Enhancing End-to-End Autonomous Driving with Latent World Model
核心信息
- 论文ID :arXiv:2406.08481 - 作者 :Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, Tieniu Tan - 机构 :中国科学院自动化研究所 (CASIA), 模式识别国家重点实验室 (NLPR), 多模态人工智能系统国家重点实验室 (MAIS) - 发布时间 :2024-06-12 (v1), 2025-02-28 (v2) - 会议/期刊 :ICLR 2025 - 链接 :arXiv(https://arxiv.org/abs/2406.08481) | PDF(https://arxiv.org/pdf/2406.08481) - 代码链接:GitHub - BraveGroup/LAW(https://github.com/BraveGroup/LAW)
abstract: 一句话总结
端到端自动驾驶模型的"视觉理解能力"不够强?这个方法给模型加了一个"想象未来"的自监督任务------让模型根据当前看到的东西和打算走的路线,去预测下一帧会看到什么。预测得准,说明模型真的理解了场景。这个方法不用任何额外标注,插到 VAD 上就能在 nuScenes 上刷到新 SOTA,连那些用了深度、分割一大堆监督的方法都被超过了。
研究出发点与核心收益
question: 研究出发点
端到端自动驾驶模型直接从传感器数据学习规划,天然比传统分模块方案信息损失更少。但这也带来一个核心问题:模型从海量图像中学到的场景特征到底好不好?现有的做法要么靠感知任务的监督信号(检测、分割等)来"顺便"教模型理解场景,要么干脆只用轨迹监督------后者往往学不到足够好的场景表征。NLP 和 CV 领域已经证明,自监督学习是获得强特征表征的关键路径,但驾驶领域缺少一个能有效利用时序和动作信息的自监督任务。
check: 核心收益
- 即插即用,无需额外标注:LAW 的自监督信号来自"预测未来帧的特征"------训练数据里本来就有未来帧,不需要任何额外标注。直接加到现有框架的 loss 里就行
- 跨框架通用:同一个方法,无论是纯轨迹监督的 perception-free 框架还是带感知任务的 perception-based 框架,都能提升性能
- 全面 SOTA:三个完全不同的 benchmark(nuScenes 开环、NAVSIM 开环、CARLA 闭环)全都刷新最好成绩,特别是在 CARLA 上用纯轨迹监督就超过了用深度+分割+检测一大堆监督的方法
开篇总述
本文做了一件看似简单但效果惊人的事:给端到端驾驶模型加了一个"想象下一帧"的自监督任务。具体来说,模型在看完当前帧的图像并决定要走的路线之后,还要去预测下一帧图像会被编码成什么样子。预测得准不准,直接反映了模型对当前场景的理解程度------如果一个模型真能"脑补"出下一步会看到什么,那它一定已经理解了路上有什么、车在怎么动、自己该怎么走。
这个想法的灵感来自两个方向。一是 NLP/CV 领域自监督学习的成功:BERT 通过"猜被遮住的词"学会了理解语言,MAE 通过"重建被遮住的图像块"学会了理解图像。二是在驾驶场景中,未来不是随机的------它取决于你的动作。如果你往左转,左边就会出现在视野里;如果你加速,前面的车就会看起来更近。所以,一个真正理解场景的模型应该能根据当前观察和自己的动作来预测未来。
LAW 的核心设计是在特征空间而非像素空间做预测。之前 Drive-WM 在像素空间生成未来图像虽然效果酷炫,但扩散模型太慢了------生成一张图要好几秒。LAW 直接在编码器输出的特征向量上做预测,模型就是几层 Transformer,推理几乎不增加开销。训练时,下一帧的真实特征作为监督信号,用一个简单的 MSE loss 就行。
实验结果非常有说服力。在 nuScenes 上,perception-based 版本平均 L2 误差 0.49m、碰撞率 0.19%,全面超过 VAD(0.72m / 0.22%)。在 NAVSIM 上,PDMS 达到 84.6,超过 TransFuser、UniAD、PARA-Drive。在 CARLA 闭环仿真中,Drive Score 70.1,甚至超过了用大量感知监督的 ThinkTwice(65.0)和 DriveAdapter(65.9)。这意味着自监督的未来预测任务,比堆更多感知任务更有效地教会了模型理解场景。
摘要翻译
英文摘要
In autonomous driving, end-to-end planners directly utilize raw sensor data, enabling them to extract richer scene features and reduce information loss compared to traditional planners. This raises a crucial research question: how can we develop better scene feature representations to fully leverage sensor data in end-to-end driving? Self-supervised learning methods show great success in learning rich feature representations in NLP and computer vision. Inspired by this, we propose a novel self-supervised learning approach using the LAtent World model (LAW) for end-to-end driving. LAW predicts future scene features based on current features and ego trajectories. This self-supervised task can be seamlessly integrated into perception-free and perception-based frameworks, improving scene feature learning and optimizing trajectory prediction. LAW achieves state-of-the-art performance across multiple benchmarks, including real-world open-loop benchmark nuScenes, NAVSIM, and simulator-based closed-loop benchmark CARLA.
中文翻译
端到端自动驾驶直接用原始传感器数据做规划,比传统方法信息损失更少。那核心问题就变成了:怎么让模型从传感器数据中学到更好的场景特征?NLP 和计算机视觉里,自监督学习已经被证明是学强特征的利器。LAW 就是把这个思路搬到驾驶领域:让模型根据当前场景特征和自车轨迹来预测未来的场景特征。这个自监督任务可以无缝插到各种框架里------不需要感知标注的那种也行,带感知模块的那种也行------而且能同时提升场景理解能力和轨迹预测质量。最终在 nuScenes、NAVSIM、CARLA 三个 benchmark 上都拿到了当时的最好成绩。
核心要点提炼
- 研究背景 :端到端驾驶模型的场景特征学习不充分,perception-free 方法缺乏足够的监督信号 - 研究动机 :自监督学习在 NLP/CV 中被证明极其有效,但驾驶领域缺少利用时序和动作信息的自监督任务 - 核心方法 :在特征空间用世界模型预测未来帧的特征,以真实未来帧特征为监督 - 主要结果 :nuScenes L2 0.49m / 碰撞 0.19%;NAVSIM PDMS 84.6;CARLA DS 70.1 - 研究意义 :证明了自监督未来预测比堆感知任务更能有效提升场景理解能力
研究背景与动机
领域现状
端到端自动驾驶是近年最火热的研究方向之一。从 UniAD 到 VAD,从 ST-P3 到 TransFuser,各种方法百花齐放。但它们本质上都在做同一件事:把多摄像头的图像编码成某种特征表示,然后从这个特征表示预测未来轨迹。
这些方法可以分为两大阵营。Perception-based 阵营(UniAD、VAD 等)在训练时加了一堆感知任务------检测、跟踪、建图------用这些任务的 loss 来"顺带"教会编码器理解场景。Perception-free 阵营(TCP、LBC 等)则只用轨迹监督,完全不用感知标注。显然,perception-based 方法的场景理解能力更强,但代价是需要大量标注数据。
自监督学习在 NLP 和 CV 领域早已成为标配。BERT 通过掩码语言模型学会了理解文本,MAE 通过掩码图像重建学会了理解图像。但在自动驾驶领域,自监督学习的应用还非常有限------主要原因是驾驶场景有独特的挑战:它不是静态图像而是连续视频,而且未来不仅取决于世界本身,还取决于自车的动作。
现有方法的局限性
在像素空间做世界模型预测(如 Drive-WM)虽然视觉上很震撼,但有两个致命问题:第一,扩散模型生成一张图要好几秒,这个速度完全无法集成到实时的端到端训练中;第二,像素级重建的优化目标是"画得像",而不是"理解得深"------模型可能花大量参数去学习纹理和颜色,而不是真正理解场景的动态规律。
基于占用(Occupancy)的世界模型(如 OccWorld)需要占用标注,这本质上还是依赖昂贵的监督信号,没有解决核心问题。
Perception-free 方法虽然不依赖感知标注,但场景理解能力不足,在复杂场景中容易出问题。
研究动机
本文的核心洞察是:在特征空间做未来预测,比在像素空间更高效,且更直接地服务于规划目标。原因是:特征空间已经是编码器对场景的"理解压缩",在这个空间做预测等于是直接检验模型"理不理解场景动态",而不是"能不能画出一模一样的图"。而且,因为预测目标是特征向量而不是高维像素,模型可以非常轻量------几层 Transformer 就够,推理几乎零开销。
方法概述
核心思想
LAW 的核心思路用一句话说:"如果你真的理解了当前场景和你打算怎么走,那你应该能猜到下一秒会看到什么"。
这跟 Drive-WM 的"在像素空间生成未来图像"有本质区别。Drive-WM 要画出完整的高清未来画面,LAW 只需要预测未来画面的"特征指纹"------一个几百维的向量。打个比方,Drive-WM 是要你画出下一秒的实景照片,LAW 只要你说出"下一秒路左边会有一辆白车靠近,前面会变窄"------后者简单得多,但对规划来说信息量够了。
整体架构
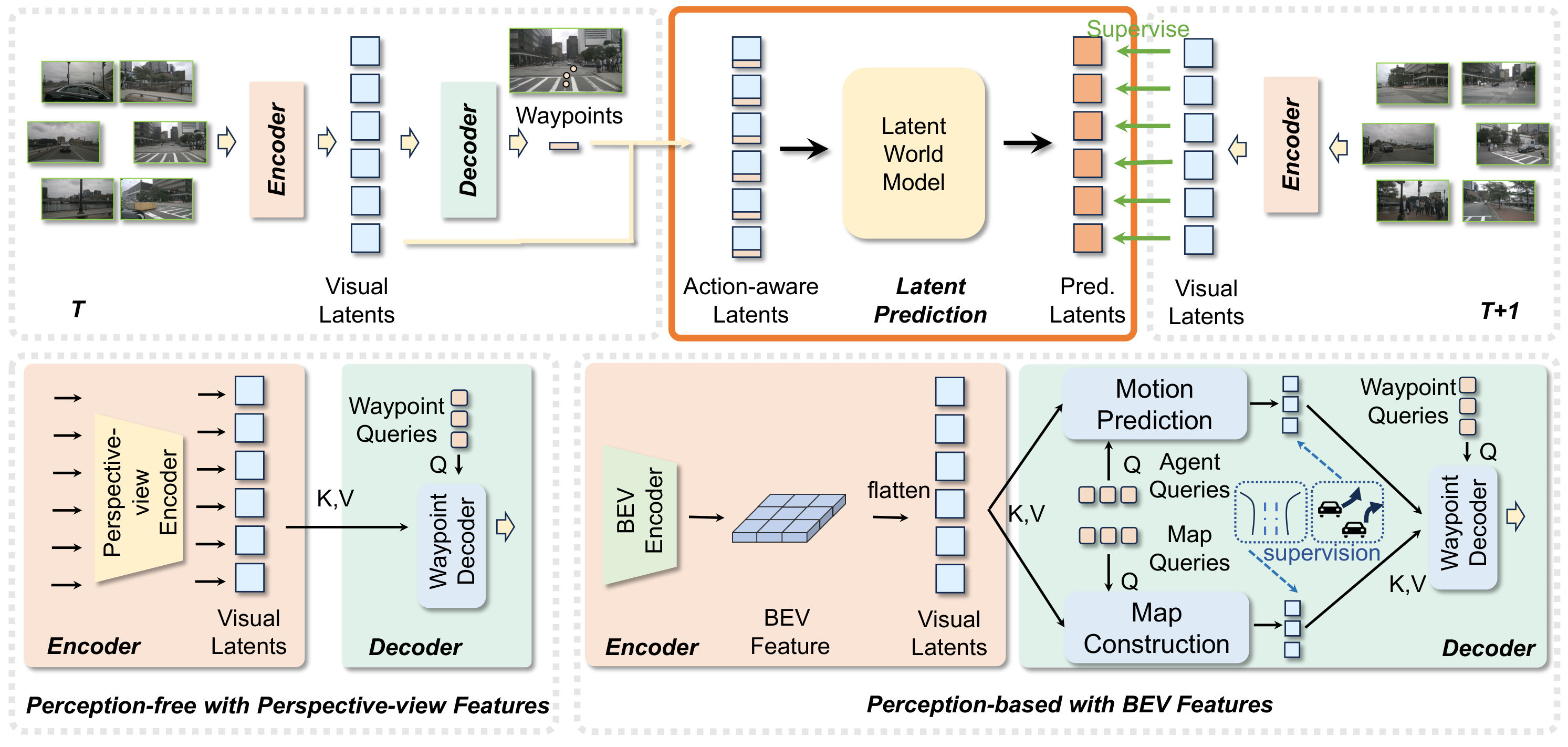
图1:LAW 的整体框架。上半部分是标准的端到端规划流水线:编码器从多摄像头图像中提取视觉特征(visual latents),解码器根据特征预测未来路径点(waypoints)。下半部分是 LAW 的核心:将视觉特征和预测路径点拼接成"动作感知特征"(action-aware latents),送入潜在世界模型预测下一帧的视觉特征。训练时,下一帧的真实视觉特征作为监督。这个框架既兼容只用前视图特征的 perception-free 模式,也兼容用 BEV 特征的 perception-based 模式。
整个框架的运行分四步:第一步,视觉编码器从当前帧的多摄像头图像中提取特征;第二步,路径解码器根据特征预测未来路径点;第三步,把特征和路径点拼在一起送入世界模型,预测下一帧的特征;第四步,用下一帧的真实特征作为监督,计算 MSE loss 并反向传播。这四步形成了一个闭环------预测得准,说明模型既理解了场景又理解了动作的后果。
关键模块拆解
动作感知特征构建:把"看到什么"和"打算做什么"绑在一起
这个模块解决的问题是:世界模型需要同时知道"当前场景长什么样"和"车打算怎么走",才能预测未来。做法很直接:把视觉特征和路径点拼接起来,过一个 MLP。
具体来说,视觉编码器输出 LL 个特征向量 Vt={vt1,vt2,...,vtL}Vt={vt1,vt2,...,vtL},每个 vti∈RDvti∈RD。路径解码器输出 MM 个路径点 Wt={wt1,...,wtM}Wt={wt1,...,wtM},每个路径点 wti=(xti,yti)wti=(xti,yti)。先把路径点拉平成一个 2M2M 维向量 w~twt,然后跟每个视觉特征拼在一起过 MLP:
ati=MLP(vti,w\~t)ati=MLP(vti,wt)
公式解释:⋅,⋅⋅,⋅ 是拼接操作。atiati 叫"动作感知特征"------它同时包含了"第 ii 个空间位置看到了什么"和"车接下来打算怎么走"的信息。MLP 把拼接后的向量映射回原来的维度 DD,方便后续处理。
为什么用拼接而不是其他融合方式?因为这里的目的是让世界模型同时看到两种信息,拼接是最直接的方式,实验也验证了它的有效性。
潜在世界模型:用 Transformer 在特征空间"想象未来"
世界模型的核心功能是:给定动作感知特征 AtAt,预测下一帧的视觉特征 V^t+1V^t+1。
V^t+1=LatentWorldModel(At)V^t+1=LatentWorldModel(At)
架构是几层堆叠的 Transformer block,每层包含自注意力和前馈网络。自注意力在特征向量的空间维度上做------也就是说,不同空间位置的特征可以互相"看到",共同推理未来的场景会变成什么样。
训练时用 MSE loss 监督预测:
Llatent=1L∑i=1L∥v^t+1i−vt+1i∥2Llatent=L1i=1∑L∥v^t+1i−vt+1i∥2
公式解释:对每个空间位置 ii,计算预测的特征 v^t+1iv^t+1i 和真实特征 vt+1ivt+1i 之间的 L2 距离,然后取平均。真实特征就是用同一个视觉编码器编码下一帧图像得到的特征------所以不需要任何额外标注。
这个设计的精妙之处在于它的双向优化效果:要预测准未来特征,编码器必须学好当前特征(否则输入就是垃圾),解码器必须预测好路径点(否则动作信息就是错的)。所以这一个 loss 同时推动了场景理解和轨迹预测。
双框架兼容:同一个世界模型,两种编码方式
LAW 的一个重要设计特点是它可以适配两种完全不同的端到端框架。
Perception-free 框架用的是前视图特征。编码器是 PETR 风格的:图像骨干网络提取特征 → 加 3D 位置编码 → 用可学习的视角查询(view queries)通过交叉注意力从每个视角提取一个全局特征向量。世界模型就在这 NN 个视角特征上做预测。
Perception-based 框架用的是 BEV 特征。编码器是 BEVFormer 风格的:图像特征被投影到鸟瞰图空间,形成 K×DK×D 的 BEV 特征图。世界模型在这个展平的 BEV 特征上做预测。BEV 特征还同时服务于检测、建图等感知任务。
两种框架的训练目标略有不同。Perception-free 的总 loss 是:
Lpf=Llatent+LwaypointLpf=Llatent+Lwaypoint
Perception-based 的总 loss 多了感知任务的 loss:
Lpb=Llatent+Lwaypoint+Lagent+LmapLpb=Llatent+Lwaypoint+Lagent+Lmap
公式解释:LwaypointLwaypoint 是轨迹预测的 L1 loss,LagentLagent 是运动预测 loss,LmapLmap 是地图构建 loss。注意 LlatentLlatent 在两个框架中完全一样------它只取决于"预测的特征像不像真实的特征",跟框架无关。
训练/推理流程
训练阶段:基于 VAD 的两阶段训练。第一阶段只训练编码器和感知头,用感知 loss 训练 48 个 epoch。第二阶段引入轨迹预测和潜在预测 loss,再训练 12 个 epoch。世界模型在这个阶段才加入训练。推理阶段:世界模型完全不参与------它只是一个训练时的辅助任务,不影响推理速度。
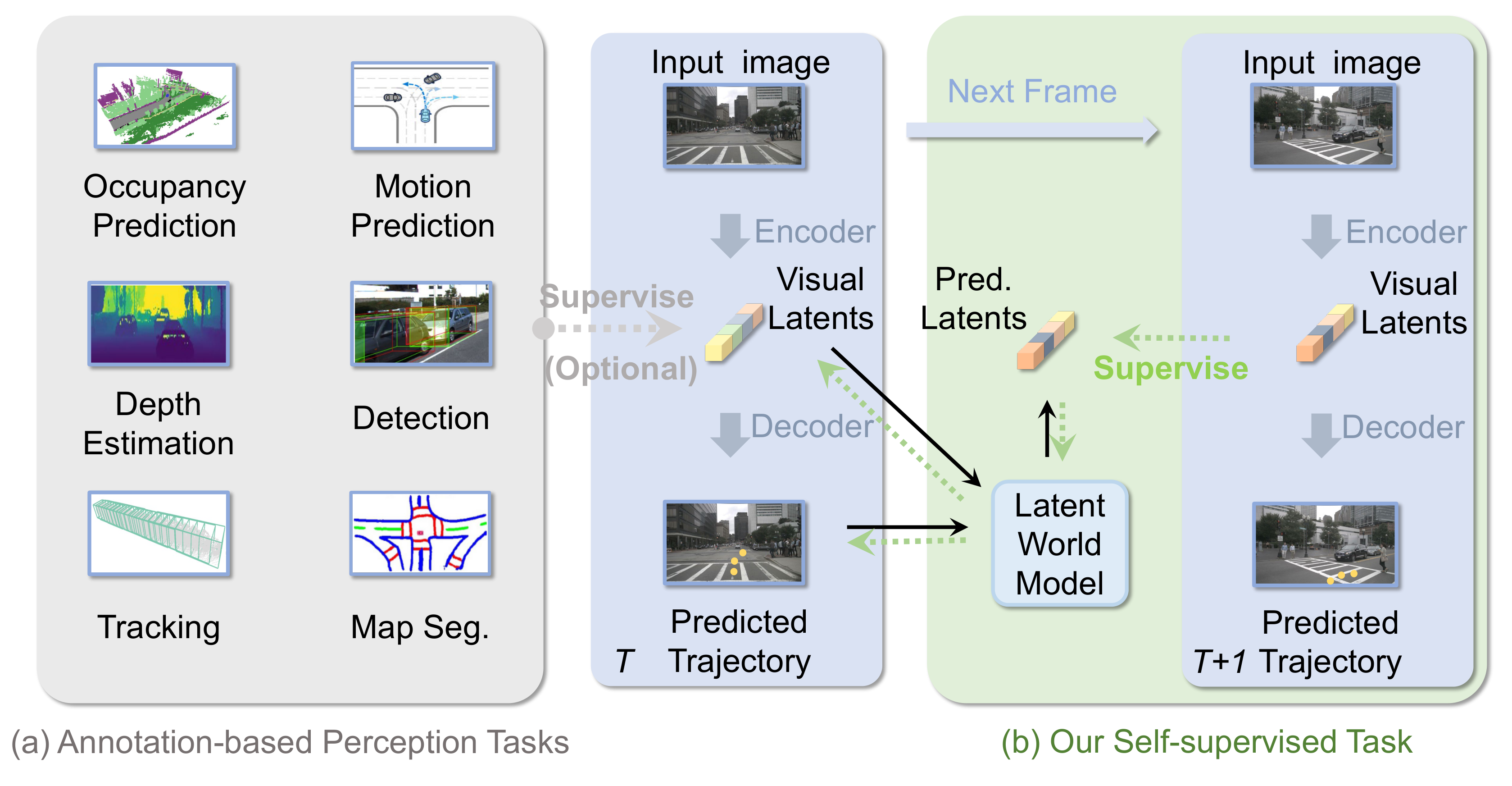
图2:LAW 与传统方法的对比。传统方法用感知标注(如分割结果)来辅助场景特征学习。LAW 则利用时序信息------通过预测未来帧的特征来自监督地学习更好的场景表征。蓝色部分是端到端规划器本身的流水线,下方是 LAW 新增的自监督分支。
实验结果
实验目标
实验要验证三个核心假设:(1)LAW 的自监督任务能有效提升场景特征学习质量;(2)动作信息(路径点)对未来预测至关重要;(3)LAW 在不同框架和 benchmark 上都有通用性。
数据集与实验设置
数据集统计
| 数据集 | 类型 | 规模 | 评估方式 | 图像分辨率 |
|---|---|---|---|---|
| nuScenes | 真实驾驶 | 1000 场景(700 训练 + 150 验证) | 开环(L2 + 碰撞率) | 800×320(perception-free)/ 原始尺寸(perception-based) |
| NAVSIM | 基于 nuPlan 的重采样 | 120 小时驾驶日志 | 开环(PDMS) | 640×320 |
| CARLA 0.9.10.1 | 仿真器 | 189K 帧(Roach 专家生成) | 闭环 Town05 Long(DS/RC/IS) | 900×256 |
基线方法
- nuScenes :NMP, SA-NMP, FF, EO, ST-P3, UniAD, VAD, BEV-Planner - NAVSIM :Constant Velocity, Ego Status MLP, TransFuser, UniAD, PARA-Drive - CARLA:CILRS, LBC, TransFuser, Roach, LAV, TCP, MILE, ThinkTwice, DriveAdapter, InterFuser
评估指标
- L2 距离 :预测轨迹与真值轨迹的平均 L2 偏差(1s/2s/3s/平均) - 碰撞率 :预测轨迹上发生碰撞的比例 - PDMS :综合了无过错碰撞(NC)、可行驶区域合规(DAC)、碰撞时间(TTC)、舒适度(Comf.)、自车进度(EP) - DS/RC/IS:CARLA 闭环指标(驾驶分数 / 路线完成度 / 违规分数)
主要结果
nuScenes 开环评估
| 方法 | 框架 | L2-1s | L2-2s | L2-3s | L2-Avg | Col-1s | Col-2s | Col-3s | Col-Avg |
|---|---|---|---|---|---|---|---|---|---|
| ST-P3 | perception-based | 1.33 | 2.11 | 2.90 | 2.11 | 0.23 | 0.62 | 1.27 | 0.71 |
| UniAD | perception-based | 0.48 | 0.96 | 1.65 | 1.03 | 0.05 | 0.17 | 0.71 | 0.31 |
| VAD | perception-based | 0.41 | 0.70 | 1.05 | 0.72 | 0.07 | 0.17 | 0.41 | 0.22 |
| BEV-Planner | perception-based | 0.30 | 0.52 | 0.83 | 0.55 | 0.10 | 0.37 | 1.30 | 0.59 |
| LAW (pf) | perception-free | 0.26 | 0.57 | 1.01 | 0.61 | 0.14 | 0.21 | 0.54 | 0.30 |
| LAW (pb) | perception-based | 0.24 | 0.46 | 0.76 | 0.49 | 0.08 | 0.10 | 0.39 | 0.19 |
关键发现:LAW (pb) 在所有指标上全面领先,平均 L2 0.49m 是当时 nuScenes 上的最好成绩。值得注意的是,LAW 的 perception-free 版本(L2-Avg 0.61m)也比 VAD(0.72m)好了 15%------这意味着仅靠一个自监督任务,不用任何感知标注,就能比精心设计的感知辅助方案更有效。
NAVSIM 开环评估
| 方法 | NC↑ | DAC↑ | TTC↑ | Comf.↑ | EP↑ | PDMS↑ |
|---|---|---|---|---|---|---|
| Human | 100 | 100 | 100 | 99.9 | 87.5 | 94.8 |
| TransFuser | 97.7 | 92.8 | 92.8 | 100 | 79.2 | 84.0 |
| UniAD | 97.8 | 91.9 | 92.9 | 100 | 78.8 | 83.4 |
| PARA-Drive | 97.9 | 92.4 | 93.0 | 99.8 | 79.3 | 84.0 |
| LAW | 96.4 | 95.4 | 88.7 | 99.9 | 81.7 | 84.6 |
关键发现:LAW 在 DAC(95.4)和 EP(81.7)上显著领先,说明自监督任务让模型更好地理解了"哪里可以开"和"该怎么前进"。PDMS 综合得分 84.6 超过了所有对比方法。NAVSIM 的数据比 nuScenes 难得多(刻意减少了简单直行场景),说明 LAW 的优势不是来自简单场景。
CARLA 闭环评估
| 方法 | 额外监督 | DS↑ | RC↑ | IS↑ |
|---|---|---|---|---|
| TCP | 专家轨迹 | 57.2 | 80.4 | 0.73 |
| MILE | 专家 + 地图 + 检测 | 61.1 | 97.4 | 0.63 |
| ThinkTwice | 专家 + 深度 + 分割 + 检测 | 65.0 | 95.5 | 0.69 |
| DriveAdapter | 专家 + 地图 + 检测 | 65.9 | 94.4 | 0.72 |
| InterFuser | 专家 + 地图 + 检测 | 68.3 | 95.0 | - |
| LAW | 专家 + 潜在预测 | 70.1 | 97.8 | 0.72 |
关键发现:这是最有说服力的实验。LAW 只用专家轨迹和自监督的潜在预测任务,没有任何感知标注,就在闭环评估中拿到了 70.1 的 DS,超过了用深度+分割+检测一大堆监督的 ThinkTwice(65.0)和 DriveAdapter(65.9)。这直接证明了"想象未来"这个自监督任务比堆感知任务更有效。
消融实验
消融设计思路
核心消融围绕三个问题展开:(1)LAW 是否真的有效?(2)动作信息有多重要?(3)模型架构和时间跨度的选择是否合理?
LAW 核心消融
| 框架 | 视觉特征 | 预测轨迹 | L2-Avg | Col-Avg |
|---|---|---|---|---|
| Perception-free | - | - | 0.71 | 0.41 |
| Perception-free | ✓ | - | 0.68 (-0.03) | 0.37 (-0.04) |
| Perception-free | ✓ | ✓ | 0.61 (-0.10) | 0.30 (-0.11) |
| Perception-based | - | - | 0.54 | 0.25 |
| Perception-based | ✓ | - | 0.52 (-0.02) | 0.21 (-0.04) |
| Perception-based | ✓ | ✓ | 0.49 (-0.05) | 0.19 (-0.06) |
关键发现:两个框架中,加入预测轨迹(动作信息)都带来了最大提升。没有轨迹信息的世界模型只有小幅改善(说明光看场景特征预测未来太模糊了),加了轨迹后提升显著。这验证了核心假设:未来取决于动作,动作信息对未来预测至关重要。
时间跨度选择
| 预测时间 | L2-Avg | Col-Avg |
|---|---|---|
| 0.5s | 0.61 | 0.30 |
| 1.5s | 0.58 | 0.25 |
| 3.0s | 0.63 | 0.27 |
| 10.0s | 0.72 | 0.43 |
关键发现:1.5s 是最佳预测时间------太近(0.5s)场景变化不够大,学不到有用的信息;太远(3.0s+)预测不准,反而有害;10s 完全没用。这跟 MAE 中的掩码比例选择是一个道理:任务太简单学不到东西,太难了又做不好。
世界模型架构选择
| 架构 | L2-Avg | Col-Avg |
|---|---|---|
| Linear Projection (单层) | 0.70 | 0.42 |
| Two-layer MLP | 0.64 | 0.33 |
| Transformer Blocks | 0.61 | 0.30 |
关键发现:线性投影太弱,MLP 有改善但不够,Transformer 效果最好。说明不同空间位置之间的交互对未来预测很重要------你不能只看每个位置自己来预测未来,还得考虑位置之间的相互影响。
NAVSIM 和 CARLA 消融
| 数据集 | Latent Pred. | PDMS / DS |
|---|---|---|
| NAVSIM | ✗ | 77.5 |
| NAVSIM | ✓ | 84.6 (+7.1) |
| CARLA | ✗ | 67.9 |
| CARLA | ✓ | 70.1 (+2.2) |
NAVSIM 上 PDMS 提升了 7.1 分(从 77.5 到 84.6),这是非常大的提升,主要来自 DAC(+6.0)和 EP(+6.6)两个维度的改善。
多步预测与多帧输入(附录)
| 预测方式 | 输入帧 | L2-Avg | Col-Avg |
|---|---|---|---|
| 预测 1.5s | 当前帧 | 0.73 | 0.32 |
| 自回归预测 1.5s→3s | 当前帧 | 0.69 | 0.29 |
| 自回归预测 1.5s→3s | 当前帧 | 0.68 | 0.33 |
| 自回归预测 1.5s→3s | -1.5s + 当前帧 | 0.55 | 0.17 |
关键发现:自回归预测多步未来比单步预测更好(0.69 vs 0.73),而加入历史帧的信息后效果大幅提升(0.55 vs 0.68)。L2-Avg 0.55 和碰撞率 0.17 已经接近甚至超过了 perception-based 框架的表现(0.49 / 0.19)。这说明时序信息对驾驶场景理解极其重要。
可视化分析
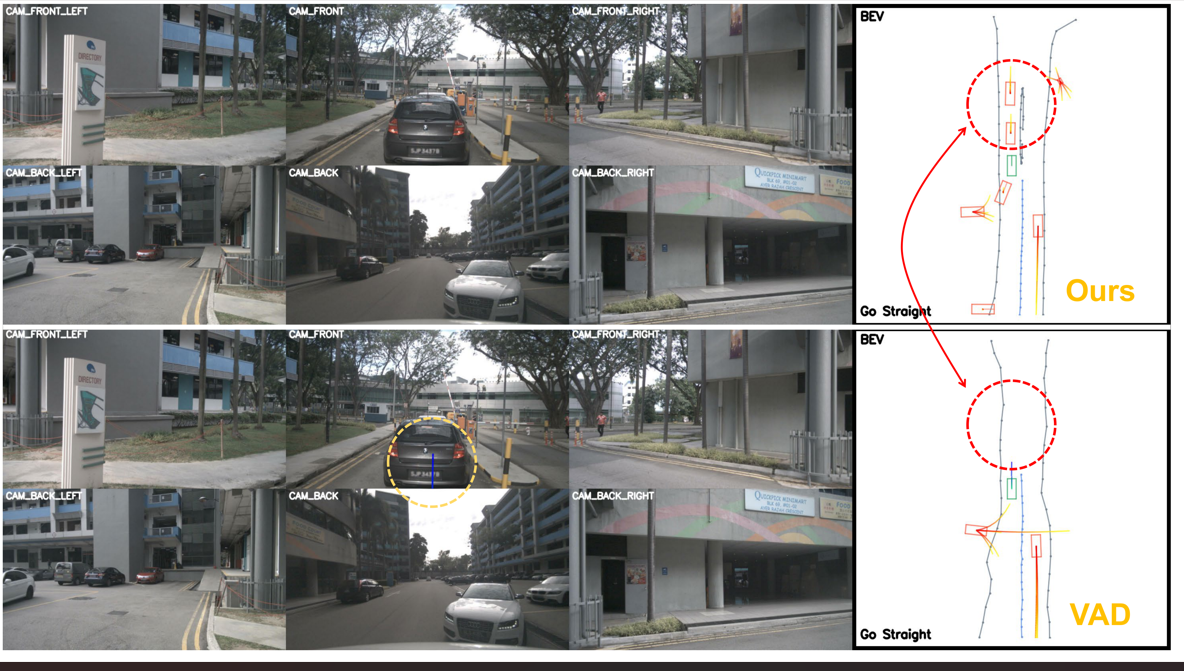
图3:LAW (perception-based) 与 VAD 的可视化对比。右半部分展示了 BEV 视角下的自车轨迹预测、他车运动预测和地图构建。红色圆圈标注了关键差异:LAW 捕捉到了 VAD 忽略的关键场景信息(如前方车辆的行为)。结果是 VAD 预测了一条会导致追尾的直行轨迹(黄色圆圈),而 LAW 因为更好的场景理解避免了这个问题。
深度分析
研究价值评估
理论贡献
- "在特征空间做世界模型"的范式 :LAW 证明了不需要在像素空间生成未来图像,直接在编码器的特征空间做预测就能有效提升场景理解。这个发现对整个驾驶世界模型领域有重要指导意义------它指明了一条比像素空间生成更高效的路径。 - 动作感知的自监督任务设计 :把"自车动作"作为未来预测的必要输入,这不仅是合理的物理直觉(未来取决于你的行为),也有实验上的强力支撑(去掉动作信息后提升大幅缩水)。 - 跨框架通用性的方法论:LAW 展示了一个自监督任务可以同时适配 perception-free 和 perception-based 两种完全不同的架构范式,这种"即插即用"的设计理念对后续工作有启发。
实际应用价值
- 无需额外标注 :LAW 的自监督信号来自训练数据中已经存在的未来帧,不需要任何额外标注。这使得它可以几乎零成本地加到任何现有的端到端训练流程中。 - 推理零开销 :世界模型只在训练时使用,推理时完全不参与。这意味着它不会影响模型的部署效率。 - 跨平台验证:在真实数据(nuScenes、NAVSIM)和仿真器(CARLA)上都有效,说明学到的特征不是数据集特定的,而是真正有泛化能力的。
领域影响
- 短期影响 :为端到端驾驶提供了一种简单有效的性能提升手段,可以直接集成到现有方法中 - 中期影响 :推动了"驾驶领域的自监督学习"这一研究方向,后续工作(如基于视频预测的预训练)可能会在这个基础上进一步发展 - 长期影响:LAW 的"特征空间世界模型"思想可能会成为端到端驾驶的标准组件,就像 MAE 成为 ViT 预训练的标准方法一样
方法优势与局限
核心优势
LAW 最大的优势在于它的简洁性和高效性。整个方法就是一个自监督 loss 加一个轻量的 Transformer 模块,不需要额外数据、不需要额外标注、不影响推理速度,却能在三个差异很大的 benchmark 上都拿到 SOTA。特别是 CARLA 闭环实验中,用纯自监督就超过了用大量感知监督的方法,这直接证明了"想象未来"比"堆感知任务"更有效。
从技术角度看,动作感知特征的设计也很巧妙:它把视觉信息和动作信息在特征层面融合,使得世界模型不是在做"无条件的未来预测",而是在做"如果我这么走,未来会怎样"的条件预测。消融实验清楚地证明了这个设计选择的价值。
局限性分析
- 依赖未来帧的可用性 :训练需要访问未来帧的特征作为监督。这在标准驾驶数据集中不成问题(数据本来就是连续视频),但在某些非连续或跳帧场景中可能需要调整。 - 特征空间的可解释性 :在特征空间做预测意味着我们无法直接"看到"模型在想象什么样的未来。与 Drive-WM 的像素空间生成相比,LAW 的预测结果不够直观。不过论文通过可视化感知结果(地图构建、运动预测)间接展示了特征质量的提升。 - 时间跨度的选择需要调参 :1.5s 的最优预测时间是在 nuScenes 数据集上实验得出的,不同场景密度和速度范围可能需要不同的预测时间。论文未探讨这个参数的迁移性。 - 单步 vs 多步预测:正文中的主实验只做单步预测(预测 1 个未来帧),多步自回归预测的潜力只在附录中初步探索。多步预测可能带来更大提升,但也增加了训练复杂度。
适用场景分析
- 最适合的场景 :任何端到端驾驶框架的训练增强。无论是 perception-free 还是 perception-based,无论是开环还是闭环评估,LAW 都能带来一致的提升。特别适合那些标注数据有限但视频数据充足的场景。 - 不适合的场景:不适用于非端到端的传统规划框架(因为它们不直接从图像学特征);也不适用于需要可视化未来预测结果的应用(因为 LAW 在特征空间操作)。
与相关论文对比
对比论文选择依据
以下论文代表了驾驶世界模型和端到端规划两条技术路线的关键节点,涵盖了像素空间世界模型、占用空间世界模型和纯规划方法。
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving (Drive-WM) - CVPR 2024
方法对比
| 对比维度 | Drive-WM | LAW |
|---|---|---|
| 核心思想 | 像素空间生成未来图像辅助规划 | 特征空间预测未来特征辅助训练 |
| 世界模型空间 | 像素空间(扩散模型) | 特征空间(Transformer) |
| 计算效率 | 低(扩散模型生成需数秒) | 高(推理零开销,训练几乎零开销) |
| 可视化能力 | 强(直接生成图像) | 弱(只有特征向量) |
| 训练方式 | 世界模型单独训练后用于规划 | 世界模型作为训练时的自监督任务 |
关系分析
- 关系类型 :技术路线演进(同一团队,LAW 是后续工作) - 核心差异 :Drive-WM 是"用世界模型的输出做规划",LAW 是"用世界模型的训练目标做特征学习"。前者是世界模型的应用,后者是世界模型作为自监督工具。两者的根本区别在于:Drive-WM 推理时需要世界模型,LAW 推理时不需要。 - 互补性:Drive-WM 的像素空间输出适合仿真和数据增强,LAW 的特征空间预测适合直接提升规划性能。理论上两者可以结合。
UniAD - UniAD: Planning-oriented Autonomous Driving
方法对比
| 对比维度 | UniAD | LAW |
|---|---|---|
| 核心思想 | 多任务联合训练辅助规划 | 自监督未来预测辅助训练 |
| 感知任务 | 检测+跟踪+建图+占用 | 复用 VAD 的感知头 |
| 自监督 | 无 | 潜在世界模型 |
| 额外标注需求 | 多种感知标注 | 无额外标注 |
性能对比
| 数据集 | 指标 | UniAD | LAW (pb) | 提升 |
|---|---|---|---|---|
| nuScenes | L2-Avg | 1.03 | 0.49 | -52% |
| nuScenes | Col-Avg | 0.31 | 0.19 | -39% |
| NAVSIM | PDMS | 83.4 | 84.6 | +1.2 |
关系分析
- 关系类型 :对比 - LAW 的优势 :LAW 不需要额外的感知任务设计,通过一个简洁的自监督任务就超越了 UniAD 繁重的多任务学习框架 - 互补性:UniAD 的多任务框架可以与 LAW 的自监督任务结合,进一步提升性能
VAD - VAD: Vectorized Scene Representation for Efficient and Autonomous Driving
方法对比
| 对比维度 | VAD | LAW (基于 VAD) |
|---|---|---|
| 核心思想 | 向量化场景表征 + 感知辅助规划 | 在 VAD 基础上加自监督世界模型 |
| 场景理解来源 | 感知任务监督 | 感知任务 + 未来特征预测 |
| 额外开销 | 无 | 训练时增加 Transformer 模块 |
性能对比
| 数据集 | 指标 | VAD | LAW (pb) | 提升 |
|---|---|---|---|---|
| nuScenes | L2-Avg | 0.72 | 0.49 | -32% |
| nuScenes | Col-Avg | 0.22 | 0.19 | -14% |
关系分析
- 关系类型 :改进/扩展(LAW 直接构建在 VAD 之上) - LAW 的改进:在 VAD 的基础上加了潜在世界模型的自监督任务,不需要任何额外标注就显著提升了性能
对比总结
LAW 在"训练效率"和"通用性"两个维度上实现了对前人工作的超越。与 Drive-WM 相比,LAW 从像素空间转向特征空间,大幅降低了计算成本并去掉了推理时的开销。与 UniAD/VAD 相比,LAW 用一个简洁的自监督任务替代了繁重的多任务学习或额外的感知标注。这些改进的方向是一致的:用更少的标注、更少的计算、更简洁的设计,获得更好的场景理解能力。
技术路线定位
所属技术路线
LAW 属于"驾驶场景自监督学习"路线,更具体地说是"基于世界模型的自监督学习"子方向。这条路线的核心思想是:利用驾驶数据的时序特性和因果关系(当前状态 + 动作 → 未来状态),设计自监督任务来学习更好的场景表征。
技术路线发展历程
MAE (掩码图像重建) → Drive-WM (像素空间世界模型) → LAW (特征空间世界模型) → 多步预测 / 视频预训练 ↑ ↑ ↑ He 2022 Wang 2023 本文, ICLR 2025
本文在技术路线中的位置
- 承上 :继承了 MAE 的"自监督学习"范式和 Drive-WM 的"世界模型"思想 - 启下 :为后续的驾驶场景自监督学习研究提供了方法论基础(特征空间预测比像素空间更高效) - 关键节点:第一次证明了"在特征空间做未来预测"是一个有效的自监督任务,可以替代或补充传统的感知任务监督
未来工作建议
作者建议的未来工作
论文未明确列出未来工作建议,但从附录实验可以推断作者探索了以下方向: - 多步自回归预测(已初步探索,有进一步优化空间) - 多帧输入融合(已初步探索,效果显著)
基于分析的未来方向
- 大规模视频预训练 :LAW 的自监督任务不依赖任何标注,理论上可以在海量无标注驾驶视频上做预训练,然后用少量标注数据微调。这种"先看大量视频理解世界,再学具体任务"的路线可能会带来更大的性能飞跃。 2. 多步预测的系统优化 :附录中多步自回归预测已经显示出比单步更好的效果,但训练策略还很初步(简单分阶段训练)。更好的多步预测策略(如课程学习、分层预测)可能会进一步释放潜力。 3. 与其他自监督任务的组合:LAW 的未来预测任务与 MAE 的掩码重建、对比学习等自监督方法可能互补,组合使用可能会有更好的效果。
我的综合评价
价值评分
总体评分
8.5/10 - 用极其简洁的设计实现了跨框架、跨 benchmark 的一致性能提升,有力证明了"特征空间世界模型"作为自监督任务的有效性。核心实验(特别是 CARLA 闭环)的说服力很强。
分项评分
| 评分维度 | 分数 | 评分理由 |
|---|---|---|
| 创新性 | 8/10 | "在特征空间做世界模型"的思路简洁有效,但核心机制(Transformer + MSE loss)本身不是新发明。创新在于将世界模型从应用工具转变为自监督训练工具的设计视角转换 |
| 技术质量 | 9/10 | 方法设计清晰,推导严谨,消融实验全面(核心消融 + 时间跨度 + 架构 + 跨 benchmark),附录还探索了多步预测和多帧输入 |
| 实验充分性 | 9/10 | 三个差异很大的 benchmark(开环真实数据 + 开环困难场景 + 闭环仿真),跨两种框架,消融实验覆盖全面 |
| 写作质量 | 8/10 | 结构清晰,公式和图表配合良好。但 perception-free 和 perception-based 两种框架的描述有些重复,可以更精简 |
| 实用性 | 8/10 | 即插即用,无需额外标注,推理零开销,可直接集成到现有训练流程。但 1.5s 的最优时间跨度需要针对不同场景调参 |
重点关注
值得关注的技术点
"动作感知特征"的设计值得仔细思考------把视觉特征和动作信息拼接后过 MLP 看似简单,但它传递了一个重要的设计理念:在驾驶场景中,未来不是被动观测到的,而是主动创造出来的。这意味着任何有效的驾驶自监督任务都必须把自车动作纳入考虑,否则就是在做"无条件预测"------这和普通视频预测没本质区别。
需要深入理解的部分
LAW 虽然在三个 benchmark 上都有效,但提升幅度差异较大(nuScenes 上提升显著,NAVSIM 上相对温和)。这可能反映了不同数据集的特性------nuScenes 的简单场景较多,LAW 帮助模型更好地处理了少数复杂场景;NAVSIM 本身就更难,LAW 的边际贡献相对小一些。理解这种差异对于在具体应用场景中选择和调优 LAW 很重要。
我的笔记
相关论文
直接相关
- Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving - 同团队前置工作,像素空间世界模型。LAW 是其在特征空间的演进 - VAD - 基础规划框架,LAW 的 perception-based 版本直接构建在 VAD 之上
背景相关
- UniAD - 多任务感知辅助规划的代表性工作 - BEVFormer - BEV 编码器的代表性工作 - MAE - 自监督学习范式的重要参考 - MILE - 驾驶世界模型的早期探索 - TCP - Perception-free 端到端规划的代表性工作 - OccWorld - 占用空间世界模型
后续工作
- 论文未提及 / 未检索到可靠的直接后续工作
外部资源
- 代码仓库:github.com/BraveGroup/LAW(https://github.com/BraveGroup/LAW)
tip: 关键启示
在特征空间做"想象未来"的自监督任务,比在像素空间生成未来图像或堆更多感知标注,都更高效地教会了模型理解驾驶场景------关键洞察是"理解场景"的本质是"能根据当前观察和动作预测未来"。
warning: 注意事项
- 1.5s 的最优预测时间是在 nuScenes 上得出的,不同速度和场景密度可能需要不同时间跨度
- 特征空间预测的结果不可直接可视化,难以直观评估预测质量
- 多步自回归预测只在附录中初步探索,其稳定性和效果需要进一步验证
success: 推荐指数
⭐⭐⭐⭐⭐ 强烈推荐。设计简洁优雅,实验全面充分,结论清晰有力。对做端到端驾驶的研究者来说是必读工作,对做自监督学习和世界模型的研究者也有重要参考价值。