1.一维前缀和
【模板】前缀和_牛客题霸_牛客网 (nowcoder.com)![]() https://www.nowcoder.com/practice/acead2f4c28c401889915da98ecdc6bf?tpId=230&tqId=2021480&ru=/exam/oj&qru=/ta/dynamic-programming/question-ranking&sourceUrl=%2Fexam%2Foj%3Fpage%3D1%26tab%3D%25E7%25AE%2597%25E6%25B3%2595%25E7%25AF%2587%26topicId%3D196题中说给了一个长度为n的数组a1,a2......an,这里数组下标从1开始计数。有q次查询,每次查有l和r两个参数,输出al到ar的和。下面来解决,比如:
https://www.nowcoder.com/practice/acead2f4c28c401889915da98ecdc6bf?tpId=230&tqId=2021480&ru=/exam/oj&qru=/ta/dynamic-programming/question-ranking&sourceUrl=%2Fexam%2Foj%3Fpage%3D1%26tab%3D%25E7%25AE%2597%25E6%25B3%2595%25E7%25AF%2587%26topicId%3D196题中说给了一个长度为n的数组a1,a2......an,这里数组下标从1开始计数。有q次查询,每次查有l和r两个参数,输出al到ar的和。下面来解决,比如:

先想一个暴力解法:模拟就行,让求哪一段区间和,从头到尾加一下就可以了O(n*q)。接下来想一个更优的解法:前缀和,该算法用来解决快速求出数组中某一个连续区间的和。前缀和算法一般分为两步进行:1.先处理出来一个前缀和数组。2.使用前缀和数组。下面细看:首先创建一个数组,这个数组和原始arr数组是同等规模的:

dpi表示1,i区间内所有元素的和,如dp3表示arr1+arr2+arr3的和放在dp3的位置:

这样就把dp数组初始化完成了,dpi=dpi-1+arri。下面来使用:就是处理每次询问,比如:
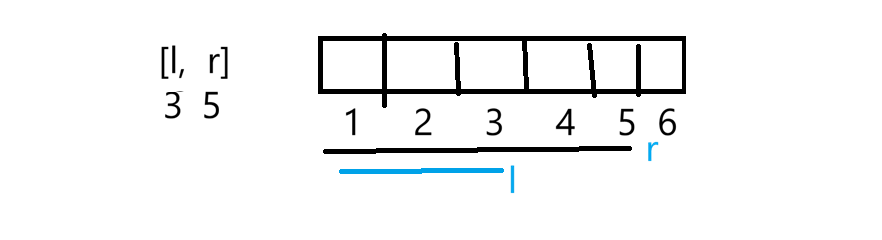
可以算1~5区间的和,然后减1~2区间的和就剩下3~5区间的和了。1~5区间的和其实是dpr,1~2区间的和其实是dpi-1,这样dp中的数据减就可以了:
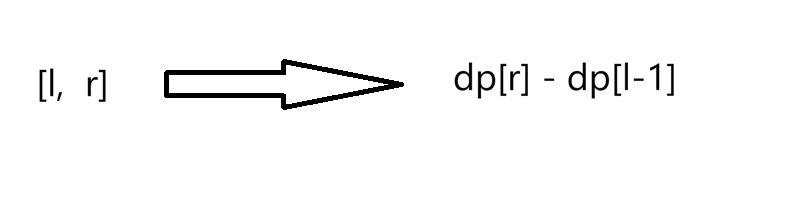
这样时间复杂度是O(q) + O(n)。这有个疑问,为什么我们的下标要从1开始计数?为了处理边界情况。比如询问0,2,得出dp2-dp-1,不能到-1位置,要特殊处理。若下标从1开始,最左边最低是1,1,2是dp2 - dp0,0位置填写0即可,没有越界。下面来实现:
2.二维前缀和
【模板】二维前缀和_牛客题霸_牛客网 (nowcoder.com)![]() https://www.nowcoder.com/practice/99eb8040d116414ea3296467ce81cbbc?tpId=230&tqId=2023819&ru=/exam/oj&qru=/ta/dynamic-programming/question-ranking&sourceUrl=%2Fexam%2Foj%3Fpage%3D1%26tab%3D%25E7%25AE%2597%25E6%25B3%2595%25E7%25AF%2587%26topicId%3D196 先想一个暴力解法,就是模拟,让求哪个区间就把哪个区间的和都求出来。如:
https://www.nowcoder.com/practice/99eb8040d116414ea3296467ce81cbbc?tpId=230&tqId=2023819&ru=/exam/oj&qru=/ta/dynamic-programming/question-ranking&sourceUrl=%2Fexam%2Foj%3Fpage%3D1%26tab%3D%25E7%25AE%2597%25E6%25B3%2595%25E7%25AF%2587%26topicId%3D196 先想一个暴力解法,就是模拟,让求哪个区间就把哪个区间的和都求出来。如:
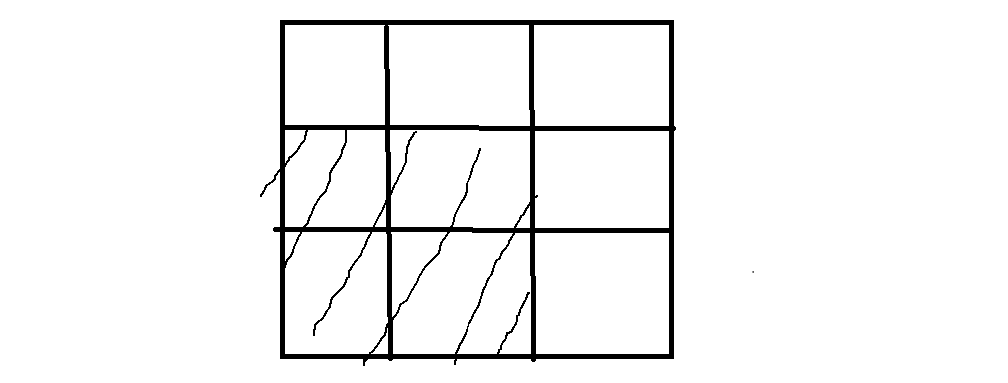
问阴影区间就都依次详相加就可以,这样时间复杂度是O(n*m*q)。接下来想一个更优的解法,前缀和:1.预处理出来一个前缀和矩阵。2.使用前缀和矩阵。如:
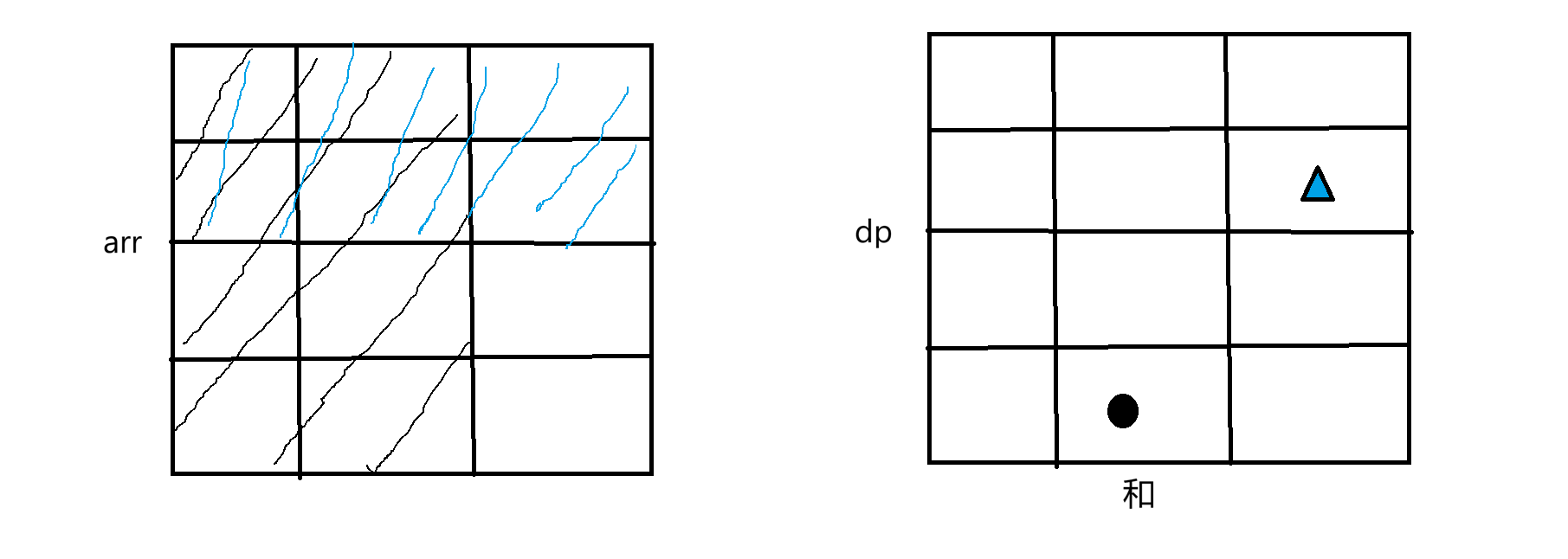
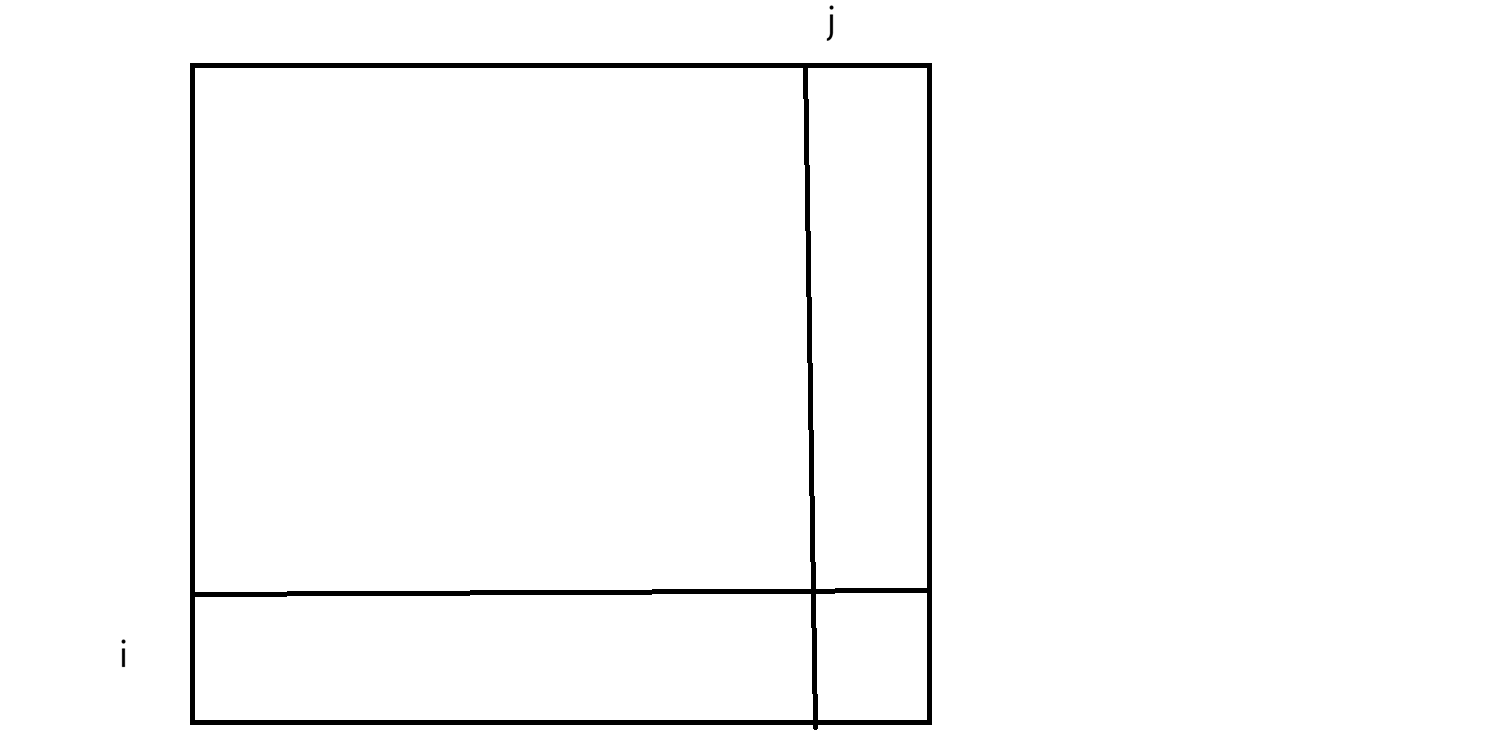
重新创一个矩阵dp和原始arr数组规模一样大,dpij表示从1,1位置到i,j位置这段区间内所有元素的和。那如何快速求出dpij值是多少?若从前遍历原数组求和时间复杂度会很高,所以找个规律来快速求dpij的值。把图抽象出来:
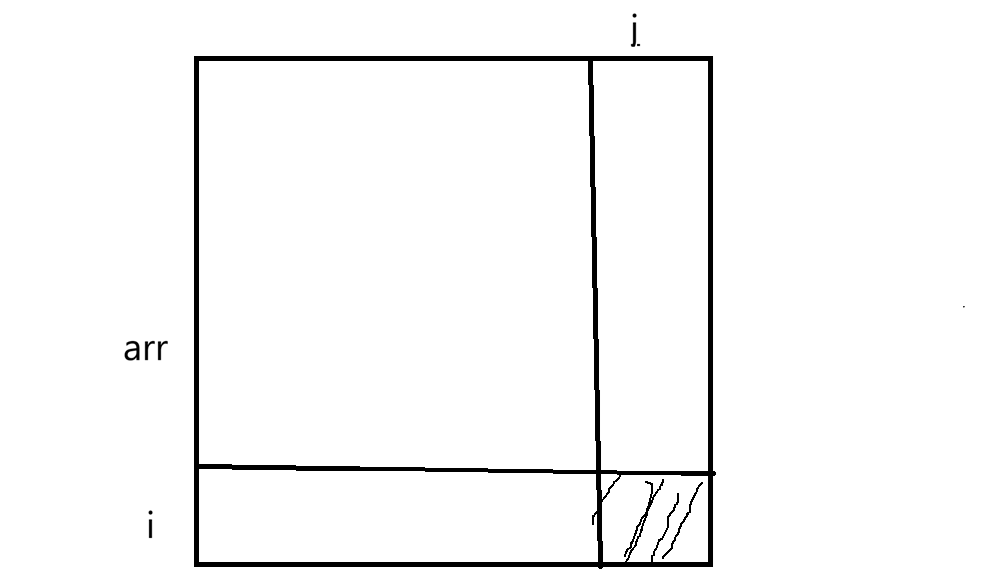
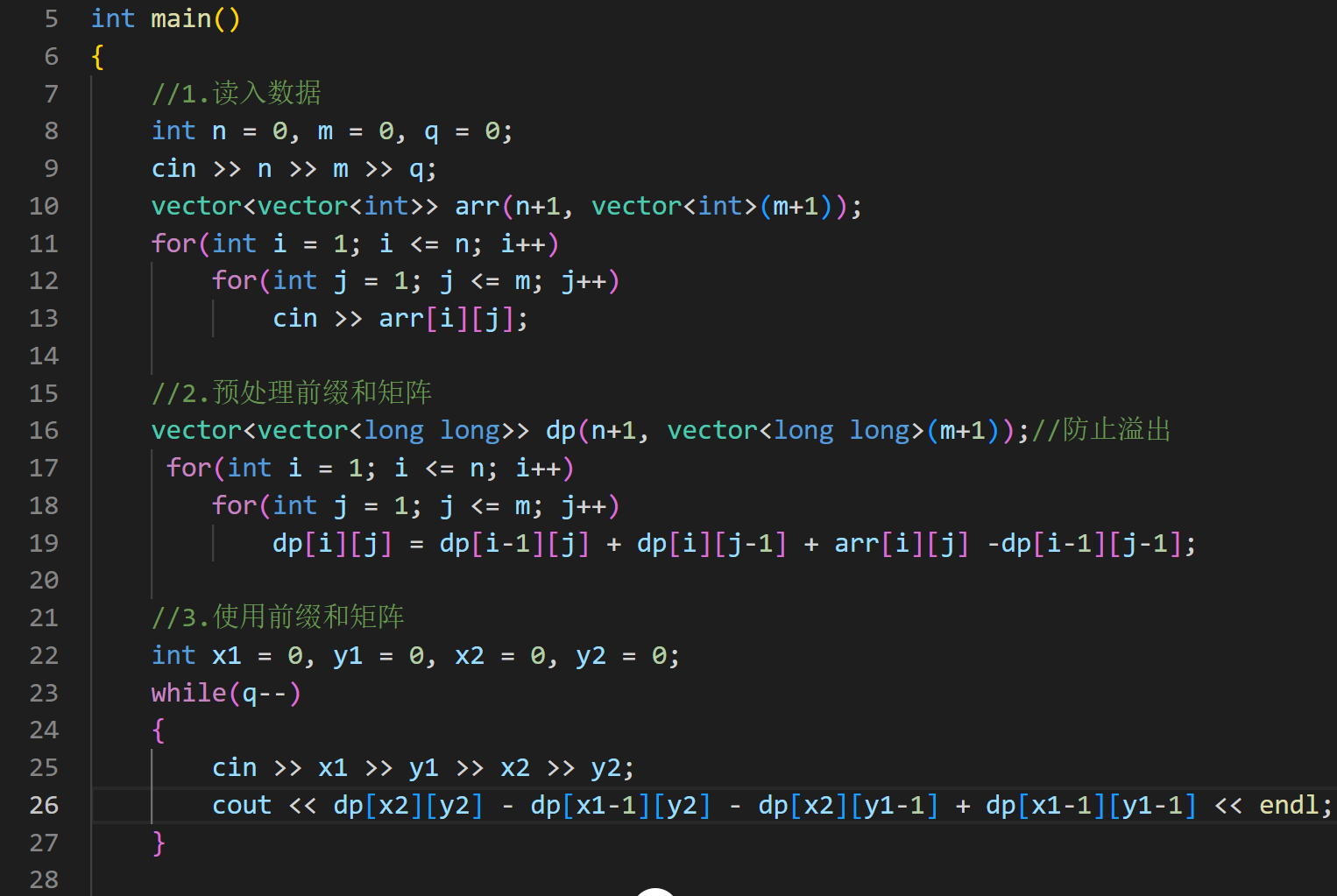
要求dpij,相当于求一个区域的和,可以分为这样一些部分:
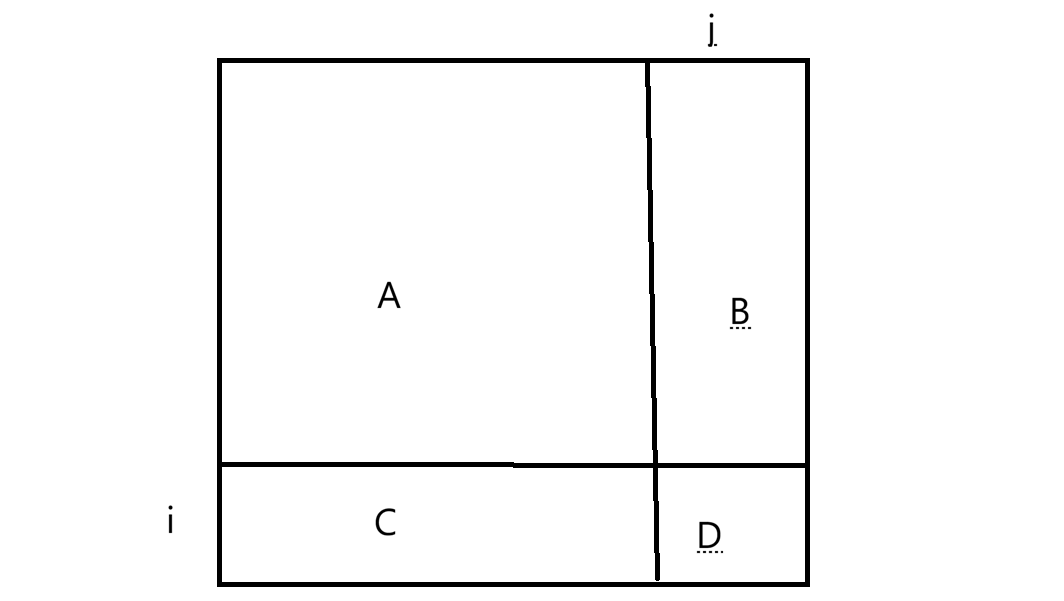
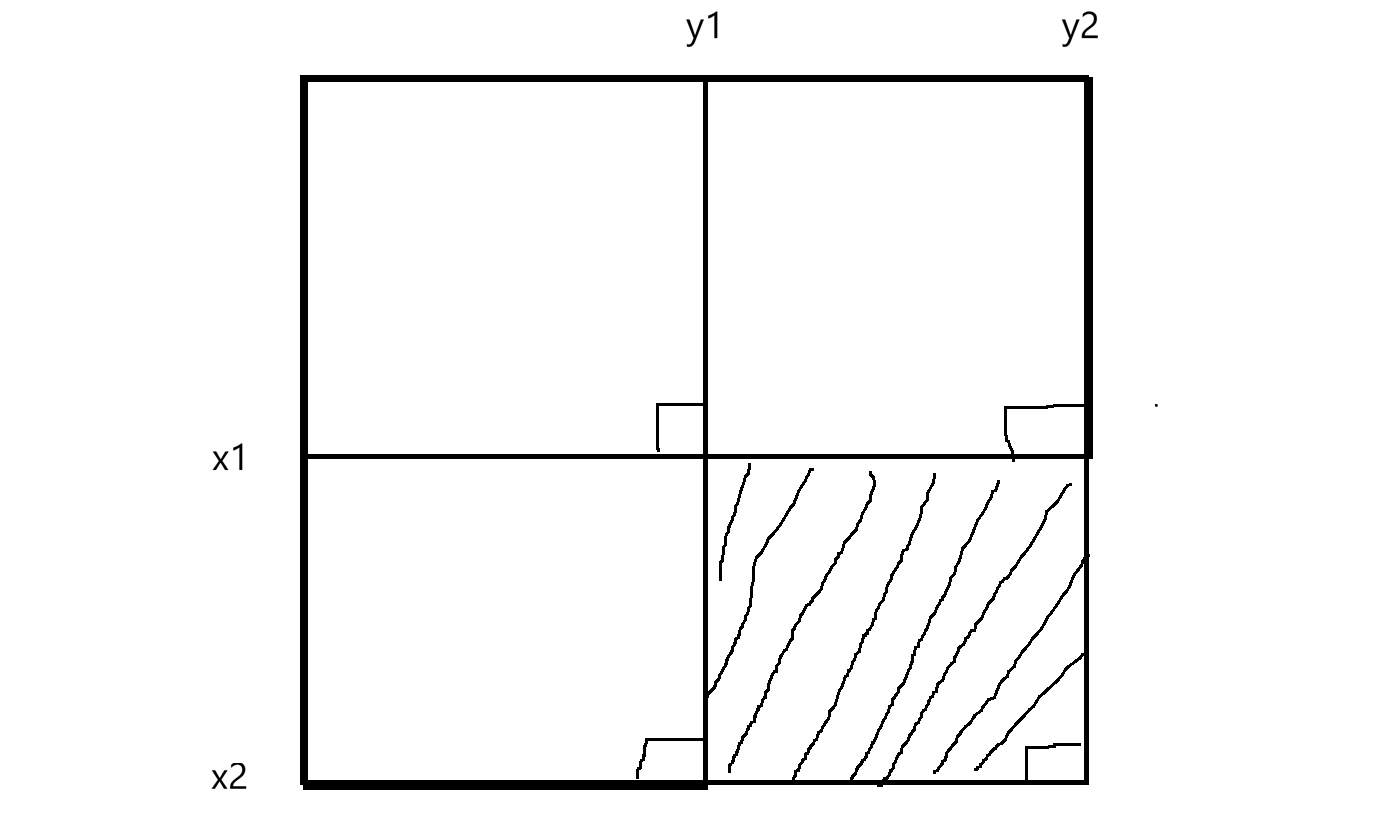
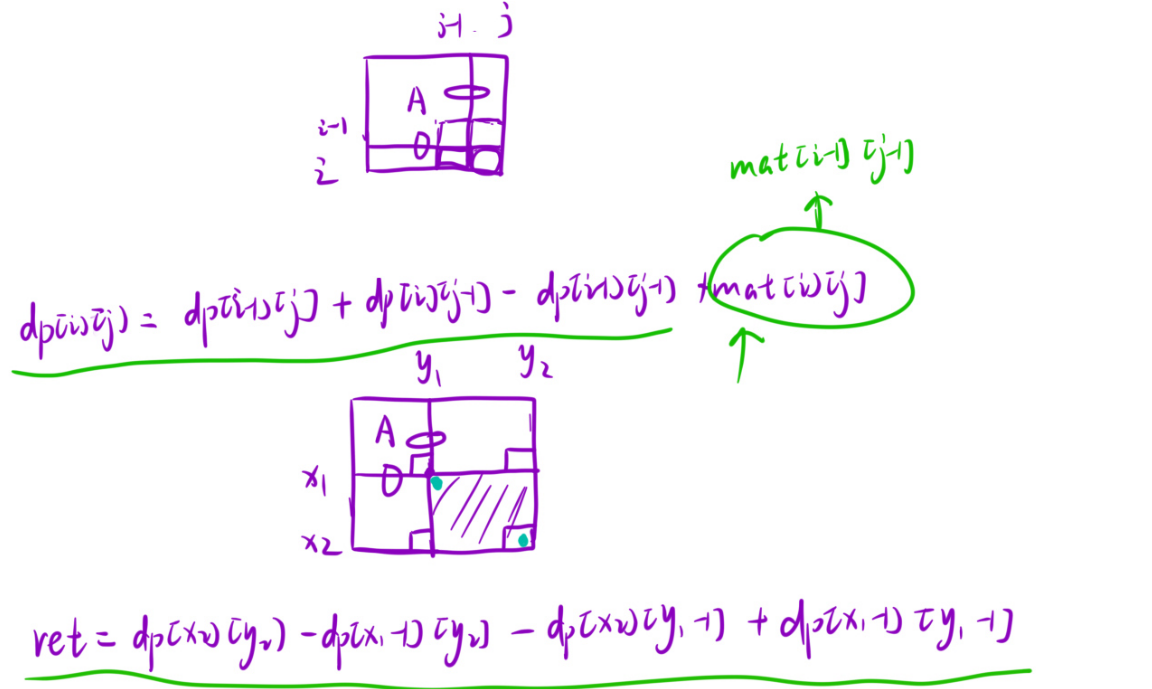
最终dpij=A+B+C+D,A区域的和相当于从1,1到i-1,j-1所有元素和,A区域相当于是dp\[\]i-1j-i 但B和C不好表示,因此改为dpij = A+B+A+C+D-A,此时A+B相当于从1,1到i-1,j所有元素的和,即dpi-1j;A+C相当于从1,1到i,j-1,即dpij-1;D相当于arrij。因此得出dpij = dpi-1j + dpij-1 + arrij - dpi-1j-1,这样在O(1)得出dpij。那如何使用?如求x1,y1~x2,y2,继续抽象一下:
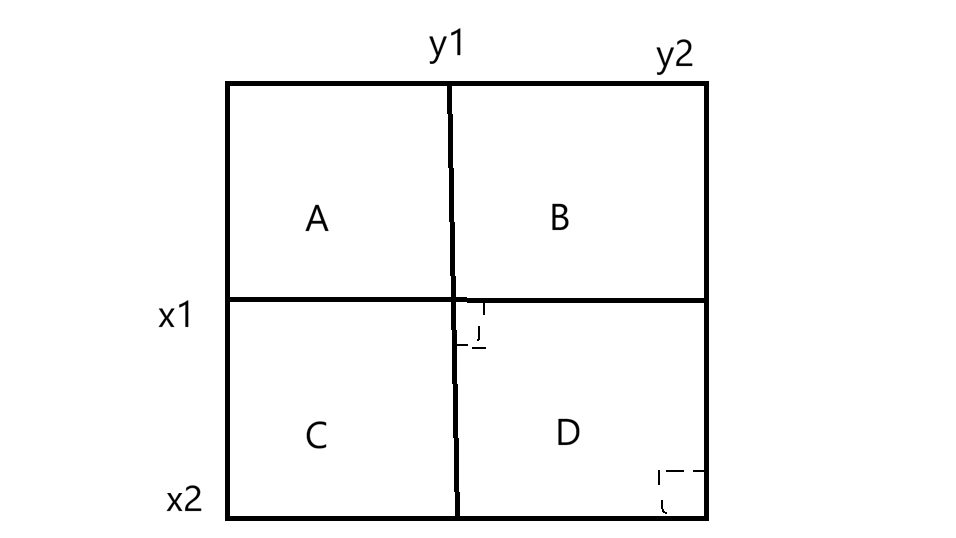
相当于A+B+C+D-(A+B)-(A+C)+A=D=dpx2y2-dpx1-1y2-dpx2y1-1+dpx1-1y1-1,时间复杂度是O(m*n)+O(q),下面来实现:
3.寻找数组的中心下标
724. 寻找数组的中心下标 - 力扣(LeetCode)![]() https://leetcode.cn/problems/find-pivot-index/description/ 以该下标为分界线,左边所有元素和是等于右边所有元素和的为中心下标:
https://leetcode.cn/problems/find-pivot-index/description/ 以该下标为分界线,左边所有元素和是等于右边所有元素和的为中心下标:
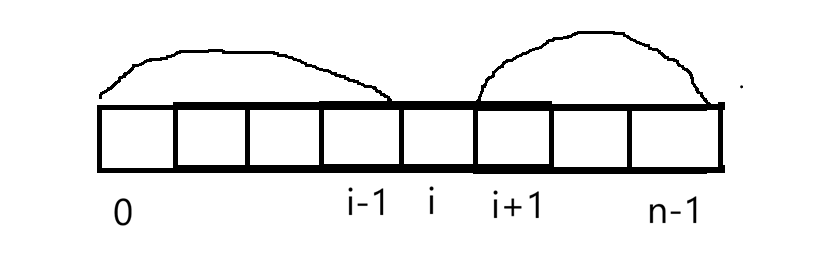
若选择一个i点想判断它是否为中心下标,先算0~i-1区间的和,再算i+1~n-1区间的和,对比一下和看是否相等。若是暴力解法,每次枚举一个中心下标就左边加一通,右边加一通,这样时间复杂度是O(n^2)。可以通过前缀和思想优化暴力解法,首先预处理,该题需要前面元素的和,又需要后面元素的和,所以需要两个数组:f表示前缀和数组,g表示后缀和数组;fi表示区间0~i-1的所有元素和,gi表示i+1~n-1区间所有元素的和。下面有了数组想想怎么推数组的值:fi=fi-1+numsi-1,gi=gi+1+numsi+1。再来使用数组:枚举所有中心下标i,判断fi和gi是否相等,若相等返回。还有些细节问题:1.填f0是会有f-1+nums-1越界,因此提前写好f0=0;同理gn-1=gn+numsn,因此提前写gn-1=0。2.填f时从左向右填,填g时从右向左填。下面来实现(vector开始默认是0):

4.除自身以外数组的乘积
想求某一个位置,就把除该位置外的数都乘起来再放到该位置,这样时间复杂度是O(n^2)。下面想个优化方法:
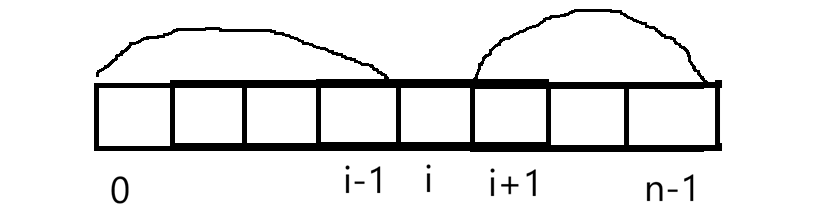
单看某个位置,想求i位置最终结果,先算0~i-1区间的积,再算i+1~n-1区间所有元素的积。所以可以用前缀和思想先预处理一下,再用后缀和思想处理一下,当求i位置时直接从前缀和后缀和拿值就可以了。定义f表示前缀积,g表示后缀积:求fi时不要i位置元素,仅需i-1位置及之前元素积,因此fi表示0~i-1区间内所有元素的乘积,fi=fi-1*numsi-1。gi表示i+1~n区间内所有元素的积,gi=gi+1*numsi+1。有了数组后下面来使用,最后要数组,就创建一个数组ret,然后依次填数组reti=fi*gi。最后处理一下细节问题:f(0)=1,g(n-1)=1。下面来实现:
5.和为k的子数组
560. 和为 K 的子数组 - 力扣(LeetCode)![]() https://leetcode.cn/problems/subarray-sum-equals-k/description/ 先想一个暴力解法:
https://leetcode.cn/problems/subarray-sum-equals-k/description/ 先想一个暴力解法:
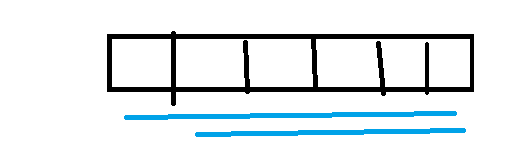
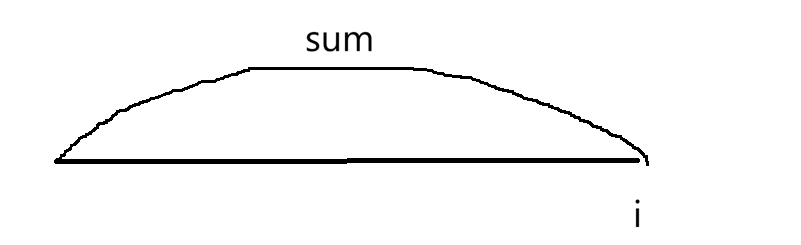
固定一个起始位置,直到找到一个位置不能停止(数据既有正又有负,找到一个不能停,可能正负抵消),继续向后找,直到最后位置;下一个位置也是一样的,这里时间复杂度是O(N^2)。下面来优化,引入一个概念,以i位置结尾的所有的子数组,如:
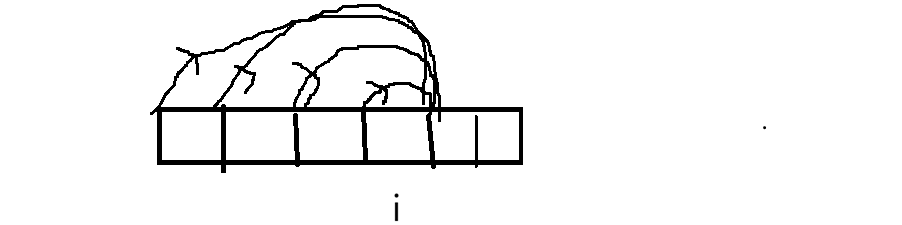
这样也能把所有子数组枚举出来。那以i为结尾的子数组中和为k的如何找:
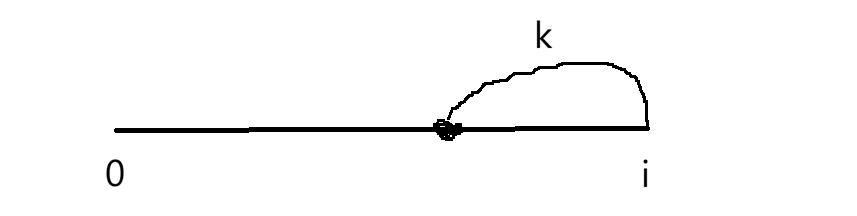
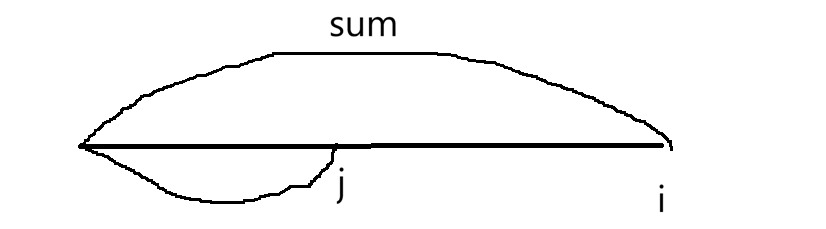
相当于找一个位置,从该位置到i和为k就行。直接找就是从i开始向前(左)加,直到为k,这样和暴力没有区别。现在这样看:
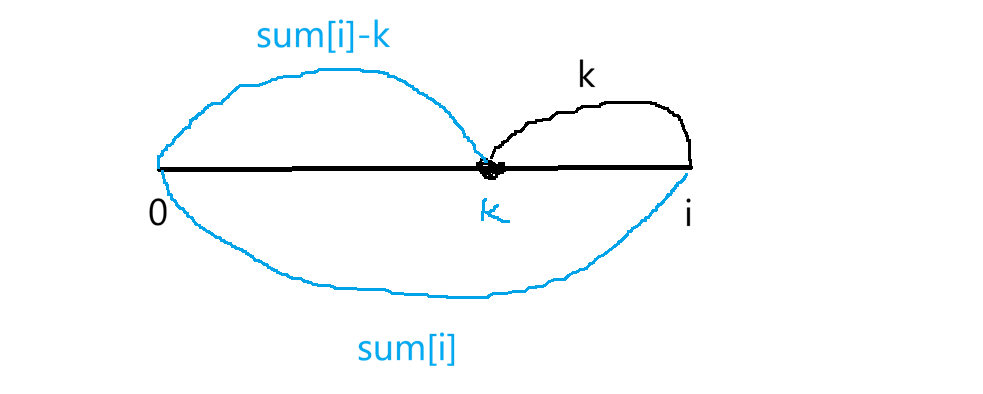
当枚举到i位置时,已经知道以i位置为结尾的前缀和是sumi,要找个区间让它和k,仅需找前一段和为sumi-k就行。当枚举到以i位置为结尾时,问题转换为在0,i-1区间内,有多少个前缀和等于sumi-k。若单纯把前缀和数组弄出来:
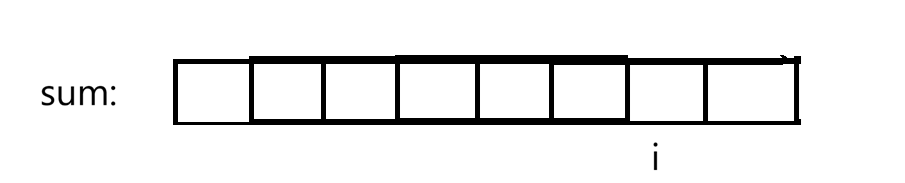
找i位置之前有多少个前缀和为sumi-k,从头到i-1遍历有多少个sumi-k,这样还不如暴力解法,还多弄了个前缀和数组。要想如何快速找到前缀和有多少个sumi-k,所以借助哈希快速查找,<int, int>,哈希表中存两个int,第一个int是前缀和,第二个int是前缀和出现的次数,这样仅需找前缀和出现了多少次。还有些细节:1.前缀和加入哈希的时机?所有前缀和都是算出来的,再都丢到哈希里?不行,因为可能i之后也有前缀和为sumi-k,会重复统计。因此再计算i位置之前,哈希表中只保存0,i-1位置前缀和。2.不用真的创建一个前缀和数组,用一个sum来标记前一个位置前缀和即可。3.如果整个前缀和为k呢:
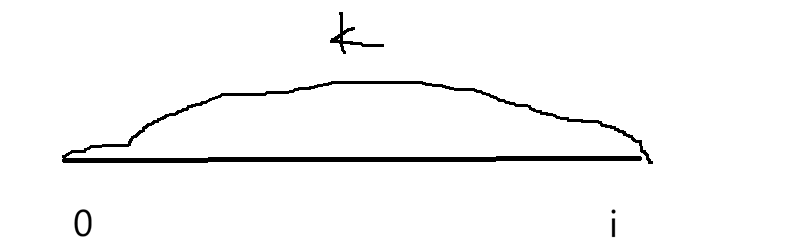
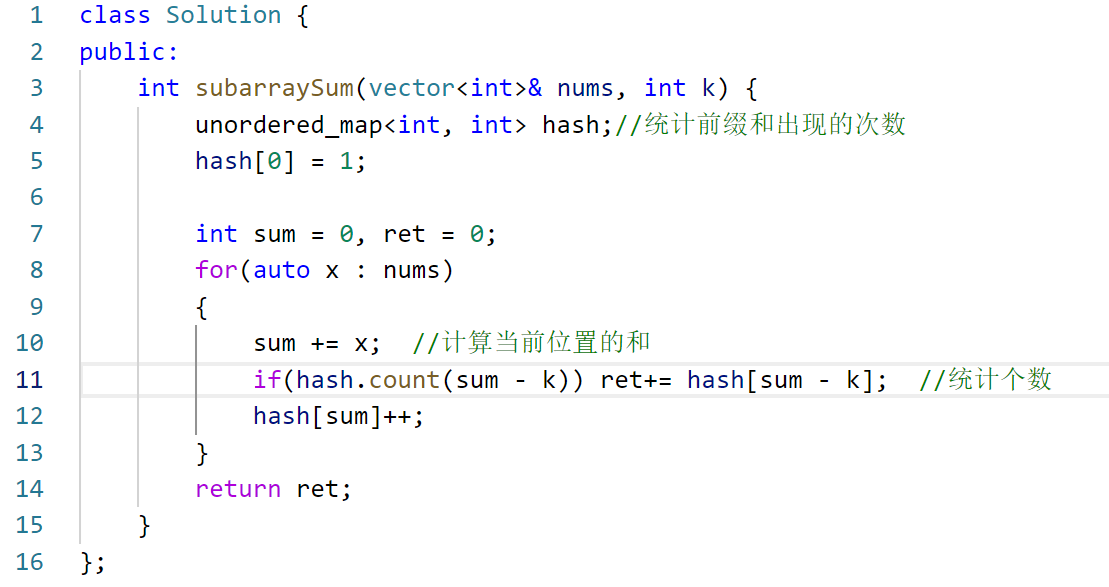
要找一个前缀和数组为0,直接hash0=1,默认有一个。下面来实现:
6.和可被k整除的子数组
974. 和可被 K 整除的子数组 - 力扣(LeetCode)![]() https://leetcode.cn/problems/subarray-sums-divisible-by-k/description/ 解法一是暴力枚举,暴力枚举出所有子数组,把和加起来看被k整除的有几个就行了。再看优化解法时先来补充一个知识:1.同余定理:(a -b)/ p = k......0,就是a-b的结果能够被p整除,说明a%p = b%p,它们余数是一样的。2.c++或java中%正数的结果以及修正:负%正=负,若想修正为正数,可通过(a%p + p) % p修改为正数。这道题和上一题很像,依旧是前缀和+哈希表:
https://leetcode.cn/problems/subarray-sums-divisible-by-k/description/ 解法一是暴力枚举,暴力枚举出所有子数组,把和加起来看被k整除的有几个就行了。再看优化解法时先来补充一个知识:1.同余定理:(a -b)/ p = k......0,就是a-b的结果能够被p整除,说明a%p = b%p,它们余数是一样的。2.c++或java中%正数的结果以及修正:负%正=负,若想修正为正数,可通过(a%p + p) % p修改为正数。这道题和上一题很像,依旧是前缀和+哈希表:
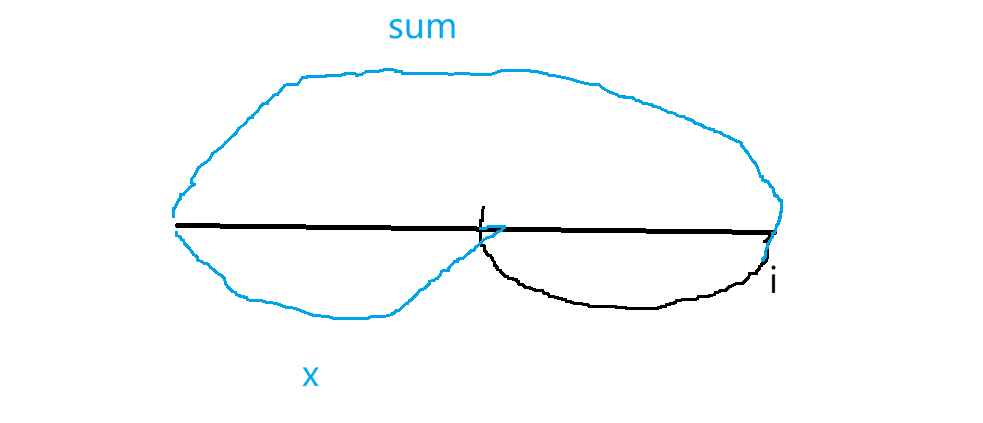
依旧考虑i前面的子数组,该题找这个区间(黑线)能否被k整除,此时可找两个前缀和sum和x,若找的黑区间能被k整除,应该是(sum-x) / k = 0,然后推出sum%k=x%k,所以问题变成了在0~i-1区间找一找前缀和中有多少个条数等于sum%k。但是前缀和有可能是负数,所以改为余数等于(sum%k+k)%k。最后注意细节:1.没必要真创建一个前缀和数组,仅需把前缀和条数存哈希表中。定义哈希表<int,int>,第一个int表示前缀和条数,第二个是次数,剩下的细节和前一道题一样。下面来实现:
7.连续数组
525. 连续数组 - 力扣(LeetCode)![]() https://leetcode.cn/problems/contiguous-array/description/ 如1,0,1,1,0,0,0,1,这道题本质是让我们找一个连续的区域,使这段区间中的0和1数目相等,并且要找一个最长的连续区域。如果把0都变成-1:1,-1,1,1,-1,-1,-1,1,相当于在数组中找一段连续区域,使这段区域的和为0,相当于找最长和为0的子数组。那么用前缀和+哈希表来解决,和之前一样。下面来看细节问题:1.哈希表中存什么?hash<int,int>存的是前缀和与下标(统计长度)。2.什么时候存入哈希表?谁置于与对应前缀和绑定存入哈希表中:
https://leetcode.cn/problems/contiguous-array/description/ 如1,0,1,1,0,0,0,1,这道题本质是让我们找一个连续的区域,使这段区间中的0和1数目相等,并且要找一个最长的连续区域。如果把0都变成-1:1,-1,1,1,-1,-1,-1,1,相当于在数组中找一段连续区域,使这段区域的和为0,相当于找最长和为0的子数组。那么用前缀和+哈希表来解决,和之前一样。下面来看细节问题:1.哈希表中存什么?hash<int,int>存的是前缀和与下标(统计长度)。2.什么时候存入哈希表?谁置于与对应前缀和绑定存入哈希表中:
3.如果有重复的<sum, i>如何存:
更新到i位置发现前面有个位置前缀和也为sum,只保留前面那一对<sum, j>。4.默认的前缀和为0情况如何存?hash0=-1。5.长度怎么算:
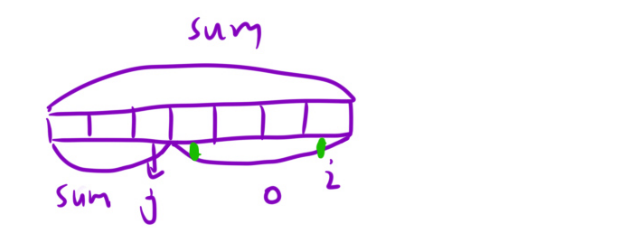
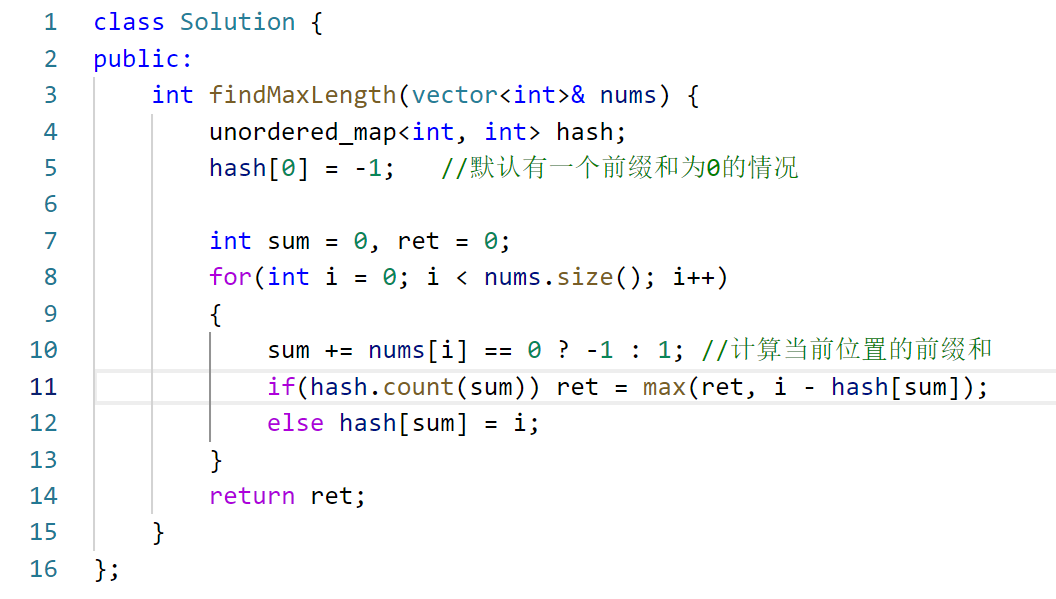
i-(j+1)+1等于i-j。下面来实现:
8.矩阵区域和
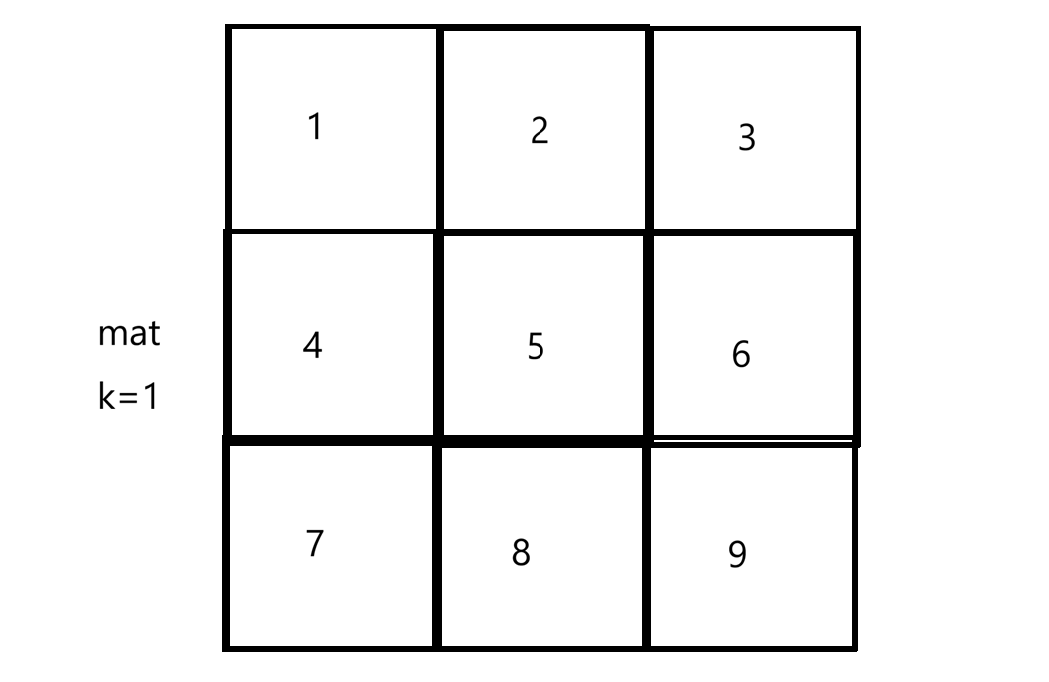
1314. 矩阵区域和 - 力扣(LeetCode)![]() https://leetcode.cn/problems/matrix-block-sum/description/题目给我们一个原始的矩阵mat和一个整数k,如:
https://leetcode.cn/problems/matrix-block-sum/description/题目给我们一个原始的矩阵mat和一个整数k,如:
最终让我们返回一个同等规模的矩阵answer,answer任意一个位置的值是向上扩展k个单位,此时围成的长方形周围所有元素的和。比如求answer0,0:
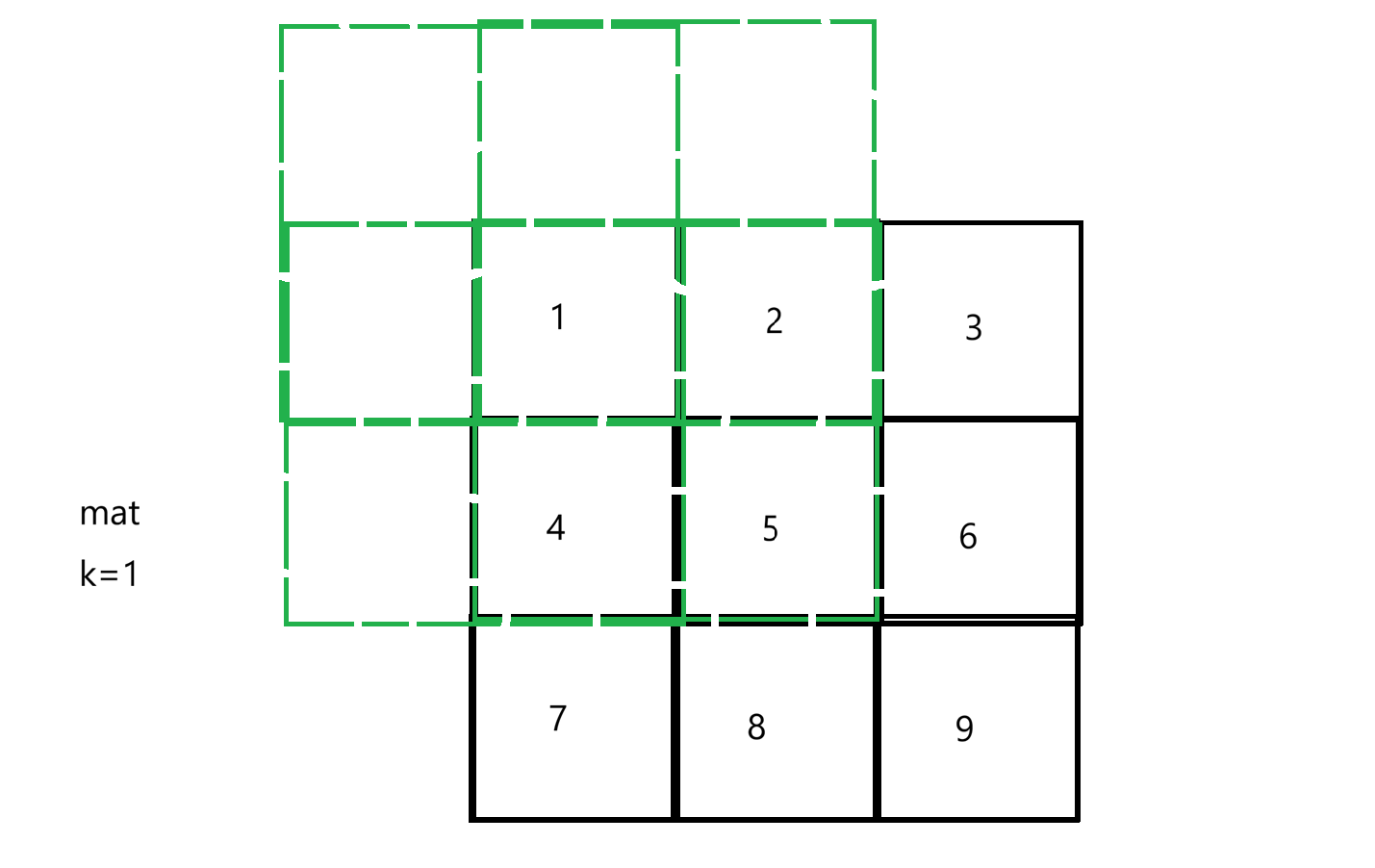
超出界的不考虑,这样answer0,0是12。下面来解决,这道题本质是快速求出矩阵某一区域的和,解法是一个二维前缀和:1.
dpij = dpi-1j + dpij-1 - dpi-1j-1 + matij。2.使用:
ret = dpx2y2 - dpx1-1y2 - dpx2y1-1 + dpx1-1y1-1。回归题目:
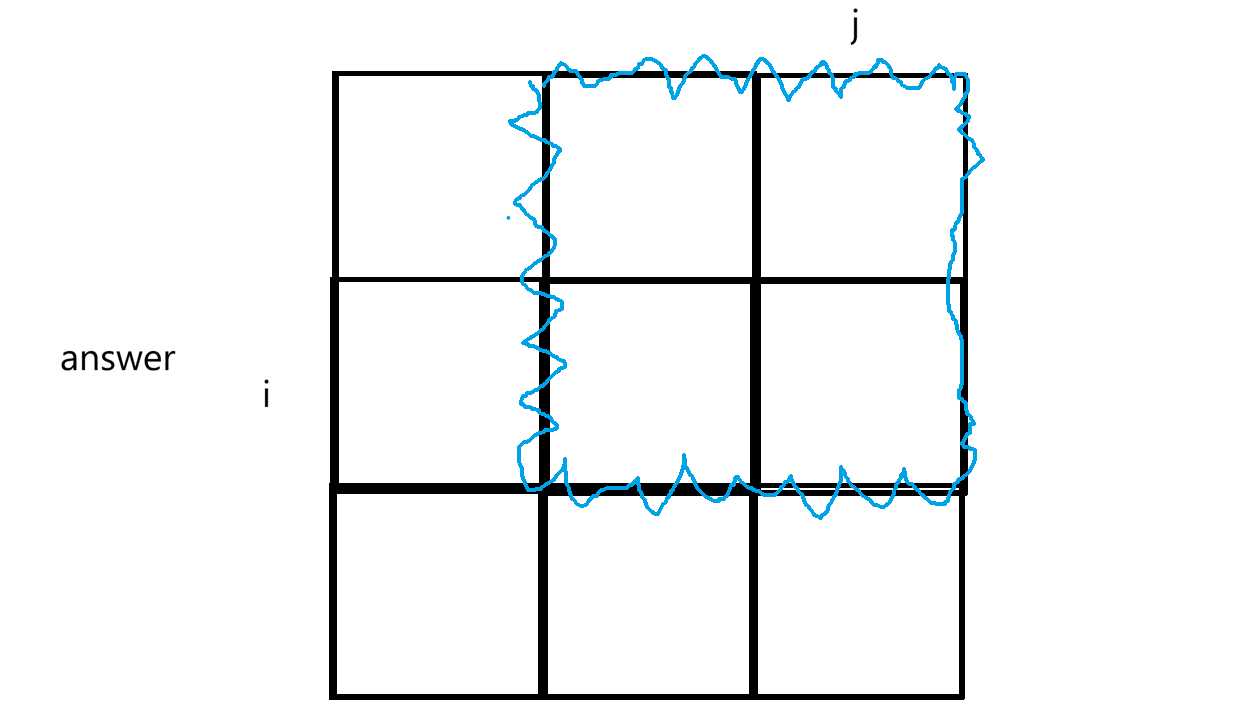
想求answerij,必须知道在原始矩阵中表示的区域是什么,需要知道右下角和左上角的坐标,如:
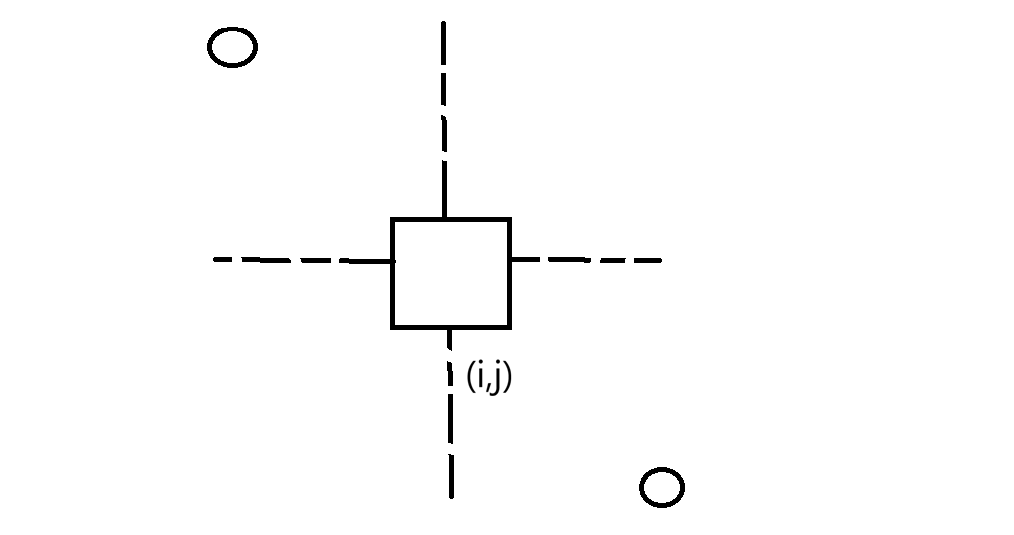
求区域时要扩k个单位,这样就很好找,左上角(i-k,j-k),右下角是(i+k,j+k)。但有些左边可能越界,所以可这样处理:

还有个问题是下标映射关系:为了处理公式中边界情况,dp矩阵下标是从1开始计数的,但题目给的矩阵是从0开始计数的:
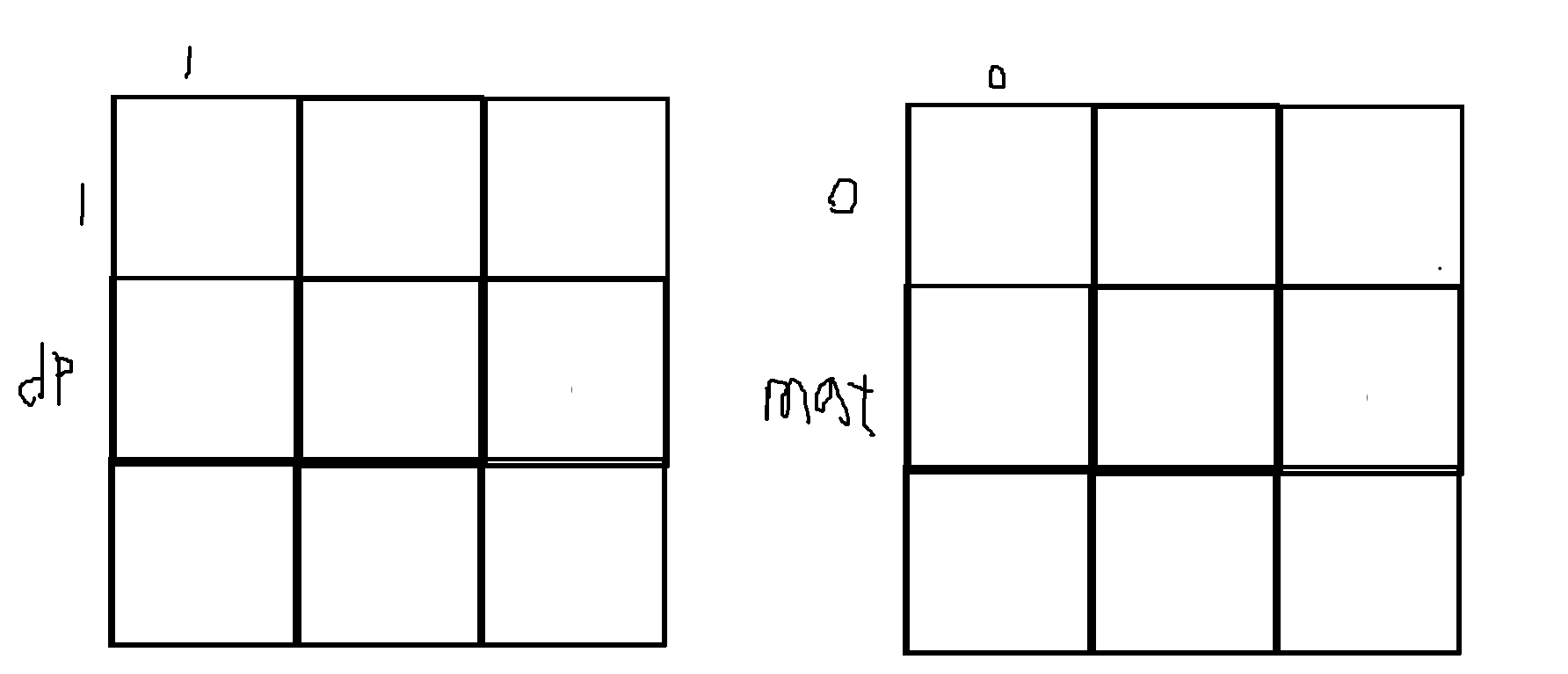
所以填dp11时找的是原始矩阵中的mat00。所以让dp多加一行和一列:
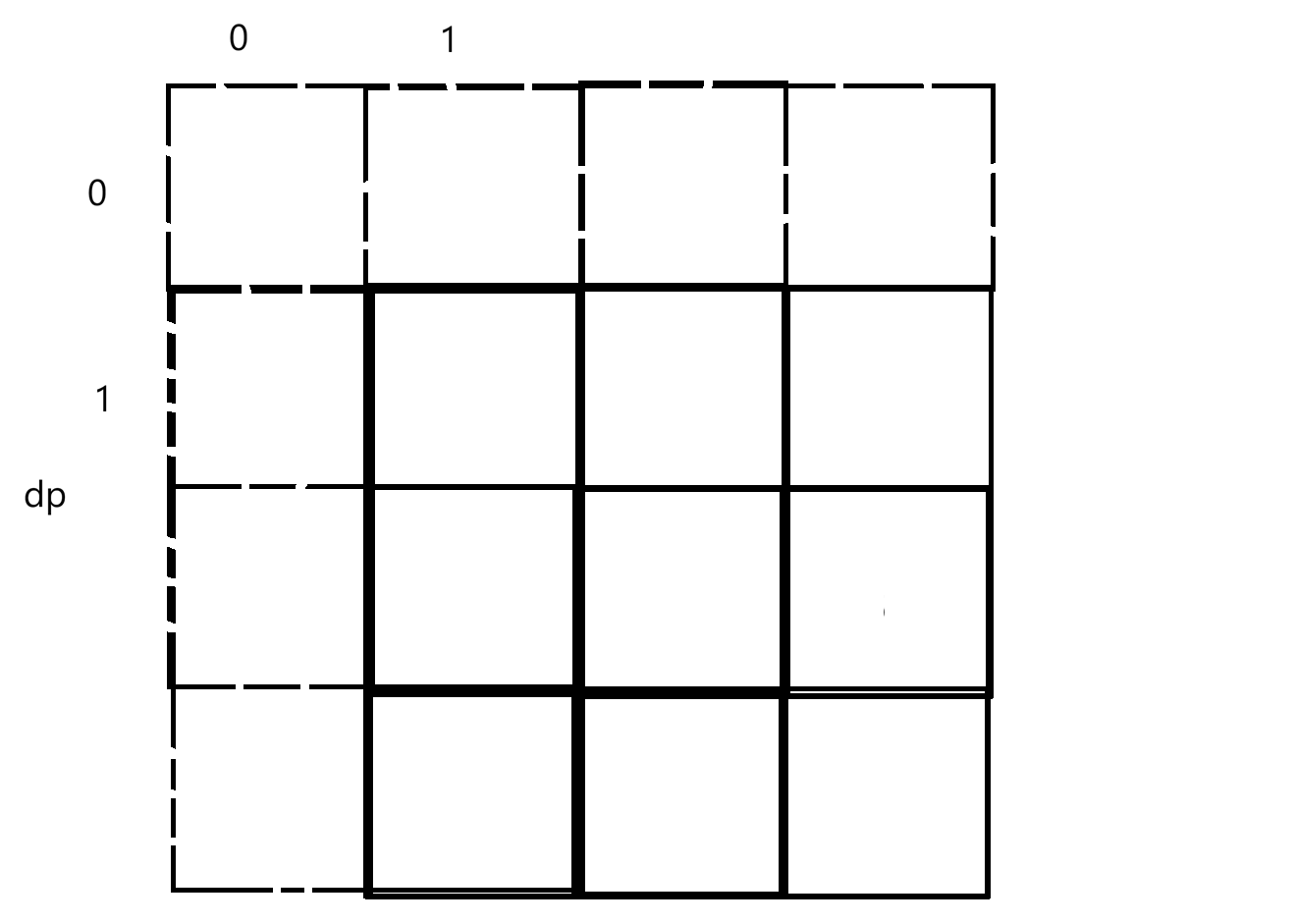
此时要修改一下公式:当填dp11时,本质mat00找结果,也就是dpxy时去matx-1y-1找值:
当使用时ans也是从0计数:
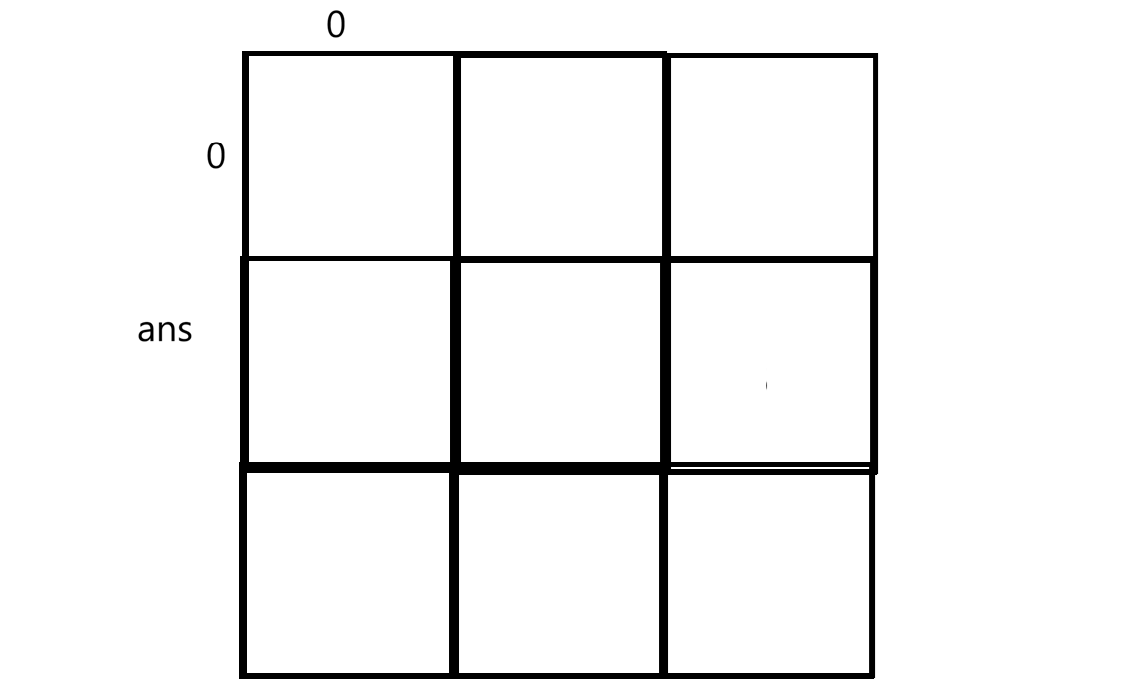
ans00(x,y)对应dp11(x+1,y+1),可给ret统一加1或者通过ansij得到原始矩阵下标,然后+1:
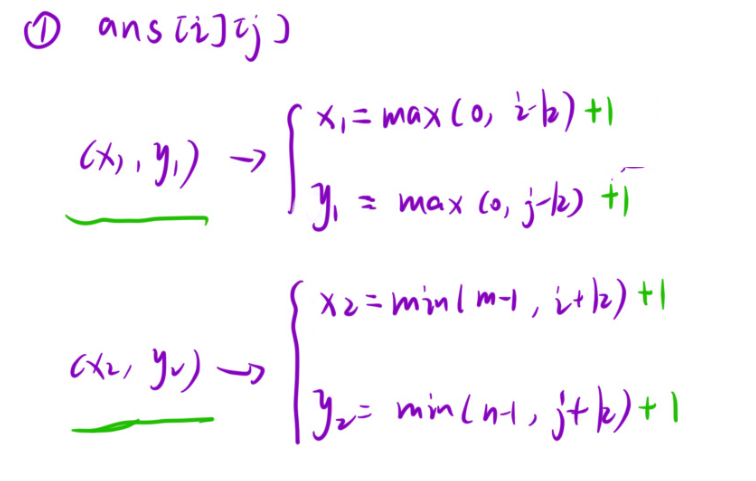
下面来实现:
