具
tools_map = {"get_forecast": get_forecast, "get_alerts": get_alerts}
tools = [
{
"type": "function",
"function": {
"name": "get_forecast",
"description": "weather: Get weather forecast for a location.\n\nArgs:\n latitude: Latitude of the location\n longitude: Longitude of the location\n",
"strict": False,
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"description": "",
"title": "Latitude",
},
"longitude": {
"type": "number",
"description": "",
"title": "Longitude",
},
},
"required": ["latitude", "longitude"],
"additionalProperties": False,
},
},
},
{
"type": "function",
"function": {
"name": "get_alerts",
"description": "weather: Get weather alerts for a US state.\n\nArgs:\n state: Two-letter US state code (e.g. CA, NY)\n",
"strict": False,
"parameters": {
"type": "object",
"properties": {
"state": {"type": "string", "description": "", "title": "State"}
},
"required": ["state"],
"additionalProperties": False,
},
},
},
]演示:
可以看到两个工具都已经被成功调用了:
🎉 第一篇小结
恭喜你!到这里,你已经亲手撸出了一个 ReAct Agent 的最小原型(MVP) 。 我们回顾一下目前的成果:
我们实现了:
- ✅ 使用 DeepSeek 跑通了 LLM 核心接口。
- ✅ 完美处理了逼格极高但容易写出 Bug 的"流式响应输出"。
- ✅ 实现了业务工具映射和 Tool Schema 注册。
- ✅ 构建了 Agent 最核心的
While True(思考->工具->回答)闭环架构。
换句话说:
我们已经从 ChatBot → Agent 跨出了最关键的一步。
接下来做什么?
看下我们现在的代码,你会发现一个痛点: 目前注册工具还是全手工的 ------ 写完函数,还得手写一大串啰嗦的 JSON Schema,如果参数一多,简直是反人类 😅。
在下一篇《从 0 到 1 实现 AI Agent(02)》中,我们将对 Tool 系统进行大重构:
- 做一个通用的 Tool 注册与调用模块
- 让新工具可以"即插即用"
不过不会完全照搬 MCP ------ 我们会走一条更贴近真实 Web / 企业开发的实现路线 👀
🔗 源码与延伸阅读
本文源码仓库:GitHub - agent-playground
如果你对 Agent 的演进方向非常感兴趣,强烈推荐提前预习 B 站这个关于 MCP 协议的硬核系列:
如果在实操中遇到任何报错或者有疑惑的地方,欢迎在评论区留言或者去 GitHub 提 Issue,我们一起探讨。
如果觉得这篇文章帮你把 Agent 的概念落了地,别忘了点个赞 👍 + 收藏 ⭐ 哦!我们下一篇见~