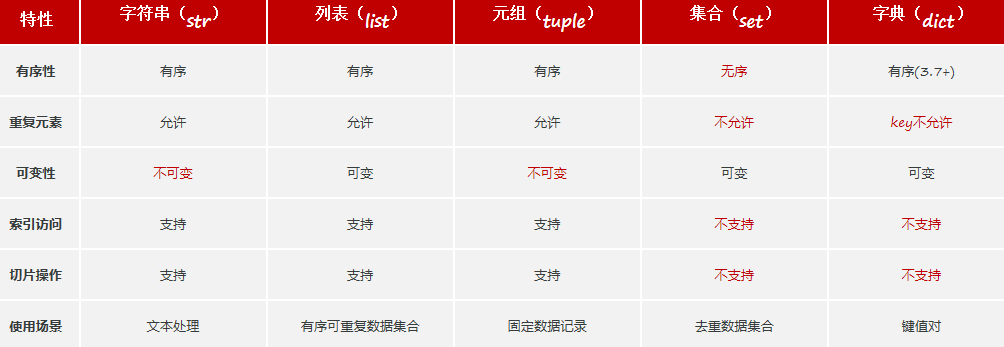
1.列表(list):列表是数据容器中的一类,是一次性可以存储多个数据(元素)的。
(1)特点:可以存储不同类型的元素 元素有序、可以重复、元素可以修改
定义:
列表名称 = 元素1,元素2,元素3,元素4,元素5...
s = 54, 15, 75, 108, 23, 78, 75
python
# 定义列表
s = [56,90,88,65,90,"A","Hello",True]
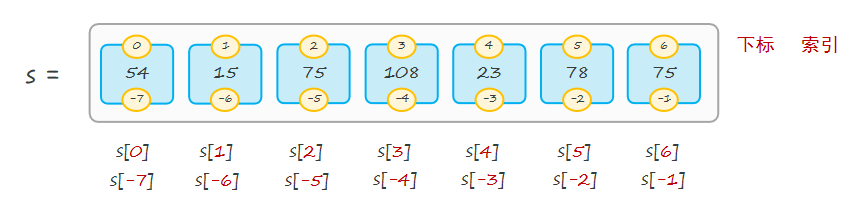
print(type(s))序列类型:容器中的元素按特定顺序排列的、可通过索引访问的容器类型称之为序列。
注意:从前向后(正向索引),下标从0开始;从后向前(反向索引),下标从-1开始。
(2)列表元素的查看、修改、删除
查看:list10
修改:list10 = "A"
删除:del list13
注意:如果指定的索引值超出范围,将会报错
python
# 访问列表元素
# 获取
print(s[0])
print(s[-8])
# 修改
s[5] = "ABC"
print(s)(3)切片:切片是指对操作的数据截取其中一部分的操作。列表、字符串、元组都支持切片操作。

语法:序列数据 开始索引:结束索引:步长
(1)不包含结束索引位置对应的元素(开始索引未指定默认为0;
(2)结束索引未指定默认为列表长度(直到列表末尾);
(3)步长未指定默认为1) 索引采用正向、反向索引都可以 步长是选取间隔,默认步长为1
s0:5:1 切片后的结果为 "A", "C", "E", "B", "D"
s0:5:2 切片后的结果为 "A", "E", "D"
python
s = ["A","C","H","K","L","B","D","X","C","U"]
print(s[0:5:1])
print(type(s[0:5:1]))
print(s[:5:1])
print(s[:5:])
print(s[:5])
print(s[0:5:2])
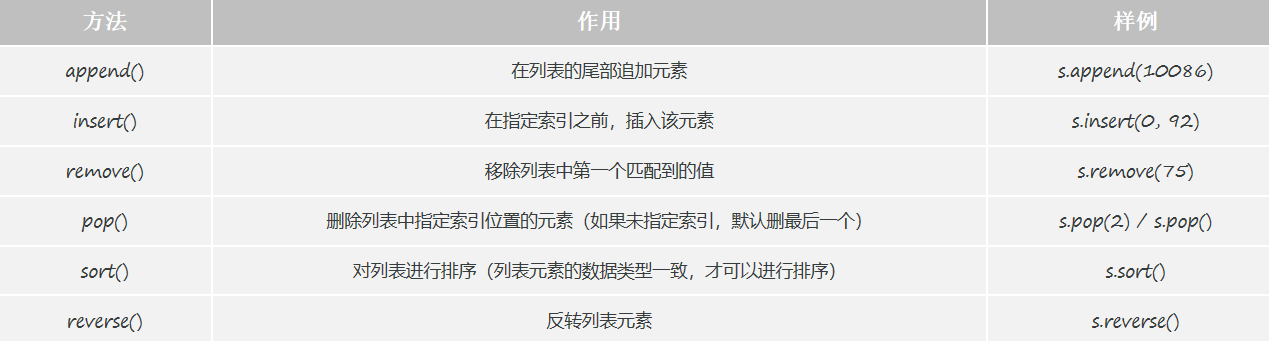
print(s[0:-2:1])(4)方法
python
# 列表定义
s = [56,90,88,65,90,100,209,72,145]
print(s)
# append(): 在列表尾部追加元素
s.append(188)
print(s)
# insert(): 在指定索引之前,插入元素
s.insert(2,80)
print(s)
# remove(): 移除列表中第一个匹配到的元素
s.remove(90)
print(s)
# pop(): 移除列表中指定索引位置的元素并返回(如果未指定,默认删除最后一个)
e = s.pop(1)
print(e)
print(s)
# sort(): 排序
s.sort()
print(s)
# reverse(): 反转列表元素
s.reverse()
print(s)案例1:将用户输入的10个数字,存储到一个列表中,并将列表中的数字进行排序,输出其中的最小值、最大值 和 平均值
python
# 1.定义列表
num_list = []
# 2.将用户输入的10个数字存入列表
for i in range(10):
num = int(input("请输入一个有效数字:"))
num_list.append(num)
print("数字列表:",num_list)
# 3.排序
num_list.sort()
print("排序后的数字列表:",num_list)
# 4. 输出其中的最小值、最大值 和平均值 ---> sum() 求和;len() 获取元素个数
print("最小值:", num_list[0])
print("最大值:", num_list[-1])
print("平均值:", sum(num_list)/len(num_list))案例2(简化):合并两个列表中的元素,并对合并的结果进行去重处理(去除列表中的重复元素)
python
num_list1 = [19,23,54,64,875,20,109,232,123,54]
num_list2 = [55,80,72,35,60,123,54,29,91]
#1.合并列表
num_list = num_list1 + num_list2
print("合并后的原始列表:",num_list)
#2.去重重复记录
new_list = []
for num in num_list:
# 判断new_list中是否存在num元素,如果不存在,再添加
if num not in new_list: # 判断元素是否存在于列表中,如果存在,则返回True,不存在,返回Fals
new_list.append(num)
print("去重重复记录后的列表:",new_list)案例3:生成1-20的平方列表。 --> range(1,21)
python
# 方式一:传统方式
num_list = []
for i in range(1,21):
num_list.append(i**2)
print(num_list)
# 方式二:列表推导式 ---> 就是按照一定的规则快速生成一个列表的方法 --> 语法格式1:[要插入的值 for i in 序列/列表]
num_list2 = [i**2 for i in range(1,21)]
print(num_list2)案例4:从一个数字列表中提取所有偶数,并计算其平方,组成一个新的列表 ---> 判断偶数:num%2 == 0
python
# 列表推导式 ---> 就是按照一定的规则快速生成一个列表的方法 ---> 语法格式2:[要插入的值 for i in 序列/列表 if 条件]
num_list = [12,32,45,77,80,92,33,57,97,110,111,122]
new_list = [i**2 for i in num_list if i % 2 == 0]
print(new_list)
print(num_list[::])2.字符串(str):字符串是字符的容器,一个字符串中可以存放任意数量的字符。如:"Python" 'Python' """Python"""
特点:不可变性(无法修改)、有序性、可迭代性。
字符串中的每一个字符元素都有其对应的下标(索引),通过元素对应的索引,就可以获取到对应的元素。
注意:从前向后(正向索引),下标从0开始;从后向前(反向索引),下标从-1开始。
python
# 字符串 基本操作 ---> 不可变的(无法修改)、有序性、可迭代性
s = "Hello-Python"
print(s[4]) # 正向索引
print(s[-8]) # 反向索引
for i in s:
print(i)(1)切片:切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
语法:序列对象 开始索引:结束索引:步长
1.不包含结束索引位置对应的元素(开始索引未指定默认为0;结束索引未指定默认为-1;步长未指定默认为1)
2.索引采用正向、反向索引都可以
3.步长是选取间隔,默认步长为1 (如果是-1, 表示从后向前)

s0:5:1 切片后的结果为 "Pytho"
S0:5:2 切片后的结果为 "Pto"
python
s = "Hello-Python"
print(s[0:5:1])
print(s[:5:1])
print(s[:5:])
print(s[:5])
print(s[6:12:1])
print(s[6::1])
print("-------------------------")
# 步长 --> 正数: 从前往后截取 ; 负数: 从后往前截取
print(s[-1:-7:-1])
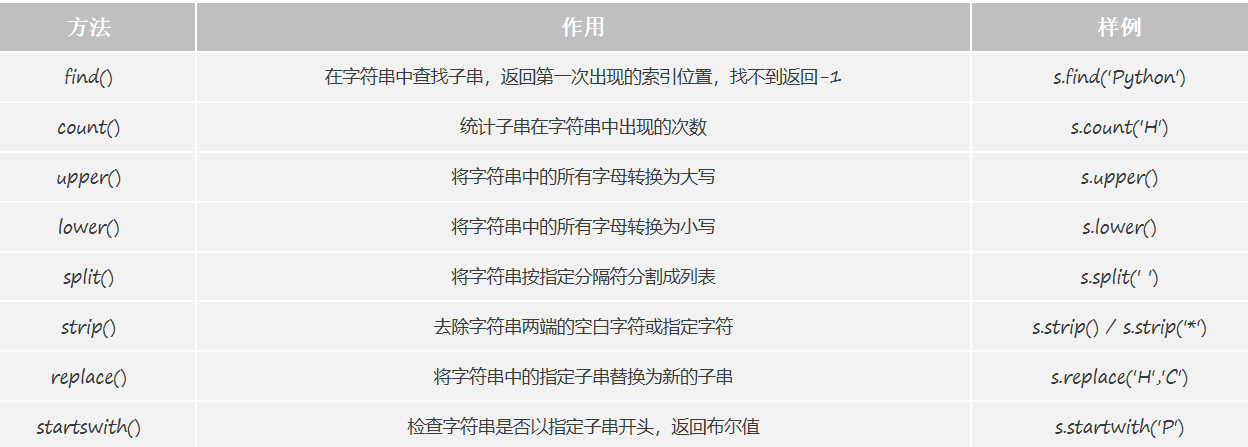
print(s[::-1])(2)字符串常用方法:
python
s = " Hello-Python-Hello-World "
# find() 查找指定字符串第一次出现的索引位置
index = s.find("-")
print(index)
# count() 统计子字符串在指定字符串中出现的次数
c = s.count("o")
print(c)
# upper() 转为大写
su = s.upper()
print(su)
# lower() 转为小写
sl = s.lower()
print(sl)
# split() 将字符串按照指定字符串切割 - 列表
slist = s.split("-")
print(slist)
# strip() 去除字符串两端的空格
ss = s.strip()
print(ss)
# replace() 将字符串中的指定子串替换为新的内容
sr = s.replace("-", "_")
print(sr)
# startswith() / endswith() 判断字符串是否是以指定的字符串开头 / 结尾, 返回布尔值
print(s.startswith("Hello"))
print(s.endswith("Python"))
print("-------------------------------------------")
print(s)(3)如何判断指定的子字符串是否出现在字符串之中?
in运算符,返回bool值
案例1: 邮箱格式验证:用户输入一个邮箱, 验证邮箱格式是否正确(包含一个@和至少一个.), 如果输入正确, 输出"邮箱格式正确", 否则输出"邮箱格式错误"。
python
# 方式一:
# 1. 接收用户输入的邮箱
mail = input("请输入邮箱: ")
# 2. 判断邮箱的格式
if mail.count("@") == 1 and mail.count(".") >= 1:
print(f"{mail} 是合法的邮箱")
else:
print(f"{mail} 是非法的邮箱")
python
# 方式二: in 运算符 ---> 判断子串是否存在字符串中, 存在, 返回True; 否则, 返回False
# 1. 接收用户输入的邮箱
mail = input("请输入邮箱: ")
# 2. 判断邮箱的格式
if mail.count("@") == 1 and "." in mail:
print(f"{mail} 是合法的邮箱")
else:
print(f"{mail} 是非法的邮箱")3.元组(tuple):元组是不可变的序列,类似于列表,但创建后不能修改。
特点:
可以存储不同类型的元素
元素可以重复、有序、不可以修改 (支持索引访问、切片)
(1)定义元组:元组名称 = (元素1,元素2,...)
t1 = (5, 7, 9, 1, 2, 3, 10, 6, 4, 8 ,12, 7, 5)
定义空元组:元组名称 = () 元组名称 = tuple()
t2 = ()
t3 = tuple()
python
# 元组基本操作 - tuple ---> 元素可以重复, 有序, 不可修改
# 定义
t1 = (80, 95, 78, 50, 76, 80, 85, 20)
print(t1)
print(type(t1))
# 索引访问
print(t1[0])
print(t1[-1])(2)方法
count():统计某元素在元组中出现的次数
index():查找某个元素在元组中的索引位置(第一次出现的位置)
python
# # 切片
t1 = (80, 95, 78, 50, 76, 80, 85, 20)
print(t1[0:5:1])
# count() 统计元素的个数
print(t1.count(80))
# index() 获取元素的索引(第一个元素的位置)
print(t1.index(80))
# 注意点: 如果定义单元素的元组, 单个元素之后需要加上逗号, 比如 (100,)
t2 = ()
print(t2)
print(type(t2))
t3 = (100,)
print(t3)
print(type(t3))(3)组包与解包
组包(Packing):将多个值合并到一个容器(元组、列表)中。
解包(Unpacking):将容器(元组、列表)解开成独立的元素,分别赋值给多个变量。
说明:在元组解包时,* 表示收集剩余的所有元素,允许我们处理不确定数量的元素(生成列表,以便于可以进行进一步的处理)。
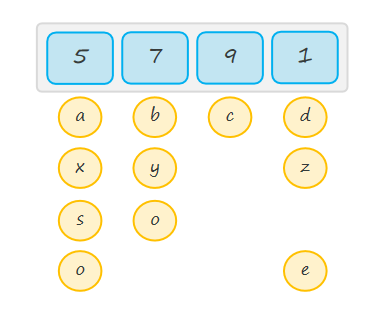
python
# 定义元组, 组包
t1 = (5, 7, 9, 1)
# 定义元组, 组包
t2 = 5, 7, 9, 1
# 基础解包
a, b, c, d = t1
# (*)扩展解包
x, *y, z = t2 # x为5,y为[7, 9],z为1
s, *o = t2 # s为5,o为[7, 9, 1]
*o, e = t2 # o为[5, 7, 9],e为1
# 组包操作
t1 = (5, 7, 9, 10, 2, 23, 12)
t2 = 5, 7, 9, 10, 2, 23, 12
print(t1)
print(t2)
# 解包操作
# 基础解包(变量数量与容器的元素个数一致)
a,b,c,d,e,f,g = t1
print(a,b,c,d,e,f,g)
# * 扩展解包 (* 收集剩余的所有元素, 封装列表list中)
first,second,*other,last = t1
print(first,second)
print(other)
print(last)
*other,last2,last1 = t1
print(other)
print(last2)
print(last1)案例1: 现有两个变量,分别为:a = 10, b = 20,现需要将这两个变量值交换,然后输出到控制台。
python
a = 10
b = 20
# 组包
t = b,a
# # 解包
a,b = t
# 合并
a,b = b,a
print(a) # 20
print(b) # 10案例2: 现有三个变量,分别为:a = 100,b = 200,c = 300,现需要将这三个变量值进行交换,将a,b,c的值分别赋值给c,a,b,并将其输出到控制台。
python
a = 100
b = 200
c = 300
# 组包与解包操作
c,a,b = a,b,c
print(a)
print(b)
print(c)
根据如下提供的学生成绩单,完成如下需求: 1. 计算每个学生的总分、各科平均分,然后一并输出出来。 2. 统计各科成绩的最低分、最高分、平均分,并输出。 3. 查找成绩优秀(平均分大于90)的学生,并输出。
python
students = (
("S001", "王林", 85, 92, 78),
("S002", "李慕婉", 92, 88, 95),
("S003", "十三", 78, 85, 82),
("S004", "曾牛", 88, 79, 91),
("S005", "周轶", 95, 96, 89),
("S006", "王卓", 76, 82, 77),
("S007", "红蝶", 89, 91, 94),
("S008", "徐立国", 75, 69, 82),
("S009", "许木", 86, 89, 98),
("S010", "遁天", 66, 59, 72)
)
# 1. 计算每个学生的总分、各科平均分,然后一并输出出来。 ---> {avg:.1f} ---> 保留1位小数 .
print("学号\t\t姓名\t\t语文\t\t数学\t\t英语\t\t总分\t\t平均分")
# 方式一:
for s in students: # ("S001", "王林", 85, 92, 78)
total = s[2] + s[3] + s[4]
avg = total / 3
print(f"{s[0]} \t {s[1]} \t {s[2]} \t {s[3]} \t {s[4]} \t {total} \t {avg:.1f}")
# 方式二: 元组解包
for id,name,chinese,math,english in students:
total = chinese + math + english
avg = total / 3
print(f"{id} \t {name} \t {chinese} \t {math} \t {english} \t {total} \t {avg:.1f}")
print()2.统计各科成绩的最低分、最高分、平均分,并输出
python
# 2.1 获取到各科的成绩列表
chinese_scores = [s[2] for s in students]
math_scores = [s[3] for s in students]
english_scores = [s[4] for s in students]
# 2.2 统计各科成绩的最低分、最高分、平均分,并输出。
print(f"语文最低分: {min(chinese_scores)}, 最高分: {max(chinese_scores)}, 平均分: {sum(chinese_scores)/len(chinese_scores)}")
print(f"数学最低分: {min(math_scores)}, 最高分: {max(math_scores)}, 平均分: {sum(math_scores)/len(math_scores)}")
print(f"英语最低分: {min(english_scores)}, 最高分: {max(english_scores)}, 平均分: {sum(english_scores)/len(english_scores)}")
print()
# 3. 查找成绩优秀(平均分大于90)的学生,并输出。
print("优秀学生(平均分 > 90)名单如下: ")
# 方式一:
for s in students:
total = s[2] + s[3] + s[4]
avg = total / 3
if avg > 90: # 优秀学生
print(f"学号: {s[0]}, 姓名: {s[1]}, 平均分: {avg:.1f}")
# 方式二: 元组解包
for id,name,chinese,math,english in students:
total = chinese + math + english
avg = total / 3
if avg > 90: # 优秀学生
print(f"学号: {id}, 姓名: {name}, 平均分: {avg:.1f}")4.集合(set):是一种无序的、不可重复、可修改的数据容器。
定义集合
s1 = {"C", "D", "X", "T", "O", "U"}
定义空集合
s2 = set()
注意:空集合的定义不可以使用{},{}表示的是空字典;由于集合是无序的,因此是不支持下标索引访问的。
python
# 集合 set ---> 无序, 不可重复, 可修改
# 定义
s1 = {5, 3, 2, 0, 9 ,12, 43, 64, 22, 5, 0}
print(s1)
print(type(s1))
# 定义空集合
s2 = set()
print(s2)
print(type(s2))(1)集合常见的用法
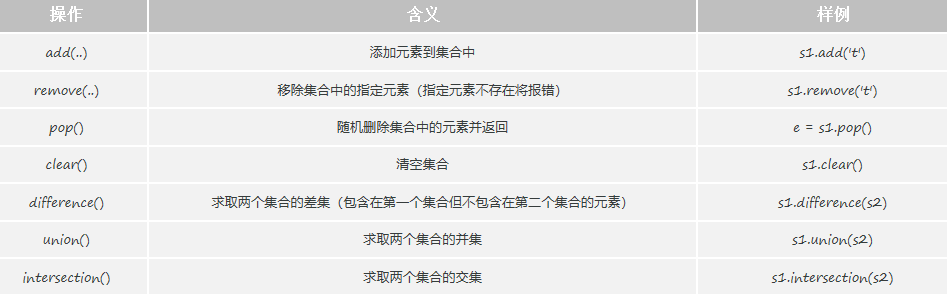
python
# 常见方法 :
# add() : 添加元素到集合
s1 = {100,200,300,400,500,600,700,800}
print(s1)
s1.add(1200)
print(s1)
# remove() : 移除集合中的指定元素(指定元素不存在将报错)
s1.remove(200)
print(s1)
# pop() : 随机删除集合中的元素并返回
e = s1.pop()
print(e)
print(s1)
# clear() : 清空集合
s1.clear()
print(s1)
#
s2 = {"A", "B", "C", "D", "E", "X", "Y"}
s3 = {"C", "E", "Y", "Z"}
# difference() : 求两个集合的差集 (存在于第一个集合, 但不存在于第二个集合)
print(s2.difference(s3))
print(s3.difference(s2))
# union() : 求两个集合的并集
print(s2.union(s3))
# intersection() : 求两个集合的交集
print(s2.intersection(s3))(2)集合set操作的运算符 & | -
&:交集
|:并集
-:差集
(3)集合推导式的写法
变量名称={i表达式 for i in 列表}
变量名称={i表达式 for i in 列表 if 条件}
案例
python
# 选修足球学生名单
football_set = {"王林", "曾牛", "徐立国", "遁天", "天运子", "韩立", "厉飞雨", "乌丑", "紫灵"}
# 选修篮球学生名单
basketball_set = {"张铁", "墨居仁","王林", "姜老道", "曾牛", "王蝉", "韩立", "天运子", "李化元", "厉飞雨", "云露"}
# 选修法语学生名单
french_set = {"许木", "王卓", "十三", "虎咆", "姜老道", "天运子", "红蝶", "厉飞雨", "韩立", "曾牛"}
# 选修艺术学生名单
art_set = { "遁天", "天运子", "韩立", "虎咆", "姜老道", "紫灵"}
# 1. 找出同时选修了 法语 和 艺术 的学生 french_set art_set
# 方式一:
fa_set = french_set.intersection(art_set)
print(f"同时选修了 法语 和 艺术 的学生: {fa_set}")
# 方式二: & --> 交集
fa_set2 = french_set & art_set
print(f"同时选修了 法语 和 艺术 的学生: {fa_set2}")
# 2. 找出同时选修了所有四门课程的学生
all_set = football_set & basketball_set & french_set & art_set
print(f"同时选修了所有四门课程的学生: {all_set}")
# 3. 找出选修了足球, 但是没有选修篮球的学生 - 差集
# 方式一:
fb_set = football_set.difference(basketball_set)
print(f"选修了足球, 但是没有选修篮球的学生: {fb_set}")
# 方式二: - ---> 差集
fb_set2 = football_set - basketball_set
print(f"选修了足球, 但是没有选修篮球的学生: {fb_set2}")
# 方式三: 集合推导式 ---> 快速构建集合, 语法: {要往集合中添加的数据 for s in set1 if 条件}
fb_set3 = {s for s in football_set if s not in basketball_set}
print(f"选修了足球, 但是没有选修篮球的学生: {fb_set3}")
# 4. 统计每一个学生选修的课程数量
# 4.1 获取到学生名单 -- 并集 (|)
# all_set = football_set.union(basketball_set).union(french_set).union(art_set)
all_set = football_set | basketball_set | french_set | art_set
# 4.2 获取每一个学生选修的课程数量
all_list = [*football_set, *basketball_set, *french_set, *art_set]
for s in all_set:
print(f"{s} 选修了 {all_list.count(s)} 课程")5.字典(dict):Python中的字典(dict),里面存储的是键值对(key: value)类型的数据,可以根据键(key)找到对应的值(value)。
特点:键值对(key:value)存储、键(key)不能重复、可修改。
注意:字典(dict)中的value可以是任何类型的数据,而key不能为可变类型(如:不能为 列表list、集合set、字典dict)。
python
# 定义字典字典名称 = {key: value, key:value, key:value ...}
# 定义字典
dict1 = {"王林": 675, "李慕婉": 608, "许立国": 478, ...}
# 定义空字典
字典名称 = {}
字典名称 = dict()
# 根据key获取value
值 = 字典名称[key]
score = dict1["李思"]
python
# 字典 -- key不能重复(如果重复, 后面的值, 会覆盖前面的值)、key必须得是不可变类型(str,int,float,tuple)
# 定义字典
dict1 = {"王林":670, "李慕婉":608, "徐立国":580, "韩立":688}
print(dict1)
print(type(dict1))
# key必须得是不可变类型(str,int,float,tuple), 不能是 list、set、dict
dict2 = {0:670, 1.5:608, (1,2):580, ('A','B'):688}
print(dict2)
# 访问
print(dict1["李慕婉"]) # 获取
dict1["李慕婉"] = 688 # 修改
print(dict1)(1)字典的增删改查
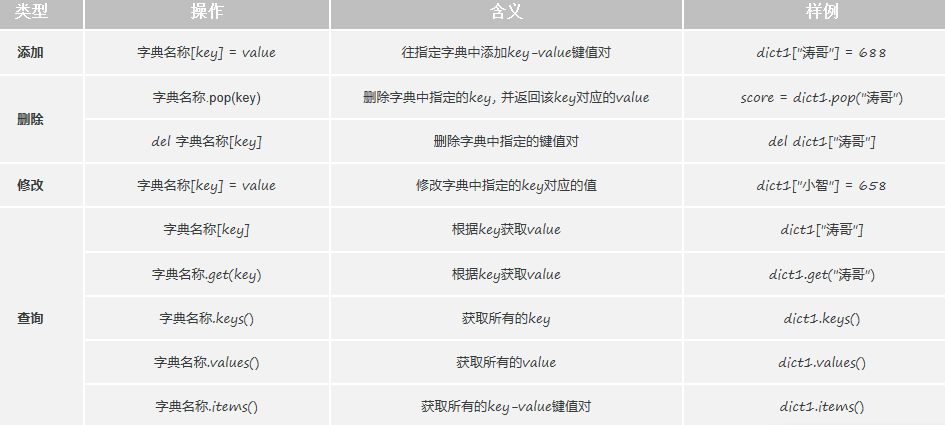
python
dict1 = {"王林":670, "李慕婉":608, "许立国":580, "韩立":688}
print(dict1)
# 添加 - key不存在就是添加
dict1["涛哥"] = 550
print(dict1)
# 修改 - key存在就是修改
dict1["涛哥"] = 620
print(dict1)
# 查询
print(dict1["涛哥"]) # 根据key获取value
print(dict1.get("涛哥")) # 根据key获取value
print(dict1.keys()) # 获取所有的key
print(dict1.values()) # 获取所有的value
print(dict1.items()) # 获取所有的键值对 key:value
# 删除
score = dict1.pop("许立国")
print(score)
print(dict1)
del dict1["韩立"]
print(dict1)(2)字典的遍历:字典支持for循环遍历 通过keys()、values()、items() 进行循环遍历
python
# 遍历
dict1 = {"王林":670, "李慕婉":608, "许立国":580, "韩立":688}
for k in dict1.keys():
print(f"{k} : {dict1[k]}")
for item in dict1.items():
print(f"{item[0]} : {item[1]}")
for k,v in dict1.items():
print(f"{k} : {v}")
案例: 开发一个购物车管理系统,实现商品信息的添加、修改、删除、查询和统计功能。系统使用嵌套字典结构存储商品数据,通过控制台菜单与用户交互。 具体功能如下: 1. 添加购物车:用户根据提示录入商品名称、以及该商品的价格、数量,保存该商品信息到购物车。 2. 修改购物车:要求用户输入要修改的购物车商品名称,然后再提示输入该商品的价格、数量,输入完成后修改该商品信息。 3. 删除购物车:要求用户输入要删除的购物车名称,根据名称删除购物车中的商品。 4. 查询购物车:将购物车中的商品信息展示出来,格式为:"商品名称: xxx, 商品价格: xxx, 商品数量: xxx"。 5. 退出购物车 结构: shopping_cart = {"Meta80": {"price": 6999, "num": 2}, "鼠标": {...}}
python
shopping_cart = {}
menu = """
########### 购物车系统 ##########
# 1. 添加购物车 #
# 2. 修改购物车 #
# 3. 删除购物车 #
# 4. 查询购物车 #
# 5. 退出购物车 #
###############################
"""
print("欢迎使用购物车管理系统 ~")
while True:
# 1. 制作菜单
print(menu)
# 2. 执行的具体操作
choice = input("请选择要执行的操作(1-5): ")
match choice:
case "1": # 添加购物车
goods_name = input("请输入商品名称: ")
goods_price = float(input("请输入商品价格: "))
goods_num = int(input("请输入商品数量: "))
# 如果商品存在, 则不执行添加, 提示信息
if goods_name in shopping_cart:
print("该商品已存在, 请重新选择 ~")
else:
shopping_cart[goods_name] = {"price": goods_price, "num": goods_num}
print("商品添加完毕 ~")
case "2": # 修改购物车
goods_name = input("请输入要修改的商品名称: ")
# 如果商品不存在, 则提示错误信息, 重新选择
if goods_name not in shopping_cart:
print("该商品不存在, 请重新选择 ~")
continue
goods_price = float(input("请输入商品最新的价格: "))
goods_num = int(input("请输入商品最新的数量: "))
shopping_cart[goods_name] = {"price": goods_price, "num": goods_num}
print("商品修改完毕 ~")
case "3": # 删除购物车
goods_name = input("请输入要删除的商品名称: ")
# 如果商品不存在, 则提示错误信息, 重新选择
if goods_name not in shopping_cart:
print("该商品不存在, 请重新选择 ~")
else:
del shopping_cart[goods_name]
print("商品删除完毕 ~")
case "4": # 查询购物车
for goods_name in shopping_cart.keys():
goods_info = shopping_cart[goods_name]
print(f"商品名称: {goods_name}, 商品价格: {goods_info['price']}, 商品数量: {goods_info['num']}")
case "5": # 退出购物车
print("Bye ~")
break
case _: # 匹配其他所有情况
print("非法操作, 不支持!!!")6.数据容器总结与对比