Vibe Coding 时代,研发经理为何越来越值钱?
作者:吴佳浩
撰稿时间:2026-05-25
引言
现在的研发圈,焦虑几乎已经成了主旋律。
有人拼命学习怎么和 AI 共存;
有人用了几天就开始狂喷:
- "AI 根本不能用"
- "全是幻觉"
- "还不如我自己写"
但与此同时,另一边更戏剧化的事情也在发生。
产品经理、设计师、运营,甚至消防员,开始拿着 Cursor 和 Claude 两小时搓出一个 MVP,然后兴奋地说:
"软件开发?我也可以。"
于是你会看到一个很奇怪的时代:
真正写代码的人越来越焦虑,
没写过代码的人却越来越自信。
两拨人同时在互联网上高强度发言,热闹得很。
而我这种长期在技术前沿瞎晃的人(先放个狗头保命),往往会比很多人更早一点闻到一些变化。
因为很多人现在讨论 AI,还停留在:
- "它能不能替代程序员"
- "它写代码到底强不强"
- "Cursor 是不是骗局"
- "Claude 有没有幻觉"
但真正的问题其实已经变了。
AI 正在把"写代码"这件事,变成一种越来越廉价的能力。
而当执行成本开始无限下降之后,真正稀缺的东西,就不再是"会不会写",而是:
- 知不知道该写什么
- 能不能控制复杂系统
- 能不能看出 AI 到底写对了没有
- 能不能为最终结果负责
今天想聊一个有点反直觉的判断:
在"人人都能做软件"的时代, 最近的一些大厂突然开始停止给员工发放token,背后的原因还是在于很多人并不知道哪里该用,哪里不该用AI,甚至有人出现了AI什么都可以的幻觉,但事实是AI只能放大你的专业和认知内的优势,而你认知之外的内容基本等于科技平权毫无优势可言,甚至会出现过度依赖信假为真感叹号!!!!!!!!!!
有一个职业,正在逆势升值。
背景:一场正在发生的结构性断裂
2025 年 2 月,AI 研究员 Andrej Karpathy 造了一个词:"vibe coding"------你只需要描述你想要什么,AI 写代码,你不用看懂每一行。同年年底,柯林斯词典把它评为年度词。
这不是一个比喻,是真实的数字:
| 指标 | 数据 | 来源 |
|---|---|---|
| 美国开发者每日使用 AI 工具 | 92% | Stack Overflow, 2026 |
| 新代码中 AI 生成比例 | 46% | GitHub, 2026 |
| vibe coding 用户中非开发者 | 63% | 13Labs, 2026 |
| YC 2025 冬季批次 AI 代码 >91% 的初创 | 21% | Y Combinator |
| Fortune 500 使用 vibe coding 平台 | 87% | Second Talent, 2026 |
这意味着"写代码"这件事,正在被商品化。
但有一件事没有被商品化:
判断代码写得对不对。
第一层:初级程序员最危险
AI 最擅长替代的,恰好是初级工程师的传统成长路径:
| 任务类型 | AI 时间节省 | 影响 |
|---|---|---|
| 样板代码生成 | ~81% | 初级核心工作 |
| CRUD 开发 | ~78% | 初级核心工作 |
| API 对接胶水代码 | ~75% | 初级核心工作 |
| 代码 review 辅助 | ~45% | 中级工作 |
| 架构决策 | 负效果 | 高级工作,AI 反而更慢 |
数据来源:McKinsey February 2026 study,150 家企业
但更危险的是一个致命的信任悖论------越不懂代码的人,越敢跳过 review 直接上线:
结论:越不懂技术的人越敢直接上线 AI 代码,越敢上线的人写出来的质量越差。这个倒置,是系统崩溃的火种。
第二层:AI 制造了一种新型技术债
MIT 教授 Armando Solar-Lezama 的比喻一针见血:
"AI 就像一张全新的信用卡,让我们以前所未有的速度积累技术债。"
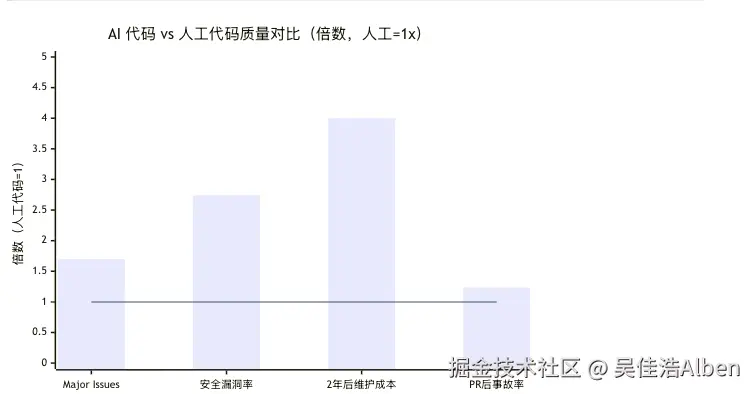 数据来源:CodeRabbit 分析 470 个 PR;DORA 2024-2025;BuildMVPFast 2026
数据来源:CodeRabbit 分析 470 个 PR;DORA 2024-2025;BuildMVPFast 2026
其他关键预测:
- Gartner:prompt-to-app 方式将使软件缺陷到 2028 年增加 2,500%
- Forrester:75% 的技术决策者将在 2026 年面临中度到严重的技术债
- Lovable 平台:1,645 个应用中 10.3% 存在严重行级安全漏洞
这不是 AI 写代码的问题。
这是:
- 谁能识别出问题
- 谁能判断风险
- 谁来为系统后果负责
的问题。
第三层:研发经理的技术底座------这才是核心
这是最容易被忽视、也最关键的一层。
研发经理不是"不写代码的管理者",而是:
"写了大量代码之后,才能做出正确判断的人。"
研发经理的晋升路径几乎是固定的:
这条路径意味着什么?
研发经理在成为管理者之前,已经:
- 亲手踩过无数技术陷阱,知道哪种写法三个月后会变成噩梦
- 经历过多次系统崩溃,知道"这段代码看起来没问题"有多危险
- 主导过架构迁移,知道"重构"有多贵、技术债有多重
- 做过大量 code review,知道 AI 生成的"工整代码"背后可能藏着什么逻辑漏洞
3.1 技术经验赋予的"代码大局观"
研发经理看一个 PR,看的不只是这段代码本身,而是:
AI 能生成符合语法的代码。
但 AI 没有:
- "踩过坑"的记忆
- "系统崩溃过"的直觉
- "凌晨三点被 oncall 叫醒"的风险嗅觉
这些能力都来自真实后果。
3.2 为什么 AI 无法替代这种技术判断力
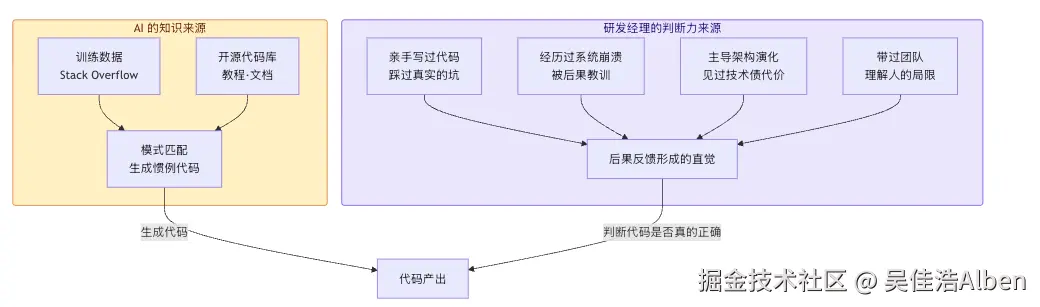
AI 的"知识"来自训练数据。
研发经理的"判断力"来自后果反馈。
 AI 是"见多识广"。
AI 是"见多识广"。
研发经理是"吃一堑长一智"。
前者是模式匹配。
后者是后果驱动的直觉。
这两者在 vibe coding 时代的价值完全不对等。
3.3 技术能力让研发经理能做 AI 做不到的事
| 能力维度 | AI | 没有技术背景的管理者 | 技术出身研发经理 |
|---|---|---|---|
| 识别 AI 生成代码的隐藏问题 | ✗ | ✗ | ✅ |
| 判断架构决策的长期影响 | ✗ | ✗ | ✅ |
| 设计有效的 AI workflow | △ | ✗ | ✅ |
| 在代码层面控制技术债 | ✗ | ✗ | ✅ |
| 与工程师建立技术信任 | ✗ | ✗ | ✅ |
| 向业务翻译技术风险 | △ | △ | ✅ |
第四层:为什么偏偏是研发经理
4.1 价值链拆解:AI 强在哪里,弱在哪里
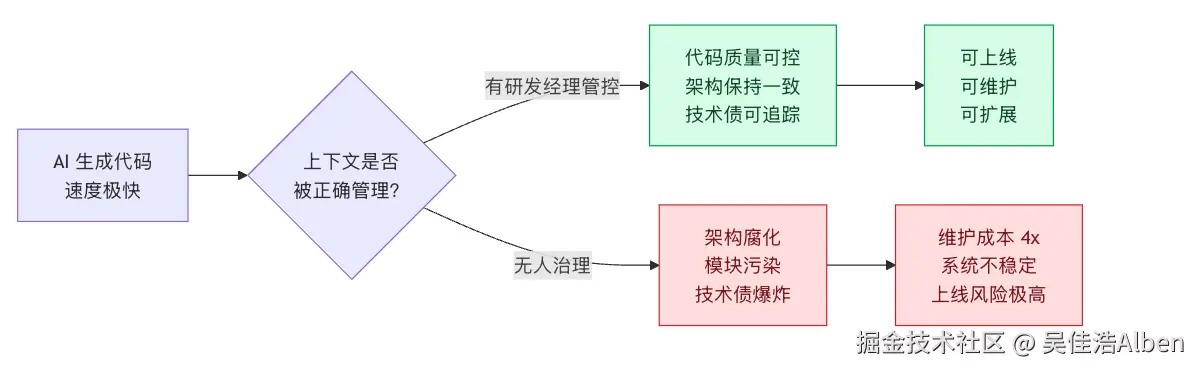
4.2 "上下文失控":AI 最大的工程盲区
METR 做了一个严格随机对照实验:
有经验的开源开发者使用 AI 工具后,客观上变慢了,但 95% 的人主观上认为自己更快了。
第五层:工作流的变化------Before vs After
Before:2022 传统研发工作流
After:2026 AI 时代研发工作流
角色对比
| 旧角色定义 | 新角色定义 |
|---|---|
| Sprint 规划员 | AI workflow 架构师 |
| 人力协调者 | Multi-agent orchestration manager |
| Jira 管理员 | 系统级质量控制者 |
| 进度跟踪者 | 技术债治理者 |
| 需求传递者 | 上下文设计者(Context Architect) |
第六层:市场信号------数据不说谎
6.1 工程师需求不降反升
- 软件工程职位同比上涨 11%
- 当前开放职位 67,000 个,创三年新高
原因很简单:
AI 让更多人能"造软件",但造出来的系统,需要更多真正懂工程的人来治理。
6.2 非技术型管理者正在被系统性淘汰
被淘汰的是:
- 不懂技术
- 不会 review
- 只会流程协调
的管理者。
留下来的,是:
- 技术出身
- 能看懂 AI 产出
- 能设计工程体系
- 能控制技术债
的研发经理。
6.3 高 AI 采用团队 vs 低 AI 采用团队
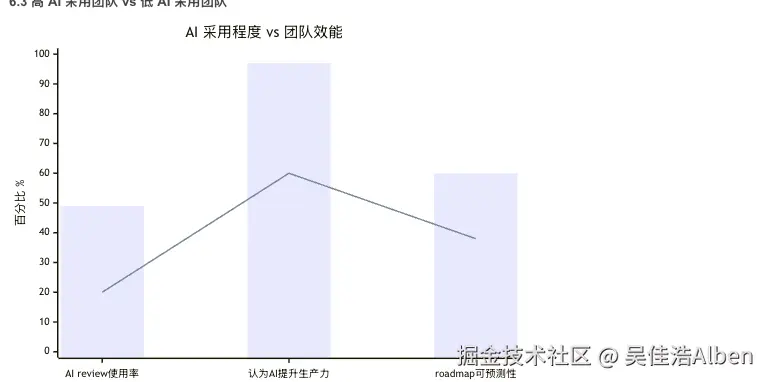
真正拉开差距的不是工具。
而是:
谁能建立 AI 使用规范、质量门槛与治理体系。
第七层:研发经理真正的护城河
实战:研发经理的一次 AI 代码审查
理论说再多,不如看一段真实代码。假设 AI 生成了下面这个用户查询接口:
python
## 实战:并发场景下的 AI 代码隐患
如果说 SQL 注入是"一眼能看出的问题",那么并发场景下的隐患则隐蔽得多。AI 生成的代码在单线程测试中往往表现完美,一旦上线面对真实流量,竞态条件就会像定时炸弹一样引爆。
假设 AI 生成了下面这个热点数据缓存查询接口:
```python
# AI 生成的代码 ------ 单线程测试通过,高并发下必崩
import redis
import time
r = redis.Redis(host="localhost", port=6379, db=0)
def get_hot_data(key):
# 问题 1:非原子性检查 + 设置,存在缓存击穿
cached = r.get(key)
if cached is not None:
return cached.decode("utf-8")
# 模拟从数据库查询(耗时 200ms)
data = query_from_db(key)
# 问题 2:没有设置过期时间,缓存永不过期
r.set(key, data)
return data
def query_from_db(key):
time.sleep(0.2) # 模拟慢查询
return f"value_for_{key}"这段代码在单线程下完全正常:缓存未命中 → 查数据库 → 写入缓存 → 返回。但在高并发场景下,1000 个请求同时请求同一个热点 key,会发生什么?
- 1000 个请求全部未命中缓存
- 1000 个请求同时穿透到数据库
- 数据库瞬间被打满,连接池耗尽
- 缓存写入 1000 次,全是重复数据
这就是经典的缓存击穿问题。
研发经理 review 后,指出三个问题并修正:
python
# 研发经理修正版 ------ 原子操作 + 分布式锁 + 过期策略
import redis
import time
import threading
r = redis.Redis(host="localhost", port=6379, db=0)
# 分布式锁的 Lua 脚本(原子操作)
LOCK_SCRIPT = """
if redis.call("SETNX", KEYS[1], ARGV[1]) == 1 then
redis.call("EXPIRE", KEYS[1], ARGV[2])
return 1
else
return 0
end
"""
UNLOCK_SCRIPT = """
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
end
"""
def get_hot_data(key):
# 修复 1:先尝试读缓存,命中直接返回
cached = r.get(key)
if cached is not None:
return cached.decode("utf-8")
# 修复 2:分布式锁,只让一个请求去查数据库
lock_key = f"lock:{key}"
lock_value = f"{threading.get_ident()}:{time.time_ns()}"
locked = r.eval(LOCK_SCRIPT, 1, lock_key, lock_value, 5) # 锁超时 5 秒
if not locked:
# 没抢到锁,等待 50ms 后重试(自旋等待)
time.sleep(0.05)
return get_hot_data(key)
try:
# 双重检查:拿到锁后再次检查缓存(防止等待期间已被写入)
cached = r.get(key)
if cached is not None:
return cached.decode("utf-8")
# 只有这一个请求会查数据库
data = query_from_db(key)
# 修复 3:设置过期时间 + 随机偏移,防止缓存雪崩
import random
expire_time = 300 + random.randint(0, 60) # 5 分钟 ± 随机 1 分钟
r.setex(key, expire_time, data)
return data
finally:
# 修复 4:使用 Lua 脚本原子释放锁(只释放自己的锁)
r.eval(UNLOCK_SCRIPT, 1, lock_key, lock_value)
def query_from_db(key):
time.sleep(0.2)
return f"value_for_{key}"修正要点总结:
| 问题 | AI 版本 | 研发经理修正 | 风险等级 |
|---|---|---|---|
| 缓存击穿 | 无锁,高并发下 N 个请求同时穿透到 DB | 分布式锁 + 双重检查,只让一个请求查 DB | 高危 |
| 缓存永不过期 | r.set(key, data) 无过期时间 |
r.setex(key, expire_time, data) 带过期 + 随机偏移 |
中危 |
| 锁释放安全 | 无锁机制 | Lua 脚本原子释放,只释放自己的锁,防止误删 | 中危 |
| 自旋等待 | 无重试机制,未命中直接穿透 | 抢锁失败后 50ms 自旋重试,避免空转 | 低危 |
这个案例揭示了一个更隐蔽的风险:AI 生成的代码在单线程、低并发场景下测试全部通过,但一旦上线面对真实流量,竞态条件就会暴露。 只有经历过线上事故的研发经理,才能在 review 阶段就嗅到并发场景下的隐患------这不是模式匹配能学会的,这是被 oncall 电话教训出来的直觉。
AI 生成的代码 ------ 看起来没问题,实则隐患重重
python
from flask import Flask, request, jsonify
import sqlite3
app = Flask(__name__)
@app.route("/user/<user_id>")
def get_user(user_id):
conn = sqlite3.connect("users.db")
cursor = conn.cursor()
# 问题:SQL 注入:直接拼接用户输入
cursor.execute(f"SELECT * FROM users WHERE id = '{user_id}'")
row = cursor.fetchone()
conn.close()
return jsonify({"id": row[0], "name": row[1]}) # 问题:无空值检查,user_id 不存在时抛异常研发经理 review 后,指出三个问题并修正:
python
# 研发经理修正版 ------ 安全、健壮、可维护
from flask import Flask, request, jsonify, abort
import sqlite3
from contextlib import closing
app = Flask(__name__)
@app.route("/user/<user_id>")
def get_user(user_id):
# 修复 1:参数化查询,杜绝 SQL 注入
query = "SELECT id, name FROM users WHERE id = ?"
try:
with closing(sqlite3.connect("users.db")) as conn:
cursor = conn.cursor()
cursor.execute(query, (user_id,))
row = cursor.fetchone()
except sqlite3.Error as e:
# 修复 2:数据库异常捕获,避免 500 裸奔
app.logger.error(f"DB error for user {user_id}: {e}")
abort(500)
if row is None:
# 修复 3:空结果返回 404,而非抛异常
abort(404, description=f"User {user_id} not found")
return jsonify({"id": row[0], "name": row[1]})修正要点总结:
| 问题 | AI 版本 | 研发经理修正 | 风险等级 |
|---|---|---|---|
| SQL 注入 | 字符串拼接 f"'{user_id}'" |
参数化查询 ? 绑定 |
高危 |
| 异常处理 | 无 try-except,DB 断开即 500 | 捕获 sqlite3.Error 并记录日志 |
中危 |
| 空值检查 | 直接解包 row[0],不存在则抛 TypeError |
判空后返回 404 | 中危 |
小结:
这些能力有一个共同前提:
必须真正写过代码,被后果教训过,才能形成判断力。
AI 没有后果。
所以 AI 永远无法真正获得这种能力。
结论
不是因为 AI 变弱了,而是因为 AI 让"系统后果"的重量变重了。 更深层的原因是:研发经理是从代码里走出来的人,而 AI 永远不是。
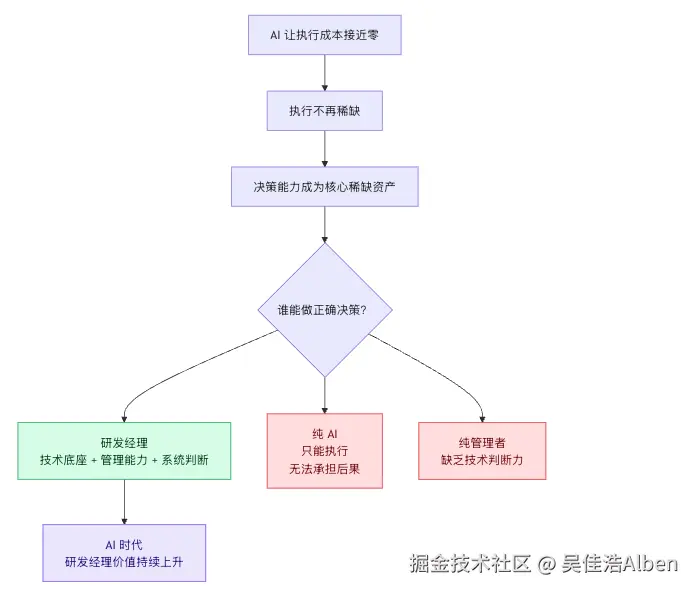
vibe coding 没有消灭研发管理。
它做了一件更彻底的事:
把执行成本压到接近零,让"写过代码 + 能做决策 + 承担后果"这三者合一的人,变成最稀缺的资产。
这个角色,就是研发经理。
过去,研发经理是"工程师的管理者"。
现在,研发经理是"AI 工厂的厂长"------他不只是管理人力,更是在控制一个由 AI 驱动的软件生产系统,并最终为系统后果负责。
肯定会有人讲:"现在skills这么丰富,一个skill不就行了?"
如果你是这么想的那就是你对!抱拳了。