上一篇文章展示了 PDF 转 Markdown 工具的功能效果。这篇深入拆解两个核心模块的架构设计和关键算法------标题怎么检测、段落怎么合并、表格怎么处理,以及实战中踩过的坑。
说明:程序实现和本文内容均有借助AI生成。
在线体验: 点击立即体验 PDF 转 Markdown
一、整体架构:两阶段流水线
核心思路先解析,再转换 。
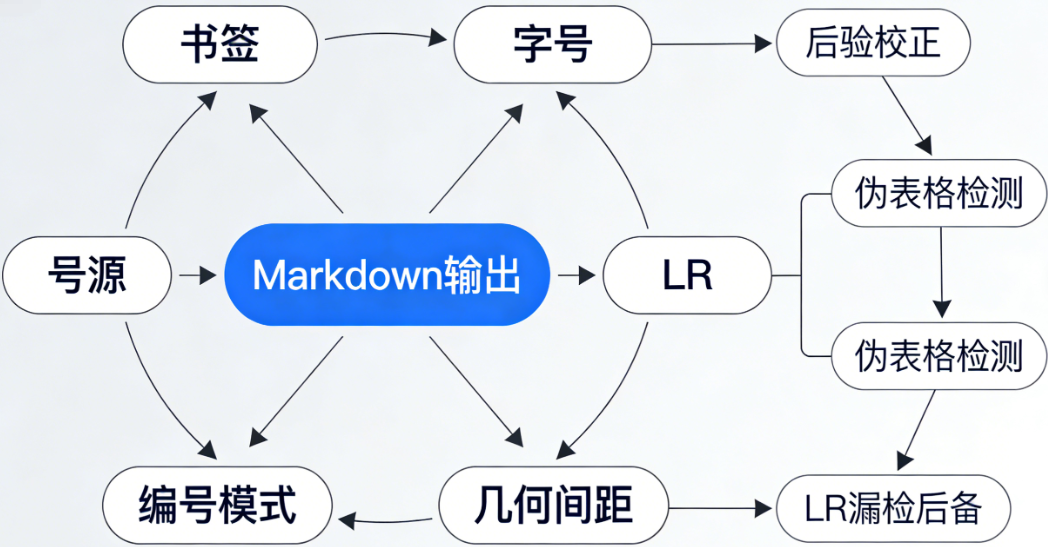
架构流程图如下:
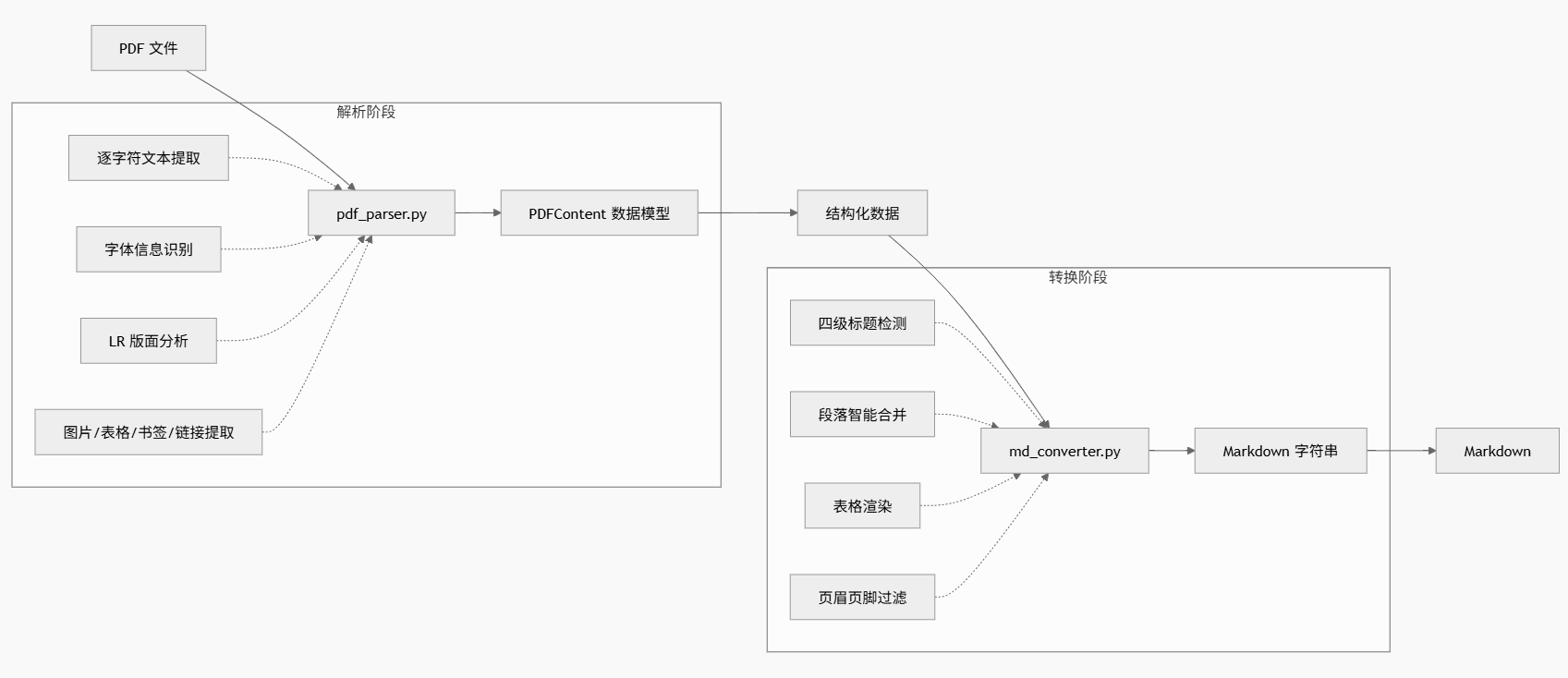
解析阶段(pdf_parser.py,约 1200 行)负责把 PDF 打散成原子级的结构数据------每个字的字号、字体、坐标,每张图的位置和像素,每个书签的层级和页码,每个表格的行列结构。
转换阶段(md_converter.py,约 900 行)根据这些原子数据推断文档的逻辑结构------哪些文本是标题、哪些文本属于同一个段落、哪些文本是重复的页眉页脚------然后渲染为 Markdown 字符串。
这个两阶段设计的好处是关注点分离:解析器不需要懂 Markdown 语法,转换器不需要关心 PDF 字节流。加一个输出格式(比如 HTML)只需要写一个新的转换器,解析器完全复用。
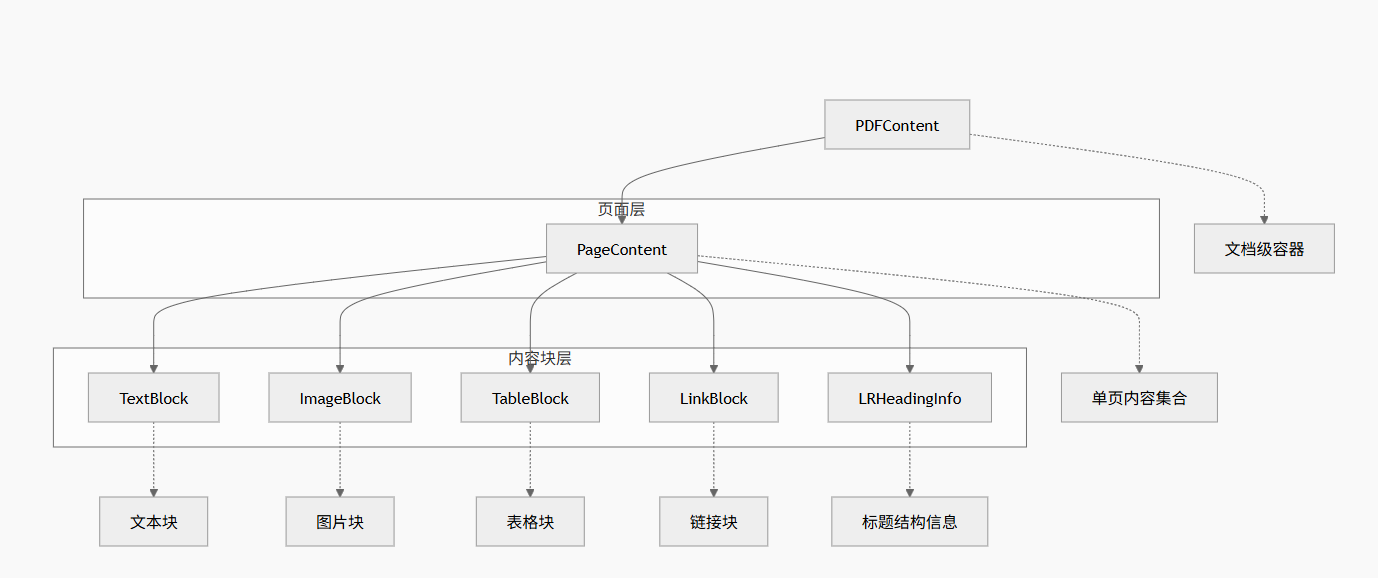
二、数据模型:解析到转换的"桥梁"
两个阶段之间通过一组数据类(dataclass)传递信息:
python
@dataclass
class PDFContent:
title: str # 文档标题(来自元数据)
author: str # 作者
page_count: int # 总页数
bookmarks: List[BookmarkItem] # 书签树
pages: List[PageContent] # 各页内容
@dataclass
class PageContent:
page_index: int
width: float # 页面宽度
height: float # 页面高度
text_blocks: List[TextBlock] # 文本块(带字体信息和坐标)
image_blocks: List[ImageBlock] # 图片
link_blocks: List[LinkBlock] # 超链接
table_blocks: List[TableBlock] # 表格(来自 LR 模块)
lr_headings: List[LRHeadingInfo] # LR 识别的标题元素
lr_paragraphs: List[Tuple] # LR 段落边界框其中最核心的是 TextBlock------每个文本块带着完整的样式信息:
python
@dataclass
class TextBlock:
text: str
font_name: str = ""
font_size: float = 0.0
is_bold: bool = False
is_italic: bool = False
bbox: Tuple[float, float, float, float] = (0, 0, 0, 0) # left, bottom, right, top
page_index: int = 0这些字段在转换阶段全都会用到------font_size 用于标题检测,is_bold 用于兜底标题判断,bbox 坐标用于段落合并和页眉页脚过滤。
数据模型层级图如下图所示:
三、核心算法 1:四级级联标题检测
标题检测是转换质量的核心------检测不准,整个 Markdown 的结构就乱了。因此我设计了一个四级级联策略,按优先级依次命中,高优先级命中后直接跳过低优先级。如下图所示:
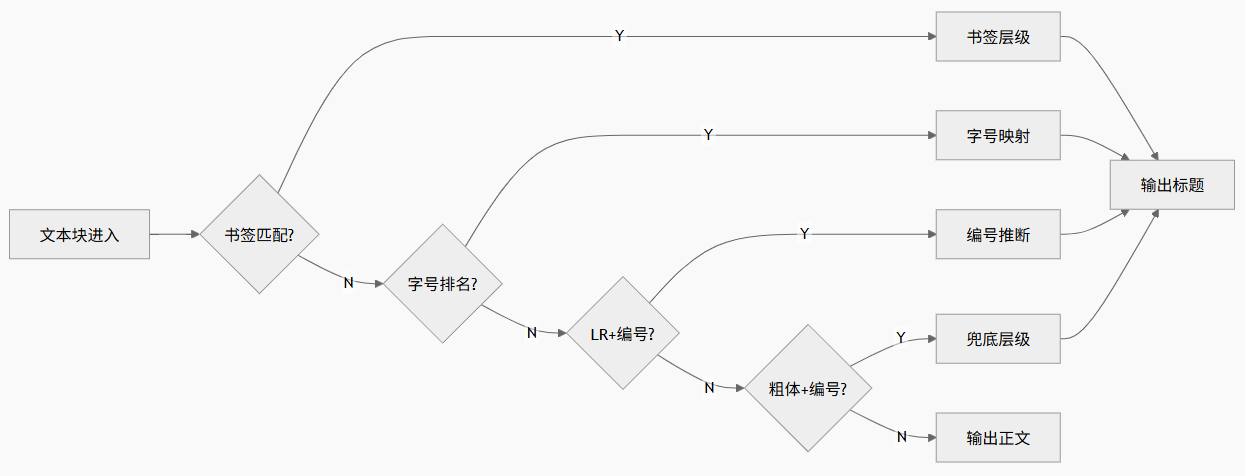
3.1 第一优先级:PDF 书签匹配
PDF 书签(Bookmark)是 PDF 作者或排版工具在文件中显式标记的目录结构,它直接告诉你"第三章 xxx"在第几页、属于第几级。这是最可靠的标题信号源。
做法是把书签树展平为一个映射表 (page_index, title) → heading_level,然后对每个文本块做模糊匹配:
python
for (bm_page, bm_title), bm_level in bm_heading_map.items():
if bm_page == page.page_index:
if bm_title in text or text in bm_title or \
normalize(bm_title) == normalize(text):
heading_level = bm_level
break为什么用"包含"而不是精确匹配?因为书签文本和页面实际文本经常存在微小差异------多一个空格、编号格式略不同。用包含关系匹配可以容忍这些差异。
3.2 第二优先级:字号排名启发式
当 PDF 没有书签、或书签没覆盖的标题,就用字号来判断。
核心思路是:统计全文档的字号分布,出现次数最多的字号就是正文字号(body_size),所有比正文大 20% 以上的字号按从大到小排序,依次映射为 H1、H2、H3......
python
body_size = max(size_char_count, key=size_char_count.get) # 使用最多的字号
min_heading_size = body_size * 1.20 # 至少大 20%
heading_sizes = sorted(
[fs for fs in sizes if fs >= min_heading_size],
reverse=True,
)
# heading_sizes[0] → H1, heading_sizes[1] → H2, ...为什么阈值是 1.20 而不是 1.0? 因为实际中,目录条目、表格标题等文字的字号经常比正文大一点点(比如 10.5pt vs 9pt),如果阈值太低,这些非标题内容会被错误升级为标题。20% 是经过 20 多份 PDF 反复测试调出来的平衡值。
另外,同字号但粗体的短文本(≤50 字符)也会被提升为低级标题(比如 ####),但长文本(粗体的整段正文)不会。
以下是 _compute_font_stats() 的完整实现------它负责完成上述"统计 → 排名 → 映射"的全过程:
python
# ---- md_converter.py: _compute_font_stats() ----
def _compute_font_stats(pages: List[PageContent]) -> Dict:
size_char_count: Dict[float, int] = {}
for page in pages:
for block in page.text_blocks:
fs = round(block.font_size, 1)
if fs > 0:
char_len = len(block.text)
size_char_count[fs] = size_char_count.get(fs, 0) + char_len
if not size_char_count:
return {"body_size": 12.0, "heading_sizes": [], "size_rank_map": {}}
# 出现字符数最多的字号 → 正文字号
body_size = max(size_char_count, key=size_char_count.get)
# 至少比正文大 20% 才算标题字号
min_heading_size = body_size * 1.20
heading_sizes = sorted(
[fs for fs in size_char_count if fs >= min_heading_size],
reverse=True,
)
# 从大到小映射为 H1, H2, H3 ...
size_rank_map: Dict[float, int] = {}
for rank, fs in enumerate(heading_sizes):
level = min(rank + 1, 6)
size_rank_map[fs] = level
return {
"body_size": body_size,
"heading_sizes": heading_sizes,
"size_rank_map": size_rank_map,
}3.3 第三优先级:LR 确认 + 编号模式
有些标题的字号和正文完全一样(在中文学术论文中很常见),但 Foxit SDK 的 LR(Layout Recognition)模块识别出了它是标题。此时结合中文编号模式来确定层级:
python
if heading_level == 0 and is_lr_heading and len(text) < 80:
num_level = heading_level_from_numbering(text)
if num_level > 0:
heading_level = min(num_level, 6)编号模式的识别规则:
| 模式 | 示例 | 映射层级 |
|---|---|---|
第X章 |
第三章 研究方法 | H1 |
N.M |
3.2 研究设计 | H2(按小数点深度) |
N.M.K |
3.2.1 变量定义 | H3 |
(N) |
(一)研究背景 | H4 |
注意这里有一个重要的文本长度守卫条件 len(text) < 80------超过 80 字符的文本即使 LR 说它是标题也不采信。因为 LR 模块有时会把整段正文误分类为"标题"(后面踩坑实录会详细说)。
3.4 第四优先级:粗体 + 编号模式兜底
如果前三级都没命中,但文本是粗体、长度较短(< 60 字符)、且匹配了编号模式,也升级为标题:
python
if heading_level == 0 and len(text) < 60:
num_level = heading_level_from_numbering(text)
if num_level > 0 and block.is_bold:
heading_level = min(num_level, 6)这是最后的兜底------只有同时满足粗体+编号+短文本三个条件才会触发,误判概率极低。
四级级联完整代码
上面分别讲了每一级的逻辑,下面是它们在 _convert_page() 中实际组合在一起的样子------一个清晰的 if-elif 链条:
python
# ---- md_converter.py: _convert_page() 核心片段 ----
# --- Heading detection (priority cascade) ---
heading_level = 0
# 1) 书签匹配(最可靠)
for (bm_page, bm_title), bm_level in bm_heading_map.items():
if bm_page == page.page_index:
if bm_title and (
bm_title in text or text in bm_title or
_normalize(bm_title) == _normalize(text)
):
heading_level = bm_level
break
# 2) 字号排名
if heading_level == 0:
heading_level = _heading_level_from_font(
block.font_size, block.is_bold, font_stats, text
)
# 3) LR 确认 + 编号模式
if heading_level == 0 and is_lr_heading and len(text) < 80:
num_level = _heading_level_from_numbering(text)
if num_level > 0:
heading_level = min(num_level, 6)
else:
max_rank = max(
font_stats.get("size_rank_map", {}).values(), default=0
)
heading_level = min(max_rank + 1, 6)
# 4) 粗体 + 编号模式兜底
if heading_level == 0 and len(text) < 60:
num_level = _heading_level_from_numbering(text)
if num_level > 0 and block.is_bold:
heading_level = min(num_level, 6)
# --- 输出 ---
if heading_level > 0:
prefix = "#" * heading_level
items.append((y_pos, "heading", f"{prefix} {md_text}", blk_bbox))
else:
items.append((y_pos, "body", md_text, blk_bbox))可以看到,四级之间完全是串行的"未命中就降级"关系。每一级的守卫条件(len(text) < 80、block.is_bold)确保误判不会向下传播。
四、核心算法 2:段落智能合并
这可能是整个项目中最令人头疼的部分。
问题本质
PDF 内部的文字存储方式和我们看到的"段落"完全是两回事。一个段落可能被 PDF 排版引擎拆成十几个独立的文本对象,每个对象就是一行。当你逐字符提取时,换行位置是排版引擎决定的,跟逻辑段落边界毫无关系。
如果简单地每个 TextBlock 单独成段,输出就是一行一行的碎片。
多层合并策略
以下段落合并流程图展示三层合并的判断逻辑:
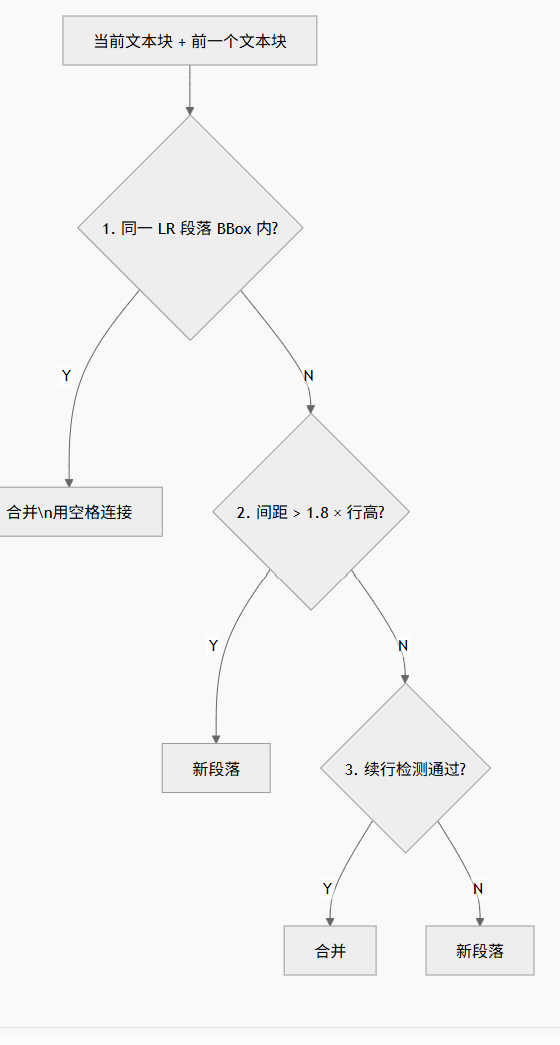
第一层:LR 段落分组(最优先)
SDK 的 LR 模块不仅能识别标题和表格,还能识别段落的边界框。如果两个相邻的文本块都落在同一个 LR 段落的边界框内,那它们就是同一个段落,直接合并:
python
cur_lr_idx = find_lr_paragraph(bbox)
if cur_lr_idx >= 0 and cur_lr_idx == prev_lr_idx:
# 同一个 LR 段落 → 合并
para_parts.append(text)这是最准确的信号------LR 模块做了专业的版面分析,它说这些文本属于同一段落,大概率是对的。
第二层:几何间距启发式
当 LR 数据不可用时,通过行间距判断:
- 间距 > 行高 × 1.8 → 大概率是新段落,输出段落分隔
- 间距在正常范围内 → 进入第三层续行检测
这里有一个"body_size 校验"细节很重要:某些 PDF 的 SDK 返回的 font_size 是非标准单位(比如 240 代表 12pt),如果直接拿来算行高会导致阈值荒谬地大。我做了一个兜底:
python
avg_block_h = sum(block_heights) / len(block_heights)
if body_size > avg_block_h * 3:
body_size = avg_block_h # 回退到平均块高度第三层:续行检测兜底
对于间距接近但不确定的情况,通过多个信号综合判断是否是续行:
python
def _looks_wrapped_continuation(prev_bbox, cur_bbox, prev_text, cur_text, gap):
# 1. 左边距是否对齐(偏差 < 1.2 倍字号)
if abs(cur_left - prev_left) > max(body_size * 1.2, 10.0):
return False
# 2. 是否在同一列(排除双栏布局的误合并)
if abs(cur_center - prev_center) > page_width * 0.35:
return False
# 3. 当前行以列表编号开头?→ 不合并
if list_start_re.match(cur_text):
return False
# 4. 前一行以句末标点结尾且非全宽行?→ 新段落
if prev_text.endswith(("。", "!", "?", ".", "!")):
if not is_full_width_line(prev_bbox):
return False
return True # 通过所有检查 → 合并这里第 4 点很精巧:只有当前一行以句末标点结尾 AND 行宽没有占满整行时,才判定为段落结束。因为如果前一行以句号结尾但占满了整行,很可能只是段落中间的一句话恰好在行尾结束,后面还有内容。
后处理层:假空行清理
最后还有一个全局后处理,扫描输出的 Markdown,清理段内假空行:
python
def _collapse_spurious_blank_lines(md_text):
# 如果前行不以 。!?.!? 结尾
# 且后行以中文/英文/数字开头
# 且两行之间有空行
# → 该空行是多余的,移除五、核心算法 3:页眉页脚过滤
PDF 的每一页都可能有重复的页眉页脚。不过滤的话,每隔几段就蹦出一行"第 X 页"。
频率统计策略
python
def _detect_header_footer_texts(pages, margin_ratio=0.10, min_repeat=3):
for page in pages:
# 取页面上下各 10% 区域的文本块
top_threshold = page.height * (1.0 - margin_ratio) # PDF 坐标:0=底部
bottom_threshold = page.height * margin_ratio
for block in page.text_blocks:
y_centre = (block.bbox[1] + block.bbox[3]) / 2.0
if y_centre >= top_threshold or y_centre <= bottom_threshold:
# 归一化文本后统计出现频率
text_page_count[normalize(block.text)] += 1
# 出现 ≥ 3 次的文本 → 页眉或页脚
hf_texts = {t for t, c in text_page_count.items() if c >= min_repeat}页码的特殊处理
页码每页都变("第1页"、"第2页"......),不能用重复文本检测。但页码的位置是固定的。我按位置分桶(10pt 精度),如果同一位置桶出现在大多数页面,则该位置的纯数字文本全部标记为页码:
python
# 页码位置分桶
zone = "top" if in_top else "bottom"
x_bucket = round(block.bbox[0] / 10.0) * 10
page_num_position_counts[(zone, x_bucket)] += 1
# 如果某个位置桶出现次数 >= 50% 页数
if count >= max(min_repeat, page_count * 0.5):
hf_texts.add(f"__PAGE_NUM__{zone}_{x_bucket}")📷 【图 5:页面区域划分示意】 示意图:一个 PDF 页面,上下各用蓝色虚线框标出 10% 的页眉/页脚检测区域。页眉区域标注"频率统计:重复文本 → 过滤",页脚区域标注"位置分桶:固定位置的数字 → 过滤"。
六、表格处理:从 LR 检测到管道表格渲染
LR 表格提取流程
Foxit SDK 的 LR 模块输出一棵结构化元素树,表格部分的层次和 HTML 类似:
Table
├── THead (表头组)
│ └── TR (行)
│ ├── TH (表头单元格)
│ └── TH
├── TBody (表体组)
│ ├── TR
│ │ ├── TD (数据单元格)
│ │ └── TD
│ └── TR
│ ├── TD
│ └── TD
└── TFoot (表footer组)遍历这棵树,对每个单元格通过 GetBBox() 获取边界框,然后用 TextPage 提取该区域的文字。合并单元格的信息通过 ColSpan / RowSpan 属性读取。
Markdown 管道表格渲染
提取到的表格数据需要渲染为 Markdown 的管道表格。主要的复杂度在于处理合并单元格:
python
# 构建 grid[行][列] 二维数组
for cell in row:
# ColSpan:文本放第一列,后续列留空
for c in range(colspan):
grid[ri][cursor + c] = text if c == 0 else ""
# RowSpan:后续行对应列标记"已占用"
for r in range(1, rowspan):
occupied[ri + r][cursor + c] = True
# 渲染为 Markdown
"| " + " | ".join(grid_row) + " |"Markdown 本身不支持 RowSpan,我的处理方式是后续行的被合并列留空------这在 GitHub Flavored Markdown 下渲染效果尚可。
七、踩坑实录 1:伪表格------长标题被误判为表格
这是项目开发中最有意思的一个问题。
现象
一份 170 多页的项目申报报告中,标题"3.2 企业自身发展、管理等创新点及对项目建设的推进作用"被输出成了一个表格,而不是标题。
排查
通过日志发现,LR 模块将这个标题检测为了一个 1 行 2 列的表格。根因是这个标题太长,在 PDF 中换行了:
3.2 企业自身发展、管理等创新点及对项目建设的推进作用
用LR 看到两行左不对齐的文字块,将它们判定为表格行的两个单元格。
更隐蔽的是文本顺序问题------如果简单拼接两个单元格文本,得到的是"3.2 用 企业自身发展...推进作",因为那个换行位置的"用"字在 PDF 中恰好落在了第一列区域内。
三步修复
第 1 步:伪表格检测。 完整的 _is_false_table() 函数包含三条检测路径------空行/参考文献模式、全参考文献判定、以及单行伪标题判定:
python
# ---- pdf_parser.py: _is_false_table() 核心逻辑 ----
def _is_false_table(rows: List[List[TableCell]]) -> bool:
if not rows:
return True
empty_rows = 0
bib_rows = 0
non_empty_rows = 0
for row in rows:
row_text = " ".join(c.text.strip() for c in row).strip()
if not row_text:
empty_rows += 1
continue
non_empty_rows += 1
if _RE_BIB_NUM.match(row_text): # 匹配 [1], [23] 等参考文献编号
bib_rows += 1
# 路径 1: 多数行为空 + 非空行多为参考文献 → 假表格
if non_empty_rows > 0 and bib_rows / non_empty_rows >= 0.5 \
and empty_rows >= non_empty_rows:
return True
# 路径 2: 全部非空行都是参考文献 → 假表格
if non_empty_rows > 0 and bib_rows == non_empty_rows:
return True
# 路径 3: 单行少列 + 合并文本匹配章节编号 → 伪表格(换行标题)
max_cols = max(len(row) for row in rows) if rows else 0
if non_empty_rows <= 1 and max_cols <= 3:
all_text = re.sub(
r"\s+", " ",
" ".join(c.text.strip() for row in rows for c in row),
).strip()
if _RE_SECTION_HEADING.match(all_text):
return True
return False第 2 步:正确的文本提取。 不用单元格文本拼接,而是在整个表格 BBox 范围内用 TextPage 按字符顺序提取------这样字符顺序和原文一致。
第 3 步:CJK 空格修复。 换行位置可能产生多余空格(如"推进作 用"),对中文字符间的空白做规范化:
python
all_text = re.sub(r"(?<=[\u4e00-\u9fff])\s+(?=[\u4e00-\u9fff])", "", all_text)八、踩坑实录 2:LR 漏检表格------无边框表格完全未识别
现象
一份学术论文中,"有一张表是一个 3 列 6 行的表格,但 LR 模块完全没有识别它。表格内容散落成一堆 ###### 小标题和零散文本。
根因
这个表格在 PDF 中没有可见边框线,文字字号比正文还小。LR 模块把其中的短文本误分类为 heading 而非 table cell。
启发式重建
我写了一个约 400 行的 _reconstruct_missed_tables() 函数作为后备:
| 步骤 | 做法 |
|---|---|
| 1. 定位表格 | 用正则 ^表\s*\d+[\------..]\d+\s 扫描文本块,找到表格标题 |
| 2. 收集候选 | 标题下方、同字号的文本块作为候选 |
| 3. 列网格检测 | 对候选块的 x 坐标聚类(间距 ≤15 合并),确定列边界 |
| 4. 跨列块拆分 | 用正则拆分横跨多列的文本块(如"Puhakka(2006) 机会识别..."→ 两部分) |
| 5. 自适应行分组 | 对每列内的 y 间距排序,找最大跳变点作为行分组阈值 |
| 6. 锚列行对齐 | 选最右列为锚列(描述列间距最明显),其他列通过 y 重叠映射到锚列行 |
| 7. 结果验证 | 要求 ≥2 行、≥2 列、≥2 行有多列内容 |
更深层的问题:行数不对
重建后的表格是 2 行而不是 4 行------_group_cells() 的自适应间距阈值将 4 个标签合并为 2 组。
修复方案是引入 LR heading 锚点:用 LR heading 的 y 坐标作为行的锚点,通过"句末感知打分"拆分描述列。以下是实际的打分和分割逻辑:
python
# ---- pdf_parser.py: heading-based 行分割(_reconstruct_missed_tables 内部)----
_RE_SENT_END = re.compile(r'[。!?)\]】」』][。\s]*$')
# gap_info: [(间隙中点y, 实际间隙, entry_index), ...]
# h_mids: 相邻 heading 中心点的中值线(分割参考线)
for hm in h_mids: # 对每个 heading 边界
best_ei = None
best_score = float("-inf")
for gm, ag, ei in gap_info: # 遍历所有可能的分割点
if ei in used:
continue
dist = abs(gm - hm)
if dist > max(80, med_gap * 6): # 距离太远的不考虑
continue
score = -dist # 越近越好
if _RE_SENT_END.search(entries[ei][1]):
score += 30 # 以句号结尾 → 加分
if ag > med_gap * 1.5:
score += 20 # 间距大于中位数 → 加分
if score > best_score:
best_score = score
best_ei = ei
if best_ei is not None:
splits.append(best_ei)
used.add(best_ei)
splits.sort()
# 按 splits 位置将 entries 分组,每组对应表格一行打分公式的核心思想是:优先选择"前一行以句号结尾"且"间距较大"的位置------这正是行边界最自然的位置。
同时加入触发条件:只有当 heading 数 > gap-based 行数 且 gap-based 行数 ≤ 3 且 最长 cell ≥ 80 字符时才启用这个修复。这样已经正确重建的表格不受影响。
九、踩坑实录 3:LR 把整页正文误判为标题
现象
某份论文 PDF 的正文段落内出现大量 \r 字符,段落被打碎。
根因(三个问题叠加)
- LR 误分类 :LR 模块把整页正文误判为一个"标题",合并文本用
\r分隔。代码直接使用了这个文本,\r泄漏到输出中。 - font_size 异常 :SDK 返回
font_size=240(实际约 12pt),导致几何阈值全部偏大。 - 行宽阈值过严 :用
page_width * 0.78判断全宽行,但实际文本只占 71% 页宽。
多管齐下修复
| 修复 | 做法 |
|---|---|
| LR heading 守卫 | 当 LR heading 合并文本 ≥ 120 字符时,判定为误分类的正文段落,不使用合并文本 |
| body_size 校验 | 计算 body block 平均高度,若 body_size > avg_height × 3 则回退 |
| 有效页宽 | 取所有 body block 最大宽度作为有效页宽(而非整个页面宽度) |
| 句末标点 | 以句末标点结尾的非全宽行判定为段落结束 |
每一个修复都很小,但叠加在一起才能解决问题。这就是为什么需要"多信号融合"的策略------单一信号源永远不够可靠。
十、总结:多信号融合 + 后验校正
做了这个项目的一个核心体会是:PDF 转 Markdown 不是文本提取问题,而是文档结构理解问题。 文字可以轻松拿到,但"这段文字是什么角色"------是标题、是正文、是表格里的内容、还是页脚的页码------这个判断才是真正困难的。
设计原则总结为两个关键词:
1. 多信号融合------不依赖单一信号源。标题检测用了书签、字号、LR、编号模式四路;段落合并用了 LR 段落、几何间距、续行检测、后处理清理四层。
2. 后验校正------对 SDK 的输出做质量检验。伪表格检测校验了"这个表格真的是表格吗";LR 漏检后备处理了"LR 没检测到但实际上存在的表格";120 字符守卫处理了"LR 说是标题但实际上是正文"。
下一篇文章将聚焦 Foxit PDF SDK 本身------逐字符提取 API 怎么用、LR 模块怎么初始化和遍历、SDK 11.0 有哪些坑。如果你打算用 Foxit SDK 做类似的 PDF 处理工具,那篇会是一个实用的速查指南。
技术栈:Python 3.10 + Foxit PDF SDK 11.x + FastAPI + Jinja2
*本文为 PDF 转 Markdown 系列第 2 篇,第 1 篇【pdf2md-1:开篇】高保真PDF转MarkDown附源码(标题/表格/图片全还原))