摘要 :本文在 Decoder Only Transformer 与 LLaMA 架构 的基础上,按数据流顺序 介绍 Qwen 1(QWEN) 各模块:Tokenization、Embedding、位置编码(RoPE)、单层 Decoder 内的 RMSNorm、掩码多头自注意力、SwiGLU 前馈网络及输出层,并给出关键矩阵形状与公式推导 。文中用三方对照 突出 Qwen 与「经典 Decoder-only(Post-Norm + 绝对位置 + ReLU FFN)」、**LLaMA(Pre-Norm + RoPE + SwiGLU + 典型 4 d 4d 4d 中间维)**的差异;最后简述 Qwen 1.5 与 推理期长上下文 技术。读者可将本文视为 LLaMA 篇的「平行章节」,公式记号与 LLaMA 架构 博文保持一致。
关键词:Qwen;Qwen1.5;Decoder-only;RMSNorm;Pre-Norm;SwiGLU;RoPE;Flash Attention;NTK-aware;GQA;大语言模型
同系列博文(便于串联阅读):
- Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算
- Transformer 11. Encoder-Decoder Transformer 经典架构以及每一步骤的详细计算
- Transformer 12. LLaMA 架构介绍以及与 Transformer 架构对比。
💡 理解要点 :可以把 Qwen 1 想成「LLaMA 同款骨架 (Decoder-only、Pre-Norm、RMSNorm、RoPE、SwiGLU)+ 几处论文里写明的改法 」:更大词表 、输入嵌入与输出投影不绑权 、QKV 线性层保留 bias 、FFN 中间宽度用 8 3 d \frac{8}{3}d 38d 而不是常见的 4 d 4d 4d ,以及报告重点写的推理期长文扩展 。标准 Transformer Decoder (见 LLaMA 架构)则是另一套「LayerNorm 顺序 + 在词嵌入上加位置向量 + ReLU FFN」的经典图画------三者的差别,下文用表格和公式一起钉死。
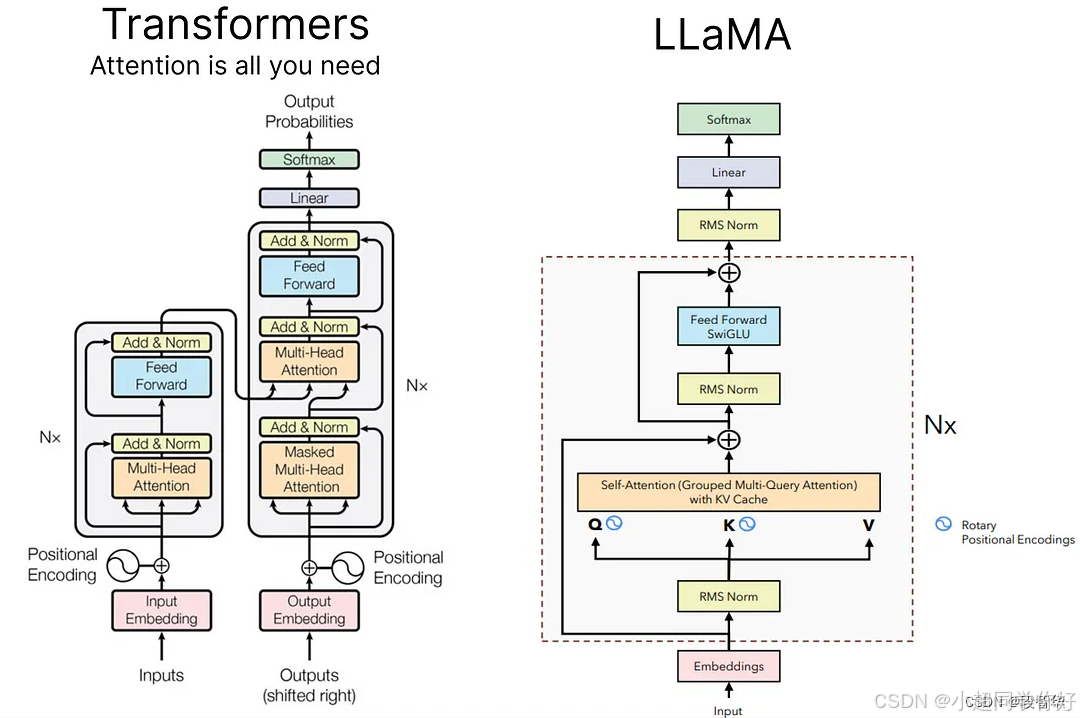
1. 概述:Qwen 在 Transformer 家族中的位置
Qwen Technical Report(arXiv:2309.16609) 将 QWEN 描述为在 LLaMA 开源路线上的改进型 Decoder-only 模型:只有带因果掩码的多头自注意力 和前馈网络 ,没有 Encoder、没有交叉注意力;训练目标是「看前文、预测下一个 token」,与 Decoder Only Transformer 一致。
单层 Qwen Decoder 的流程与 LLaMA 同型:
RMSNorm → 掩码自注意力(RoPE + 可选 QKV bias)→ 残差 → RMSNorm → SwiGLU FFN → 残差。
🔍 实际例子(Qwen-7B,报告表 1) : d model = 4096 d_{\text{model}}=4096 dmodel=4096,层数 N = 32 N=32 N=32,头数 h = 32 h=32 h=32。若当前序列长度 L = 2048 L=2048 L=2048,则每一层 的输入、输出张量形状都是 2048 × 4096 2048 \times 4096 2048×4096 ;最后一层取最后一个位置 的向量 h ∈ R 4096 \mathbf{h}\in\mathbb{R}^{4096} h∈R4096,乘以 W out ∈ R 4096 × V W_{\text{out}}\in\mathbb{R}^{4096\times V} Wout∈R4096×V ( V V V 为词表大小)得到 logits,再 Softmax 得到下一 token 分布。
下文先讲数据如何进入第一层 ,再展开单层内每一步的数学与形状 ,最后做三方架构对比 与 Qwen 1.5 / 长上下文 补充。
2. 从输入到 Decoder:数据如何进入
模型不吃原始字符串,只吃 Token ID 序列 ;先 Tokenization ,再 Embedding ;位置信息 由 RoPE 在注意力里注入,不像经典 Transformer 那样在输入端「词向量 + 位置向量」。
2.1 Tokenization:从文本到 Token 序列
直觉 :Tokenization 像把一句话切成一块块「乐高」,每块对应词表里一个 token ,计算机里变成一个整数 ID。
矩阵视角 :长度为 L L L 的 ID 序列 ( w 0 , ... , w L − 1 ) (w_0,\ldots,w_{L-1}) (w0,...,wL−1),后面通过 Embedding 变成矩阵 X ∈ R L × d model X\in\mathbb{R}^{L\times d_{\text{model}}} X∈RL×dmodel ,第 i i i 行是第 i i i 个位置的向量。这里的 d model d_{\text{model}} dmodel 即模型隐层维度 (与 Qwen / LLaMA 配置表中的 Hidden size 同义):每个 token 的嵌入向量有多少维,整网中间张量的「宽度」就是多少(例如 Qwen-7B 中 d model = 4096 d_{\text{model}}=4096 dmodel=4096)。
Qwen 1 的做法 来源:Qwen Technical Report §2.2:
- 算法:BPE ;起点为 tiktoken 的 cl100k_base。
- 为中文等多语:扩充常用字词与其它语言符号。
- 数字 :按 LLaMA 系列习惯拆成逐位 token,便于算术与代码。
- 词表规模约 V ≈ 152 K V\approx 152\text{K} V≈152K。
💡 理解要点 :词表大 → 同样一句话往往更少的 token 数 (压缩率高),推理按 token 计费时更省;但 Embedding / 输出层 参数随 V V V 线性变大,是显存大户之一。
2.2 Embedding:从 Token ID 到向量
嵌入矩阵 (词表大小 V V V):
E ∈ R V × d model . E \in \mathbb{R}^{V \times d_{\text{model}}}. E∈RV×dmodel.
记号 :将 E E E 的第 w w w 行 (长度为 d model d_{\text{model}} dmodel 的行向量)转置为列向量 ,记为 e w \mathbf{e}_w ew,则
e w = E w , : ⊤ ∈ R d model . \mathbf{e}w = Ew,\\,:^\top \in \mathbb{R}^{d{\text{model}}}. ew=Ew,:⊤∈Rdmodel.
第 i i i 个位置的 token ID 为 w i w_i wi 时, Embedding ( w i ) = e w i \text{Embedding}(w_i)=\mathbf{e}_{w_i} Embedding(wi)=ewi(与「直接用行向量 E w i Ew_i Ewi」等价;下文统一用列向量,避免行/列混写)。
L L L 个位置按行堆叠成送入第一层 Decoder 的矩阵:
X = e w 0 ⊤ ⋮ e w L − 1 ⊤ ∈ R L × d model . X = \begin{bmatrix} \mathbf{e}{w_0}^\top \\ \vdots \\ \mathbf{e}{w_{L-1}}^\top \end{bmatrix} \in \mathbb{R}^{L \times d_{\text{model}}}. X= ew0⊤⋮ewL−1⊤ ∈RL×dmodel.
绑权(weight tying)是什么,Qwen 1 为何用 untied
输出端 (预测下一 token):取最后一层输出 H ∈ R L × d model H\in\mathbb{R}^{L\times d_{\text{model}}} H∈RL×dmodel 的最后一个位置 ,得列向量 h ∈ R d model \mathbf{h}\in\mathbb{R}^{d_{\text{model}}} h∈Rdmodel( h \mathbf{h} h 的正式定义与 logits 公式见 §5 )。要把 h \mathbf{h} h 映射到词表上 V V V 个 logits,未绑权(untied) 时单独有可学习矩阵 W out ∈ R d model × V W_{\text{out}}\in\mathbb{R}^{d_{\text{model}}\times V} Wout∈Rdmodel×V 与可选 b out ∈ R V \mathbf{b}_{\text{out}}\in\mathbb{R}^V bout∈RV。
绑权(tied embedding):令
W out = E ⊤ , W_{\text{out}} = E^\top, Wout=E⊤,
即 输出线性层与嵌入矩阵共用参数 ,不再单独存放 W out W_{\text{out}} Wout。此时第 w w w 个 logit 为
s w = h ⊤ e w + ( b out ) w , s_w = \mathbf{h}^\top \mathbf{e}w + (b{\text{out}})_w, sw=h⊤ew+(bout)w,
也就是 当前上下文表示 h \mathbf{h} h 与 该词嵌入 e w \mathbf{e}_w ew 的内积 (再加偏置);输入端「词 w w w → 向量」与输出端「向量 → 词 w w w 的分数」在词表维上共用同一组 V V V 个 d model d_{\text{model}} dmodel 维方向。
💡 理解要点 :绑权可省约一整块 d model × V d_{\text{model}}\times V dmodel×V 的输出权重(参数量与显存上,相对「 E E E 与 W out W_{\text{out}} Wout 各一份」常从约 2 份系数降到 1 份);实证上 Press & Wolf (2017) 等表明 tying 常有利于困惑度。许多模型(含部分 LLaMA 实现)采用 tied ;Qwen 1 在报告中明确采用 untied 来源:Qwen Technical Report §2.3:单独 维护 W out W_{\text{out}} Wout(及可选 bias),不 强制 W out = E ⊤ W_{\text{out}}=E^\top Wout=E⊤,以换更大表达自由度;代价是词表维 V V V 已很大时,Embedding + 输出层 合计更显存敏感。
数值示例(Qwen-7B) : L = 2048 L=2048 L=2048, d model = 4096 d_{\text{model}}=4096 dmodel=4096 → Embedding 输出 2048 × 4096 2048\times 4096 2048×4096。
2.3 位置编码:经典 Transformer、LLaMA 与 Qwen
2.3.1 经典 Decoder-only(见 Decoder Only Transformer 博文)
- 时机 :Embedding 之后、进第一层之前 ,只做一次。
- 形式 :每个位置 p o s pos pos 一个向量 P E ( p o s ) ∈ R d model \mathrm{PE}(pos)\in\mathbb{R}^{d_{\text{model}}} PE(pos)∈Rdmodel(正弦/余弦或可学习),与词嵌入相加:
I n p u t p o s = E m b e d p o s + P E ( p o s ) . \mathrm{Input}pos = \mathrm{Embed}pos + \mathrm{PE}(pos). Inputpos=Embedpos+PE(pos).
正弦版本常用:
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d model ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d model ) . PE_{(pos, 2i)} = \sin\Big(\frac{pos}{10000^{2i/d_{\text{model}}}}\Big), \quad PE_{(pos, 2i+1)} = \cos\Big(\frac{pos}{10000^{2i/d_{\text{model}}}}\Big). PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos).
2.3.2 LLaMA 与 Qwen 的 RoPE:在注意力里转 Q、K
共同点 :不在 X X X 上加位置向量;在每一层 、算注意力分数 之前 ,对当前层的 Query、Key (按位置、按维度对)做 旋转 。记第 p o s pos pos 行经旋转后的向量为 Q ′ p o s , K ′ p o s Q'pos, K'pos Q′pos,K′pos,则仍算:
S i j = Q ′ i ⋅ K ′ j d k . S_{ij} = \frac{Q'i \cdot K'j}{\sqrt{d_k}}. Sij=dk Q′i⋅K′j.
RoPE 的设计使得 S i j S_{ij} Sij 能体现 i i i 与 j j j 的相对位置 (如依赖 i − j i-j i−j),对外推更长序列 往往比「只在输入加一次绝对 PE」更友好。详见 LLaMA 架构 §2.3。
Qwen 相对 LLaMA 的实现注记 来源:Qwen Technical Report §2.3:RoPE 里与频率相关的缓冲(inverse frequency)用 FP32 存,减轻低精度下的数值误差;不改变 Q , K Q,K Q,K 的形状,仍是 L × d k L\times d_k L×dk。
2.3.3 对比小结(三列)
| 维度 | 经典 Decoder-only | LLaMA | Qwen 1 |
|---|---|---|---|
| 注入时机 | 进网络前 一次 | 每层注意力内 | 同 LLaMA |
| 注入对象 | 与 Embedding 相加 | 只旋 Q、K | 同 LLaMA |
| 位置类型 | 偏 绝对 位置向量 | 相对 关系进 Q K ⊤ QK^\top QK⊤ | 同 LLaMA |
| 进入第一层的 X X X | Emb + PE \text{Emb}+\text{PE} Emb+PE | 仅 Emb \text{Emb} Emb | 仅 Emb \text{Emb} Emb |
| 额外实现细节 | --- | 依实现而定 | RoPE 频率表倾向 FP32 |
2.4 小结:进入第一层 Decoder 的矩阵
- Tokenization :文本 → 长度 L L L 的整数 ID。
- Embedding : E ∈ R V × d model E\in\mathbb{R}^{V\times d_{\text{model}}} E∈RV×dmodel → X ∈ R L × d model X\in\mathbb{R}^{L\times d_{\text{model}}} X∈RL×dmodel。
- 位置 :无 I n p u t = E m b + P E \mathrm{Input}=\mathrm{Emb}+\mathrm{PE} Input=Emb+PE;RoPE 在 §3.2 的注意力里处理。
3. Qwen Decoder 单层:每一步的矩阵计算与推导
单层由两个子层组成,均为 Pre-Norm + 子层 + 残差:
- RMSNorm → 掩码多头自注意力 → Add
- RMSNorm → SwiGLU FFN → Add
设本层输入为 X in ∈ R L × d model X_{\text{in}}\in\mathbb{R}^{L\times d_{\text{model}}} Xin∈RL×dmodel。
3.1 RMSNorm(Root Mean Square Layer Normalization)
作用 :对每一行 (每个 token 位置的 d model d_{\text{model}} dmodel 维向量)做缩放归一化 ,不减去均值------比 LayerNorm 少算均值、少一组 shift 参数,计算更省。
对 x ∈ R d model \mathbf{x}\in\mathbb{R}^{d_{\text{model}}} x∈Rdmodel( X X X 的一行),先算均方根尺度:
R M S ( x ) = ε + 1 d model ∑ j = 1 d model x j 2 , \mathrm{RMS}(\mathbf{x}) = \sqrt{\varepsilon + \frac{1}{d_{\text{model}}}\sum_{j=1}^{d_{\text{model}}} x_j^2}, RMS(x)=ε+dmodel1j=1∑dmodelxj2 ,
再归一化并乘可学习缩放 γ ∈ R d model \boldsymbol{\gamma}\in\mathbb{R}^{d_{\text{model}}} γ∈Rdmodel:
R M S N o r m ( x ) = x R M S ( x ) ⊙ γ . \mathrm{RMSNorm}(\mathbf{x}) = \frac{\mathbf{x}}{\mathrm{RMS}(\mathbf{x})} \odot \boldsymbol{\gamma}. RMSNorm(x)=RMS(x)x⊙γ.
形状 :输入 X X X,输出逐行 RMSNorm,仍为 L × d model L\times d_{\text{model}} L×dmodel。
💡 与标准 Transformer 的对比 :Post-Norm 的 LayerNorm 是「先子层、加残差、再 LN」且含 减均值、除方差、 β \boldsymbol{\beta} β 平移 」。Qwen 与 LLaMA 一样选 Pre-Norm + RMSNorm ,训练深层更稳、式子更短------细节对照见 LLaMA 架构 §3.1。
3.2 带掩码的多头自注意力(含 RoPE 与 Qwen 的 QKV bias)
本子层输入为 X ~ 1 = R M S N o r m ( X in ) \tilde{X}1=\mathrm{RMSNorm}(X{\text{in}}) X~1=RMSNorm(Xin)。为简洁,下面用 X X X 表示 X ~ 1 \tilde{X}_1 X~1。
约定 :头数 h h h, d k = d model / h d_k = d_{\text{model}}/h dk=dmodel/h。Qwen-7B: d model = 4096 d_{\text{model}}=4096 dmodel=4096, h = 32 h=32 h=32 → d k = 128 d_k=128 dk=128。
3.2.1 线性投影得到 Q、K、V(含 Qwen 的 bias)
第 t t t 个头( t = 1 , ... , h t=1,\ldots,h t=1,...,h):
Q ( t ) = X W Q ( t ) + 1 L ( b Q ( t ) ) ⊤ , K ( t ) = X W K ( t ) + 1 L ( b K ( t ) ) ⊤ , V ( t ) = X W V ( t ) + 1 L ( b V ( t ) ) ⊤ , Q^{(t)} = X W_Q^{(t)} + \mathbf{1}_L (b_Q^{(t)})^\top, \quad K^{(t)} = X W_K^{(t)} + \mathbf{1}_L (b_K^{(t)})^\top, \quad V^{(t)} = X W_V^{(t)} + \mathbf{1}_L (b_V^{(t)})^\top, Q(t)=XWQ(t)+1L(bQ(t))⊤,K(t)=XWK(t)+1L(bK(t))⊤,V(t)=XWV(t)+1L(bV(t))⊤,
其中 W Q ( t ) , W K ( t ) , W V ( t ) ∈ R d model × d k W_Q^{(t)},W_K^{(t)},W_V^{(t)}\in\mathbb{R}^{d_{\text{model}}\times d_k} WQ(t),WK(t),WV(t)∈Rdmodel×dk,bias 为 d k d_k dk 维, 1 L \mathbf{1}_L 1L 为全 1 列向量,使得 bias 按位置广播。
形状: Q ( t ) , K ( t ) , V ( t ) ∈ R L × d k Q^{(t)},K^{(t)},V^{(t)}\in\mathbb{R}^{L\times d_k} Q(t),K(t),V(t)∈RL×dk。
线性层里的 bias 是干什么的? 没有 bias 时, q = W ⊤ x q = W^\top x q=W⊤x 是过原点的超平面 ;加上 bias 相当于 q = W ⊤ x + b q = W^\top x + b q=W⊤x+b,给每个维度一个与输入无关的平移 。在注意力里,它会在 Q K ⊤ QK^\top QK⊤ 形成的 logits 上整体改变「各键方向相对谁更容易被 attend」,相当于多了一类可学习的基线偏移。
为什么 Qwen 1 专门保留 QKV 的 bias? 报告写明:其余多数层去掉 bias (沿袭 PaLM 等做法),但 在注意力的 QKV 线性层上保留 bias ,动机是增强长度外推 等与 RoPE 相关的行为,并引用 Su (2023b) 的讨论 来源:Qwen Technical Report §2.3。直观上:RoPE 主要约束 Q , K Q,K Q,K 的几何关系;bias 给 logits 留出一部分不随内容旋转而完全确定的自由度,实践中有时能缓和「训练长度 → 更长推理」时的分布偏移(是否有效依实现与规模而定,以论文与后续工作为准)。
小结 :LLaMA ≈ 无 QKV bias ;Qwen 1 = 有 QKV bias(其余层仍多无 bias),这是二者在注意力上的显式工程差异之一。
3.2.2 RoPE 作用于 Q、K
对 Q ( t ) , K ( t ) Q^{(t)},K^{(t)} Q(t),K(t) 的每一行 (每个 p o s pos pos)在 d k d_k dk 维内做 RoPE 旋转,得到仍记为 Q ( t ) , K ( t ) Q^{(t)},K^{(t)} Q(t),K(t)(数值已变、形状不变)。
推导直觉(二维一对) :把 d k d_k dk 维看成 d k / 2 d_k/2 dk/2 个二维平面。对频率 ω \omega ω,位置 m m m 的旋转可写成 2 × 2 2\times 2 2×2 块乘在 ( q 2 i , q 2 i + 1 ) (q_{2i},q_{2i+1}) (q2i,q2i+1) 上;两个位置 m , n m,n m,n 的内积会带上 ( m − n ) ω (m-n)\omega (m−n)ω 的相位差,从而让 注意力只依赖相对位置差(严格推导见 RoPE 原文 Su et al., 2021)。
3.2.3 注意力分数、因果掩码与 Softmax
未归一化分数矩阵(单头):
S ( t ) = Q ( t ) ( K ( t ) ) ⊤ d k ∈ R L × L . S^{(t)} = \frac{Q^{(t)} (K^{(t)})^\top}{\sqrt{d_k}} \in \mathbb{R}^{L\times L}. S(t)=dk Q(t)(K(t))⊤∈RL×L.
因果(自回归)掩码 :不允许位置 i i i 看见 j > i j>i j>i。令 M i j = 0 M_{ij}=0 Mij=0 若 j ≤ i j\le i j≤i,否则 M i j = − ∞ M_{ij}=-\infty Mij=−∞(实现常用极大负数):
S ~ i j ( t ) = S i j ( t ) + M i j . \tilde{S}^{(t)}{ij} = S^{(t)}{ij} + M_{ij}. S~ij(t)=Sij(t)+Mij.
对每一行 i i i 做 softmax(只在 j ≤ i j\le i j≤i 处非零):
A i j ( t ) = exp ( S ~ i j ( t ) ) ∑ k = 1 L exp ( S ~ i k ( t ) ) . A^{(t)}{ij} = \frac{\exp(\tilde{S}^{(t)}{ij})}{\sum_{k=1}^{L}\exp(\tilde{S}^{(t)}_{ik})}. Aij(t)=∑k=1Lexp(S~ik(t))exp(S~ij(t)).
输出(矩阵形式):
h e a d ( t ) = A ( t ) V ( t ) ∈ R L × d k . \mathrm{head}^{(t)} = A^{(t)} V^{(t)} \in \mathbb{R}^{L\times d_k}. head(t)=A(t)V(t)∈RL×dk.
这就是「缩放点积注意力 + 因果掩码 」的完整推导链:线性投影(+bias)→ RoPE → Q K ⊤ / d k QK^\top/\sqrt{d_k} QK⊤/dk → 加掩码 → softmax → 乘 V V V。
3.2.4 多头拼接与输出投影
C o n c a t = h e a d ( 1 ) ∥ ⋯ ∥ h e a d ( h ) ∈ R L × d model , \mathrm{Concat} = \big\\mathrm{head}\^{(1)} \\,\\\|\\, \\cdots \\,\\\|\\, \\mathrm{head}\^{(h)}\\big \in \mathbb{R}^{L\times d_{\text{model}}}, Concat=head(1)∥⋯∥head(h)∈RL×dmodel,
A t t n O u t = C o n c a t W O , W O ∈ R d model × d model . \mathrm{AttnOut} = \mathrm{Concat}\, W_O, \quad W_O\in\mathbb{R}^{d_{\text{model}}\times d_{\text{model}}}. AttnOut=ConcatWO,WO∈Rdmodel×dmodel.
3.2.5 残差
X mid = X in + A t t n O u t ∈ R L × d model . X_{\text{mid}} = X_{\text{in}} + \mathrm{AttnOut} \in \mathbb{R}^{L\times d_{\text{model}}}. Xmid=Xin+AttnOut∈RL×dmodel.
维度小结表
| 步骤 | 张量 | 形状 |
|---|---|---|
| RMSNorm 后 | X X X | L × d model L\times d_{\text{model}} L×dmodel |
| 每头 Q , K , V Q,K,V Q,K,V | Q ( t ) , K ( t ) , V ( t ) Q^{(t)},K^{(t)},V^{(t)} Q(t),K(t),V(t) | L × d k L\times d_k L×dk |
| logits | S ( t ) S^{(t)} S(t) | L × L L\times L L×L |
| 注意力权重 | A ( t ) A^{(t)} A(t) | L × L L\times L L×L |
| 每头输出 | h e a d ( t ) \mathrm{head}^{(t)} head(t) | L × d k L\times d_k L×dk |
| 多头输出 | A t t n O u t \mathrm{AttnOut} AttnOut | L × d model L\times d_{\text{model}} L×dmodel |
训练时可用 Flash Attention 在不显式物化完整 L × L L\times L L×L 的前提下等价完成上述计算 来源:Qwen Technical Report §2.4。
3.3 前馈网络:SwiGLU(Qwen 的 8 3 d \frac{8}{3}d 38d 中间维)
作用 :对每个位置独立做非线性变换,是模型表达力的主要来源之一。
形式 (与 LLaMA 同族,差在 d ff d_{\text{ff}} dff):
S w i G L U ( X ~ ) = ( σ swish ( X ~ W 1 ) ⊙ ( X ~ W 3 ) ) W 2 , \mathrm{SwiGLU}(\tilde{X}) = \big(\sigma_{\text{swish}}(\tilde{X} W_1) \odot (\tilde{X} W_3)\big) W_2, SwiGLU(X~)=(σswish(X~W1)⊙(X~W3))W2,
其中 σ swish ( z ) = z ⋅ σ ( z ) \sigma_{\text{swish}}(z)=z\cdot\sigma(z) σswish(z)=z⋅σ(z), ⊙ \odot ⊙ 为逐元素乘。
Qwen 与 LLaMA 的关键数字 来源:Qwen Technical Report §2.3:LLaMA 常用 d ff = 4 d model d_{\text{ff}} = 4 d_{\text{model}} dff=4dmodel ;Qwen 1 取 d ff = 8 3 d model d_{\text{ff}} = \frac{8}{3} d_{\text{model}} dff=38dmodel (实现常对齐为整数)。记 X ~ 2 = R M S N o r m ( X mid ) \tilde{X}2=\mathrm{RMSNorm}(X{\text{mid}}) X~2=RMSNorm(Xmid):
- Z 1 = X ~ 2 W 1 Z_1=\tilde{X}2 W_1 Z1=X~2W1, W 1 ∈ R d model × d ff W_1\in\mathbb{R}^{d{\text{model}}\times d_{\text{ff}}} W1∈Rdmodel×dff, Z 1 ∈ R L × d ff Z_1\in\mathbb{R}^{L\times d_{\text{ff}}} Z1∈RL×dff。
- Z 3 = X ~ 2 W 3 Z_3=\tilde{X}2 W_3 Z3=X~2W3, W 3 ∈ R d model × d ff W_3\in\mathbb{R}^{d{\text{model}}\times d_{\text{ff}}} W3∈Rdmodel×dff。
- Z = σ swish ( Z 1 ) ⊙ Z 3 Z=\sigma_{\text{swish}}(Z_1)\odot Z_3 Z=σswish(Z1)⊙Z3。
- F F N O u t = Z W 2 \mathrm{FFNOut}=Z W_2 FFNOut=ZW2, W 2 ∈ R d ff × d model W_2\in\mathbb{R}^{d_{\text{ff}}\times d_{\text{model}}} W2∈Rdff×dmodel。
- 残差 : X out = X mid + F F N O u t X_{\text{out}}=X_{\text{mid}}+\mathrm{FFNOut} Xout=Xmid+FFNOut。
💡 直觉 :SwiGLU 比单层 ReLU-FFN 多一路「门」;若中间维还用 4 d 4d 4d,参数量会很大。Qwen 把中间维缩到 8 3 d ≈ 2.67 d \frac{8}{3}d\approx 2.67d 38d≈2.67d ,相当于在「门控表达能力 」与「参数/显存」之间再折中一次。
3.4 单层 Qwen Decoder 的完整数据流(汇总)
- X ~ 1 = R M S N o r m ( X in ) \tilde{X}1=\mathrm{RMSNorm}(X{\text{in}}) X~1=RMSNorm(Xin)
- A t t n O u t = M a s k e d M u l t i H e a d ( X ~ 1 ) \mathrm{AttnOut}=\mathrm{MaskedMultiHead}(\tilde{X}_1) AttnOut=MaskedMultiHead(X~1)(内含 QKV bias、RoPE、掩码、 W O W_O WO)
- X mid = X in + A t t n O u t X_{\text{mid}}=X_{\text{in}}+\mathrm{AttnOut} Xmid=Xin+AttnOut
- X ~ 2 = R M S N o r m ( X mid ) \tilde{X}2=\mathrm{RMSNorm}(X{\text{mid}}) X~2=RMSNorm(Xmid)
- F F N O u t = S w i G L U ( X ~ 2 ) \mathrm{FFNOut}=\mathrm{SwiGLU}(\tilde{X}2) FFNOut=SwiGLU(X~2)( d ff = 8 3 d model d{\text{ff}}=\frac{8}{3}d_{\text{model}} dff=38dmodel)
- X out = X mid + F F N O u t X_{\text{out}}=X_{\text{mid}}+\mathrm{FFNOut} Xout=Xmid+FFNOut
全程 L × d model L\times d_{\text{model}} L×dmodel 形状不变。
规格速查(Qwen 1 报告表 1)
| 规模 | Hidden | Heads | Layers |
|---|---|---|---|
| 1.8B | 2048 | 16 | 24 |
| 7B | 4096 | 32 | 32 |
| 14B | 5120 | 40 | 40 |
4. GQA(Grouped-Query Attention):主要见于 Qwen 1.5 部分规格
4.1 MHA 与 GQA 区别(是什么、为什么)
MHA(Multi-Head Attention,多头注意力)
- Query / Key / Value 头数相同 ,记为 h h h。第 t t t 个头各自有投影 W Q ( t ) , W K ( t ) , W V ( t ) W_Q^{(t)}, W_K^{(t)}, W_V^{(t)} WQ(t),WK(t),WV(t),得到 Q ( t ) , K ( t ) , V ( t ) ∈ R L × d k Q^{(t)}, K^{(t)}, V^{(t)} \in \mathbb{R}^{L\times d_k} Q(t),K(t),V(t)∈RL×dk, d k = d model / h d_k = d_{\text{model}}/h dk=dmodel/h。
- 直觉 : h h h 个「小专家」从 h h h 个子空间各算一遍注意力,再拼回 d model d_{\text{model}} dmodel 维。
- 推理时的代价 :自回归每步都要缓存已生成位置 的 Key 和 Value 。总缓存量与 KV 头数 成正比------MHA 里 每个注意力头各有一份 K、V ,头数多 → KV Cache 显存大、读写多。
GQA(Grouped-Query Attention,分组查询注意力)
- 把 Query 头数 h q h_q hq 与 Key/Value 头数 h kv h_{\text{kv}} hkv 拆开 ,且 h kv < h q h_{\text{kv}} < h_q hkv<hq (通常 h q h_q hq 整除 h kv h_{\text{kv}} hkv)。
- g = h q / h kv g = h_q / h_{\text{kv}} g=hq/hkv 个 Query 头共用 同一组 K , V K,V K,V(同一套 W K , W V W_K,W_V WK,WV 对应的头)。每个 Q 头仍算自己的注意力权重,但 去同一个(或同一组)K、V 上取加权。
- 直觉 :「看的角度」(Query)可以很多,但「记忆里供检索的键值槽」(KV)可以少开几份,在表达力与显存之间折中。
- 与 MHA 相比 :输出张量形状不变 ------多头输出仍拼成 L × d model L\times d_{\text{model}} L×dmodel,再乘 W O W_O WO;变的是 K、V 的参数量与推理时缓存的 KV 体积 ,大致按 h kv / h q h_{\text{kv}}/h_q hkv/hq 比例下降。
极端情况(便于对照)
- MHA : h kv = h q h_{\text{kv}} = h_q hkv=hq(每头自有 KV)。
- MQA(Multi-Query Attention) : h kv = 1 h_{\text{kv}} = 1 hkv=1,所有 Q 头共享一份 K 和 V;KV 最省,但容量最紧。
- GQA :介于两者之间,多组 KV 头被多组 Q 头复用。
| 项目 | MHA | GQA |
|---|---|---|
| Q 头数 / KV 头数 | h q = h kv = h h_q = h_{\text{kv}} = h hq=hkv=h | h q > h kv h_q > h_{\text{kv}} hq>hkv |
| 每头 d k d_k dk | 常取 d model / h q d_{\text{model}}/h_q dmodel/hq | 同左,保证拼接维仍为 d model d_{\text{model}} dmodel |
| 单层输出形状 | L × d model L\times d_{\text{model}} L×dmodel | 同左 |
| 推理 KV Cache(粗) | 正比于 h q h_q hq 份 K、V | 正比于 h kv h_{\text{kv}} hkv 份 K、V |
配置里常写 num_attention_heads = h q h_q hq,num_key_value_heads = h kv h_{\text{kv}} hkv;二者相等即为 MHA。
4.2 在 Qwen 系列中的位置
Qwen 1 技术报告中的基线以标准 MHA ( h q = h kv h_q=h_{\text{kv}} hq=hkv)描述为主。
Qwen1.5-32B 在官方博客中说明:与同系列其它尺寸相比,主要结构差异是引入 GQA ,以利于推理效率 参考:https://qwenlm.github.io/blog/qwen1.5-32b/。更细的矩阵形状与 LLaMA 架构 §4 一致。其它规格是否 GQA 以各模型 config.json 为准。
5. 输出层:线性层与 Softmax
最后一层输出 H ∈ R L × d model H\in\mathbb{R}^{L\times d_{\text{model}}} H∈RL×dmodel。自回归预测下一 token 时,取最后一个位置 的列向量( e w \mathbf{e}_w ew 见 §2.2):
h = H L − 1 , : ⊤ ∈ R d model . \mathbf{h} = HL-1,\\,:^\top \in \mathbb{R}^{d_{\text{model}}}. h=HL−1,:⊤∈Rdmodel.
Qwen 1 使用独立输出权重 (untied): W out ∈ R d model × V W_{\text{out}}\in\mathbb{R}^{d_{\text{model}}\times V} Wout∈Rdmodel×V,logits 列向量 s ∈ R V \mathbf{s}\in\mathbb{R}^V s∈RV,
s = W out ⊤ h + b out . \mathbf{s} = W_{\text{out}}^\top \mathbf{h} + \mathbf{b}_{\text{out}}. s=Wout⊤h+bout.
等价地( h ⊤ \mathbf{h}^\top h⊤ 为 1 × d model 1\times d_{\text{model}} 1×dmodel):
s ⊤ = h ⊤ W out + b out ⊤ . \mathbf{s}^\top = \mathbf{h}^\top W_{\text{out}} + \mathbf{b}_{\text{out}}^\top. s⊤=h⊤Wout+bout⊤.
下一 token 分布:
P ( next ) = s o f t m a x ( s ) . P(\text{next})=\mathrm{softmax}(\mathbf{s}). P(next)=softmax(s).
绑权 时令 W out = E ⊤ W_{\text{out}}=E^\top Wout=E⊤,第 w w w 个 logit 为 s w = h ⊤ e w + ( b out ) w s_w=\mathbf{h}^\top\mathbf{e}w+(b{\text{out}})_w sw=h⊤ew+(bout)w( e w \mathbf{e}_w ew 见 §2.2 )。Qwen 1 明确不采用绑权 来源:Qwen Technical Report §2.3。后继 Qwen2 则按模型规模在 tied / untied 间切换。
6. 与标准 Transformer Decoder、LLaMA 的架构对比
6.1 整体结构
| 项目 | 标准 Encoder-Decoder Transformer | 经典Decoder-only | LLaMA | Qwen 1 |
|---|---|---|---|---|
| 编码器 | 有 | 无 | 无 | 无 |
| Decoder 子层 | 掩码自注意力+交叉注意力+FFN | 掩码自注意力+FFN | 掩码自注意力+FFN | 同 LLaMA |
| 位置信息 | 常在与 Emb 相加 | 常在与 Emb 相加 | RoPE 在 Q , K Q,K Q,K | 同 LLaMA + FP32 频率等实现细节 |
6.2 组件级对比(强调 Qwen 差异)
| 组件 | 经典Decoder-only | LLaMA | Qwen 1 |
|---|---|---|---|
| 归一化 | 多为 LayerNorm | RMSNorm | RMSNorm |
| 归一化位置 | 常为 Post-Norm | Pre-Norm | Pre-Norm |
| FFN | ReLU: d → 4 d → d d\to 4d\to d d→4d→d | SwiGLU , d ff = 4 d d_{\text{ff}}=4d dff=4d | SwiGLU , d ff = 8 3 d d_{\text{ff}}=\frac{8}{3}d dff=38d |
| 位置编码 | 正弦/可学习,+ 到 Emb | RoPE 于 Q , K Q,K Q,K | 同左 + QKV bias、RoPE 实现精度取舍 |
| 词表 / 输出 | 依模型 | 常较小 V V V、可 tied | V ∼ 152 K V\sim 152\text{K} V∼152K ,untied |
| 长文(报告) | 依实现 | 生态内外推 | 推理期 NTK / LogN / 窗口等组合 |
6.3 单层公式对比(便于一眼看出「顺序」差异)
经典 Post-Norm Decoder 一层 (与 Decoder-only 一致的精神):
O u t = L N 2 ( F F N ( L N 1 ( A t t n ( X ) + X ) ) + L N 1 ( A t t n ( X ) + X ) ) . \mathrm{Out} = \mathrm{LN}_2\big(\mathrm{FFN}(\mathrm{LN}_1(\mathrm{Attn}(X)+X)) + \mathrm{LN}_1(\mathrm{Attn}(X)+X)\big). Out=LN2(FFN(LN1(Attn(X)+X))+LN1(Attn(X)+X)).
LLaMA / Qwen(Pre-Norm):
h = X + A t t n ( R M S N o r m ( X ) ) , O u t = h + F F N ( R M S N o r m ( h ) ) . h = X + \mathrm{Attn}(\mathrm{RMSNorm}(X)), \qquad \mathrm{Out} = h + \mathrm{FFN}(\mathrm{RMSNorm}(h)). h=X+Attn(RMSNorm(X)),Out=h+FFN(RMSNorm(h)).
Qwen 在 A t t n \mathrm{Attn} Attn 内含 QKV bias 与 RoPE ;在 F F N \mathrm{FFN} FFN 内为 SwiGLU 且 d ff = 8 3 d model d_{\text{ff}}=\frac{8}{3}d_{\text{model}} dff=38dmodel。
7. 长上下文:Qwen 1 在推理期的外推(不改变单层形状)
预训练上下文 2048 来源:Qwen Technical Report §2.4。更长序列依赖推理期 技巧,例如:NTK-aware RoPE 插值 、dynamic NTK 、LogN-Scaling (按长度比缩放注意力 logits)、窗口注意力 及按层分配不同窗口 。报告表 3 表明组合后可在 8K+ 仍保持合理困惑度。读实现时重点看:RoPE 底数/缩放 、attention scale 、稀疏/局部 mask。
8. Qwen 1.5:在 Qwen 1 骨架上的产品化迭代
Qwen1.5 介绍:多规格 Base/Chat、统一约 32K 上下文 、合并进 Hugging Face Transformers ≥ 4.37.0 (免 trust_remote_code)、量化与 vLLM 等生态。架构上 仍以 Decoder-only + Pre-Norm + RMSNorm + RoPE + SwiGLU 为主;Qwen1.5-32B 明确加入 GQA 参考:https://qwenlm.github.io/blog/qwen1.5-32b/。对齐(DPO/PPO 等)属 post-training,不改变 §3 的算子类型。
9. 各环节参数量简要(与 Decoder-only、LLaMA 对照)
记 d = d model d=d_{\text{model}} d=dmodel, N N N 为层数, V V V 为词表大小。
| 模块 | Qwen 1 相对 LLaMA 的要点 |
|---|---|
| Embedding | V ⋅ d V\cdot d V⋅d,untied 时另加 d ⋅ V d\cdot V d⋅V 量级给 W out W_{\text{out}} Wout(与 LLaMA tied 方案比通常更大) |
| RoPE | 无额外大量可训练参数(实现级 buffer) |
| 每层注意力 | 与 LLaMA 同为约 4 d 2 4d^2 4d2 级( W Q , W K , W V , W O W_Q,W_K,W_V,W_O WQ,WK,WV,WO);Qwen 多 QKV bias ( 3 h d k = 3 d 3hd_k=3d 3hdk=3d,常可忽略相对 d 2 d^2 d2) |
| 每层 RMSNorm | 两处,各 d d d 个 γ \gamma γ → 2 d 2d 2d |
| 每层 SwiGLU | W 1 , W 3 ∈ R d × d ff W_1,W_3\in\mathbb{R}^{d\times d_{\text{ff}}} W1,W3∈Rd×dff, W 2 ∈ R d ff × d W_2\in\mathbb{R}^{d_{\text{ff}}\times d} W2∈Rdff×d, d ff = 8 3 d d_{\text{ff}}=\frac{8}{3}d dff=38d → 权重约 3 ⋅ d ⋅ d ff + d ff ⋅ d = d ⋅ d ff ⋅ 4 3\cdot d\cdot d_{\text{ff}} + d_{\text{ff}}\cdot d = d\cdot d_{\text{ff}}\cdot 4 3⋅d⋅dff+dff⋅d=d⋅dff⋅4 ;因 d ff d_{\text{ff}} dff 小于 LLaMA 的 4 d 4d 4d,FFN 参数少于 LLaMA 同宽模型 |
10. 小结
- 数据进模型 :BPE(大词表)→ X ∈ R L × d X\in\mathbb{R}^{L\times d} X∈RL×d ;无 经典式 E m b + P E \mathrm{Emb}+\mathrm{PE} Emb+PE;位置在 RoPE 里进 Q , K Q,K Q,K。
- 单层 :Pre-Norm RMSNorm → MHA(QKV bias + RoPE + 因果掩码) + 残差 → RMSNorm → SwiGLU( d ff = 8 3 d d_{\text{ff}}=\frac{8}{3}d dff=38d) + 残差;形状恒为 L × d L\times d L×d。
- 相对 LLaMA :更大 V V V 、untied 、QKV bias 、更窄 FFN 中间维 、报告强调的推理长文组合。
- 相对经典 Decoder-only(10) :Pre-Norm + RMSNorm 、RoPE 、SwiGLU 、无输入端绝对 PE。
- Qwen 1.5 :生态与 32K ;32B 等规格见 GQA 与
config.json。