刚刚落幕的 2026 科技界「春晚」GTC 大会上,一个全行业的共识已经形成:AI 正在进入智能体(Agent)时代。
然而,当各大厂商都在疯狂入局智能体时,一个尴尬的现实却摆在面前:这些聪明的数字大脑,缺少一个「灵动」的「躯壳」。如果说「龙虾」OpenClaw 已经为 AI 智能体工作的范式打开了方向,那么解决 AI 怎么和人打交道的交互领域,技术还面临着挑战。
因涉及多个模态的转换,为聪明的 AI 打造一副高表现力的「躯壳」,比想象中还要困难得多。
直到最近,京东数字人的一系列新研究打破了这一僵局。
京东 JoyStreamer 和 JoyStreamer-Flash 两个数字人大模型,解决行业长期存在的文本指令控制力弱、多模态控制信号冲突、长时长生成能力不足等痛点问题,实现了长时长、自由态、实时互动的数字人生成效果,相关成果发表在了 arXiv 上,新一代数字人的性能全面超越了当前 SOTA 模型,将效果推向了新的高度。
-
技术主页:joyavatar.github.io/
它具有超强的文本控制能力:
提示词:A little girl is first singing with a beaming smile, then she picks up a camera from the table, points it toward the viewer, and the flash goes of.
提示词:A woman stands indoors, speaking to the camera. She begins by picking up a vase from a cabinet, then gazes at it contemplatively, and finally places it on a chair within the scene. (Keep the character fully in frame throughout.)
可以实现分钟级时长的数字人合成:
京东 JoyStreamer 系列数字人模型有打破僵局的意义,展现出了代差级别的优势,彻底告别了数字人「站桩式播报」:它不仅能精准理解「复杂指令」,丝滑做出全身复杂动作,还能完美配合动态镜头轨迹以及背景的无缝变化。更绝的是,哪怕是在这种大幅度、剧烈运动的过程中,它依然能保持唇形与输入音频的完美同步。
输入指令「拿起巧克力吃掉」京东数字人能够根据文本提示词,流畅地完成整套抓取和咀嚼动作:
提示词:The girl picks up the chocolate box, shows it to the viewer, then takes out a piece of chocolate and eats it.
输入指令「放下手中的箱子」京东数字人不仅能平滑处理复杂的动作指令与背景流转,还能在超过 20 秒的视频生成中保持人物身份的稳定:
提示词:A man in the frame speaks to the camera while placing a toolbox on the ground, then climbs a ladder, keeping himself within the shot. He wears a white safety helmet, holds a black and yellow toolbox, with a room under renovation behind him. A ladder and a level are placed nearby.
京东数字人的三大技术创新
在生成式 AI 领域,数据是让模型学习和理解的原材料。但收集大量既有剧烈肢体运动、又有清晰语音播报的高质量视频数据,其成本是极其高昂的。面对静态播报数据的天然偏见,京东数字人团队转向了一条更为新颖的路径:双教师 DMD(分布匹配蒸馏)后训练。
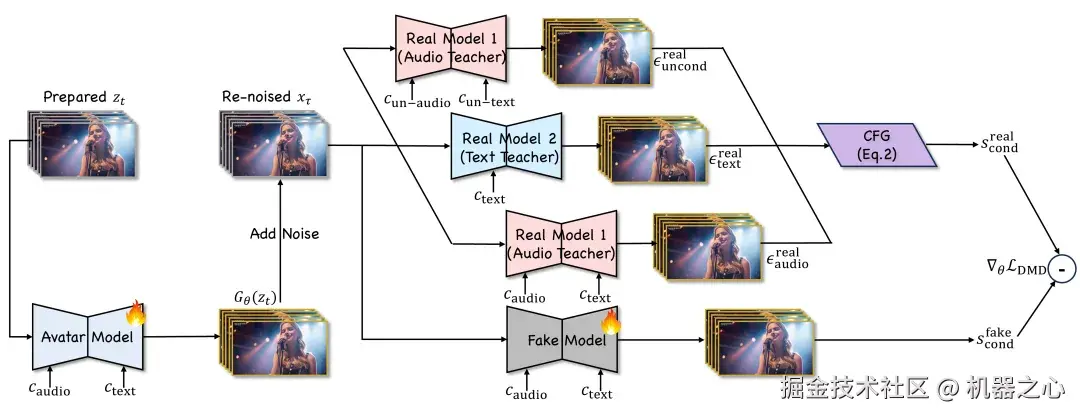
图 1 双教师 DMD 后训练框架图
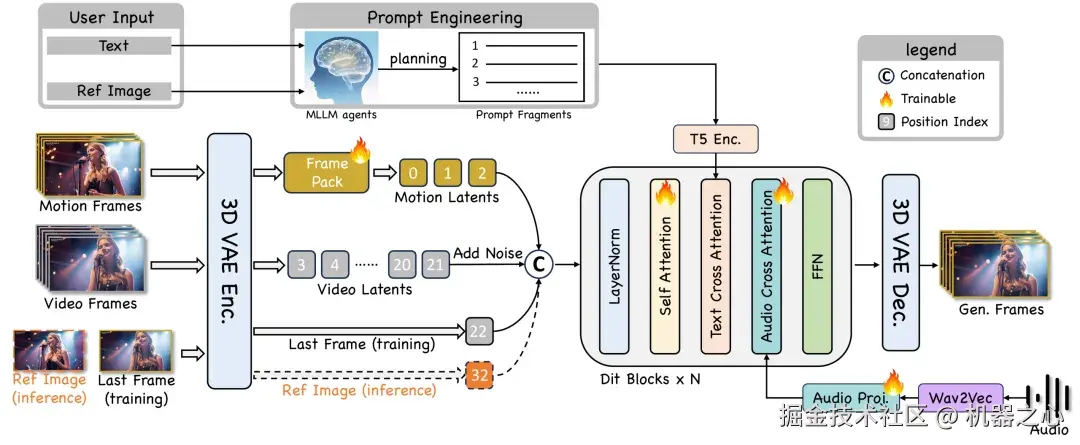
图 2 数字人模型预训练框架图
研究人员给数字人模型请来两位「老师」,其中一位是「音频教师」,由数字人基础模型担任,专攻口型和节奏;另一位则是「文本教师」,引入了视频基础大模型。由于视频生成模型具备不错的文本到视频生成能力,能够完美理解复杂的动作指令,通过这种分离式监督、融合式学习的蒸馏机制,数字人模型在不增加任何新训练数据的前提下,直接继承了其文本可控性。
让数字人既要听从剧本做出复杂动作,又要严丝合缝地对口型,在过去是一个难以兼顾的任务。因为在模型的潜在空间里,文本信号和音频信号常常会相互打架 ------ 文本要主导全身动作,音频要主导面部肌肉,两者一旦冲突,画面就会崩溃失真。
为了解决这个多模态控制冲突,团队创新性地提出了「动态 CFG 调制策略」。
研究人员发现,扩散模型在生成视频时,全局的动作框架是在早期的高噪声阶段确定的,而口型这种细粒度的细节,是在后期的低噪声阶段雕琢出来的。所以数字人模型让两种信号「错峰出行」:在生成早期,模型优先听文本的指令,先把跑跳、转身等动作框架搭好。到了生成中后期,模型再把控制权优先交给音频,保证唇形同步。
这种巧妙的设计,让文本和音频两种控制模态各司其职,互不干扰。
接下来还有一个更加面向实际的挑战。数字人需要长时间直播,而对于 AI 的长视频生成而言,最大的挑战在于「身份漂移」------ 人物说着说着,脸或者衣服就变样了。
JoyStreamer 给出的解法是历史帧编码模块(FramePack)+ 伪最后一帧策略。在推理过程中,模型不断将用户的参考图像作为「伪最后一帧」注入模型,就像给模型定了一个永远不会偏离的锚点。这使得数字人模型能够支持 30 秒以上的长视频生成,全程保持身份稳定、动作流畅,彻底打破了传统数字人模型帧闪烁、时长受限的短板。
为验证技术领先性,京东数字人团队将 JoyStreamer 模型(Ours)与业界主流 SOTA 闭源模型进行了主观 GSB 评分对比。结果显示,JoyStreamer 在文本遵从、唇形准确度、ID 保持、视频画质等核心维度均表现显著优势,整体 GSB 评分分别达到 1.36(超 omnihuman-1.5)与 1.73(超 KlingAvatar2.0),技术实力得到权威验证。(GSB计算方式: GSB=(Good+Same)/(Bad+Same))
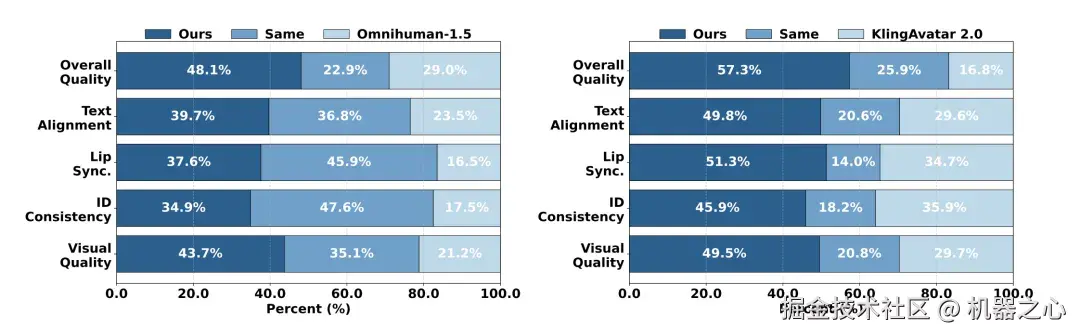
图 3 JoyStreamer 模型实验结果
与此同时,京东数字人团队还在数字人模型的推理速度优化上做出了大量创新性设计,推出了 JoyStreamer-Flash 版本(arxiv.org/abs/2512.11... CausVid 和 Self Forcing 等技术将双向模型蒸馏成自回归单向模型,并通过 4 步采样、kv-cache 和多 GPU 并行推理实现 30FPS 的生成速度。
研究团队还提出了渐进步数引导、运动条件注入、基于 cache 重置的无限 RoPE 等创新点,实现实时流式生成无限时长的高保真数字人视频,并在视觉质量、时序一致性与唇形同步等方面表现卓越。
场景与商业化
让中小商家用得起「数字人直播」
底层技术一旦捅破了天花板,广阔的应用想象力就彻底打开了。数字人直播作为核心商业场景率先迎来体验升级:无论是 7x24 小时连轴转的电商直播带货,还是需要极强表现力的电商短视频,整体内容形态与交互体验都将实现质的升级。
随着本次长时长、自由态、实时互动技术的突破,京东数字人的第一块试金石就是京东自己的核心业务 ------ 数字人直播。
从引爆全网的「采销东哥」数字人,到海尔、格力等一众总裁数字人在直播间挑起大梁,再到对微表情和肢体动作要求极高的 Vivi 明星数字人,京东数字人早已在直播场景中完成了多轮实战验证,不断打磨高表现力的直播交互能力。去年更是推出了「JoyAI 零帧起手」小程序,实现了万物皆可说,让每一个普通用户也能「玩起来」,真正把硬核的 AI 技术变成了全民皆可玩的生产力工具。
结合新技术,京东数字人 JoyStreamer 在行业内率先推出「自由态数字人」,针对家电家居、时尚服饰等五大行业推出精准适配的数字人,支持自然走动、灵活摆姿,镜头跟随、出画入画流畅,脸部遮挡也能保持高保真质感,实现了更加自然灵动的交互形态。
「自由态数字人」直播间
对于普通用户来说,新一代数字人主播可以在直播间走动,展示商品局部细节,甚至能进行多主播的复杂互动,这让直播更加有趣了;而对于电商来说,这种视觉表现力上的质变,直接拉长了用户的停留时长。
京东打造了低门槛的数字人平台。对于数量最多的中小商家而言,一听到「影视级」、「高表现力」这样的词汇,第一反应往往是用不起,这恰恰是 JoyStreamer 最大的商业杀手锏:京东的数字人直播能力目前免费开放,商家可以在自己的后台进行一键配置,自定义模型,或是一比一还原真人主播的声音。
基于此,JoyStreamer 推出的「数字人直播间复刻」能力,帮助商家最大化沉淀直播资产商家仅需上传一段真人直播视频素材,就可以快速生成一个形象、声线、神态、直播间布景上都与真人主播高度一致的「数字分身」,将单次成功直播转化为可长期复用的数字人直播资产。
新秀丽正是通过「直播间复刻」能力实现长期稳定开播,带来公域流量提升超 60%,直播间人均停留时长近 2 分钟,充分验证了该功能的商业价值。
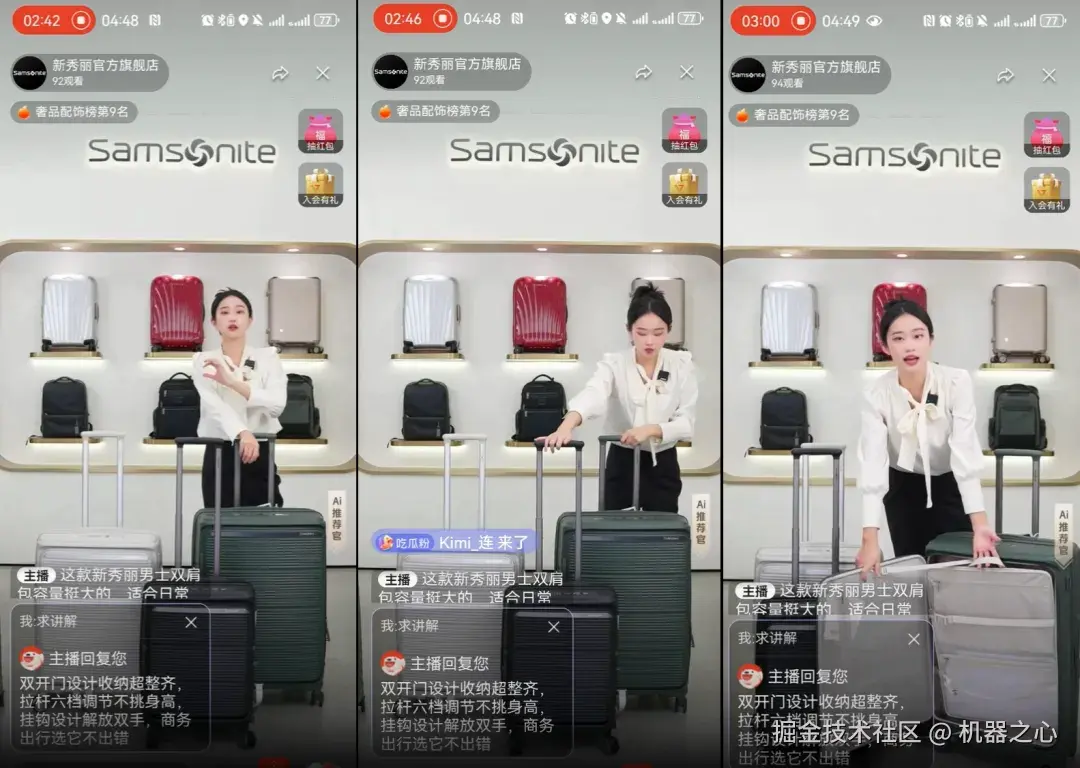
在京东的平台上,数字人与真人的直播是同场 pk 的,流量竞争正在推动数字人技术持续提升。每一次技术的升级迭代,包括数字人、语音、多模态能力,都能获得几万商家的深度应用和反馈。
目前,京东数字人 JoyStreamer 已服务超 7 万家商家,规模行业领先,几乎覆盖京东全品类,数字人直播成为越来越多商家的标配选择。高表现力的数字人主播正从「尝鲜工具」转变为拉动 GMV 的核心增长引擎。
京东 AI 的「护城河」
环顾当下的全球 AI 竞争格局,不难发现:整个行业正陷入一场烧钱的「算力军备竞赛」。
面对快速显现的需求与前沿 AI 能力的探索,京东此刻却显得更加冷静。京东相关负责人表示,大模型的发展必须从参数至上的旧范式,彻底转向效率、成本与性能平衡的新范式。
这种克制与平衡的技术哲学,不仅体现在数字人身上,也贯穿于京东大模型的整体布局。以京东近期开源的通用基础大模型 JoyAI-LLM Flash 为例,这款模型的总参数量为 480 亿,在实际运行中通过动态稀疏路由技术只激活 3B 的参数,智能体任务的 token 消耗量只有竞品模型的 1/5,并获得了很好的效果。
在庞大的 AI 应用端,大模型的知识广度,必须配合极低的推理成本和极快的响应速度,才能完美契合产业界对于经济与效果的诉求。
作为一家新型实体企业,京东拥有零售、物流、健康、工业等丰富的真实业务场景,同时具备可观的数字技术和能力。目前,京东的 AI 技术已经深度融入自身的超级供应链,在超过 2000 个具体的业务场景中落地生根。
JoyStreamer 之所以能迅速迭代出高表现力的数字人直播能力,正是因为每天有数以万计的商家在直播间里提需求、做反馈。这种基于真实商业场景的数据飞轮,是很多技术公司难以比拟的。
最后,我们都好奇数字人的下一步是什么。京东的技术负责人表示,让数字人直播间内的主播学会换装、实现更丰富的跨主播互动,并最终实现零幻觉是他们努力的方向。目前在行业里,还没有任何一个团队解决了这些问题。
在京东的直播间里,这些富有表现力的数字躯壳还在快速成长,属于京东 AI 的这场产业突围战,才刚刚拉开序幕。