在阅读本文之前,建议读者优先阅读作者的Java专栏。
目录
前言
本文主要介绍Java中的集合框架部分的相关知识。
一、集合框架简介
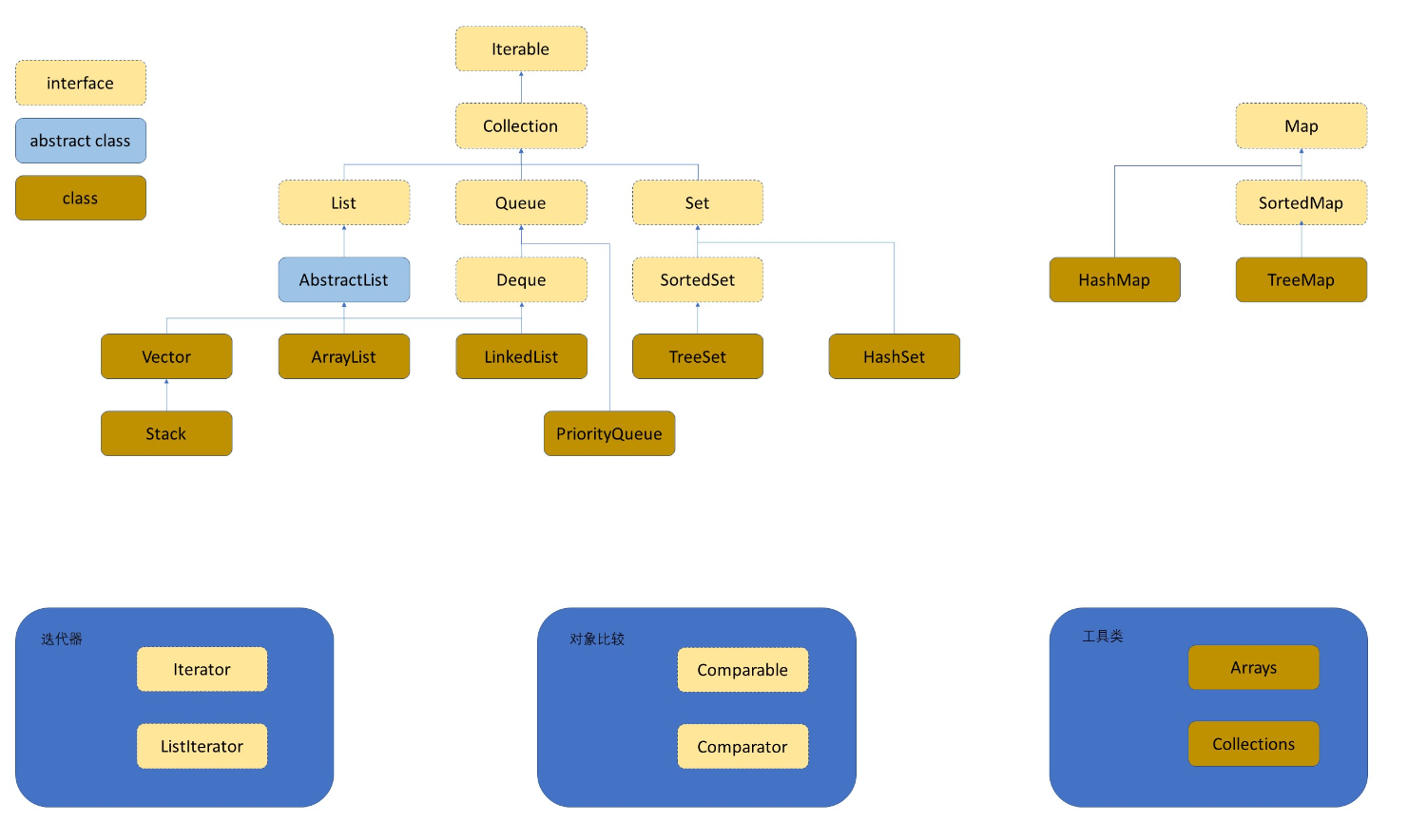
Java集合框架又被称为容器,它是定义在java.util包下的一组接口和其实现类,其主要表现为将多个元素置于一个单元中,用于对这些元素快速便捷的存储、检索和管理,也即我们平时俗称的增删改查。这些接口和类大致如下图所示。
二、集合框架的数据结构与算法知识
数据结构是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的
集合。该阶段,我们主要学习以下容器,每个容器其实都是对某种特定数据结构的封装,大概了解一下,后序会给大家详细讲解并模拟实现。Collection,是一个接口,包含了大部分容器常用的一些方法;List,是一个接口,规范了ArrayList和LinkedList中要实现的方法;ArrayList,实现了List接口,底层为动态类型顺序表;LinkedList,实现了List接口,底层为双向链表;Stack,底层是栈,栈是一种特殊的顺序表;Queue,底层是队列,队列是一种特殊的顺序表;Deque,是一个接口;Set,集合,是一个接口,里面放置的是K模型;HashSet,底层为哈希桶,查询的时间复杂度为O(1);TreeSet,底层为红黑树,查询的时间复杂度为O(logN),关于key有序的;Map,映射,里面存储的是K-V模型的键值对;HashMap,底层为哈希桶,查询时间复杂度为O(1),TreeMap,底层为红黑树,查询的时间复杂度为O(logN),关于key有序。
关于时间复杂度和空间复杂度的相关知识,请参考我下面的文章:
三、初识包装类及泛型
在Java中,由于基本类型不是继承自Object,为了在泛型代码中可以支持基本类型,Java给每个基本类型都对应了一个包装类型,它们基本有着如下的对应:
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
那么在了解上述部分之后,我们需要来介绍一下装箱和拆箱这两种操作。装箱就是把基本数据类型变为包装类类型的过程,比如我们如下的代码:
java
public class Main {
public static void main(String[] args) {
int a = 10;
Integer i1 = Integer.valueOf(a);
Integer i2 = 10;
System.out.println(i1);
System.out.println(i2);
}
}其运行结果如下:

我们此时可以用javap命令来观看一下它底层的过程:
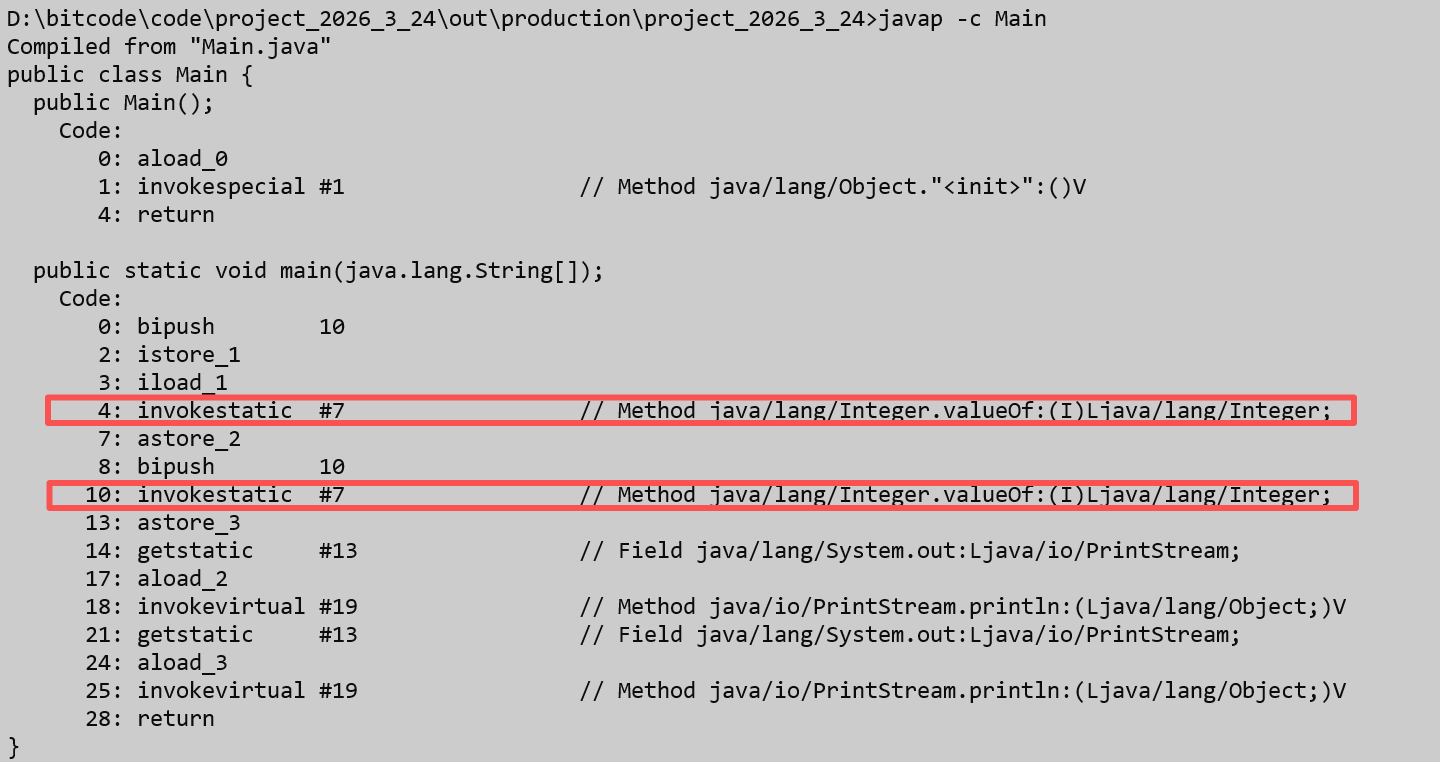
可以看到我用红框圈出的部分其实就是我们两个Integer所在的语句,同时虽然第二句并没有调用其中的valueOf方法,编译器也自动帮我们进行了这个操作。我们就把第一句就叫做显式装箱,第二句为隐式装箱。然后我们再键入如下的代码:
java
public class Main {
public static void main(String[] args) {
Integer i1 = 10;
int i2 = i1;
int i3 = i1.intValue();
double i4 = i1.doubleValue();
System.out.println(i1);
System.out.println(i2);
System.out.println(i3);
System.out.println(i4);
}
}其运行结果如下:

同样我们用javap命令来看一下底层运行过程:
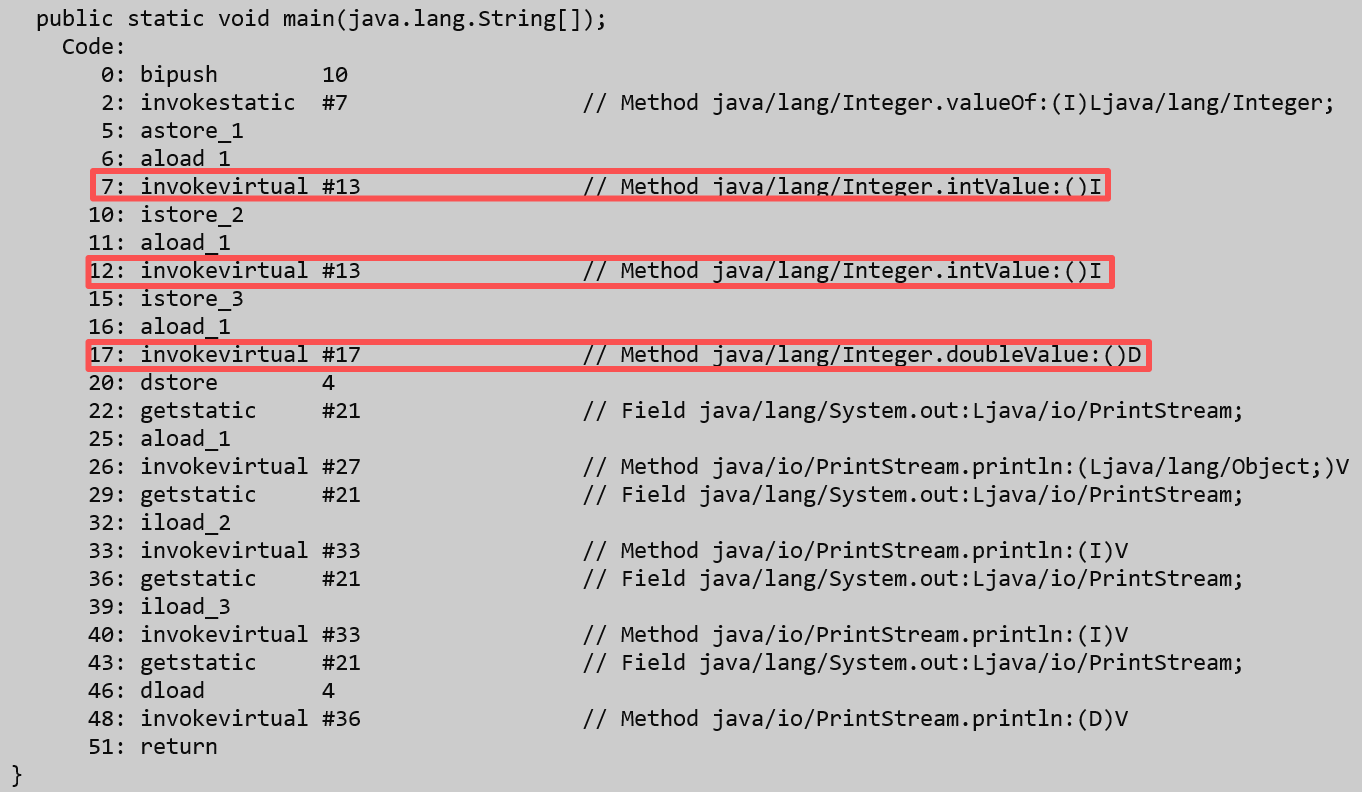
可以看到上面圈出的这三部分,其实就是拆箱,所以拆箱就是把包装类类型变为基本数据类型的过程。我们接下来看看下面这部分代码,读者可以先行猜测一下这段代码最终运行的结果:
java
public class Main {
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
System.out.println(a == b);
Integer c = 200;
Integer d = 200;
System.out.println(c == d);
}
}其运行结果如下:

为什么会产生这种结果呢?我们可以去看看Integer的源码:
java
@IntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}根据这部分源码,我们就可以初步猜测源码中的i应该是在一个范围的时候,就直接去数组拿值,当不在这个范围的时候,它就会返回新的对象,而我们如果用等号去比较新的对象的话,那必然是不一样的。那么这个low和high都分别是多少呢?我们可以去看看:
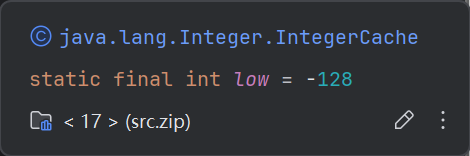
java
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
h = Math.max(parseInt(integerCacheHighPropValue), 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(h, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;所以我们这-128~127这256个数字就被存放在cache这个数组之中,然后从-128开始按顺序存放在整个cache数组之中。然后我们再来看一下什么是泛型?一般的类和方法,只能使用具体的类型,要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。泛型是在JDK1.5引入的新的语法,通俗讲泛型就是适用于许多许多类型。从代码上讲,就是对类型实现了参数化。比如现在,我们需要实现一个类,这个类中包含一个数组成员,使得数组之中可以存放任何类型的数据,也可以根据成员方法返回数组之中某个下标的值。由于Object是所有类的父类,我们就借用一下它,给出如下的代码:
java
class myArray{
public Object[] array = new Object[10];
public void setValue(int pos, Object val){
array[pos] = val;
}
public Object getValue(int pos){
return array[pos];
}
}
public class Main {
public static void main(String[] args) {
myArray obj = new myArray();
obj.setValue(0, 10);
obj.setValue(1, "hello");
System.out.println(obj.getValue(0));
System.out.println(obj.getValue(1));
}
}其运行结果如下:

但是在我们写完这部分代码之后,我们就会有两个比较明显的问题。第一个就是这种方式存放数据过于杂乱了,我们什么类的数据都可以放进去;第二个就是如果说我们不是直接输出的话,而是获取这个数据并存放到一个变量之中,我们就必须去进行强转,而每次都要强转就十分麻烦。这个时候我们就可以借用泛型来解决这些问题。泛型的主要目的就是指定当前的容器,要持有什么类型的对象。让编译器去做检查。此时,就需要把类型,作为参数传递。需要什么类型,就传入什么类型。它的基本语法就是如下形式:
java
class 泛型类名称<类型形参列表> {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> {
}
class 泛型类名称<类型形参列表> extends 继承类/* 这里可以使用类型参数 */ {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
// 可以只使用部分类型参数
}那我们就可以对我们上面的代码进行相关的改造:
java
class myArray<E>{
public Object[] array = new Object[10];
public void setValue(int pos, Object val){
array[pos] = val;
}
public E getValue(int pos){
return (E)array[pos];
}
}
public class Main {
public static void main(String[] args) {
myArray<Integer> myArray = new myArray<>();
myArray.setValue(0, 10);
myArray.setValue(1, 20);
myArray.setValue(2, 30);
Integer a = myArray.getValue(0);
Integer b = myArray.getValue(1);
Integer c = myArray.getValue(2);
System.out.println(a);
System.out.println(b);
System.out.println(c);
myArray<String> arr = new myArray<>();
arr.setValue(0,"hello");
arr.setValue(1," world");
String s1 = arr.getValue(0);
String s2 = arr.getValue(1);
System.out.println(s1 + s2);
}
}其运行结果如下:

需要注意的是,首先我们类名后的<E>代表占位符,表示当前类是一个泛型类,它其中的形参一般都是用一个大写字母来代替的,常用的有如下几种,E表示Element,K表示Key,V表示Value,N表示Number,T表示Type,S, U, V 等等表示第二、第三、第四个类型;其次我们不能够new泛型类型的数据,应该在类型后面加入<>来指定当前的类型;然后我们如果说在指定好类型之后传输了一个错误的类型就会报错,这是因为在我们创建对象的时候就已经指定类当前的类型了,到我们传输数据的时候,编译器就会替我们去做检查;最后我们的泛型只能接受包装类,不允许直接传入基本数据类型,而如果说编译器可以根据上下文推导出类型实参时,可以省略类型实参的填写,也就是下面这种意思:
java
MyArray<Integer> list = new MyArray<>();此时如果说我们修改一下上面代码部分变为下面这样:
java
myArray myArray = new myArray();
myArray.setValue(0, 10);
myArray.setValue(1, 20);
myArray.setValue(2, "abcdef");
Integer a = myArray.getValue(0);
Integer b = myArray.getValue(1);
Integer c = (Integer)myArray.getValue(2); 此时我们并没有写<>但是却没有报错,这就是一种裸类型,它是一个泛型类却没有带类型实参,我们不要自己去使用裸类型,它是为了兼容老版本的API保留的机制。在了解完上面关于泛型使用的部分之后,我们再来聊聊泛型是如何编译的呢?实际上,泛型是编译时期的一种机制,在运行的时候我们没有泛型的概念。我们可以利用javap命令来看一下:
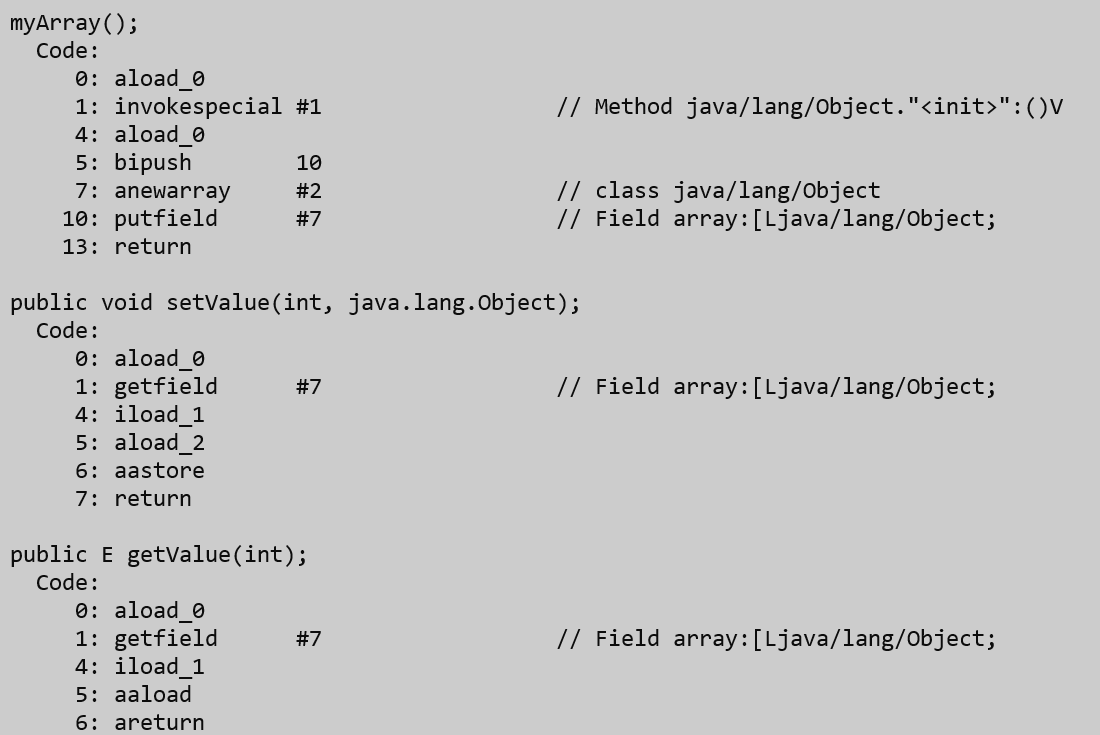
我们发现实际上这个E其实被替换为了Object类,我们就称这种机制为擦除机制。Java的泛型机制是在编译级别实现的。编译器生成的字节码在运行期间并不包含泛型的类型信息。具体有关泛型擦除机制的文章可以参考下面:
在我们定义泛型类的时候,有时需要对传入的类型变量做一定约束,这时我们可以通过类型边界来约束。它遵循如下的语法形式:
java
class 泛型类名称<类型形参 extends 类型边界> {
...
}同样我们也可以将泛型和方法结合:
java
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) { ... }总结
本文介绍了Java集合框架的基础知识,包括集合框架的概念、常用数据结构与算法,以及包装类和泛型的使用。集合框架是Java中用于存储和管理数据的核心组件,包含List、Set、Map等多种容器。文章详细讲解了包装类的装箱拆箱机制,以及泛型的定义和使用方法,包括泛型类的创建、类型擦除机制等。通过代码示例展示了如何利用泛型提高代码的安全性和灵活性,同时解释了泛型在编译期的处理机制。