Day 2-Linux复习日
今天主要是速通一下linux,顺便继续看+做算法题。
今天看到别人推荐的这个书不错:Hello-Agents
1.hot100-进度8/100
复习一下前几道题,还是照常看几集灵神的课,然后做题,我是优先做简单和中等难度的,困难的放到最后。
15. 三数之和
这道题之前明明有看过,但还是忘记做法了,我下意识使用的方案2,简直做的一塌糊涂,思路也完全错了。
- 三个数相加等于0,等同于
两个数相加的和等于负的第三个数。 - 有两种方案可供选择:
- 先定下一个数,然后查找另外两个数。
- 先定下两个数,然后查找第三个数。
- 如果选择
方案2,需要用到Map。因为需要对nums去重复;在Map中查找第三个数时,还需要避开已经定下的两个数,实现起来会比较麻烦。 - 如果选择
方案1,查找另外两个数时,需要用到双指针算法。
第一种解法:双指针
排序 + 双指针 + 集合自动去重 的三数之和解法。
- list:有序、可重复
- set:无序、自动去重
- 取每一个数字作为三元组的第一个数
nums[:len(nums)-2]保证后面至少还有 2 个数字,才能构成三元组
还有一个知识点我搞混了:
- add 是 **set 的方法:**不管 x 重不重复,直接往后面加。
- append 是 **list 的方法:**如果 x 已经存在,什么都不做 ;如果不存在,才加进去
时间复杂度:O(N * N)
空间复杂度:O(N)
cs
class Solution:
def threeSum(self, nums: list[int]) -> list[list[int]]:
nums.sort()
results = set()
for i,num in enumerate(nums[:len(nums) - 2]):
left = i + 1
right = len(nums) - 1
while left < right:
sum_ = nums[left] + nums[right]
if sum_ == -num:
results.add((num,nums[left],nums[right]))
left += 1
elif sum_ > -num:
right -= 1
else:
left += 1
return list(results)第二种解法:使用 Map(慢而复杂)
这个解法速度太慢,主要是了解一下思路就好。
将这道题拆分为:两数之和 + 哈希表 = 三数之和
时间复杂度:O(N * N)
空间复杂度:O(N)
cs
# from collections import defaultdict
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums = duplicate_removed_nums(nums)
results = set()
num_to_indices = defaultdict(list)
for i, num in enumerate(nums):
num_to_indices[num].append(i)
for i in range(len(nums) - 1):
for j in range(i + 1, len(nums)):
if -(nums[i] + nums[j]) in num_to_indices:
for index in num_to_indices[-(nums[i] + nums[j])]:
if index not in (i, j):
result = [nums[i], nums[j], nums[index]]
result.sort()
results.add(tuple(result))
return list(results)
def duplicate_removed_nums(nums):
num_to_count = defaultdict(int)
for i, num in enumerate(nums):
if num_to_count[num] <= 2 or (num_to_count[num] <= 3 and num == 0):
num_to_count[num] += 1
new_nums = []
for num in num_to_count:
new_nums.extend([num] * num_to_count[num])
return new_nums知识点:
- defaultdict(int):Python 专门用来计数的神器字典,用来记录每个数字出现了几次。
- extend:把里面元素拆开放入
- defaultdict(list):这是一个字典 :key:数字 ;value:这个数字出现的所有下标(位置)列表
42. 接雨水
这道题属于困难级别,但是看过灵神的课,感觉还是有些思路,遂挑战之。
挑战失败,虽然思路对了但是一直没法实现,还是再练练吧。
我自己写的错误代码:
cs
class Solution:
def trap(self, height: List[int]) -> int:
water = 0
left = 1
right = len(height) - 2 #10
l_height = height
r_height = height
for i in height[1:len(height) - 1]:
l_height[left] = max(l_height[left],height[left - 1])
left += 1
r_height[right] = max(r_height[right],height[right - 1])
right -= 1
for j in l_height:
water += min(l_height[j],r_height[j]) - height[j]
return water最致命错误:l_height = height 是浅拷贝,不是新数组。在 Python 中,= 是引用赋值 ,l_height 和 height 指向同一个列表。
第一种解法:前后缀最大值
这个版本是最正确的写法。。。:
时间复杂度:O(n)
空间复杂度:O(n)
cs
class Solution:
def trap(self, height: List[int]) -> int:
n = len(height)
if n <= 2:
return 0
# 错误1修复:创建新数组,不是别名
l_height = [0] * n
r_height = [0] * n
# 左最大值(正确写法)
l_height[0] = height[0]
for i in range(1, n):
l_height[i] = max(l_height[i-1], height[i])
# 右最大值(正确写法)
r_height[-1] = height[-1]
for i in range(n-2, -1, -1):
r_height[i] = max(r_height[i+1], height[i])
# 计算雨水(错误4修复:遍历下标)
water = 0
for i in range(n):
water += min(l_height[i], r_height[i]) - height[i]
return water第二种解法:双指针写法(最快、最省空间)
左右两边同时往中间走,哪边柱子矮就从哪边算雨水,用两个变量记录左右最高,不用额外数组,一遍遍历就算完。
- 时间复杂度:O(n)(只跑一遍)
- 空间复杂度:O(1)(不用数组,只用 4 个变量)
cs
class Solution:
def trap(self, height: list[int]) -> int:
left = 0
right = len(height) - 1
left_max = right_max = 0
water = 0
while left < right:
if height[left] < height[right]:
if height[left] >= left_max:
left_max = height[left]
else:
water += left_max - height[left]
left += 1
else:
if height[right] >= right_max:
right_max = height[right]
else:
water += right_max - height[right]
right -= 1
return water3. 无重复字符的最长子串
第一种解法:暴力(慢且不高效)
这道题我自己的解法如下:暴力枚举所有起点,往后找不重复的子串,记录最长长度
cs
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
result = 0
for c in s:
max_str = 0
num_to_count = defaultdict(int)
for i,c in enumerate(s):
if num_to_count[c] == 0:
num_to_count[c] += 1
max_str += 1
result = max(result,max_str)
return result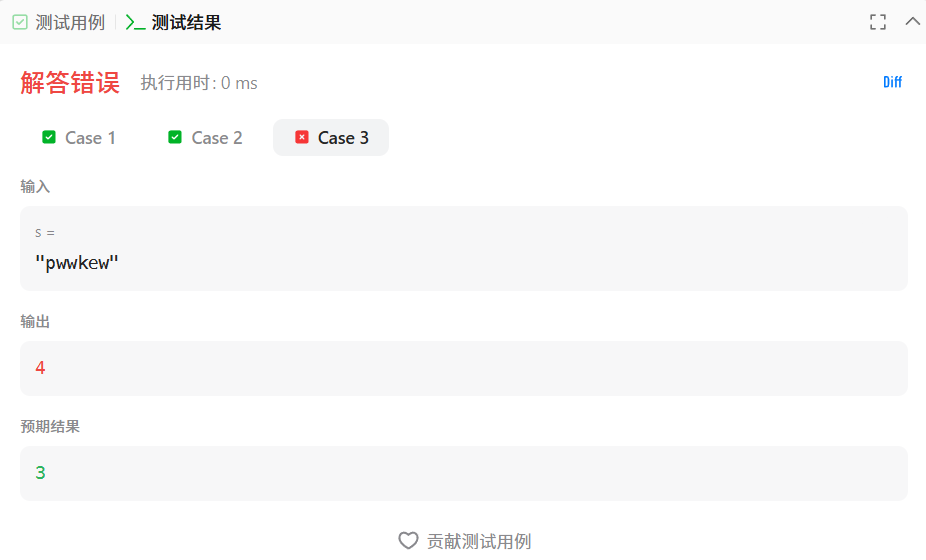
结果通过了两个案例,最后一个没通过。
**问题:**外层多了一层完全多余的循环,导致每次还没计算完就重置当前长度和计数器;内层循环没有处理字符重复的情况,遇到重复时不会停止,逻辑不符合题目要求;同时 result 的更新位置也不对,整体结构混乱,无法正确算出最长无重复子串的长度。
更正后的正确解法:
cs
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
result = 0
n = len(s)
# 从每个位置 i 开始,往后找无重复子串
for i in range(n):
seen = set()
current_length = 0
for j in range(i, n):
if s[j] in seen:
break # 重复就停止
seen.add(s[j])
current_length += 1
result = max(result, current_length)
return result时间复杂度:O (n²)
空间复杂度:O (n)
第二种解法:滑动窗口(Sliding Window) 最优解法
思路:用左右指针形成一个窗口 ,右边一直往右走,遇到重复就把左边直接跳到合法位置,全程只遍历一次字符串,最快
- 时间复杂度:O (n)
- 空间复杂度:O (n)
cs
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
char_index = {} # 记录字符最后出现的位置
left = 0 # 窗口左边界
max_len = 0 # 最长长度
for right, c in enumerate(s):
# 如果字符重复,且在窗口内,左边界直接跳到重复位置+1
if c in char_index and char_index[c] >= left:
left = char_index[c] + 1
char_index[c] = right
max_len = max(max_len, right - left + 1)
return max_len感觉滑动窗口的题还是没有特别理解,今天先到这里,再去看几个视频缓一下。
2.Linux学习
感觉linux没有特别合适的课,直接看官方文档比较快:https://www.gnu.org/software/coreutils/manual/coreutils.html?utm_source=chatgpt.com
有基础的准备速成的可以选择性的过一遍这个up主的视频,我觉得精简但是有干货:【GeekHour】30分钟Linux入门教程 - 哔哩哔哩
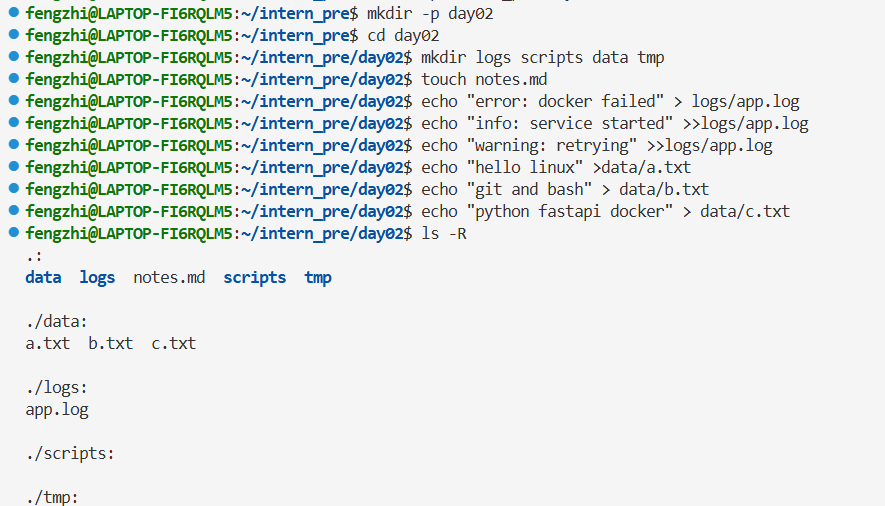
2.1准备测试文件并检查
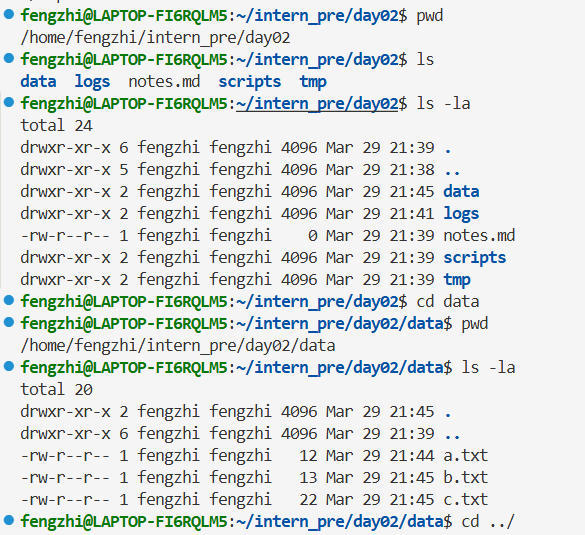
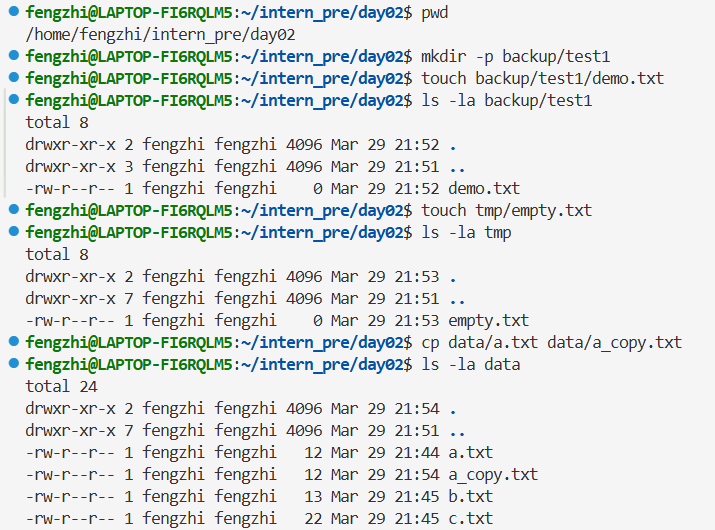
2.2基础文件和目录操作
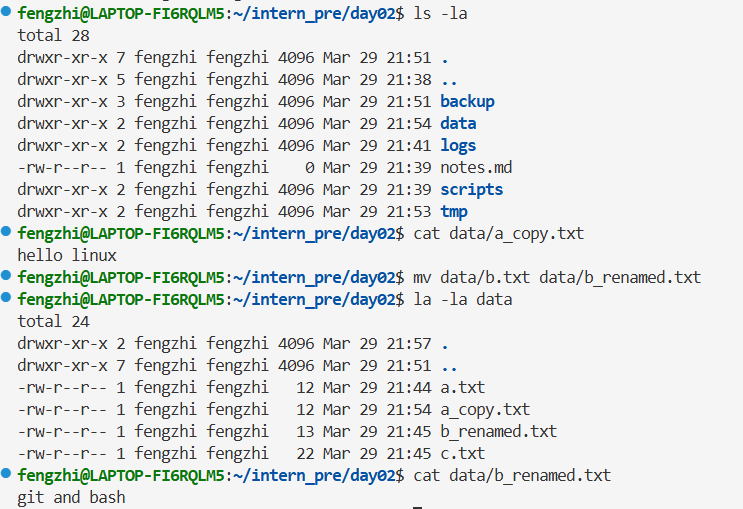
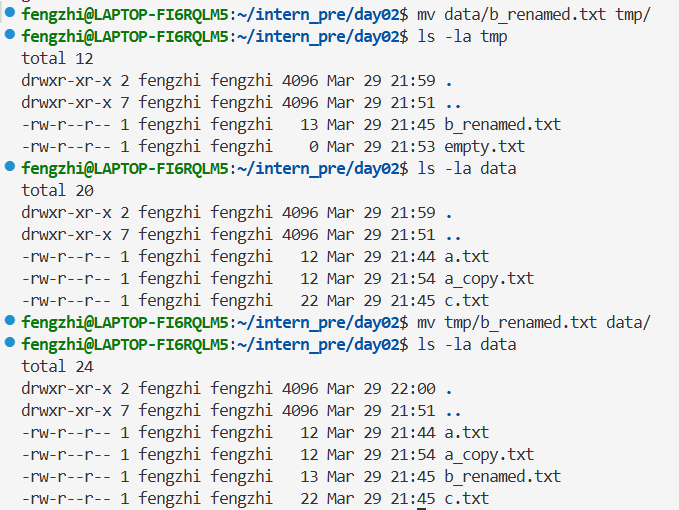
2.3 grep 和 find
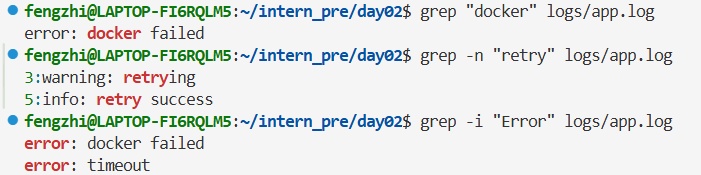
练习 1:grep 基础搜索
查找 error:

显示行号:

忽略大小写:

再练几个:
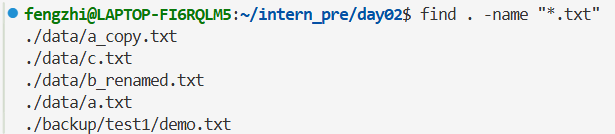
练习 2:find 查找文件
查找所有 txt 文件:
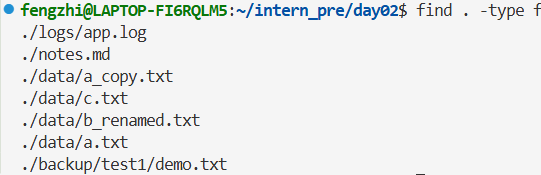
查找所有普通文件:
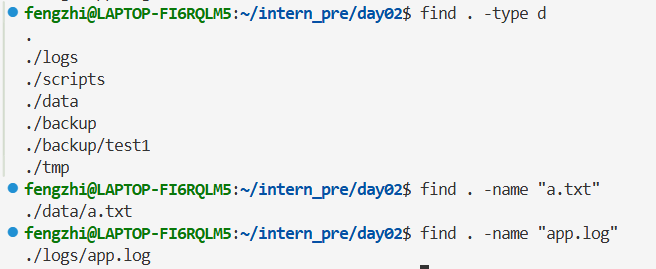
查找所有 log 文件:

再练几个:
练习 3:find + xargs 组合
find负责找文件xargs负责把这些文件批量交给下一个命令处理
这就是 Linux 里非常常见的批量处理套路。
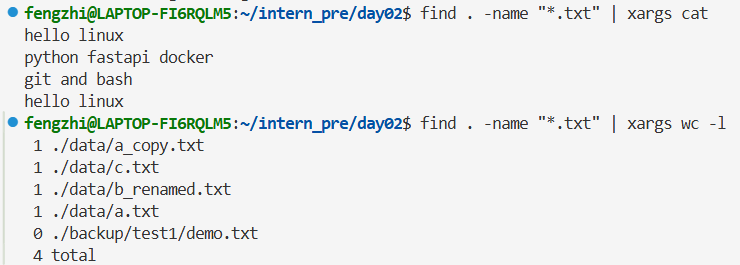
在所有 .txt 文件中搜索 linux:

把所有普通文件用 ls -l 展示详情:
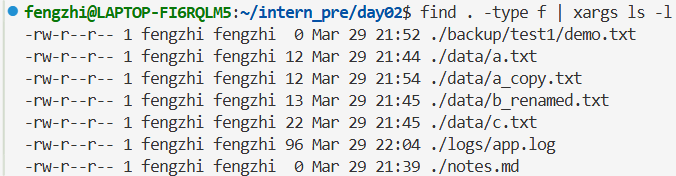
再练两个:
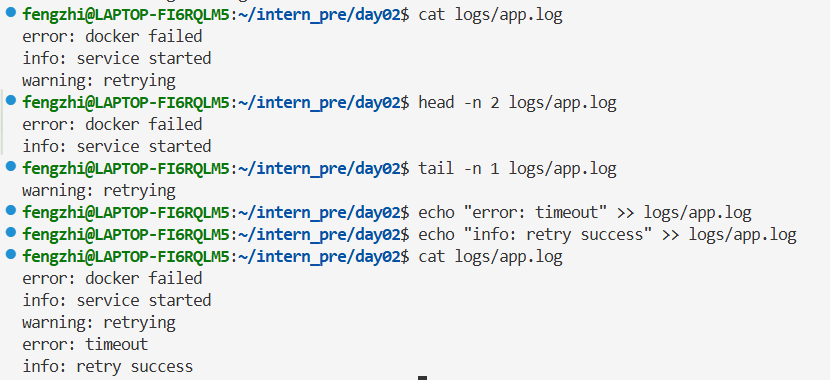
2.4 重定向和管道
练习 1:覆盖重定向 >
把目录列表写入文件:
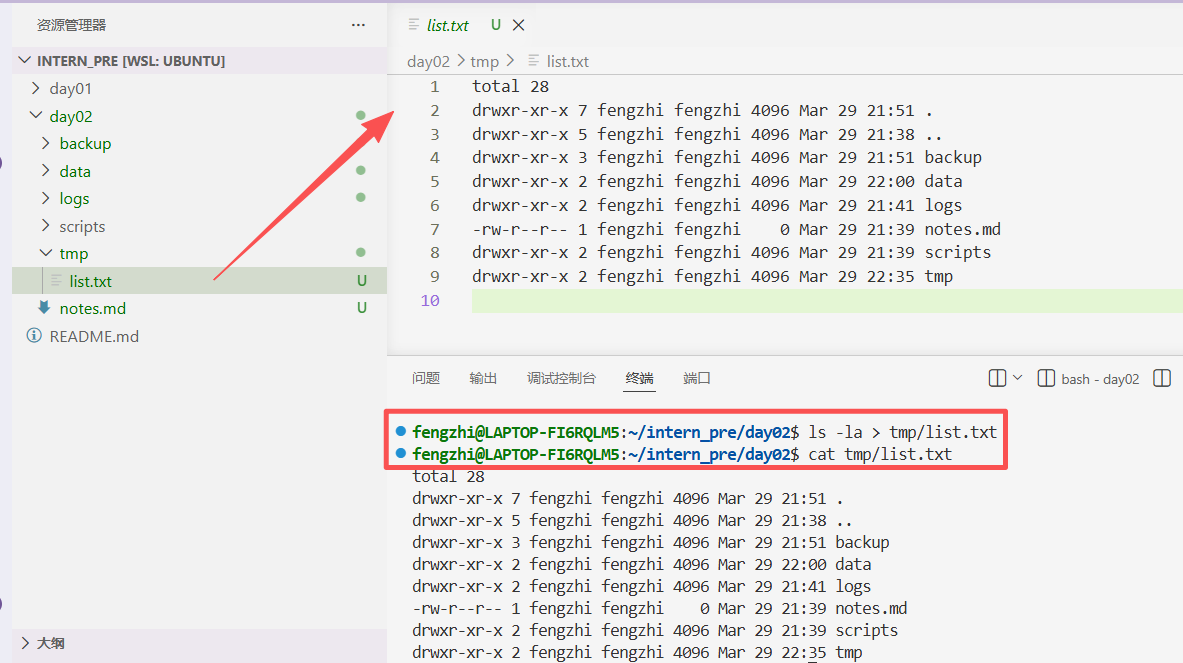
再覆盖一次:(前一次内容被覆盖了)

练习 2:追加重定向 >>
(>> 是在原文件后面追加)

练习 3:管道 |
从日志里筛选 error:

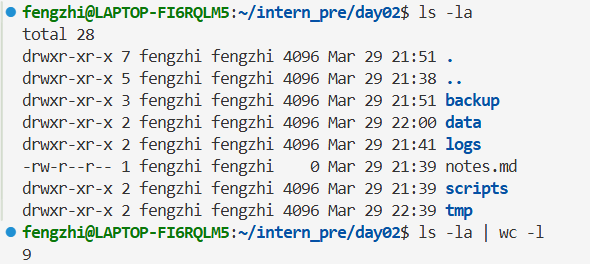
统计日志总行数:

统计当前目录所有普通文件数量:(wc -l:统计列表的行数 = 统计文件的总数量)

再练几个:

练习 4:把搜索结果输出到文件

2.5 权限、进程、端口、日志跟踪
练习 1:写一个最小 shell 脚本
创建脚本:

先直接执行,通常会报权限问题:

加执行权限:

再执行:

练习 2:查看进程
命令本身:ps
- 全称:Process Status(进程状态)
- 作用:列出当前系统中正在运行的进程
- 你输入的是无参数的
ps,只会显示当前终端(pts/4)下的进程,不会显示系统后台进程。

| 列名 | 全称 | 含义 |
|---|---|---|
| PID | Process ID | 进程 ID(系统给每个进程分配的唯一编号,用来管理进程) |
| TTY | Teletypewriter | 终端设备(进程运行在哪个终端窗口) |
| TIME | CPU Time | 进程占用 CPU 的总时间(格式 时:分:秒) |
| CMD | Command | 启动这个进程的命令 / 程序名 |
补充:常用 ps 拓展命令(工作中必用)
| 命令 | 作用 | |
|---|---|---|
ps aux |
查看系统所有进程的详细信息(最常用) | |
ps -ef |
另一种格式查看所有进程 | |
| `ps -ef | grep bash` | 筛选出所有 bash 进程 |
kill 9627 |
强制关闭 PID 为 9627 的 bash 进程(会关闭当前终端) |
看更完整的信息:
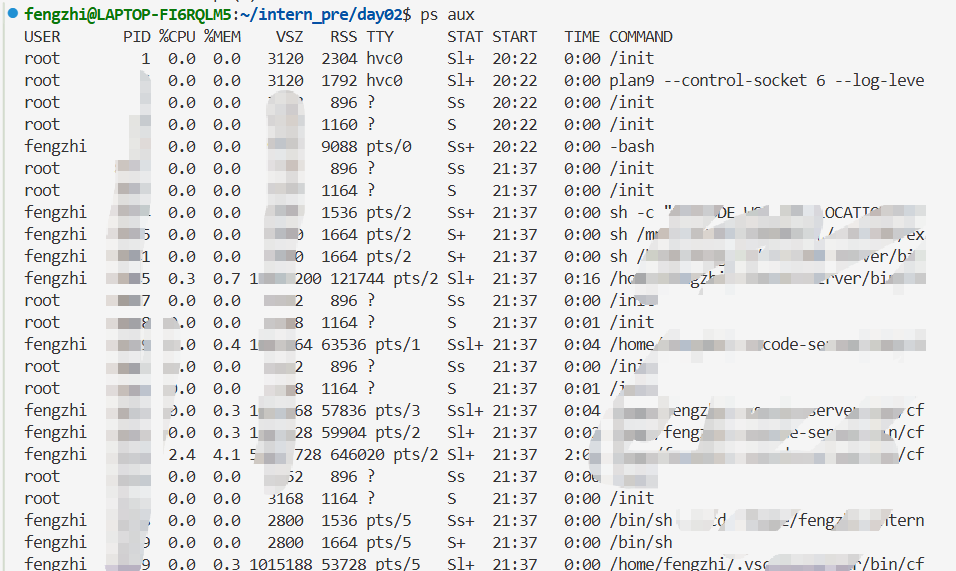
过滤 bash 相关进程:

练习 3:查看监听端口
ss -ltn = 只查看本机正在监听的 TCP 端口,并用数字形式显示
① ss( Socket Statistics)
- 作用:查看系统网络连接、端口状态
- 比
netstat更快、更现代
② -l → Listen(监听)
- 只显示正在监听、等待连接的端口
- 不显示已经连上的连接
③ -t → TCP
- 只看 TCP 协议 的端口
- 不看 UDP
④ -n → Numeric(数字)
- 不把端口号翻译成名字(比如 80 不翻译成 http)
- 直接显示数字 IP、数字端口,看得更清楚

练习 4:跟踪日志变化
打开一个终端执行:
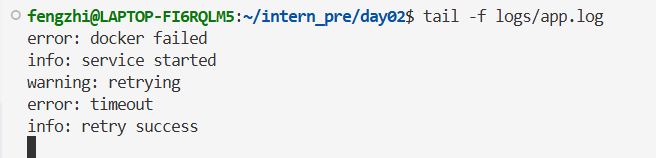
然后再开另一个终端,往日志追加内容:

会看到 tail -f 那边实时刷新:
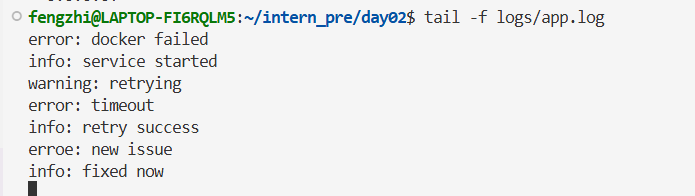
按Ctrl + C结束。
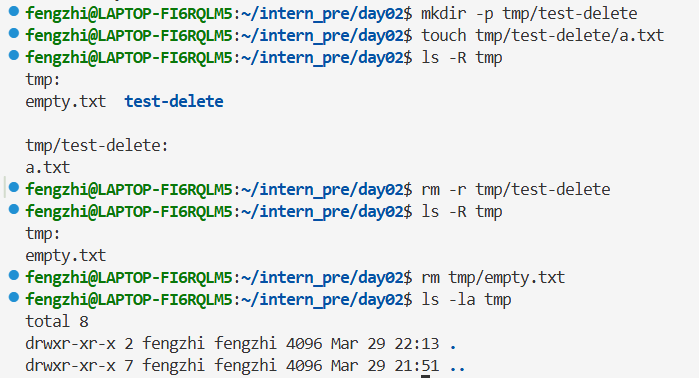
2.6 综合练习
任务 1:统计所有 .txt 文件行数,并写入 summary.txt
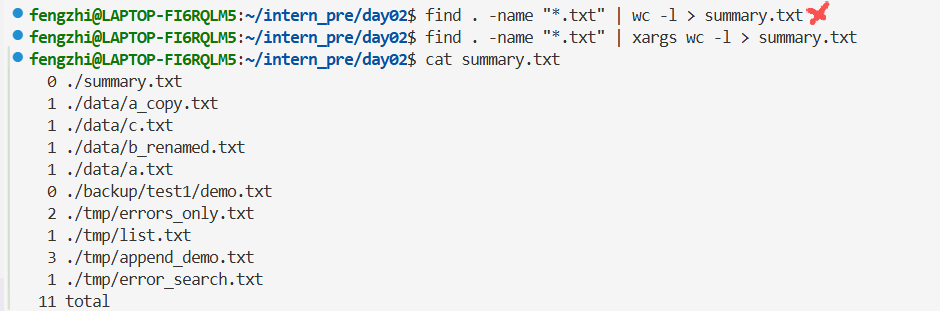
第一行是我自己想的错误答案。
区别在于:xargs 会把管道传来的多行文件路径 ,转换成 wc -l 命令的命令行参数
| 写法 | 统计对象 | 输出结果 | 是否符合需求 | |
|---|---|---|---|---|
| `find . -name "*.txt" | wc -l` | .txt 文件的个数(路径行数) |
单个数字(文件数量) | ❌ 错误 |
| `find . -name "*.txt" | xargs wc -l` | 每个 .txt 文件的内容行数 |
分文件行数 + 总行数 | ✅ 正确 |
任务 2:统计所有日志里包含 error 的行
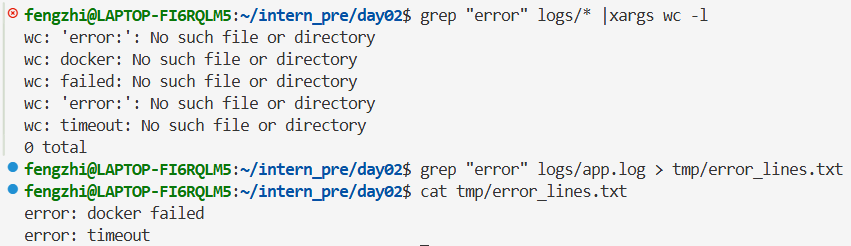
是我想复杂了,以为logs文件夹下面有很多个日志文件,所以有些混乱。
任务 3:列出当前目录所有文件详情,并保存
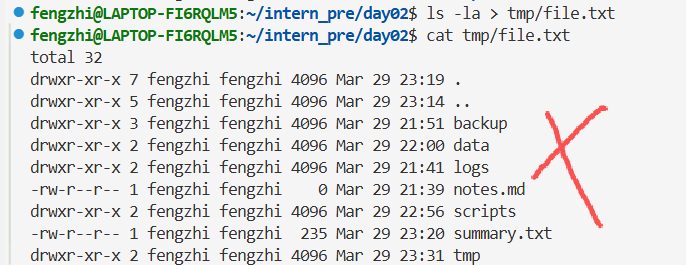
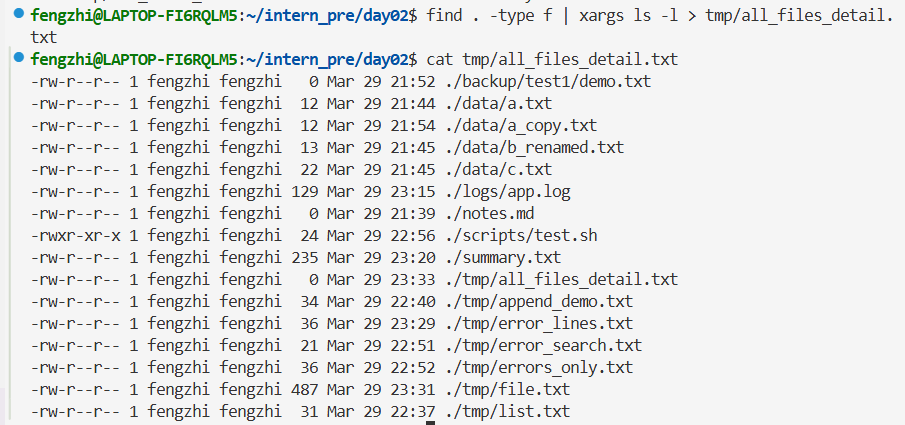
| 命令 | 范围 | 显示内容 | 是否递归 |
|---|---|---|---|
ls -la |
当前目录 | 文件 + 文件夹 | ❌ 不递归 |
find ... ls -l |
全部目录 | 只显示文件 | ✅ 递归 |
这是两种结果的区别,还是得认真审题啊。
今日份linux学完,推送至github即可。
3.补充git知识
感觉git命令还是得练一下,还是强推这个up主的课程:【GeekHour】一小时Git教程_哔哩哔哩_bilibili
笔记的话这个链接里面up主也整理好了,我就不做笔记,大概过一遍得了。
4.Docker入门
Docker看的还是这位up主的,很适合速成/有一点基础的:【GeekHour】30分钟Docker入门教程_哔哩哔哩_bilibili
上面的视频感觉确实有点太短了,有些不知所云,所以我又自己找了点小题目实操一下。
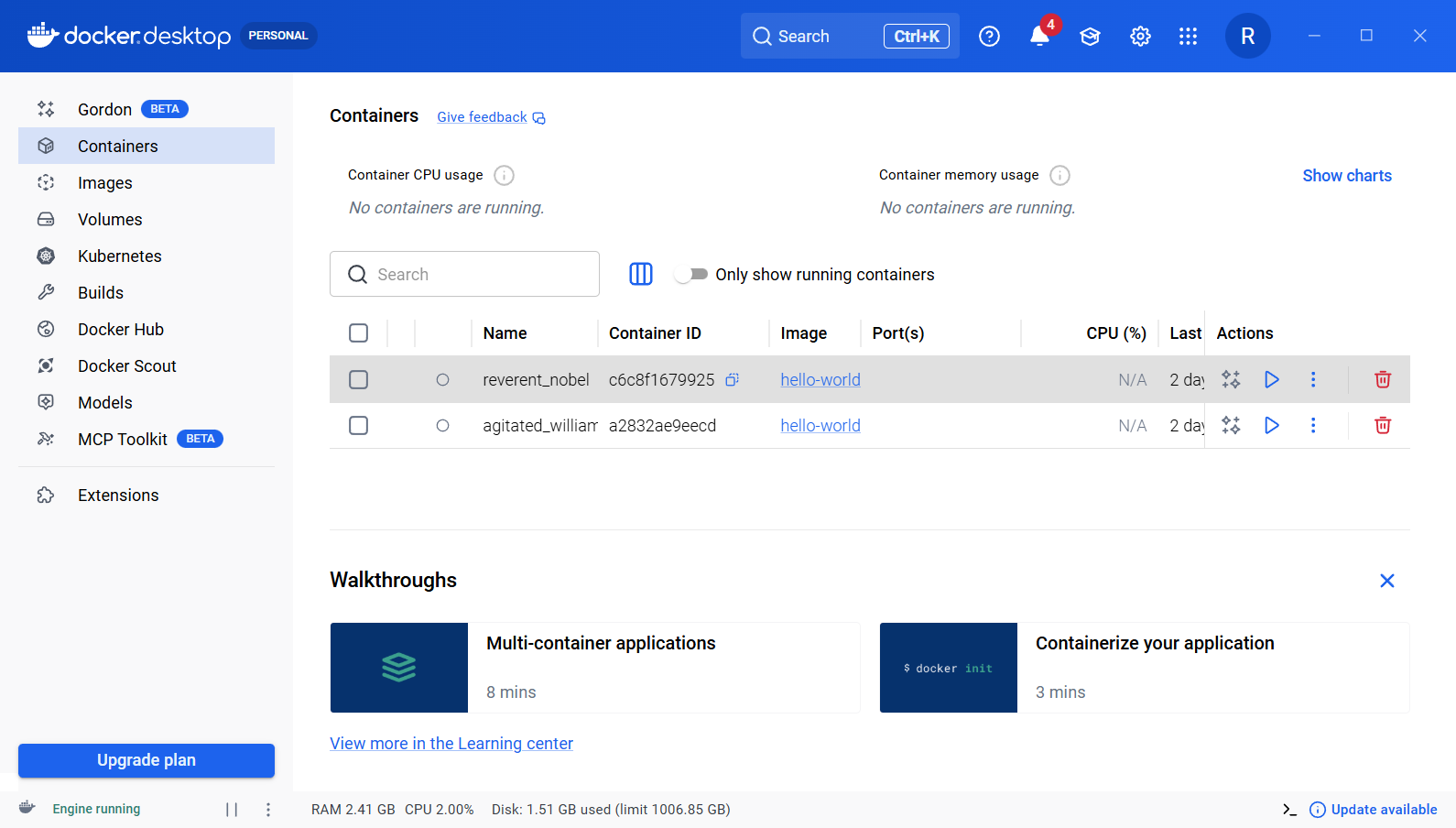
简单的练习一下 Docker 中的命令。我是windows环境,首先在本地终端激活WSL,再在VS Code 打开就可以了,方便很多。
4.1 确认 Docker 和 WSL 打通
分别用来看:正在运行的容器、所有容器、已有镜像
**
docker version:**查看 Docker 客户端和服务端版本。如果这个命令能正常输出,说明 Docker CLI 和 Docker Engine 已经联通。**
docker ps:**查看当前正在运行的容器。**
docker images:**查看本机已有的镜像。
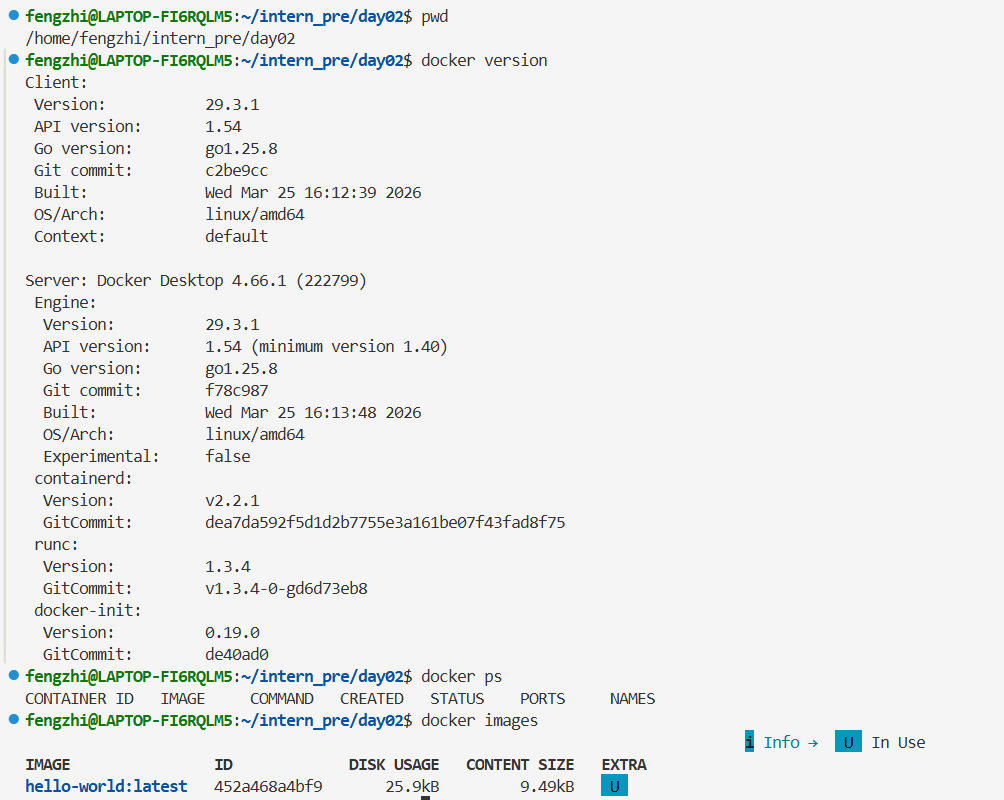
4.2 重要概念
4.2.1镜像
镜像就是一个可重复复制的程序运行模板。
里面已经准备好了某个程序运行所需的环境、文件和依赖。
比如:
nginx镜像:里面已经装好了 nginxpython镜像:里面已经装好了 Pythonpytorch/pytorch镜像:里面已经装好了 PyTorch
4.2.2 容器
容器就是"镜像运行起来后的实例"。
- 镜像是模板
- 容器是模板跑起来之后的实际运行对象
在 Docker 里:nginx 是镜像
4.2.3 端口映射
容器内部有自己的网络环境。
比如 nginx 默认监听容器内部的 80 端口,但电脑浏览器访问不到容器内部的 80,除非把它映射出来。例如:
-p 8080:80
- 本机访问
8080 - 转发到容器内部的
80
也就是:宿主机端口 : 容器端口
4.3 运行第一个真正有用的容器
启动一个 nginx 容器,并通过浏览器访问它。
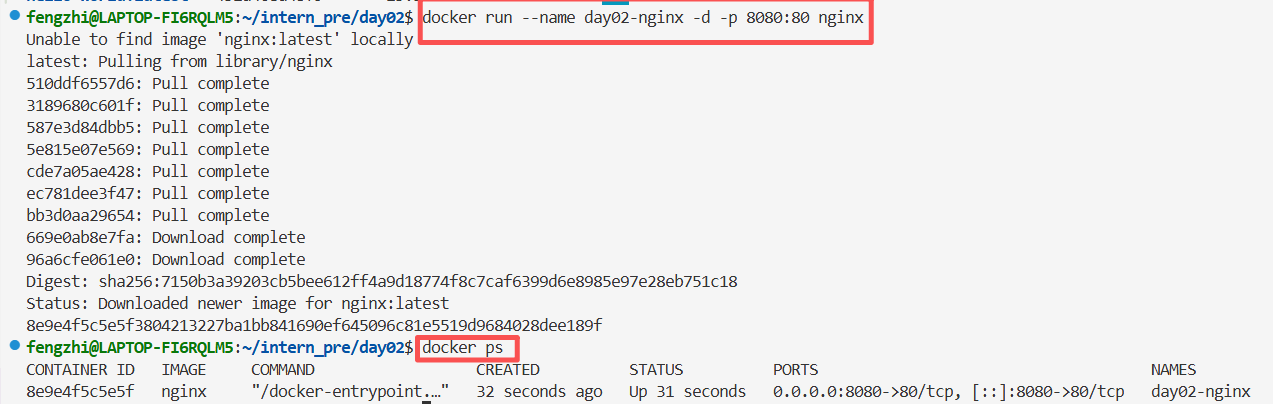
**
docker run:**创建并启动一个容器。这是 Docker 最核心的命令之一。**
--name day2-nginx:**给这个容器起名字,叫day2-nginx。
-d: 表示后台运行(detached mode)。如果不加-d,容器会占着当前终端。**
-p 8080:80:**端口映射。意思是:电脑访问8080,实际转发到容器里的80
nginx: 表示使用nginx这个镜像启动容器。如果本地没有这个镜像,Docker 会自动下载。
Docker Desktop 页面也可以同步看到这个容器的情况。
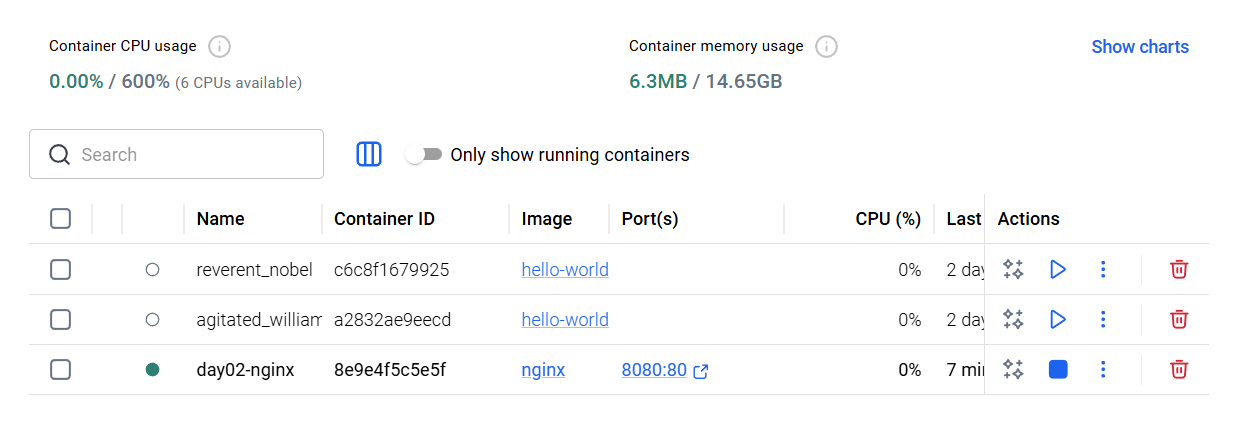
此时访问 http://localhost:8080 可以看到这个页面,说明容器已经顺利运行啦。
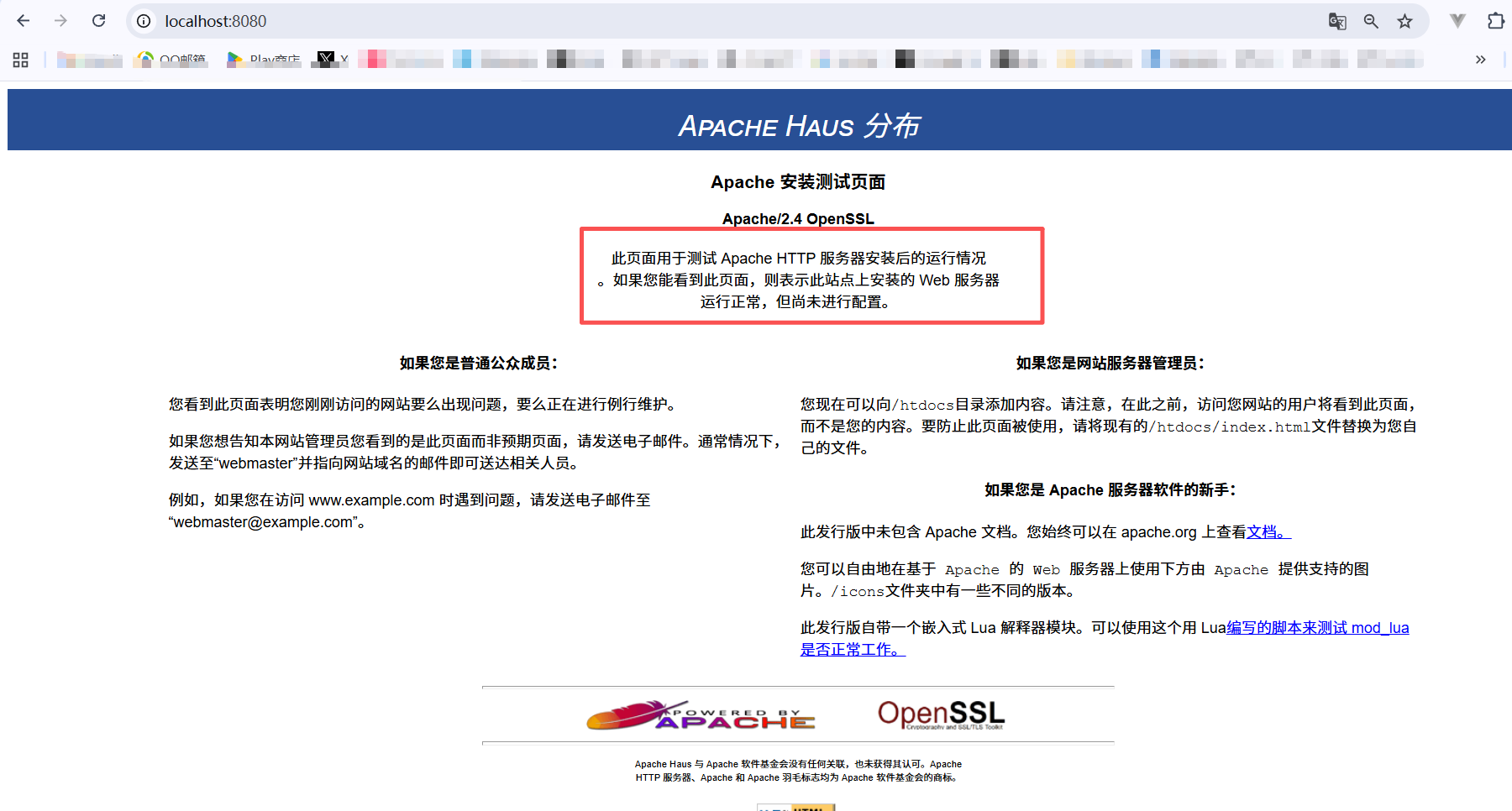
至此,已经第一次真正完成了:
- 使用镜像
- 创建容器
- 启动服务
- 从宿主机访问容器里的服务
这就是 Docker 最核心的入门闭环。
4.4 查看容器日志
查看容器输出日志。
感觉 docker 的很多命令都和 git 有相似之处,下面这个是查看容器日志的命令。
bash
docker logs day02-nginx
**
docker logs:**查看某个容器的日志输出。**
day2-nginx:**指定你要查看日志的容器名字。
4.5 进入容器内部
进入运行中的容器,在里面查看文件和目录。
这里终端输出有点多,我直接将命令打在这里。执行:
bash
docker exec -it day2-nginx /bin/sh进入后其实就是进入了 linux 环境,再执行:
bash
pwd
ls -la
ls -la /usr/share/nginx/html
cat /usr/share/nginx/html/index.html退出:
bash
exit
docker exec:在一个已经运行中的容器里执行命令。**
-it:**以交互方式进入容器终端。
-i:保持输入流
-t:一个终端界面**
day22-nginx:**要进入的容器名字。**
/bin/sh:**在容器里启动一个 shell。
4.6 停止和删除容器
容器生命周期管理:停止容器、删除容器。
停止容器运行。容器停止后,不代表容器被删除,只是"不运行了"。
bash
docker stop day02-nginx
删除容器,需要先停止后,才可以删除。
bash
docker rm day02-nginx图形化界面也可以看到这个容器被删除了。
 4.7 目录挂载
4.7 目录挂载
**最接近真实开发场景的一步:**把宿主机目录挂载到容器里,让容器直接使用本地的文件。
挂载是连接"本地开发"和"容器运行"的桥梁。
先准备一个本地目录:

bash
cd ~/intern_pre/day02
mkdir -p docker_demo
echo '<h1>Hello from Docker bind mount</h1>' > docker_demo/index.html然后启动容器:
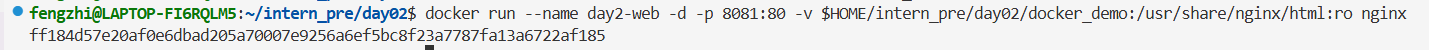
bash
docker run --name day2-web -d -p 8081:80 -v $HOME/intern_pre/day02/docker_demo:/usr/share/nginx/html:ro nginx此时在浏览器访问 http://localhost:8081,可以正常访问:
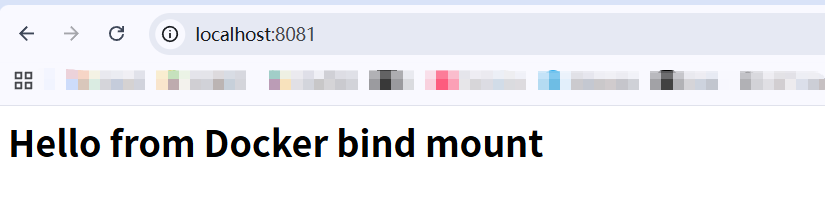
尝试修改这个文件,重新写入会发现页面也发生了变化。
bash
echo '<h1>Updated from host machine</h1>' > docker_demo/index.html
curl http://localhost:8081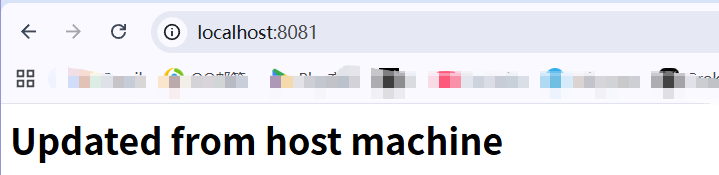
测试完毕,可以将这个容器删掉了。
bash
docker stop day2-web
docker rm day2-web
这一步和运行容器很相似,区别就在于:
-v 宿主机目录:容器目录:ro这是挂载语法。
意思是:把宿主机目录映射到容器里的某个目录。
例如:
bash
-v $HOME/intern_pre/day02/docker_demo:/usr/share/nginx/html:ro表示:
- 宿主机目录:
docker_demo - 容器目录:
/usr/share/nginx/html ro:只读挂载
5. PyTorch 入门
今天已经练习挺多得了,PyTorch 的时间不是很多了,大概看几个视频就收尾得了。
这部分直接无脑小土堆了,大家都推荐的肯定没错:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
完整学习笔记直接参考这个博主:【Pytorch入门】小土堆PyTorch入门教程完整学习笔记(详细笔记并附练习代码 ipynb文件)-CSDN博客
5.1 Pytorch 的配置与安装
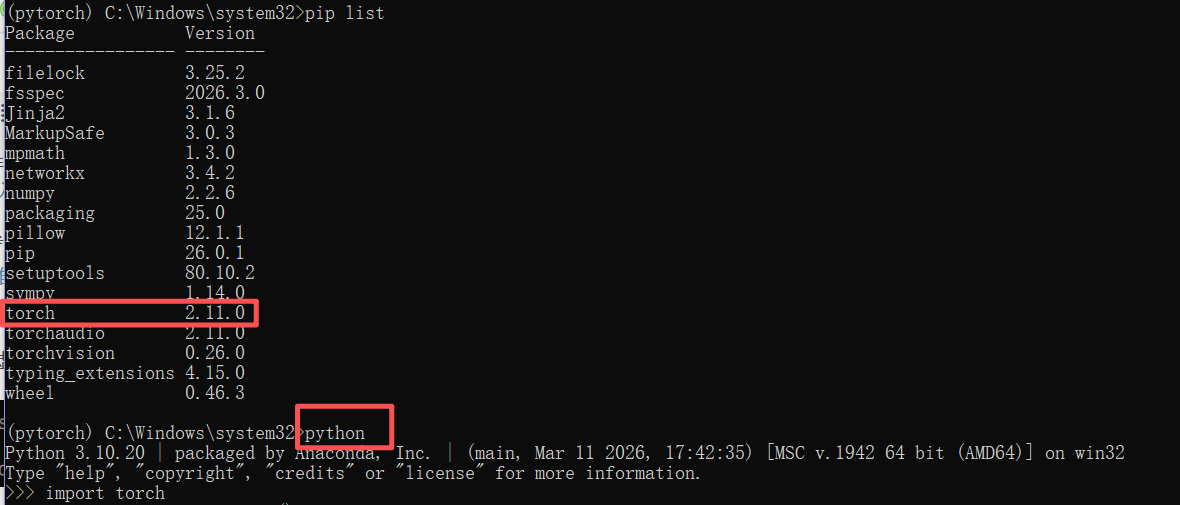
打开Anacanda并激活虚拟环境,下载pytorch:

然后测试一下是否可以正常使用:(我的电脑没有GPU所以安装的是CPU版本的)
5.2 Python 编辑器
准备好 Pycharm 和 Jupyter 即可。
在 Pycharm 中新建项目:
然后配置好解释器,测试一下当前环境是否可以正常使用 torch。
接下来准备 Jupyter 环境,很久没用了,先尝试打开:
但是这个环境和 pytorch 不互通,优先解决方案是在 pytorch 环境中再安装一遍 Jupyter,所以需要回到 pytorch 虚拟环境中下载对应的包:
bash
#安装命令如下
pip install ipykernel然后打开 jupyter 页面(我的没有显卡,返回 False 是正常的):
bash
jupyter notebook
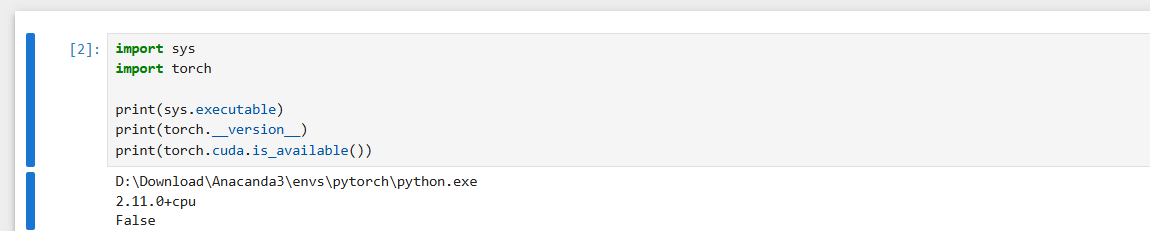
配置好之后,以后每次用的时候,只需要在 Anacanda 里面打开然后运行以下命令就可以了:
bash
conda activate pytorch
jupyter notebook今日份学习over ,撒花!